全新緩存組件,大幅加速雲上飛槳分佈式訓練作業

在Kubernetes的架構體系中,計算與存儲是分離的,這給數據密集型的深度學習作業帶來較高的網絡IO開銷。為了解決該問題,我們基於JuiceFS在開源項目Paddle Operator中實現了樣本緩存組件,大幅提升了雲上飛槳分佈式訓練作業的執行效率。
*JuiceFS:
http://github.com/juicedata/juicefs
*Paddle Operator:
http://github.com/PaddleFlow/paddle-operator
背景介紹
由於雲計算平台具有高可擴展性、高可靠性、廉價性等特點,越來越多的機器學習任務運行在Kubernetes集羣上。因此我們開源了Paddle Operator項目,通過提供PaddleJob自定義資源,讓雲上用户可以很方便地在Kubernetes集羣使用飛槳(PaddlePaddle)深度學習框架運行模型訓練作業。
然而,在深度學習整個pipeline中,樣本數據的準備工作也是非常重要的一環。目前雲上深度學習模型訓練的常規方案主要採用手動或腳本的方式準備數據,這種方案比較繁瑣且會帶來諸多問題。比如將HDFS裏的數據複製到計算集羣本地,然而數據會不斷更新,需要定期的同步數據,這個過程的管理成本較高;或者將數據導入到遠程對象存儲,通過製作PV和PVC來訪問樣本數據,從而模型訓練作業就需要訪問遠程存儲來獲取樣本數據,這就帶來較高的網絡IO開銷。
*Paddle Operator:
http://github.com/PaddleFlow/paddle-operator
http://www.paddlepaddle.org.cn/
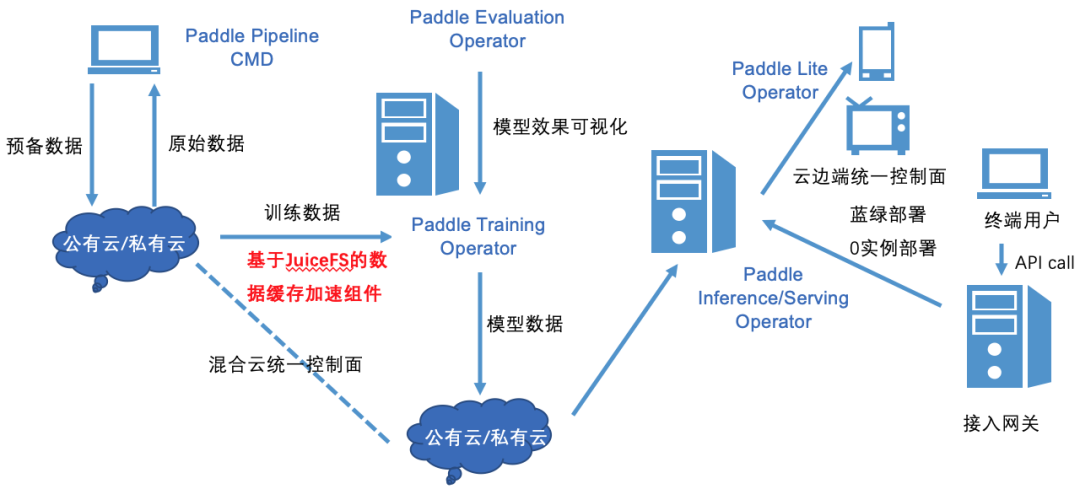
為了方便雲上用户管理樣本數據,加速雲上飛槳框架分佈式訓練作業,我們與JuiceFS社區合作,聯合推出了面向飛槳框架的樣本緩存與管理方案,該方案期望達到如下目標:
-
數據集及其管理操作的自定義資源抽象。將樣本數據集及其管理操作抽象成Kubernetes的自定義資源,屏蔽數據操作的底層細節,減輕用户心智負擔。用户可以很方便地通過操作自定義資源對象來管理數據,包括數據同步、數據預熱、清理緩存、淘汰歷史數據等,同時也支持定時任務。
