分散式資料庫架構路線大揭祕
摘要:這些年大家都在談分散式資料庫,各大企業也紛紛開始做資料庫的分散式改造。那麼所謂的分散式資料庫是什麼?採用什麼架構,優勢在哪?為什麼越來越多企業選擇它?我們不妨一起來深入瞭解下。
本文分享自華為雲社群《GaussDB分散式架構大揭祕》,作者:華為雲資料庫首席架構師 馮柯。
這些年大家都在談分散式資料庫,各大企業也紛紛開始做資料庫的分散式改造。那麼所謂的分散式資料庫是什麼?採用什麼架構,優勢在哪?為什麼越來越多企業選擇它?我們不妨一起來深入瞭解下。
分散式資料庫是如何演進的?
回顧分散式資料庫的演進歷程,我們可以大致概括為三個發展階段:應用分庫分表做垂直拆分、分散式中介軟體、分散式資料庫。每個階段都呈現出了不同的特點:
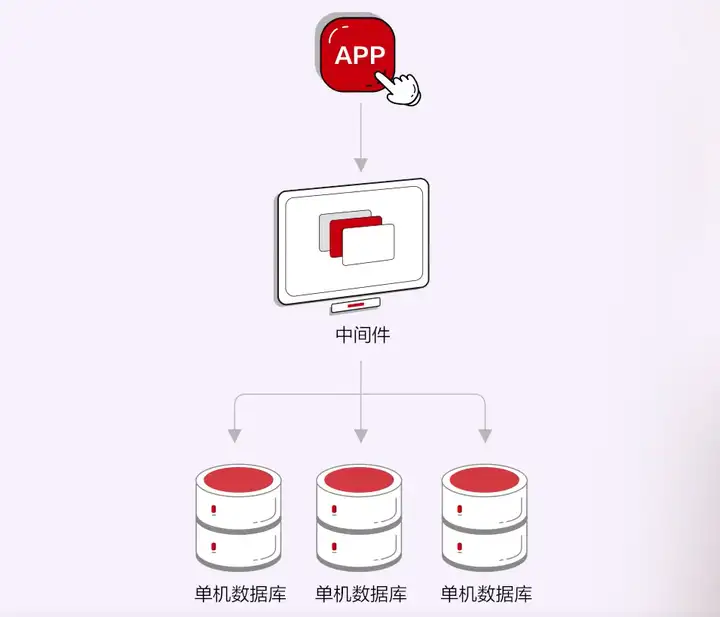
應用分庫分表做垂直拆分本質上是應用側的改造,和資料庫本身沒有太大關係。
在分散式中介軟體階段,分散式資料庫本質上是由兩部分組成的,上層是分散式中介軟體,底層再搭載開源MySQL或PG單機核心。這種方式因為使用了比較成熟的核心,所以生態友好、成本較低,比較容易實現,不過缺點也顯而易見,比如功能降級、分散式事務處理能力較差,最重要的是,因為使用的是開源產品的核心,資料庫會始終受制於開原始碼修改、專利、發行方式等很多方面的風險,這種形式顯然已經無法滿足當前國內金融、政企客戶的需求。
到了分散式資料庫階段,主要呈現出兩種形態。一種是基於分散式儲存實現的分散式資料庫,這種形態先有分散式儲存,再疊加資料庫能力,我們習慣把它稱為“分散式+”。
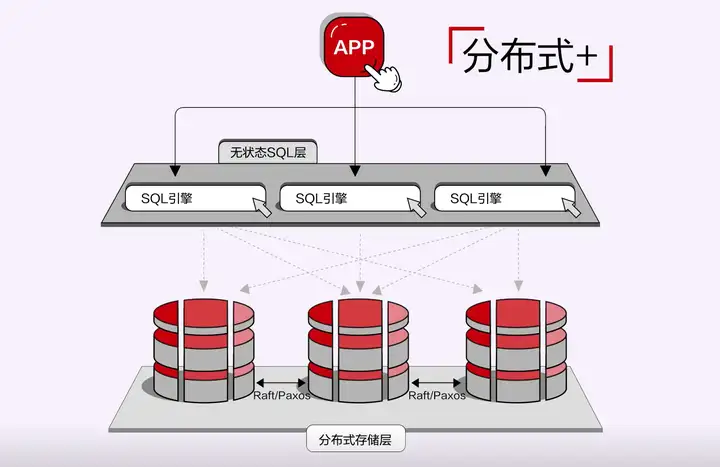
