短視訊中解決音視訊混音出現雜音的問題
1 你用過音視訊合成嗎?
現在抖音快手各種短視訊也算是深入人心了,短視訊剪輯中有一個非常重要的功能,就是音視訊合成,選擇一段視訊和一段音訊,然後將它們合成一個新的視訊,新生成的視訊中會有兩個音訊的混音。
下面我們來拆分一下音視訊合成的做法:
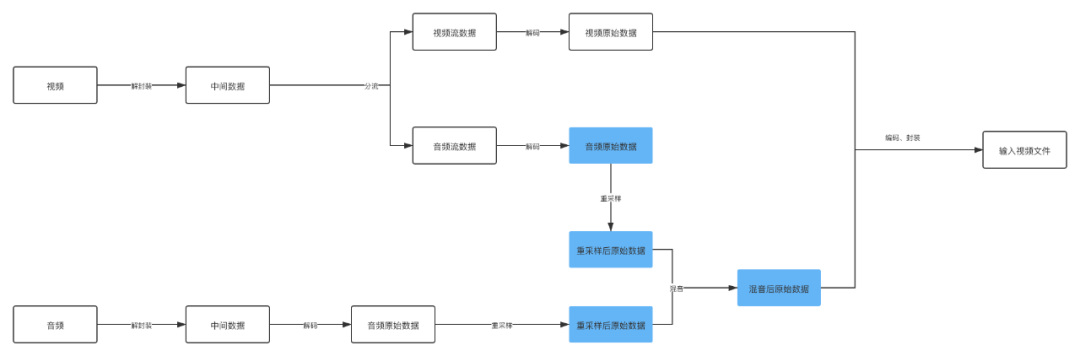
圖中著重標記的幾個流程可以看出來這是音訊視訊合成的重點,其實容易出錯也是在這個地方。
重取樣,這是一個什麼知識點?在介紹重取樣之前,可以先介紹介紹一下音訊的一些性質了。
2 音訊採集的指標
2.1 取樣率
取樣率就是俗稱的取樣頻率,指每秒鐘取得聲音樣本的次數,取樣頻率越高,聲音的質量就越好,聲音的還原也就越真實,但是取樣頻率比較高佔用的資源就比較高。
我們知道人耳正常情況下只能接收20Hz ~ 20kHz 音訊範圍聲音,超過20kHz成為超聲波,低於20Hz成為低聲波,我們都是聽不到的,這兒是說的聲音的頻率和取樣率關係不大。
言歸正傳,過高的取樣率確實可以將聲音刻畫的比較細緻,但是對人耳意義不大,所以還是要做好權衡,根據實際的應用來選擇合適的取樣率。
| 取樣率 |
使用場景 |
| 8000 Hz |
家用電話的取樣率 |
| 44100 Hz |
音樂CD的取樣率 |
| 48000 Hz |
標準的音訊取樣率,目前手機大多數採用這個取樣率 |
| 96000 Hz |
藍光視訊的取樣率 |
其他的取樣很多,不一一介紹了,大家感興趣可以參考:
http://en.wikipedia.org/wiki/Sampling_%28signal_processing%29
2.2 取樣位數
取樣位數就是取樣值或者取樣值,本質就是將取樣樣本幅度量化,這是用來衡量聲音波動變化的一個引數,也可以被認為是聲音的“解析度”,它的數值越大,說明聲音的“解析度”越高,能發出的聲音能力就越強,越細膩。
每個取樣資料記錄的是振幅,取樣精度取決於取樣位數的大小:
1位元組:8bit,只能記錄256個數,振幅只能劃分為256個等級。
2位元組:16bit,可以細化到65536個數,正常的CD就是這個標準。
4位元組:32bit,可以細分到4294967296個數,劃分比較細緻,人耳識別不了這麼細緻的聲音。