-
基於JuiceFS加速遠程數據訪問。JuiceFS是一款面向雲環境設計的高性能共享文件系統,其在數據組織管理和訪問性能上進行了大量針對性的優化。基於JuiceFS實現樣本數據緩存引擎,能夠提供高效的文件訪問性能。
-
充分利用本地存儲,緩存加速模型訓練。要能夠充分利用計算集羣本地存儲,比如內存和磁盤,來緩存熱點樣本數據集,並配合緩存親和性調度,在用户無感知的情況下,智能地將作業調度到有緩存的節點上。這樣就不用反覆訪問遠程存儲,從而加速模型訓練速度,一定程度上也能提升GPU資源的利用率。
-
統一數據接口,支持多種存儲後端。樣本緩存組件要能夠支持多種存儲後端,並且能提供統一的POSIX協議接口,用户無需在模型開發和訓練階段使用不同的數據訪問接口,降低模型開發成本。同時樣本緩存組件也要能夠支持從多個不同的存儲源導入數據,適配用户現有的數據存儲狀態。
面臨的挑戰
然而,在Kubernetes的架構體系中,計算與存儲是分離的,這種架構給上訴目標的實現帶來了些挑戰,主要體現在如下幾點:
-
Kubernetes 調度器是緩存無感知的,也就是説kube-scheduler並沒有針對本地緩存數據的調度策略,因此模型訓練作業未必能調度到有緩存的節點,從而導致緩存無法重用。如何實現緩存親和性調度,協同編排訓練作業與緩存數據,是我們面臨的首要問題。
-
在數據並行的分佈式訓練任務中,單機往往存放不下所有的樣本數據,因此樣本數據是要能夠以分區的形式分散緩存在各計算節點上。然而,我們知道負責管理自定義資源的控制器(Controller Manager)不一定運行在緩存節點上,如何通過自定義控制器來管理分佈式的緩存數據,也是實現該方案時要考慮的難點問題。
-
除了前述兩點,如何結合飛槳框架合理地對樣本數據進行分發和預熱,提高本地緩存命中率,減少作業訪問遠程數據的次數,從而提高作業執行效率,這還需要進一步的探索。
針對上述問題,我們在開源項目Paddle Operator中提供了樣本緩存組件,較好地解決了這些挑戰,下文將詳細闡述我們的解決方案。
整體設計方案
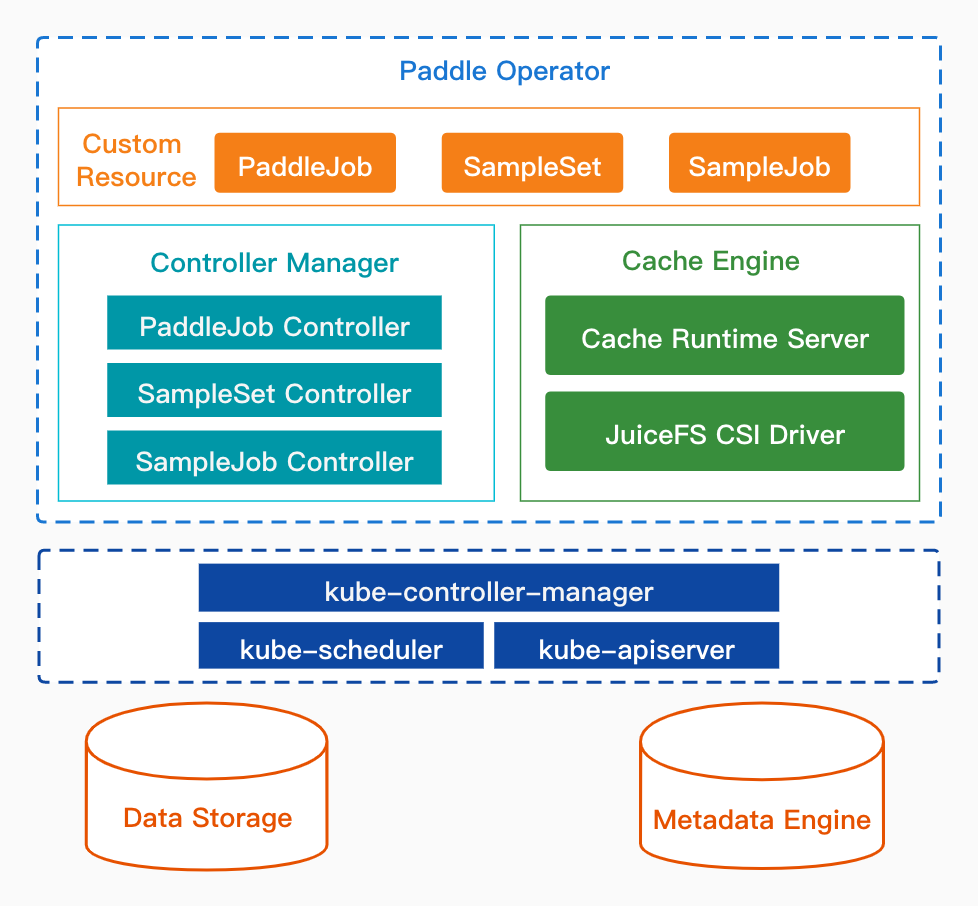
上圖是Paddle Operator的整體架構,其構建在Kubernetes上,包含如下三個主要部分:
