【建議收藏】超詳細的Canal入門,看這篇就夠了!!!
概述
canal是阿里巴巴旗下的一款開源專案,純Java開發。基於資料庫增量日誌解析,提供增量資料訂閱&消費,目前主要支援了MySQL(也支援mariaDB)。
背景
早期,阿里巴巴B2B公司因為存在杭州和美國雙機房部署,存在跨機房同步的業務需求。不過早期的資料庫同步業務,主要是基於trigger的方式獲取增量變更,不過從2010年開始,阿里系公司開始逐步的嘗試基於資料庫的日誌解析,獲取增量變更進行同步,由此衍生出了增量訂閱&消費的業務,從此開啟了一段新紀元。ps. 目前內部使用的同步,已經支援mysql5.x和oracle部分版本的日誌解析
基於日誌增量訂閱&消費支援的業務:
- 資料庫映象
- 資料庫實時備份
- 多級索引 (賣家和買家各自分庫索引)
- search build
- 業務cache重新整理
- 價格變化等重要業務訊息
當前的 canal 支援源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
工作原理
Mysql的BinLog
它記錄了所有的DDL和DML(除了資料查詢語句)語句,以事件形式記錄,還包含語句所執行的消耗的時間。主要用來備份和資料同步。
binlog 有三種模式:STATEMENT、ROW、MIXED
- STATEMENT 記錄的是執行的sql語句
- ROW 記錄的是真實的行資料記錄
- MIXED 記錄的是1+2,優先按照1的模式記錄
舉例說明
舉例來說,下面的sql
COPYupdate user set age=20
對應STATEMENT模式只有一條記錄,對應ROW模式則有可能有成千上萬條記錄(取決資料庫中的記錄數)。
MySQL主備複製原理
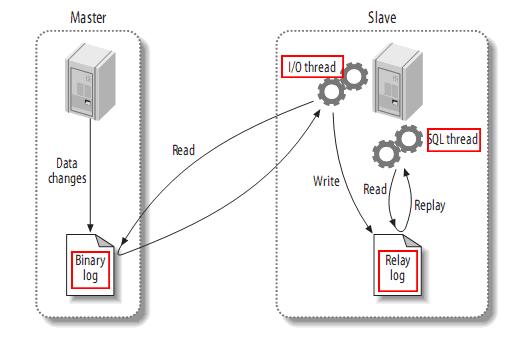
- Slave 上面的IO執行緒連線上 Master,並請求從指定日誌檔案的指定位置(或者從最開始的日誌)之後的日誌內容;
- Master 接收到來自 Slave 的 IO 執行緒的請求後,通過負責複製的 IO 執行緒根據請求資訊讀取指定日誌指定位置之後的日誌資訊,返回給 Slave 端的 IO 執行緒。返回資訊中除了日誌所包含的資訊之外,還包括本次返回的資訊在 Master 端的 Binary Log 檔案的名稱以及在 Binary Log 中的位置;
- Slave 的 IO 執行緒接收到資訊後,將接收到的日誌內容依次寫入到 Slave 端的Relay Log檔案(mysql-relay-bin.xxxxxx)的最末端,並將讀取到的Master端的bin-log的檔名和位置記錄到master- info檔案中,以便在下一次讀取的時候能夠清楚的高速Master“我需要從某個bin-log的哪個位置開始往後的日誌內容,請發給我”
- Slave 的 SQL 執行緒檢測到 Relay Log 中新增加了內容後,會馬上解析該 Log 檔案中的內容成為在 Master 端真實執行時候的那些可執行的 Query 語句,並在自身執行這些 Query。這樣,實際上就是在 Master 端和 Slave 端執行了同樣的 Query,所以兩端的資料是完全一樣的。 當然這個過程本質上還是存在一定的延遲的。
mysql的binlog檔案長這個樣子。
COPYmysql-bin.003831
mysql-bin.003840
mysql-bin.003849
mysql-bin.003858
啟用Binlog注意以下幾點:
- Master主庫一般會有多臺Slave訂閱,且Master主庫要支援業務系統實時變更操作,伺服器資源會有瓶頸;
- 需要同步的資料表一定要有主鍵;
canal能夠同步資料的原理
理解了mysql的主從同步的機制再來看canal就比較清晰了,canal主要是聽過偽裝成mysql從server來向主server拉取資料。