2.3 取樣通道數
通道數就是聲音採集的渠道有多少。常用的有立體聲和單聲道。
mono:單聲道
stereo:雙聲道
4.1聲道:有4個發聲點,前左、前右、後左、後右,同時增加一個低音道,增強對低頻訊號的處理。
5.1聲道:基於4.1聲道,同時增加一箇中置單元,這個中置單元負責傳送低於80Hz的聲音訊號,增加了人聲,一般用在電影院裡面。
7.1聲道:在聽者的周圍建立起一套前後場相對平衡的聲場,7.1聲道在5.1聲道的基礎上加上了雙路中後置,可以在聽者在任意角度都能聽到一致的聲音。
3 聲音的三個基本屬性
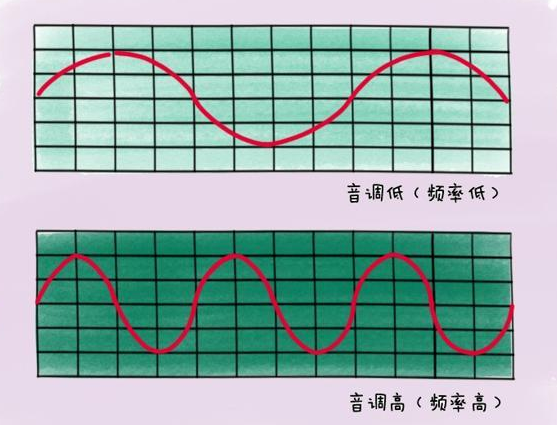
3.1 音調
聲音訊率的高低叫做音調(Pitch),是聲音的三個主要的主觀屬性,即音量(響度)、音調、音色(也稱音品) 之一。表示人的聽覺分辨一個聲音的調子高低的程度。音調主要由聲音的頻率決定,同時也與聲音強度有關
波長長短是衡量聲音音調的因素:
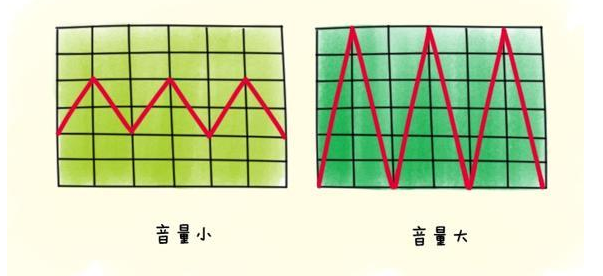
3.2 響度
人主觀上感覺聲音的大小(俗稱音量),由“振幅”(amplitude)和人離聲源的距離決定,振幅越大響度越大,人和聲源的距離越小,響度越大。(單位:分貝dB)
聲波的振幅表示聲音的音量大小:
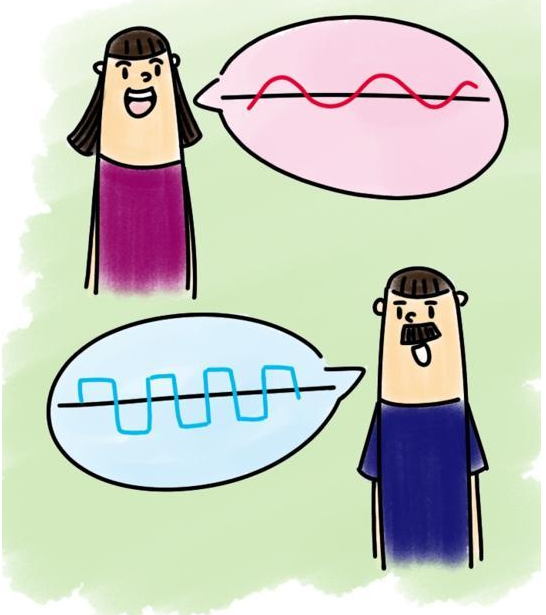
3.3 音色
又稱音品,波形決定了聲音的音色。聲音因不同物體材料的特性而具有不同特性,音色本身是一種抽象的東西,但波形是把這個抽象直觀的表現。音色不同,波形則不同。典型的音色波形有方波,鋸齒波,正弦波,脈衝波等。不同的音色,通過波形,完全可以分辨的。
音色主要和聲波的波紋有關:
4 為什麼需要重取樣
因為不同的平臺不能支援所有的取樣率,所以移植到其他平臺播放的時候,如果不支援當前的音訊取樣率,就需要對音訊取樣率進行重新取樣,就像視訊的重新編解碼一樣的。不然播放音訊會出現問題。無法將聲音的原本特性還原出來。
在音視訊編輯中,經常用到的混音,就需要用到重取樣的功能,保證兩個音訊混合起來,音訊的取樣率一定要標準化,是一樣的取樣率,這樣播放出來的音訊才不能失真。
但是音訊取樣率一樣就一定不會出現問題嗎?
