從hudi持久化檔案理解其核心概念
【概述】
這是hudi系列的第一篇文章,先從核心概念,儲存的檔案格式加深對概念的理解,後續再逐步對使用(spark/flink入hudi,hudi同步hive等)、原理(壓縮機制,索引,聚族等)展開分享~
【什麼是資料湖】
簡單來說,資料湖技術是計算引擎和底層儲存格式之間的一種資料組織格式,用來定義資料、元資料的組織方式,並實現以下的功能:
支援事務(ACID)
支援流批一體
支援schema演化和schema結束
支援多種底層資料儲存HDFS、OSS、S3
從實現上來說,基於分散式檔案系統之上,以傳統關係型資料庫的方式對外提供使用。
開源的資料湖實現有Hudi、IceBerg、Delta。
【hudi介紹】
Apache hudi代表Hadoop Upserts Deletes Incrementals。能夠使HDFS資料集在分鐘級的延時內支援變更,也支援下游系統對這個資料集的增量處理。
hudi資料集通過自定義的InputFormat相容當前hadoop生態系統,包括Hive、Presto、Trino、Spark、Flink,使得終端使用者可以無縫的對接。
Hudi會維護一個時間軸(這個是hudi的核心),在每次執行操作時(如寫入、刪除、壓縮等),均會帶有一個時間戳。通過時間軸,可以實現在僅查詢某個時間點之後成功提交的資料,或是僅查詢某個時間點之前的資料。這樣可以避免掃描更大的時間範圍,並非常高效地只消費更改過的檔案。
上面是一些理論上的介紹,簡單的使用,官網也有對應的例子,這裡就不再囉嗦,下面我們介紹下hudi的一些核心概念,hudi的持久化檔案及檔案格式。
【相關概念】
1. 表型別
hudi中表有兩種型別
MOR(Merge on Read)
在讀取時進行合併處理的表。通常而言,寫入時其資料以日誌形式寫入到行式儲存到檔案中,然後通過壓縮將行式儲存檔案轉為列式儲存檔案。讀取時,則可能需要將儲存在日誌檔案中的資料和儲存在列式檔案中的資料進行合併處理,得到使用者期望查詢的結果。
COW(Copy on Write)
在寫入的時候進行拷貝合併處理的表。每次寫入時,就完成資料的合併處理,並以列式儲存格式儲存,即沒有增量的日誌檔案。
兩者的一些對比
| 權衡 |
COW |
MOR |
| 資料延遲 |
更高 |
更低 |
| 更新代價(I/O) |
更高 |
更低 |
| parquet檔案大小 |
更小 |
更大 |
| 寫放大 |
更高 |
更低(取決於壓縮策略) |
2. 時間軸
hudi維護了在不同時間點中(instant time)在表上的所有(instant)操作的時間軸,這有助於提供表的即時檢視,同時還能有效的提供順序檢索資料。
instant由以下元件組成:
instant action:對資料集(表)的操作型別(動作)。
instant time:通常是一個時間戳,它按照操作開始時間的順序單調遞增。
state:當前的狀態
關鍵的操作型別包括:
commit
原子的將一批資料寫入資料集(表)中
cleans
清除資料集(表)中不再需要的老版本檔案
delta_commit
增量提交,表示將一批記錄原子的寫入MOR型別的表中,其中一些/所有資料可能僅被寫入增量日誌檔案中
compaction
通常而言,是將基於行式的日誌檔案移動更新到列式檔案中。
rollback
表明提交或增量提交不成功後的回滾,此時會刪除寫過程中產生的任意分割槽檔案。
savepoint
將某些檔案組標識為"已儲存",這樣在清理時不會進行刪除。在災備或資料恢復的場景中,有助於恢復到時間軸上的某個點。
任意給定的instant只能處於下面的其中一個狀態:
REQUESTED:指明一個動作已經被排程,但還未進行執行
INFLIGHT:指明一個動作正在被執行
COMPLETED:指明時間軸上的一個已完成的動作
狀態由requested->inflight->complete進行轉換。
3. 檢視
hudi支援三種類型的檢視:
讀優化檢視(Read Optimized Queries)
該檢視僅將最新檔案切片中的基本/列檔案暴露給查詢,並保證與非hudi列式資料集相比,具有相同的列式查詢效能。簡單而言,對於MOR表來說,僅讀取提交或壓縮後的列式儲存檔案,而不讀取增量提交的日誌檔案。
增量檢視(Incremental Queries)
對該檢視的查詢只能看到從某個提交/壓縮後寫入資料集的新資料。該檢視有效地提供了更改流,來支援增量資料。
實時檢視(Snapshot Queries)
在此檢視上的查詢將某個增量提交操作中資料集的最新快照。該檢視通過動態合併最新的基本檔案來提供近實時的資料集。
檢視型別和表的關係為:
| COW | MOR |
|
| 實時檢視 |
Y |
Y |
| 增量檢視 |
Y |
Y |
| 讀優化檢視 |
N |
Y |
【持久化檔案】
如果上面的概念還有些抽象,那麼來看看寫入hudi的資料是如何在hdfs上儲存的,再來理解前面提到的概念。
根據官網的示例,寫入表中的資料,其在hdfs上儲存的檔案,大概是這樣的:
[root@localhost ~] hdfs dfs -ls -R /user/hncscwc/hudiedemo
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux/.bootstrap
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux/.bootstrap/.fileids
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux/.bootstrap/.partitions
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.temp
