基於U-Net網路的影象分割的MindStudio實踐
摘要:本實踐是基於Windows版MindStudio 5.0.RC3,遠端連線ECS伺服器使用,ECS是基於官方分享的CANN6.0.RC1_MindX_Vision3.0.RC3映象建立的。
本文分享自華為雲社群《【MindStudio訓練營第一季】基於U-Net網路的影象分割的MindStudio實踐》,作者:Tianyi_Li 。
1.U-Net網路介紹:
U-Net模型基於二維影象分割。在2015年ISBI細胞跟蹤競賽中,U-Net獲得了許多最佳獎項。論文中提出了一種用於醫學影象分割的網路模型和資料增強方法,有效利用標註資料來解決醫學領域標註資料不足的問題。U型網路結構也用於提取上下文和位置資訊。
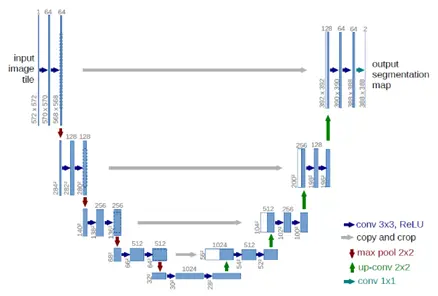
[U-Net 論文]: Olaf Ronneberger, Philipp Fischer, Thomas Brox. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” conditionally accepted at MICCAI 2015. 2015.
2.ECS執行說明
我們的操作基本都在root使用者下執行。
首先,修改bash,具體命令和結果如下。

本專案支援MindStudio執行和終端執行。
(1)下載專案程式碼
下載連結:http://alexed.obs.cn-north-4.myhuaweicloud.com/unet_sdk.zip
將專案檔案unet_sdk.zip上傳至華為雲ECS彈性雲伺服器/root/目錄下,並解壓;或者下載到本地電腦,用MindStudio開啟。
將之前unet_hw960_bs1.air模型放到/unet_sdk/model/目錄下。
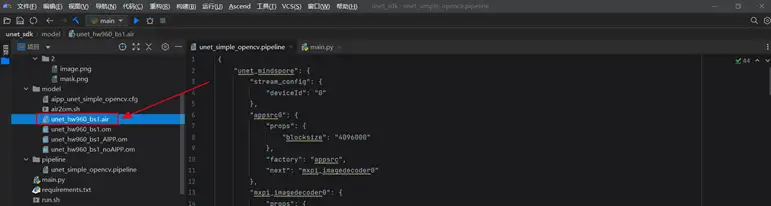
專案檔案結構
├── unet_sdk
├── README.md
├── data //資料集
│ ├── 1
│ │ ├──image.png //圖片
│ │ ├──mask.png //標籤
│ ...
├── model
│ ├──air2om.sh // air模型轉om指令碼
│ ├──xxx.air //air模型
│ ├──xxx.om //om模型
│ ├──aipp_unet_simple_opencv.cfg // aipp檔案
├── pipeline
│ ├──unet_simple_opencv.pipeline // pipeline檔案
├── main.py // 推理檔案
├── run.sh // 執行檔案
├── requirements.txt // 需要的三方庫(2) 模型轉換
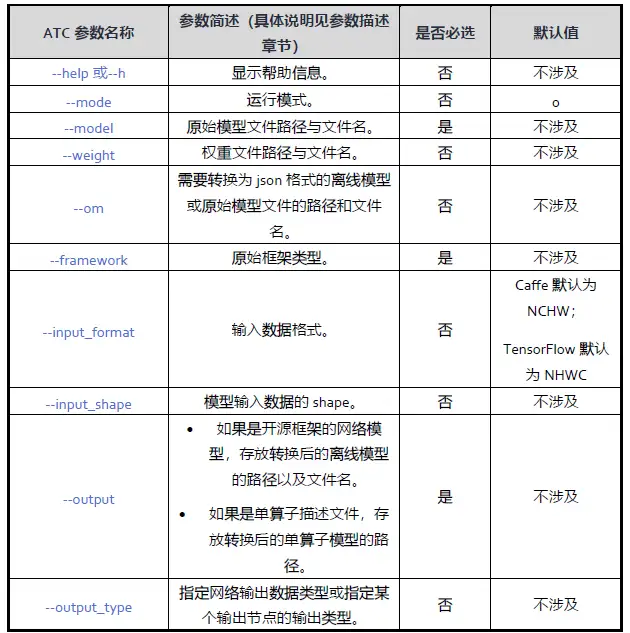
將unet_hw960_bs1.air模型轉為昇騰AI處理器支援的.om格式離線模型,此處模型轉換需要用到ATC工具。
昇騰張量編譯器(Ascend Tensor Compiler,簡稱ATC)是昇騰CANN架構體系下的模型轉換工具,它可以將開源框架的網路模型或Ascend IR定義的單運算元描述檔案(json格式)轉換為昇騰AI處理器支援的.om格式離線模型。模型轉換過程中可以實現運算元排程的優化、權值資料重排、記憶體使用優化等,可以脫離裝置完成模型的預處理。
ATC引數概覽:

(3)執行指令碼
執行指令碼:
cd unet_sdk/model/ # 切換至模型儲存目錄
atc --framework=1 --model=unet_hw960_bs1.air --output=unet_hw960_bs1 --input_format=NCHW --soc_version=Ascend310 --log=error --insert_op_conf=aipp_unet_simple_opencv.cfg- 注意air模型轉om只支援靜態batch,這裡batchsize=1。
引數說明:
framework:原始框架型別。
model:原始模型檔案路徑與檔名。
output:轉換後的離線模型的路徑以及檔名。
input_format:輸入資料格式。
soc_version:模型轉換時指定晶片版本。
log:顯示日誌的級別。
insert_op_conf:插入運算元的配置檔案路徑與檔名,這裡使用AIPP預處理配置檔案,用於影象資料預處理。輸出結果:
ATC run success,表示模型轉換成功,得到unet_hw960_bs1.om模型。
模型轉換成功之後,可以使用MindX SDK mxVision執行指令碼,在Ascend 310上進行推理。
(4) MindX SDK mxVision 執行推理
MindX SDK文件請參考:http://support.huaweicloud.com/ug-vis-mindxsdk203/atlasmx_02_0051.html
MindX SDK執行推理的業務流程:
通過stream配置檔案,Stream manager可識別需要構建的element以及element之間的連線關係,並啟動業務流程。Stream manager對外提供介面,用於向stream傳送資料和獲取結果,幫助使用者實現業務對接。
plugin表示業務流程中的基礎模組,通過element的串接構建成一個stream。buffer用於內部掛載解碼前後的視訊、影象資料,是element之間傳遞的資料結構,同時也允許使用者掛載元資料(Metadata),用於存放結構化資料(如目標檢測結果)或過程資料(如縮放後的影象)。
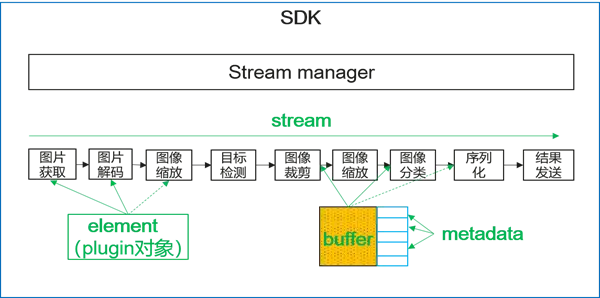
MindX SDK基礎概念介紹:
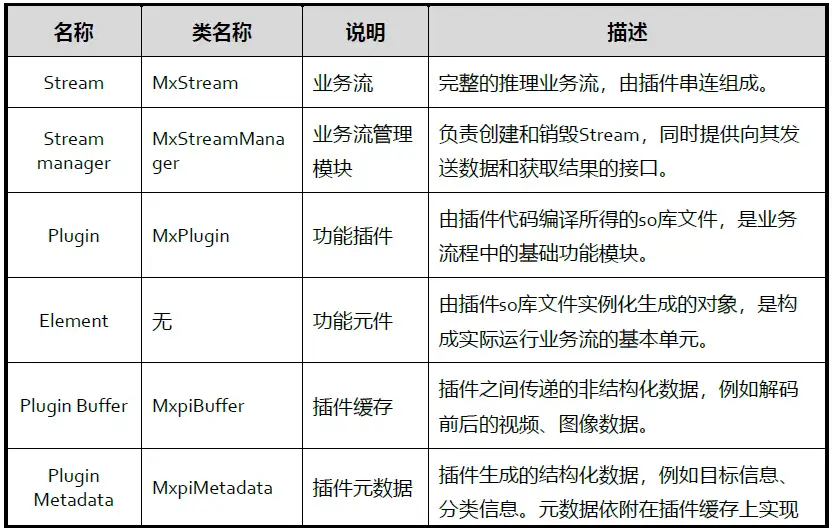

MindX SDK基礎外掛:
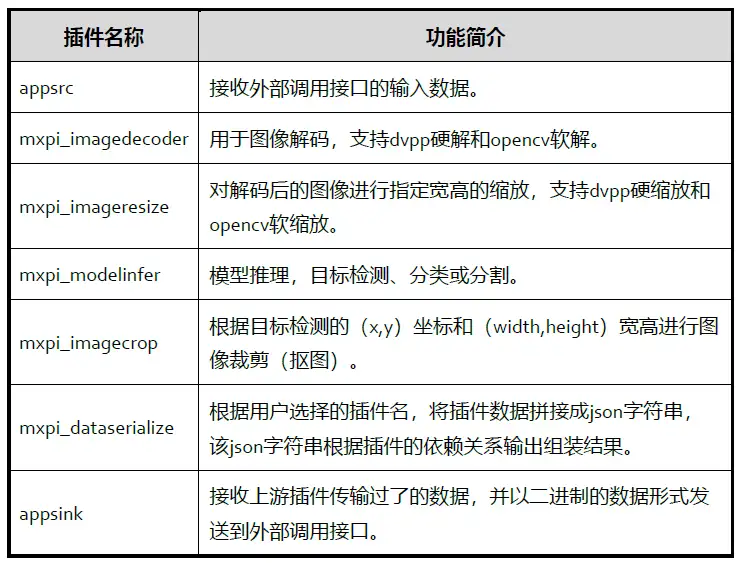
MindX SDK業務流程編排:
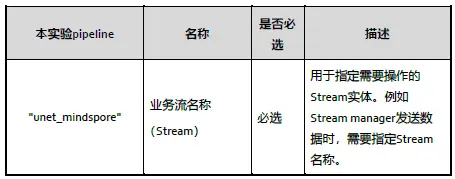
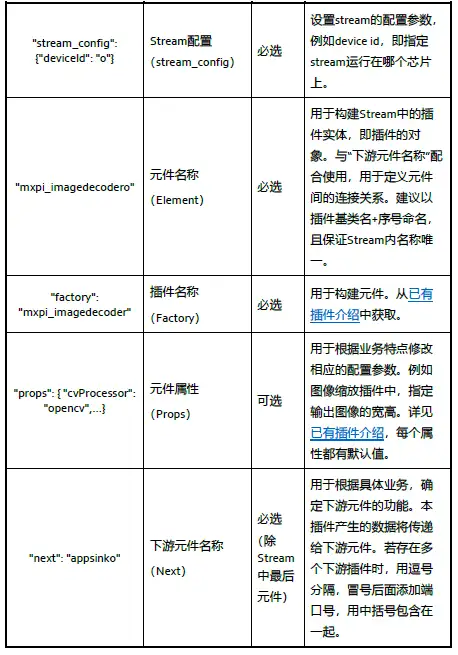
Stream配置檔案以json格式編寫,使用者必須指定業務流名稱、元件名稱和外掛名稱,並根據需要,補充元件屬性和下游元件名稱資訊。
以下表格為本實驗pipeline/unet_simple_opencv.pipeline檔案及其對應的名稱及描述:
pipeline/unet_simple_opencv.pipeline檔案內容如下,可根據實際開發情況進行修改。
{
"unet_mindspore": {
"stream_config": {
"deviceId": "0"
},
"appsrc0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsrc",
"next": "mxpi_imagedecoder0"
},
"mxpi_imagedecoder0": {
"props": {
"cvProcessor": "opencv",
"outputDataFormat": "BGR"
},
"factory": "mxpi_imagedecoder",
"next": "mxpi_imagecrop0"
},
"mxpi_imagecrop0": {