1.自定義API資源(Custom Resource)
Paddle Operator定義了三個CRD,用户可編寫和修改對應的YAML文件來管理訓練作業和樣本數據集。
-
PaddleJob是飛槳分佈式訓練作業的抽象,它將Parameter Server(參數服務器)和Collective(集合通信)兩種分佈式深度學習架構模式統一到一個CRD中,用户通過創建PaddleJob可以很方便地在Kubernetes集羣運行分佈式訓練作業。
-
SampleSet是樣本數據集的抽象,數據可以來自遠程對象存儲、HDFS或Ceph等分佈式文件系統,並且可以指定緩存數據的分區數、使用的緩存引擎、 多級緩存目錄等配置。
-
SampleJob定義了些樣本數據集的管理作業,包括數據同步、數據預熱、清除緩存、淘汰歷史舊數據等操作,支持用户設置各個數據操作命令的參數, 同時還支持以定時任務的方式運行數據管理作業。
2.自定義控制器(Controller Manager)
控制器在 Kubernetes 的 Operator 框架中是用來監聽 API 對象的變化(比如創建、修改、刪除等),然後以此來決定實際要執行的具體工作。
-
PaddleJob Controller負責管理PaddleJob的生命週期,比如創建參數服務器和訓練節點的Pod,並維護工作節點的副本數等。
-
SampleSet Controller負責管理SampleSet的生命週期,其中包括創建 PV/PVC等資源對象、創建緩存運行時服務、給緩存節點打標籤等工作。
-
SampleJob Controller負責管理SampleJob的生命週期,通過請求緩存運行時服務的接口,觸發緩存引擎異步執行數據管理操作,並獲取執行結果。
3.緩存引擎(Cache Engine)
緩存引擎由緩存運行時服務(Cache Runtime Server)和JuiceFS存儲插件(JuiceFS CSI Driver)兩部分組成,提供了樣本數據存儲、緩存、管理的功能。
-
Cache Runtime Server負責樣本數據的管理工作,接收來自SampleSet Controller和SampleJob Controller的數據操作請求,並調用JuiceFS客户端完成相關操作執行。
