OneFlow源碼解析:Eager模式下的設備管理與併發執行

作者|鄭建華
更新|趙露陽
通過這篇筆記,希望能初步瞭解 OneFlow 在 Eager 模式下對設備的管理方式、設備執行計算的過程以及如何充分利用設備計算能力。這裏的設備主要指類似 CUDA 這樣的並行計算加速設備。
1
設備、流相關類型及關係
框架通過流(Stream)向設備(Device)提交計算任務。一個 Stream 是一個命令序列,可以類比 CUDA Stream(http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#streams),或者 CPU Thread 的指令序列。同一個 Stream 中的命令按順序執行;不同 Stream 之間的命令有依賴關係時,需要同步。不同的任務,比如 kernel 計算、host2device、device2host 等都有自己獨立的 Stream,可以併發執行,從而在 Eager 模式下儘可能充分利用設備的異步併發執行能力。
OneFlow 中Device和Stream相關的部分類結構如下所示:
Device相關類型
oneflow::Device
oneflow::Device是用於表示設備的基礎類型,例如:構建tensor時 flow.tensor(shape, device="cuda:1")就會在內部構造出這個基礎的Device類型,其中設備編號為1、設備類型為CUDA。
oneflow/core/framework/device.h:
class Device final {public:...private:Device(const std::string& type, int64_t device_id);Maybe<void> Init();const std::string type_;DeviceType enum_type_;const int64_t device_id_;const size_t hash_value_;std::shared_ptr<MemoryCase> mem_case_;};
oneflow::Device中最重要的兩個成員變量分別是用於表示設備類型的DeviceType;用於表示設備編號的device_id_。
DeviceType
DeviceType是一個枚舉類,不同的值代表不同的計算設備類型,其定義位於 oneflow/core/common/device_type.proto:
enum DeviceType {kInvalidDevice = 0; // 無效設備kCPU = 1; // cpu設備kCUDA = 2; // cuda設備kMockDevice = 3; // pseudo device for test.}
目前在oneflow master分支中,主要有kCPU表示cpu設備;kCUDA表示nvidia cuda設備;在其他多設備支持的分支中,這裏還增加了更多的設備類型。
oneflow::ep::Device
oneflow::Device是oneflow中對設備的基礎封裝類型,而oneflow::ep::Device則是一個抽象類,屬於oneflow的ep模塊(execution provider),是對設備行為的封裝,ep模塊為多硬件設備提供了更高層次的抽象,方便oneflow支持和兼容多硬件設備提供了更高的靈活性和可拓展性。
oneflow::ep::Device不僅提供了表示設備類型的device_type()方法、表示設備編號的device_index()方法,還提供了創建/銷燬ep::Stream、創建/銷燬Event、在設備上申請/釋放內存的各種方法。
oneflow/core/ep/include/device.h:
class Device {public:OF_DISALLOW_COPY_AND_MOVE(Device);Device() = default;virtual ~Device() = default;virtual void SetAsActiveDevice() = 0;virtual DeviceType device_type() const = 0;virtual size_t device_index() const = 0;virtual DeviceManager* device_manager() const = 0;virtual Stream* CreateStream() = 0;virtual void DestroyStream(Stream* stream) = 0;virtual Event* CreateEvent();virtual void DestroyEvent(Event* event);virtual void CreateEvents(Event** events, size_t count) = 0;virtual void DestroyEvents(Event** events, size_t count) = 0;virtual Maybe<void> Alloc(const AllocationOptions& options, void** ptr, size_t size) = 0;virtual void Free(const AllocationOptions& options, void* ptr) = 0;virtual Maybe<void> AllocPinned(const AllocationOptions& options, void** ptr, size_t size) = 0;virtual void FreePinned(const AllocationOptions& options, void* ptr) = 0;virtual bool IsStreamOrderedMemoryAllocationSupported() const;};