"props": {
"cvProcessor": "opencv",
"dataSource": "ExternalObjects"
},
"factory": "mxpi_imagecrop",
"next": "mxpi_imageresize0"
},
"mxpi_imageresize0": {
"props": {
"handleMethod": "opencv",
"resizeType": "Resizer_Stretch",
"resizeHeight": "960",
"resizeWidth": "960"
},
"factory": "mxpi_imageresize",
"next": "mxpi_tensorinfer0"
},
"mxpi_tensorinfer0": {
"props": {
"dataSource": "mxpi_imageresize0",
"modelPath": "model/unet_hw960_bs1_AIPP.om"
},
"factory": "mxpi_tensorinfer",
"next": "mxpi_dumpdata0"
},
"mxpi_dumpdata0": {
"props": {
"requiredMetaDataKeys": "mxpi_tensorinfer0"
},
"factory": "mxpi_dumpdata",
"next": "appsink0"
},
"appsink0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsink"
}
}
}(5) 修改modelPath
開啟pipeline/unet_simple_opencv.pipeline檔案,將"mxpi_tensorinfer0"元件的屬性"modelPath"(模型匯入路徑)修改為模型轉換後儲存的om模型"model/unet_hw960_bs1.om"。
修改結果:
"modelPath": "model/unet_hw960_bs1.om"modelPath修改完成之後,儲存pipeline/unet_simple_opencv.pipeline檔案。
StreamManagerApi:StreamManagerApi文件請參考:
http://support.huaweicloud.com/ug-vis-mindxsdk203/atlasmx_02_0320.html
StreamManagerApi用於對Stream流程的基本管理:載入流程配置、建立流程、向流程傳送資料、獲得執行結果、銷燬流程。
這裡用到的StreamManagerApi有:
- InitManager:初始化一個StreamManagerApi。
- CreateMultipleStreams:根據指定的配置建立多個Stream。
- SendData:向指定Stream上的輸入元件傳送資料(appsrc)。
- GetResult:獲得Stream上的輸出元件的結果(appsink)
- DestroyAllStreams:銷燬所有的流資料。
main.py檔案內容如下,可根據實際開發情況進行修改。
import argparse
import base64
import json
import os
import cv2
import numpy as np
from StreamManagerApi import *
import MxpiDataType_pb2 as MxpiDataType
x0 = 2200 # w:2200~4000; h:1000~2800
y0 = 1000
x1 = 4000
y1 = 2800
ori_w = x1 - x0
ori_h = y1 - y0
def _parse_arg():
parser = argparse.ArgumentParser(description="SDK infer")
parser.add_argument("-d", "--dataset", type=str, default="data/",
help="Specify the directory of dataset")
parser.add_argument("-p", "--pipeline", type=str,
default="pipeline/unet_simple_opencv.pipeline",
help="Specify the path of pipeline file")
return parser.parse_args()
def _get_dataset(dataset_dir):
img_ids = sorted(next(os.walk(dataset_dir))[1])
for img_id in img_ids:
img_path = os.path.join(dataset_dir, img_id)
yield img_path
def _process_mask(mask_path):
# 手動裁剪
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)[y0:y1, x0:x1]
return mask
def _get_stream_manager(pipeline_path):
stream_mgr_api = StreamManagerApi()
ret = stream_mgr_api.InitManager() #初始化stream
if ret != 0:
print(f"Failed to init Stream manager, ret={ret}")
exit(1)
with open(pipeline_path, 'rb') as f:
pipeline_content = f.read()
ret = stream_mgr_api.CreateMultipleStreams(pipeline_content) # 建立stream
if ret != 0:
print(f"Failed to create stream, ret={ret}")
exit(1)
return stream_mgr_api
def _do_infer_image(stream_mgr_api, image_path):
stream_name = b'unet_mindspore' # 與pipeline中stream name一致
data_input = MxDataInput()
with open(image_path, 'rb') as f:
data_input.data = f.read()
# 插入摳圖的功能,扣1800*1800大小
roiVector = RoiBoxVector()
roi = RoiBox()
roi.x0 = x0
roi.y0 = y0
roi.x1 = x1
roi.y1 = y1
roiVector.push_back(roi)
data_input.roiBoxs = roiVector
unique_id = stream_mgr_api.SendData(stream_name, 0, data_input) # 向指定Stream上的輸入元件傳送資料(appsrc)
if unique_id < 0:
print("Failed to send data to stream.")