-
JuiceFS CSI Driver是JuiceFS社區提供的CSI插件,負責樣本數據的存儲與緩存工作,將樣本數據緩存到集羣本地並將數據掛載進PaddleJob的訓練節點。
*JuiceFS存儲插件:
http://github.com/juicedata/juicefs-csi-driver
難點突破與優化
在上述的整體架構中,Cache Runtime Server是非常重要的一個組件,它由Kubernetes原生的API資源StatefulSet實現,在每個緩存節點上都會運行該服務,其承擔了緩存數據分區管理等工作,也是解決難點問題的突破口。下圖是用户創建SampleSet後,Paddle Operator對PaddleJob完成緩存親和性調度的大概流程。
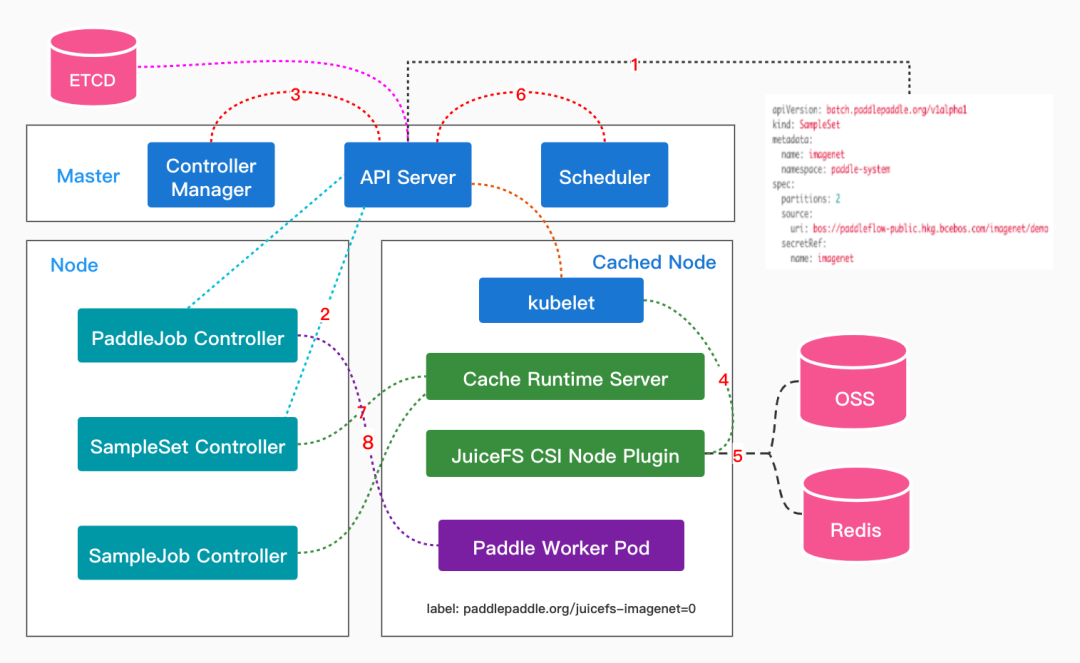
當用户創建SampleSet後,SampleSet Controller就會根據 SampleSet中的配置創建出PV和PVC。在PV和PVC完成綁定後,SampleSet Controller則會將PVC添加到Runtime Pod模板中,並創建出指定分區數的Cache Runtime Server。在Cache Runtime Server成功調度到相應節點後,SampleSet Controller則會對該節點做標記,且標記中還帶有緩存的分區數。這樣等下次用户提交PaddleJob時,Paddle Controller會自動地給Paddle Worker Pod添加nodeAffinity和PVC字段,這樣調度器(Scheduler)就能將Paddle Worker調度到指定的緩存分區節點上,這即實現了對模型訓練作業的緩存親和性調度。
值得一提的是,在該調度方案中,Paddle框架的訓練節點能夠做到與緩存分區一一對應的,這能夠最大程度上地利用本地緩存的優勢。當然,該方案同時也支持對PaddleJob的擴縮容,當PaddleJob的副本數大於SampleSet的分區數時(這也是可以調整的),PaddleJob Controller並不會對多出來Paddle Worker做nodeAffinity限制,這些Paddle Worker還可以通過掛載的Volume訪問遠程存儲來獲取樣本數據。
