YOLOv5全面解析教程⑤:計算mAP用到的Numpy函式詳解

作者 | Fengwen、 BBuf
本文主要介紹在One-YOLOv5專案中計算mAP用到的一些numpy操作,這些numpy操作使用在utils/metrics.py中。本文是《YOLOv5全面解析教程④:目標檢測模型精確度評估》的補充,希望能幫助到小夥伴們。
歡迎Star、試用One-YOLOv5:
http://github.com/Oneflow-Inc/one-yolov5
用到的numpy操作比如:np.cumsum()、np.interp()、np.maximum.accumulate()、np.trapz()等。接下來將在下面逐一介紹。
import numpy as np
np.cumsum()
返回元素沿給定軸的累積和。
numpy.cumsum(a, axis=None, dtype=None, out=None)原始碼( http://github.com/numpy/numpy/blob/v1.23.0/numpy/core/fromnumeric.py#L2497-L2571 )
-
引數
-
a:陣列
-
axis: 軸索引,整型,若a為n維陣列,則axis的取值範圍為[0,n-1]
-
dtype: 返回結果的資料型別,若不指定,則預設與a一致n
-
out: 資料型別為陣列。用來放置結果的替代輸出陣列,它必須具有與輸出結果具有相同的形狀和資料緩衝區長度
-
返回
-
沿著指定軸的元素累加和所組成的陣列,其形狀應與輸入陣列a一致
更多資訊請參閱讀:
1.API_CN( http://www.osgeo.cn/numpy/reference/generated/numpy.cumsum.html?highlight=cumsum#numpy.cumsum )
2.API_EN( http://numpy.org/doc/stable/reference/generated/numpy.cumsum.html?highlight=cumsum#numpy.cumsum )
np.cumsum(a) # 計算累積和的軸。預設(無)是在展平的陣列上計算cumsum。
array([ 1, 3, 6, 10, 15, 21])
a = np.array([[ 1, 2, 3], [ 4, 5, 6]])
np.cumsum(a, dtype=float) # 指定輸出的特定的型別
array([ 1., 3., 6., 10., 15., 21.])
np.cumsum(a,axis= 0) # 3列中每一列的行總和
array([[1, 2, 3],
[5, 7, 9]])
x = np.ones(( 3, 4),dtype=int)
np.cumsum( x ,axis= 0)
array([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]])
np.cumsum(a,axis= 1) # 2行中每行的列總和
array([[ 1, 3, 6],
[ 4, 9, 15]])
np.interp()
-
引數
-
x: 陣列待插入資料的橫座標
-
xp: 一維浮點數序列原始資料點的橫座標,如果period引數沒有指定那麼就必須是遞增的 否則,在使用xp = xp % period正則化之後,xp在內部進行排序
-
fp: 一維浮點數或複數序列 原始資料點的縱座標,和xp序列等長.
-
left: 可選引數,型別為浮點數或複數(對應於fp值) 當x < xp[0]時的插值返回值,預設為fp[0].
-
right: 可選引數,型別為浮點數或複數(對應於fp值),當x > xp[-1]時的插值返回值,預設為fp[-1].
-
period: None或者浮點數,可選引數橫座標的週期 此引數使得可以正確插入angular x-coordinates. 如果該引數被設定,那麼忽略left引數和right引數
-
返回
-
浮點數或複數(對應於fp值)或ndarray. 插入資料的縱座標,和x形狀相同
注意!
在沒有設定period引數時,預設要求xp引數是遞增序列
# 插入一個值
import numpy as np
import matplotlib.pyplot as plt
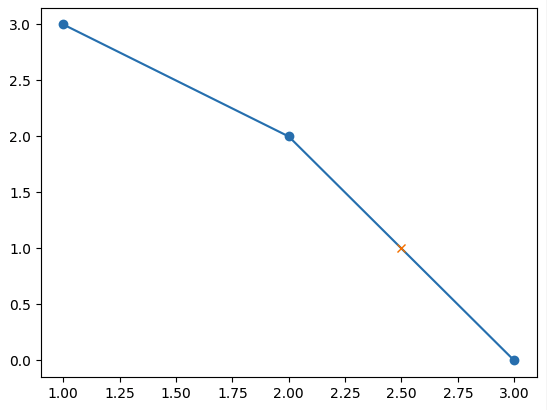
x = 2.5
xp = [ 1, 2, 3]
fp = [ 3, 2, 0]
y = np.interp(x, xp, fp) # 1.0