exit(1)
infer_result = stream_mgr_api.GetResult(stream_name, unique_id) # 獲得Stream上的輸出元件的結果(appsink)
if infer_result.errorCode != 0:
print(f"GetResult error. errorCode={infer_result.errorCode},"
f"errorMsg={infer_result.data.decode()}")
exit(1)
# 用dumpdata獲取資料
infer_result_data = json.loads(infer_result.data.decode())
content = json.loads(infer_result_data['metaData'][0]['content'])
tensor_vec = content['tensorPackageVec'][0]['tensorVec'][1] # 1是argmax結果
data_str = tensor_vec['dataStr']
tensor_shape = tensor_vec['tensorShape']
argmax_res = np.frombuffer(base64.b64decode(data_str), dtype=np.float32).reshape(tensor_shape)
np.save("argmax_result.npy", argmax_res)
tensor_vec = content['tensorPackageVec'][0]['tensorVec'][0] # 0是softmax結果
data_str = tensor_vec['dataStr']
tensor_shape = tensor_vec['tensorShape']
softmax_res = np.frombuffer(base64.b64decode(data_str), dtype=np.float32).reshape(tensor_shape)
np.save("softmax_result.npy", softmax_res)
return softmax_res # ndarray
# 自定義dice係數和iou函式
def _calculate_accuracy(infer_image, mask_image):
mask_image = cv2.resize(mask_image, infer_image.shape[1:3])
mask_image = mask_image / 255.0
mask_image = (mask_image > 0.5).astype(np.int)
mask_image = (np.arange(2) == mask_image[..., None]).astype(np.int)
infer_image = np.squeeze(infer_image, axis=0)
inter = np.dot(infer_image.flatten(), mask_image.flatten())
union = np.dot(infer_image.flatten(), infer_image.flatten()) + \
np.dot(mask_image.flatten(), mask_image.flatten())
single_dice = 2 * float(inter) / float(union + 1e-6)
single_iou = single_dice / (2 - single_dice)
return single_dice, single_iou
def main(_args):
dice_sum = 0.0
iou_sum = 0.0
cnt = 0
stream_mgr_api = _get_stream_manager(_args.pipeline)
for image_path in _get_dataset(_args.dataset):