5 一個雜音的例子
需要合成的視訊:
http://github.com/JeffMony/JianYing/blob/main/jeffmony_voice.mp4
Duration: 00:00:11.35, start: 0.000000, bitrate: 21123 kb/sStream #0:0(eng): Video: h264 (High) (avc1 / 0x31637661), yuvj420p(pc, bt470bg/bt470bg/smpte170m), 1920x1080, 20341 kb/s, SAR 1:1 DAR 16:9, 30.02 fps, 30 tbr, 90k tbn, 180k tbc (default)Metadata:rotate : 90creation_time : 2021-08-04T07:59:58.000000Zhandler_name : VideoHandlevendor_id : [0][0][0][0]Side data:displaymatrix: rotation of -90.00 degreesStream #0:1(eng): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 320 kb/s (default)Metadata:creation_time : 2021-08-04T07:59:58.000000Zhandler_name : SoundHandlevendor_id : [0][0][0][0]
需要合成的音訊:
http://github.com/JeffMony/JianYing/blob/main/output.aac
Duration: 00:02:38.18, bitrate: 33 kb/sStream #0:0: Audio: aac (HE-AACv2), 44100 Hz, stereo, fltp, 33 kb/s
如果按照的正常的方式將它們合成:
http://github.com/JeffMony/JianYing/blob/main/output1.mp4
Duration: 00:00:09.99, start: 0.000000, bitrate: 5938 kb/sStream #0:0(und): Video: h264 (Constrained Baseline) (avc1 / 0x31637661), yuv420p, 720x1280, 5814 kb/s, 30.12 fps, 30 tbr, 10k tbn, 60 tbc (default)Metadata:handler_name : VideoHandlervendor_id : [0][0][0][0]Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, mono, fltp, 128 kb/s (default)Metadata:handler_name : SoundHandlervendor_id : [0][0][0][0]
這兒大家可以直接將例子下載下來看看,不好傳視訊和音訊,所以大家將就看吧。
輸入的視訊中的音訊取樣率是48000 Hz,輸入的音訊取樣率是44100 Hz,最後合成後視訊中音訊的取樣率是44100 Hz,看上去實現了重取樣了,但是輸出的視訊雜音非常嚴重,完全無法聽。
這兒就要多問一句了,為什麼呢?