解決了緩存親和性調度的問題,我們還面臨着SampleSet/SampleJob Controller如何管理分佈式樣本緩存數據集,如何合理地做分佈式預熱的挑戰。使用JuiceFS CSI存儲插件可以解決樣本數據存儲與緩存的問題,但由於Kubernetes CSI插件提供的接口有限(只提供了與 Volume 掛載相關的接口),所以需要有額外的數據管理服務駐守在緩存節點,即:Cache Runtime Server。
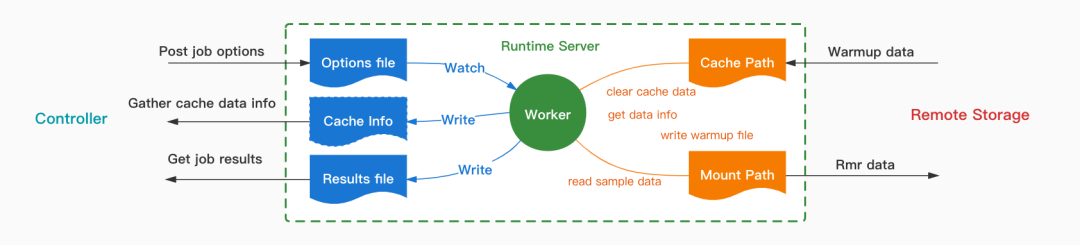
上圖是 Cache Runtime Server 內部工作流程示意圖,其中封裝了JuiceFS客户端的可執行文件。Runtime Server提供了三種類型的接口,它們的作用分別是:
1.上傳數據操作命令的參數
2.獲取數據操作命令的結果
3.獲取樣本數據集及其緩存的狀態。
Server在接收到Controller上傳的命令參數後,會將參數寫到指定路徑,然後會觸發Worker進程異步地執行相關操作命令,並將命令執行結果寫到結果路徑,然後Controller可以通過調用相關接口獲取數據管理作業的執行結果。
數據同步、清理緩存、淘汰舊數據這三個操作比較容易實現,而數據預熱操作的實現相對會複雜些。因為,當樣本數據量比較大時,單機儲存無法緩存所有數據,這時就要考慮對數據進行分區預熱和緩存。為了最大化利用本地緩存和存儲資源,我們期望對數據預熱的策略要與飛槳框架讀取樣本數據的接口保持一致。
因此,對於WarmupJob我們目前實現了兩種預熱策略:Sequence和Random,分別對應飛槳框架SequenceSampler和DistributedBatchSampler兩個數據採樣API。JuiceFS的Warmup命令支持通過--file參數指定需要預熱的文件路徑,故將0號Runtime Server作為Master,負責給各個分區節點分發待預熱的數據,即可實現根據用户指定的策略對樣本數據進行分佈式預熱的功能。
至此,難點問題基本都得以解決,該方案將緩存引擎與飛槳框架緊密結合,充分利用了本地緩存來加速雲上飛槳的分佈式訓練作業。
使用示例