- canal模擬mysql slave的互動協議,偽裝自己為mysql slave,向mysql master傳送dump協議
- mysql master收到dump請求,開始推送binary log給slave(也就是canal)
- canal解析binary log物件(原始為byte流)
Canal架構
canal的設計理念
canal的元件化設計非常好,有點類似於tomcat的設計。使用組合設計,依賴倒置,面向介面的設計。

canal的元件
- canal server 這個代表了我們部署的一個canal 應用
- canal instance 這個代表了一個canal server中的多個 mysql instance ,從這一點說明一個canal server可以蒐集多個庫的資料,在canal中叫 destionation。
每個canal instance 有多個元件構成。在conf/spring/default-instance.xml中配置了這些元件。他其實是使用了spring的容器來進行這些元件管理的。
instance 包含的元件
這裡是一個cannalInstance工作所包含的大元件。擷取自
conf/spring/default-instance.xml
COPY<bean id="instance" class="com.alibaba.otter.canal.instance.spring.CanalInstanceWithSpring">
<property name="destination" value="${canal.instance.destination}" />
<property name="eventParser">
<ref local="eventParser" />
</property>
<property name="eventSink">
<ref local="eventSink" />
</property>
<property name="eventStore">
<ref local="eventStore" />
</property>
<property name="metaManager">
<ref local="metaManager" />
</property>
<property name="alarmHandler">
<ref local="alarmHandler" />
</property>
</bean>
EventParser設計
eventParser 最基本的元件,類似於mysql從庫的dump執行緒,負責從master中獲取bin_log

整個parser過程大致可分為幾步:
- Connection獲取上一次解析成功的位置 (如果第一次啟動,則獲取初始指定的位置或者是當前資料庫的binlog位點)
- Connection建立連結,傳送BINLOG_DUMP指令 // 0. write command number // 1. write 4 bytes bin-log position to start at // 2. write 2 bytes bin-log flags // 3. write 4 bytes server id of the slave // 4. write bin-log file name
- Mysql開始推送Binaly Log
- 接收到的Binaly Log的通過Binlog parser進行協議解析,補充一些特定資訊 // 補充欄位名字,欄位型別,主鍵資訊,unsigned型別處理
- 傳遞給EventSink模組進行資料儲存,是一個阻塞操作,直到儲存成功
- 儲存成功後,定時記錄Binaly Log位置
EventSink設計
eventSink 資料的歸集,使用設定的filter對bin log進行過濾,工作的過程如下。

說明:
資料過濾:支援萬用字元的過濾模式,表名,欄位內容等
資料路由/分發:解決1:n (1個parser對應多個store的模式)
資料歸併:解決n:1 (多個parser對應1個store)
資料加工:在進入store之前進行額外的處理,比如join
資料1:n業務
為了合理的利用資料庫資源, 一般常見的業務都是按照schema進行隔離,然後在mysql上層或者dao這一層面上,進行一個數據源路由,遮蔽資料庫物理位置對開發的影響,阿里系主要是通過cobar/tddl來解決資料來源路由問題。
所以,一般一個數據庫例項上,會部署多個schema,每個schema會有由1個或者多個業務方關注
資料n:1業務
同樣,當一個業務的資料規模達到一定的量級後,必然會涉及到水平拆分和垂直拆分的問題,針對這些拆分的資料需要處理時,就需要連結多個store進行處理,消費的位點就會變成多份,而且資料消費的進度無法得到儘可能有序的保證。
所以,在一定業務場景下,需要將拆分後的增量資料進行歸併處理,比如按照時間戳/全域性id進行排序歸併.
EventStore設計
eventStore 用來儲存filter過濾後的資料,canal目前的資料只在這裡儲存,工作流程如下
- 目前僅實現了Memory記憶體模式,後續計劃增加本地file儲存,mixed混合模式
- 借鑑了Disruptor的RingBuffer的實現思路
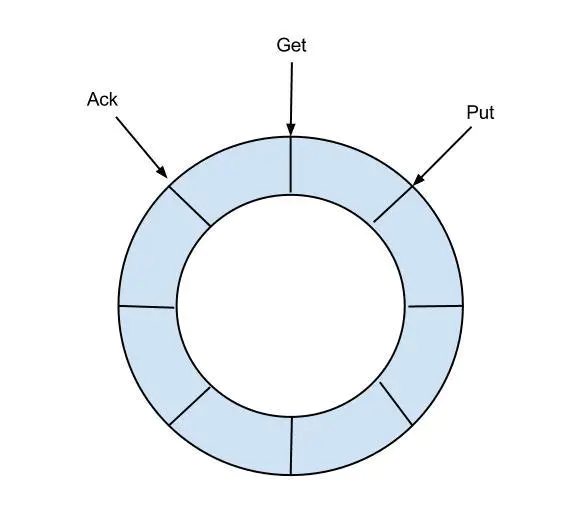
定義了3個cursor
- Put : Sink模組進行資料儲存的最後一次寫入位置
- Get : 資料訂閱獲取的最後一次提取位置
- Ack : 資料消費成功的最後一次消費位置
借鑑Disruptor的RingBuffer的實現,將RingBuffer拉直來看:

實現說明:
- Put/Get/Ack cursor用於遞增,採用long型儲存
- buffer的get操作,通過取餘或者與操作。(與操作: cusor & (size - 1) , size需要為2的指數,效率比較高)
metaManager
metaManager 用來儲存一些原資料,比如消費到的遊標,當前活動的server等資訊
alarmHandler
alarmHandler 報警,這個一般情況下就是錯誤日誌,理論上應該是可以定製成郵件等形式,但是目前不支援
各個元件目前支援的型別
canal採用了spring bean container的方式來組裝一個canal instance ,目的是為了能夠更加靈活。
canal通過這些元件的選取可以達到不同使用場景的效果,比如單機的話,一般使用file來儲存metadata就行了,HA的話一般使用zookeeper來儲存metadata。
eventParser
eventParser 目前只有三種
- MysqlEventParser 用於解析mysql的日誌
- GroupEventParser 多個eventParser的集合,理論上是對應了分表的情況,可以通過這個合併到一起
- RdsLocalBinlogEventParser 基於rds的binlog 的複製
eventSink
eventSink 目前只有EntryEventSink 就是基於mysql的binlog資料物件的處理操作
eventStore
eventStore 目前只有一種 MemoryEventStoreWithBuffer,內部使用了一個ringbuffer 也就是說canal解析的資料都是存在記憶體中的,並沒有到zookeeper當中。
metaManager
metaManager 這個比較多,其實根據元資料存放的位置可以分為三大類,memory,file,zookeeper
Canal-HA機制
canal是支援HA的,其實現機制也是依賴zookeeper來實現的,用到的特性有watcher和EPHEMERAL節點(和session生命週期繫結),與HDFS的HA類似。
canal的ha分為兩部分,canal server和canal client分別有對應的ha實現
- canal server: 為了減少對mysql dump的請求,不同server上的instance(不同server上的相同instance)要求同一時間只能有一個處於running,其他的處於standby狀態(standby是instance的狀態)。
- canal client: 為了保證有序性,一份instance同一時間只能由一個canal client進行get/ack/rollback操作,否則客戶端接收無法保證有序。
server ha的架構圖如下

