ml-agents專案實踐(一)

本文首發於:行者AI
強化學習 (reinforcement learning) 是機器學習和人工智慧裡的一類問題,研究如何通過一系列的順序決策來達成一個特定目標。它是一類演算法, 是讓計算機實現從一開始什麼都不懂,腦袋裡沒有一點想法,,通過不斷地嘗試, 從錯誤中學習, 最後找到規律, 學會了達到目的的方法。 這就是一個完整的強化學習過程。這裡我們可以引用下方圖做一個更直觀形象的解釋。
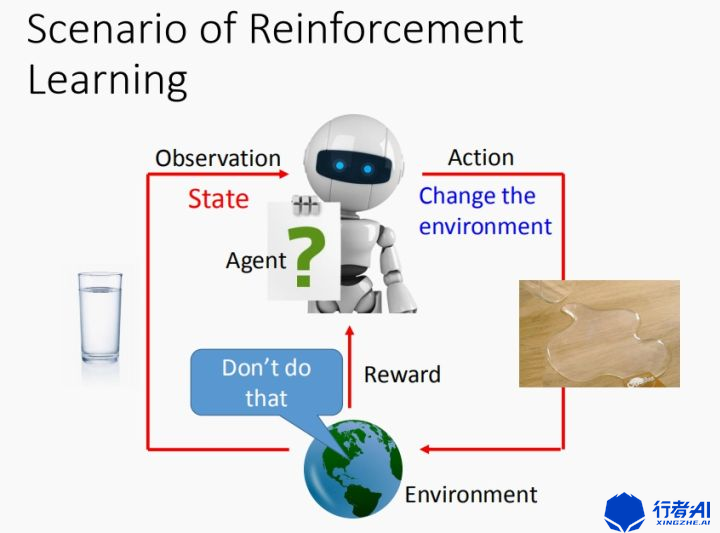
Agent為智慧體,也就是我們的演算法,在遊戲當中以玩家的形式出現。智慧體通過一系列策略,輸出一個行為(Action)從而作用到環境(Environment),而環境則返回作用後的狀態值也就是圖中的觀察(Observation)和獎勵值(Reward)。當環境返回獎勵值給智慧體之後,更新自身所在的狀態,而智慧體獲取到新的Observation。
1. ml-agents
1.1 介紹
目前遊戲大部分Unity遊戲數量龐大,引擎完善,訓練環境好搭建。由於Unity 可以跨平臺,可以在Windows、Linux平臺下訓練後再轉成WebGL釋出到網頁上。而mlagents是Unity的一款開源外掛,能讓開發者在Unity的環境下進行訓練,甚至不用去編寫python端的程式碼,不用深入理解PPO,SAC等演算法。只要開發者配置好引數,就可以很輕鬆的使用強化學習的演算法來訓練自己的模型。
1.2 Anaconda、tensorflow及tensorboard安裝
本文介紹的ml-agents需要通過Python與Tensorflow通訊,訓練時從ml-agents的Unity端拿到Observation、Action、Reward、Done等資訊傳入Tensorflow進行訓練,然後將模型的決策傳入Unity。因此在安裝ml-agents前,需要根據如下連結進行tensorflow的安裝。
Tensorboard方便資料視覺化,方便分析模型是否達到預期。
1.3 ml-agents安裝步驟
(1) 前往github下載ml-agents (本例項採用release6版本)
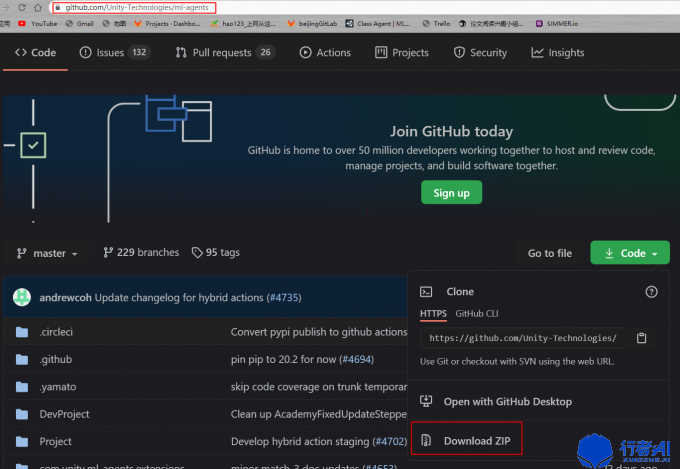
(2) 將壓縮包解壓,把com.unity.ml-agents,com.unity.ml-agents.extensions 放入Unity的Packages目錄下(如果沒有請建立一個),將manifest.json中加入此兩個目錄。
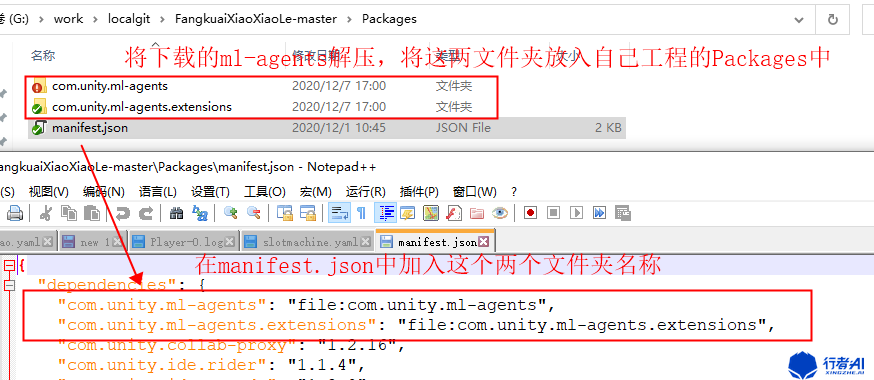
(3) 安裝完成後,到工程中就匯入後,建立個新指令碼,輸入以下引用以驗證安裝成功
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Policies;
public class MyAgent : Agent
{
}
2. ml-agents訓練例項
2.1 概要及工程
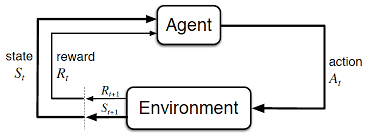
Environment 通常利用馬爾可夫過程來描述,agent 通過採取某種 policy 來產生Action,和 Environment 互動,產生一個 Reward。之後 agent 根據 Reward 來調整優化當前的 policy。
本例實際工程參考消消樂規則,湊齊三個同樣的顏色即可得分,本例項去除了四個連色及多連的額外獎勵(以方便設計環境)

工程例項下載處 點選前往
Unity工程匯出部分請參考官方 點選前往 。
下面將從四個角度來分享專案專案實踐的方法,介面抽離、選演算法、設計環境、引數調整。
2.2 遊戲框架AI介面抽離
將工程的Observation、Action需要的介面從遊戲中抽離出來。用於傳入遊戲當前的狀態和執行遊戲的動作。
static List<ML_Unit> states = new List<ML_Unit>();
public class ML_Unit
{
public int color = (int)CodeColor.ColorType.MaxNum;
public int widthIndex = -1;
