GPT-3/ChatGPT復現的經驗教訓

作者:楊靖鋒,現任亞馬遜科學家,本科畢業於北大,碩士畢業於佐治亞理工學院,師從 Stanford 楊笛一教授。
譯文由楊昊桐翻譯,王驍修訂。感謝靳弘業對第一版稿件的建議,感謝陳三星,符堯的討論和建議。(本文經授權後由OneFlow發佈。原文:http://jingfengyang.github.io/gpt)
為什麼所有公開的對 GPT-3 的復現都失敗了?我們應該在哪些任務上使用 GPT-3.5 或 ChatGPT?
對於那些想要復現一個屬於自己的 GPT-3 或 ChatGPT 的人而言,第一個問題是關鍵的。第二個問題則對那些想要使用它們的人是重要的(下文提到 GPT-3,主要是指 GPT-3.5 或 InstructGPT 的最新版本,除了一些指向 GPT-3 原文的情況)。
這篇博客 包括我在仔細重新檢查了一系列文章的細節之後給出的總結,以及對上面兩個問題我個人的思考。這些文章包括且不限於:GPT-3, PaLM, BLOOM, OPT, FLAN-T5/PaLM, HELM 等。均為個人意見,僅供參考。如果您有更可靠的參考資料或者更實際的經驗,歡迎指正。
1
為什麼所有公開的對GPT-3的復現都失敗了?
這裏,我稱之為“失敗”,是指訓練得出模型有接近 GPT-3 或者更大的參數量,但仍無法與 GPT-3 原始文獻中報告的性能所匹配。在這一標準下,GPT-3 和 PaLM 是“成功”的,但這兩個模型都不是公開的。而所有的公開模型(例如:OPT-175B 和 BLOOM-176B)都在一定程度上“失敗”了。但是我們仍然可以從這些“失敗”中吸取一些教訓。
我們需要注意的是,假如能夠多次嘗試各種不同的訓練設置,開源社區可能最終可以復現 GPT-3。但截至目前,訓練另一個版本的 OPT-175B 的開銷仍然太過高昂——對於如此大規模的模型,一次訓練就將需要在約 1000 個 80G A100 GPU 上花費至少 2 個月的時間(數據來自於 OPT 的原始文獻)。
儘管一些文章(例如 OPT-175B 和 GLM-130B)聲稱,它們在一些任務上能夠匹配甚至超過原始的 GPT-3 的表現,在更多 GPT-3 已經測試過的任務上,這種聲明仍然是存疑的。同時,根據大多數使用者在更多樣的任務上的經驗,以及 HELM 的評估來看,最近的 OpenAI GPT-3 的 API 表現也仍然比這些開源模型更好。
儘管它背後的模型可能使用了指令微調(instruction tuning, 正如 InstructGPT 那樣),類似的使用了指令微調的 OPT 版本(OPT-IML)和 BLOOM 版本(BLOOMZ)也仍然遠比 InstructGPT 和 FLAN-PaLM(PaLM 的指令微調版本)要差得多。
根據文章的細節,相比 GPT-3 和 PaLM 的成功,有多個可能的原因導致了OPT-175B 和 BLOOM-176B 的失敗。我將其分為兩個部分:預訓練數據和訓練策略。
預訓練數據
讓我們首先觀察 GPT-3 是如何準備和使用預訓練數據的。GPT-3 在共計 300B 的 token 上進行訓練,其中 60% 來自經過篩選的 Common Crawl,其它則來自webtext2(用於訓練 GPT-2 的語料庫)、Books1、Books2 和維基百科。
更新版本的 GPT-3 還用了代碼數據集進行訓練(例如 Github Code)。每個部分的佔比並不與原始數據集的大小成比例,相反,具有更高質量的數據集被更加頻繁地採樣。導致 OPT-175B 和 BLOOM-176B 失敗的,可能是以下三個難點,它們使得開源社區難以收集到類似的數據:
1. 第一點是一個具有良好性能的用於篩選低質量數據的分類器。它被用於構建 GPT-3 和 PaLM 的預訓練數據集,但在 OPT 和 BLOOM 的訓練中卻沒有被採用。一些文章已經展示,一個用更少但質量更高的數據集訓練的預訓練模型,可以在性能上超過另一個用更多的混合質量數據集訓練的模型。當然,數據的多樣性仍然是十分重要的,正如我們將在第三點中討論的。因此,人們應當非常小心地處理在數據多樣性和質量之間的權衡。
