當我們在談論DataOps時,我們到底在談論什麼
1. DataOps到底是什麼?
伴隨着全球數字化轉型的高速發展,在雲計算、物聯網、5G、邊緣計算、元宇宙等新技術的驅動下,數據爆炸的時代已經來臨。IDC Global DataSphere顯示,2021年,全球數據總量達到了84.5ZB,預計到2026年,全球結構化與非結構化數據總量將達到221.2ZB。
此外,在《數字化轉型架構:方法論和雲原生實踐》一書中也提到雲原生應用平台的發展將經歷DevOps—DataOps—AIOps的演進路徑,可以看出在雲原生的浪潮下,企業也越來越需要數據。但在面對數據量巨大、數據種類繁多、數據急劇增長的困境時,對企業駕馭數據的能力也提出更高的要求。如果不能對海量數據進行合理有序的組織和管理,非但不能產生數據價值,反而會對企業造成極大的負擔,從某種程度上來説,也是一種“數據災難”,而這也是DataOps一直處於熱門話題的原因。在開源SREWorks項目數據化建設過程中,我們也一直在思考:DataOps到底是在做什麼?
在討論DataOps之前,我們先來看下DevOps。DevOps是一種軟件交付管理的思想,它追求一種敏捷的、規範的、跨團隊的軟件研發協作狀態,力求將一套軟件的開發模式,從小作坊形態演變成一條標準的生產流水線。DevOps在一定程度上為DataOps的發展奠定了基礎,因此,DevOps是我們在討論DataOps時繞不開的重要話題。
DataOps本身也是屬於敏捷開發範疇,類似DevOps以較短的開發迭代週期快速滿足各自的需求,同時DataOps也需要大量標準化數據工具或組件,依賴團隊之間協作,進行數據的開發和分析。與DevOps不同的是DataOps主要專注於數據流,因此,通過數據化的方法或方法論來推動企業運營水平的提升都可以隸屬於DataOps的範疇。

The DataOps lifecycle (來源 The Rise of DataOps: Governance and Agility with TrueDataOps)
DataOps是data operationalization的縮寫,DataOps不單單指數據技術的工具和平台,更重要的是一套數據全生命週期管理的方法論和思想。基於數據驅動,通過一系列面向流程的工具和平台,將DataOps思想進行工程化落地實踐,能夠將所有系統的相關數據採集起來,打破數據孤島,統一建設高效規範的數據模型和數據體系,深度挖掘數據價值。
DataOps的方法論和思想主要是被分析和數據團隊使用,旨在簡化數據使用、降低數據分析門檻,提高數據分析質量、縮短數據分析週期。也就是説,數據作為一種大數據時代的“新能源”,本身是需要通過平台化的能力, 實現圍繞“數據集成、數據開發、數據存儲、數據治理以及數據服務”等體系化的數據管理流程。更進一步,基於數據驅動的思想,進行數據分析和數據消費,通過數據賦能,做好各個業務領域的相關工作,真正解決實際生產過程中遇到的痛點問題,實現數據價值落地的場景化輸出。

DataOps架構(來源:Diving into DataOps: The Underbelly of Modern Data Pipelines)
2. DataOps能夠解決哪些問題?
下面列舉一些常見的數據相關的問題,對於想要實施DataOps的公司來講,可以判斷一下是否有遇到:
1. 如何確保生產的數據質量?
2. 如何判斷生產的數據能否滿足業務的需求?
3. 如何判斷某個數據型項目工程的價值並持續投入?
4. 如何尋找大數據人才?
5. 如何提高數據處理的性能?
6. 大數據方案採用什麼技術棧?
7. 大數據方案的運維穩定性如何保障?
8. 引入了多個大數據方案,如何統一進行管理?
9. 大數據的數據權限如何管理?
10. 數據分析結果如何指導最終的決策?
上面常見的問題,可以歸為三大場景:數據管理、數據運維和數據使用。通常實施數據化的公司都是在初期嚐到了一些數據帶來的甜頭,但是在持續投入之後,卻又發現這塊的收益產出似乎帶有很大的不確定性:數據表逐漸地被雜亂的數據堆滿,數據產出鏈路常常延遲,而通過數據分析進行決策似乎也沒像之前那麼有效了。
簡而言之,當數據量變大,數據工程變複雜之後,如果沒有規範的體系和流程,整體的協作關係又容易變回小作坊形態,存在諸如數據計算口徑不統一、數據重複建設以及數據質量不高等問題,需要尋求一些標準化、規範化、體系化、工程化的方式來進行解決。
3. 如何進行DataOps實踐?