oneflow::ep::Device有如下子類實現:
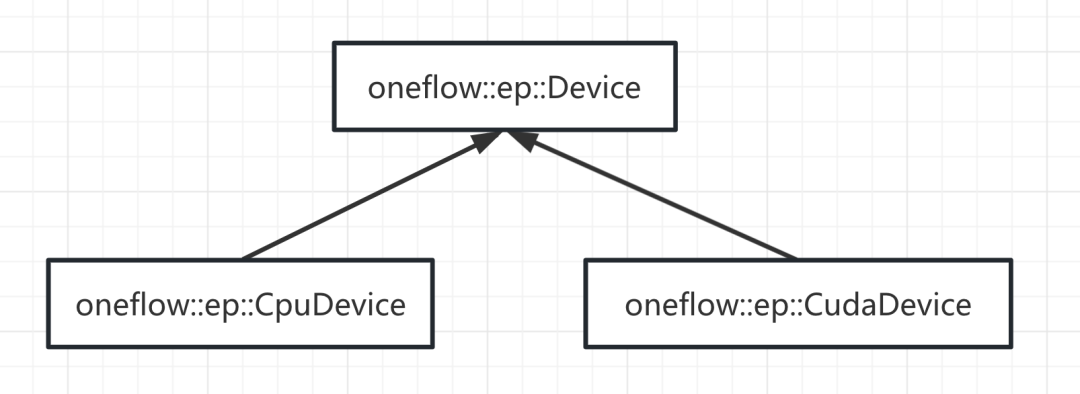
Stream相關類型
oneflow::Stream和cuda device以及stream的關係類似,oneflow中也存在類似的基礎Stream類型。
oneflow/core/framework/stream.h:
class Stream final {....private:Stream(Symbol<Device> device, StreamType stream_type, size_t thread_uid);static Maybe<Symbol<Stream>> RawNew(Symbol<Device> device, StreamType stream_type,size_t thread_uid);Maybe<void> Init(size_t unique_stream_id);Symbol<Device> device_;StreamType stream_type_;size_t thread_uid_;size_t unique_stream_id_;};
可以看見Stream類中的成員變量:
-
device_ 表示該Stream對象將在何種設備上執行 -
streamtype_ 表示該Stream的類型,是用於計算的compute stream還是用於數據搬運的host2device、device2host stream等 -
threaduid_ 表示負責啟動該Stream的線程id -
unique_streamid_ 表示這個stream自身的unique id
StreamType
enum class StreamType {kInvalid = 0, // 無效kCompute, // kernel計算流kHost2Device, // 數據搬運(host -> device)流kDevice2Host, // 數據搬運(device -> host)流kCcl, // 集合通信流kBarrier, // 線程屏障流kCriticalSection,// 臨界區流kLazyJobLauncher,// job啟動流(lazy mode)kPinnedCompute // pinned memory kernel計算流};
oneflow::ep::Stream
-
同步Sync() -
執行Event事件RecordEvent()
class Stream {public:OF_DISALLOW_COPY_AND_MOVE(Stream);Stream() = default;virtual ~Stream() = default;virtual DeviceType device_type() const = 0;virtual Device* device() const = 0;virtual Maybe<void> Sync() = 0;virtual void RecordEvent(Event* event) = 0;virtual Maybe<void> GetAsyncError() { return Maybe<void>::Ok(); }virtual Maybe<void> AllocAsync(void** ptr, size_t size) { UNIMPLEMENTED_THEN_RETURN(); }virtual Maybe<void> FreeAsync(void* ptr) { UNIMPLEMENTED_THEN_RETURN(); }template<typename T>Maybe<void> AllocAsync(T** ptr, size_t size) {return AllocAsync(reinterpret_cast<void**>(ptr), size);}virtual Maybe<void> OnExecutionContextSetup() { return Maybe<void>::Ok(); }virtual Maybe<void> OnExecutionContextTeardown() { return Maybe<void>::Ok(); }template<typename T>T* As() {return static_cast<T*>(this);}};
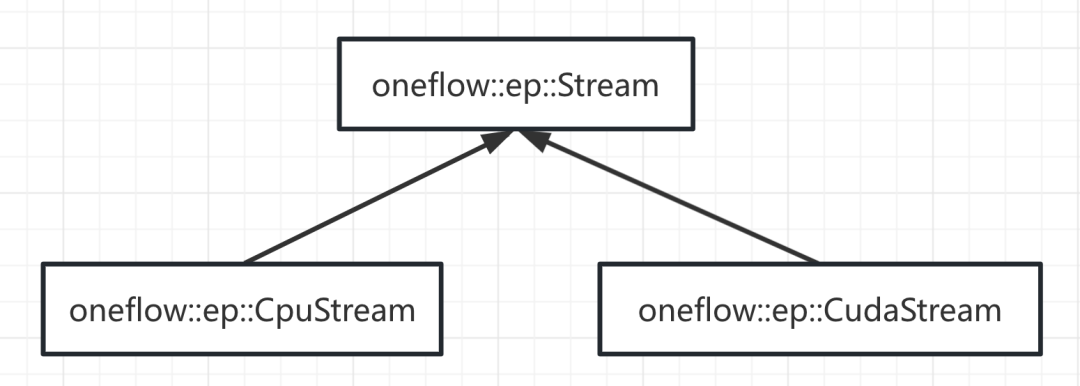
oneflow::vm::Stream