2. 第二點是預訓練數據集的去重。去重有助於避免預訓練模型多次面對相同的數據後記住它們或者在其上過擬合,因此有助於提高模型的泛化能力。GPT-3 和 PaLM 採用了文檔級別的去重,這同樣被 OPT 所採用。但 OPT 預訓練的去重 Pile 語料庫中仍有許多重複存在,這也可能導致它較差的性能(注:在一些最近的文獻中顯示去重對於預訓練語言模型的重要性可能沒有想象中大)。
3. 第三點是預訓練數據集的多樣性,包括領域多樣性、格式多樣性(例如:文本、代碼和表格)和語言多樣性。OPT-175B 所使用的 Pile 語料庫聲稱有着更好的多樣性,但 BLOOM 採用的 ROOTS 語料庫則有太多的已經存在的學術數據集,缺乏 Common Crawl 數據所包含的多樣性。這可能導致 BLOOM 性能更差。作為對比,GPT3 來自 Common Crawl 語料的佔比則要高得多,而它們來自廣泛領域,是多樣的,這也可能是 GPT-3 能夠作為首個通用聊天機器人 ChatGPT 的基礎模型的原因之一。
請注意:雖然一般來説,多樣性的數據對於訓練一個通用的 LLM(Large Language Model,大規模語言模型)是重要的,但特定的預訓練數據分佈,則會對 LLM 在特定的下游任務上的性能產生巨大的影響。例如,BLOOM 和 PaLM 在多語言數據上有更高的佔比,這導致它們在一些多語言任務和機器翻譯任務上的性能更高。
OPT 使用了很多對話數據(例如 reddit),這可能是它在對話中表現好的原因之一。PaLM 有很大的佔比在社交媒體對話中,這可能是它在多種問答任務和數據集上有着卓越表現的原因。同樣的,PaLM 和更新版本的 GPT-3 有很大比例的代碼數據集,這增強了它們在代碼任務上的能力,以及可能增強了它們 CoT (Chain-of-Thought,思維鏈) 的能力。
一個有趣的現象是,BLOOM 在代碼和 CoT 上的表現仍然是較差的,儘管它在預訓練過程中使用了代碼數據。這可能暗示着單獨代碼數據本身並不能保證模型的代碼和 CoT 能力。
總之,一些文章表明瞭上面三點的重要性,即:通過數據去重避免記憶和過擬合,通過數據篩選以得到高質量數據,保證數據多樣性以確保 LLM 的泛化性。但不幸的是,對於 PaLM 和 GPT-3 預處理這些數據的細節,或者這些預訓練數據本身,仍然沒有公佈,這使得公共社區很難去復現它們。
訓練策略
此處訓練策略包括訓練框架、訓練持續時間、模型架構/訓練設置、訓練過程中的修改。在訓練非常大的模型時,它們被用於獲得更好的穩定性和收斂性。
一般來説,由於未知的原因,預訓練過程中廣泛觀察到損失尖峯(loss spike)和無法收斂的情況。因此,眾多的對訓練設置和模型架構的修改被提出,用以避免這些問題。但是其中一些修改在 OPT 和 BLOOM 之中還不是最優解,這可能導致它們的性能較差。GPT-3 並沒有明確提到他們是如何解決這個問題的。
1. 訓練框架。一個參數量大於 175B 的模型往往需要 ZeRO 式的數據並行(分佈式的優化器)和模型並行(包括張量並行(tensor parallel)、流水線並行(pipeline parallel),有時還包括序列並行(sequence parallel))。OPT 採用了 ZeRO 的 FSDP 實現,以及模型並行的 Megatron-LM 實現。BLOOM 採用了 ZeRO 的 Deepspeed 實現和模型並行的 Megatron-LM 實現。
PaLM 採用了 Pathways,這是一個基於 TPU 的模型並行和數據並行系統。GPT-3 的訓練系統的細節仍然未知,但它們至少在一定程度上使用了模型並行(一些人稱它使用了 Ray)。不同的訓練系統和硬件可能導致不同的訓練時的現象。顯然,一些在 PaLM 的文章中呈現的、用於 TPU 訓練的設置,可能並不適用於其它所有模型使用的 GPU 訓練。
