“千言”開源數據集項目全面升級:數據驅動AI技術進步

“千言”是由百度聯合中國計算機學會、中國中文信息學會共同發起的面向自然語言處理的開源數據集項目,旨在推動中文信息處理技術的進步。近日,在2021年12月12日的WAVE SUMMIT+2021深度學習開發者峯會上,清華大學長聘副教授黃民烈作了題為“千言:數據驅動技術進步”的演講,回顧了千言過去一年中取得的進展和廣泛影響力,併發布了千言的全新升級,重點聚焦大模型時代的機遇和挑戰。此外,還推出了“百+”計劃,邀請更多的專家學者共同建設千言,構建世界範圍內的中文NLP影響力。
中文開源數據集項目 “千言”獲得廣泛關注和使用
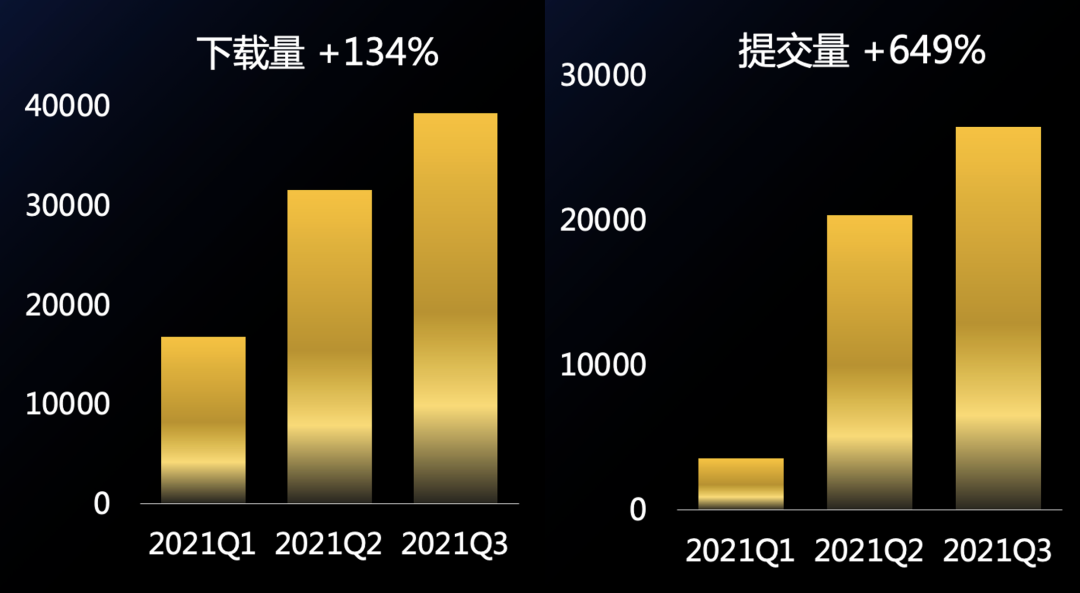
“千言”開源數據集項目自2020年8月發佈以來,已經有來自清華、哈工大、中科院、美團、OPPO等14家單位的數據集作者加入共同建設,目前已經覆蓋了10多個自然語言處理的任務,包含了開放域對話、機器閲讀理解、機器同傳、文本生成、情感分析等任務。“千言”為研究者提供了一站式的數據集瀏覽、整理、下載以及評測體驗,受到了越來越多研究者的關注和使用,數據集下載量增長134%,相關任務的提交次數增長649%,增長非常顯著。
此外,千言還推動了多項自然語言處理的評測,截至目前總共支持了20多項技術評測,包含了語言與智能技術競賽(LIC 2021)、CCF BDCI多技能對話評測、NLGIW 2021面向事實一致性的生成評測、CCF BDCI問題匹配魯棒性評測、NAACL 2021機器同傳評測等。其中,參與評測的人員有57%來自高校和科研院所,21%來自企業,在學術界和工業界都產生了很大的影響力。開源數據集和技術評測的聯動,很好的推動了相關任務的技術研究和應用發展。
“千言”升級:聚焦通用、可信、跨模態等大模型時代的機遇和技術挑戰
推動人工智能技術進步的三大驅動力是算法、算力和數據。其中,數據作為最重要的基礎,其數量和質量直接決定了算法能夠達到的上限水平。人工智能的歷史上,優秀的數據集極大地推動了領域技術的發展和行業的進步。近兩三年,隨着大模型技術的出現和發展,基於大模型的自然語言處理技術也取得了長足的進步。在取得進步的同時,大模型也帶來了新的技術挑戰和新的技術機遇,包括了通用、可信、跨模態等。“千言”的升級也重點聚焦在了這三個方面。
第一,通用。通用指模型需要具有全面的、處理多個子任務的能力,同時需要在跨領域數據上具有較好的泛化能力。“千言”推出了多技能對話任務和多形態信息抽取任務來促進模型通用性的提升。在多技能對話任務中,期望模型能夠同時處理多種對話子任務,包括知識對話、閒聊對話、推薦對話、畫像對話等;在多形態信息抽取任務上,期望模型能夠同時處理句子級關係抽取、句子級事件抽取和以及篇章級事件抽取等任務。
