DevOps整合Jenkins+k8s+CICD
作者:大蝦別跑 原文連結:http://blog.csdn.net/qq_35583325/article/details/126936804
轉自:IT運維技術圈
一、DevOps介紹
軟體開發最開始是由兩個團隊組成:
開發計劃由開發團隊從頭開始設計和整體系統的構建。需要系統不停的迭代更新。
運維團隊將開發團隊的Code進行測試後部署上線。希望系統穩定安全執行。
這看似兩個目標不同的團隊需要協同完成一個軟體的開發。
在開發團隊指定好計劃並完成coding後,需要提供到運維團隊。
運維團隊向開發團隊反饋需要修復的BUG以及一些需要返工的任務。
這時開發團隊需要經常等待運維團隊的反饋。這無疑延長了事件並推遲了整個軟體開發的週期。
會有一種方式,在開發團隊等待的時候,讓開發團隊轉移到下一個專案中。等待運維團隊為之前的程式碼提供反饋。
可是這樣就意味著一個完整的專案需要一個更長的週期才可以開發出最終程式碼。
基於現在的網際網路現狀,更推崇敏捷式開發,這樣就導致專案的迭代速度更快,但是由於開發團隊與運維團隊的溝通問題,會導致新版本上線的時間成本很高。這又違背的敏捷式開發的最初的目的。
那麼如果讓開發團隊和運維團隊整合到成一個團隊,協同應對一套軟體呢?這就被稱為DevOps。
DevOps,字面意思是Development &Operations的縮寫,也就是開發&運維。
然字面意思只涉及到了開發團隊和運維團隊,其實QA測試團隊也是參與其中的。
網上可以檢視到DevOps的符號類似於一個無窮大的符號
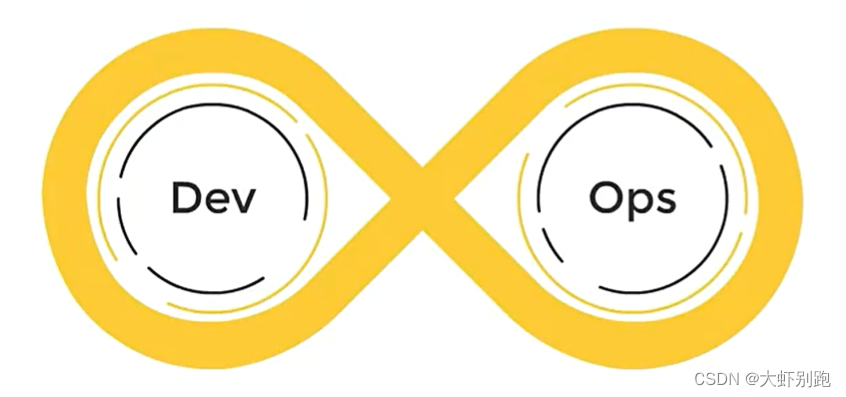
這表明DevOps是一個不斷提高效率並且持續不斷工作的過程
DevOps的方式可以讓公司能夠更快地應對更新和市場發展變化,開發可以快速交付,部署也更加穩定。
核心就在於簡化Dev和Ops團隊之間的流程,使整體軟體開發過程更快速。
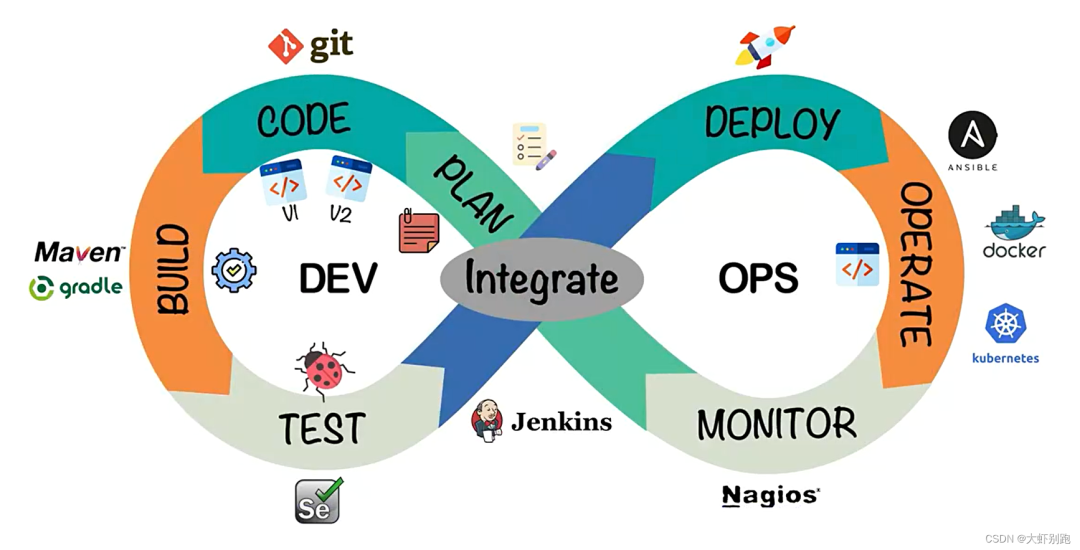
整體的軟體開發流程包括:
PLAN:開發團隊根據客戶的目標制定開發計劃
CODE:根據PLAN開始編碼過程,需要將不同版本的程式碼儲存在一個庫中。
BUILD:編碼完成後,需要將程式碼構建並且執行。
TEST:成功構建專案後,需要測試程式碼是否存在BUG或錯誤。
DEPLOY:程式碼經過手動測試和自動化測試後,認定程式碼已經準備好部署並且交給運維團隊。
OPERATE:運維團隊將程式碼部署到生產環境中。
MONITOR:專案部署上線後,需要持續的監控產品。
INTEGRATE:然後將監控階段收到的反饋傳送回PLAN階段,整體反覆的流程就是DevOps的核心,即持續整合、持續部署。
為了保證整體流程可以高效的完成,各個階段都有比較常見的工具,如下圖:
最終可以給DevOps下一個定義:DevOps 強調的是高效組織團隊之間如何通過自動化的工具協作和溝通來完成軟體的生命週期管理,從而更快、更頻繁地交付更穩定的軟體。
自動化的工具協作和溝通來完成軟體的生命週期管理
二、安裝git工具
serverA主機安裝
在code階段,我們需要將不同版本的程式碼儲存到一個倉庫中,常見的版本控制工具就是SVN或者Git,這裡我們採用Git作為版本控制工具,GitLab作為遠端倉庫。
2.1 Git安裝
https://git-scm.com/(傻瓜式安裝)
2.2 GitLab安裝
單獨準備伺服器,採用Docker安裝
檢視GitLab映象
docker search gitlab
拉取GitLab映象
docker pull gitlab/gitlab-ce
準備docker-compose.yml檔案
mkdir -p /data/git
vim /data/git/docker-compose.yml
version: '3.1'
services:
gitlab:
image: 'gitlab/gitlab-ce:latest'
container_name: gitlab
restart: always
environment:
GITLAB_OMNIBUS_CONFIG: |
external_url 'http://10.1.100.225:8929'#自己安裝git的伺服器IP
gitlab_rails['gitlab_shell_ssh_port'] = 2224
ports:
- '8929:8929'
- '2224:2224'
volumes:
- './config:/etc/gitlab'
- './logs:/var/log/gitlab'
- './data:/var/opt/gitlab'
啟動容器(需要稍等一小會……)
docker-compose up -d
訪問GitLab首頁
http://10.1.100.225:8929
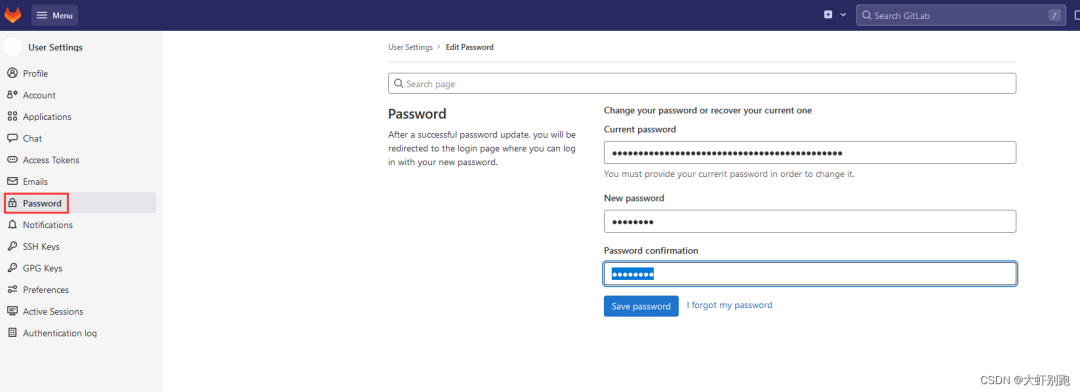
檢視root使用者初始密碼
docker exec -it gitlab cat /etc/gitlab/initial_root_password
第一次登入後需要修改密碼
三、安裝jdk 、maven、Jenkins
1.安裝jdk 和maven
JDK包下載地址:Java Downloads | Oracle
MAven下載地址:Maven – Download Apache Maven
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local/
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /usr/local/
cd /usr/local
mv apache-maven-3.6.3/ maven
mv jdk1.8.0_231/ jdk
1.1 編輯maven配置
vim /usr/local/maven/conf/settings.xml
<!--#maven配置阿里雲倉庫,在159行插入-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
<!--#maven配置jdk,在252行插入-->
<profile>
<id>jdk1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile>
<!--#maven配置jdk,在257行插入-->
<activeProfiles>
<activeProfile>jdk1.8</activeProfile>
