為什麼99%的程式設計師都做不好SQL優化?

- 連線層
最上層是一些客戶端和連結服務,包含本地sock 通訊和大多數基於客戶端/服務端工具實現的類似於 TCP/IP的通訊。主要完成一些類似於連線處理、授權認證、及相關的安全方案。在該層上引入了執行緒 池的概念,為通過認證安全接入的客戶端提供執行緒。同樣在該層上可以實現基於SSL的安全連結。服務 器也會為安全接入的每個客戶端驗證它所具有的操作許可權。
- 服務層
第二層架構主要完成大多數的核心服務功能,如SQL介面,並完成快取的查詢,SQL的分析和優化,部 分內建函式的執行。所有跨儲存引擎的功能也在這一層實現,如 過程、函式等。在該層,伺服器會解 析查詢並建立相應的內部解析樹,並對其完成相應的優化如確定表的查詢的順序,是否利用索引等, 最後生成相應的執行操作。如果是select語句,伺服器還會查詢內部的快取,如果快取空間足夠大, 這樣在解決大量讀操作的環境中能夠很好的提升系統的效能。
- 引擎層
儲存引擎層, 儲存引擎真正的負責了MySQL中資料的儲存和提取,伺服器通過API和儲存引擎進行通 信。不同的儲存引擎具有不同的功能,這樣我們可以根據自己的需要,來選取合適的儲存引擎。資料庫 中的索引是在儲存引擎層實現的。
- 儲存層
資料儲存層, 主要是將資料(如: redolog、undolog、資料、索引、二進位制日誌、錯誤日誌、查詢 日誌、慢查詢日誌等)儲存在檔案系統之上,並完成與儲存引擎的互動。
和其他資料庫相比,MySQL有點與眾不同,它的架構可以在多種不同場景中應用併發揮良好作用。主要 體現在儲存引擎上,外掛式的儲存引擎架構,將查詢處理和其他的系統任務以及資料的儲存提取分離。 這種架構可以根據業務的需求和實際需要選擇合適的儲存引擎。
儲存引擎介紹

大家可能沒有聽說過儲存引擎,但是一定聽過引擎這個詞,引擎就是發動機,是一個機器的核心元件。 比如,對於艦載機、直升機、火箭來說,他們都有各自的引擎,是他們最為核心的元件。而我們在選擇 引擎的時候,需要在合適的場景,選擇合適的儲存引擎,就像在直升機上,我們不能選擇艦載機的引擎 一樣。 而對於儲存引擎,也是一樣,他是mysql資料庫的核心,我們也需要在合適的場景選擇合適的儲存引 擎。接下來就來介紹一下儲存引擎。 儲存引擎就是儲存資料、建立索引、更新/查詢資料等技術的實現方式 。儲存引擎是基於表的,而不是 基於庫的,所以儲存引擎也可被稱為表型別。我們可以在建立表的時候,來指定選擇的儲存引擎,如果 沒有指定將自動選擇預設的儲存引擎。
- 建表時指定儲存引擎
CREATE TABLE 表名(
欄位1 欄位1型別 [ COMMENT 欄位1註釋 ] ,
......