infer_image = _do_infer_image(stream_mgr_api, os.path.join(image_path, 'image.png')) # 摳圖並且reshape後的shape,1hw
mask_image = _process_mask(os.path.join(image_path, 'mask.png')) # 摳圖後的shape, hw
dice, iou = _calculate_accuracy(infer_image, mask_image)
dice_sum += dice
iou_sum += iou
cnt += 1
print(f"image: {image_path}, dice: {dice}, iou: {iou}")
print(f"========== Cross Valid dice coeff is: {dice_sum / cnt}")
print(f"========== Cross Valid IOU is: {iou_sum / cnt}")
stream_mgr_api.DestroyAllStreams() # 銷燬stream
if __name__ == "__main__":
args = _parse_arg()
main(args)run.sh檔案內容如下,可根據實際開發情況進行修改。參考SDK軟體包sample指令碼,需要按照實際路徑修改各個環境變數路徑。
set -e
CUR_PATH=$(cd "$(dirname "$0")" || { warn "Failed to check path/to/run.sh" ; exit ; } ; pwd)
# Simple log helper functions
info() { echo -e "\033[1;34m[INFO ][MxStream] $1\033[1;37m" ; }
warn() { echo >&2 -e "\033[1;31m[WARN ][MxStream] $1\033[1;37m" ; }
#export MX_SDK_HOME=${CUR_PATH}/../../..
export LD_LIBRARY_PATH=${MX_SDK_HOME}/lib:${MX_SDK_HOME}/opensource/lib:${MX_SDK_HOME}/opensource/lib64:/usr/local/Ascend/ascend-toolkit/latest/acllib/lib64:${LD_LIBRARY_PATH}
export GST_PLUGIN_SCANNER=${MX_SDK_HOME}/opensource/libexec/gstreamer-1.0/gst-plugin-scanner
export GST_PLUGIN_PATH=${MX_SDK_HOME}/opensource/lib/gstreamer-1.0:${MX_SDK_HOME}/lib/plugins
#to set PYTHONPATH, import the StreamManagerApi.py
export PYTHONPATH=$PYTHONPATH:${MX_SDK_HOME}/python
python3 main.py
exit 0(6) 執行指令碼
啟用mxVision環境變數(本作業無需此步驟):
. /root/mxVision/set_env.sh執行指令碼:
cd /root/unet_sdk/ # 切換至推理指令碼目錄
bash run.sh 執行截圖如下:
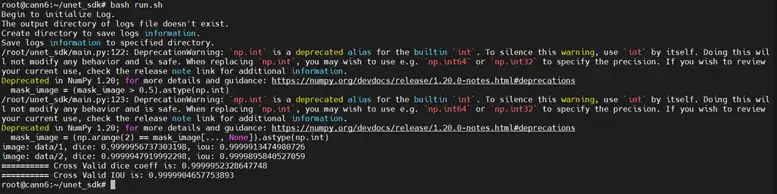
通過MindStudio執行,會自動上傳程式碼到預設路徑,並執行,執行結果如下:
MindStudio專家系統工具
專家系統工具當前支援專家系統自有知識庫和生態知識庫對模型/運算元進行效能分析,支援效能調優一鍵式閉環實現一鍵式效能問題優化能力。