下面我們通過訓練ResNet50模型的例子來簡要説明下如何使用Paddle Operator,您只需要準備兩個YAML配置文件,即可輕鬆地在Kubernetes集羣上完成複雜的分佈式深度學習任務。第一步是編寫SampleSet的YAML文件,並指定遠程數據源,如下:
apiVersion: batch.paddlepaddle.org/v1alpha1
kind: SampleSet
metadata:
name: imagenet
namespace: paddle-system
spec:
# 分區數,一個Kubernetes節點表示一個分區
partitions: 2
source:
uri: bos://paddleflow-public.hkg.bcebos.com/imagenet
secretRef:
name: imagenet
通過kubectl apply -f命令可以創建該樣本數據集,您還可以查看樣本數據集及其緩存的狀態:
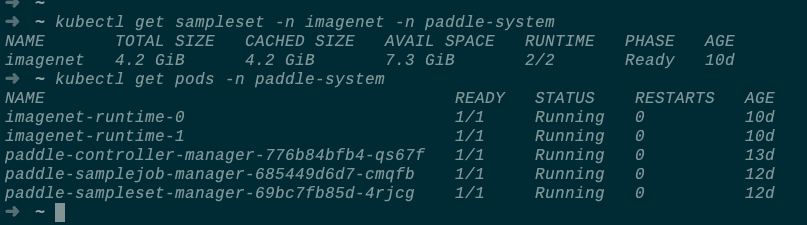
等SampleSet的狀態為Ready後,您就可以通過編寫如下的PaddleJob來完成ResNet50模型的訓練了:
apiVersion: batch.paddlepaddle.org/v1
kind: PaddleJob
metadata:
name: resnet
spec:
# 指定要使用的 SampleSet
sampleSetRef:
name: imagenet
mountPath: /data
worker:
replicas: 2
template:
spec:
containers:
- name: resnet
image: registry.baidubce.com/paddle-operator/demo-resnet:v1
command:
- python
args:
- "-m"
- "paddle.distributed.launch"
- "./tools/train.py"
- "-c"
- "./config/ResNet50.yaml"
resources:
limits:
nvidia.com/gpu: 2
更多的使用文檔可以參考Paddle Operator。
性能測試