硬件和訓練框架的一個重要的影響是,人們是否可以使用 bfloat16 去存儲模型權重和中間層激活值等。這已經被證明是穩定訓練的一個重要因素,因為 bfloat16 可以表示更大範圍的浮點數,能夠處理在損失尖峯時出現的大數值。在 TPU 上 bfloat16 是默認設置,這可能是 PaLM 能夠成功的一個祕密。但是在 GPU 上,以前人們主要使用 float16,這是 V100 中混合精度訓練的唯一選擇。
OPT 使用了 float16,這可能是其不穩定的因素之一。BLOOM 發現了這樣的問題並最終在 A100 GPU 上使用了 bfloat16,但它沒有意識到這種設置的重要性,因此在第一個詞向量層後引入額外的層歸一化(layer normalization),用於解決他們使用 float16 的初步實驗中的不穩定性。然而,這種層歸一化已被證明會導致更糟糕的零樣本泛化(zero-shot generalization),這可能是 BLOOM 失敗的一個因素。
2. 訓練過程中的修改。OPT 做了很多中途調整並從最近的 checkpoint 重啟訓練,包括改變截斷梯度範數 (clip gradient norm) 和學習率,切換到簡單的 SGD 優化器然後回到 Adam,重置動態損失標量 (dynamic loss scalar),切換到更新版本的 Megatron 等等。
這種中途調整可能是 OPT 失敗的原因之一。相比之下,PaLM 幾乎沒有做任何中途調整。它只是當損失尖峯出現時,從尖峯開始前大約 100 步的 checkpoint 重新開始訓練,並跳過了大約 200-500 個 batch 的數據。僅僅依靠這種簡單的重啟,PaLM 就取得神奇的成功。這是由於它在預訓練數據構建期間就已經完成採樣,因此模型具有在 Bit 意義上的確定性,以及它對模型架構和訓練設置進行了許多修改以獲得更好的穩定性。PaLM 中的此類修改在下一點中展示。
3. 模型架構/訓練設置 :為了使訓練更穩定,PaLM 對模型架構和訓練設置進行了多項調整,包括使用 Adafactor 的修改版本作為優化器,縮放在 softmax 之前的輸出 logit,使用輔助損失來鼓勵 softmax 歸一化器接近 0,對詞向量和其他層權重使用不同的初始化,在前饋層和層歸一化中不使用偏差項,並且在預訓練期間不使用 dropout。
請注意,GLM-130B 中還有更多有價值的內容關於如何穩定地訓練非常大的模型,例如:使用基於 DeepNorm 的後置層歸一化而不是前置層歸一化,以及詞向量層梯度收縮。以上大多數模型修改沒有被 OPT 和 BLOOM 採用,這可能會導致它們的不穩定和失敗。
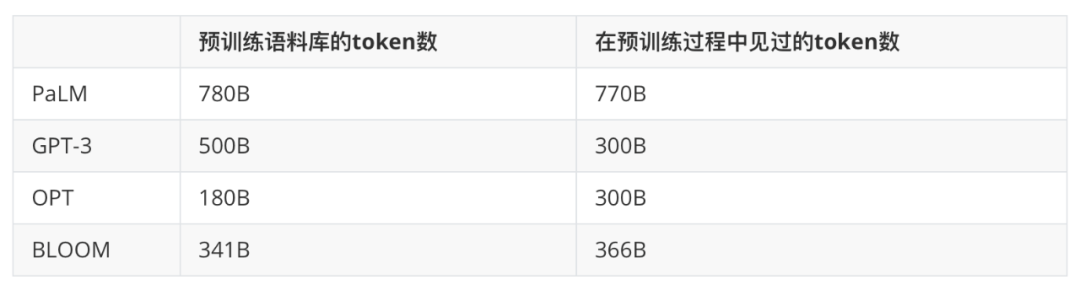
4. 訓練過程 :如下表所示,原始的 GPT-3 預訓練過程見過的 token 數與 OPT 和 BLOOM 接近,而 PaLM 則遠遠超過了它們。同樣,PaLM 和 GPT-3 預訓練語料庫都大於 BLOOM 和 OPT。因此,在更多的 token 上、用更大規模的高質量語料庫進行預訓練可能是 GPT-3 和 PaLM 成功的一個重要因素。
除了上面列出的四點,還有一些其它因素,它們可能對於更穩定的訓練並不重要,但仍然可能影響最終的性能。
第一點,PaLM 和 GPT-3 都使用了在訓練過程中從小到大逐漸增加的 batch size,這已經被證明對於訓練一個更好的 LLM 是有效的,然而 OPT 和 BLOOM 都使用了恆定的 batch size。
第二點,OPT 使用了 ReLU 激活函數,而 PaLM 使用 SwiGLU 激活函數,GPT-3 和 BLOOM 使用 GeLU,它通常使得訓練的 LLM 的性能更好。
第三點,為了更好的建模更長的序列,PaLM 使用 RoPE 詞向量,BLOOM 使用 ALiBi 詞向量,而原始的 GPT-3 和 OPT 使用學習得到的詞向量,這可能影響在長序列上的性能。
2
我們應該在哪些任務上使用GPT-3.5或ChatGPT?
