效果提升28個點!基於領域預訓練和對比學習SimCSE的語義檢索

語義檢索相比傳統基於字面關鍵詞的檢索有諸多優勢,廣泛應用於問答、搜索系統中。今天小編就手把手帶大家完成一個基於領域預訓練和對比學習SimCSE的語義檢索小系統。
所謂語義檢索(也稱基於向量的檢索),是指檢索系統不再拘泥於用户Query字面本身(例如BM25檢索),而是能精準捕捉到用户Query背後的真正意圖並以此來搜索,從而向用户返回更準確的結果。
最終可視化demo如下,一方面可以獲取文本的向量表示;另一方面可以做文本檢索,即得到輸入Query的top-K相關文檔!
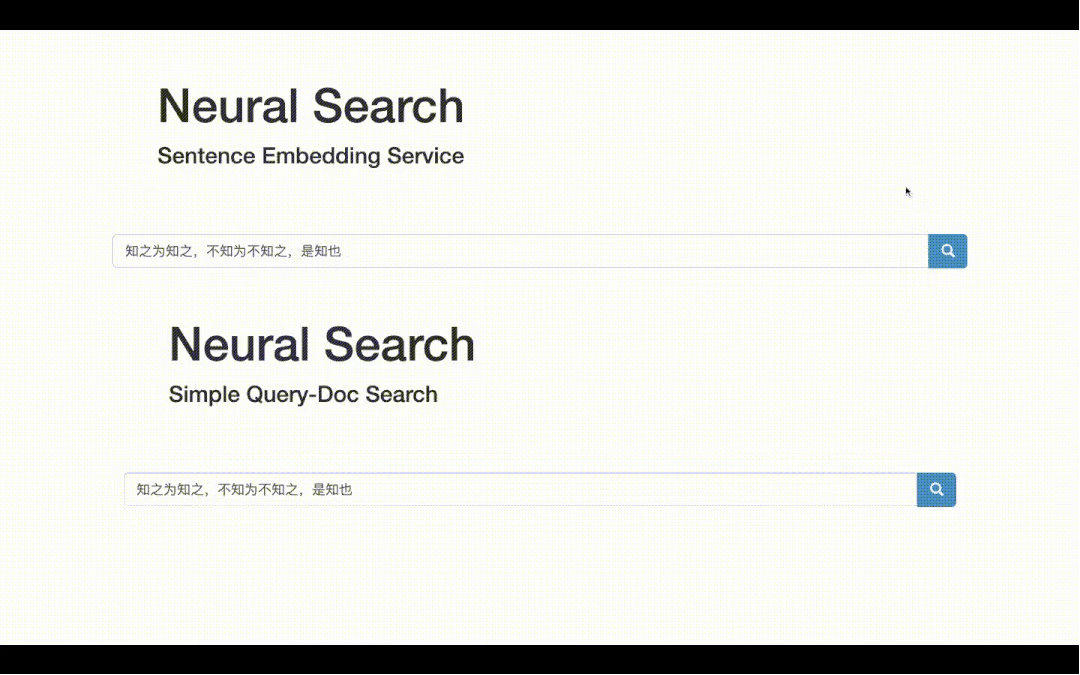
語義檢索,底層技術是語義匹配,是NLP最基礎常見的任務之一。從廣度上看,語義匹配可以應用到QA、搜索、推薦、廣告等各大方向;從技術深度上看,語義匹配需要融合各種SOTA模型、雙塔和交互兩種常用框架的魔改、以及樣本處理的藝術和各種工程tricks。
比較有趣的是,在查相關資料的時候,發現百度飛槳PaddleNLP最近剛開源了類似的功能,可謂國貨之光!之前使用過PaddleNLP,基本覆蓋了NLP的各種應用和SOTA模型,調用起來也非常方便,強烈推薦大家試試!
