t-io:被神指引的開源商業之路
【編者按】除了SaaS、open-core等典型的開源商業模式之外,企業還有什麼其它方式能夠依賴開源專案生存下來,並且活得很好?多年前,t-io 在早期階段開創了國內開源專案程式碼開源、文件收費的先河。雖然為人所不理解,但這種獲取收入的方式在《大教堂與集中》一書中被稱為“附屬物策略”,如其所言:“在這種模型下,人們出售開源軟體的附屬物,如低端市場上的杯子或T恤,高階市場上的專業書籍或者文章。”
作者:譚耀武
如果三流程式設計師的作品能被大家喜歡且使用(後文簡稱喜用),那必然是巧合,如果一直被喜用,那就是一直巧合,當巧合次數到了指定閾值,量變產生質變,巧合就變成了神奇(神創造的奇蹟)。今天我就細數一下t-io是如何被神指引到創業之路的,在路上又經歷了哪些奇蹟。
01 教員鐵令下誕生t-io
2011年的時候,我接手一個網管系統,舊系統用的是bio,執行緒數量多且不可控。所以收到的命令是用nio對系統進行重寫(是重寫,不是重構),而且不允許使用當時使用面較廣的另一個網路程式設計框架。
現在回想這個決定,這不就是讓我弄個t-io出來麼?(t-io早年叫talent-nio。)每想到這,就莫名佩服當時的教員,早在2011年就知道我要弄個t-io出來,藉著網管專案提前成就我。
好了,這就是t-io還是一隻小蝌蚪時的情況,和其他成年人一樣,稀、鬆、平、常。
時間來到2017年,t-io躲在西牛賀州猥瑣發育了6年,師父覺得這毛孩子該下山闖蕩闖蕩了,於是在開源中國發文公示《talent-aio 1.0.0 正式版,千呼萬喚始出來》,文筆雖羞嫩醜陋,但在開源中國滔滔洪流帶動下,此文竟奇蹟般激起千層波浪,引無數猿友折腰留言。
至此t-io在開源中國的圈子逐漸名就,從流量的使用者轉變成流量的創造者。
02 首次化緣之文件付費
在長達一年多的時間裡,t-io是沒有文件的。那段日子,喜愛t-io的工程師們,只能通過幾個demo去掌握t-io。即使在這樣艱辛的條件下,也沒能阻止t-io的流行。所以有朋友調侃t-io說:“文件不行,demo來湊,一湊傾城,二湊傾國,三湊傾天下眾生”,這也間接說明了t-io的易用、健壯。
但是沒文件的開源產品,總感覺缺點味道,在收集到使用者渴望文件的心聲後,開始編寫文件。