專家系統自有知識庫當前提供的功能:基於Roofline模型的運算元瓶頸識別與優化建議、基於Timeline的AI CPU運算元優化、運算元融合推薦、TransData運算元識別和運算元優化分析。
生態知識庫的專家系統效能調優功能:由生態開發者使用Python程式語言進行開發,使用者通過呼叫專家系統提供的介面,對生態開發者提供的模型/運算元進行效能分析。
MindStudio IDE當前版本僅支援的生態知識庫建立功能,可以在上面完成生態知識庫程式碼開發,暫不支援對生態知識庫的專家系統分析功能。效能調優一鍵式閉環提供一鍵式效能問題分析和優化能力,有效提升使用者效能分析和優化效率。
下面介紹如何使用專家系統工具對模型和運算元進行效能瓶頸識別並輸出優化建議。
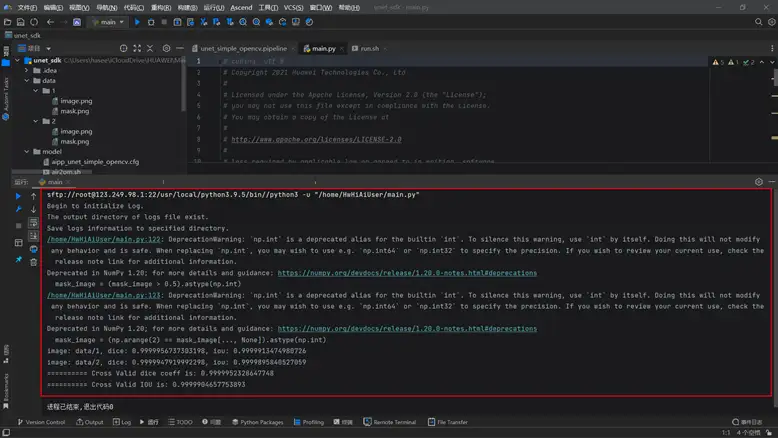
1. 單擊選單欄“Ascend > Advisor”,彈出專家系統工具介面 。如圖所示。

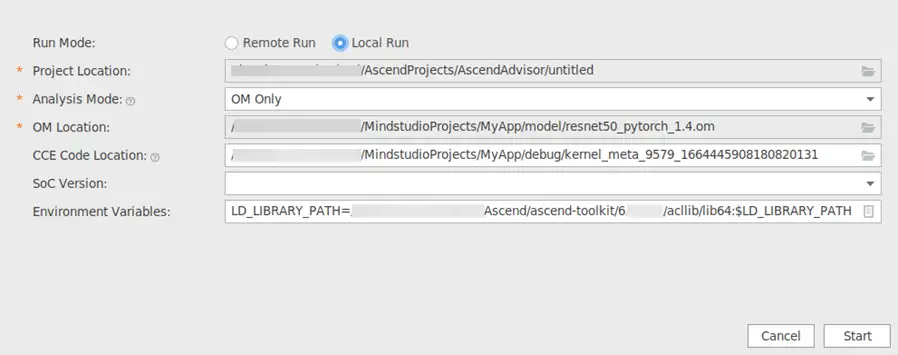
2. 單擊上圖介面左上角紅框中的按鈕,開啟專家系統配置介面,各引數配置示例如圖所示。
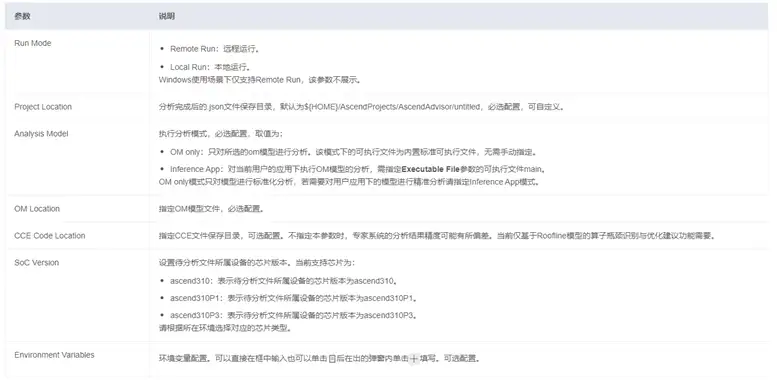
各引數具體說明如下:
3. 配置完成後單擊“Start”啟動分析。
之後開始執行,如圖所示,具體時間與網路情況有關。
執行完成後,會自動跳轉到如下圖所示介面。
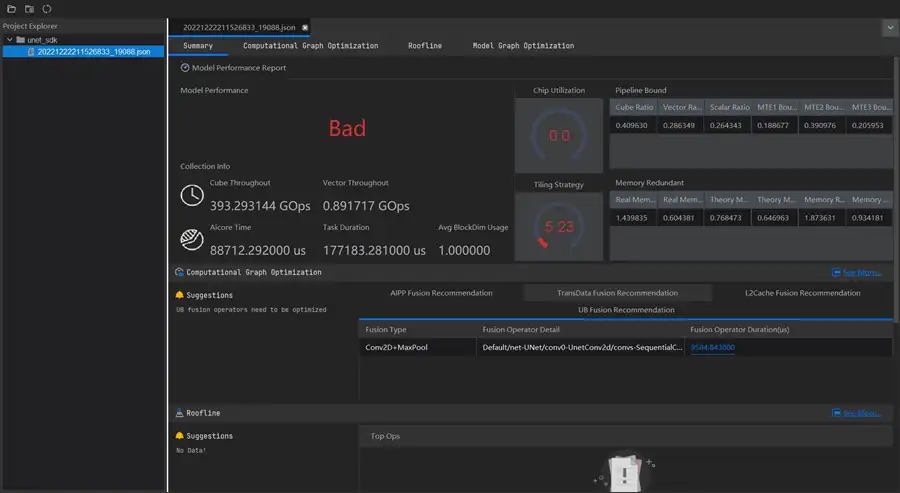
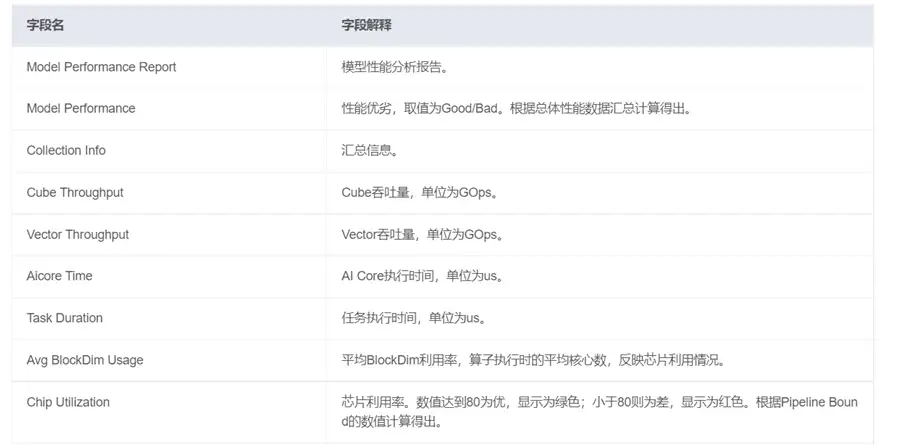
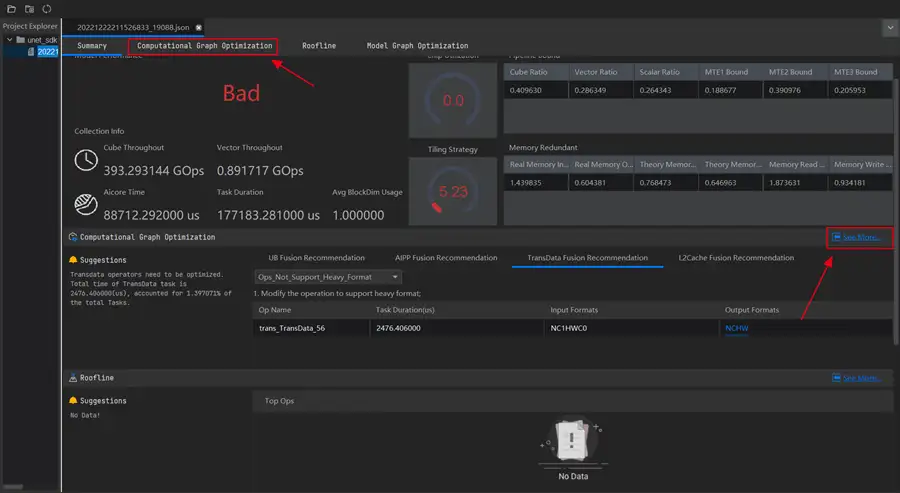
這裡的Model Performance Report是模型效能的總結報告。根據該頁面,可以知道模型效能是好是壞,也可以知道模型的吞吐率和執行時間,AI Core的利用率,Tiling策略是否合理,部分欄位說明如下所示,,具體可參見http://www.hiascend.com/document/detail/zh/mindstudio/50RC3/msug/msug_000285.html。
從上述截圖的分析結果可以看出我們所用的U-Net模型的晶片利用率是偏低的,甚至可以說是很差,有很大的優化的空間。下面我們來詳細分析。

先來看根據總體效能資料彙總計算得出的Model Performance,顯示為Bad,情況不樂觀啊。接著看看彙總資訊。
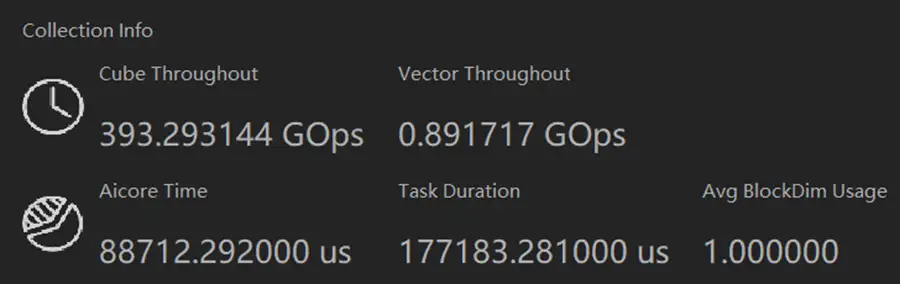
可以看到Cube吞吐量Cube Throughput約393 GOps,Vector吞吐量Vector Throughput約0.89 GOps,AI Core執行時間88712us,任務執行時間177183us,平均BlockDim利用率Avg BlockDim Usage,運算元執行時的平均核心數,數值為1,這反映了反映晶片利用情況,考慮到我們ECS的Ascend 310總計2個AI Core,且由系統自動排程,這裡為1還可以接收。但下面的資料可難看了。

如圖所示,晶片利用率Chip Utilization。按照規則,80為優,顯示為綠色;小於80則為差,顯示為紅色。根據Pipeline Bound的數值計算得出。而我們這裡直接為0了。再看Cube利用率Cube Ratio約為0.41,Vector利用率Vector Ratio約為0.29,Scalar利用率Scalar Ratio約為0.26,還有優化空間,而MTE1瓶頸、MTE2瓶頸、MTE3瓶頸都還不小。特別是MTE2瓶頸,約為0.39。下面接著看。

來看記憶體讀入量的資料切片策略Tiling Strategy為5.23,情況糟糕。根據規則,數值達到80為優,顯示為綠色;小於80則為差,顯示為紅色。這是根據Memory Redundant的數值計算得出。同時,可以看到真實記憶體讀入量Real Memory Input(GB)約為1.44GB,真實記憶體寫出量Real Memory Output(GB)約為0.60GB,都在可用範圍內。