public int heightIndex = -1;
}
//從當前畫面中,拿到所有方塊的資訊,包含所在位置x(長度),位置y(高度),顏色(座標軸零點在左上)
public static List<ML_Unit> GetStates()
{
states.Clear();
var xx = GameMgr.Instance.GetGameStates();
for(int i = 0; i < num_widthMax;i++)
{
for(int j = 0; j < num_heightMax; j++)
{
ML_Unit tempUnit = new ML_Unit();
try
{
tempUnit.color = (int)xx[i, j].getColorComponent.getColor;
}
catch
{
Debug.LogError($"GetStates i:{i} j:{j}");
}
tempUnit.widthIndex = xx[i, j].X;
tempUnit.heightIndex = xx[i, j].Y;
states.Add(tempUnit);
}
}
return states;
}
public enum MoveDir
{
up,
right,
down,
left,
}
public static bool CheckMoveValid(int widthIndex, int heigtIndex, int dir)
{
var valid = true;
if (widthIndex == 0 && dir == (int)MoveDir.left)
{
valid = false;
}
if (widthIndex == num_widthMax - 1 && dir == (int)MoveDir.right)
{
valid = false;
}
if (heigtIndex == 0 && dir == (int)MoveDir.up)
{
valid = false;
}
if (heigtIndex == num_heightMax - 1 && dir == (int)MoveDir.down)
{
valid = false;
}
return valid;
}
//執行動作的介面,根據位置資訊和移動方向,呼叫遊戲邏輯移動方塊。widthIndex 0-13,heigtIndex 0-6,dir 0-3 0上 1右 2下 3左
public static void SetAction(int widthIndex,int heigtIndex,int dir,bool immediately)
{
if (CheckMoveValid(widthIndex, heigtIndex, dir))
{
GameMgr.Instance.ExcuteAction(widthIndex, heigtIndex, dir, immediately);
}
}2.3 遊戲AI演算法選擇
走入強化學習專案的第一個課題,面對眾多演算法,選擇一個合適的演算法能事半功倍。如果對演算法的特性還不太熟悉,可以直接使用ml-agents自帶的PPO和SAC。
本例筆者最開始使用的PPO演算法,嘗試了比較多的調整,平均9步才能走對一步,效果比較糟糕。
後來仔細分析遊戲的環境,由於此工程的三消類的遊戲,每次的環境都完全不一樣,每一步的結果對下一步產生的影響並沒有多大關係,對馬爾科夫鏈的需求不強。由於PPO是OnPolicy的policy-based的演算法,每次更新的策略更新非常小心,導致結果很難收斂(筆者嘗試了XX布,依然沒有收斂)。
相比DQN是OffPolicy的value-base演算法,可以收集大量環境的引數建立Qtable,逐步找到對應的環境的最大值。
簡單地說,PPO是線上學習,每次自己跑幾百步後,回過頭來學習這幾百步哪裡做得對,哪裡做的不對,然後更新學習後,再跑幾百步,如此反覆。這樣學習效率慢不說,還很難找到全域性最優的解。
而DQN是離線學習,可以跑上億步,然後回去把這些跑過的地方都拿出來學習,然後很容易找到全域性最優的點。
(本例使用PPO做演示,後續分享在ml-agents外接演算法,使用外部工具stable_baselines3,採用DQN的演算法來訓練)
