hdfs——nn的啟動優化
【概述】
上一篇文章講解了,在一定DN節點規模,一定block資料量下的併發寫檔案的優化問題。
在這種節點、資料量規模的叢集中,當HDFS全部重啟(nn+dn全部重啟),或者兩個NN都重啟後,需要經過較長時間,才能真正對外提供服務。
那麼nn啟動過程中都幹了些啥,主要耗時點在哪,以及應當如何優化,本文就來聊聊這些問題——啟動優化。
【啟動流程與耗時分析】
NN的啟動可以粗略的分為以下幾個步驟:
啟動http服務
載入檔案系統
啟動rpc服務
按需啟動外掛服務
處理dn的註冊以及dn的全量塊彙報
其中啟動HTTP服務、RPC服務,都是在對應配置的IP埠上進行監聽,然後建立對應的reader執行緒、handler執行緒,然後等待客戶端的連線並處理客戶端的請求。
而載入檔案系統則是啟動過程中的關鍵步驟,又可以細分為:
載入fsimage檔案
載入fsimage的MD5檔案並進行比對校驗
載入editlog檔案
checkpoint的儲存(可選)
進入安全模式
載入fsimage就是讀取fsimage檔案中的內容,並以此在記憶體中構建相關的元資料資訊;載入editlog則是讀取本地editlog檔案或到JournalNode上讀取editlog檔案;checkpoint本質上還是對元資料資訊持久化儲存,對於HA模式而言,不需要進行checkpoint的儲存處理;最後按需進入安全模式,等待dn的註冊與塊上報,當上報的塊資訊達到指定比例後(預設為99.9%),延遲一段時間後解除安全模式。
需要注意的是:這幾個步驟是序列進行的,一個步驟完成後才進行下一個處理動作。
整個啟動過程中,耗時的點在於載入檔案系統和dn註冊後的塊彙報。載入檔案系統的耗時在整個啟動過程中佔50%左右,剩下的50%為dn註冊的塊彙報處理。http服務和rpc服務的啟動幾乎不耗時。
【fsimage的格式】
既然載入檔案系統佔整個啟動過程中一半的耗時,有必要先來了解了fsimage檔案格式是怎樣的,具體的載入過程又是怎樣的。
整個fsimage檔案由幾個部分組成,最前面的是Header頭資訊,然後是多個section段,section之後是一個Summary概要資訊,以及Summary的長度。
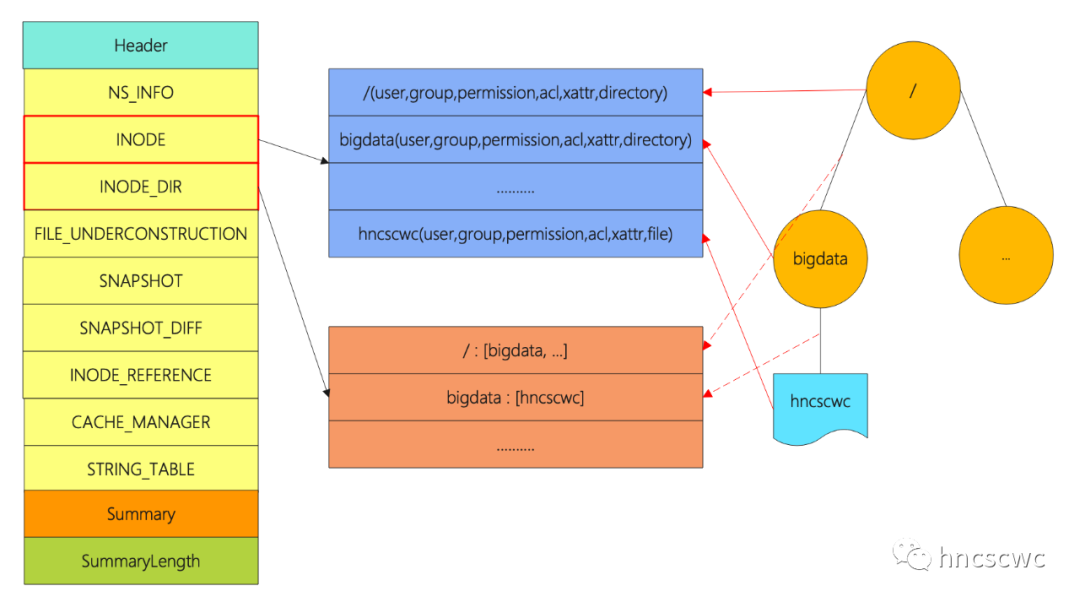
header的內容在2.4版本之後均固定為"HDFSIMG1",長度為8位元組,同時指明後面的section的編碼方式(採用protobuf的方式編碼儲存)。
summary則記錄各個section的名字、在檔案中的起始偏移位置以及長度。section則儲存Hdfs元資料的相關資訊,其中最重要的當屬INODE和INODE_DIR兩個section了,通常來說,這兩個section佔據fsimage的絕大部分空間。
INODE記錄了hdfs中包含的所有檔案/目錄的資訊,包括名稱及可能的各個屬性,每個INODE對應一條記錄資訊;而INDOE_DIR則記錄了INODE的父子關係,也就是檔案、目錄的層級關係,同樣也是一條記錄對應一條關係資訊。有了兩個section,就可以構造出完整的檔案系統目錄樹。