我嘗試解釋我們應該在哪些任務和應用上使用 GPT-3,而哪些則不該使用。為了展示 GPT-3 是否適合某個特定任務,我主要比較了帶有提示(prompting)的 GPT-3 和經過微調的更小的模型,這些小模型有時還加入了其他特殊的設計。鑑於最近出現的更小的而且可以微調的 FLAN-T5 模型的良好性能,這一問題更加重要。
在理想情形下,如果微調 GPT-3 的負擔是能夠承擔的,它可能帶來更進一步的提升。然而,在一些任務上通過微調 PaLM-540B 帶來的提升是如此有限,讓人們懷疑在一些任務中微調 GPT-3 是否是值得的。從科學的角度來看,更公平的比較應在微調 GPT-3 和提示 GPT-3 之間進行。然而,要使用 GPT-3,人們可能更關心將提示 GPT-3 和微調一個更小的模型去進行對比。
注意到,我主要關心的是將完成任務的精確度作為度量,但仍然存在很多其它重要的維度,例如:有害性(toxicity)、公平性等,它們也應該在決定是否使用 GPT-3 時被納入考慮,正如 HELM 的文章中所呈現的。下圖展示了一個粗略的決策流程,希望它能夠作為一個有用的實踐指南,無論對於已有任務還是一個全新的任務。
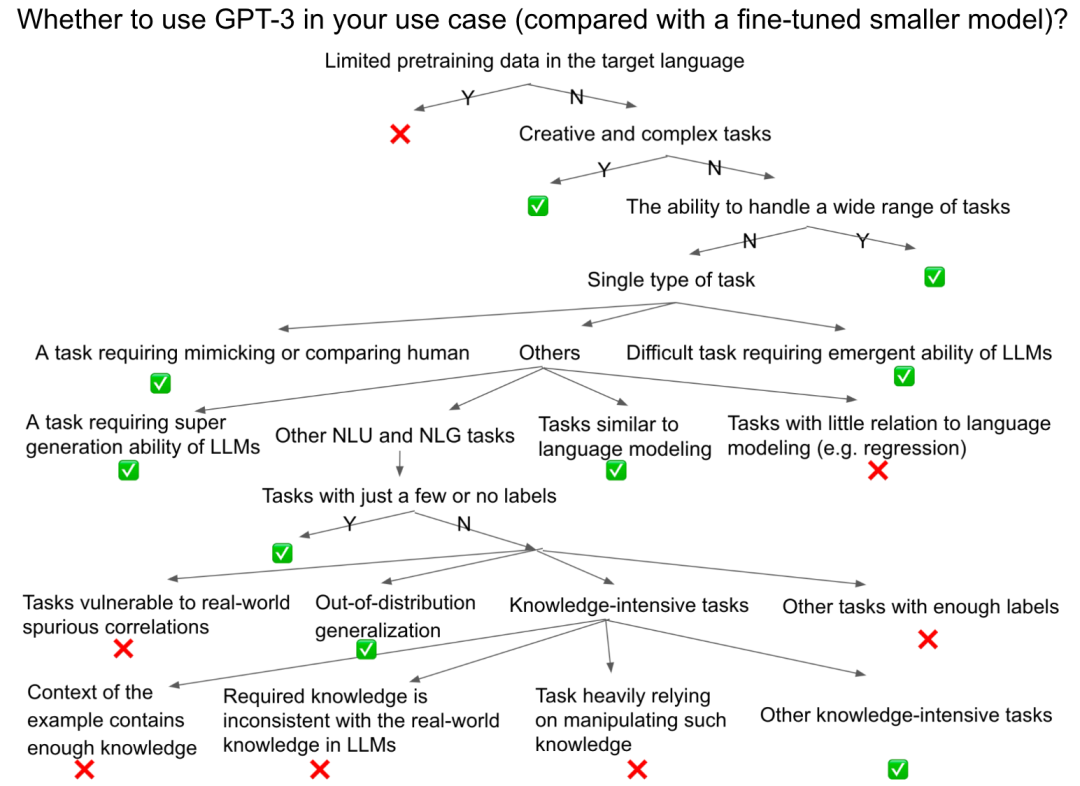
注 1:由於在對話場景下的良好對齊,ChatGPT 作為一個聊天機器人表現優異。但我們通常使用 GPT-3、InstructGPT (GPT-3.5)、以及 Codex 這些 ChatGPT 背後的模型作為在更多任務和使用場景下的通用模型。
注 2:這一節中的結論是基於一些對模型當前版本的發現得到的,這可能不適用於未來的更強的模型。因為,使用更多與目標數據集接近的預訓練數據、學術數據集指令調整(例如提示一個 FLAN-PaLM 可能會帶來更強的性能,它仍未公開)或者通過 RLHF 以使得模型對目標任務的更好對齊,這些都可能使得模型在目標任務中表現更好,即使有時這會犧牲在其他場景下的能力(例如,InstructGPT的“對齊税/Alignment tax”)。
在這種情況下,很難判斷 GPT 是進行泛化和跨任務泛化,還是僅僅在預訓練時就已經記住了一些測試樣例,或者説見過那些在預訓練時所謂“沒有見過”的任務。然而,記憶在實踐中是否真的是一個嚴重的問題,這仍然值得懷疑。因為用户與研究人員不同,如果他們發現 GPT 已經可以在他們的測試數據上表現良好,他們可能不會關心 GPT 在預訓練期間是否看到了相同或相似的數據。
不論如何,為了最大化這一節在當前的實用價值,我盡最大努力,試圖比較微調公共的更小型的模型(T5、FALN-T5、一些特殊設計的微調 SOTA 模型等)和最近的 GPT-3 (GPT-3.5、InstructGPT)、PaLM(或 FLAN-PaLM)的最佳性能,如果這些模型的測評數據夠獲得的話。
一般來説,有以下這些情況更適合使用提示 GPT-3。令人驚訝的是,如果我們回看 GPT-3 論文的介紹部分,在那裏很多初始設計時的目標涵蓋了這些任務。這意味着那些當初宏偉的目標已經被部分實現了。
1. 創造性和複雜的任務:包括代碼(代碼補全、自然語言指令生成代碼、代碼翻譯、bug 修復)、文本摘要、翻譯、創造性寫作(例如寫故事、文章、郵件、報告,以及寫作的改進等)。正如原始的 GPT-3 文獻中所示,GPT-3 被設計用於那些困難和“不可能標註”的任務。在一定程度上,對於這些任務,先前那種經過微調的模型不可能應用於真實世界的應用;而 GPT-3 使它們成為可能。舉個例子,最近的文章顯示,過去的人類標註的文本摘要已經被 LLM 生成的摘要所超越。
在某些需要從低、中資源語言翻譯到英語的機器翻譯任務中,通過提示 PaLM-540B,它甚至能夠超越微調模型。
在 BLOOM-176B 中也觀察到了類似的趨勢。這是因為英語數據通常在預訓練語料庫中佔了很大比例,因此 LLM 擅長生成英語語句。注意到,為了在代碼任務中獲得良好性能,儘管 Codex 和 PaLM 已經在整體上具有比之前模型更好的性能,我們仍需允許 LLM 多次(k 次)採樣,以通過測試樣例(使用 pass@k 作為度量)。