</activeProfiles>
2.Jenkins介紹
Jenkins是一個開源軟體專案,是基於Java開發的一種持續整合工具
Jenkins應用廣泛,大多數網際網路公司都採用Jenkins配合GitLab、Docker、K8s作為實現DevOps的核心工具。
Jenkins最強大的就在於外掛,Jenkins官方提供了大量的外掛庫,來自動化CI/CD過程中的各種瑣碎功能。


Jenkins最主要的工作就是將GitLab上可以構建的工程程式碼拉取並且進行構建,再根據流程可以選擇釋出到測試環境或是生產環境。
一般是GitLab上的程式碼經過大量的測試後,確定發行版本,再發布到生產環境。
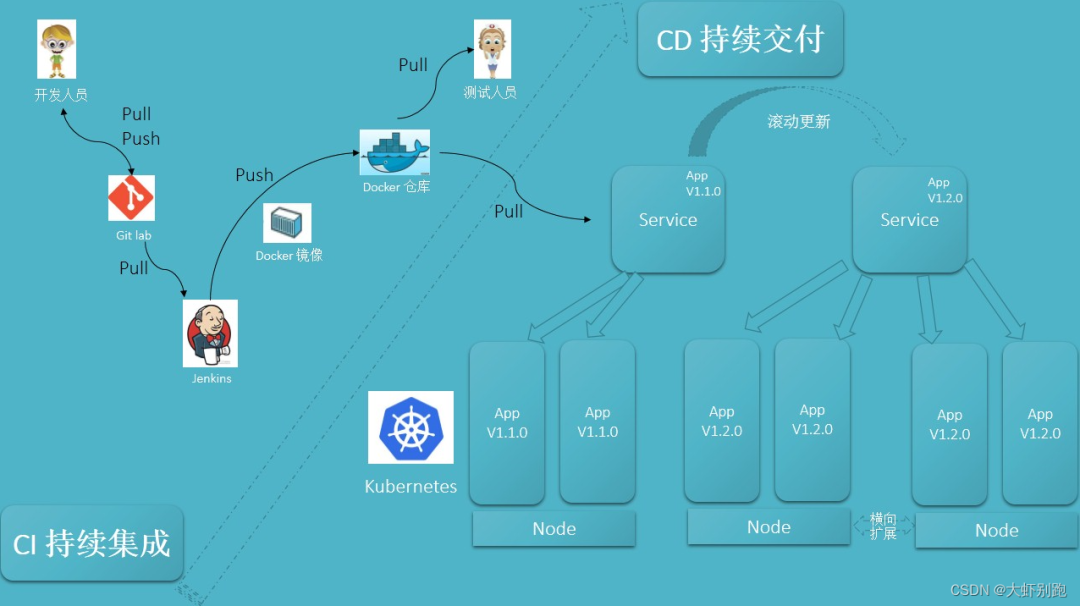
CI/CD可以理解為:
CI過程即是通過Jenkins將程式碼拉取、構建、製作映象交給測試人員測試。
持續整合:讓軟體程式碼可以持續的整合到主幹上,並自動構建和測試。
CD過程即是通過Jenkins將打好標籤的發行版本程式碼拉取、構建、製作映象交給運維人員部署。
持續交付:讓經過持續整合的程式碼可以進行手動部署。
持續部署:讓可以持續交付的程式碼隨時隨地的自動化部署
2.0下載jenkins
docker pull jenkins/jenkins:2.319.1-lts
vim /data/jenkins/docker-compose.yml
version: "3.1"
services:
jenkins:
image: jenkins/jenkins
container_name: jenkins
ports:
- 8080:8080
- 50000:50000
volumes:
- ./data/:/var/jenkins_home/
- /var/run/docker.sock:/var/run/docker.sock
- /usr/bin/docker:/usr/bin/docker
- /etc/docker/daemon.json:/etc/docker/daemon.json
2.1啟動jenkins
#修改Jenkins使用者許可權
cd /var/run
chown root:root docker.sock
#其他使用者有讀和寫許可權
chmod o+rw docker.sock
cd /data/jenkins/
docker-compose up -d
#授權
chmod 777 data/
cat /data/jenkins/data/hudson.model.UpdateCenter.xml
#重新啟動Jenkins容器後,由於Jenkins需要下載大量內容,但是由於預設下載地址下載速度較慢,
#需要重新設定下載地址為國內映象站# 清華大學的外掛源也可以
# 修改資料卷中的hudson.model.UpdateCenter.xml檔案
# 將下載地址替換為http://mirror.esuni.jp/jenkins/updates/update-center.json
# 清華大學的外掛源也可以
#http://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
#重啟
docker-compose restart
#檢視日誌
docker logs -f jenkins
2.2訪問頁面
http://10.1.100.225:8080
1.輸入密碼2.選擇外掛來安裝3.點選安裝
英文介面安裝外掛 Manage Jenkins–Manage Plugins-Available搜尋外掛
Locale
Localization
Git Parameter
Publish Over SSH
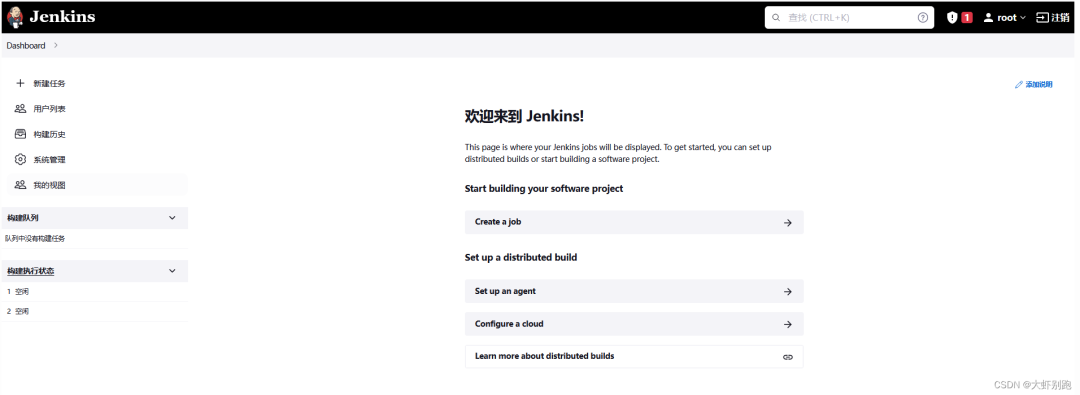
2.3 配置jenkins
mv /usr/local/maven/ /data/jenkins/data/
mv /usr/local/jdk/ /data/jenkins/data/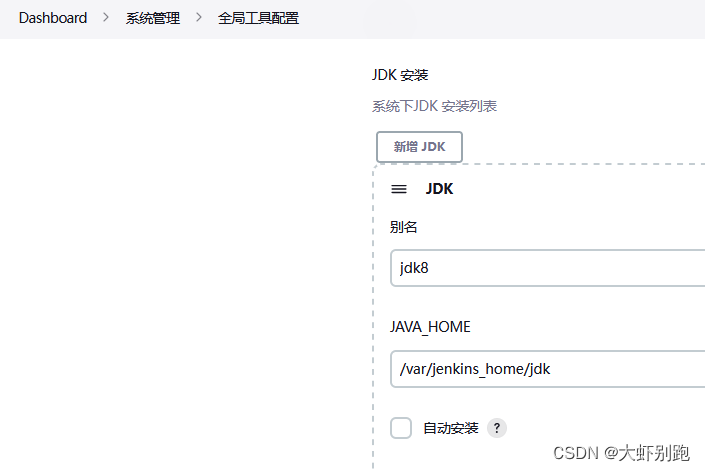
2.4 測試拉取程式碼
系統管理-系統配置-Publish over SSH-SSH Servers
#自定義專案名稱
name
test
#主機IP
Hostname
10.1.100.25
#主機使用者名稱
Username
root
#拉取專案路徑
Remote Directory
/data/work/mytest
點選高階
√ Use password authentication, or use a different key
#輸入伺服器密碼
Passphrase / Password
xxxx
點選 測試 Test Configuration
四、Jenkins實現基礎的拉取操作
1.軟體下載
連結:http://pan.baidu.com/s/1Jkyh_kgrT2o388Xiujbdeg?pwd=b7rx
提取碼:b7rx
本機執行環境的基本外掛
安裝git 、 maven、 jdk8
安裝開發工具IDEA :2019.2.3 x64
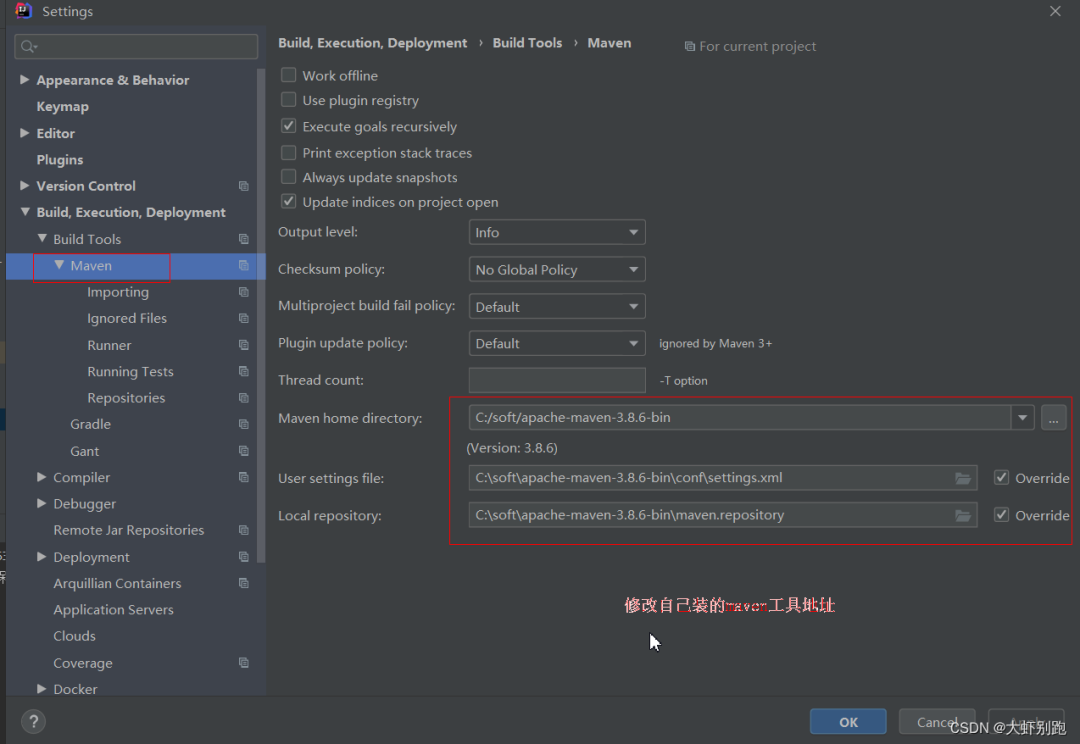
2.修改IDEA中maven路徑
3.建立專案 File - New - Project
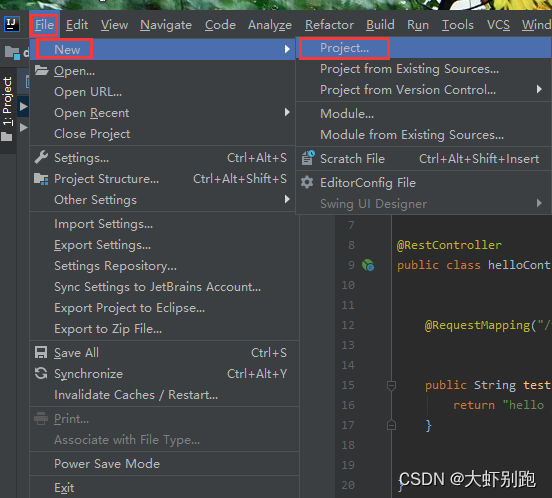
3.1 Spring Initalizr - Project SDK: java version “1.8.0_333” - Next
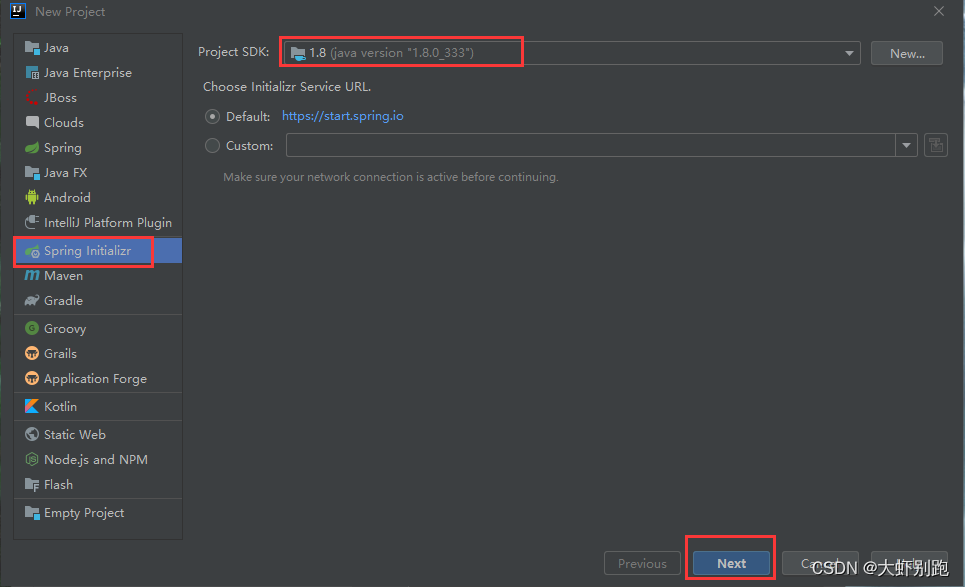
3.2修改JDK -Next
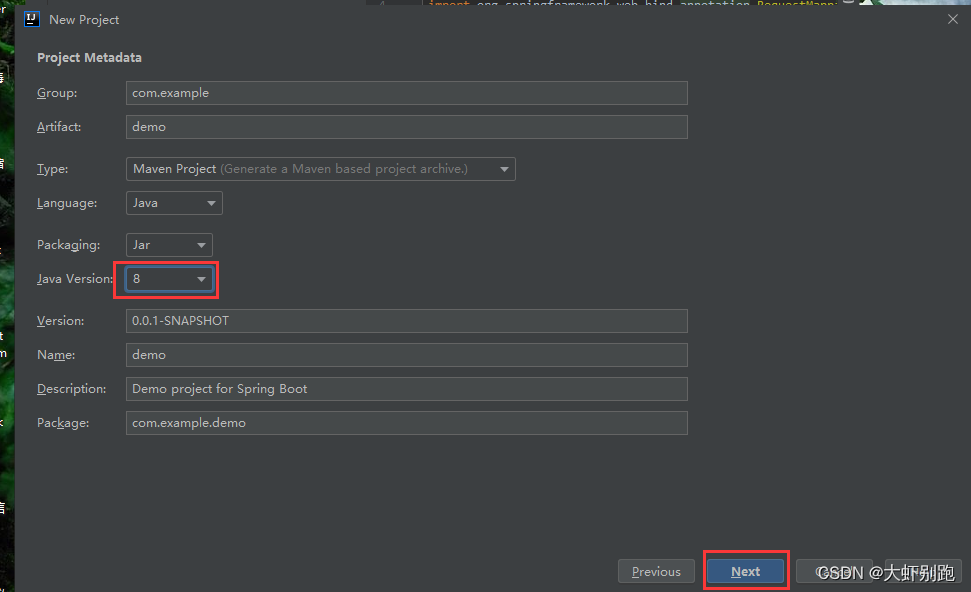
3.3 建立Spring Web
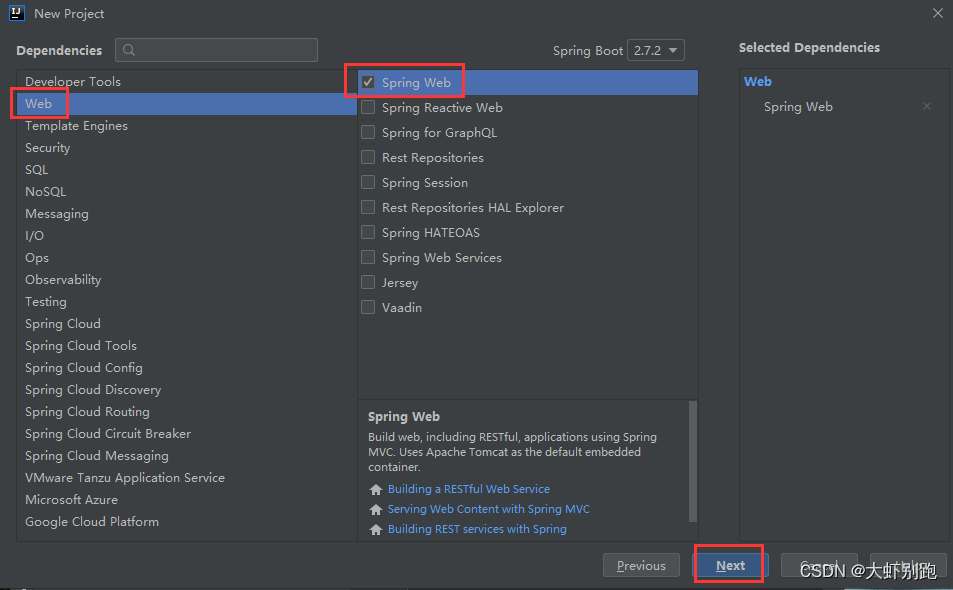
3.4 點選Finish
3.5建立controller目錄和 helloController檔案
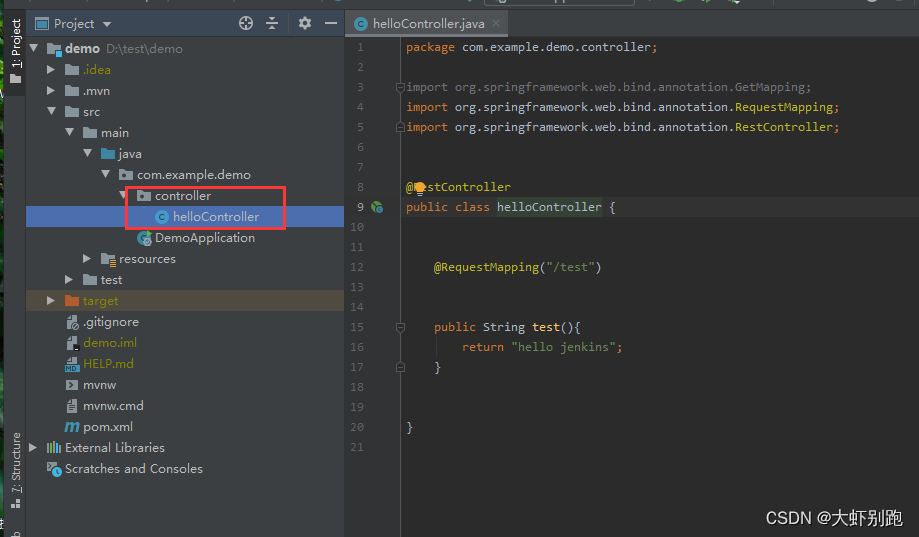
程式碼
package com.example.demo.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class helloController {
@RequestMapping("/test")
public String test(){
return "hello jenkins";
}
}
3.6 點選執行
