一文搞懂hadoop中的使用者
又有一段時間沒有更新了,最近忙著搬磚的同時,也填了一些坑,其中不少坑是有關聯的,甚至其中有一個配置項接連引發了兩三個問題,後續打算逐個總結輸出,這裡先進行一些鋪墊~
【hadoop的使用者概述】
在hadoop中,客戶端不管是向hdfs請求上傳下載檔案,還是向yarn提交任務、下載檢視任務的日誌,都會指定一個使用者來進行操作。
在開啟了ACL鑑權機制後,hdfs的namenode,yarn的resourcemanager還會根據請求的使用者資訊來進行許可權校驗,檢視該使用者是否有許可權進行對應的操作。
那麼,客戶端中的使用者資訊是如何指定的,又是如何在rpc通訊中傳遞給服務端的,本文就來聊聊hadoop中使用者相關的內容。
【如何指定使用者】
客戶端中使用者資訊的指定可分為兩種場景,不啟用kerberos認證的場景和啟用kerberos認證的場景。
1. 非kerberos認證場景
在不啟用kerberos認證的場景中,客戶端依次通過環境變數、配置引數以及當前執行程式的系統使用者來獲取用於hadoop操作的使用者資訊。
-
環境變數(HADOOP_USER_NAME)
-
配置引數屬性(-DHADOOP_USER_NAME=xxx)
-
當前執行程式的系統使用者
一個示例如下所示:
[[email protected] /]# cat test.sh
#!/bin/bash
# "use -D"
export HADOOP_CLIENT_OPTS=-DHADOOP_USER_NAME=bigdata
hdfs dfs -mkdir /test1
# "use env"
export HADOOP_USER_NAME=hncscwc
hdfs dfs -mkdir /test2
unset HADOOP_USER_NAME
# "use system user"
unset HADOOP_CLIENT_OPTS
hdfs dfs -mkdir /test3
# "list directory"
hdfs dfs -ls /
[[email protected] /]# sh test.sh
Found 6 items
drwxr-xr-x - root supergroup 0 2022-04-07 15:44 /benchmarks
drwxr-xr-x - root supergroup 0 2022-04-07 15:44 /history
drwxr-xr-x - bigdata supergroup 0 2022-04-21 14:16 /test1
drwxr-xr-x - hncscwc supergroup 0 2022-04-21 14:16 /test2
drwxr-xr-x - root supergroup 0 2022-04-21 14:16 /test3
drwx------ - root supergroup 0 2022-04-07 15:44 /tmp