2. 只有少數標註或者沒有標註數據的任務。正如原始的 GPT-3 文獻所説,GPT-3 是為了那些“昂貴標註”的任務設計的。在這種情況下,用極少量標註數據微調一個更小的模型通常不可能達到 GPT-3 在零樣本(zero-shot)、單樣本(one-shot)或少樣本(few-shot)的情況下的表現。
3. 分佈外(Out-of-distribution, OOD)泛化。給定一些訓練數據,傳統的微調可能會過擬合訓練集並且有較差的分佈外泛化能力;而少樣本的上下文學習(in-context learning)能夠有更好的分佈外泛化性。例如,帶有提示的 PaLM 能夠在對抗自然語言推斷任務(Adversarial Natural Language Inference,ANLI)上超越經過微調的 SOTA 模型,而它在正常的語言推斷任務上可能仍然劣於微調的 SOTA。
另一個例子是提示 LLM 比微調模型顯示出更好的組合泛化能力。更好的分佈外泛化性可能是因為在上下文學習期間不需要更新參數,避免了過擬合;或者因為那些過去的分佈外樣例對於 LLM 而言是分佈內的。這種使用場景被闡釋為 GPT-3 的初始設計目標之一:“微調模型在特定任務的數據集上的性能可以達到所謂的人類水平,實際上可能誇大了在真實世界中該任務上的性能,這是因為模型只是學到了訓練集中存在的虛假的相關性,以及模型過度擬合了這個訓練集狹窄的分佈。”
4. 需要處理多種任務的能力,而非關注特定任務上的卓越表現。聊天機器人就是這樣一種場景,其中,用户期待它能夠正確地響應各種各樣的任務。這可能就是為什麼 ChatGPT 是 GPT-3 最成功的使用場景之一。
5. 那些檢索不可行的知識密集型任務。存儲在 LLM 中的知識可以顯著地提高在知識密集型任務的性能,例如閉卷問答和 MMLU(一個基準數據集,包括來自於 STEM、人文、社科等 57 個學科的選擇題,它用於測試 LLM 的世界知識和問題解答的能力)。然而,如果預先檢索的步驟可以被加入來做檢索增強的生成,一個微調的更小的模型(例如 Atlas 模型)甚至可以有更好的性能(在閉卷的 NaturalQuestions 和 TrivialQA 數據集上,Atlas 比 PaLM 和最新的 InstructGPT 都要更好)。
檢索或者傳統的搜索同樣是將 GPT-3 或 ChatGPT 整合到搜索引擎中的一個必要的步驟,這可以提升生成的準確性,並且提供更多的參考鏈接以增強説服力。但我們應該承認,在某些情況下,檢索是不允許或者不容易的,比如參加 USMLE (美國醫學執照考試),谷歌已經證明基於 FLAN-PaLM 的模型可以在其中做得很好。
同樣的,在 MMLU 基準集中,PaLM-540B 有着比其他微調模型更好的性能,甚至後者結合了檢索,儘管最新版本的 InstructGPT 還差於這些帶有檢索的微調 SOTA。也請注意,指令調整一個較小的模型也可以實現與更大規模的 LLM 模型接近的效果,這已經在 FLAN-T5 中展現。
6. 一些困難的任務,其中需要LLM 的湧現能力,比如帶有 CoT 的推理和 BIG-Bench 中的複雜任務(包括邏輯推理、翻譯、問答、數學任務等)。舉個例子,PaLM 已經展示,在 7 個包括數學和常識推理的多步推理任務上,8-樣例的 CoT 比微調 SOTA 在其中 4 個任務上更好,在其它 3 個任務上則基本持平。
這樣的成功表現要同時歸因於更大規模的模型和 CoT。PaLM 還顯示了在 BIG-Bench 任務上從 8B 到 62B 再到 540B 模型的不連續的表現提升,這超出了規模定律(scaling law),被稱為 LLMs 的湧現能力。另外,帶有 5 個 Prompt 的 PaLM-540B 在 Big-Bench 的 58 項常見任務中的 44 項上優於之前的(少樣本)SOTA。PaLM-540B 在 Big-Bench 的總體表現也優於人類的平均表現。