欄位n 欄位n型別 [COMMENT 欄位n註釋 ]
) ENGINE = INNODB [ COMMENT 表註釋 ] ;
- 查詢當前資料庫支援的儲存引擎
SHOW ENGINES;

- 建立表 my_myisam , 並指定MyISAM儲存引擎
CREATE TABLE my_myisam(
`id` INT,
`name` VARCHAR(10)
)ENGINE = MYISAM;
- 建立表 my_memory , 指定Memory儲存引擎
CREATE TABLE my_memory(
`id` INT,
`name` VARCHAR(10)
)ENGINE = MEMORY;
儲存引擎特點
上面我們介紹了什麼是儲存引擎,以及如何在建表時如何指定儲存引擎,接下來我們就來介紹下來上面 重點提到的三種儲存引擎 InnoDB、MyISAM、Memory的特點。
InnoDB
- 介紹
InnoDB是一種兼顧高可靠性和高效能的通用儲存引擎,在 MySQL 5.5 之後,InnoDB是預設的 MySQL 儲存引擎。
- 特點
- DML操作遵循ACID模型,支援事務;
- 行級鎖,提高併發訪問效能;
- 支援外來鍵FOREIGN KEY約束,保證資料的完整性和正確性;
- 檔案
xxx.ibd:xxx代表的是表名,innoDB引擎的每張表都會對應這樣一個表空間檔案,儲存該表的表結 構(frm-早期的 、sdi-新版的)、資料和索引。
引數:innodb_file_per_table
show variables like 'innodb_file_per_table';
| Variable_name | Value |
|---|---|
| innodb_file_per_table | ON |
如果該引數開啟,代表對於InnoDB引擎的表,每一張表都對應一個ibd檔案。 我們直接開啟MySQL的 資料存放目錄: D:\DevelopTools\mysql-5.7.19-winx64\data , 這個目錄下有很多檔案 夾,不同的資料夾代表不同的資料庫,我們直接開啟frx_db02資料夾。 
可以看到裡面有很多的ibd檔案,每一個ibd檔案就對應一張表,比如:我們有一張表 account,就有這樣的一個account.ibd檔案,而在這個ibd檔案中不僅存放表結構、資料,還會存放該表對應的索引資訊。 而該檔案是基於二進位制儲存的,不能直接基於記事本開啟,我們可以使用mysql提供的一個指令 ibd2sdi ,通過該指令就可以從ibd檔案中提取sdi資訊,而sdi資料字典資訊中就包含該表的表結構。
ibd2sdi account.ibd
針對MySQL8有效
- 邏輯儲存結構
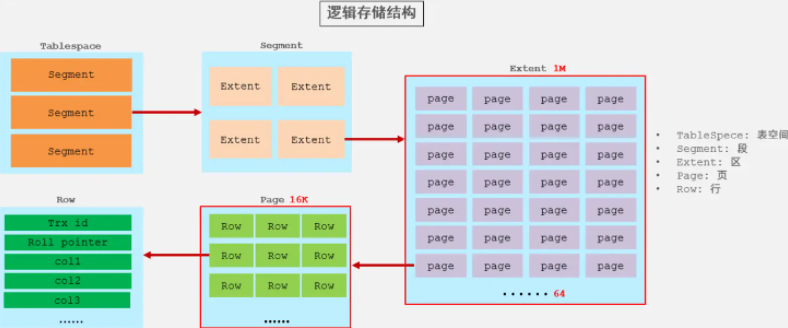
- 表空間 : InnoDB儲存引擎邏輯結構的最高層,ibd檔案其實就是表空間檔案,在表空間中可以包含多個Segment段。
- 段 : 表空間是由各個段組成的, 常見的段有資料段、索引段、回滾段等。InnoDB中對於段的管理,都是引擎自身完成,不需要人為對其控制,一個段中包含多個區。
- 區 : 區是表空間的單元結構,每個區的大小為1M。 預設情況下, InnoDB儲存引擎頁大小為16K, 即一個區中一共有64個連續的頁。
- 頁 : 頁是組成區的最小單元,頁也是InnoDB 儲存引擎磁碟管理的最小單元,每個頁的大小預設為 16KB。為了保證頁的連續性,InnoDB 儲存引擎每次從磁碟申請 4-5 個區。
- 行 : InnoDB 儲存引擎是面向行的,也就是說資料是按行進行存放的,在每一行中除了定義表時所指定的欄位以外,還包含兩個隱藏欄位(後面會詳細介紹)。
MyISAM
- 介紹
MyISAM是MySQL早期的預設儲存引擎。
- 特點
訪問速度快
不支援事務,不支援外來鍵
支援表鎖,不支援行鎖
- 檔案
xxx.sdi:儲存表結構資訊
xxx.MYD: 儲存資料
xxx.MYI: 儲存索引
Memory
- 介紹
Memory引擎的表資料時儲存在記憶體中的,由於受到硬體問題、或斷電問題的影響,只能將這些表作為 臨時表或快取使用。
- 特點
記憶體存放
hash索引(預設)
- 檔案
xxx.sdi:儲存表結構資訊
區別及特點
| 特點 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 儲存限制 | 64TB | 有 | 有 |
| 事務安全 | 支援 | - | - |
| 鎖機制 | 行鎖 | 表鎖 | 表鎖 |
| B+tree索引 | 支援 | 支援 | 支援 |
| Hash索引 | - | - | 支援 |
| 全文索引 | 支援(5.6版本之後) | 支援 | - |
| 空間使用 | 高 | 底 | N/A |