接下來基於PaddleNLP提供的輪子一步步搭建語義檢索系統。整體框架如下,由於計算量與資源的限制,一般工業界的搜索系統都會設計成多階段級聯結構,主要有召回、排序(粗排、精排、重排)等模塊,各司其職。
-
step-1:利用預訓練模型離線構建候選語料庫;
-
step-2:召回模塊,對於在線查詢Query,利用Milvus快速檢索得到top1000候選集;
-
step-3:排序模塊,對於召回的top1000,再做更精細化的排序,得到top100結果返回給用户。
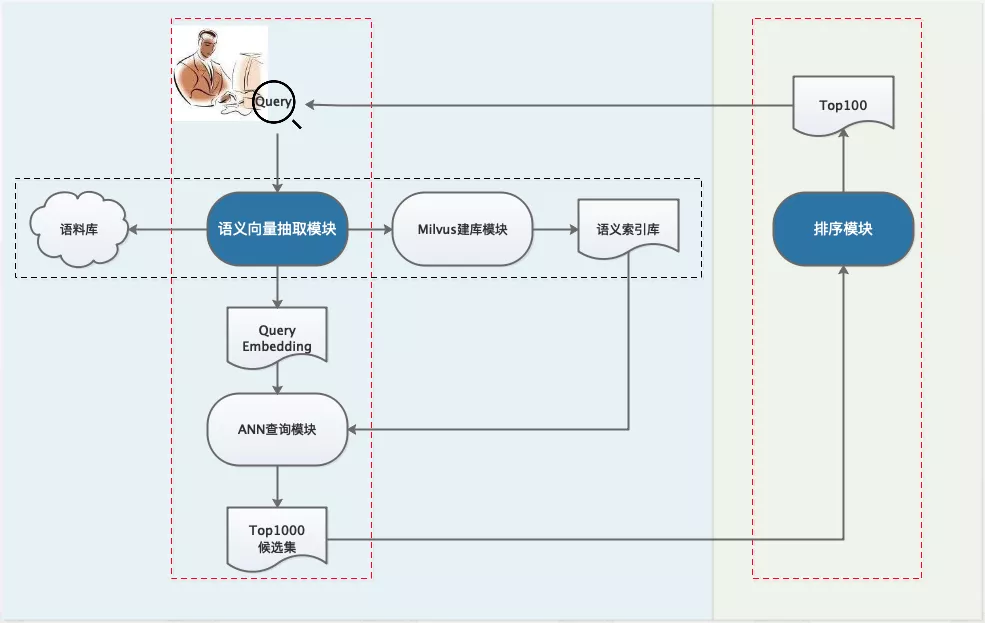
語義檢索技術框架圖
整體概覽
1.1 數據
數據來源於某文獻檢索系統,分為有監督(少量)和無監督(大量)兩種。
1.2 代碼
首先clone代碼:
git clone [email protected]:PaddlePaddle/PaddleNLP.git
cd applications/neural_search
運行環境是:
-
python3
-
paddlepaddle==2.2.1
-
paddlenlp==2.2.1
還有一些依賴包可以參考requirements.txt。
離線建庫
從上面的語義檢索技術框架圖中可以看出,首先我們需要一個語義模型對輸入的Query/Doc文本提取向量,這裏選用基於對比學習的SimCSE,核心思想是使語義相近的句子在向量空間中臨近,語義不同的互相遠離。
那麼,如何訓練才能充分利用好模型,達到更高的精度呢?對於預訓練模型,一般常用的訓練範式已經從『通用預訓練->領域微調』的兩階段範式變成了『通用預訓練->領域預訓練->領域微調』三階段範式。
具體地,在這裏我們的模型訓練分為幾步(代碼和相應數據在下一節介紹):
1.在無監督的領域數據集上對通用ERNIE 1.0 進一步領域預訓練,得到領域ERNIE;
2.以領域ERNIE為熱啟,在無監督的文獻數據集上對 SimCSE 做預訓練;
3.在有監督的文獻數據集上結合In-Batch Negatives策略微調步驟2模型,得到最終的模型,用於抽取文本向量表示,即我們所需的語義模型,用於建庫和召回。
由於召回模塊需要從千萬量級數據中快速召回候選集合,通用的做法是藉助向量搜索引擎實現高效 ANN,從而實現候選集召回。這裏採用Milvus開源工具,關於Milvus的搭建教程可以參考官方教程
http://milvus.io/cn/docs/v1.1.1/
Milvus是一款國產高性能檢索庫, 和Facebook開源的Faiss功能類似。
離線建庫的代碼位於PaddleNLP/applications/neural_search/recall/milvus
|—— scripts
|—— feature_extract.sh #提取特徵向量的bash腳本
├── base_model.py # 語義索引模型基類
├── config.py # milvus配置文件
├── data.py # 數據處理函數
├── embedding_insert.py # 插入向量
├── embedding_recall.py # 檢索topK相似結果 / ANN
├── inference.py # 動態圖模型向量抽取腳本
├── feature_extract.py # 批量抽取向量腳本
├── milvus_insert.py # 插入向量工具類
├── milvus_recall.py # 向量召回工具類
├── README.md
└── server_config.yml # milvus的config文件,本項目所用的配置2.1 抽取向量