3.7瀏覽器輸入:http://localhost:8080/test
3.8 準備推送專案-構建本地svc推送路徑
3.9 點選OK
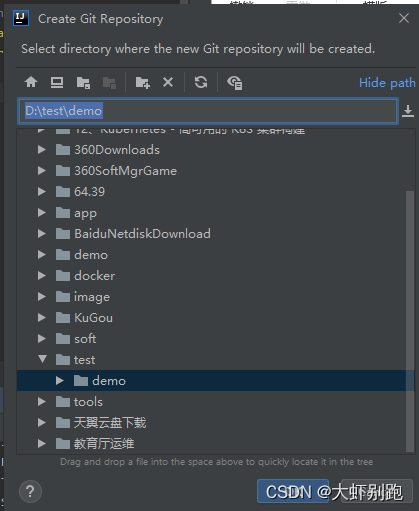
4.0 右鍵點選專案名稱選擇Git
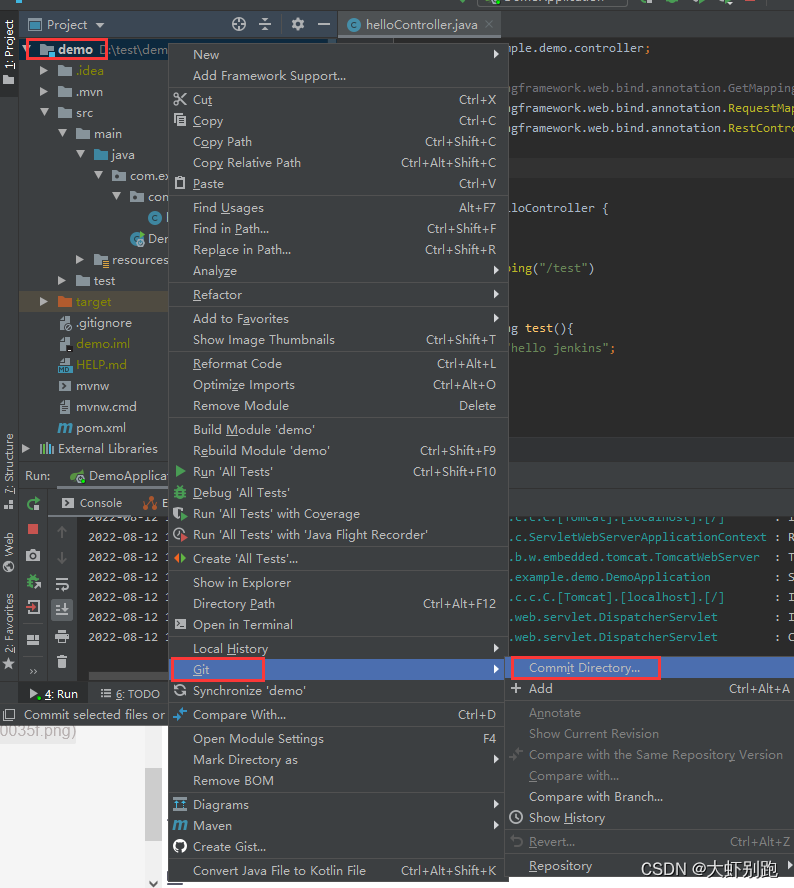
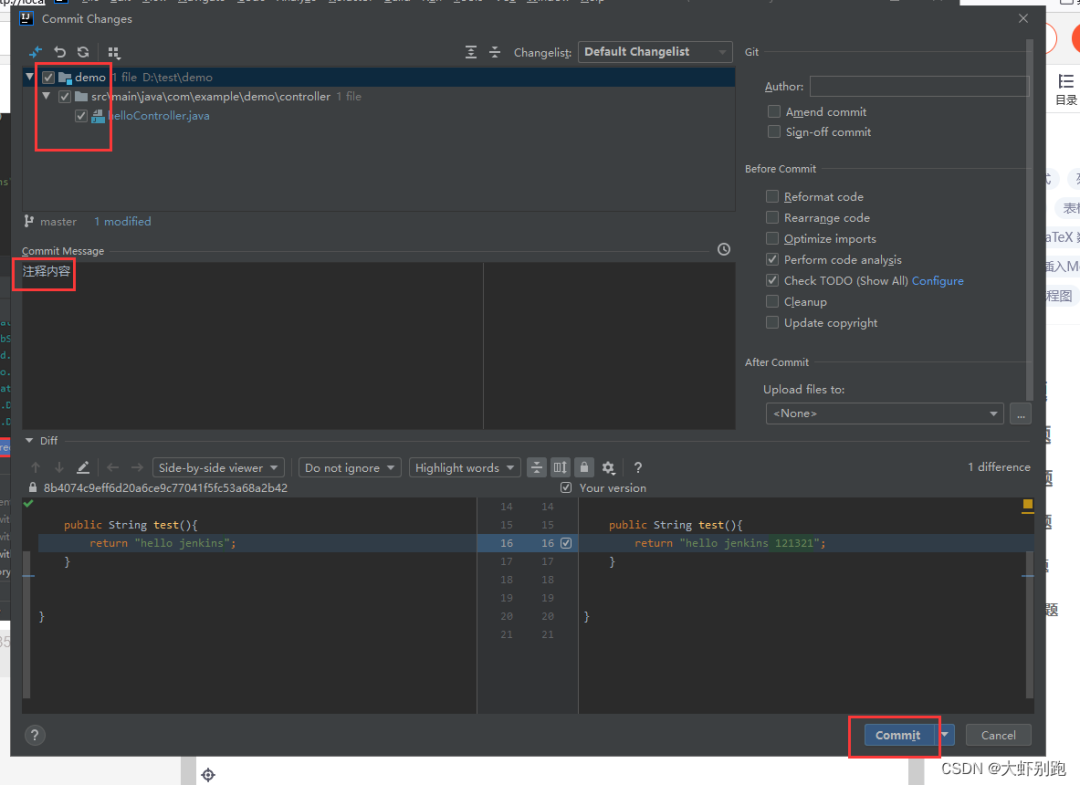
4.1選擇需要上傳的檔案-填寫註釋-Conmmit
4.2 選擇Push
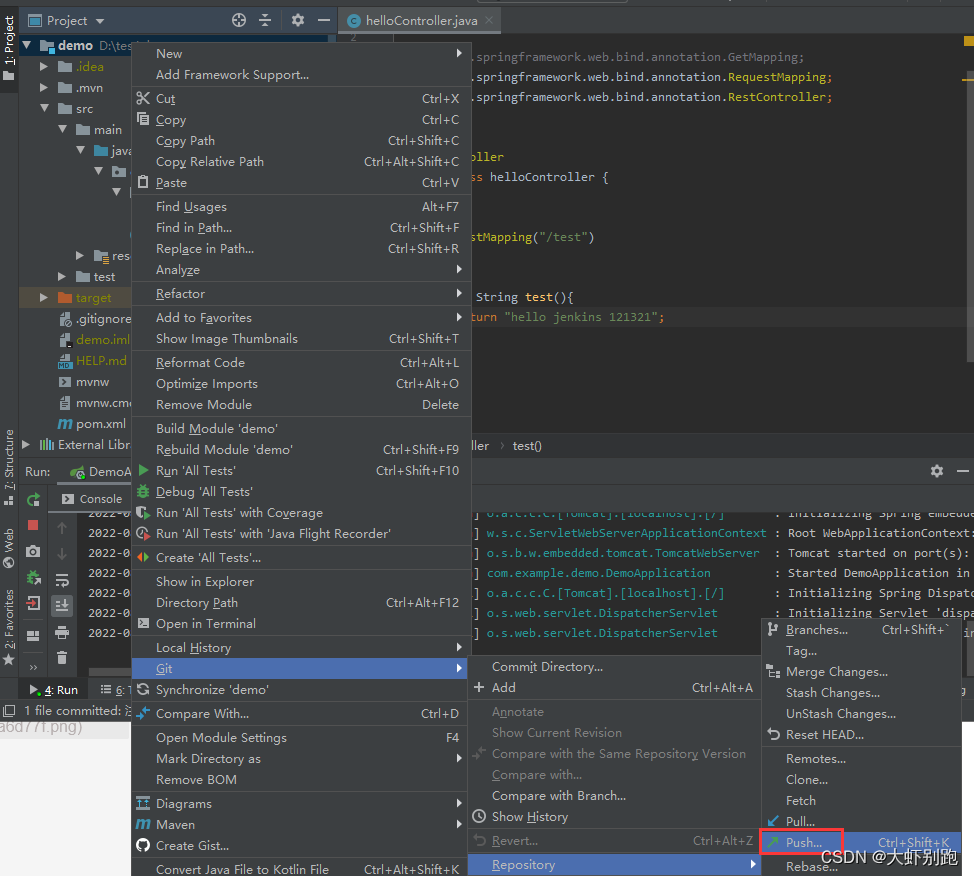
4.3 檢視git倉庫地址
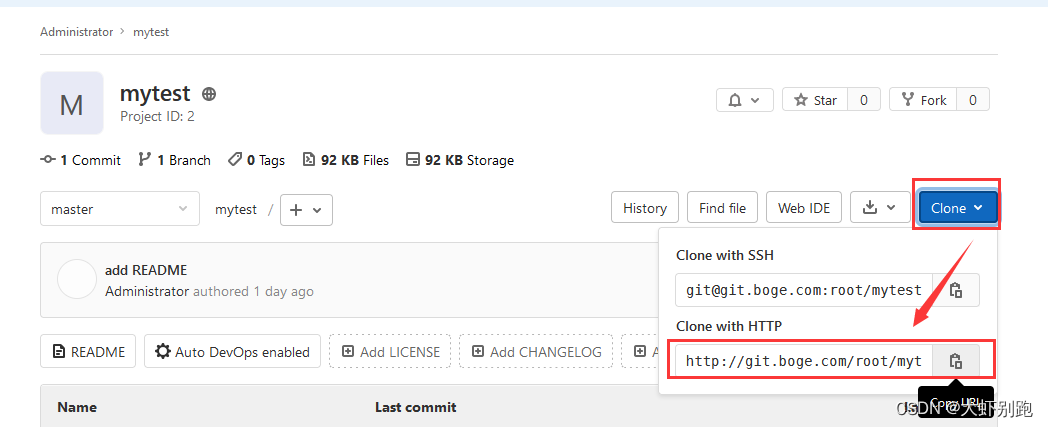
4.4 填寫git倉庫地址,提交程式碼

4.5 登入倉庫檢視程式碼 恭喜你成功啦!!!!
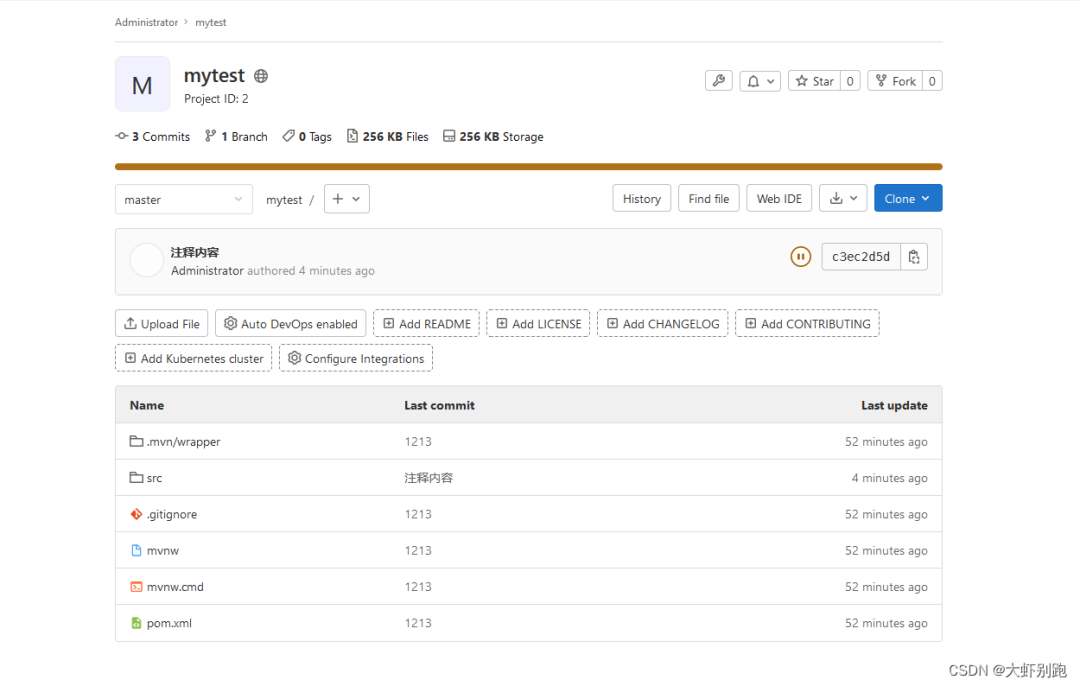
4.6Jenkins拉取程式碼
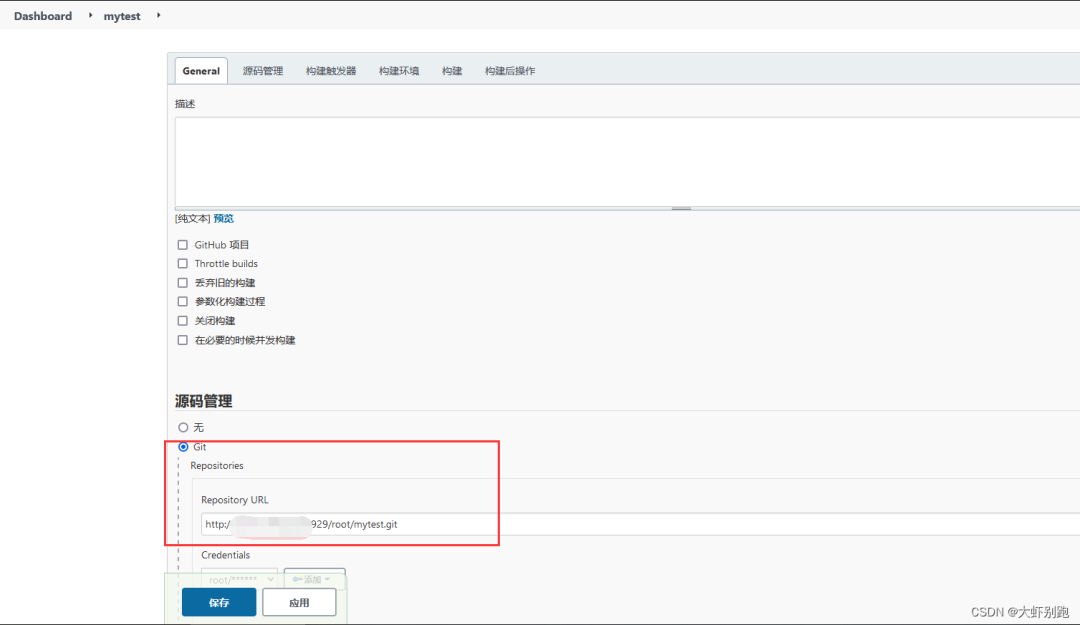
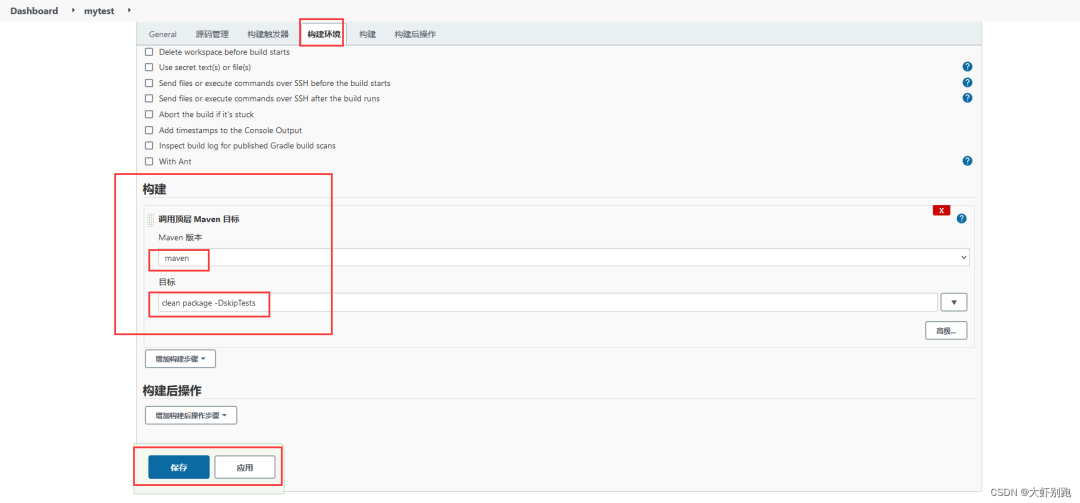
4.7構建環境拉取程式碼
4.8檢視日誌
五、Jenkins實現-sonarqbue 程式碼質量檢測部署
1.安裝sonarqube
docker pull postgres
docker pull sonarqube:8.9.6-community
1.1修改核心引數
vi /etc/sysctl.conf
vm.max_map_count=262144
sysctl -p
mkdir -p /data/sonarqube
cd /data/sonarqube
cat docker-compose.yml
version: '3.1'
services:
db:
image: postgres
container_name: db
ports:
- 5432:5432
networks:
- sonarnet
volumes:
- ~/sonarqube/postgresql/:/var/lib/postgresql
- ~/sonarqube/datasql/:/var/lib/postgresql/data
#配置資料庫使用者名稱和密碼
environment:
TZ: Asia/Shanghai
POSTGRES_USER: sonar
POSTGRES_PASSWORD: sonar
#下載社群長期支援版本
sonarqube:
image: sonarqube:8.9.6-community
container_name: sonarqube
#讓db先跑起來
depends_on:
- db
volumes:
- ~/sonarqube/extensions:/opt/sonarqube/extensions
- ~/sonarqube/logs:/opt/sonarqube/logs
- ~/sonarqube/data:/opt/sonarqube/data
- ~/sonarqube/conf:/opt/sonarqube/conf
ports:
- 9000:9000
#讓2個容器在一個網路中執行
networks:
- sonarnet
#資料庫連線地址
environment:
SONAR_JDBC_URL: jdbc:postgresql://db:5432/sonar
SONAR_JDBC_USERNAME: sonar
SONAR_JDBC_PASSWORD: sonar
#網路橋接方式
networks:
sonarnet:
driver: bridge
1.2 啟動
docker-compose up -d
1.3 檢視日誌
docker logs -f sonarqube
#進入sonarqube頁面 ip:9000 預設賬戶密碼admin/admin
#安裝中文外掛Administrator -Marketplace -下面搜尋框中查詢Chines同意 I Chinese-lunderstand the risk -下載Install 下載完畢提示重啟 Restart Server
2.專案中maven外掛新增到pom.xml 倒數第二行新增如下內容,mytest專案打包名稱
<build>
<finalName>mytest</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
3.專案同級目錄,新建docker目錄
3.1新建檔案Dockerfile
FROM daocloud.io/library/java:8u40-jdk
COPY mytest.jar /usr/local/
WORKDIR /usr/local/
CMD java -jar mytest.jar
3.2新建檔案ocker-compose.yml
version: '3.1'
services:
mytest:
build:
context: ./
dockerfile: Dockerfile
image: mytest:v1.0.0
#容器名稱
container_name: mytest
ports:
- 8081:8080
3.3 新增新增檔案的檔案,推送至git倉庫
3.4 git倉庫給專案新增tag標籤
4.jenkins裝外掛SonarQube Scanner
4.1安裝sonar-scanner
#下載地址 http://docs.sonarqube.org/latest/analysis/scan/sonarscanner/
unzip sonar-scanner-cli-4.6.0.2311-linux.zip
mv sonar-scanner-4.6.0.2311-linux sonar-scanner
#把sonar-scanner 複製到 jenkins容器資料卷中
mv sonar-scanner /data/jenkins/data/
#修改sonar-scanner基礎配置檔案
cat /data/jenkins/data/sonar-scanner/conf/sonar-scanner.properties
#換成自己的IP##################################
sonar.host.url=http://10.66.66.64:9000
sonar.sourceEncoding=UTF-8
##############################################