2.4 遊戲AI設計環境
當我們確定了演算法框架之後,如何設計Observation、Action及Reward,便成了決定訓練效果的決定性因素。在這個遊戲中,環境的這裡的環境主要有兩個變數,一個是方塊的位置,另一個是方塊的顏色。
--Observation:
針對如果上圖,我們的本例長14、寬7、顏色有6種。
ml-agents使用的swish作為啟用函式,可以使用不太大的浮點數(-10f ~10f),但是為了讓agents獲得環境更純淨,訓練效果更理想,我們還是需要對環境進行編碼。
本例筆者使用Onehot的方式進行環境編碼,左上角定位座標零點。如此下來,左上角的青色方塊的環境編碼就可以表示為 長[0,0,0,0,0,0,0,0,0,0,0,0,0,1],
高[0,0,0,0,0,0,1],顏色按固定列舉來處理( 黃,綠,紫,粉,藍,紅)顏色[0,0,0,0,1,0]。
環境總共包含 (14+7+6)14 * 7 = 2646
程式碼示例:
public class MyAgent : Agent
{
static List<ML_Unit> states = new List<ML_Unit>();
public class ML_Unit
{
public int color = (int)CodeColor.ColorType.MaxNum;
public int widthIndex = -1;
public int heightIndex = -1;
}
public static List<ML_Unit> GetStates()
{
states.Clear();
var xx = GameMgr.Instance.GetGameStates();
for(int i = 0; i < num_widthMax;i++)
{
for(int j = 0; j < num_heightMax; j++)
{
ML_Unit tempUnit = new ML_Unit();
try
{
tempUnit.color = (int)xx[i, j].getColorComponent.getColor;
}
catch
{
Debug.LogError($"GetStates i:{i} j:{j}");
}
tempUnit.widthIndex = xx[i, j].X;
tempUnit.heightIndex = xx[i, j].Y;
states.Add(tempUnit);
}
}
return states;
}
List<ML_Unit> curStates = new List<ML_Unit>();
public override void CollectObservations(VectorSensor sensor)
{
//需要判斷是否方塊移動結束,以及方塊結算結束
var receiveReward = GameMgr.Instance.CanGetState();
var codeMoveOver = GameMgr.Instance.IsCodeMoveOver();
if (!codeMoveOver || !receiveReward)
{
return;
}
//獲得環境的狀態資訊
curStates = MlagentsMgr.GetStates();
for (int i = 0; i < curStates.Count; i++)
{
sensor.AddOneHotObservation(curStates[i].widthIndex, MlagentsMgr.num_widthMax);
sensor.AddOneHotObservation(curStates[i].heightIndex, MlagentsMgr.num_heightMax);
sensor.AddOneHotObservation(curStates[i].color, (int)CodeColor.ColorType.MaxNum);
}
}
}--Action:
每個方塊可以上下左右移動,我們需要記錄的最小資訊包含,14*7個方塊,以及每個方塊可以移動4個方向,本例方向列舉(上,右,下,左)。