依照Milvus教程搭建完向量引擎後,就可以利用預訓練語義模型提取文本向量了。運行feature_extract.py即可,注意修改需要建庫的數據源路徑。
運行結束會生成1000萬條的文本數據,保存為corpus_embedding.npy。
2.2 插入向量
接下來,修改config.py中的Milvus ip等配置,將上一步生成的向量導入到Milvus庫中。
embeddings=np.load('corpus_embedding.npy')
embedding_ids = [i for i in range(embeddings.shape[0])]
client = VecToMilvus()
collection_name = 'literature_search'
partition_tag = 'partition_2'
data_size=len(embedding_ids)
batch_size=100000
for i in tqdm(range(0,data_size,batch_size)):
cur_end=i+batch_size
if(cur_end>data_size):
cur_end=data_size
batch_emb=embeddings[np.arange(i,cur_end)]
status, ids = client.insert(collection_name=collection_name, vectors=batch_emb.tolist(), ids=embedding_ids[i:i+batch_size],partition_tag=partition_tag)
抽取和插入向量兩步,如果機器資源不是很"富裕"的話,可能會花費很長時間。這裏建議可以先用一小部分數據進行功能測試,快速感知,等真實部署的階段再進行全庫的操作。
插入完成後,我們就可以通過Milvus提供的可視化工具[1]查看向量數據,分別是文檔對應的ID和向量。
文檔召回
召回階段的目的是從海量的資源庫中,快速地檢索出符合Query要求的相關文檔Doc。出於計算量和對線上延遲的要求,一般的召回模型都會設計成雙塔形式,Doc塔離線建庫,Query塔實時處理線上請求。
召回模型採用Domain-adaptive Pretraining + SimCSE + In-batch Negatives方案。
另外,如果只是想快速測試或部署,PaddleNLP也貼心地開源了訓練好的模型文件,下載即可用,這裏直接貼出模型鏈接:
-
領域預訓練ERNIE:
-
無監督SimCSE:
http://bj.bcebos.com/v1/paddlenlp/models/simcse_model.zip
-
有監督In-batch Negatives:
http://bj.bcebos.com/v1/paddlenlp/models/inbatch_model.zip
3.1 領域預訓練
Domain-adaptive Pretraining的優勢在之前文章已有具體介紹,不再贅述。直接給代碼,具體功能都標註在後面。
domain_adaptive_pretraining/
|—— scripts
|—— run_pretrain_static.sh # 靜態圖與訓練bash腳本
├── ernie_static_to_dynamic.py # 靜態圖轉動態圖
├── run_pretrain_static.py # ernie1.0靜態圖預訓練
├── args.py # 預訓練的參數配置文件
└── data_tools # 預訓練數據處理文件目錄
3.2 SimCSE無監督預訓練