為了驗證Paddle Operator樣本緩存加速方案的實際效果,我們選取了常規的ResNet50模型以及ImageNet數據集來進行性能測試,並使用了PaddleClas項目中提供的模型實現代碼。具體的實驗配置如下:
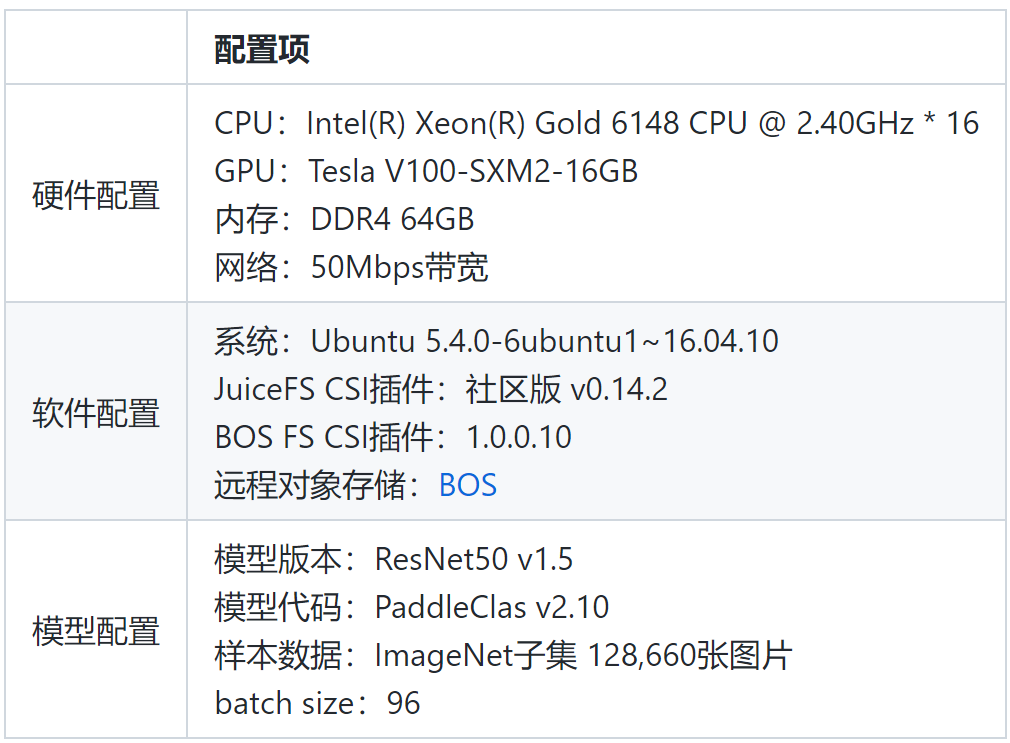
基於以上配置,我們做了兩組實驗。
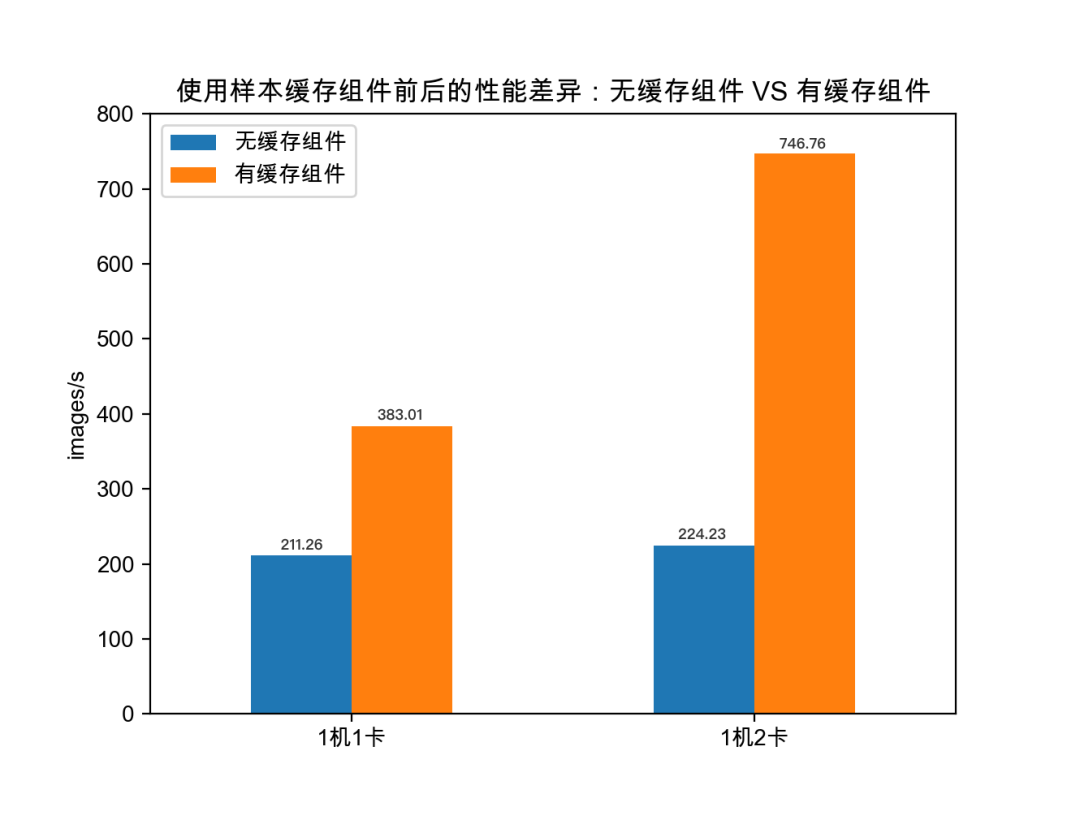
第一組實驗對比了樣本數據緩存前後的性能差異,從而驗證了使用樣本緩存組件來加速雲上飛槳訓練作業的必要性。
如上圖,在樣本數據緩存到訓練節點前,1機1卡和1機2卡的訓練速度分別為211.26和224.23 images/s;在樣本數據得以緩存到本地後,1機1卡和1機2卡的訓練速度分別為383.01和746.76 images/s。可以看出,在計算與存儲分離的Kubernetes集羣裏,由於帶寬有限(本實驗的帶寬為50Mbps),訓練作業的主要性能瓶頸在於遠程樣本數據IO上。帶寬的瓶頸並不能通過調大訓練作業的並行度來解決,並行度越高,算力浪費越為嚴重。
因此,使用樣本緩存組件提前將數據預熱到訓練集羣本地,可以大幅加速雲上飛槳訓練作業的執行效率。在本組實驗中,1機1卡訓練效率提升了81.3%,1機2卡的訓練速度提升了233%。
此外,使用樣本緩存組件預熱數據後,1機1卡383.01 images/s的訓練速度與直接在宿主機上的測試結果一致,也就是説,緩存引擎本身基本上沒有帶來性能損耗。
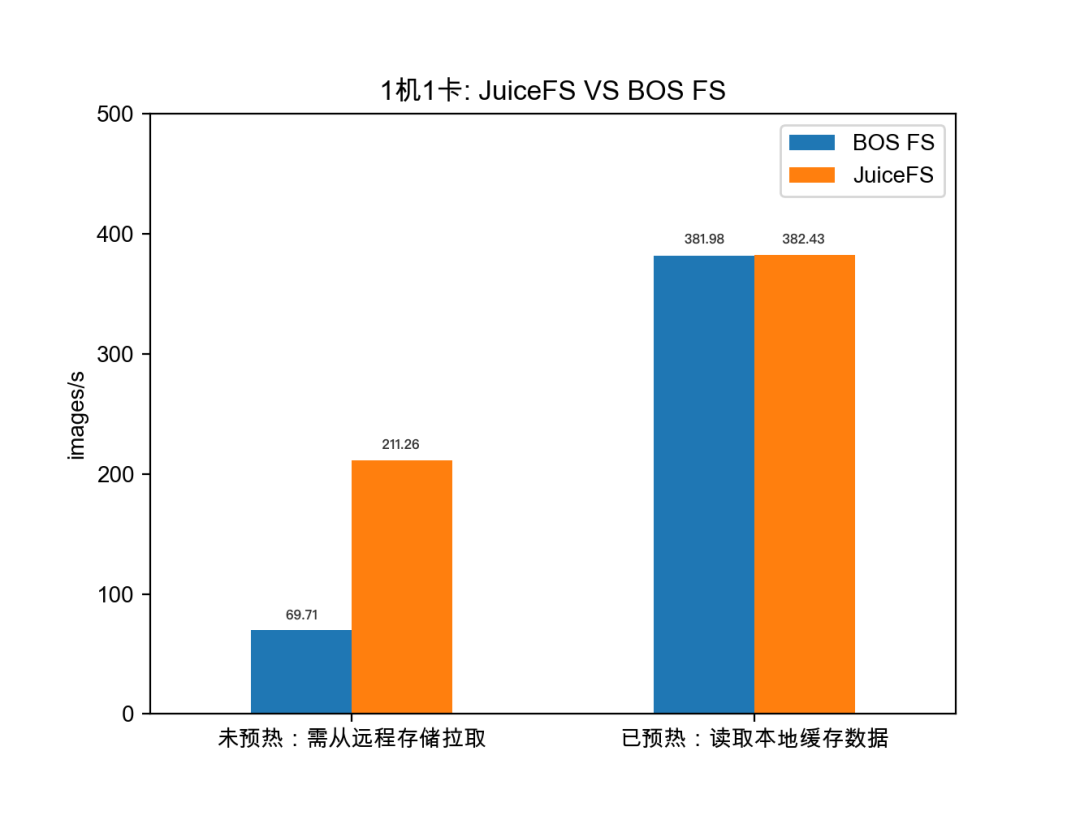
第二組實驗對比了使用1機1卡時樣本數據預熱前後JuiceFS與BOS FS的性能差異,相比於BOS FS,JuiceFS在訪問遠程小文件的場景下具有更優的性能表現。
如上圖,在樣本數據預熱到本地前,需要通過CSI插件訪問遠程對象存儲(如BOS)中的樣本數據,使用BOS FS CSI插件與JuiceFS CSI插件的訓練速度分別是69.71和211.26 images/s;在樣本數據得以緩存在本地後,使用BOS FS CSI插件與JuiceFS CSI插件的訓練速度分別是381.98和382.43 images/s,性能基本沒有差異。