| 記憶體使用 | 高 | 底 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支援外來鍵 | 支援 | - | - |
儲存引擎選擇
在選擇儲存引擎時,應該根據應用系統的特點選擇合適的儲存引擎。對於複雜的應用系統,還可以根據 實際情況選擇多種儲存引擎進行組合。
- InnoDB: 是Mysql的預設儲存引擎,支援事務、外來鍵。如果應用對事務的完整性有比較高的要 求,在併發條件下要求資料的一致性,資料操作除了插入和查詢之外,還包含很多的更新、刪除操 作,那麼InnoDB儲存引擎是比較合適的選擇。
- MyISAM : 如果應用是以讀操作和插入操作為主,只有很少的更新和刪除操作,並且對事務的完 整性、併發性要求不是很高,那麼選擇這個儲存引擎是非常合適的。
- MEMORY:將所有資料儲存在記憶體中,訪問速度快,通常用於臨時表及快取。MEMORY的缺陷就是 對錶的大小有限制,太大的表無法快取在記憶體中,而且無法保障資料的安全性。
MySQL InnoDB引擎
邏輯儲存引擎
InnoDB的邏輯儲存結構如下圖所示: 
- 表空間
表空間是InnoDB儲存引擎邏輯結構的最高層, 如果使用者啟用了引數 innodb_file_per_table(在8.0版本中預設開啟) ,則每張表都會有一個表空間(xxx.ibd),一個mysql例項可以對應多個表空間,用於儲存記錄、索引等資料。
- 段
段,分為資料段(Leaf node segment)、索引段(Non-leaf node segment)、回滾段(Rollback segment),InnoDB是索引組織表,資料段就是B+樹的葉子節點, 索引段即為B+樹的非葉子節點。段用來管理多個Extent(區)。
- 區
區,表空間的單元結構,每個區的大小為1M。 預設情況下, InnoDB儲存引擎頁大小為16K, 即一個區中一共有64個連續的頁。
- 頁
頁,是InnoDB 儲存引擎磁碟管理的最小單元,每個頁的大小預設為 16KB。為了保證頁的連續性,InnoDB 儲存引擎每次從磁碟申請 4-5 個區。
- 行
行,InnoDB 儲存引擎資料是按行進行存放的。
在行中,預設有兩個隱藏欄位:
- Trx_id:每次對某條記錄進行改動時,都會把對應的事務id賦值給trx_id隱藏列。
- Roll_pointer:每次對某條引記錄進行改動時,都會把舊的版本寫入到undo日誌中,然後這個隱藏列就相當於一個指標,可以通過它來找到該記錄修改前的資訊。
架構
概述
MySQL5.5 版本開始,預設使用InnoDB儲存引擎,它擅長事務處理,具有崩潰恢復特性,在日常開發中使用非常廣泛。下面是InnoDB架構圖,左側為記憶體結構,右側為磁碟結構。

記憶體架構

在左側的記憶體結構中,主要分為這麼四大塊兒: Buffer Pool、Change Buffer、Adaptive Hash Index、Log Buffer。 下來介紹一下這四個部分。
- Buffer Pool
InnoDB儲存引擎基於磁碟檔案儲存,訪問物理硬碟和在記憶體中進行訪問,速度相差很大,為了儘可能彌補這兩者之間的I/O效率的差值,就需要把經常使用的資料載入到緩衝池中,避免每次訪問都進行磁碟I/O。
在InnoDB的緩衝池中不僅快取了索引頁和資料頁,還包含了undo頁、插入快取、自適應雜湊索引以及InnoDB的鎖資訊等等。
緩衝池 Buffer Pool,是主記憶體中的一個區域,裡面可以快取磁碟上經常操作的真實資料,在執行增 刪改查操作時,先操作緩衝池中的資料(若緩衝池沒有資料,則從磁碟載入並快取),然後再以一定頻 率重新整理到磁碟,從而減少磁碟IO,加快處理速度。
緩衝池以Page頁為單位,底層採用連結串列資料結構管理Page。根據狀態,將Page分為三種類型:
- free page:空閒page,未被使用。
- clean page:被使用page,資料沒有被修改過。
- dirty page:髒頁,被使用page,資料被修改過,也中資料與磁碟的資料產生了不一致。
在專用伺服器上,通常將多達80%的實體記憶體分配給緩衝池 。引數設定: show variables like 'innodb_buffer_pool_size';
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.00 sec)
- Change Buffer
Change Buffer,更改緩衝區(針對於非唯一二級索引頁),在執行DML語句時,如果這些資料Page沒有在Buffer Pool中,不會直接操作磁碟,而會將資料變更存在更改緩衝區 Change Buffer中,在未來資料被讀取時,再將資料合併恢復到Buffer Pool中,再將合併後的資料重新整理到磁碟中。
Change Buffer的意義是什麼呢?