7. 一些需要模仿人類的場景,或者是其目標是製作性能達到人類水平的通用人工智能。同樣的,ChatGPT 是其中的一個案例,ChatGPT 使自己更像是一個人,從而取得了現象級的成功。這也被闡釋為 GPT-3 的初始設計目標之一:“人類不需要大規模監督數據集來學習大多數語言任務。最多隻需要幾個例子,人類就可以將各種任務和技巧無縫地混合在一起或者在它們之間切換。因此傳統的微調模型導致了與人類的不公平比較,儘管他們聲稱在許多基準數據集中有着人類水平的性能。”
8. 在一些傳統的接近於語言建模的 NLP 任務上,少樣本 PaLM-540B 能夠大致匹配或者甚至超過微調的 SOTA,例如:一段話最後一句和最後一個單詞的完型填空,以及回指(anaphora)解析。需要指出,在這種情況下,零樣本的 LLM 已經足夠了,單樣本或少樣本的示例則通常幫助不大。
另一些任務則並不需要提示(prompt)一個 GPT-3 這樣規模的模型:
1. 調用 OpenAI GPT-3 的 API 超出了預算(例如對於沒有太多錢的創業公司)。
2. 調用 OpenAI GPT-3 的 API 存在安全問題(例如數據泄露給 OpenAI,或者可能生成的有害內容)。
3. 沒有足夠的工程或者硬件資源去部署一個相似大小的模型及消除推斷的延遲問題。例如,在沒有最先進的 80G 的 A100 或者工程資源來優化推斷速度的情況下,簡單地使用 Alpa 在 16 個 40G 的 A100 上部署 OPT-175B 需要 10 秒才能完成單個樣例的推斷,這對於大多數現實世界的在線應用程序來説是無法接受的延遲。
4. 如果想用 GPT-3 替代一個性能良好的、高準確度的微調模型,或者想要在一些特定的單一任務和使用場景下去部署一個 NLU(Natural Language Understanding,自然語言理解)或 NLG(Natural Language Generating,自然語言生成)模型,請三思這是否值得。
-
對於一些傳統的 NLU 任務,比如分類任務,我建議首先嚐試微調 FLAN-T5-11B 模型,而不是提示 GPT-3。例如,在 SuperGLUE,一個困難的 NLU 基準數據集(包括閲讀理解、文本藴含、詞義消歧、共指消解和因果推理等任務)上,所有的 PaLM-540B 的少樣本提示性能都劣於微調的 T5-11B,並在其中大多數任務上有着顯著的差距。如果使用原始 GPT3,其提示結果與微調 SOTA 的結果之間的差距更大。有趣的是,即使是經過微調的 PaLM 也僅比經過微調的 T5-11B 有着有限的改進,而經過微調的 PaLM 甚至比經過微調的編-解碼器模型 32B MoE 模型還要差。這表明使用更合適的架構(例如編-解碼器模型)微調較小的模型仍然是比使用非常大的僅解碼器模型更好的解決方案,無論是微調還是提示來使用這些大模型。根據最近的一篇論文,即使對於最傳統的 NLU 分類任務——情感分析,ChatGPT 仍然比經過微調的較小模型差。
-
一些不以現實世界數據為基礎的困難任務。例如,BigBench 中仍然有許多對 LLM 來説困難的任務。具體地説,在 35% 的 BigBench 任務上,人類的平均表現仍然高於 PaLM-540B,並且在某些任務中,擴大模型規模甚至無濟於事,例如導航和數學歸納。在數學歸納中,當提示中的假設不正確時(例如“2 是奇數”),PaLM 會犯很多錯誤。在逆規模定律競賽 (Inverse Scaling Law Challenge) 中,也觀察到了類似的趨勢,例如重新定義數學符號(例如提示可能“將 π 重新定義為 462”)後再使用這個符號。在這種情況下,LLM 中的現實世界先驗知識太強而無法被提示覆蓋,而微調較小的模型可能可以更好地學習這些反事實知識。
-
在很多多語言任務和機器翻譯任務中,使用少樣本的提示 GPT 仍然要比微調的更小的模型更差。這很可能是由於除英語之外的其它語言在預訓練語料庫中佔比很少。
-
當從英語翻譯為其他語言,以及翻譯高資源語言到英語時,PaLM 和 ChatGPT 仍然比在機器翻譯任務上微調的更小的模型要差。
-
對於多語言問答任務來説,在少樣本的 PaLM-540B 和微調的更小模型之間還存在較大差距。