正如前文所説,DataOps本身是一套完整的數據體系建設的方法論,其目標是能夠讓數據持續用起來,實現“數據集成、數據開發、數據存儲、數據治理以及數據服務”等數據管理能力。這也意味着需要依賴眾多的數據技術或數據組件來建設和運營DataOps數據平台,進而形成高效可靠的數據資產化體系和數據服務化能力,也即針對Data的數據運維。
數據集成
數據集成是構建企業級DataOps數據平台的第一步,依賴企業內部的跨部門協作,能夠將不同來源的數據(不同的業務系統)以及不同類型的數據(結構化、半結構化、非結構化、離線以及實時數據等)進行整合,實現互聯互通。從源頭上避免數據的重複造輪和資源浪費問題,為構建規範化的數據體系、沉澱數據資產以及挖掘數據價值作準備。
數據集成一般是通過數據引入方式,將一個系統的數據按時按量集成到另一個系統中。通常採用ELT(Extract-Load-Transform,提取-加載-轉換)的模式,重點在於數據匯聚,即將數據提取後直接加載到目標端存儲中,這個階段一般不做或者只做簡單的數據清洗和數據處理。業界優秀的數據集成工具包括像Sqoop、DataX、Kettle、Canal以及StreamSets等。
數據開發
數據開發的目標是能夠將數據集成階段的原始數據,按照業務的需求進行加工處理、將原始的低業務價值的數據轉換成高業務價值的數據資產,也就是説數據開發階段是實現數據資產化的核心技術手段。
數據開發作為數據加工處理的核心階段,通常會採用ETL(Extract-Transform-Load,提取-轉換-加載)的模式並集成一系列的數據開發管控流程和工具,方便數據開發人員對ETL任務的編寫、構建、發佈、運維以及任務資源管控等,提升效率。通常數據開發主要分成離線數據開發和實時數據開發兩大場景。
離線數據開發主要用於離線數據的批量定時加工處理,離線數據開發需要包含離線計算引擎、作業開發、任務調度、數據管控以及運維監控等核心能力,實際使用過程中,相關的離線ETL任務會按照預先設定的加工邏輯和ETL之間的拓撲依賴關係,進行調度執行。常見的離線處理框架包括MapReduce、Hive以及Spark等。在阿里巴巴內部也早已形成體系的MaxCompute通用大數據開發套件,快速解決用户的海量數據離線計算問題,有效降低企業成本並保障數據安全等。
實時數據開發主要涉及對實時流式數據的加工處理,滿足像監控告警、數據大屏等對實時性要求較高的場景。在實時計算場景下,業務系統每產生一條數據,都會通過消息中間件(比如Kafka)被實時發送到流式處理平台進行加工處理,不再依賴調度引擎。常見的流式處理框架包括Storm、Spark Streaming以及Flink等。在阿里巴巴內部也基於Apache Flink構建了一站式的實時大數據分析平台,提供端到端的亞秒級實時數據加工處理分析能力。
數據存儲
有了數據集成和數據開發的能力,下一階段就是考慮如何進行數據存儲和數據組織,其核心是標準規範的數據倉庫和數據模型建設,也就是説數據倉庫是實現數據資產化的呈現載體。
目前用的最多的數據建模方式是維度建模,典型代表有阿里巴巴建設的“OneData”數據建模體系,主要包括數據規範定義、數據模型設計以及ETL開發規範三部分。
數據規範定義:數據主題域、業務過程、指標規範、名詞定義以及時間週期等命名規範。
數據模型設計:模型層次劃分(分成數據引入層ODS、數據公共層CDM以及數據應用層ADS三層,其中CDM層又包括明細數據層DWD、彙總數據層DWS和維度數據層DIM)、模型設計原則、模型命名規範、模型生命週期管理以及數據質量規範等。