這種架構在分散式比較擅長的領域,更容易形成它的技術競爭力。什麼是分散式擅長的領域呢?比如說像擴充套件性、及時的擴充套件性,大規模運維的靈活性,比如擴縮容。在這方面,分散式+的天花板會更少,因為它一開始就是按照分散式儲存來設計的。這裡面有意思的一點是,這跟架構本身沒有太大關係,我們看到,今年所有的在國內的分散式+的廠商都有一個共同特點,就是在整個儲存引擎的設計上跟今天我們認知的,不管是MySQL還是PG,都不一樣。它不是一個類似於B-TREE的這樣一種結構,而通常是基於LSM-Tree儲存引擎,資料寫記憶體,然後批量寫持久化的這樣一種方式。這是因為這些分散式+的廠商,他們的所有技術體系都來源於Google,而Google最早做的第一款產品就是分散式儲存,叫Big Table,Big Table本身就是基於LSM-Tree的,這是一個歷史傳統。這就是為什麼LSM-Tree跟分散式+本身沒有必然關係,但是今天我們看到國內所有走分散式+路線的廠商,都使用的是LSM-Tree。
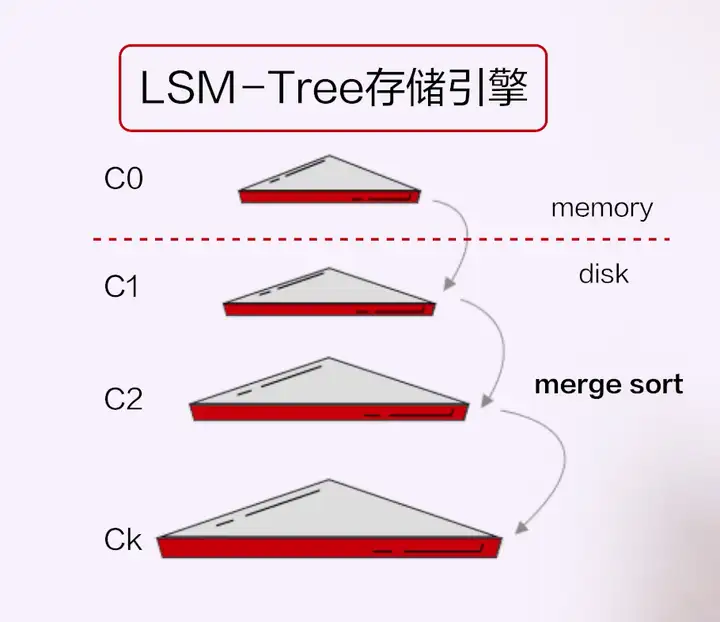
LSM-Tree有它的優點,比如主備之間的異構性有天生的優勢,但也有一個非常大的缺點,就是對於場景的普遍適用性。它比較適合於寫密集的場景,有大量寫入插入,比如我的訂單、流水化的訂單,但不太適合狀態類的業務,有大量的讀和寫,要去更新狀態。而且它把隨機寫轉為順序寫,在做compaction也就是記憶體和持久化儲存資料合併時也會有空間放大和效能抖動問題,所以它整個場景的適用性比B-Tree要低。
這個階段的另外一種形態,就是基於分散式資料庫理論實現的原生分散式資料庫,與“分散式+”正好相反,它是先有TP單機資料庫引擎,再疊加分散式能力,我們一般稱之為“資料庫+”,華為雲GaussDB分散式資料庫就是這種形態的典型代表。