6 問題剖析
我們這兒是將音訊統一按照44100 Hz重取樣,然後混音處理。從48000 Hz 重取樣至 44100 Hz,相同的buffer size的大小降低取樣率之後buffer size也會降低,而我們要做混音的時,需要兩個buffer都填充滿,這種情況下有一個音訊的buffer沒有填充滿。
就像下面的示意圖:
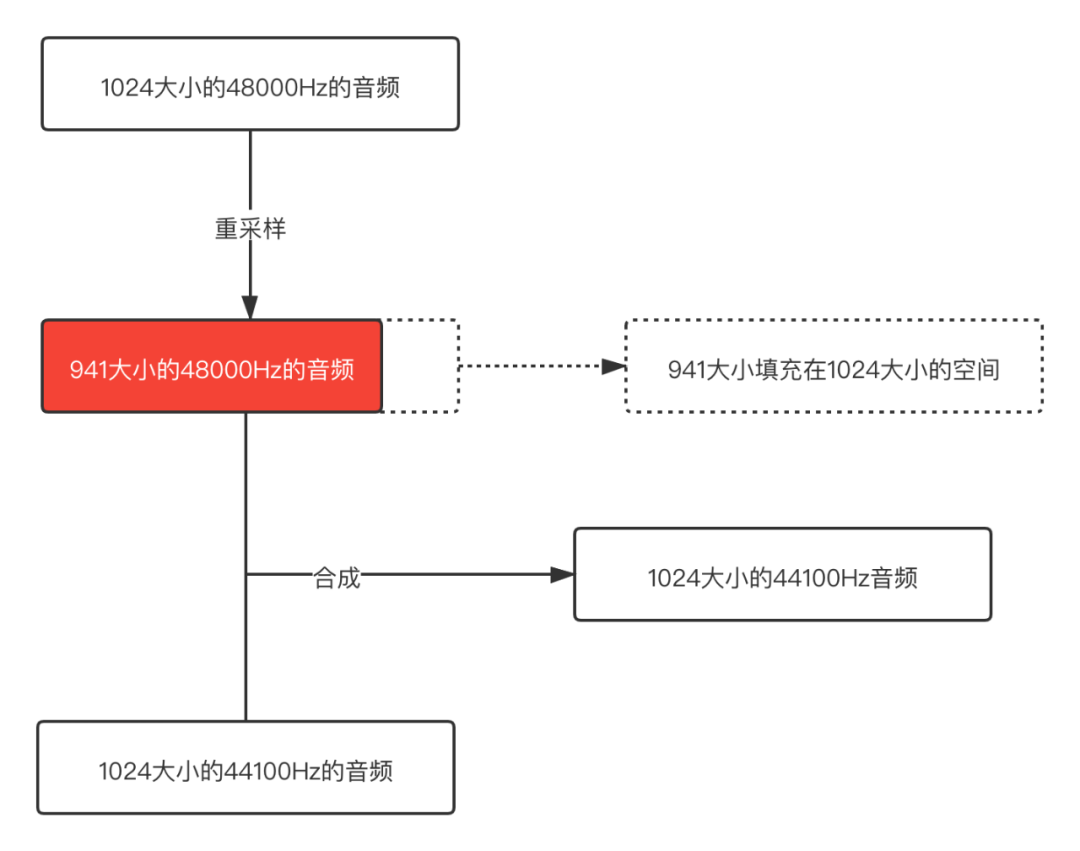
從這個示意圖可以很明顯的看出問題,48000 Hz重取樣之後的音訊buffer size已經變小了,但是用這個buffer和44100 Hz正常的buffer合併,那其中一個音訊後面就是一段空資料,所以合成之後肯定會出現雜音的。
既然知道了是什麼問題,那我們可以在合成之前將buffer填充滿,然後再混音處理,這樣就不會出現這個問題了。示意圖如下:
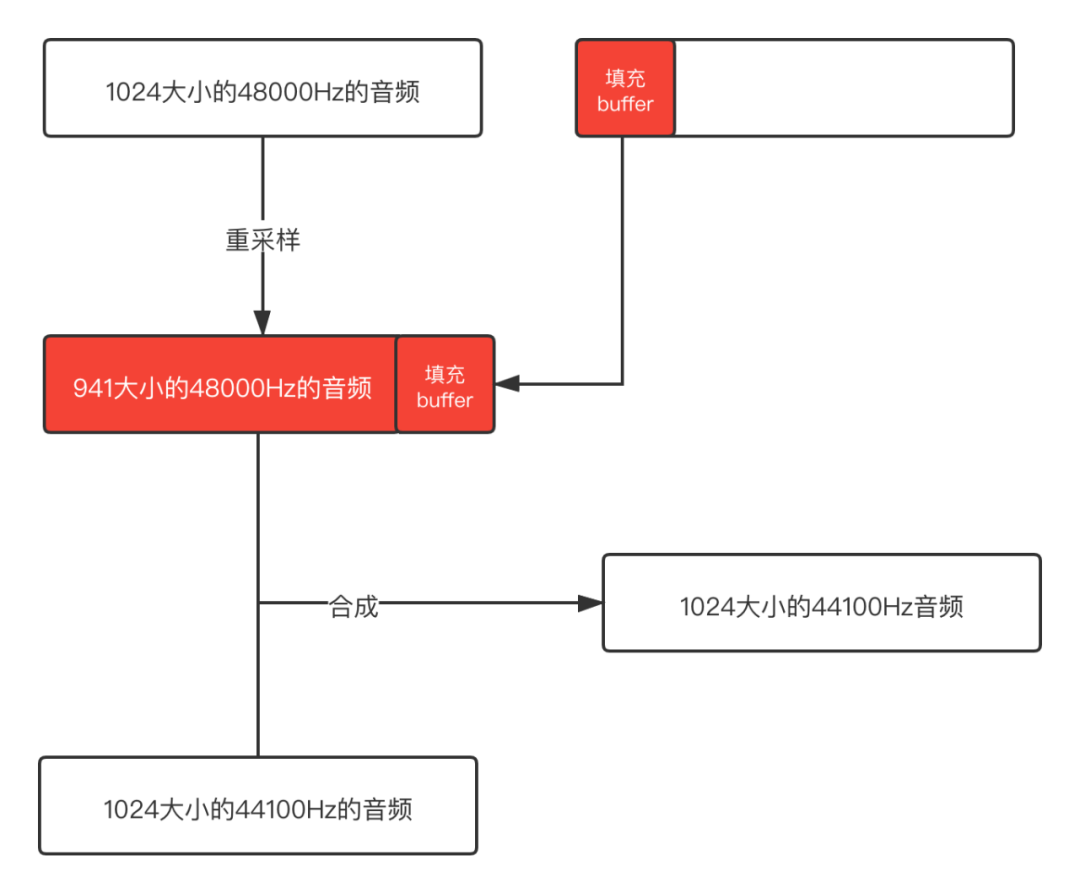
後面依次填充不滿的buffer,這樣得到的就是完整的buffer了,不會有冗餘的資料,混音之後輸出的音訊是正常的。
下面展示一下混音之後正常輸出的檔案:
http://github.com/JeffMony/JianYing/blob/main/output3.mp4
7 混音演算法介紹
聲音是由於物體的振動對周圍的空氣產生壓力而傳播的一種壓力波,轉成電訊號後經過抽樣,量化,仍然是連續平滑的波形訊號,量化後的波形訊號的頻率與聲音的頻率對應,振幅與聲音的音量對應,量化的語音訊號的疊加等價於空氣中聲波的疊加,所以當取樣率一致時,混音可以實現為將各對應訊號的取樣資料線性疊加。反應到音訊資料上,也就是把同一個聲道的數值進行簡單的相加而問題的關鍵就是如何處理疊加後溢位問題。(通常的語音資料為16bit 容納的範圍是有限的 -32768 到 32767之間 所以單純的線性疊加是有可能出現溢位問題的。直接截斷會產生噪音。所以需要平滑過度)
所以在進行混音之前要先保證需要混合的音訊 取樣率、通道數、取樣精度一樣。
7.1 平均法
將每一路的語音線性相加,再除以通道數,該方法雖然不會引入噪聲,但是隨著通道數成員的增多,各路語音的衰減將愈加嚴重。具體體現在隨著通道數成員的增多,各路音量會逐步變小。
public static short[] mixRawAudioBytes(short[][] inputAudios) {int coloum = finalLength;//最終合成的音訊長度// 音軌疊加short[] realMixAudio = new short[coloum];int mixVal;for (int trackOffset = 0; trackOffset < coloum; ++trackOffset) {mixVal = (inputAudios[0][trackOffset]+inputAudios[1][trackOffset])/2;realMixAudio[trackOffset] = (short) (mixVal);}return realMixAudio;}