雙塔模型,採用ERNIE 1.0熱啟,引入 SimCSE 策略。訓練數據示例如下代碼結構如下,各個文件的功能都有備註在後面,清晰明瞭。
simcse/
├── model.py # SimCSE 模型組網代碼
|—— deploy
|—— python
|—— predict.py # PaddleInference
├── deploy.sh # Paddle Inference的bash腳本
|—— scripts
├── export_model.sh # 動態圖轉靜態圖bash腳本
├── predict.sh # 預測的bash腳本
├── evaluate.sh # 召回評估bash腳本
├── run_build_index.sh # 索引的構建腳本
├── train.sh # 訓練的bash腳本
|—— ann_util.py # Ann 建索引庫相關函數
├── data.py # 無監督語義匹配訓練數據、測試數據的讀取邏輯
├── export_model.py # 動態圖轉靜態圖
├── predict.py # 基於訓練好的無監督語義匹配模型計算文本 Pair 相似度
├── evaluate.py # 根據召回結果和評估集計算評估指標
|—— inference.py # 動態圖抽取向量
|—— recall.py # 基於訓練好的語義索引模型,從召回庫中召回給定文本的相似文本
└── train.py # SimCSE 模型訓練、評估邏輯
對於訓練、評估和預測分別運行scripts目錄下對應的腳本即可。訓練得到模型,我們一方面可以用於提取文本的語義向量表示,另一方面也可以用於計算文本對的語義相似度,只需要調整下數據輸入格式即可。
3.3 有監督微調
對上一步的模型進行有監督數據微調,訓練數據示例如下,每行由一對語義相似的文本對組成,tab分割,負樣本來源於引入In-batch Negatives採樣策略。

關於In-batch Negatives 的細節,可以參考文章:
http://mp.weixin.qq.com/s/MyVK6iKTiI-VpP1LKf4LIA
整體代碼結構如下:
|—— data.py # 數據讀取、數據轉換等預處理邏輯
|—— base_model.py # 語義索引模型基類
|—— train_batch_neg.py # In-batch Negatives 策略的訓練主腳本
|—— batch_negative
|—— model.py # In-batch Negatives 策略核心網絡結構
|—— ann_util.py # Ann 建索引庫相關函數
|—— recall.py # 基於訓練好的語義索引模型,從召回庫中召回給定文本的相似文本
|—— evaluate.py # 根據召回結果和評估集計算評估指標
|—— predict.py # 給定輸入文件,計算文本 pair 的相似度
|—— export_model.py # 動態圖轉換成靜態圖
|—— scripts
|—— export_model.sh # 動態圖轉換成靜態圖腳本
|—— predict.sh # 預測bash版本
|—— evaluate.sh # 評估bash版本
|—— run_build_index.sh # 構建索引bash版本
|—— train_batch_neg.sh # 訓練bash版本
|—— deploy
|—— python
|—— predict.py # PaddleInference
|—— deploy.sh # Paddle Inference部署腳本
|—— inference.py # 動態圖抽取向量訓練、評估、預測的步驟和上一步無監督的類似,聰明的你肯定一看就懂了!