plt.plot(xp, fp, '-o')
plt.plot(x, y, 'x') # 畫插值
plt.show()
# 插入一個序列
import numpy as np
import matplotlib.pyplot as plt
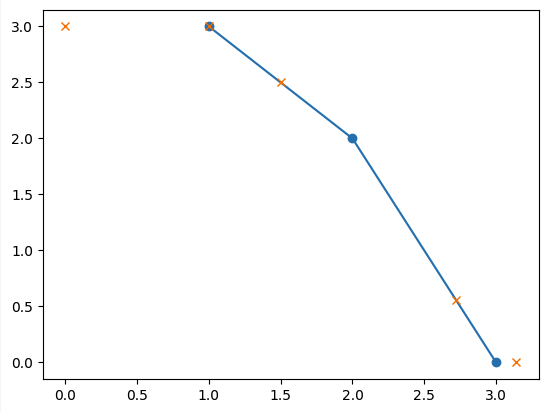
x = [ 0, 1, 1.5, 2.72, 3.14]
xp = [ 1, 2, 3]
fp = [ 3, 2, 0]
y = np.interp(x, xp, fp) # array([ 3. , 3. , 2.5 , 0.56, 0. ])
plt.plot(xp, fp, '-o')
plt.plot(x, y, 'x')
plt.show()
np.maximum.accumulate
計算陣列(或陣列的特定軸)的累積最大值
import numpy as np
d = np.random.randint(low = 1, high = 10, size=( 2, 3))
print( "d:\n",d)
c = np.maximum.accumulate(d, axis= 1)
print( "c:\n",c)
d:
[[1 9 5]
[2 6 1]]
c:
[[1 9 9]
[2 6 6]]
np.trapz()
numpy.trapz(y, x=None, dx=1.0, axis=- 1) 使用複合梯形規則沿給定軸積分。
import matplotlib.pyplot as plt
import numpy as np
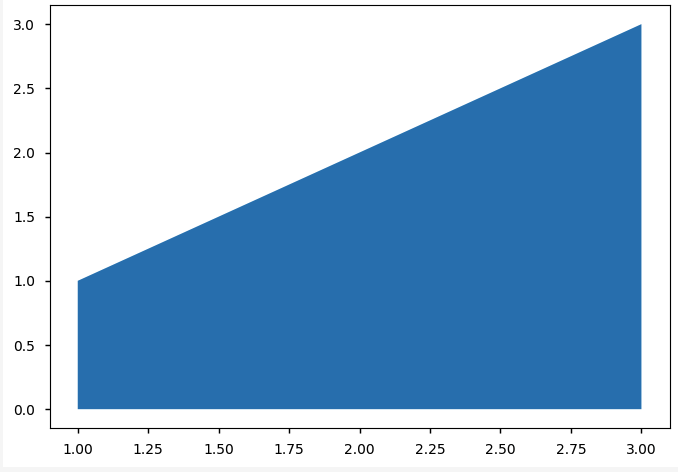
y = [ 1, 2, 3] ; x = [i+ 1 for i in range(len(y))]
print(np.trapz(x))
plt.fill_between(x, y)
plt.show() # (1 + 3)*(3 - 1)/2 = 4
4.0
import matplotlib.pyplot as plt
import numpy as np
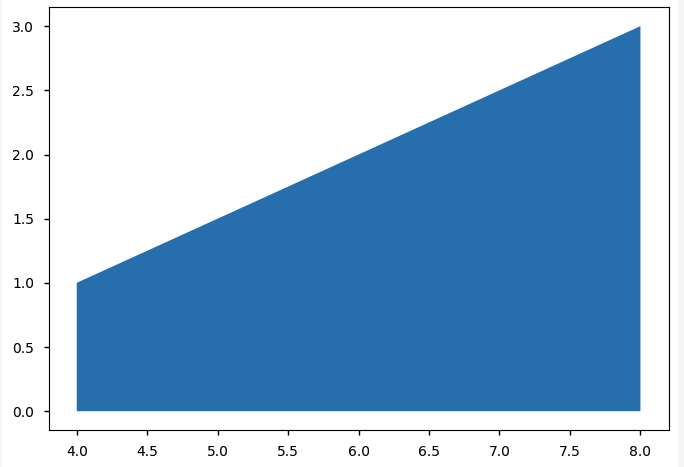
y = [ 1, 2, 3]
x = [ 4, 6, 8]
print(np.trapz(y,x))
plt.fill_between(x, y)
plt.show() # (3 + 1)*(8 - 4) / 2 = 8
8.0
參考資料:
1. numpy API文件 CN:http://www.osgeo.cn/numpy/dev/index.html
2. numpy API文件 EN:http://numpy.org/doc/stable/reference/index.html
3. axis的基本使用:http://www.jb51.net/article/242067.htm
其他人都在看
歡迎Star、試用OneFlow最新版本:http://github.com/Oneflow-Inc/oneflow/

本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- OneFlow原始碼解析:Eager模式下的裝置管理與併發執行
- OpenAI創始人:GPT-4的研究起源和構建心法
- GPT-4創造者:第二次改變AI浪潮的方向
- NCCL原始碼解析①:初始化及ncclUniqueId的產生
- GPT-4問世;LLM訓練指南;純瀏覽器跑Stable Diffusion
- 適配PyTorch FX,OneFlow讓量化感知訓練更簡單
- 超越ChatGPT:大模型的智慧極限
- ChatGPT作者John Schulman:我們成功的祕密武器
- YOLOv5全面解析教程⑤:計算mAP用到的Numpy函式詳解
- GPT-3/ChatGPT復現的經驗教訓
- ChatGPT背後:從0到1,OpenAI的創立之路
- 一塊GPU搞定ChatGPT;ML系統入坑指南;理解GPU底層架構
- YOLOv5全面解析教程④:目標檢測模型精確度評估
- ChatGPT資料集之謎
- OneFlow原始碼解析:Eager模式下的SBP Signature推導
- YOLOv5全面解析教程③:更快更好的邊界框迴歸損失
- ChatGPT背後的經濟賬
- Sam Altman的成功學|升維指南
- 開源機器學習軟體對AI的發展意味著什麼?
- “一鍵”模型遷移,效能翻倍,多語言AltDiffusion推理速度超快