讀取fsimage檔案時,先讀檔案末尾4位元組,得到Summary的起始位置,然後讀取Summary的內容,這樣就知道每個section的起始位置,長度,因此就可以按需載入各個section的內容了。
另外,section的載入順序是序列的,即載入INODE_DIR時,必須先完成INODE的載入,否則可能出現找不到對應的inode條目。
【如何優化】
從上面fsimage的檔案格式可以看出,每個檔案的inode在INodeSection中都是一個獨立的條目,讀fsimage檔案時單執行緒遍歷每個條目,並在記憶體中構造對應的資料結構進行儲存。因此,當有海量檔案資訊儲存在fsiamge中時,單執行緒遍歷必然是非常耗時的。這也就是啟動耗時長的主要原因。
既然單執行緒載入很慢,那是否可以調整成多執行緒載入,每個執行緒讀取其中的一部分,從而加速完成整個INodeSection的載入呢?
實際上,社群版本中的優化就是這麼做的,將INodeSeciont拆分成多個帶sub字尾的新分割槽名,同時保留原始的分割槽資訊,同時在summary中增加各個子section的資訊。
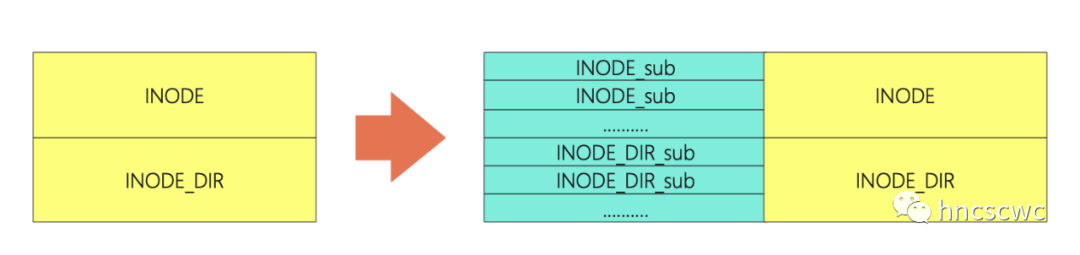
真正讀取檔案時,使用多執行緒進行載入,每個執行緒完成一部分子section的讀取,實現讀取的加速,同樣INODE_DIR也通過多執行緒並行進行讀取。
其中,拆分後的子分割槽個數由配置項("dfs.image.parallel.target.sections")決定,並行載入的執行緒數由配置項("dfs.image.parallel.threads")決定。
這樣一來,就可以通過多執行緒並行進行載入INODE和INODE_DIR兩個section,每個執行緒讀取一個子section,有效提升載入速度。
除此之外,社群還有兩個優化:
一個優化是:fsimage檔案md5校驗計算和fsimage的載入並行處理,在此之前是序列處理的,詳見官方JIRA(HDFS-13694)。
另一個優化是:在載入INodeDirectorySection後,需要更新blocksMap、更新nameCache,然後將inode新增到inode directory的child列表中,優化的邏輯是將這三個操作步驟並行進行處理。
【優化效果】
從官方給出的優化效果來看,資料量在幾個億的級別時,三個優化整體能達到40%-60%的提升(有興趣的可以去看看社群給出的測試資料)。
而實際測試發現,整體效果差不多是在這個範圍內,但具體還會NN所在節點的CPU核數有一定的關係,並行載入時,CPU幾乎處於滿負荷狀態,如果核數不夠,那麼效果會一般,核數稍微大一些,優化的效果會明顯了。
【總結】
好了,小結一下,本文主要講述了nn的啟動流程,分析了主要的耗時點,然後結合fsimage的檔案結構,講述社群的實際優化處理,以及優化後的效果。
本文分享自微信公眾號 - hncscwc(gh_383bc7486c1a)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。