左上為零點,左上角的青色方塊佔據了Action的前四個動作,分別是(左上角的青色方塊向上移動,左上角的青色方塊向右移動,左上角的青色方塊向下移動,
左上角的青色方塊向左移動)。
那麼動作總共包含 14 7 4 = 392
細心的讀者可能會發現 左上角的青色方塊 並不能往上和往左移動,這時我們需要設定Actionmask,來遮蔽掉這些在規則上禁止的動作。
程式碼示例:
public class MyAgent : Agent
{
public enum MoveDir
{
up,
right,
down,
left,
}
public void DecomposeAction(int actionId,out int width,out int height,out int dir)
{
width = actionId / (num_heightMax * num_dirMax);
height = actionId % (num_heightMax * num_dirMax) / num_dirMax;
dir = actionId % (num_heightMax * num_dirMax) % num_dirMax;
}
//執行動作,並獲得該動作的獎勵
public override void OnActionReceived(float[] vectorAction)
{
//需要判斷是否方塊移動結束,以及方塊結算結束
var receiveReward = GameMgr.Instance.CanGetState();
var codeMoveOver = GameMgr.Instance.IsCodeMoveOver();
if (!codeMoveOver || !receiveReward)
{
Debug.LogError($"OnActionReceived CanGetState = {GameMgr.Instance.CanGetState()}");
return;
}
if (invalidNums.Contains((int)vectorAction[0]))
{
//方塊結算的呼叫,這裡可以獲得獎勵(這裡是懲罰,因為這是在遮蔽動作內,訓練的時候會呼叫所有的動作,在非訓練的時候則不會進此邏輯)
GameMgr.Instance.OnGirdChangeOver?.Invoke(true, -5, false, false);
}
DecomposeAction((int)vectorAction[0], out int widthIndex, out int heightIndex, out int dirIndex);
//這裡回去執行動作,移動對應的方塊,朝對應的方向。執行完畢後會獲得獎勵,並根據情況重置場景
MlagentsMgr.SetAction(widthIndex, heightIndex, dirIndex, false);
}
//MlagentsMgr.SetAction呼叫後,執行完動作,會進入這個函式
public void RewardShape(int score)
{
//計算獲得的獎勵
var reward = (float)score * rewardScaler;
AddReward(reward);
//將資料加入tensorboard進行統計分析
Mlstatistics.AddCumulativeReward(StatisticsType.action, reward);
//每一步包含懲罰的動作,可以提升探索的效率
var punish = -1f / MaxStep * punishScaler;
AddReward(punish);
//將資料加入tensorboard進行統計分析
Mlstatistics.AddCumulativeReward( StatisticsType.punishment, punish);
}
//設定遮蔽動作actionmask
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker)
{
// Mask the necessary actions if selected by the user.