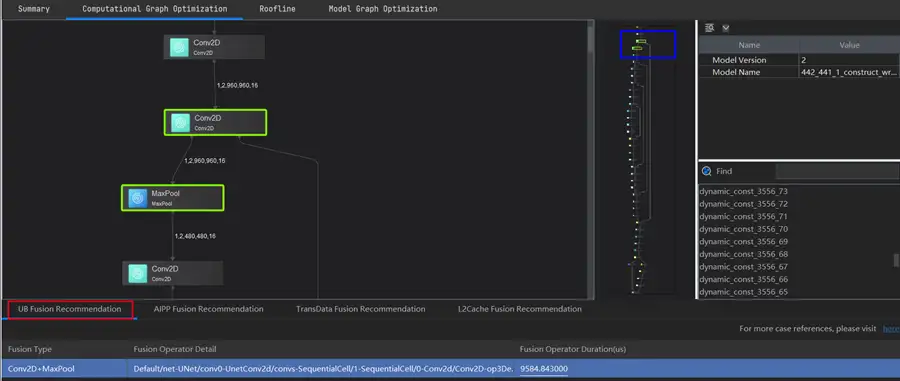
接下來進入Computational Graph Optimization介面,如圖紅框所示兩處都可以,二者就是簡版和精裝版的區別了。在這裡,我們可以看到計算圖優化,運算元融合推薦功能專家系統分析建議,會分行展示可融合的運算元。
先來看看需要進行UB融合的運算元,點選運算元,會自動跳轉相應的計算圖,既直觀又方便啊。同時我們看到可融合運算元的執行時間Fusion Operator Duration達到了約9585us,接近10ms了,算是比較大了。本模型沒有AIPP融合推薦和L2Cache融合推薦。
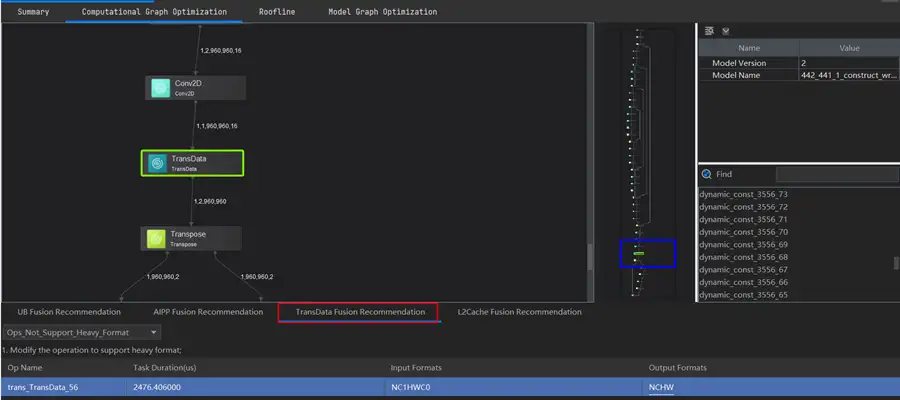
我們直接看TransData運算元融合推薦,如圖所示。該運算元執行持續時間在2.5ms左右,也不算小了,也是一個值得優化的地方啊。
但遺憾的是本次Roofline頁面(基於Roofline模型的運算元瓶頸識別與優化建議功能輸出結果)和Model Graph Optimization頁面(基於Timeline的AICPU運算元優化功能輸出結果)都沒什麼結果展示,具體分別如下圖所示。
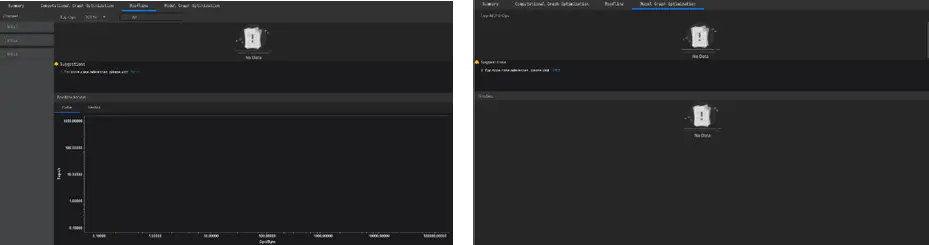
這裡提個建議,看了下執行日誌(顯示了這一句[ERROR] Analyze model(RooflineModel) failed, please check dfx log.),Roofline之所以沒有結果顯示,可能是Roofline執行失敗,不過這個日誌有點太簡潔了,不太友好,也沒有給出 dfx log的具體路徑或位置,哪怕彈出一個連結給使用者,讓使用者去自行查詢呢,這都沒有,感覺介面不太友好啊。
專家系統提供對推理模型和運算元的效能瓶頸分析能力並輸出專家建議,但實際效能調優還需使用者自行修改,不能做到效能調優一鍵式閉環。而效能調優一鍵式閉環提供一鍵式效能問題分析和優化能力,有效提升使用者效能分析和優化效率。同時,效能調優一鍵式閉環當前實現生態知識庫ONNX模型的部分推理場景瓶頸識別和自動化調優能力。
但這需要準備待優化的ONNX模型檔案(.onnx)以及ONNX模型經過ATC轉換後的OM模型檔案(.om),而我們這次是.air模型轉om模型,雖然可以獲得onnx模型,但太麻煩了,我們這次就不嘗試了。
這裡再提個建議,效能調優一鍵式閉環還需要下載ONNX模型調優知識庫,我按照文件(文件連結:http://www.hiascend.com/document/detail/zh/mindstudio/50RC3/msug/msug_000303.html)中提供Link跳轉下載(如下圖所示),未能找到文件後續所說的KnowledgeBase Configuration知識庫配置檔案echosystem.json。不知道是不是我的問題,建議工程師看看,驗證一下。
MindStudio Profiling工具
Profiling作為專業的昇騰AI任務效能分析工具,其功能涵蓋AI任務執行時關鍵資料採集和效能指標分析。熟練使用Profiling,可以快速定位效能瓶頸,顯著提升AI任務效能分析的效率。
下面介紹使用Profiling工具採集效能資料並作簡單的效能資料分析。
1. 更換python連結(可選)
這裡先給大家排下雷,如果大家遇到如下報錯,那麼按照下面的操作修復下就行了,報錯資訊如下圖所示:

個人認為,這應該是本地電腦沒安裝Python或者安裝了,但是沒有新增到系統Path,以致無法呼叫,這應該Profiling需要在Windows上呼叫Python做一些操作,但無法呼叫Python導致的。那麼我們只要安裝Python的時候,選擇新增到Path,或者已經安裝Python的同學,將Python新增到Path,最終使得能夠在Windows終端下直接呼叫Python即可。最終效果示例如下:

此外,因為ECS終端預設啟動的Python是/usr/bin/python,而在ECS預設是Python2直接執行程式會報錯,而我們需要用Python3,所以需要重新連結符號,具體流程為:刪除python連結檔案–>>新建連結檔案到python3,下面是操作步驟:

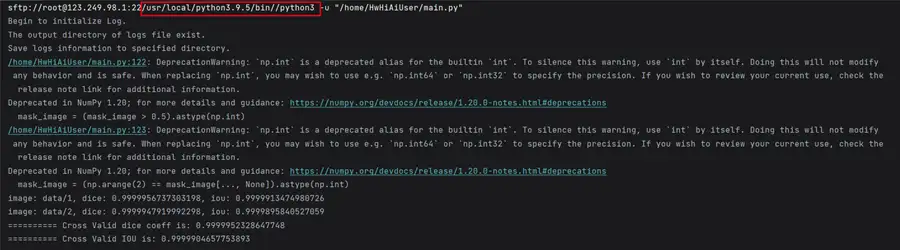
那麼有人可能就要問了,為什麼是/usr/local/python3.9.5/bin/python3呢?因為我們在通過MindStudio直接在遠端ECS上執行的時候,就是用的這個啊,來張圖看看:
這裡提個建議,我之前執行會報錯,詳情見http://www.hiascend.com/forum/thread-0229107014330773104-1-1.html,連著兩天重啟,試了好幾次,就是不行,後來又試了一次,突然就可以了,感覺很奇怪,莫明其妙地報錯,莫名其秒地好了,這給我一種IDE很不穩定的感覺。建議優化一下,提升下穩定性。
2. 執行Profiling採集
(1)單擊選單欄“Ascend > System Profiler > New Project”,彈出Profiling配置視窗 。
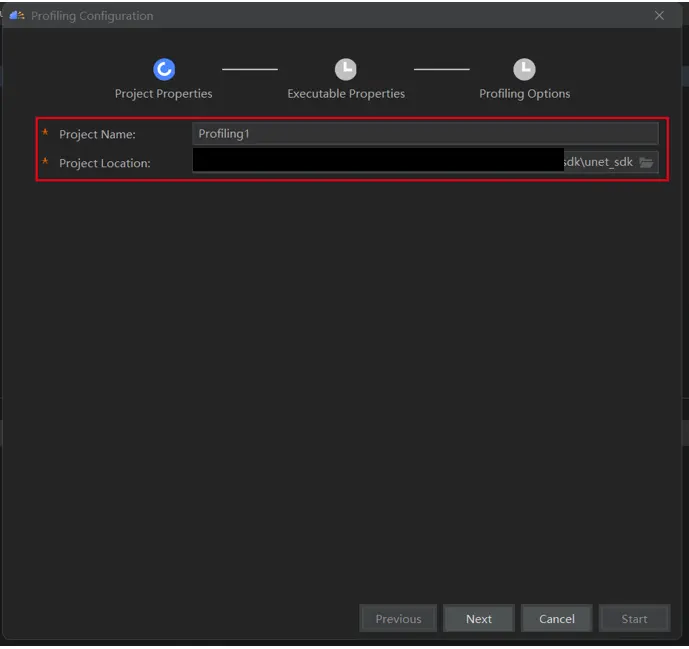
配置“Project Properties”,配置工程名稱“Project Name”和選擇工程路徑“Project Location”。單擊“Next”進入下一步。
(2)進入“Executable Properties”配置介面。
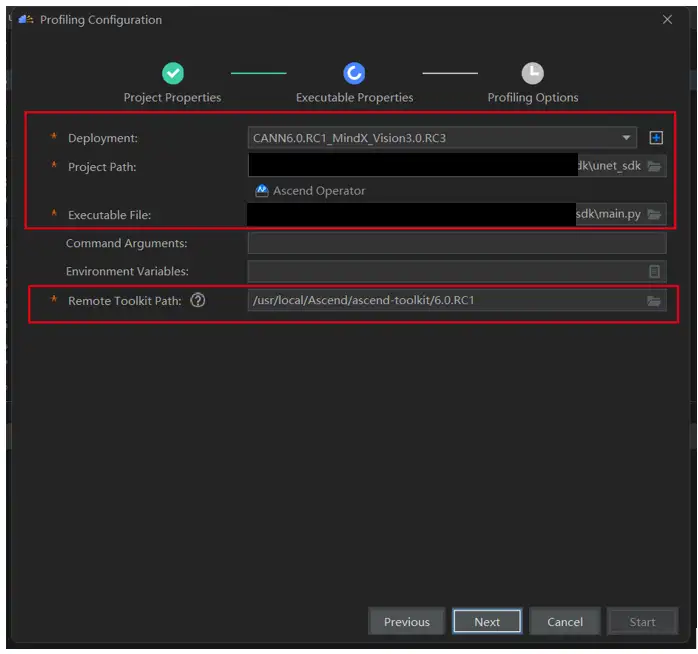
(3)進入“Profiling Options”配置介面,配置項按預設配置
完成上述配置後單擊視窗右下角的“Start”按鈕,啟動Profiling。工程執行完成後,MindStudio自動彈出Profiling結果檢視。
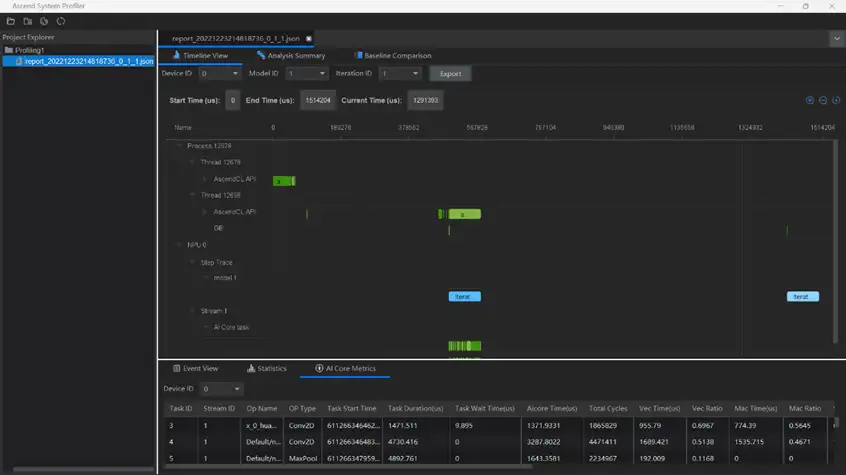
先來看下全量迭代耗時資料,在Timeline檢視下檢視Step Trace資料迭代耗時情況,識別耗時較長迭代進行分析。注意,可選擇匯出對應迭代Timeline資料,單擊耗時較長迭代按鈕彈出對話方塊,單擊“Yes”匯出對應迭代Timeline資料。如圖所示,如果最初看不見,建議將滑鼠放到圖上,之後滑動放大,就能看見了。
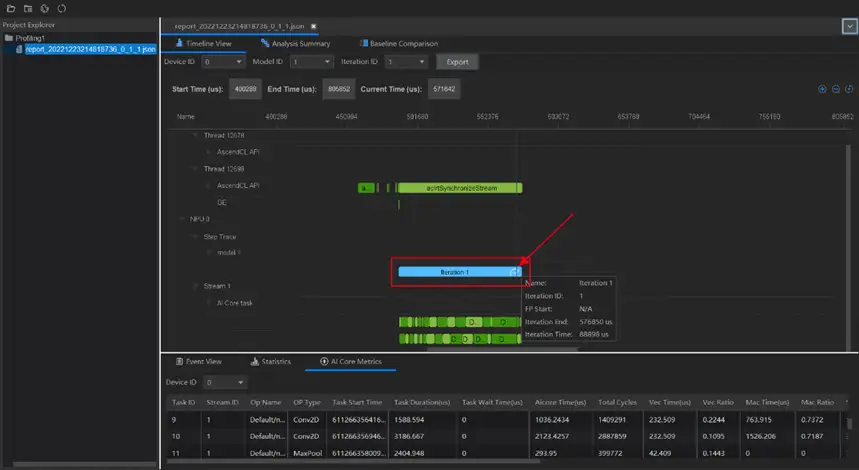
還可以檢視迭代內耗時情況:存在較長耗時運算元時,可以進一步找運算元詳細資訊輔助定位;存在通訊耗時或排程間隙較長時,分析呼叫過程中介面耗時。如圖所示。
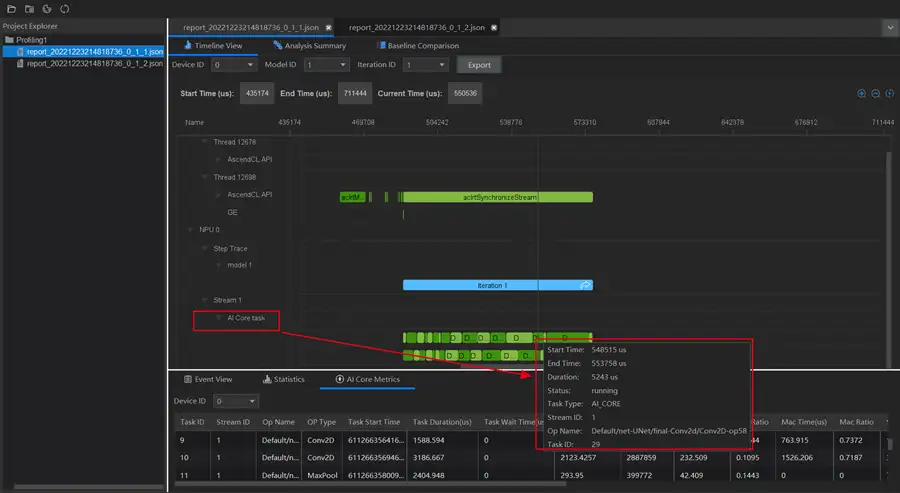
在介面下方還能檢視對應的運算元統計表:檢視迭代內每個AICORE和AICPU運算元的耗時及詳細資訊,進一步定位分析運算元的Metrics指標資料,分析運算元資料搬運、執行流水的佔比情況,識別運算元瓶頸點。
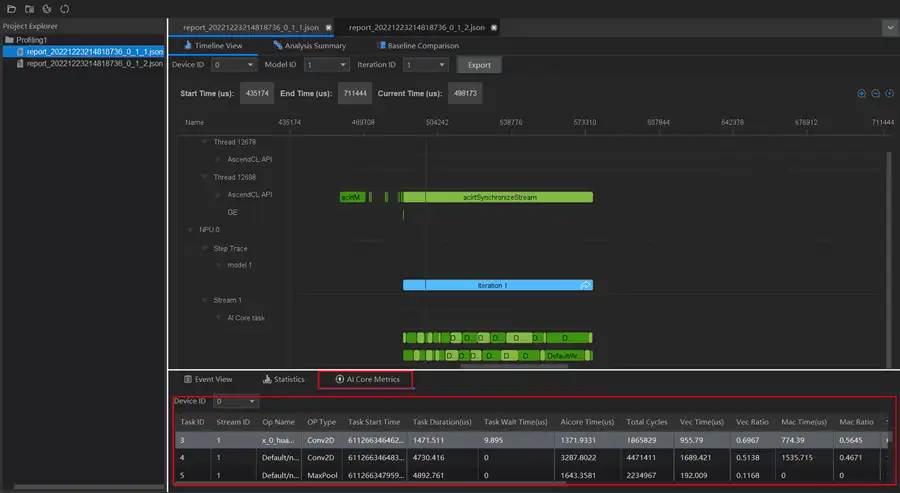
此外,這裡還能檢視元件介面耗時統計表:檢視迭代內AscendCL API和Runtime API的介面耗時情況,輔助分析介面呼叫對效能的影響。
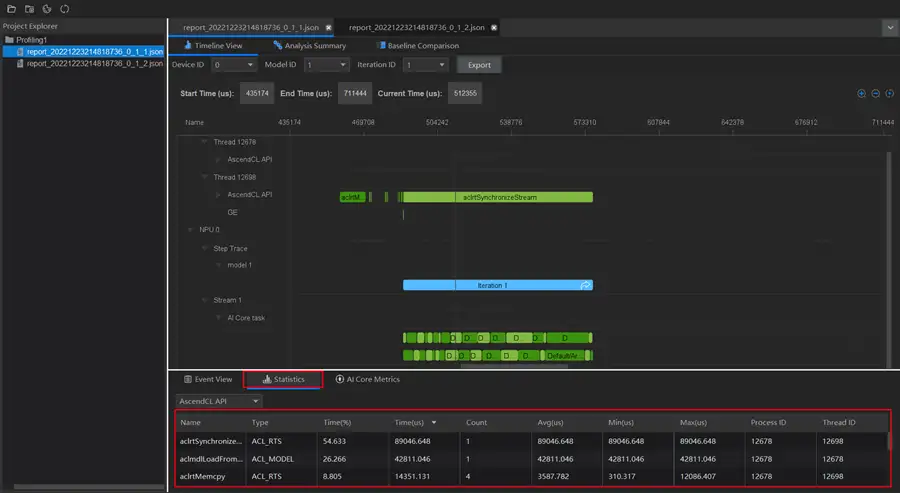
這個要說一下,限於螢幕大小,上述這次資料的完整展示,可能需要放大或縮小,或者調整某些部分大小,這些操作很卡頓,操作起來沒什麼反應,彷彿這個介面卡死了,可用性差,使用者體驗不好,建議優化一下。
我們可以看到下圖中這個Op的Task Wait Time要9.895us,而其他Op基本為0,所以可以考慮試試能不能減少這個Wait Time,從而提升效能。

這裡說一下,上圖中這個Op Name很長,我需要將這欄橫向拉伸很長才能完整顯示,這有點麻煩,我本來想將滑鼠懸停此處,讓其自動顯示完整名稱,但好像不行,能否考慮加一下這個懸停顯示全部內容的操作,否則我要先拉伸看,之後再拉回去看其他,比較麻煩。