-rw-r--r-- 3 root supergroup 2017 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/20211130143947.deltacommit
-rw-r--r-- 3 root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/20211130143947.deltacommit.inflight
-rw-r--r-- 3 root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/20211130143947.deltacommit.requested
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/archived
-rw-r--r-- 3 root supergroup 388 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/hoodie.properties
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/par1
-rw-r--r-- 3 root supergroup 960 2021-11-30 14:39 /user/hncscwc/hudidemo/par1/.f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0
-rw-r--r-- 3 root supergroup 93 2021-11-30 14:39 /user/hncscwc/hudidemo/par1/.hoodie_partition_metadata從hdfs的儲存檔案中可以看出幾點:
表的資料都儲存在指定配置目錄中(這裡為/user/hncscwc)
資料大概分為多個目錄儲存,其中.hoodie目錄下儲存元資料相關的資訊,本質上也就是時間軸對應的相關資料,以分割槽命名(這裡為par1)的目錄中則存放資料表在該分割槽中的具體資料。
先來看看.hoodie目錄下元資料相關的持久化檔案:這裡包括:
yyyyMMddHHmmss.deltacommit
記錄MOR表一次事務的執行結果,包括該事務對哪些分割槽的哪些資料(日誌)檔案進行了操作,對(日誌)檔案操作的型別(插入或更新),寫入的長度,表的元資料資訊等內容。檔案內容以json格式儲存。
檔案中幾個比較重要的欄位有:
partitionToWrtieStats
以分割槽為key,記錄每個分割槽的實際操作資訊,包括本次事務寫入的分割槽的ID、路徑、寫入/刪除/更新的記錄數、實際寫入的位元組長度等。
compacted
標記本次提交操作是否是壓縮操作觸發進行的
extraMetadata
最重要的是schema欄位,記錄了表的schema資訊。
另外需要注意:檔名中yyyyMMddHHmmss為本次事務提交的時間戳,其後綴為deltacommit,並且對應檔案內容非空,即表示該事務已經完成,相關的檔案還有yyyyMMddHHmmss.deltacommit.inflight 和 yyyyMMddHHmmss.deltacommit.requested。恰好對應前面概念中提到的instant對應的三種狀態。也就是說,通過將內容寫入到不同字尾的檔案中,來表示某個操作的當前狀態。
一個簡單示例為:
{
"partitionToWriteStats" : {
"par1" : [ {
"fileId" : "f9037b56-d84c-4b9a-87db-7cae41ab2505",
"path" : "par1/.f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0",
"prevCommit" : "20211130143947",
"numWrites" : 1,
"numDeletes" : 0,
"numUpdateWrites" : 0,
"numInserts" : 1,
"totalWriteBytes" : 960,
"totalWriteErrors" : 0,
"tempPath" : null,
"partitionPath" : "par1",
"totalLogRecords" : 0,
"totalLogFilesCompacted" : 0,
"totalLogSizeCompacted" : 0,
"totalUpdatedRecordsCompacted" : 0,
"totalLogBlocks" : 0,
"totalCorruptLogBlock" : 0,
"totalRollbackBlocks" : 0,
"fileSizeInBytes" : 960,
"minEventTime" : null,
"maxEventTime" : null,
"logVersion" : 1,
"logOffset" : 0,
"baseFile" : "",
"logFiles" : [ ".f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0" ]
} ]
},
"compacted" : false,
"extraMetadata" : {
"schema" : "{\"type\":\"record\",\"name\":\"record\",\"fields\":[{\"name\":\"uuid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"name\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"age\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ts\",\"type\":[\"null\",{\"type\":\"long\",\"logicalType\":\"timestamp-millis\"}],\"default\":null},{\"name\":\"partition\",\"type\":[\"null\",\"string\"],\"default\":null}]}"