4.2jenkins 全域性工具配置
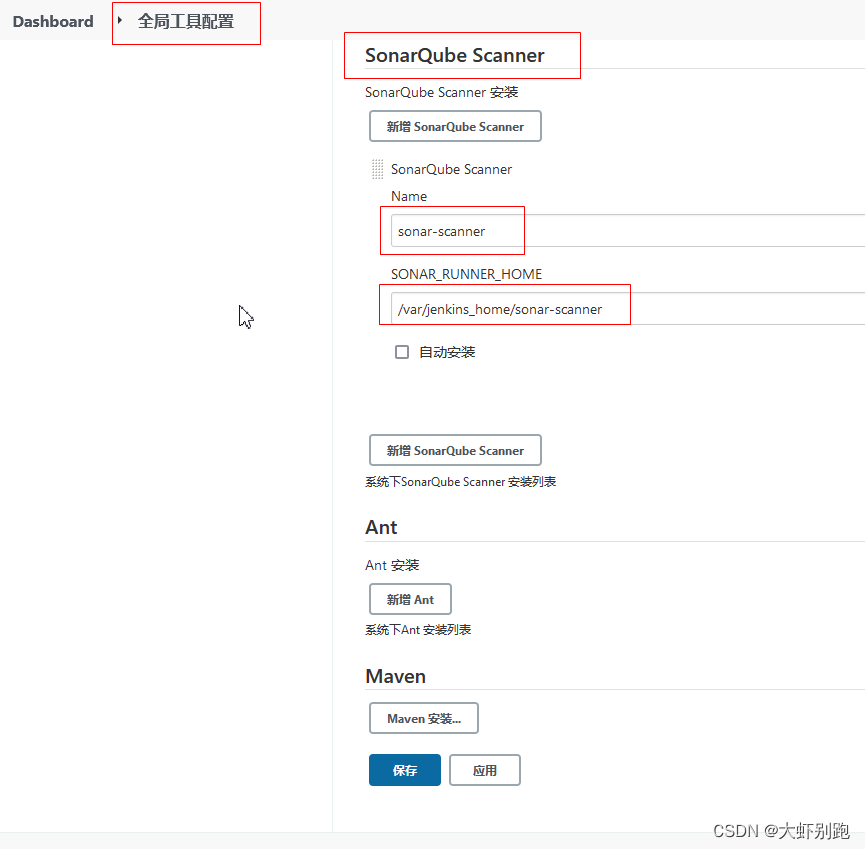
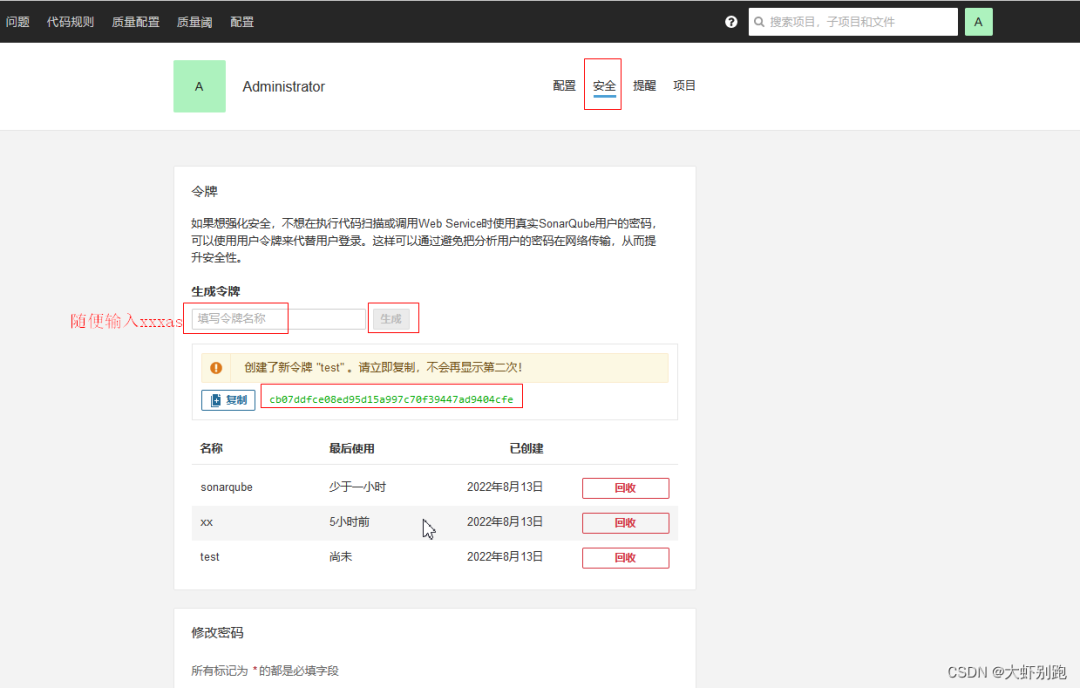
4.3 sonarqbue生成祕鑰
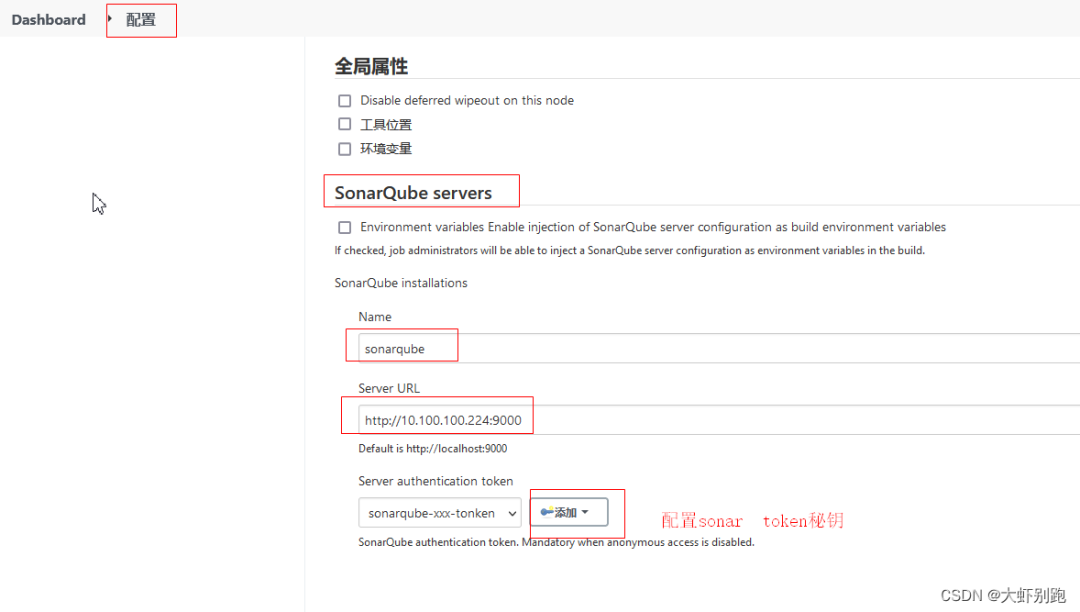
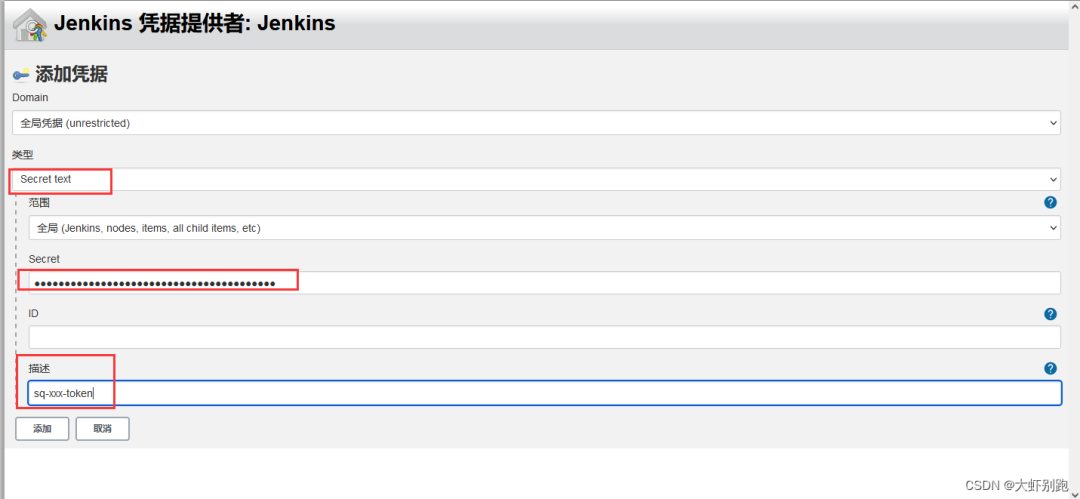
4.4 配置sonarqbue url和 token祕鑰
4.5 Publish over SSH 配置拉取程式碼的路徑和Ip 賬戶密碼
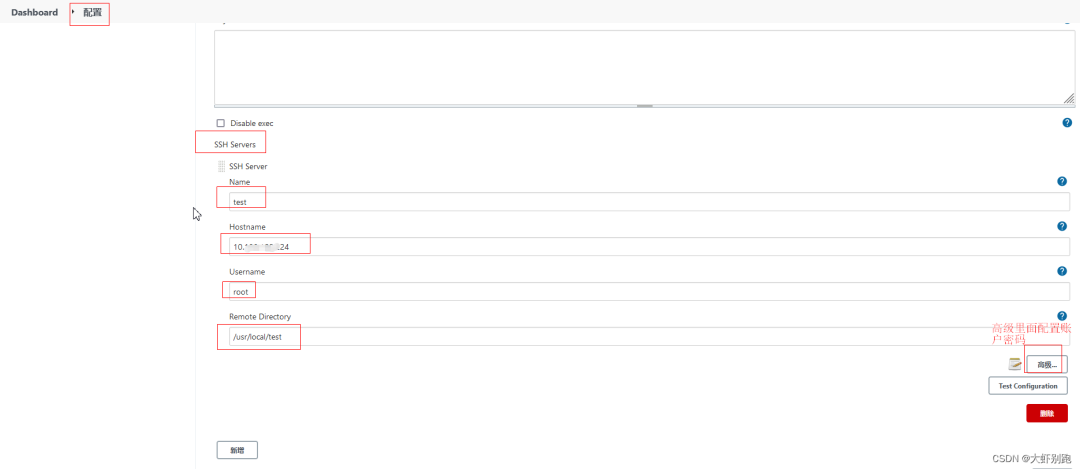
4.6 jenkins 專案新增tag 標籤
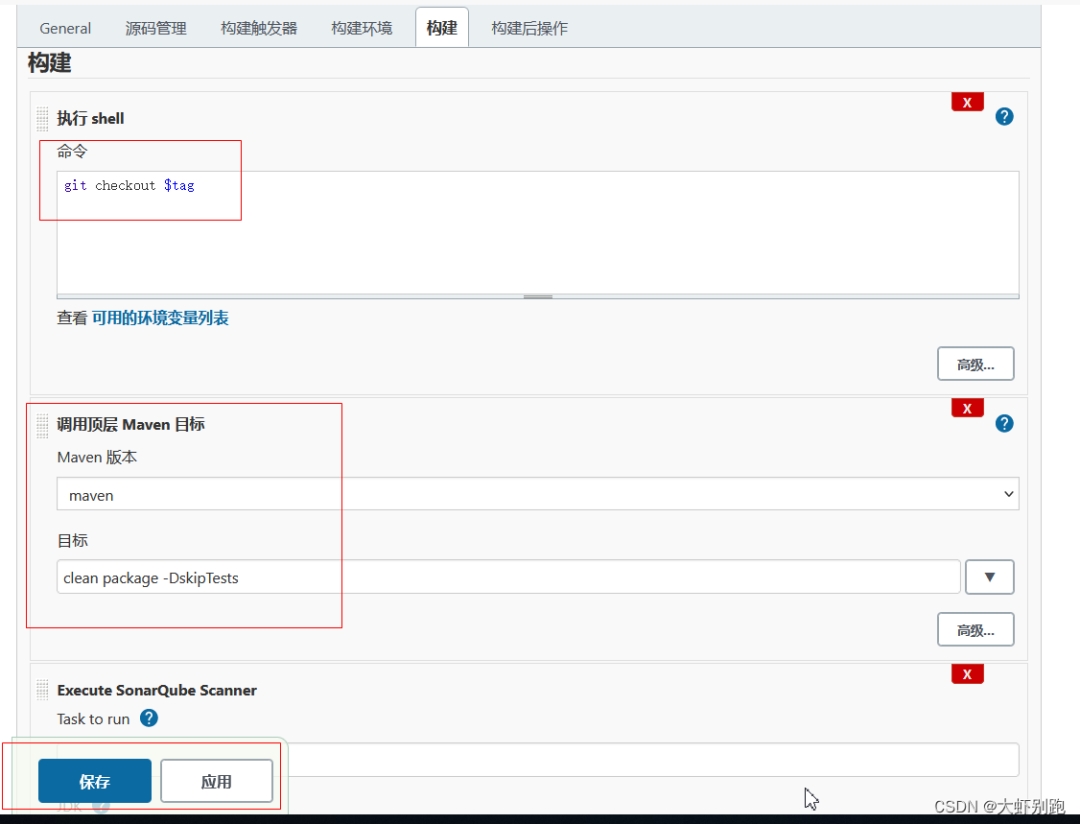
4.7新增程式碼質量檢測-
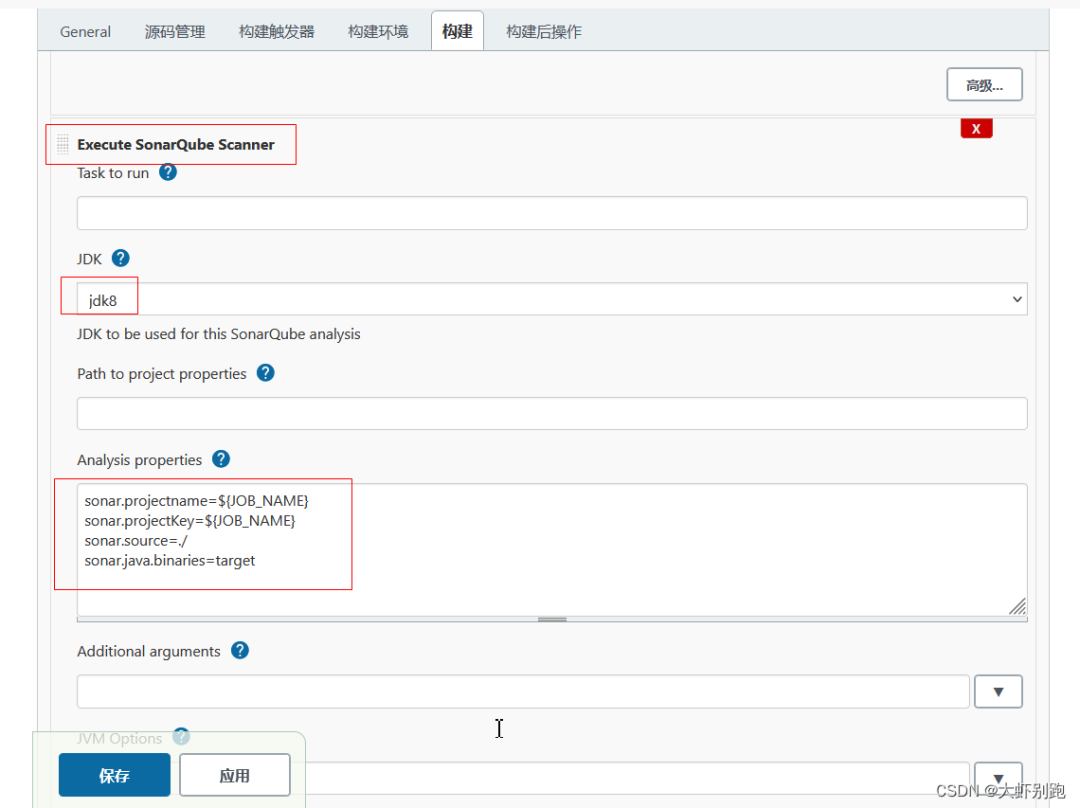
sonar.projectname=${JOB_NAME}sonar.projectKey=${JOB_NAME}sonar.source=./sonar.java.binaries=target
4.8構建後操作
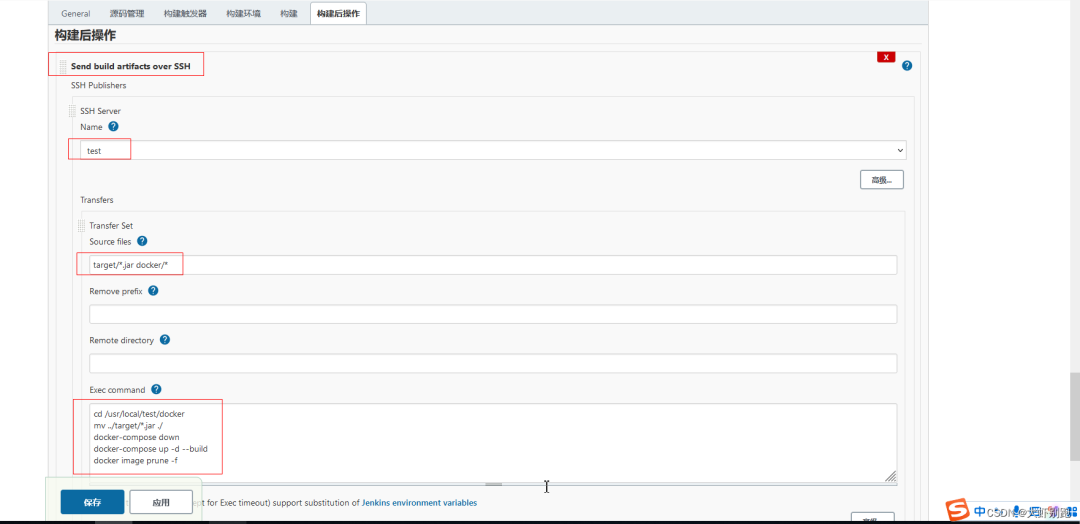
cd /usr/local/test/dockermv ../target/*.jar ./docker-compose downdocker-compose up -d --build刪除多餘的映象docker image prune -f
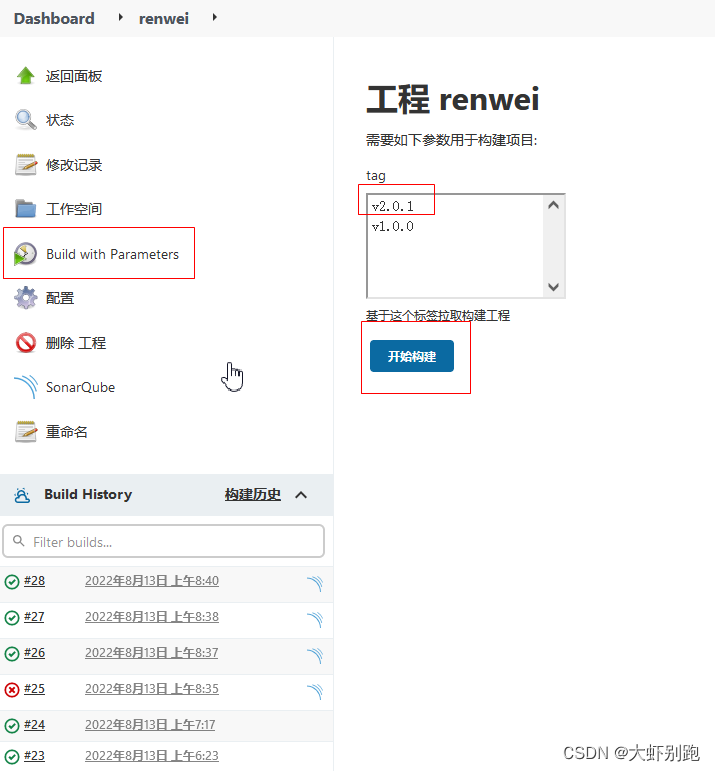
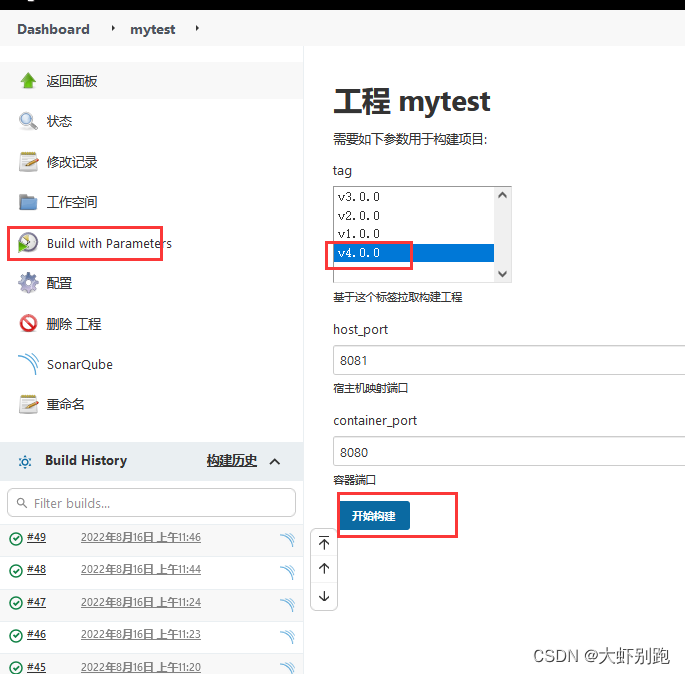
4.9 選擇 tag開始部署專案
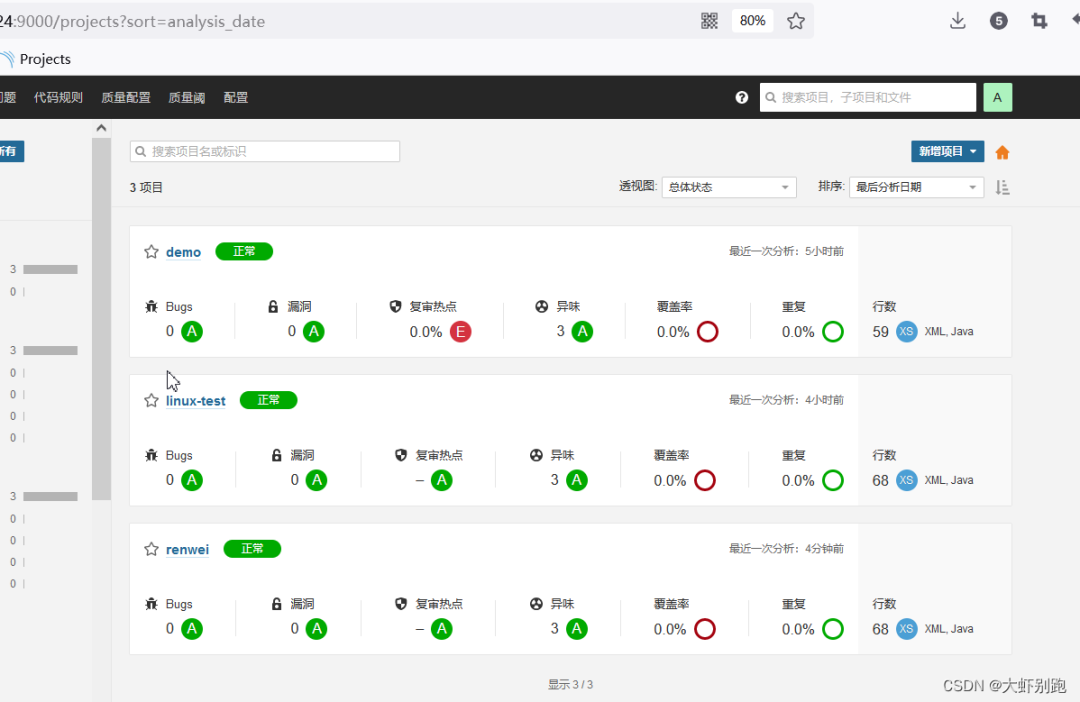
5.0 檢視質量檢測情況
六、Jenkins實現製作自定義映象並推送harbor部署
1.專案刪除docker-compose.yml,修改版本資訊,推送至git倉庫
2.gti倉庫新建tag標籤 v3.0.0
3.刪除之前的構建後操作-Send build artfacts over SSH
4.增加構建步驟-執行shell
mv target/*.jar docker/
docker build -t mytest:$tag docker/
docker login -u admin -p Harbor12345 192.168.1.6:80
docker tag mytest:$tag 192.168.1.6:80/repo/mytest:$tag
docker push 192.168.1.6:80/repo/mytest:$tag
5.伺服器編輯指令碼
cat > /root/deploy.sh <<EOF
horbar_addr=$1
horbar_repo=$2
project=$3
version=$4
echo "容器執行時埠"
container_port=$5
echo "宿主機對映埠"
host_prot=$6
echo "映象名稱"
imagesName=$horbar_addr/$horbar_repo/$project:$version
echo $imagesName
echo "拿到正在執行的id"
containerId=`docker ps -a |grep ${project} | awk '{print $1}'`
echo $containerId
echo "存在id 停止刪除程序"
if [ "$containerId" != "" ] ; then
docker stop $containerId
docker rm $containerId
fi
echo "列印工程 tag版本"
tag=`docker images | grep ${project} | awk '{print $2}'`
echo $tag
echo "versin中包含tag版本,刪除映象"
if [[ "$tag" =~ "$version" ]] ; then
docker rmi $imagesName
fi
echo "登入harbor倉庫"
docker login -u admin -p Harbor12345 $horbar_addr
echo "推送映象"
docker pull $imagesName
echo "刪除 none多餘映象"
docker images | grep none | awk '{print $3}'| xargs docker rmi --force
docker run -d -p $host_prot:$container_port --name $project $imagesName
echo "success"
<<EOF
6.指令碼授權
chmod a+x deploy.sh
#檢視當前環境變數
echo $PATH
#指令碼移動到環境變數中,讓其他使用者可執行
mv deploy.sh /usr/bin/
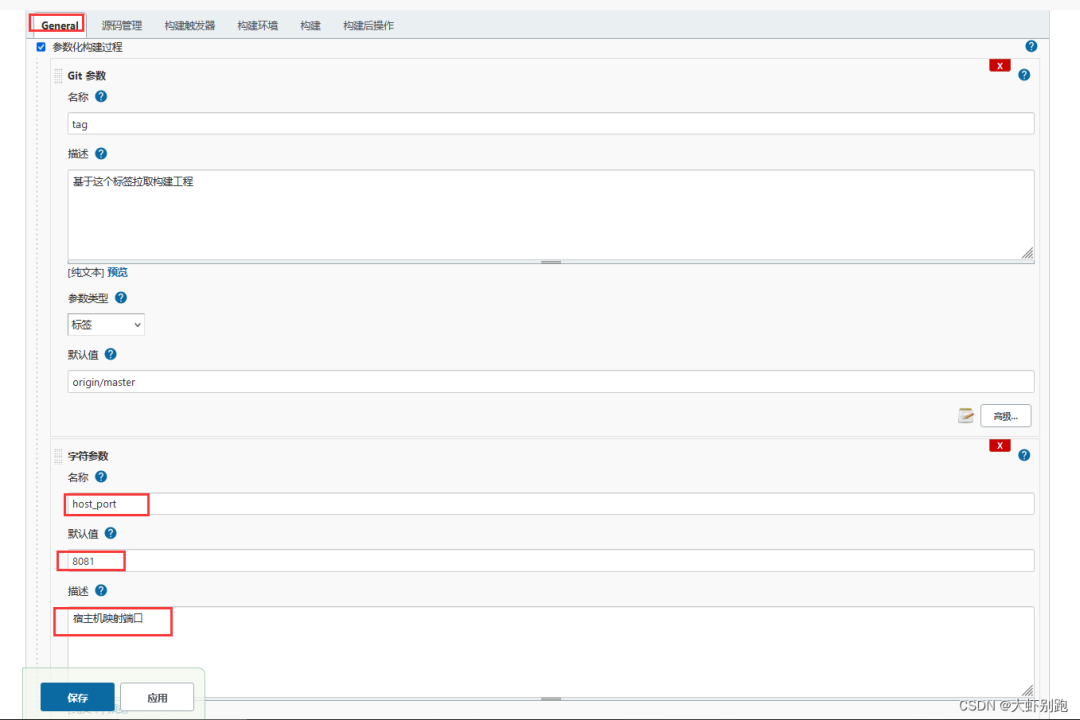
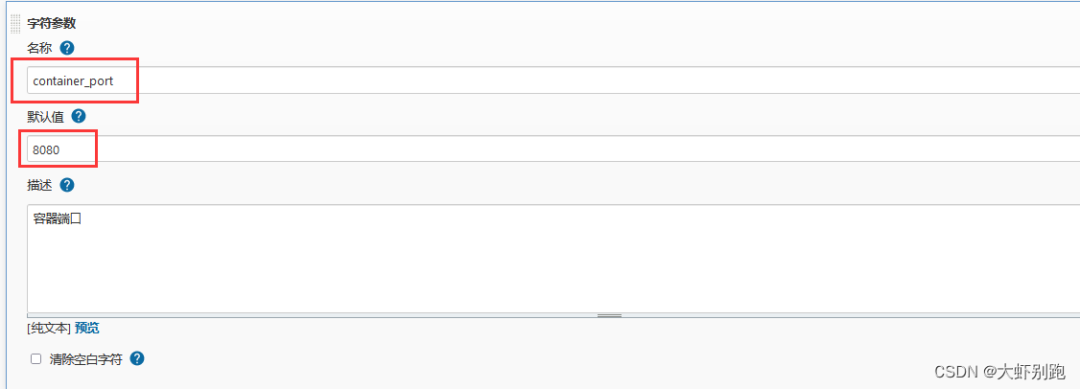
7.專案新增埠字元引數
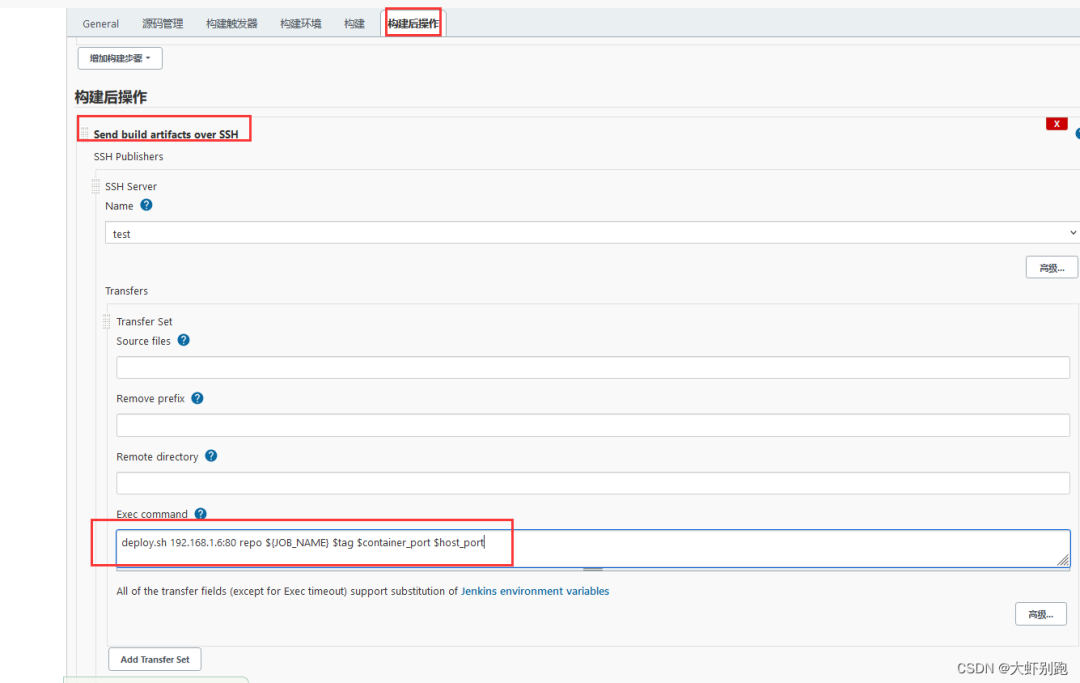
8.新增構建後操作 -Send build artfacts over SSH
9.執行專案,並檢視日誌
七、Jenkins的流水線初體驗
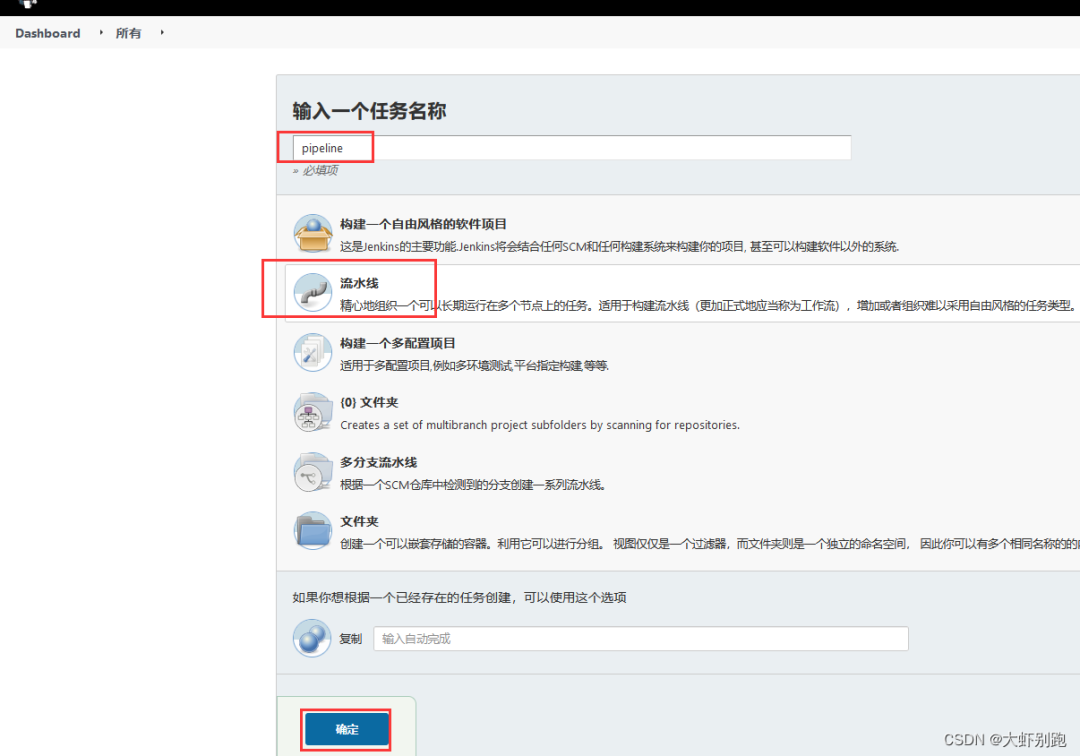
1.新建專案
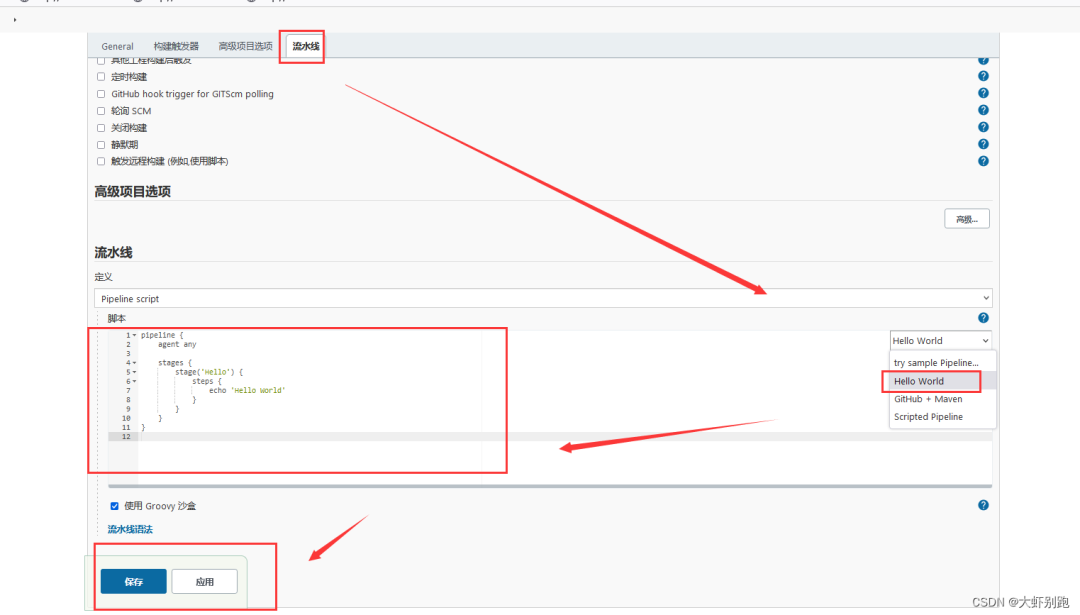
2.將下面程式碼全部覆蓋 流水線-Hello word 中-應用-儲存- 立即構建
//所有的指令碼命令都放在pipeline中
pipeline {
//執行任務再哪個叢集節點中執行
agent any
environment {
key = 'valus'
}
stages {
stage('拉取git倉庫程式碼') {
steps {
echo '拉取git倉庫程式碼 - SUCCESS'
}
}
stage('通過maven構建專案') {
steps {
echo '通過maven構建專案 - SUCCESS'
}
}
stage('通過sonarQube做程式碼質量檢測') {
steps {