編寫文件前,作者先考察了各大知名開源產品的文件體驗,決定自主設計一個文件編輯、文件閱讀的平臺。
文件編寫平臺做完後,開始正式編寫t-io文件,一個多月的熬夜換來了t-io文件正式上線。
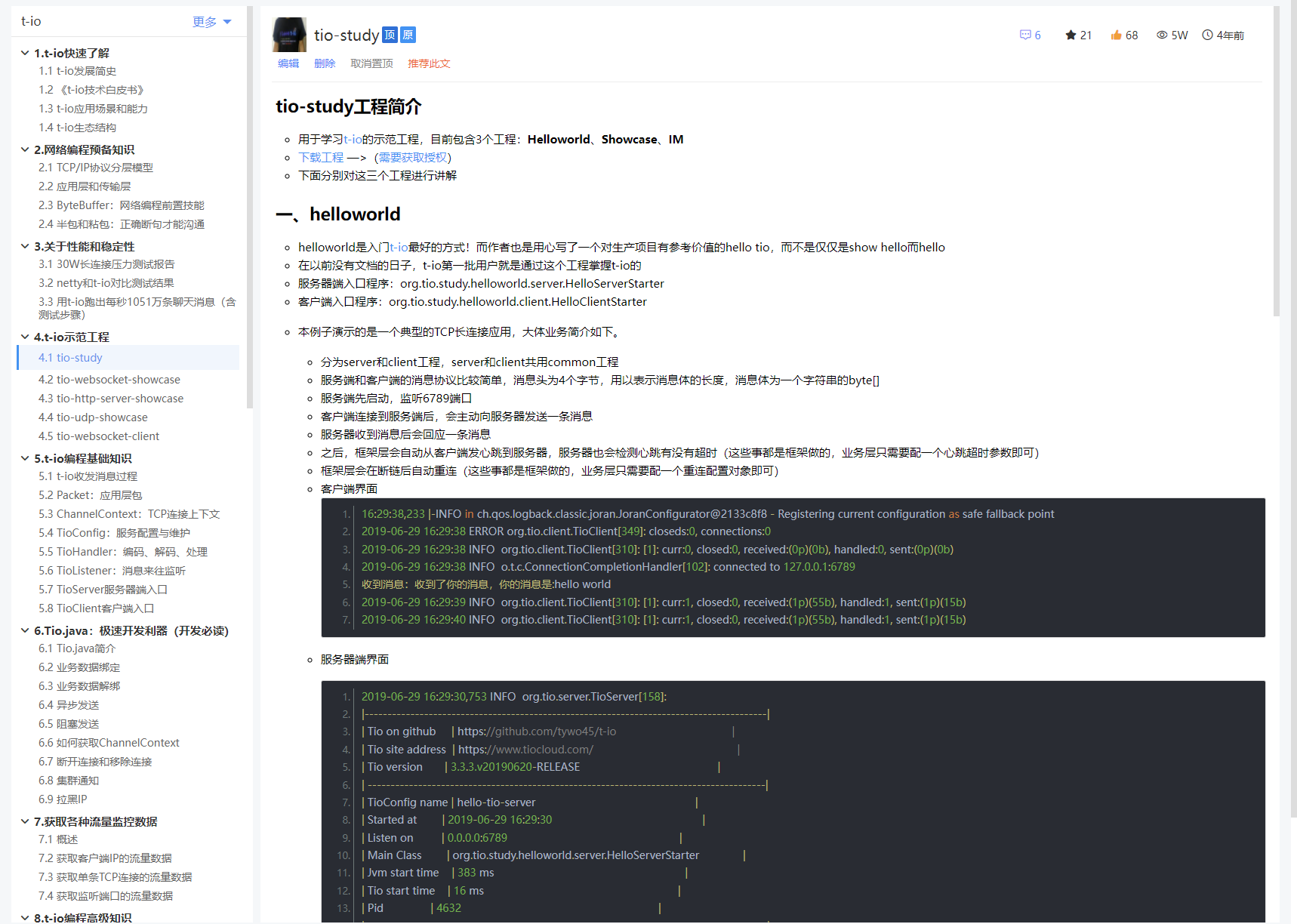
t-io文件
本應是歡呼雀躍的日子,但卻是幾家歡喜幾家愁——因為文件是付費的。眾人驚呼:“t-io作者不按常理出牌啊,哪有文件收費的開源產品”。網路對t-io的口誅筆伐達到巔峰,這很神奇,作者至今未能理解這個你情我願、非強買強賣的行為,為何引來這樣山呼海嘯般的吐槽和謾罵。
一半是冰,另一半就是火。事實證明,許多優秀的工程師願意對知識進行付費,還有不少工程師願意無償捐助t-io,更有許多使用者願意站出來為t-io發聲。
是非自有公論,功過後人評說。t-io可能是開創了開源產品文件付費的先河,是非難辨的時候,就只能交給時間了。
03 鬼使神差著了創業之道
t-io創業之路始於一條午夜朋友圈,也許神仙們都喜歡在午夜檢視人間的朋友圈吧。在發完這條圈圈3分鐘後,接到了一個來自魔都的鈴聲:“去掉一切對t-io不利的條款,立即投資t-io”。因為失眠發了個朋友圈,神就給我一頂創業的緊箍咒?既然上了創業這條取經的路,那就做個快樂的孫猴子吧。

發者無意,看者有心,一條朋友圈引發的創業大案
2019年12月20日,杭州鈦特雲科技有限公司在許多前輩的幫助下正式成立。在此特別感謝牛吧雲播創始人張晶總一直給我打氣加油,免費提供辦公場地以及創業需要的其他基礎知識。

毛孩子下山了,但對師父的想念一刻也沒停過,何以解憂,唯有談聊。創業後的第一個商業產品便是譚聊,有了這個工具,不管身在何處,都能和想念的人且談且聊。
產品雖好,但擁有同樣功能的產品早已氾濫成災(同功不同質,但許多客戶識別不了質量),如何差異化化緣換飯錢,是件費猴毛的事,對此我們採取的策略是毀天滅地的提供全部原始碼,讓客戶無後顧之憂,許多朋友覺得我們是在飲鴆止渴、竭澤而漁。
其實不然。t-io的開源經歷告訴我,網路程式設計這塊蛋糕足夠大,定製需求足夠多,用一款產品去適配所有產品,幾無可能,而我們丟擲譚聊這塊石頭,引來他山之玉,再用t-io強大無比的屠龍能力將這些玉一一收為己有,這便是商道中的最高境界:利他之後自然利己。
回頭看,“竭澤而漁”的策略讓我們贏得了現金流,公司艱難活了下來,活下來才有希望!