注1:由於使用了hdfs自帶的命令,因此是通過HADOOP_CLIENT_OPTS環境變數進行-DHADOOP_USER_NAME引數的設定(可檢視hdfs指令碼命令的實現)
注2:第二個測試時,未清除前一個測試設定的引數,即此時同時指定了環境變數和啟動引數,但環境變數的優先順序更高。
注3:最後一個測試前,先清除了第一次建立目錄時匯入的環境變數,即此時環境變數與啟動引數均未指定,因此採用當前系統使用者作為hdfs客戶端的操作使用者。
2. kerberos場景
在啟用了kerberos認證的情況下,又分為兩種情況獲取使用者資訊,一種是從系統快取的票據(ticket)中獲取使用者資訊;一種是指定principal以及keytab檔案,然後呼叫hadoop提供的介面完成kerberos認證,並從中得到使用者資訊。
從ticket中獲取:
多數情況下, 我們會先通過kinit向kdc完成認證並獲取票據,然後再進行相關的操作。此時程式不需要有額外的設定,會自動從系統快取的票據中獲取到principal,並從中解析出使用者名稱,以此作為hadoop操作的使用者。
例如:
[[email protected] ~]# kinit hncscwc
Password for [email protected]:
[[email protected] ~]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: [email protected]
Valid starting Expires Service principal
04/22/2022 10:26:48 04/23/2022 10:26:48 krbtgt/[email protected]
renew until 04/22/2022 10:26:48
[[email protected] ~]# hdfs dfs -mkdir /user/hncscwc/test1
[[email protected] ~]# hdfs dfs -ls /user/hncscwc
Found 1 items
drwxr-xr-x - hncscwc supergroup 0 2022-04-22 10:29 /user/hncscwc/test1
指定principal與keytab並呼叫對應介面:
這也是一種常用的手段,通過指定principal,以及對應的keytab檔案,隨後呼叫hadoop提供的介面完成kerberos認證,並從中獲取到hadoop操作的使用者資訊,然後使用該使用者資訊進行rpc通訊。
呼叫流程的大概步驟如下所示:
// 使用principal, keytab登入
UserGroupInformation.loginUserFromKeytab(principal, keytab);
// 獲取ugi類例項
UserGroupInformation ugi = UserGroupInformation.getCurrentUser();
// 執行具體的rpc請求
ugi.doAs(
@Override
public void run() throws Exceptions {