3.4 語義模型效果
前面説了那麼多,來看看幾個模型的效果到底怎麼樣?對於匹配或者檢索模型,常用的評價指標是Recall@K,即前TOP-K個結果檢索出的正確結果數與全庫中所有正確結果數的比值。
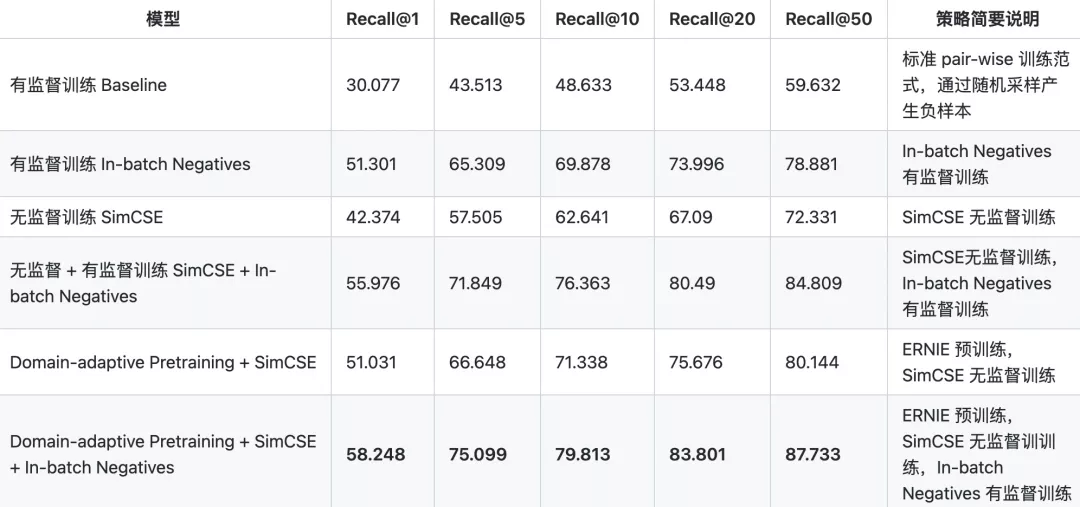
對比可以發現,首先利用ERNIE 1.0做Domain-adaptive Pretraining,然後把訓練好的模型加載到SimCSE上進行無監督訓練,最後利用In-batch Negatives 在有監督數據上進行訓練能獲得最佳的性能。
3.5 向量召回
終於到了召回,回顧一下,在這之前我們已經訓練好了語義模型、搭建完了召回庫,接下來只需要去庫中檢索即可。代碼位於
PaddleNLP/applications/neural_search/recall/milvus/inference.py
def search_in_milvus(text_embedding):
collection_name = 'literature_search' # 之前搭建好的Milvus庫
partition_tag = 'partition_2'
client = RecallByMilvus()
status, results = client.search(collection_name=collection_name, vectors=text_embedding.tolist(),
partition_tag=partition_tag)
corpus_file = "../../data/milvus/milvus_data.csv"
id2corpus = gen_id2corpus(corpus_file)
for line in results:
for item in line:
idx = item.id
distance = item.distance
text = id2corpus[idx]
print(idx, text, distance)
以輸入 國有企業引入非國有資本對創新績效的影響——基於製造業國有上市公司的經驗證據 為例,檢索返回效果如下

返回結果的最後一列為相似度,Milvus默認使用的是歐式距離,如果想換成餘弦相似度,可以在Milvus的配置文件中修改。
文檔排序
不同於召回,排序階段由於面向的打分集合相對小很多,一般只有幾千級別,所以可以使用更復雜的模型,這裏採用 ERNIE-Gram 預訓練模型,loss選用 margin_ranking_loss。
訓練數據示例如下,三列,分別為(query,title,neg_title),tab分割。對於真實搜索場景,訓練數據通常來源業務線上的點擊日誌,構造出正樣本和強負樣本。

代碼結構如下
ernie_matching/
├── deply # 部署
└── python
├── deploy.sh # 預測部署bash腳本
└── predict.py # python 預測部署示例
|—— scripts
├── export_model.sh # 動態圖參數導出靜態圖參數的bash文件
├── train_pairwise.sh # Pair-wise 單塔匹配模型訓練的bash文件
├── evaluate.sh # 評估驗證文件bash腳本
├── predict_pairwise.sh # Pair-wise 單塔匹配模型預測腳本的bash文件
├── export_model.py # 動態圖參數導出靜態圖參數腳本
├── model.py # Pair-wise 匹配模型組網
├── data.py # Pair-wise 訓練樣本的轉換邏輯 、Pair-wise 生成隨機負例的邏輯
├── train_pairwise.py # Pair-wise 單塔匹配模型訓練腳本
├── evaluate.py # 評估驗證文件
├── predict_pairwise.py # Pair-wise 單塔匹配模型預測腳本,輸出文本對是相似度
訓練運行sh scripts/train_pairwise.sh即可。