echo '通過sonarQube做程式碼質量檢測 - SUCCESS'
}
}
stage('通過docker製作自定義映象') {
steps {
echo '通過docker製作自定義映象 - SUCCESS'
}
}
stage('將自定義映象推送到Harbor') {
steps {
echo '將自定義映象推送到Harbor - SUCCESS'
}
}
stage('通過 Publish Over SSH通知目標伺服器') {
steps {
echo '通過 Publish Over SSH通知目標伺服器 - SUCCESS'
}
}
}
}
3.維護指令碼
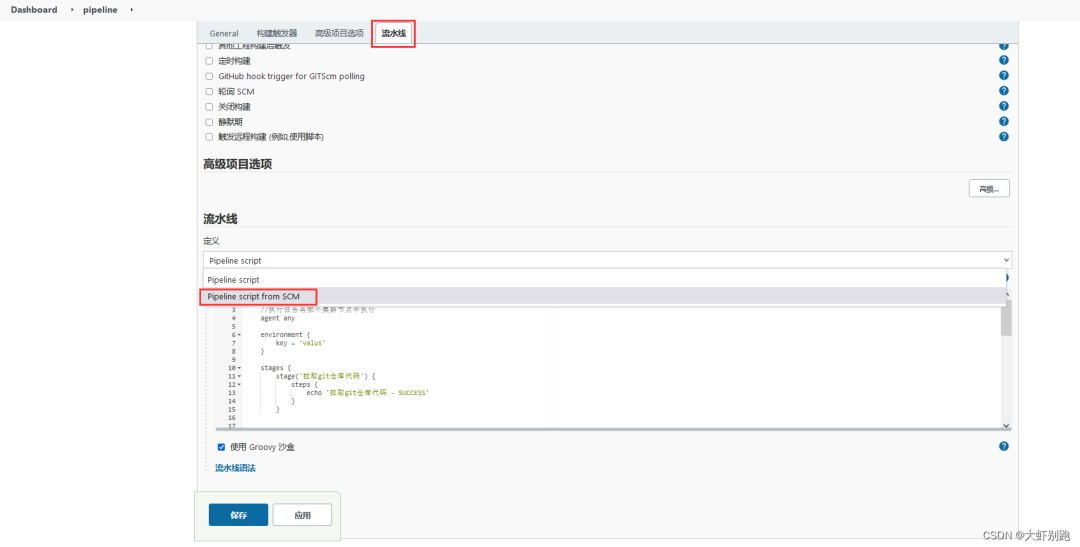
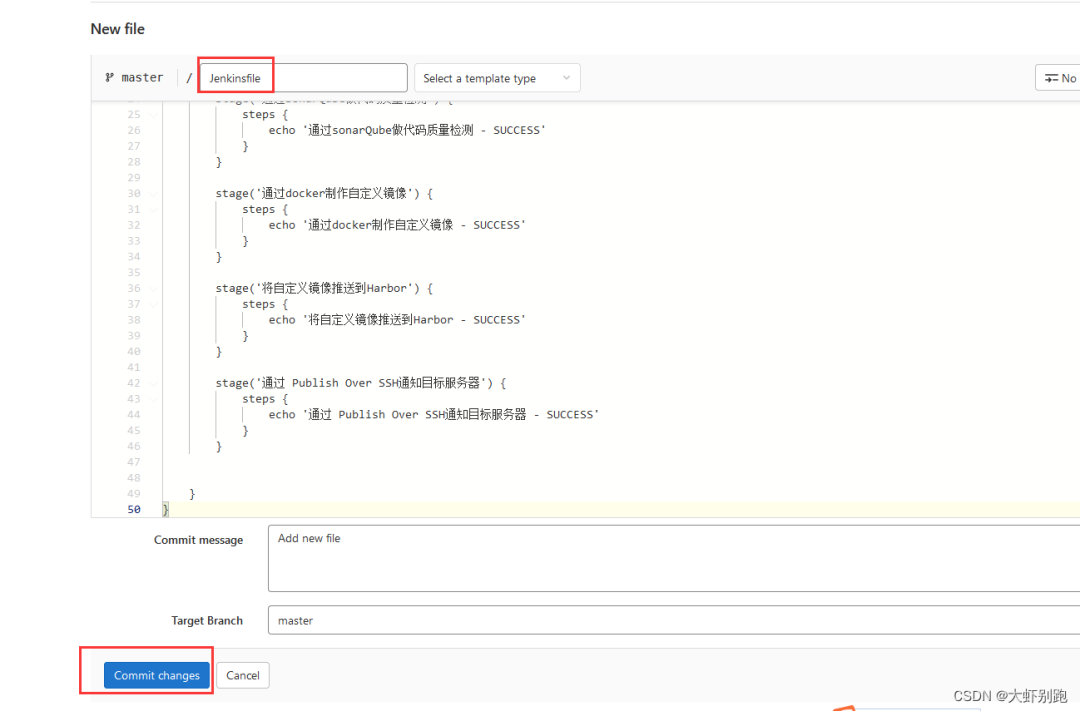
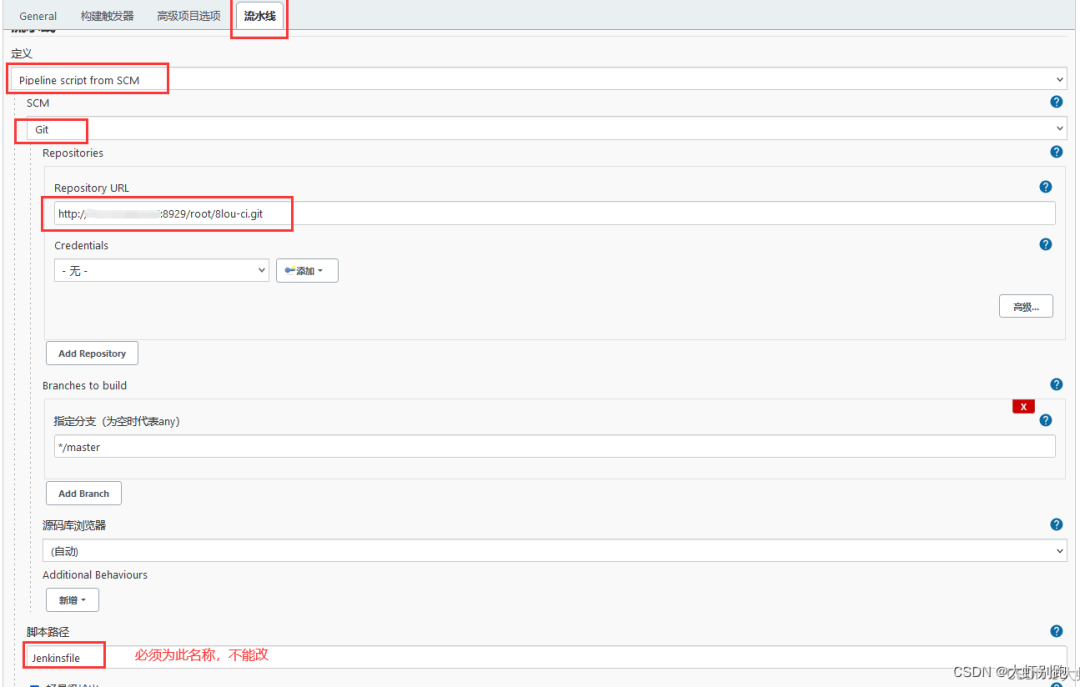
八、Jenkins中pipeline流水線-打包質量檢測推送docker部署,企業微信推送訊息
企業微信-配置Jenkins-安裝外掛-在外掛管理中,安裝外掛Qy Wechat Notification ,安裝後重啟jenkins
英文介面安裝外掛 Manage Jenkins–Manage Plugins-Available搜尋外掛
Locale
Localization
Git Parameter
Publish Over SSH
Qy Wechat Notification
SonarQube Scanner
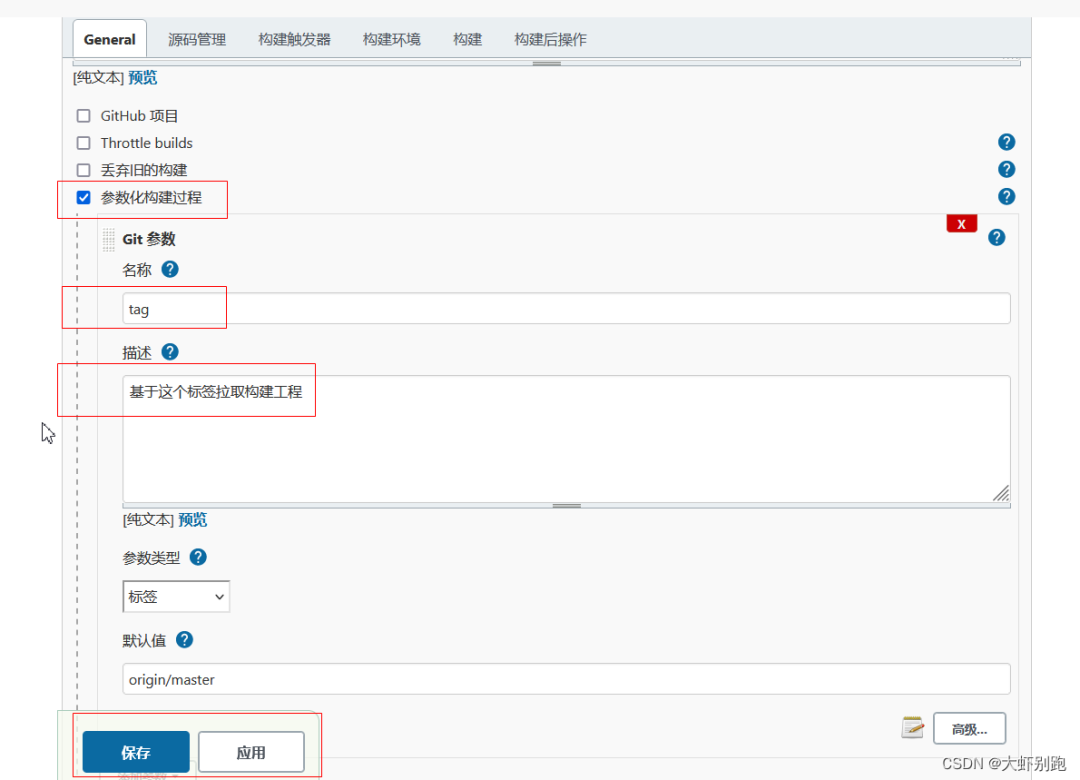
1,專案新增tag
Dashboard-pipeline-General-引數化構建過程-Git引數-名稱(tag)-描述(程式碼的版本標籤)——預設值(origin/master)-應用-儲存
2.拉取git倉庫程式碼
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(checkout:Check out from version control)
Repository URL
http://192.168.1.6:8929/root/pipeline.git
點選-生成流水線指令碼
checkout([$class: 'GitSCM', branches: [[name: '*/master']], extensions: [], userRemoteConfigs: [[url: 'http://192.168.1.6:8929/root/pipeline.git']]])
回到git倉庫修改Jenkinsfile,並儲存
//*/master 是預設拉取最新的程式碼, 我們自定義了tag版本,這裡需要引入$tag
stages {
stage('拉取git倉庫程式碼') {
steps {
checkout([$class: 'GitSCM', branches: [[name: '${tag}']], extensions: [], userRemoteConfigs: [[url: 'http://192.168.1.6:8929/root/pipeline.git']]])
}
}
3.maven構建包
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(sh:Shell Script)
Shell Script
/var/jenkins_home/maven/bin/mvn clean package -DskipTests
生成流水線指令碼
sh '/var/jenkins_home/maven/bin/mvn clean package -DskipTests'
4.通過sonarQube做程式碼質量檢測
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(sh:Shell Script) -生成後的流水線指令碼新增至git倉庫修改Jenkinsfile
#原始碼位置 -Dsonar.source=./
#專案名稱 -Dsonar.projectname
#專案的標識 -Dsonar.projectKey
#編譯後的目錄 -Dsonar.java.binaries
#祕鑰 -Dsonar.login
Shell Script
/var/jenkins_home/sonar-scanner/bin/sonar-scanner -Dsonar.source=./ -Dsonar.projectname=${JOB_NAME} -Dsonar.projectKey=${JOB_NAME} -Dsonar.java.binaries=./target/ -Dsonar.login=c5f80db608830252de0b368c9aaecc3a8d95463f
生成流水線指令碼
sh '/var/jenkins_home/sonar-scanner/bin/sonar-scanner -Dsonar.source=./ -Dsonar.projectname=${JOB_NAME} -Dsonar.projectKey=${JOB_NAME} -Dsonar.java.binaries=./target/ -Dsonar.login=c5f80db608830252de0b368c9aaecc3a8d95463f'
5.通過docker製作自定義映象
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(sh:Shell Script) -生成後的流水線指令碼新增至git倉庫修改Jenkinsfile
Shell Script
mv ./target/*.jar ./docker/
docker build -t ${JOB_NAME}:${tag} ./docker/
生成流水線指令碼
sh '''mv ./target/*.jar ./docker/
docker build -t ${JOB_NAME}:${tag} ./docker/'''
6.將自定義映象推送到Harbor
git倉庫-修改Jenkinsfile
//宣告全域性變數,方便後面使用
environment {
harboUser = 'admin'
harborPass = 'Harbor12345'
harborAddress = '192.168.1.6:80'
harborRepo = 'repo'
}
stage('將自定義映象推送到Harbor') {
steps {