FileSystem fs = FileSystem.get(conf);
FSDataOutputStream out = fs.create(new Path(filePath), true);
Date date = new Date();
out.write(date.toString().getBytes());
out.flush();
out.close();
return ;
}
);
注:需要進行互動的操作都需要放到doAs中完成。
【內部實現】
1. 重要的實現類
在具體的實現中,使用者資訊對應的類為UserGroupInformation。該類又通過JAAS(Java Authentication and Autorization Service)結合,實現了使用者資訊的獲取與儲存。
在該類的內部通過jaas的subject作為成員變數儲存使用者的資訊;根據不同的認證方式(是否啟用kerberos認證),呼叫jaas的不同介面實現獲取對應的使用者資訊。
2. rpc通訊過程中使用者資訊的傳遞
在rpc的互動過程中,使用者資訊會作為協議的一部分傳遞給服務端。
protobuffer協議中使用者資訊的定義:
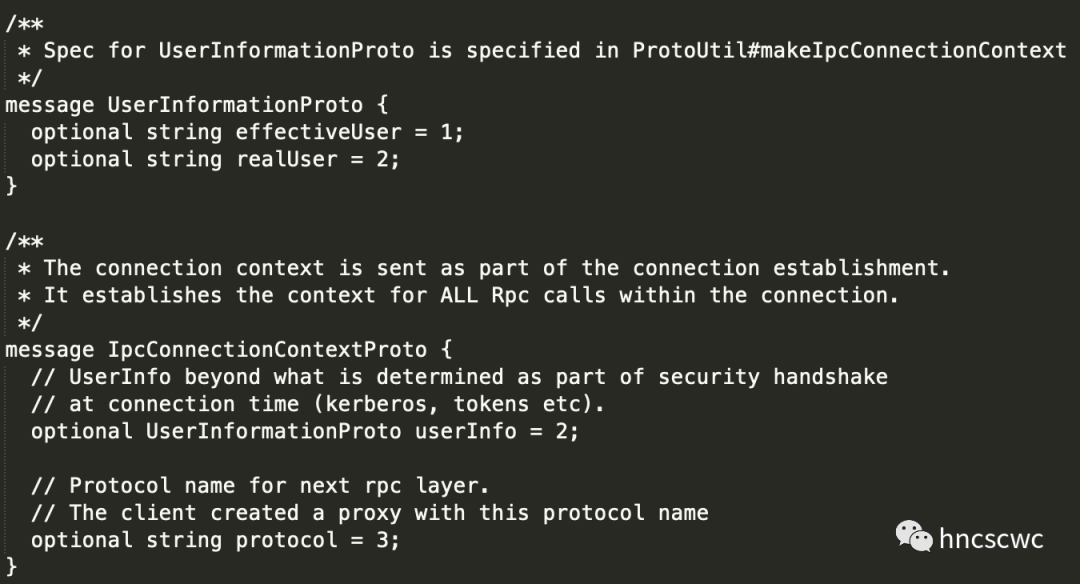
客戶端中對應的使用者資訊構造邏輯:
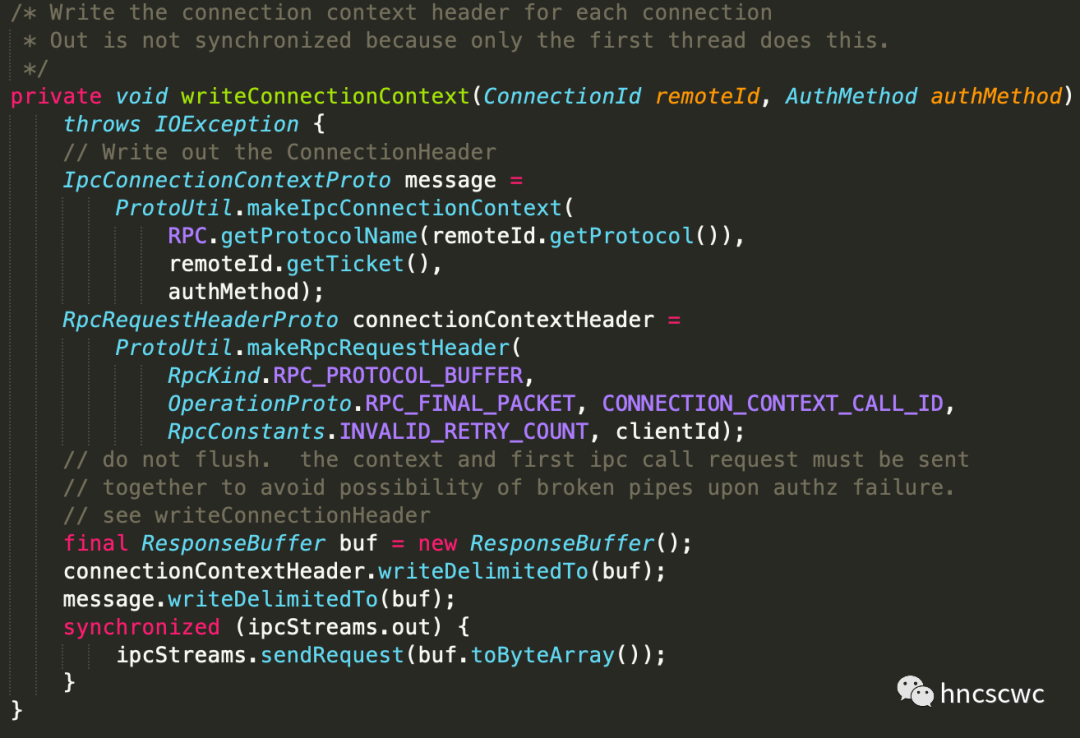
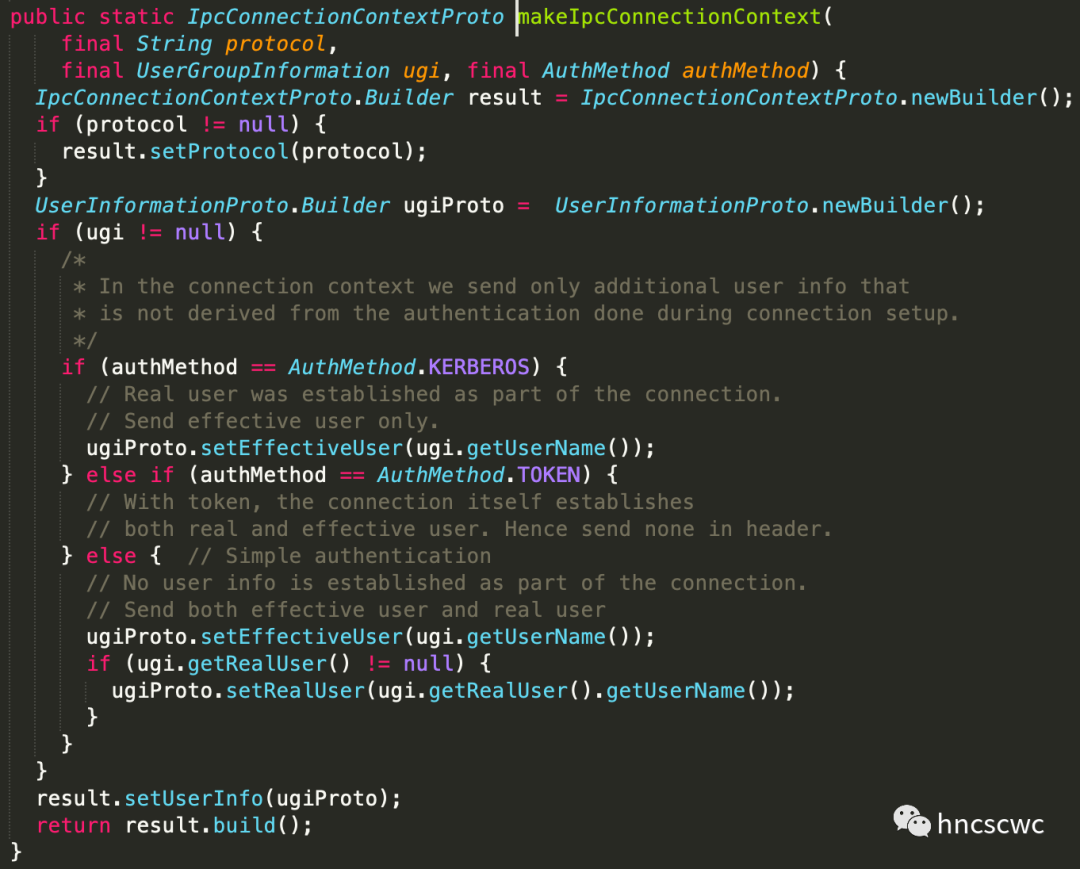
同時,在服務端一側,會先從請求中解析出使用者資訊,然後構造對應的UserGroupInformation類例項,並將該資訊作為請求的一部分(Call例項物件的成員),向上傳遞給後續的handler處理。
【使用者代理】
考慮一種場景,在開啟kerberos認證後,每個服務啟動後都會以各自的principal向kdc登入完成認證,此後就以該principal對應的票據資訊向其他服務進行訪問。
如果某個服務支援不同使用者登入,然後根據使用者請求完成不同的邏輯業務處理,例如操作hdfs。此時,這個服務可能需要為每個使用者維護一個有效的票據,或者持有該使用者的使用者名稱密碼資訊,或者principal與keytab資訊,確保通過kerberos認證的同時,可以以該使用者的身份進行後續的操作。
這顯然不是一種好的做法,並且還需要動態維護使用者資訊,例如使用者的新增等。
一個實際的場景,不同的使用者各自通過jdbc連線到hiveserver2,進行相關操作,而hiveserver2最終需要以不同的使用者到hdfs上進行檔案的操作。
為了友好地解決這個問題,代理使用者(proxyUser)就應運而生。
注:在開啟kerberos認證的場景下,一個程序中同時維持多個使用者的principal會存在bug,官方的jira單中,有進行相關的討論,但最終給出的方案仍舊是試用代理使用者的方式。
代理使用者是個什麼概念?