-
對於多語言文本生成(包括文本摘要和數據到文本生成),在少樣本的 PaLM-540B 和微調的更小模型之間還存在較大差距。在大部分任務上即使微調的 PaLM-540B 也僅僅比微調的 T5-11B 有有限的提升,並仍然劣於微調的 SOTA。
-
對於常識推理任務,在最好的少樣本提示 LLM 和微調的 SOTA 之間仍然存在着較大的差距,例如:OpenbookQA,ARC(包括 Easy 和 Challenge 版本)以及 CommonsenseQA(甚至使用了 CoT 提示)。
-
對於機器閲讀理解任務,在最好的少樣本提示 LLM 和微調的 SOTA 之間仍然存在着較大的差距。在大多數數據集上,這個差距可能非常巨大。這可能是因為所有回答問題所需的知識都已經包含在給出的文本中,並不需要 LLM 中的額外知識。
總結一下,上面的這些任務可以被歸為以下類別之一:
1. 一些 NLU 任務,既不需要額外的知識也不需要 LLM 的生成能力。這意味着測試數據大多數都和手頭的訓練數據在同一個分佈之中。在這些任務上,過去微調的較小模型已經表現很好了。
2. 一些不需要額外的來自 LLM 中知識的任務,因為每一個例子已經在上下文或者提示中包含了足夠的知識,例如機器閲讀理解。
3. 一些需要額外知識,但不太可能從 LLM 中獲得這樣的知識,或者 LLM 不太可能見過類似分佈的任務,例如一些低資源語言中的任務,LLM 在這些語言中只有有限的預訓練樣本。
4. 一些任務,需要與 LLM 中包含的知識所不一致的知識,或者並非基於現實世界的語言數據的知識。因為 LLM 是在現實世界的語言數據上訓練的,它難以在新的任務中利用反事實知識覆蓋原有知識。除了在逆規模定律挑戰中的“重新定義數學符號”問題之外,還有另一個任務,即複述有細微改動的名言,其中 LLM 被要求複述一個在 prompt 中出現的被修改的名言。在這種情況下,LLM 傾向於重複出名言的原始版本,而非修改過後的版本。
5. 一些任務需要來自 LM 的知識,但也嚴重依賴於操縱這些知識,而 LLM 的“預測下一個 token”的目標無法輕易實現這種操縱。一個例子是一些常識推理任務。CoT 和 least-to-most 提示可以幫助 LLM 推理的原因可能是他們可以更好地調出那些連續的預訓練文本,這些連續文本恰好模仿了規劃和分解/組合知識的過程。
因此,CoT 和 least-to-most 提示在一些數學推理、代碼和其他簡單的自然語言推理任務中表現良好,但在許多常識推理(例如在逆規模定律競賽中展示的演繹推理任務)和自定義符號推理任務中仍然表現不佳。這些任務通常不被自然語言數據中的大多數真實世界的連續序列所包含,而需要操縱分散在各處的知識來完成。
6. 一些容易受到上下文學習樣例或者真實世界數據中存在的虛假相關性影響的任務。一個例子是來自於逆規模定律競賽中的涉及否定詞的問答。如果一個 LLM 被提問:“如果一隻貓的體温低於平均水平,它就不在……”,它傾向於回答“危險之中”而非“安全範圍“。這是因為 LLM 受到常見的“低於平均體温”和“危險”之間的關係所支配,而在否定的情況下,這是一種虛假的相關性。
7. 一些目標與處理語言數據顯著不同的任務,例如:迴歸問題,其中微調模型很難被 LLM 取代。至於多模態任務,它們不能被 LLM 解決,但是可能能從大規模的預訓練多模態模型中受益。
8. 一些任務不需要LLM的湧現能力。為了準確地對更多此類任務進行鑑別,我們需要更好地瞭解 LLM 訓練期間,湧現能力是從何產生的。
注意到,在現實世界的使用場景中,即使由於無法滿足延遲要求因而無法在線地使用 LLM,仍然可以使用 LLM 離線生成或標註數據。此類自動標註的標籤可以在線查找並提供給用户,或用於微調較小的模型。使用此類數據微調較小的模型可以減少訓練模型所需的人工註釋數據,並將 LLM 的一些新興能力(例如 CoT)注入較小的模型。