},
"operationType" : null,
"totalCreateTime" : 0,
"totalUpsertTime" : 6446,
"totalRecordsDeleted" : 0,
"totalLogRecordsCompacted" : 0,
"fileIdAndRelativePaths" : {
"f9037b56-d84c-4b9a-87db-7cae41ab2505" : "par1/.f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0"
},
"writePartitionPaths" : [ "par1" ],
"totalScanTime" : 0,
"totalCompactedRecordsUpdated" : 0,
"totalLogFilesCompacted" : 0,
"totalLogFilesSize" : 0,
"minAndMaxEventTime" : {
"Optional.empty" : {
"val" : null,
"present" : false
}
}
}yyyyMMddHHmmss.commit
與deltacommit類似,不過通常是COW表一次事務的執行結果,或者是壓縮的執行結果。但檔案內容和deltacommit基本相同,檔案內容同樣採用json格式儲存。
hoodie.properties
該檔案記錄表的相關屬性,例如:
#Properties saved on Tue Nov 30 14:39:29 CST 2021
#Tue Nov 30 14:39:29 CST 2021
hoodie.compaction.payload.class=org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
hoodie.table.precombine.field=ts
hoodie.table.name=t1
hoodie.archivelog.folder=archived
hoodie.table.type=MERGE_ON_READ
hoodie.table.version=2
hoodie.table.partition.fields=partition
hoodie.timeline.layout.version=1hoodie.compaction.payload.class:資料插入/更新時對payload的處理類
hoodie.table.precombine.field:寫入之前進行預合併處理的欄位(資料)
hoodie.table.name:表的名稱
hoodie.archivelog.folder:表的歸檔路徑
hoodie.table.type:表的型別(MOR或COW)
hoodie.table.version:表的版本號(預設為2)
hoodie.table.partition.fields:表的分割槽欄位,每個分割槽按照分割槽欄位的值作為對應的目錄名稱,其資料就儲存分割槽的目錄中
hoodie.timeline.layout.version:時間軸佈局的版本(預設為1)
以上幾個檔案應該是最常見的,除此之外,你可能還會看到如下檔案:
yyyyMMddHHmmss.compaction.requested/inflight
壓縮操作的具體內容,包括壓縮操作的時間戳,以及對哪些分割槽下的哪些檔案進行壓縮合並。
壓縮操作的檔案內容是按一個標準avro格式儲存的,可以通過avro-tool工具將檔案內容轉換為json來檢視。例如:
{
"operations":{
"array":[
{
"baseInstantTime":{"string":"20220106084115"},
"deltaFilePaths":{
"array":[".97ae031c-189b-4ade-9044-781e840c7e01_20220106084115.log.1_2-4-0"]},
"dataFilePath":null,
"fileId":{"string":"97ae031c-189b-4ade-9044-781e840c7e01"},
"partitionPath":{"string":"par1"},
"metrics":{
"map":{
"TOTAL_LOG_FILES":1.0,
"TOTAL_IO_READ_MB":0.0,
"TOTAL_LOG_FILES_SIZE":3000.0,
"TOTAL_IO_WRITE_MB":120.0,
"TOTAL_IO_MB":120.0}
},
"bootstrapFilePath":null
}]},
"extraMetadata":null,
"version":{"int":2}
}yyyyMMddHHmmss.clean.requested/inflight
清理操作的內容,包括清理操作的時間戳,以及對哪些分割槽下的哪些檔案進行清理。
和壓縮操作的檔案一樣,檔案內容也是按標準的avro格式儲存的,也可以通過工具轉換成json來檢視。
yyyyMMddHHmmss.rollback.requested/inflight
記錄回滾操作的內容,同樣也是以標準avro格式進行儲存,例如:
{
"startRollbackTime":"20220112151350",
"timeTakenInMillis":331,
"totalFilesDeleted":0,
"commitsRollback":["20220112151328"],