代理使用者就是以某個使用者完成kerberos的認證工作後,以該使用者對應的principal與其他服務進行通訊,同時為其他使用者代理提供hadoop的相關訪問操作。
代理使用者的具體配置方法是新增如下配置項:
<property>
<name>hadoop.proxyuser.${SuperUserName}.hosts</name>
<value>${HostLists}</value>
</property>
<property>
<name>hadoop.proxyuser.${SuperUserName}.groups</name>
<value>${Groups}</value>
</property>
<!-- 說明 -->
<!-- ${SuperUserName} 為具有代理功能的使用者,通常也是超級使用者, 這意味著並不是每個使用者都能成為代理使用者 -->
<!-- ${HostLists} 為代理使用者能正確完成代理功能的主機地址列表 -->
<!-- ${Groups} 為代理使用者能代理的使用者組, 也就是能為那些使用者組中的使用者進行代理 -->
<!-- 示例 -->
<!-- hadoop使用者為代理使用者, 可以為任意使用者進行代理, 但僅在hive-server.hncscwc主機地址上能夠正確完成代理工作 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>hive-server2.hncscwc</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
代理使用者的內部實現:
在UserGroupInformation類中,提供了建立代理使用者的介面,該介面需要傳入代理使用者的使用者名稱、以及真實使用者(被代理使用者)的使用者資訊。
而前面提到了使用者資訊作為rpc協議的一部分,從protobuffer的定義中可以看到,使用者資訊有兩個值:一個是有效使用者(也就是代理使用者的使用者名稱),另一個是真實使用者(也就是被代理使用者的使用者名稱),兩者一併傳遞給了服務端。
在服務端最終使用代理使用者完成認證工作,而使用真實使用者資訊完成鑑權工作,這樣,請求可以被正確呼叫的同時,能確保按照真實使用者的資訊進行鑑權操作。
有了代理使用者後,只需要以代理使用者完成kerberos認證,後續以該使用者的principal與namenode或resourcemanager進行互動,同時又確保可以按真實使用者的資訊進行許可權控制,而不至於出現許可權放大或縮小的情況。
【總結】
小結一下,本文講述了hadoop中的使用者資訊,包括客戶端在不同認證情況下如何指定使用者,使用者資訊如何在rpc請求中傳遞給服務端。最後擴充套件講解了代理使用者的使用場景,如何配置,以及內部的大概實現邏輯。
好了,這就是本文的全部內容,如果覺得本文對您有幫助,請點贊轉發,也歡迎加我微信交流~
本文分享自微信公眾號 - hncscwc(gh_383bc7486c1a)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。