其實在2020年11月6號,公司內部開會決定在未來15天內解散。誰曾想,當天晚上我發了一條關於譚聊的朋友圈,隨即有客戶在該條朋友圈留言諮詢譚聊的事,鬼使神差地讓公司獲得了一個至關重要的訂單,讓公司沒有過早夭折。當你想做一件事,連朋友圈都會幫你。
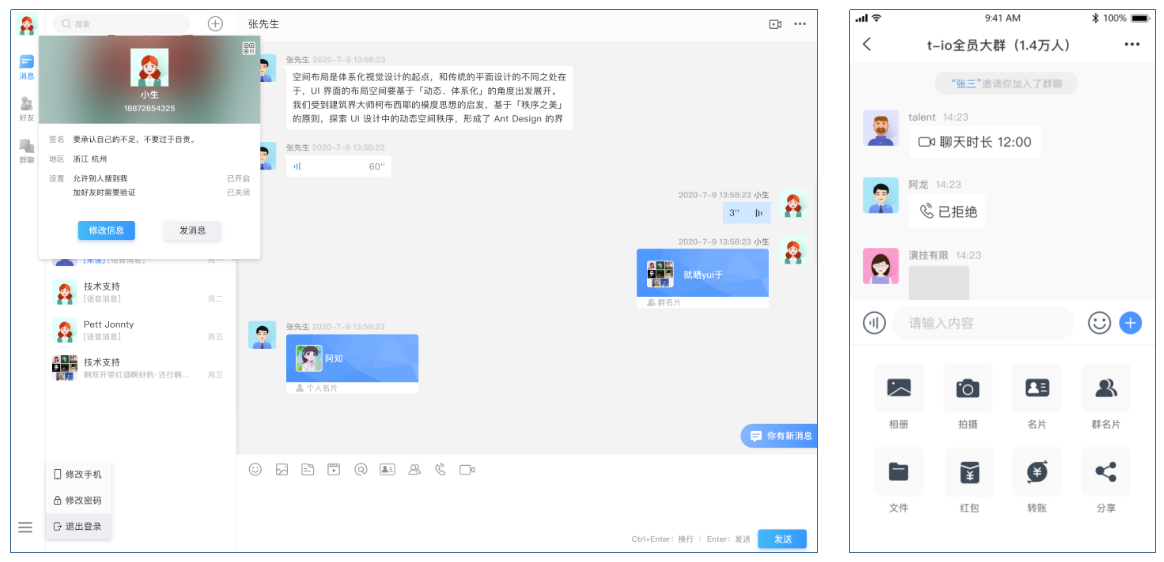
譚聊介面,左為Web版介面,右為App介面
04 無心插柳的叢集
公司差點夭折的現實讓掌舵人有了嚴重的危機意識,進軍更廣闊的IOT領域被提上日程,而在IOT領域盈利,估計要等3年。艱難的過程已經註定,那就先把IOT領域必備的叢集能力搞起來,這樣,就算公司沒撐過3年,起碼積累了令人豔羨的叢集產品。
一念魔鬼、一念天使,公司就是在這樣“絕望”的情況下研發出了tio-cluster(t-io叢集)。
研發叢集的時候,從未想過通過叢集去盈利,因為立項之初它就是個IOT必備基石而已,IOT不出來,盈利沒可能。
很意外,也很幸運,為了小試牛刀,公司將叢集用在了譚聊身上。這個純技術思維的天才想法,起初僅僅是為了展示t-io和譚聊的強大能力,可後來的市場告訴所有人,IM的叢集到現在仍是稀罕物,一個電信公司拋來的叢集訂單讓公司贏得了足夠支撐3年的現金流。