checkinfo.Clear();
invalidNums.Clear();
int invalidNumber = -1;
for (int i = 0; i < MlagentsMgr.num_widthMax;i++)
{
for (int j = 0; j < MlagentsMgr.num_heightMax; j++)
{
if (i == 0)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.left;
actionMasker.SetMask(0, new[] { invalidNumber });
}
if (i == num_widthMax - 1)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.right;
actionMasker.SetMask(0, new[] { invalidNumber });
}
if (j == 0)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.up;
actionMasker.SetMask(0, new[] { invalidNumber });
}
if (j == num_heightMax - 1)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.down;
actionMasker.SetMask(0, new[] { invalidNumber });
}
}
}
}
}原工程消除過程中使用大量協程,有很高的延遲,我們需要再訓練時把延遲的時間擠出來。
為了不影響遊戲的主邏輯,一般情況下把協程裡面的yield return new WaitForSeconds(fillTime)中的fillTime改成0.001f,這樣可以在不大量修改遊戲邏輯的情況下,在模型選擇Action後能最快得到Reward。
public class MyAgent : Agent
{
private void FixedUpdate()
{
var codeMoveOver = GameMgr.Instance.IsCodeMoveOver();
var receiveReward = GameMgr.Instance.CanGetState();
if (!codeMoveOver || !receiveReward /*||!MlagentsMgr.b_isTrain*/)
{
return;
}
//因為有協程需要等待時間,需要等待產生Reward後才去請求決策。所以不能使用ml-agents自帶的DecisionRequester
RequestDecision();
}
}
2.5 引數調整
在設計好模型後,我們先初步跑一版本,看看結果跟我們設計的預期有多大的差異。
首先配置yaml檔案,用於初始化網路的引數:
behaviors:
SanXiaoAgent:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0005
beta: 0.005
epsilon: 0.2
lambd: 0.9
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
memory: null
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
init_path: null
keep_checkpoints: 25
checkpoint_interval: 100000
max_steps: 1000000
time_horizon: 128
summary_freq: 1000
threaded: true
self_play: null
behavioral_cloning: null
framework: tensorflow訓練程式碼請參照官方提供的介面,本例使用release6版本,命令如下