"partitionMetadata":{
"par1":{
"partitionPath":"par1",
"successDeleteFiles":[],
"failedDeleteFiles":[],
"rollbackLogFiles":{"map":{}},
"writtenLogFiles":{"map":{}}
}
},
"version":{"int":1},
"instantsRollback":[{"commitTime":"20220112151328","action":"deltacommit"}]
}小結一下:對錶的每個操作,都記錄在以帶時間戳加不同的字尾的檔案中,其操作又按照狀態分別儲存在不同的檔案中,所有這些就對應了時間軸的實現。
再來看看錶分割槽中的持久化檔案,這裡主要包含幾種型別的檔案:
.hoodie_partition_metadata
記錄分割槽的元資料資訊,在寫入時,先寫.hoodie_partition_metadata_$partitionID,然後再進行重新命名。檔案中的內容如下所示:
#partition metadata
#Mon Dec 13 09:13:56 2021
commitTime=20211213091354
partitionDepth=1其中commitTime為寫入操作對應的提交時間,partitionDepth為相對錶的根目錄(上面提到的/user/hncscwc/hudidemo)的層級深度。在進行增量檢視、快照檢視查詢時,通常會直接傳遞分割槽目錄對應的路徑,因此需要從分割槽路徑中讀取該檔案,拿到層級深度,進而定位表的根目錄,從而得到表的元資料資訊。
xx.log.xx
MOR表操作的日誌資料,類似於mysql的binlog檔案。
檔案命名有兩種形式:
不帶writeToken:檔名為 $FileID_$Instant.log.$Version
帶writeToken:檔名為 $FileID_$Instant.log.$Version_$WriteToken
其中
$FileID為36位元組的UUID,$Instant為操作提交的時間戳,$Version為日誌版本資訊,預設從1開始,寫入同一個檔案時,版本號會遞增。
$WriteToken也有固定格式,為$Partition_$StageID_$AttemptID。
注意:檔案前會有個".",即以隱藏檔案的方式儲存,另外,帶token是允許多程序併發寫入,防止寫同一個檔案引起錯亂。
檔案的具體格式為:由一個或多個提交記錄組成,每個記錄都是一個類avro的行式儲存格式的資料。
一個記錄表示一次事務對錶的寫操作記錄(包括插入、刪除、更新),多個事務會append追加寫入同一個檔案中,以減少不必要的檔案建立造成海量小檔案問題。
檔案格式如下圖所示:
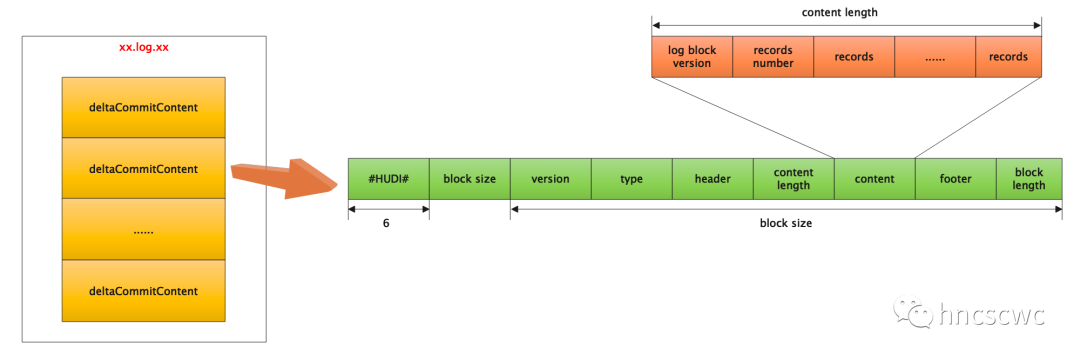
另外,每個事務中的多條寫入記錄,最終儲存在content中,同時在原有資料的基礎上,新增了下面5個欄位:
"_hoodie_commit_time"
"_hoodie_commit_seqno"
"_hoodie_record_key"
"_hoodie_partition_path"
"_hoodie_file_name"
檔案示例如下(本身無法直接檢視,通過程式碼解析後列印的相關內容):
magic:#HUDI#
block size:1061
log format version:1
block type:AVRO_DATA_BLOCK
block header:{INSTANT_TIME=20211230090953, SCHEMA={"type":"record","name":"record","fields":[{"name":"_hoodie_commit_time","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_commit_seqno","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_record_key","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_partition_path","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_file_name","type":["null","string"],"doc":"","default":null},{"name":"uuid","type":["null","string"],"default":null},{"name":"name","type":["null","string"],"default":null},{"name":"age","type":["null","int"],"default":null},{"name":"ts","type":["null",{"type":"long","logicalType":"timestamp-millis"}],"default":null},{"name":"partition","type":["null","string"],"default":null}]}}
content length:235
content:
log block version:1
total records:2
content:
[
{
"_hoodie_commit_time": "20211230090953",
"_hoodie_commit_seqno": "20211230090953_1_1",
"_hoodie_record_key": "id1",
"_hoodie_partition_path": "par1",