ETL開發規範:數據處理作業的研發流程、編碼規範以及發佈運維原則等。

數據倉庫實施工作流(來源:《大數據之路》)
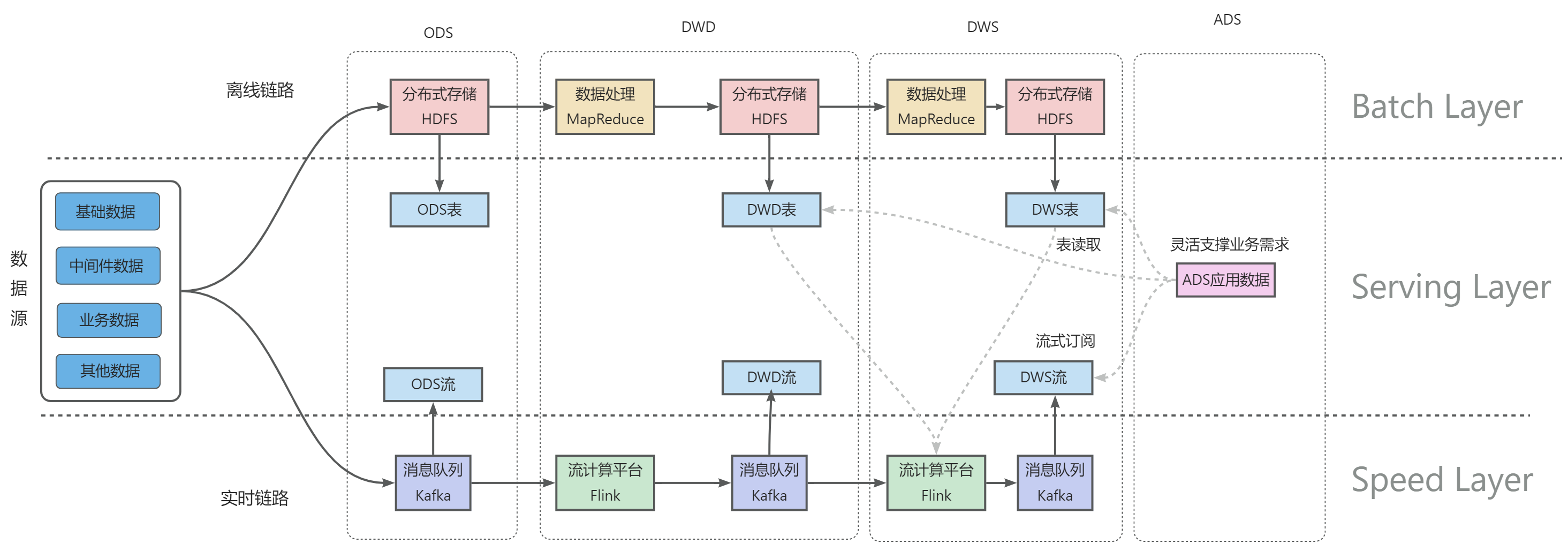
數據倉庫建設工程鏈路(離線鏈路+實時鏈路)
數據治理
數據治理主要是對數據資產,配置數據管理策略,主要包括數據標準、數據質量、數據成本以及數據安全等內容。通過多維度進行量化評估,針對數據建設提出改進與優化建議,確保數據質量、標準、安全、易用。它包含以下功能:
-
數據標準化管理:負責數據倉庫中數據的表達、格式以及定義的規範性,包括模型規範、數倉元數據規範、名詞術語規範、指標規範等進行管理,針對未標準化的內容提出改進建議。
-
數據成本:主要從存儲量和訪問情況等沉澱相關治理項,比如:空表、無效表(未關聯ETL任務表)、長期未訪問表、長週期表、大數據量表等,通過對治理項的運作,提出優化建議,推動數據開發人員進行成本治理。
-
數據質量:圍繞數據的完整性、準確性、一致性、有效性和及時性五個維度並對數據的重要性進行資產等級劃分,對質量保障既包括事前保障,比如數據開發流程、數據標準執行等,又有事中保障,比如DQC的數據質量實時監控和告警,還有事後保障,比如數據質量故障覆盤,確定質量問題根因等。
-
數據安全:評估數據安全風險,對數據設定安全等級,包括支持安全認證和權限管理、資源隔離、數據加密、數據脱敏等,保障數據安全可靠的被傳輸、存儲和使用。
數據服務
數據服務旨在提供統一的數據消費服務總線,能夠將數據資產生成API服務,其目標是把數據服務化,讓數據能夠快速集成到業務場景當中,發揮數據平台的價值。它包含以下主要功能:
-
異構跨庫查詢:如果數據分佈在多個異構數據庫時,用户無法簡單的實現數據關聯查詢,通過數據查詢服務,可以減少數據同步作業,直接實現從多個源數據庫加載數據與完成查詢的能力。
-
數據API 定義與管理:部份常用的數據點查或統計分析,可通過定義數據集與API名稱,並最終暴露為一個HTTP資源路徑的方式,並對數據API進行發佈和訪問授權,方便在各類腳本或代碼中使用數據。
-
數據緩存:對於常用的數據查詢,可定義緩存與更新策略,來減少數據查詢穿透到數據庫,提高性能並降低對數據庫的性能負載。
-
服務編排:按照業務邏輯,以串行、並行和分支等結構編排多個API及函數服務為工作流。
數據應用
有了標準化的數據體系以後,針對數據進行分析和使用又是DataOps所關心的另一個維度的問題,這也是數據驅動的關鍵環節,也即以數據為中心進行決策,驅動業務行為。數據分析人員利用各種數據統計分析方法和智能算法,通過數據平台提供的數據服務API,對相關數據進行多維度、深層次的分析挖掘,支撐業務相關的數據應用場景,持續讓數據用起來,真正發揮數據平台的業務價值。
不同的業務有各自的應用場景,所以這一部分很難面面俱到。本文僅簡單介紹幾種常見的數據應用場景,希望能幫助大家更好的理解,如何基於數據平台的數據資產和數據服務,進行數據分析和使用。
數據大屏:通過對數據進行分析計算,藉助BI類軟件,結合業務需求,以圖表等形式,把一些關鍵的彙總性數據展示出來,實現數據可視化,為業務決策提供準確可靠的數據支持。
智能場景:屬於AIOps範疇,基於數據平台的數據,通過AI算法,從數據中進行提煉、挖掘、洞察,為業務基於數據進行決策和運維運營時提供智能能力,獲得更有前瞻性的數據支持。比較典型的智能應用場景包括像智能推薦、智能客服、智能預測以及健康管理等等。