class Stream final : public intrusive::Base {public:...private:...// fieldsThreadCtx* thread_ctx_;Symbol<Device> device_;StreamType stream_type_;std::shared_ptr<StreamPolicy> stream_policy_;bool on_scheduler_thread_;std::unique_ptr<char, std::function<void(char*)>> small_pinned_mem_ptr_;...};
StreamPolicy
stream() 獲取oneflow::ep::Stream指針
mut_allocator() 獲取vm::Allocator指針(用於tensor內存管理)
device_type() 獲取device設備類型
class StreamPolicy {public:virtual ~StreamPolicy() = default;virtual ep::Stream* stream() = 0;virtual vm::Allocator* mut_allocator() = 0;virtual DeviceType device_type() const = 0;virtual void InitInstructionStatus(const Stream& stream,InstructionStatusBuffer* status_buffer) const = 0;virtual void DeleteInstructionStatus(const Stream& stream,InstructionStatusBuffer* status_buffer) const = 0;virtual bool QueryInstructionStatusLaunched(const Stream& stream, const InstructionStatusBuffer& status_buffer) const = 0;virtual bool QueryInstructionStatusDone(const Stream& stream,const InstructionStatusBuffer& status_buffer) const = 0;virtual bool OnSchedulerThread(StreamType stream_type) const;virtual bool SupportingTransportInstructions() const = 0;void RunIf(Instruction* instruction) const;protected:StreamPolicy() = default;private:virtual void Run(Instruction* instruction) const = 0;};
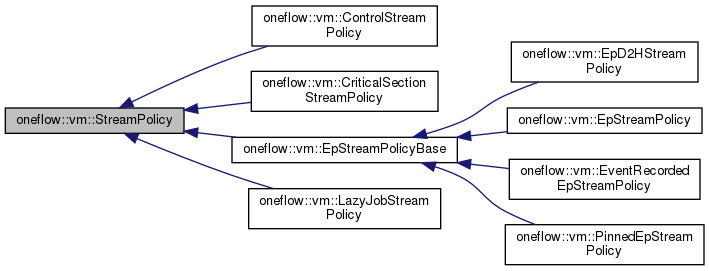
2
Eager Local模式下的Device和Stream推導
2.1 推導Device
-
1.如果inputs tensor非空,則根據第一個input tensor的device來設置default的device -
2.如果inputs tensor為空,則優先從OpExprInterpContext中獲取device,若OpExprInterpContext中未設置,則會通過 Device::New("cpu") ;默認給一個cpu device
2.2 推導Stream
-
JUST(user_op_expr.mut_local_tensor_infer_cache()->GetOrInfer(infer_args)) ); Symbol<Stream> stream = JUST(InferDeviceAndStream(... ));
InferDeviceAndStream 中, Stream 推導的邏輯是會根據user_op_expr是否定義了device_and_stream_infer_fn而有所區別
-
(少數情況)如果該op定義了推導函數,則調用此推導函數來推導Stream,例如 tensor.cuda() 方 法,inputs 在 CPU 上, output s 在 CUDA,二者的設備類型不同。 這時就不會默認推導而是利用 op 註冊的推導函數獲取 oneflow::Stream( 。 例如 CopyOp::InferDeviceA ndStream 。 -
(多數情況)否則會通過 stream = JUST(GetDefaultStreamByDevice(default_device)) ; 來推導。
Maybe<Symbol<StreamRawGetDefaultStreamByDevice(Symbol<Device> device) {return Stream::New(device, StreamType::kCompute);}
2.3 InstructionsBuilder::Call和vm::Stream推導
JUST(PhysicalRun([&](InstructionsBuilder* builder) -> Maybe<void> {return builder->Call(kernel, std::move(input_eager_blob_objects),std::move(output_eager_blob_objects), ctx, result->stream());}));