"_hoodie_file_name": "c6b44d5e-749d-4053-94bf-92b39828e065",
"uuid": "id1",
"name": "Danny",
"age": 27,
"ts": 661000,
"partition": "par1"
},
{
"_hoodie_commit_time": "20211230090953",
"_hoodie_commit_seqno": "20211230090953_1_2",
"_hoodie_record_key": "id2",
"_hoodie_partition_path": "par1",
"_hoodie_file_name": "c6b44d5e-749d-4053-94bf-92b39828e065",
"uuid": "id2", "name":
"Stephen", "age": 33,
"ts": 2000,
"partition": "par1"
}
]
footer:{}
log block length:1067
magic:#HUDI#
block size:947
log format version:1
block type:AVRO_DATA_BLOCK
block header:{INSTANT_TIME=20211230092036, SCHEMA={"type":"record","name":"record","fields":[{"name":"_hoodie_commit_time","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_commit_seqno","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_record_key","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_partition_path","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_file_name","type":["null","string"],"doc":"","default":null},{"name":"uuid","type":["null","string"],"default":null},{"name":"name","type":["null","string"],"default":null},{"name":"age","type":["null","int"],"default":null},{"name":"ts","type":["null",{"type":"long","logicalType":"timestamp-millis"}],"default":null},{"name":"partition","type":["null","string"],"default":null}]}}
content length:121
content:
log block version:1
total records:1
content:[{"_hoodie_commit_time": "20211230092036", "_hoodie_commit_seqno": "20211230092036_1_1", "_hoodie_record_key": "id4", "_hoodie_partition_path": "par1", "_hoodie_file_name": "c6b44d5e-749d-4053-94bf-92b39828e065", "uuid": "id4", "name": "Fabian", "age": 31, "ts": 4000, "partition": "par1"}]
footer:{}
log block length:953xxx.parquet(orc/hfile)
通常是COW表一次事務提交後,或者壓縮操作後,將上面提到的log檔案中的資料壓縮合併寫入後的檔案。這就是一個標準的parquet檔案格式,當然還支援orc和hfile格式。
注:spark對MOR表型別進行操作時,對於新增的資料,會直接寫入列式(parquet)檔案中,而對於更新操作則記錄在增量的日誌檔案中(xx.log.xx),這個和spark/flink預設使用的索引型別有關。
好了,這就是本文的全部內容,簡單回顧一下,先介紹了一下hudi的核心概念,然後對hudi的各個型別的持久化檔案,以及具體的格式進行了說明,通過持久化檔案可以反過來加深對hudi核心概念的理解。下篇文章,我們再來聊聊hudi的其他內容。
如果覺得本文對你有幫助,三連走起(點贊,在看,分享轉發),也歡迎加我微信交流~
本文分享自微信公眾號 - hncscwc(gh_383bc7486c1a)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- zk session expire會引起HA模式的rm一直處於standby嗎
- yarn節點屬性及排程
- 基於ranger的kafka許可權控制
- kafka的訪問控制
- 一文講透hdfs的delegation token
- kafka客戶端訊息傳送邏輯
- 原始碼閱讀之我見
- 容量排程絕對值配置佇列使用與避坑
- 2.X版本的一個通病問題
- 被這個引數三殺了
- 一文搞懂hadoop中的使用者
- 正確理解Yarn容量排程中的capacity引數
- 從hudi持久化檔案理解其核心概念
- 一文搞懂hadoop的metrics
- hdfs——nn的啟動優化
- HDFS用了這個優化後,效能直接翻倍
- 說說hdfs是如何處理塊副本多餘和缺失的
- 5000字12張圖講解nn記憶體中的元資料資訊
- 一文搞懂Hadoop Archive
- YARN——標籤排程