7.2 歸一化
全部乘個係數因子,使幅值歸一化,但是個人認為這個歸一化因子是不好確認的。
public static short[] mixRawAudioBytes(short[][] inputAudios) {int coloum = finalLength;//最終合成的音訊長度float f = divisor;//歸一化因子// 音軌疊加short[] realMixAudio = new short[coloum];float mixVal;for (int trackOffset = 0; trackOffset < coloum; ++trackOffset) {mixVal = (inputAudios[0][trackOffset]+inputAudios[1][trackOffset])*f;realMixAudio[trackOffset] = (short) (mixVal);}return realMixAudio;}
7.3 改進後的歸一化
使用可變的衰減因子對語音進行衰減,該衰減因子代表了語音的權重,該衰減因子隨著資料的變化而變化,當資料溢位時,則相應的使衰減因子變小,使後續的資料在衰減後處於臨界值以內,沒有溢位時,讓衰減因子慢慢增大,使資料變化相對平滑。
public static short[] mixRawAudioBytes(short[][] inputAudios) {int coloum = finalLength;//最終合成的音訊長度float f = 1;//衰減因子 初始值為1//混音溢位邊界int MAX = 32767;int MIN = -32768;// 音軌疊加short[] realMixAudio = new short[coloum];float mixVal;for (int trackOffset = 0; trackOffset < coloum; ++trackOffset) {mixVal = (inputAudios[0][trackOffset]+inputAudios[1][trackOffset])*f;if (mixVal>MAX){f = MAX/mixVal;mixVal = MAX;}if (mixVal<MIN){f = MIN/mixVal;mixVal = MIN;}if (f < 1){//SETPSIZE為f的變化步長,通常的取值為(1-f)/VALUE,此處取SETPSIZE 為 32 VALUE值可以取 8, 16, 32,64,128.f += (1 - f) / 32;}realMixAudio[trackOffset] = (short) (mixVal);}return realMixAudio;}
7.4 newlc演算法