sh '''docker login -u ${harboUser} -p ${harborPass} ${harborAddress}
docker tag ${JOB_NAME}:${tag} ${harborAddress}/${harborRepo}/${JOB_NAME}:${tag}
docker push ${harborAddress}/${harborRepo}/${JOB_NAME}:${tag}'''
}
}
7.通過 Publish Over SSH通知目標伺服器
pipeline-引數化構建過程-新增引數-字元引數
container_port 8080 容器內部佔用埠
host_prot 8081 宿主機對映埠
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(sshPublisher:Send build artifacts over SSH) -生成後的流水線指令碼新增至git倉庫修改Jenkinsfile
Exec command
deploy.sh $harborAddress $harborRepo $JOB_NAME $tag $container_port $host_prot
生成流水線指令碼
sshPublisher(publishers: [sshPublisherDesc(configName: 'test', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: "deploy.sh $harborAddress $harborRepo $JOB_NAME $tag $container_port $host_prot", execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: '')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
流水線指令碼中的一個坑,這裡的’’ 不會引用Jenkinsfile檔案中的變數,
‘deploy.sh $harborAddress $harborRepo $JOB_NAME $tag $container_port $host_prot’
需要換成""
“deploy.sh $harborAddress $harborRepo $JOB_NAME $tag $container_port $host_prot”
8.設定企業微信
開啟企業微信手機端,在群設定的群機器人中,新增機器人
新增成功後,複製Webhook地址,在配置Jenkins時使用
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(qyWechatNotification:企業微信通知) -生成後的流水線指令碼新增至git倉庫修改Jenkinsfile
九、Jenkins中pipeline流水線,k8s部署,企業微信推送訊息
1.Jenkins伺服器設定免密登入k8s-mast伺服器
#Jenkins伺服器-進入jenkins容器
docker exec -it jenkins bash
#進入jenkins容器-生成免密登入公私鑰,根據提示按回車
ssh-keygen -t rsa
#進入jenkins容器-檢視jenkins 祕鑰
cat /var/jenkins_home/.ssh/id_rsa.pub
#k8s-mast伺服器中authorized_keys 加入Jenkins伺服器祕鑰
echo "xxxxxx" >> /root/.ssh/authorized_keys
1.2 Jenkins新增k8s伺服器資訊
系統管理-系統配置-Publish over SSH-新增-設定密碼 點選高階-√ Use password authentication, or use a different key-Passphrase / Password(填寫自己的密碼)- Test Configuration(點選測試)

2.拷貝pipeline.yaml 到k8s-mast,生成流水語法
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(shhPublisher: Send build artifacts over SSH)
Name-(k8s)
Source files-(pipeline.yaml)
生成流水線指令碼
sshPublisher(publishers: [sshPublisherDesc(configName: 'k8s', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: '', execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: 'pipeline.yaml')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
3.遠端 執行k8s-mast伺服器中的 pipeline.yaml
編輯專案pipeline-流水線-流水線語法-片段生成器-示例步驟(sh:Shell Script)
Shell Script
ssh root@192.168.1.2 kubectl apply -f /usr/local/k8s/pipeline.yaml
生成流水線指令碼
sh ‘ssh root@192.168.1.2 kubectl apply -f /usr/local/k8s/pipeline.yaml’
4.git倉庫新建pipeline.yaml檔案
apiVersion: v1
kind: Service
metadata:
namespace: test
name: pipeline
labels:
app: pipeline
spec:
ports:
- port: 8081
protocol: TCP
targetPort: 8080
selector:
app: pipeline
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: test
name: pipeline
labels:
app: pipeline
spec:
replicas: 1
selector:
matchLabels:
app: pipeline
template:
metadata:
labels:
app: pipeline