大致步驟:
- canal server要啟動某個canal instance時都先向zookeeper_進行一次嘗試啟動判斷_(實現:建立EPHEMERAL節點,誰建立成功就允許誰啟動)
- 建立zookeeper節點成功後,對應的canal server就啟動對應的canal instance,沒有建立成功的canal instance就會處於standby狀態。
- 一旦zookeeper發現canal server A建立的instance節點消失後,立即通知其他的canal server再次進行步驟1的操作,重新選出一個canal server啟動instance。
- canal client每次進行connect時,會首先向zookeeper詢問當前是誰啟動了canal instance,然後和其建立連結,一旦連結不可用,會重新嘗試connect。
Canal Client的方式和canal server方式類似,也是利用zookeeper的搶佔EPHEMERAL節點的方式進行控制.
canal的工作過程
dump日誌
啟動時去MySQL 進行dump操作的binlog 位置確定
工作的過程。在啟動一個canal instance 的時候,首先啟動一個eventParser 執行緒來進行資料的dump 當他去master拉取binlog的時候需要binlog的位置,這個位置的確定是按照如下的順序來確定的(這個地方講述的是HA模式哈)。
- 在啟動的時候判斷是否使用zookeeper,如果是zookeeper,看能否拿到 cursor (也就是binlog的資訊),如果能夠拿到,把這個資訊存到記憶體中(MemoryLogPositionManager),然後拿這個資訊去mysql中dump binlog
- 通過1拿不到的話(一般是zookeeper當中每一,比如第一次搭建的時候,或者因為某些原因zk中的資料被刪除了),就去配置檔案配置當中的去拿,把這個資訊存到記憶體中(MemoryLogPositionManager),然後拿這個資訊去mysql中dump binlog
- 通過2依然沒有拿到的話,就去mysql 中執行一個sql
show master status這個語句會顯示當前mysql binlog最後位置的資訊,也就是剛寫入的binlog所在的位置資訊。把這個資訊存到記憶體中(MemoryLogPositionManager),然後拿這個資訊去mysql中dump binlog。
後面的eventParser的操作就會以記憶體中(MemoryLogPositionManager)儲存的binlog位置去master進行dump操作了。
mysql的
show master status操作
COPYmysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000028
Position: 635762367
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 18db0532-6a08-11e8-a13e-52540042a113:1-2784514,
318556ef-4e47-11e6-81b6-52540097a9a8:1-30002,
ac5a3780-63ad-11e8-a9ac-52540042a113:1-5,
be44d87c-4f25-11e6-a0a8-525400de9ffd:1-156349782
1 row in set (0.00 sec
歸集(sink)和儲存(store)
資料在dump回來之後進行的歸集(sink)和儲存(store)
sink操作是可以支撐將多個eventParser的資料進行過濾filter
filter使用的是instance.properties中配置的filter,當然這個filter也可以由canal的client端在進行subscribe的時候進行設定。如果在client端進行了設定,那麼服務端配置檔案instance.properties的配置都會失效
sink 之後將過濾後的資料儲存到eventStore當中去。
目前eventStore的實現只有一個MemoryEventStoreWithBuffer,也就是基於記憶體的ringbuffer,使用這個store有一個特點,這個ringbuffer是基於記憶體的,大小是有限制的(bufferSize = 16 * 1024 也就是16M),所以,當canal的客戶端消費比較慢的時候,ringbuffer中存滿了就會阻塞sink操作,那麼正讀取mysql binlog的eventParser執行緒也會受阻。 這種設計其實也是有道理的。 因為canal的操作是pull 模型,不是producer push的模型,所以他沒必要儲存太多資料,這樣就可以避免了資料儲存和持久化管理的一些問題。使資料管理的複雜度大大降低。
上面這些整個是canal的parser 執行緒的工作流程,主要對應的就是將資料從mysql搞下來,做一些基本的歸集和過濾,然後儲存到記憶體中。
binlog的消費者
canal從mysql訂閱了binlog以後主要還是想要給消費者使用。那麼binlog是在什麼時候被消費呢。這就是另一條主線了。就像咱們做一個toC的系統,管理系統是必須的,使用者使用的app或者web又是一套,eventParser 執行緒就像是管理系統,往裡面錄入基礎資料。canal的client就像是app端一樣,是這些資料的消費方。 binlog的主要消費者就是canal的client端。使用的協議是基於tcp的google.protobuf,當然tcp的模式是io多路複用,也就是nio。當我們的client發起請求之後,canal的server端就會從eventStore中將資料傳輸給客戶端。根據客戶端的ack機制,將binlog的元資料資訊定期同步到zookeeper當中。
canal的目錄結構
配置父目錄: 在下面可以看到
COPYcanal
├── bin
│ ├── canal.pid
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
└── conf
├── canal.properties
├── gamer ---目錄
├── ww_social ---目錄
├── wother ---目錄
├── nihao ---目錄
├── liveim ---目錄
├── logback.xml
├── spring ---目錄
├── ym ---目錄
└── xrm_ppp ---目錄
這裡是全部展開的目錄
COPYcanal
├── bin
│ ├── canal.pid
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
└── conf
├── canal.properties
├── game_center
│ └── instance.properties
├── ww_social
│ ├── h2.mv.db
│ ├── h2.trace.db
│ └── instance.properties
├── wwother
│ ├── h2.mv.db
│ └── instance.properties
├── nihao
│ ├── h2.mv.db
│ ├── h2.trace.db
│ └── instance.properties
├── movie
│ ├── h2.mv.db
│ └── instance.properties
├── logback.xml
├── spring
│ ├── default-instance.xml
│ ├── file-instance.xml
│ ├── group-instance.xml
│ ├── local-instance.xml
│ ├── memory-instance.xml
│ └── tsdb
│ ├── h2-tsdb.xml
│ ├── mysql-tsdb.xml
│ ├── sql
│ └── sql-map
└── ym
└── instance.properties
Canal應用場景
同步快取redis/全文搜尋ES
canal一個常見應用場景是同步快取/全文搜尋,當資料庫變更後通過binlog進行快取/ES的增量更新。當快取/ES更新出現問題時,應該回退binlog到過去某個位置進行重新同步,並提供全量重新整理快取/ES的方法,如下圖所示。