-
JUST(SoftSyncStream(output_eager_blob_objects, stream)) ; -
JUST(SoftSyncStream(input_eager_blob_objects, stream)) ; -
auto* vm_stream = JUST(Singleton<VirtualMachine>::Get()->GetVmStream(stream)) ;
2.3.1 構造 ThreadCtx 對象,啟動執行指令的線程
-
WorkerLoop 在收到通知 後,會調用 ThreadCtx::TryReceiveAndRun 處理指令。 -
在這個函數中,將 ThreadCtx 的指令挪到臨時列表 、通過 StreamPolicy 執行每個指令 。 -
ThreadCtx 的指令,是 VirtualMachineEngine 在 DispatchInstruction 時添加進去 的。
-
auto* vm_stream = JUST(Singleton<VirtualMachine>::Get()->GetVmStream(stream)) ;
-
VirtualMachine::GetVmStream() -
Maybe<vm::Stream*> VirtualMachine::CreateStream(Symbol<Stream> stream) -
Stream::__Init__(ThreadCtx* thread_ctx, Symbol<Device> device, StreamType stream_type...) -
stream_policy_ = CHECK_JUST(CreateStreamPolicy::Visit(stream_type, device)) ;
2.4 執行OpCall指令和ep::Stream推導
-
EpStreamPolicyBase::Run()
-
instruction->Compute() -
OpCallInstructionPolicy::Compute() -
OpCallInstructionUtil::Compute() -
OpCallInstructionUtil::OpKernelCompute() -
op_call_instruction_policy->mut_opkernel()->Compute()執行 kernel 的 Compute 方法
2.4.1 獲取/創建ep::Stream
static inline Maybe<void> Compute(OpCallInstructionPolicy* op_call_instruction_policy,Instruction* instruction) {Allocator* allocator = instruction->mut_stream()->mut_stream_policy()->mut_allocator();JUST(AllocateOutputBlobsMemory(op_call_instruction_policy, allocator, instruction));if (unlikely(op_call_instruction_policy->need_temp_storage())) {JUST(TryAllocateTempStorage(op_call_instruction_policy, allocator));}ep::Stream* stream = instruction->mut_stream()->mut_stream_policy()->stream();user_op::OpKernelState* state = nullptr;user_op::OpKernelCache* cache = nullptr;if (op_call_instruction_policy->user_opkernel()->has_state_or_cache()) {TryInitOpKernelStateAndCache(op_call_instruction_policy, stream, &state, &cache);}OpKernelCompute(op_call_instruction_policy, stream, state, cache);if (unlikely(op_call_instruction_policy->need_temp_storage())) {DeallocateTempStorage(op_call_instruction_policy, allocator);}return Maybe<void>::Ok();}
-
ep::Stream* stream() override { return GetOrCreateEpStream(); }
-
GetOrCreateEpStream() -
ep_stream_ = GetOrCreateEpDevice()->CreateStream() ;
private:ep::Stream* GetOrCreateEpStream() const {if (unlikely(ep_stream_ == nullptr)) {ep_stream_ = GetOrCreateEpDevice()->CreateStream();CHECK(ep_stream_ != nullptr);}return ep_stream_;}