真是有心栽花花嬌情,無心插柳柳成蔭。
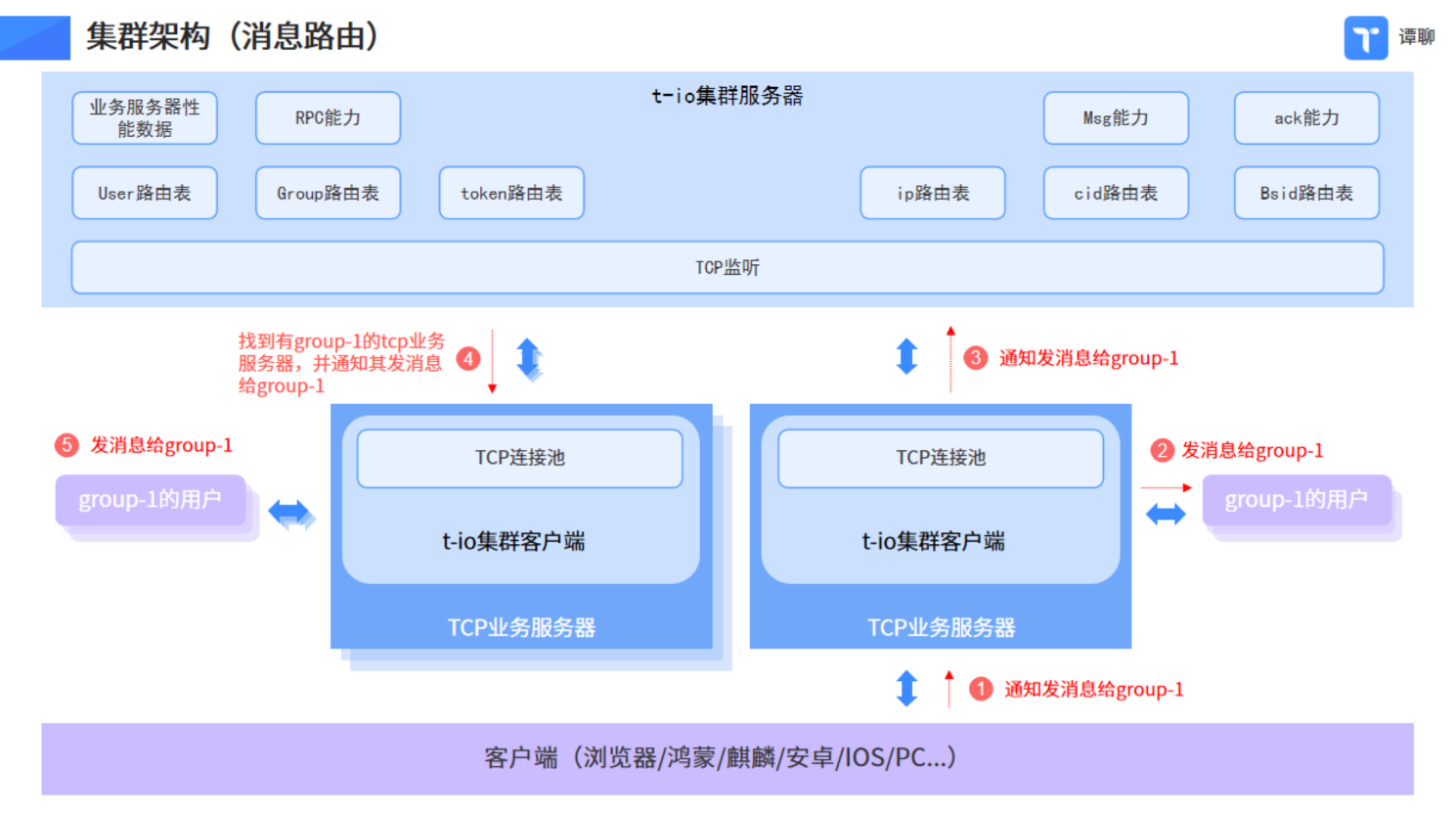
t-io叢集之訊息路由
受益於t-io良好的口碑和流量,譚聊和叢集獲得了出人意料的訂單量,併產生了令97%初創科技公司豔羨的銷售額。
深圳一位好友敏銳地察覺到了什麼,把公司引薦給ZOOM初始成員之一,雙方在一個小包廂裡回憶ZOOM的歷史過往,暢想t-io的未來巨集圖,把飲暢談間無條件地投資了t-io。

蘇州之行,暢談間敲定天使投資
有了情懷天使的加入,公司更加堅定地走“做難做但有意義有技術的產品”路線。
05 TiOMQ Client初長成
花開兩朵,各表一枝。中間穿插講了一下情懷天使的故事,我們再回到IOT領域,畢竟天使投的是未來,而我們的未來就是IOT。
工欲善其事,必先利其器。要在IOT領域有所發揮,好用易用的測試工具少不了,TiOMQ Client應運而生。有興趣的朋友可以試玩體驗:
http://122.112.214.244:8088/tiomq/#/mqtt