先來看一幅圖,這個是二級索引的結構圖:

與聚集索引不同,二級索引通常是非唯一的,並且以相對隨機的順序插入二級索引。同樣,刪除和更新可能會影響索引樹中不相鄰的二級索引頁,如果每一次都操作磁碟,會造成大量的磁碟IO。有了ChangeBuffer之後,我們可以在緩衝池中進行合併處理,減少磁碟IO。
- Adaptive Hash Index
自適應hash索引,用於優化對Buffer Pool資料的查詢。MySQL的innoDB引擎中雖然沒有直接支援hash索引,但是給我們提供了一個功能就是這個自適應hash索引。因為前面我們講到過,hash索引在進行等值匹配時,一般效能是要高於B+樹的,因為hash索引一般只需要一次IO即可,而B+樹,可能需要幾次匹配,所以hash索引的效率要高,但是hash索引又不適合做範圍查詢、模糊匹配等。
InnoDB儲存引擎會監控對錶上各索引頁的查詢,如果觀察到在特定的條件下hash索引可以提升速度,則建立hash索引,稱之為自適應hash索引。
自適應雜湊索引,無需人工干預,是系統根據情況自動完成。
引數: adaptive_hash_index
- Log Buffer
Log Buffer:日誌緩衝區,用來儲存要寫入到磁碟中的log日誌資料(redo log 、undo log),預設大小為 16MB,日誌緩衝區的日誌會定期重新整理到磁碟中。如果需要更新、插入或刪除許多行的事務,增加日誌緩衝區的大小可以節省磁碟 I/O。
引數:
innodb_log_buffer_size:緩衝區大小
innodb_flush_log_at_trx_commit:日誌重新整理到磁碟時機,取值主要包含以下三個:
1:日誌在每次事務提交時寫入並重新整理到磁碟,預設值。
0:每秒將日誌寫入並重新整理到磁碟一次。
2:日誌在每次事務提交後寫入,並每秒重新整理到磁碟一次。
mysql> show variables like 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
1 row in set (0.00 sec)
磁碟結構
接下來,再來看看InnoDB體系結構的右邊部分,也就是磁碟結構:
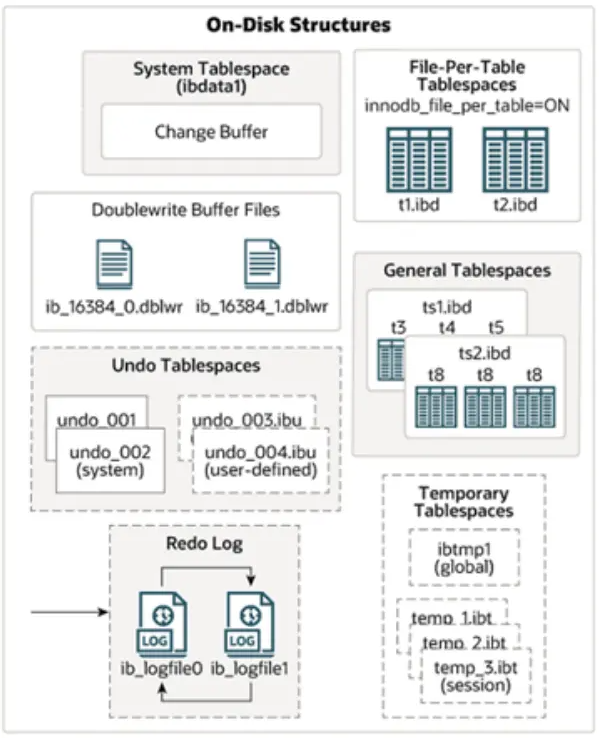
System Tablespace
系統表空間是更改緩衝區的儲存區域。如果表是在系統表空間而不是每個表文件或通用表空間中建立的,它也可能包含表和索引資料。(在MySQL5.x版本中還包含InnoDB資料字典、undolog等)
引數:innodb_data_file_path
mysql> show variables like 'innodb_data_file_path';
+-----------------------+------------------------+
| Variable_name | Value |
+-----------------------+------------------------+
| innodb_data_file_path | ibdata1:12M:autoextend |
+-----------------------+------------------------+
1 row in set (0.00 sec)