2.4.2 獲取/創建ep::Device
ep::Device* GetOrCreateEpDevice() const {if (unlikely(ep_device_ == nullptr)) {ep_device_ = Singleton<ep::DeviceManagerRegistry>::Get()->GetDevice(device_->enum_type(),device_->device_id());CHECK(ep_device_);}return ep_device_.get();}
-
stream_policy_ = CHECK_JUST(CreateStreamPolicy::Visit(stream_type, device)) ;
-
std::shared_ptr<vm::StreamPolicy>(new vm::EpStreamPolicy(device)) ;
3
Eager Global模式下的Device和Stream推導
3.1 推導Device
3.1.1 placement 的 parallel_id
-
ParallelDesc::parallel_id2machine_id_ 是 placement 分佈的 machine。 -
ParallelDesc::parallel_id2device_id_ 是 placement 分佈的 device_id。 -
parallel_id 是上述 2 個數組的索引,一個 parallel_id 對應一個 machine_id:device_id 組合。這樣,根據parallel_id可以查到對應的 machine_id 和 device_id。 -
反過來,根據 machine_id:device_id 也可以從 machine_id2device_id2parallel_id_ 查到 parallel_id。
3.1.2 eager 模式下根據 parallel_id 忽略無關計算任務
如果當前進程與該 placement 無關,parallel_id 就是空,後續處理時就可以忽略一些計算:
-
EagerGlobalTensorImpl::New 中只需要用 functional::Empty 構造一個 shape 為 0 的空的 tensor。 -
GetBoxingOutput 計算時,如果parallel_id為空則表示當前rank進程無效,無需計算直接返回。 -
Interpret 可以不給 vm 提交指令、提前返回 。
3.2 推導Stream
3.2.1 unique_stream_id
4
Eager模式下的Stream同步——SoftSyncStream
-
tensor在oneflow內存中的實際承載者是 eager_blob_object -
last_used_stream 表示一個tensor(blob)上一次使用到的stream,可能是compute stream、h2d stream、d2h stream、集合通信ccl stream等 -
如果 last_used_stream 與當前計算執行的流 stream 相同,則可以忽略,因為相同stream間天然順序執行所以無需同步,否則就需要進行後續的同步處理
Maybe<void> InstructionsBuilder::SoftSyncStream(const vm::EagerBlobObjectList& eager_blob_objects,Symbol<Stream> stream) {JUST(ForEachEagerBlobObjectsNeedingSoftSync(eager_blob_objects, stream,[&](Symbol<Stream> last_used_stream, auto&& dep_objects) -> Maybe<void> {return SoftSyncStreamBetween(std::move(dep_objects), last_used_stream, stream);}));for (const auto& eager_blob_object : eager_blob_objects) {eager_blob_object->set_last_used_stream(stream);}return Maybe<void>::Ok();}
-
const auto& opt_last_used_stream = eager_blob_object->last_used_stream() ; -
if (unlikely(!opt_last_used_stream.has_value())) { continue; }
if (last_used_stream != stream) {small_vector<intrusive::shared_ptr<LocalDepObject>, kOpArgsReservedSize> dep_objects{intrusive::shared_ptr<LocalDepObject>(JUST(eager_blob_object->compute_local_dep_object()))};JUST(DoEach(last_used_stream, std::move(dep_objects)));}