第二,可信。可信是指模型在應用中需要有足夠的魯棒性、較高的可解釋性以及結果的一致性。其中,為了促進提升模型的魯棒性,“千言”發佈了問題匹配魯棒性數據集DuQM、閲讀理解魯棒性數據集DuReaderchecklist。為了提升模型的可解釋性,“千言”發佈了情感分析可解釋數據集 DuTrust。在事實一致性方面,“千言”則推出三個生成任務來綜合進行評測,分別包括了文案生成數據集AdvertiseGen、摘要生成數據集LCSTS、問題生成數據集DuReaderQG。
第三,跨模態。跨模態是指隨着內容承載形式的多元化,模型需要具有多模態融合(語言、圖像、語音、視頻等)的內容理解等能力。為此,“千言”推出了機器同傳數據集BSTC以及跨模態情感分析數據集DuVideoSenti來促進跨模態領域的發展。機器同傳主要關注語言和語音跨模態的交互,而跨模態情感分析主要關注語言和視頻跨模態的交互。
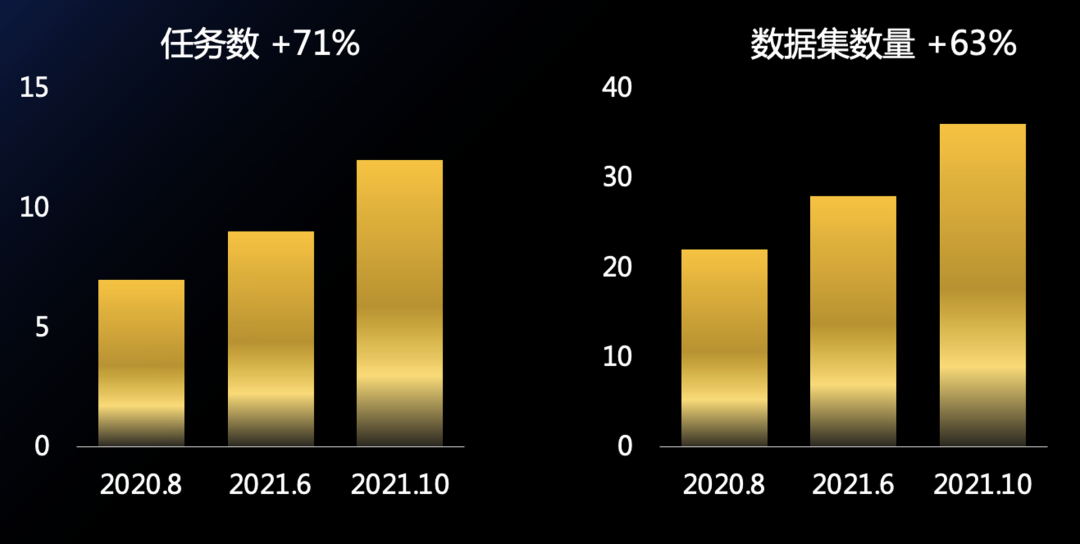
經過了一年的發展,千言所覆蓋的任務和數據集數量顯著增加,從最開始的7個任務,發展到最新的12個任務,對應的數據集數量,也從最開始的22個數據集,增加到了現在36個數據集。
千言“百+”計劃:共同構建世界範圍內中文NLP的影響力
為了更好地幫助數據集作者提升數據集影響力和推進相關技術發展,千言項目正式推出了“百+計劃”,覆蓋了“百+數據集作者”和“百+技術專家”。作為“百+數據集作者”,會被邀請進入千言學術委員會。千言會幫助數據集作者發佈評測,並提供飛槳開源基線、評測平台和GPU算力的支持,提升數據集的影響力,推動技術的發展。“百+技術專家”則是針對優秀開發者和學生的認證,技術專家可以得到大量分享和交流技術方案的機會,並會受邀參與官方活動。

中文是千年華夏文明傳承的載體,是中華民族的驕傲和根基。在當下的人工智能時代,“千言”數據開源項目也希望與學術界、產業界攜手,共同推動中文信息處理技術的進步,理解語言、擁有智能,改變世界,將華夏文明的寶藏學習並傳承下去。
- 訓練數據有缺陷?TrustAI來幫你!
- 低代碼平台中的數據連接方式(上)
- 你一定愛讀的極簡數據平台史,從數據倉庫、數據湖到湖倉一體
- 百度APP視頻播放中的解碼優化
- 如何輕鬆上手3D檢測應用實戰?飛槳產業實踐範例全流程詳解
- 四步做好 Code Review
- 百度智能雲天工邊雲融合物聯網平台,助力設備高效上雲
- Redis 主從複製的原理及演進
- 面由心生,由臉觀心:基於AI的面部微表情分析技術解讀
- 大模型應用新範式:統一特徵表示優化(UFO)
- 智能大數據,看這本白皮書就夠了
- 效果提升28個點!基於領域預訓練和對比學習SimCSE的語義檢索
- 百度基於 Prometheus 的大規模線上業務監控實踐
- AI CFD:面向空天動力的科學機器學習新方法與新範式
- 飛槳圖神經網絡PGL助力國民級音樂App,創新迭代千億級推薦系統
- 全新緩存組件,大幅加速雲上飛槳分佈式訓練作業
- 知乎用户畫像和實時數據的架構與實踐
- 全新緩存組件,大幅加速雲上飛槳分佈式訓練作業
- “千言”開源數據集項目全面升級:數據驅動AI技術進步
- 百度CTO王海峯:AI大生產平台再升級 助力中國科技自立自強