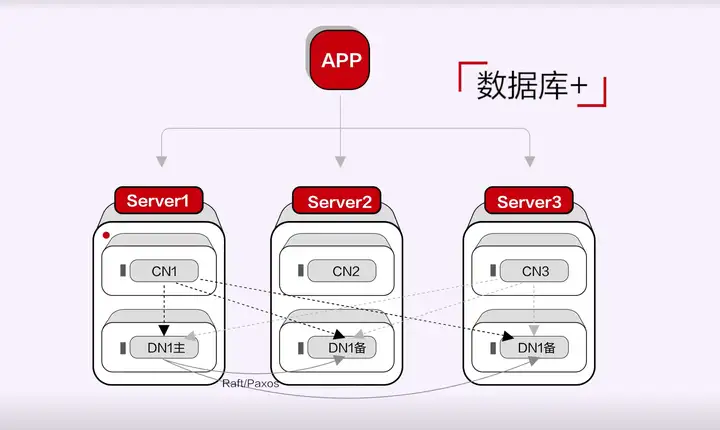
這種形態不存在空間放大和效能抖動的問題,而且更容易在資料庫本身所擅長的領域發揮優勢,比如說效能、複雜SQL處理能力、企業級能力。同時,因為金融政企客戶在使用分散式技術之前,往往已經有分庫分表、使用分散式中介軟體產品的經驗,所以對這種架構的認可度更高,學習成本也相對較低,因此這種形態也是國內當前被採用較多的一種。
資料庫+與分散式中介軟體有什麼區別?
資料庫+和分散式中介軟體,這兩種形式從架構上來看是非常相似的,分散式中介軟體上面是一個代理層,下面有很多單機資料庫。我們可以這麼來看,就像是天平的兩端,一端在0,一端在1,裡面有三個非常大的差別。
如何處理分散式事務,提供外部一致性?
分散式中介軟體通常是基於XA來實現資料一致性,但XA本身是不能實現外部一致性的,一般只支援最終一致性,而資料庫+的分散式資料庫可以基於內建全域性授時來實現全域性一致性讀,從而支援外部一致性。
如何處理分散式SQL?
分散式中介軟體是把資料庫作為黑盒,資料節點之間只能通過SQL的形式傳遞,是標準的SQL。
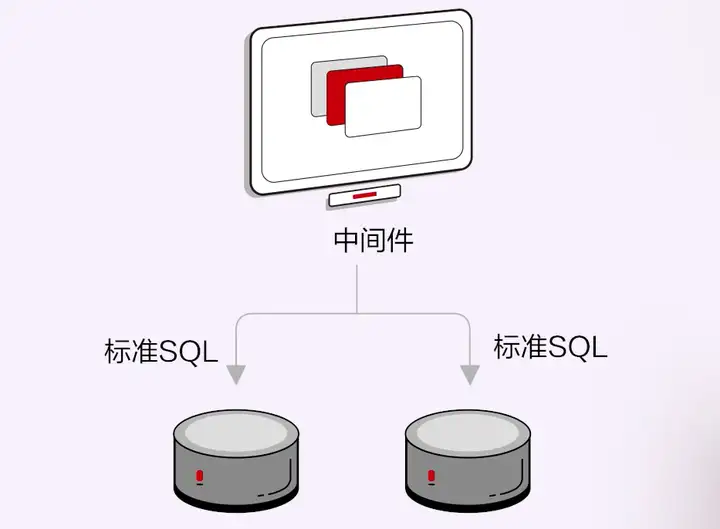
分散式中介軟體處理分散式SQL
而資料庫+的代理層和資料節點是一個數據庫的不同部分,互相之間可以傳遞更加內部的東西,比如計劃樹,不同的資料節點之間也不需要代理節點,可以直接傳遞。
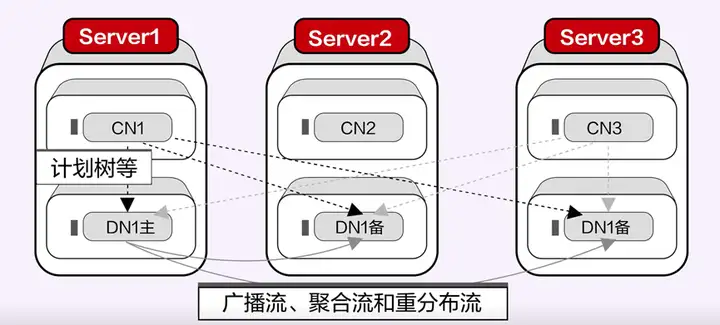
資料庫+處理分散式SQL
如何實現分散式一致性?