同樣,PaddleNLP也開源了排序模型:
http://bj.bcebos.com/v1/paddlenlp/models/ernie_gram_sort.zip
對於預測,準備數據為每行一個文本對,最終預測返回文本對的語義相似度。
是文化差異。', 'pred_prob': 0.85112214}
{'query': '中西方語言與文化的差異', 'title': '跨文化視角下中國文化對外傳播路徑瑣談跨文化,中國文化,傳播,翻譯', 'pred_prob': 0.78629625}
{'query': '中西方語言與文化的差異', 'title': '從中西方民族文化心理的差異看英漢翻譯語言,文化,民族文化心理,思維方式,翻譯', 'pred_prob': 0.91767526}
{'query': '中西方語言與文化的差異', 'title': '中英文化差異對翻譯的影響中英文化,差異,翻譯的影響', 'pred_prob': 0.8601749}
{'query': '中西方語言與文化的差異', 'title': '淺談文化與語言習得文化,語言,文化與語言的關係,文化與語言習得意識,跨文化交際', 'pred_prob': 0.8944413}
總結
本文基於PaddleNLP提供的Neural Search功能自己快速搭建了一套語義檢索系統。相對於自己從零開始,PaddleNLP非常好地提供了一套輪子。如果直接下載PaddleNLP開源訓練好的模型文件,對於語義相似度任務,調用現成的腳本幾分鐘即可搞定!對於語義檢索任務,需要將全量數據導入Milvus構建索引,除訓練和建庫時間外,整個流程預計30-50分鐘即可完成。
在訓練的間隙還研究了下,發現GitHub上的文檔也很清晰詳細啊,對於小白入門同學,做到了一鍵運行,不至於被繁雜的流程步驟困住而逐漸失去興趣;模型全部開源,拿來即用;對於想要深入研究的同學,PaddleNLP也開源了數據和代碼,可以進一步學習,贊!照着跑下來,發現PaddleNLP太香了!趕緊Star收藏一下,持續跟進最新能力吧,也表示對開源社區的一點支持~
http://github.com/PaddlePaddle/PaddleNLP
另外我們還可以基於這些功能進行自己額外的開發,譬如開篇的動圖,搭建一個更直觀的語義向量生成和檢索服務。Have Fun!
在跑代碼過程中也遇到一些問題,非常感謝飛槳同學的耐心解答。並且得知針對這個項目還有一節視頻課程已經公開,點擊鏈接即可觀看課程:
http://aistudio.baidu.com/aistudio/course/introduce/24902
最後附上本次實踐項目的代碼:
http://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search
- 訓練數據有缺陷?TrustAI來幫你!
- 低代碼平台中的數據連接方式(上)
- 你一定愛讀的極簡數據平台史,從數據倉庫、數據湖到湖倉一體
- 百度APP視頻播放中的解碼優化
- 如何輕鬆上手3D檢測應用實戰?飛槳產業實踐範例全流程詳解
- 四步做好 Code Review
- 百度智能雲天工邊雲融合物聯網平台,助力設備高效上雲
- Redis 主從複製的原理及演進
- 面由心生,由臉觀心:基於AI的面部微表情分析技術解讀
- 大模型應用新範式:統一特徵表示優化(UFO)
- 智能大數據,看這本白皮書就夠了
- 效果提升28個點!基於領域預訓練和對比學習SimCSE的語義檢索
- 百度基於 Prometheus 的大規模線上業務監控實踐
- AI CFD:面向空天動力的科學機器學習新方法與新範式
- 飛槳圖神經網絡PGL助力國民級音樂App,創新迭代千億級推薦系統
- 全新緩存組件,大幅加速雲上飛槳分佈式訓練作業
- 知乎用户畫像和實時數據的架構與實踐
- 全新緩存組件,大幅加速雲上飛槳分佈式訓練作業
- “千言”開源數據集項目全面升級:數據驅動AI技術進步
- 百度CTO王海峯:AI大生產平台再升級 助力中國科技自立自強