總之,當有足夠的標記數據時,考慮到開源 FLAN-T5 在許多任務中的驚人性能,我推薦那些調用 OpenAI API 的資源有限的個體,應該首先嚐試在目標任務上微調 FLAN-T5-11B。此外,根據最近在 MMLU 數據集上,FLAN-PaLM-540B 與最新版本的 InstructGPT 的性能(根據 HELM)相比好得驚人的性能,谷歌可能擁有比 OpenAI 更強大的基礎模型,如果 OpenAI 已經通過 API 發佈了他們獲得的最強的 LLM。
谷歌唯一剩下的步驟是通過人類反饋使這個 LLM與對話場景對齊(alignment)。如果他們很快發佈類似 ChatGPT 的或者更好的聊天機器人,我不會感到驚訝——儘管他們最近“失敗”地展示了一版可能基於 LaMDA 的 Bard。
參考文獻:
[1] HELM: Holistic Evaluation of Language Models and its board: http://crfm.stanford.edu/helm/v0.2.0/?group=core_scenarios
[2] GPT3: Language Models are Few-Shot Learners
[3] PaLM: Scaling Language Modeling with Pathways
[4] OPT: Open Pre-trained Transformer Language Models
[5] BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
[6] FLAN-T5/PaLM: Scaling Instruction-Finetuned Language Models
[7] The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
[8] InstructGPT: Training language models to follow instructions with human feedback
[9] Yao Fu’s blog on “Tracing Emergent Abilities of Language Models to their Sources”
[10] Inverse Scaling Prize: http://github.com/inverse-scaling/prize
[11] Is ChatGPT a General-Purpose Natural Language Processing Task Solver?
其他人都在看
歡迎Star、試用OneFlow最新版本:http://github.com/Oneflow-Inc/oneflow/
本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- OneFlow源碼解析:Eager模式下的設備管理與併發執行
- OpenAI創始人:GPT-4的研究起源和構建心法
- GPT-4創造者:第二次改變AI浪潮的方向
- NCCL源碼解析①:初始化及ncclUniqueId的產生
- GPT-4問世;LLM訓練指南;純瀏覽器跑Stable Diffusion
- 適配PyTorch FX,OneFlow讓量化感知訓練更簡單
- 超越ChatGPT:大模型的智能極限
- ChatGPT作者John Schulman:我們成功的祕密武器
- YOLOv5全面解析教程⑤:計算mAP用到的Numpy函數詳解
- GPT-3/ChatGPT復現的經驗教訓
- ChatGPT背後:從0到1,OpenAI的創立之路
- 一塊GPU搞定ChatGPT;ML系統入坑指南;理解GPU底層架構
- YOLOv5全面解析教程④:目標檢測模型精確度評估
- ChatGPT數據集之謎
- OneFlow源碼解析:Eager模式下的SBP Signature推導
- YOLOv5全面解析教程③:更快更好的邊界框迴歸損失
- ChatGPT背後的經濟賬
- Sam Altman的成功學|升維指南
- 開源機器學習軟件對AI的發展意味着什麼?
- “一鍵”模型遷移,性能翻倍,多語言AltDiffusion推理速度超快