系統表空間,預設的檔名叫 ibdata1。
- File-Per-Table Tablespaces
如果開啟了innodb_file_per_table開關 ,則每個表的檔案表空間包含單個InnoDB表的資料和索引 ,並存儲在檔案系統上的單個數據檔案中。
開關引數:innodb_file_per_table,該引數預設開啟。
mysql> show variables like 'innodb_file_per_table';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
1 row in set (0.00 sec)
那也就是說,我們每建立一個表,都會產生一個表空間檔案,如圖:

- General Tablespaces
通用表空間,需要通過 CREATE TABLESPACE 語法建立通用表空間,在建立表時,可以指定該表空間。
A. 建立表空間
CREATE TABLESPACE ts_name ADD DATAFILE 'file_name' ENGINE = engine_name;
mysql> CREATE TABLESPACE ts_itheima ADD DATAFILE 'myitheima.ibd' ENGINE = innodb;
Query OK, 0 rows affected (0.00 sec)
B. 建立表時指定表空間
CREATE TABLE xxx ... TABLESPACE ts_name;
mysql> create table a(id int primary key auto_increment,name varchar(10)) engine=innodb tablespace ts_itheima;
Query OK, 0 rows affected (0.01 sec)
- Undo Tablespaces
撤銷表空間,MySQL例項在初始化時會自動建立兩個預設的undo表空間(初始大小16M),用於儲存 undo log日誌。
- Temporary Tablespaces
InnoDB 使用會話臨時表空間和全域性臨時表空間。儲存使用者建立的臨時表等資料。
- Doublewrite Buffer Files
雙寫緩衝區,innoDB引擎將資料頁從Buffer Pool重新整理到磁碟前,先將資料頁寫入雙寫緩衝區檔案中,便於系統異常時恢復資料。
- Redo Log
重做日誌,是用來實現事務的永續性。該日誌檔案由兩部分組成:重做日誌緩衝(redo log buffer)以及重做日誌檔案(redo log),前者是在記憶體中,後者在磁碟中。當事務提交之後會把所有修改資訊都會存到該日誌中, 用於在重新整理髒頁到磁碟時,發生錯誤時, 進行資料恢復使用。
以迴圈方式寫入重做日誌檔案,涉及兩個檔案:
-rw-r-----. 1 mysql mysql 50331648 10月 2 22:52 ib_logfile0
-rw-r-----. 1 mysql mysql 50331648 10月 2 22:52 ib_logfile1
前面我們介紹了InnoDB的記憶體結構,以及磁碟結構,那麼記憶體中我們所更新的資料,又是如何到磁碟中的呢? 此時,就涉及到一組後臺執行緒,接下來,就來介紹一些InnoDB中涉及到的後臺執行緒。