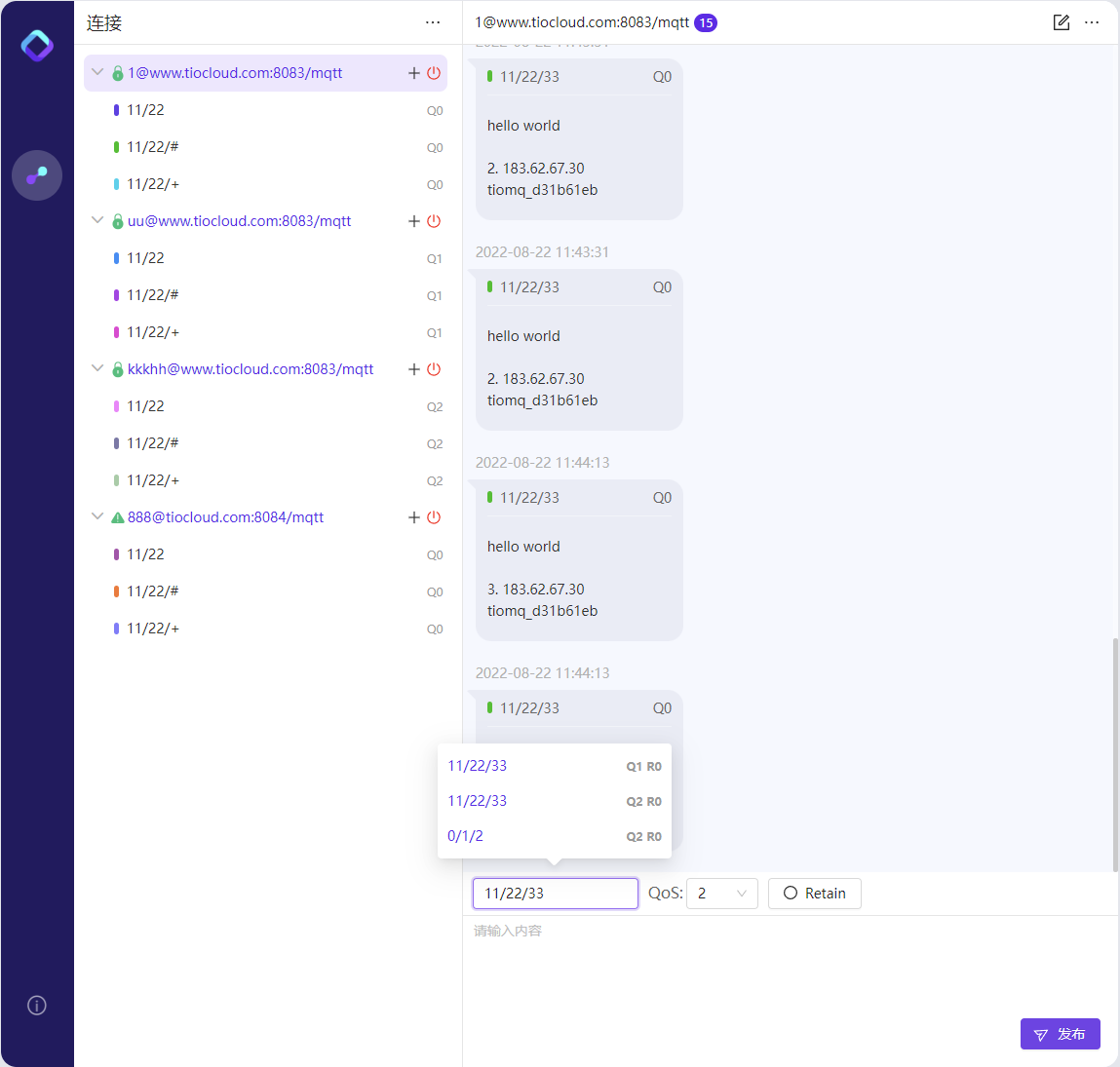
TiOMQ Client介面
心細的朋友可能留意到,這個Client工具,連的伺服器是指向www.tiocloud.com的,沒錯,我們就是用自己的Mqtt Client連線自己的Mqtt Broker,而且是擁有強大叢集能力的Mqtt Broker。
IOT基石Mqtt,最核心部分我們已經研發完成,後面就是參與到某個垂直領域,進行進一步深耕。人無遠慮,必有近憂,此時我們已經瞄上了一個新的目標,那就是quic,我們拭目以待吧。
小結:
創業是一條沒有路的路,每個十字路口,總會有一些湊巧的人和事去指引你繼續往前走,而您要做的就是堅持去做有意義能讓公司持續活下去的事。
作者簡介:
譚耀武,杭州鈦特雲科技有限公司創始人,網路程式設計框架t-io執筆人,曾任牛吧雲播CTO。四流程式設計師、三流創業者、二流傳銷佬、一流裝逼師。以前的夢想讓公司活下去,現在的夢想是成就投資人的夢想。

本文來源於開源精選集《開源觀止》第 4 期,更多精彩內容,請點選下載:
http://oscimg.oschina.net/public_shard/opensource-guanzhi-20220915.pdf
- 從雲原生到 Serverless,我們對資料庫還有哪些想象?
- 2022 年大前端總結來了,我們能抓住什麼?
- 15 大分論壇不容錯過,GOTC 2023 即將拉開帷幕!
- WebGPU 尚未釋出,Orillusion 提前公測,我們先和創始人聊了聊
- 多樣性算力、全場景支援是作業系統剛性需求
- Thoughtworks 技術專家 Phodal:2022 年前端趨勢總結
- 雲原生業界生態空前活躍,要落地仍然考驗創造力
- eBPF為雲原生應用可觀測性開啟更多可能性
- 白鯨開源代立冬:資料技術快速更迭, DataOps 應運而生
- 下一代開源作業系統 因雲而與眾不同
- 爭執不斷,但低程式碼的發展已經成為趨勢
- 閘道器基礎設施或邁出走向標準化的關鍵一步
- 前後端開發的邊界越來越模糊
- 為什麼說 AI 標準化和規模化應用來臨?
- 平臺工程理念崛起
- 雲原生成為資料庫產品的重要演進方向
- 開源資料庫賽道為何吸金?
- 資料湖與 LakeHouse 依然炙手可熱
- 作業系統根社群或能應對停服難題
- 統信王耀華:把握開源作業系統供應鏈安全