if A < 0 && B < 0
Y = A + B - (A * B / (-(2 pow(n-1) -1)))
else
Y = A + B - (A * B / (2 pow(n-1))
void Mix(char sourseFile[10][SIZE_AUDIO_FRAME],int number,char *objectFile){//歸一化混音int const MAX=32767;int const MIN=-32768;double f=1;int output;int i = 0,j = 0;for (i=0;i<SIZE_AUDIO_FRAME/2;i++){int temp=0;for (j=0;j<number;j++){temp+=*(short*)(sourseFile[j]+i*2);}output=(int)(temp*f);if (output>MAX){f=(double)MAX/(double)(output);output=MAX;}if (output<MIN){f=(double)MIN/(double)(output);output=MIN;}if (f<1){f+=((double)1-f)/(double)32;}*(short*)(objectFile+i*2)=(short)output;}}
參考文章:
http://www.git2get.com/av/104606126.html
http://blog.csdn.net/dxpqxb/article/details/78329403
本文分享自微信公眾號 - 音視訊開發進階(glumes_blog)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- 音視訊進階教程-實現直播間的自定義視訊渲染
- 音視訊開發進階|第六講:色彩和色彩空間·上篇
- H264 視訊檔案如何縮放解析度?
- 星球專享 | 播放器 FFmpeg 依賴庫的配置
- 乾貨收藏 || Vulkan Game Engine 視訊教程
- HDR技術趨勢淺析
- WebRTC 實現 Android 傳屏 demo
- 技術群裡如何提問才能獲得更高的回覆率呢?
- 【建議收藏】30 分鐘入門 Vulkan (中文翻譯版)
- 淺談音視訊自動化測試
- 揭祕版權保護下的視訊隱形水印演算法(下篇)
- 如何用研發效能搞垮一個團隊
- 如何實現H.264的實時傳輸?
- 短視訊中解決音視訊混音出現雜音的問題
- 位元組跳動招聘:30-60k 不限工作經驗!什麼崗位這麼香?
- 進擊的斜槓程式設計師 | 音視訊技術內容變現
- 面試官:RecyclerView佈局動畫原理了解嗎?
- 音視訊開發進階-學習筆記3-使用LAME編碼mp3檔案
- 音視訊開發進階-學習筆記2-LAME交叉編譯
- 網際網路寒冬之下,Android開發的港灣:音視訊進階學習