當然,數據分析也並不是數據的終點,因為隨着數據的沉澱,業務規模的擴大,很多數據分析的結果也可能會作為另一個更高維度模型的數據輸入,被納入數據平台的數據資產當中。因此,數據分析和開發人員需要從一個更高的維度和視角,去整合海量的數據。這也就意味着數據處理的鏈路並不是一成不變的,數據量會隨着業務不斷增長,數據模型也同樣需要不斷演進。

4. 總結
總的來説,DataOps 作為一種數據管理方式,利用 DevOps 方法論對數據的全生命週期進行管理,通過數據平台把數據變成一種服務能力,進而提升數據的使用效率,實現數據持續用起來的目標。以數據平台為承載,以數據場景為驅動,支持更大的創新空間和更優秀的業務模式。
SREWorks雲原生數智運維平台,沉澱了阿里大數據運維團隊近十年經內部業務錘鍊的SRE數智化工程實踐,包含DataOps在運維領域的最佳實踐,歡迎體驗。我們旨在秉承“數據化、智能化”運維思想,幫助更多的從業者採用“數智”思想做好運維。
參考材料
http://www.synopsys.com/blogs/software-security/agile-cicd-devops-difference/
http://zhuanlan.zhihu.com/p/55066486
http://www.uml.org.cn/bigdata/202108115.asp
http://en.wikipedia.org/wiki/DataOps
http://www.tamr.com/blog/from-devops-to-dataops-by-andy-palmer/
SREWorks開源地址:http://github.com/alibaba/sreworks
- 【ASPLOS 2023】圖神經網絡統一圖算子抽象uGrapher,大幅提高計算性能
- 阿里雲PAI-DeepRec CTR 模型性能優化天池大賽——獲獎隊伍技術分享
- 喜馬拉雅基於 HybridBackend 的深度學習模型訓練優化實踐
- 天池 DeepRec CTR 模型性能優化大賽 - 奪冠技術分享
- 喜馬拉雅基於DeepRec構建AI平台實踐
- SREWorks數智運維平台開源一週年 | 回顧與展望
- EasyNLP集成K-Global Pointer算法,支持中文信息抽取
- SREWorks前端低代碼組件生態演進:monorepo架構重構和遠程組件加載實踐
- 實時數倉Hologres新一代彈性計算組實例技術揭祕
- QCon演講實錄(下):多雲管理關鍵能力實現與解析-AppManager
- QCon演講實錄(上):多雲環境下應用管理與交付實踐
- 阿里雲PAI-Diffusion功能再升級,全鏈路支持模型調優,平均推理速度提升75%以上
- 當我們在談論DataOps時,我們到底在談論什麼
- 阿里媽媽Dolphin智能計算引擎基於Flink Hologres實踐
- 基於單機最高能效270億參數GPT模型的文本生成與理解
- 阿里靈傑:與開發者一起推動AI創新落地
- weidl x DeepRec:熱門微博推薦框架性能提升實戰
- vivo 推薦業務 x DeepRec:全鏈路優化實踐
- 基於雲原生的集羣自愈系統 Flink Cluster Inspector
- 模型精度再被提升,統一跨任務小樣本學習算法 UPT 給出解法!