由此可以看出,在訪問遠程小文件的場景下,JuiceFS相比BOS FS有近3倍的性能提升。兩者的性能差異可能與JuiceFS的文件存儲格式和BOS FS的實現有關,這有待進一步驗證。除了性能上的考量,JuiceFS提供的文件系統掛載服務更加穩定,功能完善且易用,這也是優先選擇JuiceFS作為底層緩存引擎的重要原因。
總結及展望
樣本數據的準備工作是深度學習pipeline中的重要一環,本文總結了在雲上管理樣本數據並加速其訪問效率所面臨的挑戰,在文章的第3和第4節我們給出了這些問題的詳細解決方案。進一步地,我們對Paddle Operator的樣本緩存方案進行了性能測試,實驗結果表明該方案能大幅加速雲上飛槳的模型訓練作業。現該方案已在Paddle Operator項目中開源,歡迎大家來體驗並使用。
在後續的工作中,我們將繼續完善樣本數據管理功能,提供更多的數據管理策略,並進一步加強Operator與飛槳框架的協同優化工作。除了離線訓練的場景,我們也在探索Operator支持在線學習場景的解決方案,如您對這些工作也很感興趣,歡迎參與進來一起討論、開發。
- 訓練數據有缺陷?TrustAI來幫你!
- 低代碼平台中的數據連接方式(上)
- 你一定愛讀的極簡數據平台史,從數據倉庫、數據湖到湖倉一體
- 百度APP視頻播放中的解碼優化
- 如何輕鬆上手3D檢測應用實戰?飛槳產業實踐範例全流程詳解
- 四步做好 Code Review
- 百度智能雲天工邊雲融合物聯網平台,助力設備高效上雲
- Redis 主從複製的原理及演進
- 面由心生,由臉觀心:基於AI的面部微表情分析技術解讀
- 大模型應用新範式:統一特徵表示優化(UFO)
- 智能大數據,看這本白皮書就夠了
- 效果提升28個點!基於領域預訓練和對比學習SimCSE的語義檢索
- 百度基於 Prometheus 的大規模線上業務監控實踐
- AI CFD:面向空天動力的科學機器學習新方法與新範式
- 飛槳圖神經網絡PGL助力國民級音樂App,創新迭代千億級推薦系統
- 全新緩存組件,大幅加速雲上飛槳分佈式訓練作業
- 知乎用户畫像和實時數據的架構與實踐
- 全新緩存組件,大幅加速雲上飛槳分佈式訓練作業
- “千言”開源數據集項目全面升級:數據驅動AI技術進步
- 百度CTO王海峯:AI大生產平台再升級 助力中國科技自立自強