[&](Symbol<Stream> last_used_stream, auto&& dep_objects) -> Maybe<void> {return SoftSyncStreamBetween(std::move(dep_objects), last_used_stream, stream);}));
-
dep_objects 存儲了tensor間的依賴關係 -
last_used_stream 則是該tensor上一次使用的stream -
stream 該tensor當前使用的stream
Maybe<void> InstructionsBuilder::SoftSyncStreamBetween(small_vector<intrusive::shared_ptr<LocalDepObject>, kOpArgsReservedSize>&& dependences,Symbol<Stream> from_stream, Symbol<Stream> to_stream) {CHECK(from_stream != to_stream) << "synchronization is unnecessary";if (SupportingStreamWait(from_stream, to_stream)) {JUST(StreamWait(std::move(dependences), from_stream, to_stream));} else {JUST(RecordEvent(std::move(dependences), from_stream));}return Maybe<void>::Ok();}
-
先額外做了一次check,檢測如果待同步的兩個stream相同,則check會報錯並提示"synchronization is unnecessary" -
通過SupportingStreamWait判斷from 和 to stream間是否支持stream wait,是則調用StreamWait方法;否則,直接調用RecordEvent 方法
-
SupportingStreamWait 的主要邏輯是,通過stream的device、以及StreamType的Visit方法來判斷。簡單來説,如果from 和 to stream之間是不同的device(譬如cpu stream <-> cuda stream之間的同步),或者from stream的device為cpu,則SupportingStreamWait一定是false;如果是相同的,則繼續通過其他判斷條件進行判斷。
SupportingStreamWait為True
-
cudaEventRecord -
cudaStreamWaitEvent
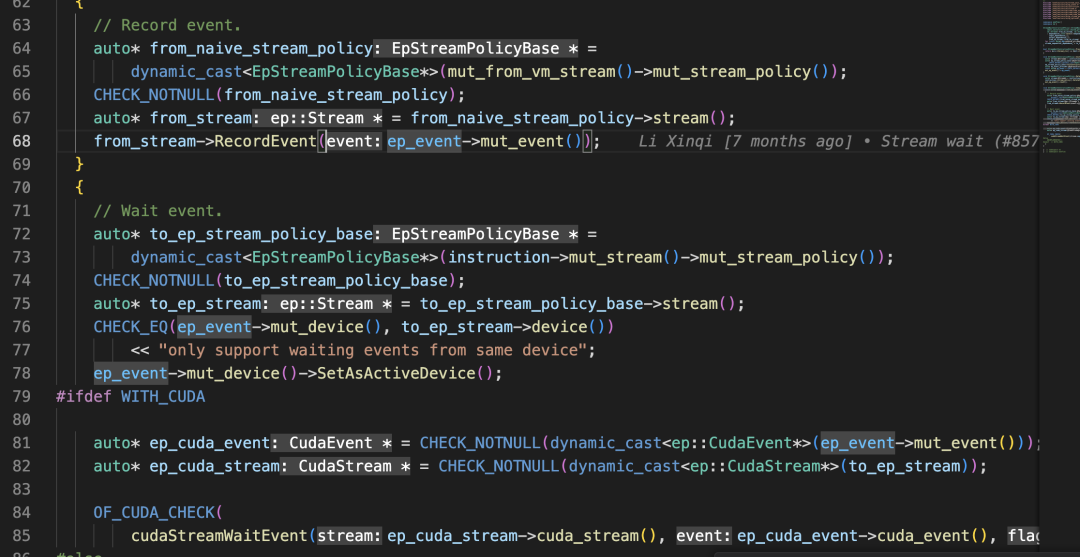
-
對於from_stream來説,插入一個 cudaEventRecord ,用於標誌from stream是否完成該stream上的event事件; -
對於to_stream來説,插入一個 cudaStreamWaitEvent 等待from stream上的事件完成後,再繼續執行to_stream。
SupportingStreamWait為False
這裏有個細節,由於cuda event的創建和銷燬都會引發cuda kernel的launch由異步轉同步,所以基於對象池的cuda event可以避免這個開銷。
5
CPU 下的並行計算
參考資料
1.http://github.com/Oneflow-Inc/oneflow/tree/845595e2c0abc3d384ff047e188295afdc41faaa
試用OneFlow: github.com/Oneflow-Inc/oneflow/

本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- OneFlow源碼解析:Eager模式下的設備管理與併發執行
- OpenAI創始人:GPT-4的研究起源和構建心法
- GPT-4創造者:第二次改變AI浪潮的方向
- NCCL源碼解析①:初始化及ncclUniqueId的產生
- GPT-4問世;LLM訓練指南;純瀏覽器跑Stable Diffusion
- 適配PyTorch FX,OneFlow讓量化感知訓練更簡單
- 超越ChatGPT:大模型的智能極限
- ChatGPT作者John Schulman:我們成功的祕密武器
- YOLOv5全面解析教程⑤:計算mAP用到的Numpy函數詳解
- GPT-3/ChatGPT復現的經驗教訓
- ChatGPT背後:從0到1,OpenAI的創立之路
- 一塊GPU搞定ChatGPT;ML系統入坑指南;理解GPU底層架構
- YOLOv5全面解析教程④:目標檢測模型精確度評估
- ChatGPT數據集之謎
- OneFlow源碼解析:Eager模式下的SBP Signature推導
- YOLOv5全面解析教程③:更快更好的邊界框迴歸損失
- ChatGPT背後的經濟賬
- Sam Altman的成功學|升維指南
- 開源機器學習軟件對AI的發展意味着什麼?
- “一鍵”模型遷移,性能翻倍,多語言AltDiffusion推理速度超快