還記得之前我們在專家系統工具那時提到的MTE2瓶頸相比之下有些大(約0.39)嘛?這裡從下圖看到Mte2時間較長,約3.7ms,說一下,mte2型別指令應該是DDR->AI Core搬運類指令,這裡我們量化一下看看,如下圖所示,AI Core時間約為6.8ms,但Task Duration約12.5ms,幾乎翻倍了,說明我們Task只有約一半時間是真正用於AI Core計算,很明顯很多時間被浪費了。


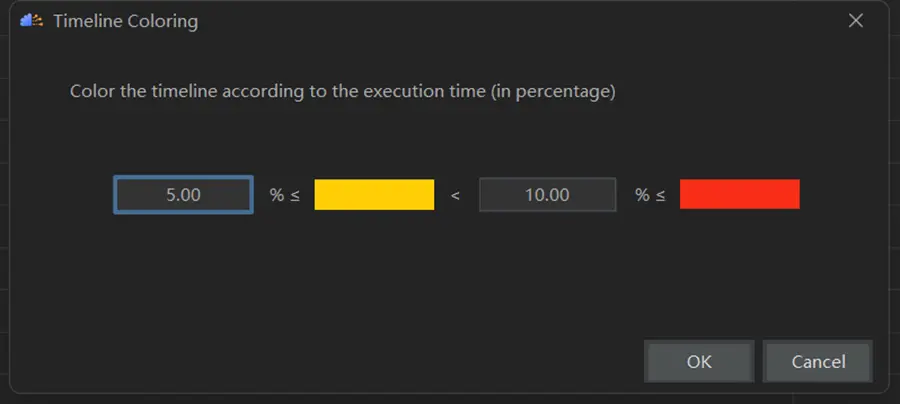
說明這一點還是比較值得優化的。而各個工具之間也是可以相互輔助,相互驗證更好地幫助我們定位問題。下面我們再看看,先確認下Timeline顏色配置調色盤,如下圖所示。而我們之前看到的Timeline基本是綠色,未見黃色或紅色,估計沒什麼優化空間了。還是優先做明顯地值得優化地點吧,這也算抓大放小吧。
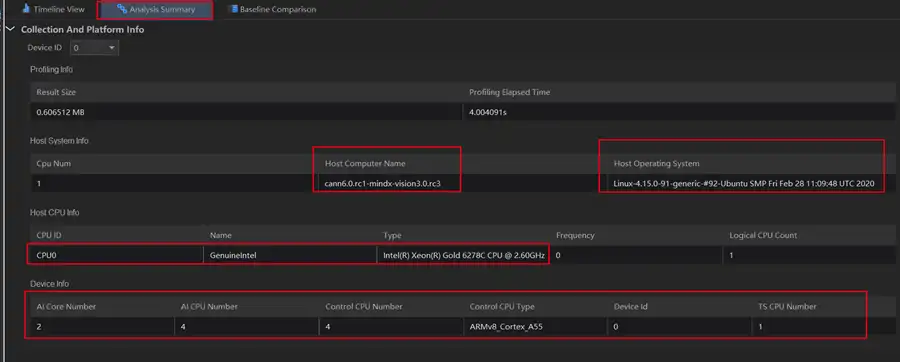
好了,我們再看點其他的,比如Analysis Summary,這裡展示了比較詳細的軟硬體資訊,比如Host Computer Name、Host Operating System等,還有我們ECS上用的CPU的詳細資訊,包括型號、邏輯核心數量等,令我感興趣的是,還有Ascend 310的資訊,包括AI Core數量2, AI CPU數量4,Control CPU數量4,Control CPU Type為ARMv8_Cortex_A55,以及一個TS CPU,很詳細了,很好地展示了Ascend 310的內部硬體資訊,更有助於我們瞭解這款處理器。
同時,再來看看Baseline Comparison吧。
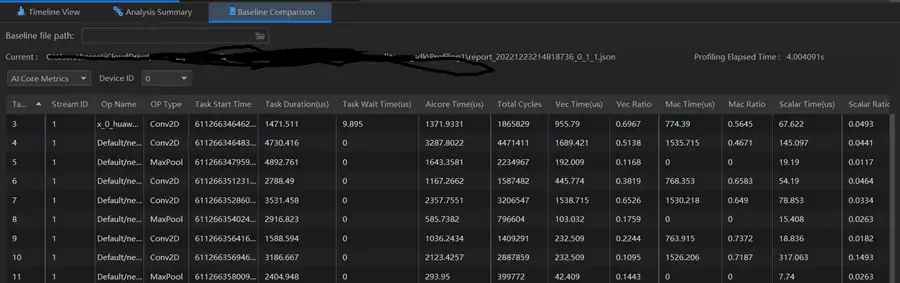
總的來說,MindStudio提供了Host+Device側豐富的效能資料採集能力和全景Timeline互動分析能力,展示了Host+Device側各項效能指標,幫助使用者快速發現和定位AI應用、晶片及運算元的效能瓶頸,包括資源瓶頸導致的AI演算法短板,指導演算法效能提升和系統資源利用率的優化。MindStudio支援Host+Device側的資源利用視覺化統計分析,具體包括Host側CPU、Memory、Disk、Network利用率和Device側APP工程的硬體和軟體效能資料。
通過Profiling效能分析工具前後兩次對網路應用推理的執行時間進行分析,並對比兩次執行時間可以得出結論,可以幫助我們去驗證替換函式或運算元後,是否又效能提升,是否提升了推理效率。此外,還可以幫助我們挑選應該優先選擇的網路模型,或者測試自定義運算元是否達到最優效能,是否還存在優化空間等等,還是挺有用的。
MindStudio精度比對工具
1. 定義
為了幫助開發人員快速解決運算元精度問題,需要提供自有實現的運算元運算結果與業界標準運算元運算結果之間進行精度差異對比的工具。
2. 功能
提供Tensor比對能力,包含餘弦相似度、歐氏相對距離、絕對誤差(最大絕對誤差、平均絕對誤差、均方根誤差)、相對誤差(最大相對誤差、平均相對誤差、累積相對誤差)、KL散度、標準差演算法比對維度。
- 使用卷積神經網路實現圖片去摩爾紋
- 核心不中斷前提下,Gaussdb(DWS)記憶體報錯排查方法
- 簡述幾種常用的排序演算法
- 自動調優工具AOE,讓你的模型在昇騰平臺上高效執行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及程式碼實現
- CosineWarmup理論與程式碼實戰
- 淺談DWS函數出參方式
- 程式碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種資料預處理的方式:AIPP和DVPP
- 詳解ResNet 網路,如何讓網路變得更“深”了
- 帶你掌握如何檢視並讀懂昇騰平臺的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網路卷積層?
- 在昇騰平臺上對TensorFlow網路進行效能調優
- 介紹3種ssh遠端連線的方式
- 分散式資料庫架構路線大揭祕
- DBA必備的Mysql知識點:資料型別和運算子
- 5個高併發導致數倉資源類報錯分析