分散式中介軟體通常是基於傳統主備架構,使用半同步、最大保護等模型來實現分散式一致性,不過這種形式下一致性和高可用是沒有辦法同時兼顧到的,而資料庫+是基於原生分散式共識而打造,比如Quorum、Paxos,Raft,可以實現底層無損容災,同時滿足一致性和高可用性。
對於資料庫廠商而言,如果以上三個問題全都做到了,那我們可以說它是分散式資料庫,如果三者都無法做到,我們一般說它是分散式中介軟體,如果說只做到了其中的一部分,那就很難下定義究竟是分散式中介軟體還是分散式資料庫,但可以從這三方面去衡量它的天平更傾向哪一邊。
資料庫+更適合金融政企的未來
出現三種不同的技術路線,本質上是團隊的人員能力模型、特質和最初要解決的問題決定了最終走向哪條路線。技術沒有絕對的好與壞,只有是不是合適。今天我們看到很多金融政企客戶都在提分散式資料庫,從0到1的突破可能是由於政策性的突破,因為國產化,但從1到N的突破,是需要產品本身競爭力的突破。我們發現,在這個階段,客戶不再關心分散式,客戶關心什麼?關心的是資料庫本身。不管叫什麼技術,能不能滿足需求,能不能提供足夠的效能、足夠的擴充套件性、足夠的高可用,能不能支撐複雜的業務場景,我們的觀點是,最終這個行業會迴歸到他的本源,分散式資料庫的本源是資料庫,不管叫分散式+還是資料庫+,最終給客戶的核心價值仍然是資料庫。因此,資料庫+更能匹配金融政企未來長期的發展。
GaussDB融合了華為在資料庫領域15年多的戰略投入,是基於分散式理論打造的行業領先的國產原生分散式關係型資料庫,採用行業先進的全並行分散式架構,有應對海量併發事務處理與複雜查詢混合負載的能力;還有同城跨AZ、兩地三中心、資料0丟失等多種高可用方案,出色的金融級高可用商用能力全方面滿足金融級監管要求。
現在,GaussDB已經在金融行業積累了非常豐富的實踐經驗,歷經華為終端雲、華為流程IT、全球TOP銀行、運營商等各種嚴苛場景的考驗,不僅成功助力郵儲銀行新一代個人業務分散式核心系統全面投產上線,為全行6.5億個人客戶、4萬多個網點提供日均20億筆、峰值6.7萬筆/秒的交易處理能力,還通過一系列技術創新,輕鬆支撐華為流程IT ERP系統5倍業務壓力下效能保持線性,實現業務效率的10倍提升,是企業數字化轉型、核心資料上雲、分散式改造的信賴之選。
- 使用卷積神經網路實現圖片去摩爾紋
- 核心不中斷前提下,Gaussdb(DWS)記憶體報錯排查方法
- 簡述幾種常用的排序演算法
- 自動調優工具AOE,讓你的模型在昇騰平臺上高效執行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及程式碼實現
- CosineWarmup理論與程式碼實戰
- 淺談DWS函數出參方式
- 程式碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種資料預處理的方式:AIPP和DVPP
- 詳解ResNet 網路,如何讓網路變得更“深”了
- 帶你掌握如何檢視並讀懂昇騰平臺的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網路卷積層?
- 在昇騰平臺上對TensorFlow網路進行效能調優
- 介紹3種ssh遠端連線的方式
- 分散式資料庫架構路線大揭祕
- DBA必備的Mysql知識點:資料型別和運算子
- 5個高併發導致數倉資源類報錯分析