下發任務
另一種常見應用場景是下發任務,當資料變更時需要通知其他依賴系統。其原理是任務系統監聽資料庫變更,然後將變更的資料寫入MQ/kafka進行任務下發,比如商品資料變更後需要通知商品詳情頁、列表頁、搜尋頁等先關係統。這種方式可以保證資料下發的精確性,通過MQ傳送訊息通知變更快取是無法做到這一點的,而且業務系統中不會散落著各種下發MQ的程式碼,從而實現了下發歸集,如下圖所示。

資料異構
在大型網站架構中,DB都會採用分庫分表來解決容量和效能問題,但分庫分表之後帶來的新問題。比如不同維度的查詢或者聚合查詢,此時就會非常棘手。一般我們會通過資料異構機制來解決此問題。
所謂的資料異構,那就是將需要join查詢的多表按照某一個維度又聚合在一個DB中。讓你去查詢。canal就是實現資料異構的手段之一。

本文由
傳智教育博學谷狂野架構師教研團隊釋出。如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支援是我堅持創作的動力。轉載請註明出處!
- ElasticSearch還能效能調優,漲見識、漲見識了!!!
- 【必須收藏】別再亂找TiDB 叢集部署教程了,這篇保姆級教程來幫你!!| 博學谷狂野架構師
- 【建議收藏】7000 字的TIDB保姆級簡介,你見過嗎
- Tomcat架構設計剖析 | 博學谷狂野架構師
- 你可能不那麼知道的Tomcat生命週期管理 | 博學谷狂野架構師
- 大哥,這是併發不是並行,Are You Ok?
- 為啥要重學Tomcat?| 博學谷狂野架構師
- 這是一篇純講SQL語句優化的文章!!!| 博學谷狂野架構師
- 捲起來!!!看了這篇文章我才知道MySQL事務&MVCC到底是啥?
- 為什麼99%的程式設計師都做不好SQL優化?
- 如何搞定MySQL鎖(全域性鎖、表級鎖、行級鎖)?這篇文章告訴你答案!太TMD詳細了!!!
- 【建議收藏】超詳細的Canal入門,看這篇就夠了!!!
- 從菜鳥程式設計師到高階架構師,竟然是因為這個字final
- 為什麼95%的Java程式設計師,都是用不好Synchronized?
- 99%的Java程式設計師者,都敗給這一個字!
- 8000 字,就說一個字Volatile
- 98%的程式設計師,都沒有研究過JVM重排序和順序一致性
- 來一波騷操作,Java記憶體模型
- 時隔多年,這次我終於把動態代理的原始碼翻了個地兒朝天
- 再有人問你分散式事務,把這篇文章砸過去給他