後臺執行緒
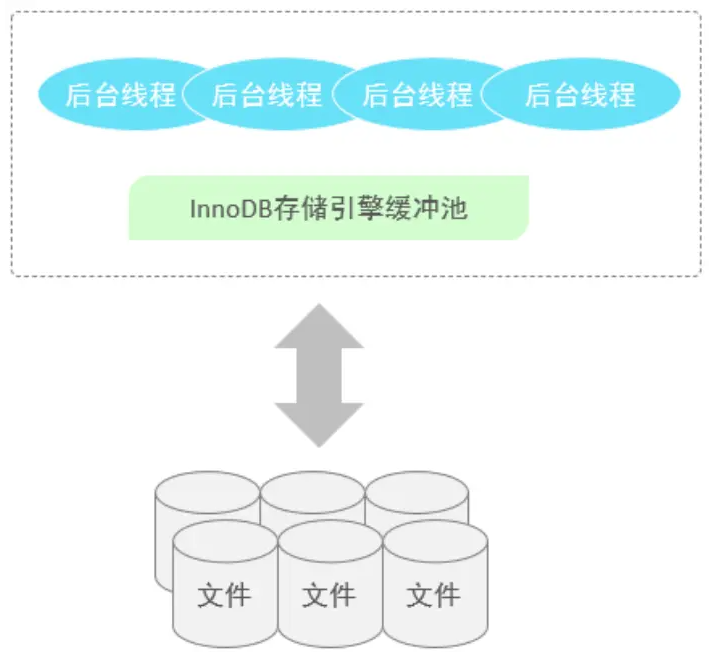
在InnoDB的後臺執行緒中,分為4類,分別是:Master Thread 、IO Thread、Purge Thread、Page Cleaner Thread。
- Master Thread
核心後臺執行緒,負責排程其他執行緒,還負責將緩衝池中的資料非同步重新整理到磁碟中, 保持資料的一致性,還包括髒頁的重新整理、合併插入快取、undo頁的回收 。
- IO Thread
在InnoDB儲存引擎中大量使用了AIO來處理IO請求, 這樣可以極大地提高資料庫的效能,而IOThread主要負責這些IO請求的回撥。
| 執行緒型別 | 默認個數 | 職責 |
|---|---|---|
| Read thread | 4 | 負責讀操作 |
| Write thread | 4 | 負責寫操作 |
| Log thread | 1 | 負責將日誌緩衝區重新整理到磁碟 |
| Insert buffer thread | 1 | 負責將寫緩衝區內容重新整理到磁碟 |
我們可以通過以下的這條指令,檢視到InnoDB的狀態資訊,其中就包含IO Thread資訊。
show engine innodb status;

- Purge Thread
主要用於回收事務已經提交了的undo log,在事務提交之後,undo log可能不用了,就用它來回收。
- Page Cleaner Thread
協助 Master Thread 重新整理髒頁到磁碟的執行緒,它可以減輕 Master Thread 的工作壓力,減少阻塞
本文由
傳智教育博學谷狂野架構師教研團隊釋出。如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支援是我堅持創作的動力。轉載請註明出處!
- ElasticSearch還能效能調優,漲見識、漲見識了!!!
- 【必須收藏】別再亂找TiDB 叢集部署教程了,這篇保姆級教程來幫你!!| 博學谷狂野架構師
- 【建議收藏】7000 字的TIDB保姆級簡介,你見過嗎
- Tomcat架構設計剖析 | 博學谷狂野架構師
- 你可能不那麼知道的Tomcat生命週期管理 | 博學谷狂野架構師
- 大哥,這是併發不是並行,Are You Ok?
- 為啥要重學Tomcat?| 博學谷狂野架構師
- 這是一篇純講SQL語句優化的文章!!!| 博學谷狂野架構師
- 捲起來!!!看了這篇文章我才知道MySQL事務&MVCC到底是啥?
- 為什麼99%的程式設計師都做不好SQL優化?
- 如何搞定MySQL鎖(全域性鎖、表級鎖、行級鎖)?這篇文章告訴你答案!太TMD詳細了!!!
- 【建議收藏】超詳細的Canal入門,看這篇就夠了!!!
- 從菜鳥程式設計師到高階架構師,竟然是因為這個字final
- 為什麼95%的Java程式設計師,都是用不好Synchronized?
- 99%的Java程式設計師者,都敗給這一個字!
- 8000 字,就說一個字Volatile
- 98%的程式設計師,都沒有研究過JVM重排序和順序一致性
- 來一波騷操作,Java記憶體模型
- 時隔多年,這次我終於把動態代理的原始碼翻了個地兒朝天
- 再有人問你分散式事務,把這篇文章砸過去給他