mlagents-learn config/ppo/sanxiao.yaml --env=G:\mylab\ml-agent-buildprojects\sanxiao\windows\display\121001display\fangkuaixiaoxiaole --run-id=121001xxl --train --width 800 --height 600 --num-envs 2 --force --initialize-from=121001訓練完成後,開啟Anaconda,在ml-agents工程主目錄上輸入tensorboard --logdir=results --port=6006,複製http://PS20190711FUOV:6006/到瀏覽器上開啟,即可看到訓練結果。
(mlagents) PS G:\mylab\ml-agents-release_6> tensorboard --logdir=results --port=6006
TensorBoard 1.14.0 at http://PS20190711FUOV:6006/ (Press CTRL+C to quit)訓練效果圖如下:
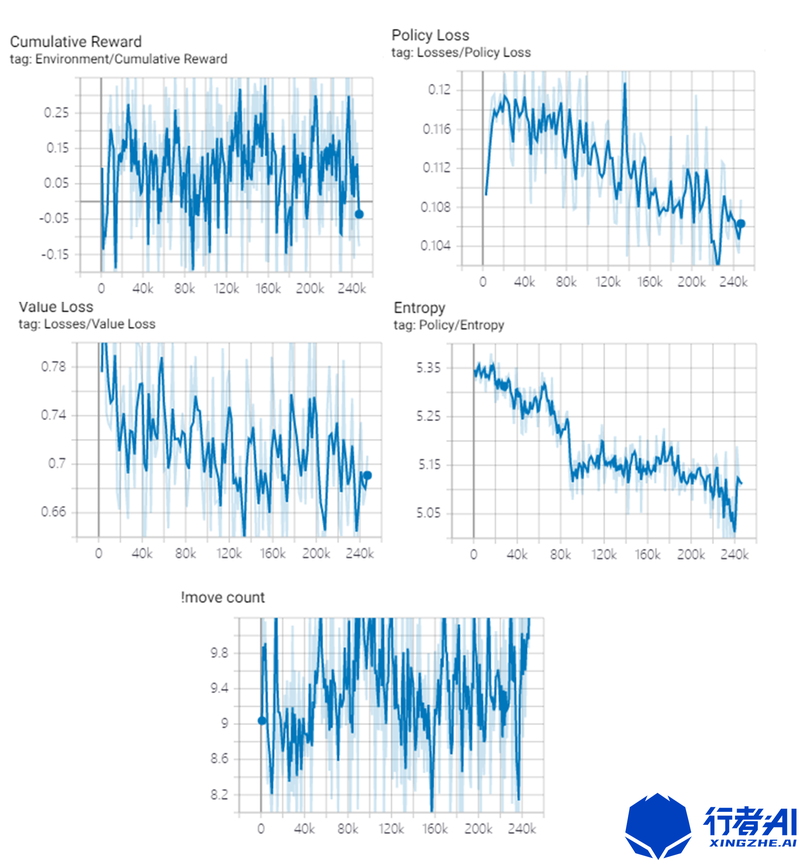
move count 為消掉一次方塊,需要走的平均步數,大概需要9布才能走正確一步。在使用Actionmask情況下,可以在6步左右消除一次方塊。
–Reward:
根據上面表格的Reward,檢視獎勵獎勵設計的均值。筆者喜歡控制在0.5到2之間。過大過小可以調整rewardScaler。
//MlagentsMgr.SetAction呼叫後,執行完動作,會進入這個函式
public void RewardShape(int score)
{
//計算獲得的獎勵
var reward = (float)score * rewardScaler;
AddReward(reward);
//將資料加入tensorboard進行統計分析
Mlstatistics.AddCumulativeReward(StatisticsType.action, reward);
//每一步包含懲罰的動作,可以提升探索的效率
var punish = -1f / MaxStep * punishScaler;
AddReward(punish);
//將資料加入tensorboard進行統計分析
Mlstatistics.AddCumulativeReward( StatisticsType.punishment, punish);
}3. 總結及雜談
目前ml-agents官方做法使用模仿學習,使用專家資料在訓練網路。
筆者在此例中嘗試PPO,有一定的效果。但PPO目前針對三消訓練起來有一定難度的,比較難收斂,很難找到全域性最優。
設定環境和Reward需要嚴謹的測試,否則對結果會產生極大的誤差,且難以排查。
強化學習目前演算法迭代比較快,如果以上有錯誤的地方,歡迎指正,大家一起進步。
因篇幅有限,不能把整個專案的程式碼全放出來,如有興趣研究的同學,可以在下方留言,我可以完整專案通過郵箱的方式發給大家。
後續將分享在ml-agents外接演算法,使用外部工具stable_baselines3,採用DQN的演算法來訓練。
PS:更多技術乾貨,快關注【公眾號 | xingzhe_ai】,與行者一起討論吧!
- buuoj Pwn writeup 31-40
- 太賽博朋克了!華為天才少年自制B站百大Up獎盃,網友:技術難度不高,但侮辱性極強...
- 後端技術:Java 泛型 T,E,K,V的含義,看完本文你就明白了?
- 淺談:MyBatis框架的學習(面試收藏!!!)
- 68.檢視子程序指令碼
- 函式封裝
- ml-agents專案實踐(一)
- 資料庫系統故障相關知識筆記
- C 物件大小,你真的知道嗎?
- js中const{xx1, xx2} = obj;的寫法
- 第五天的學習成果
- 2021開篇第一文
- 華為:明年將有超 40 家主流品牌、1 億臺裝置成為鴻蒙系統新入口
- 為了學會二分搜尋,我作了首詩
- 勵志!86歲的他,申請獲得國家自然科學基金!
- 短連結服務Octopus的實現與原始碼開放
- 如何建立一個新的AliOS Things元件
- HarmonyOS_BearPi-HM Nano學習筆記之環境搭建
- 當我們談前端效能的時候,我們談的是什麼
- 微信退款回撥解密req_info資訊資料踩坑記錄Illegal key size or default parameters