spec:
containers:
- name: pipeline
image: 192.168.1.10:80/repo/pipeline:v4.0.0
#一直從倉庫拉取映象
imagePullPolicy: Always
ports:
- containerPort: 8080
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
namespace: test
name: pipeline-ingress
spec:
rules:
#記得給自己的k8s叢集伺服器新增本地host域名解析
- host: pipeline.rw.com
http:
paths:
- backend:
serviceName: pipeline
servicePort: 8081
path: /
5.git倉庫修改Jenkinsfile檔案
//所有的指令碼命令都放在pipeline中
pipeline {
//執行任務再哪個叢集節點中執行
agent any
//宣告全域性變數,方便後面使用
environment {
harboUser = 'admin'
harborPass = 'Harbor12345'
harborAddress = '192.168.1.10:80'
harborRepo = 'repo'
}
//*/master 是預設拉取最新的程式碼, 我們自定義了tag版本,這裡需要引入$tag
stages {
stage('拉取git倉庫程式碼') {
steps {
checkout([$class: 'GitSCM', branches: [[name: '${tag}']], extensions: [], userRemoteConfigs: [[url: 'http://192.168.1.9:8929/root/pipeline.git']]])
}
}
stage('通過maven構建專案') {
steps {
sh '/var/jenkins_home/maven/bin/mvn clean package -DskipTests'
}
}
stage('通過sonarQube做程式碼質量檢測') {
steps {
sh '/var/jenkins_home/sonar-scanner/bin/sonar-scanner -Dsonar.source=./ -Dsonar.projectname=${JOB_NAME} -Dsonar.projectKey=${JOB_NAME} -Dsonar.java.binaries=./target/ -Dsonar.login=c5f80db608830252de0b368c9aaecc3a8d95463f'
}
}
stage('通過docker製作自定義映象') {
steps {
sh '''mv ./target/*.jar ./docker/
docker build -t ${JOB_NAME}:${tag} ./docker/'''
}
}
stage('將自定義映象推送到Harbor') {
steps {
sh '''docker login -u ${harboUser} -p ${harborPass} ${harborAddress}
docker tag ${JOB_NAME}:${tag} ${harborAddress}/${harborRepo}/${JOB_NAME}:${tag}
docker push ${harborAddress}/${harborRepo}/${JOB_NAME}:${tag}'''
}
}
stage('拷貝yaml 到mast') {
steps {
sshPublisher(publishers: [sshPublisherDesc(configName: 'k8s', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: '', execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: 'pipeline.yaml')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
}
}
//192.168.1.2 是k8s-mast主節點
stage('遠端mast 執行yaml') {
steps {
sh 'ssh [email protected] kubectl apply -f /usr/local/k8s/pipeline.yaml'
}
}
stage('通知企業微信') {
steps {
qyWechatNotification mentionedId: '', mentionedMobile: '', webhookUrl: 'http://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=0461ffcf-3a23-4cda-8757-371cc0xx46be'
}
}
}
}
6.執行流水線
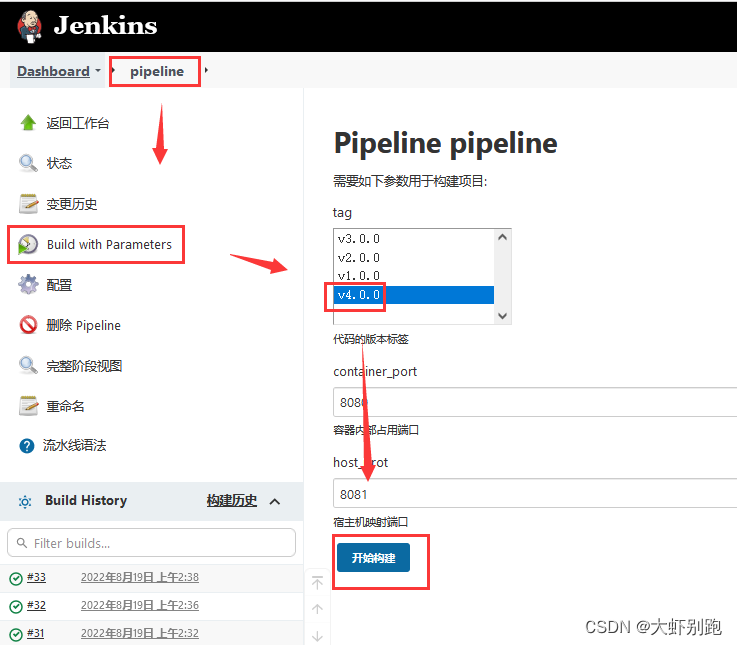
十、Jenkins自動化流水線,k8s部署,企業微信推送訊息
1.Jenkins-安裝外掛-在外掛管理中,安裝外掛GitLab ,安裝後重啟jenkins
2.Jenkins-系統配置-Gitlab
去掉√
Enable authentication for ‘/project’ end-point
應用儲存
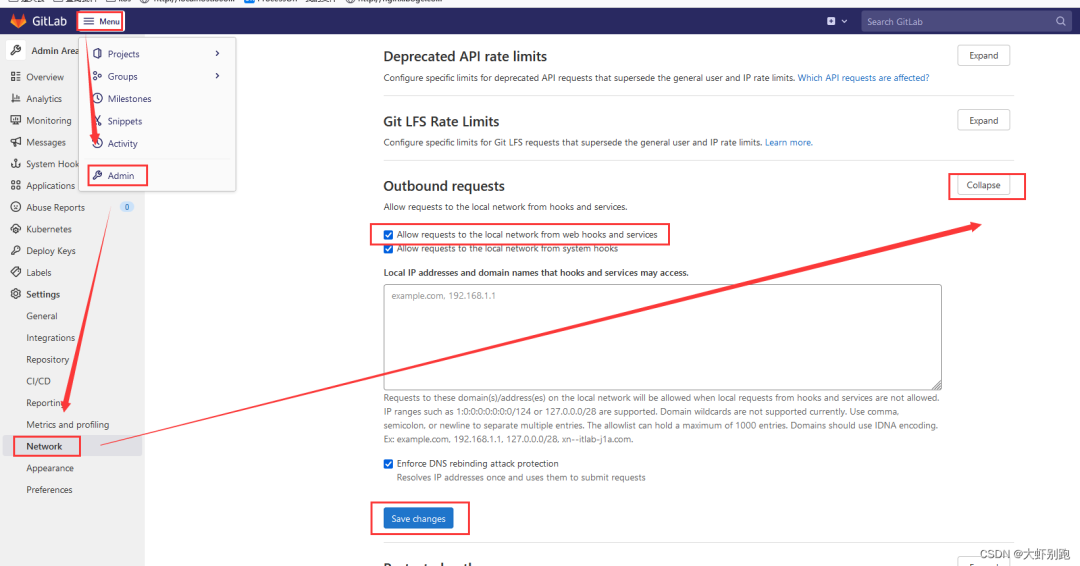
3.Git倉庫
Meun-Admin-Settings-Network-Outbound requests-Expand
打鉤 √Allow requests to the local network from web hooks and services
儲存Save changes
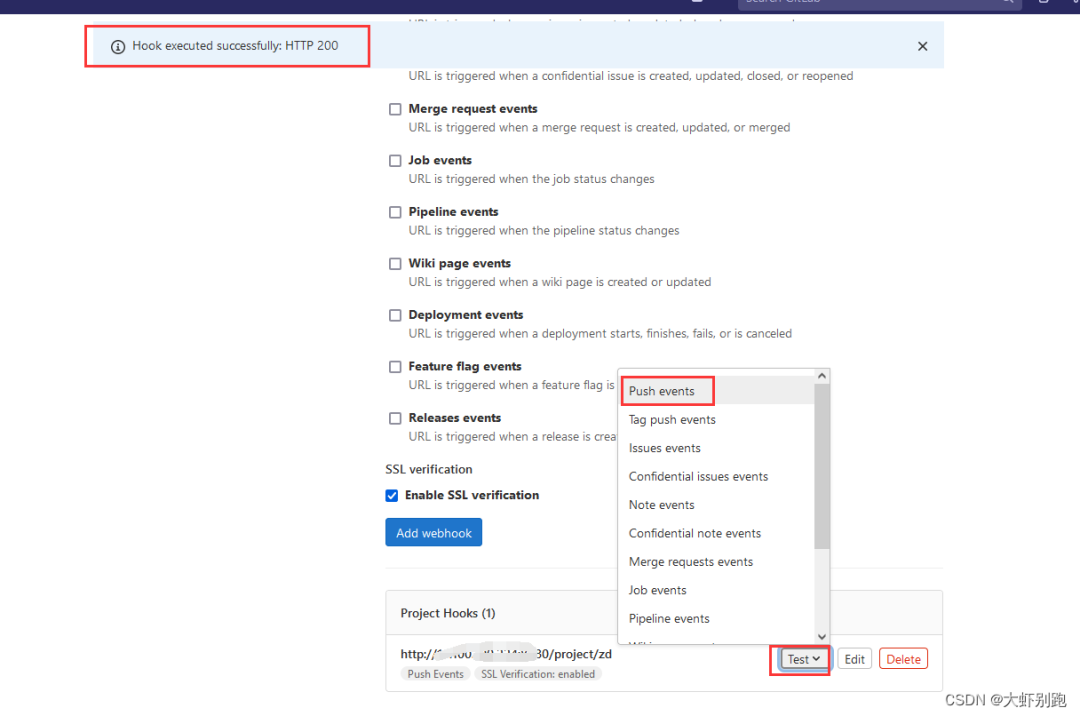
專案zd-Settings-Webhooks-URL (http://192.168.1.5:8080/project/zd) -Add webhook
4.測試
5.修改pipeline
pipeline.yaml
apiVersion: v1
kind: Service
metadata:
namespace: test
name: zd
labels:
app: zd
spec:
ports:
- port: 8081
protocol: TCP
targetPort: 8080
selector:
app: zd
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: test
name: zd
labels:
app: zd
spec:
replicas: 1
selector:
matchLabels:
app: zd
template:
metadata:
labels:
app: zd
spec:
containers:
- name: zd
image: 192.168.1.225:80/repo/zd:latest
ports:
- containerPort: 8080
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
namespace: test
name: pipeline-ingress
spec:
rules:
- host: nginx.boge.com
http:
paths:
- backend:
serviceName: zd
servicePort: 8081
path: /
6.修改 Jenkinsfile
Jenkinsfile
//所有的指令碼命令都放在pipeline中
pipeline {
//執行任務再哪個叢集節點中執行
agent any
//宣告全域性變數,方便後面使用
environment {
harboUser = 'admin'
harborPass = 'Harbor12345'
harborAddress = '192.168.1.225:80'
harborRepo = 'repo'
}
//*/master 是預設拉取最新的程式碼, 我們自定義了tag版本,這裡需要引入$tag
stages {
stage('拉取git倉庫程式碼') {
steps {
checkout([$class: 'GitSCM', branches: [[name: '*/master']], extensions: [], userRemoteConfigs: [[url: 'http://192.168.1.225:8929/root/zd.git']]])
}
}
stage('通過maven構建專案') {
steps {
sh '/var/jenkins_home/maven/bin/mvn clean package -DskipTests'
}
}
stage('通過sonarQube做程式碼質量檢測') {
steps {
sh '/var/jenkins_home/sonar-scanner/bin/sonar-scanner -Dsonar.source=./ -Dsonar.projectname=${JOB_NAME} -Dsonar.projectKey=${JOB_NAME} -Dsonar.java.binaries=./target/ -Dsonar.login=c5f80db608830252de0b368c9aaeccxx8d95463f'
}
}
stage('通過docker製作自定義映象') {
steps {
sh '''mv ./target/*.jar ./docker/
docker build -t ${JOB_NAME}:latest ./docker/'''
}
}
stage('將自定義映象推送到Harbor') {
steps {
sh '''docker login -u ${harboUser} -p ${harborPass} ${harborAddress}
docker tag ${JOB_NAME}:latest ${harborAddress}/${harborRepo}/${JOB_NAME}:latest
docker push ${harborAddress}/${harborRepo}/${JOB_NAME}:latest'''
}
}
stage('拷貝yaml 到mast') {
steps {
sshPublisher(publishers: [sshPublisherDesc(configName: 'k8s', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: '', execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: 'pipeline.yaml')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
}
}
stage('遠端mast 執行yaml') {
steps {
sh 'ssh [email protected] kubectl apply -f /usr/local/k8s/pipeline.yaml'
sh 'ssh [email protected] kubectl -n test rollout restart deployment zd'
}
}
stage('通知企業微信') {
steps {
qyWechatNotification mentionedId: '', mentionedMobile: '', webhookUrl: 'http://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=0461ffcf-3a23-4cda-8757-371xx0cd46be'
}
}
}
}
7、開發push程式碼,自動部署

- Skywalking分散式追蹤與監控:起始篇
- 如何使用 docker 搭建 hadoop 分散式叢集?
- 開源女神節——撕掉標籤,自由隨我
- 開源女神節——她說
- 大牛告訴你專案在Devops下如何測試!
- DataOps 不僅僅是資料的 DevOps!
- K8s——master擴容
- Skywalking分散式追蹤與監控:起始篇
- 這可能是最為詳細的Docker入門吐血總結
- 2023年 DevOps 七大趨勢
- k8s部署redis叢集
- DevOps20個常見問題
- Nexu私服安裝配置,IDEA打包上傳私服
- 鵝場分散式系統DevOps自動化測試實踐
- 【雲原生】持續整合和部署(Jenkins)
- k8s部署手冊-v04
- 保護 DevOps 的 5 個技巧
- CI/CD如何支撐運維自動化
- DevOps 如何幫助實現安全部署
- K8s系列-KubeSphere