聯邦學習開源框架FATE架構
作者:京東科技 葛星宇
1.前言
本文除特殊説明外,所指的都是fate 1.9版本。
fate資料存在着多處版本功能與發佈的文檔不匹配的情況,各個模塊都有獨立的文檔,功能又有關聯,坑比較多,首先要理清楚各概念、模塊之間的關係。
2.網絡互聯架構
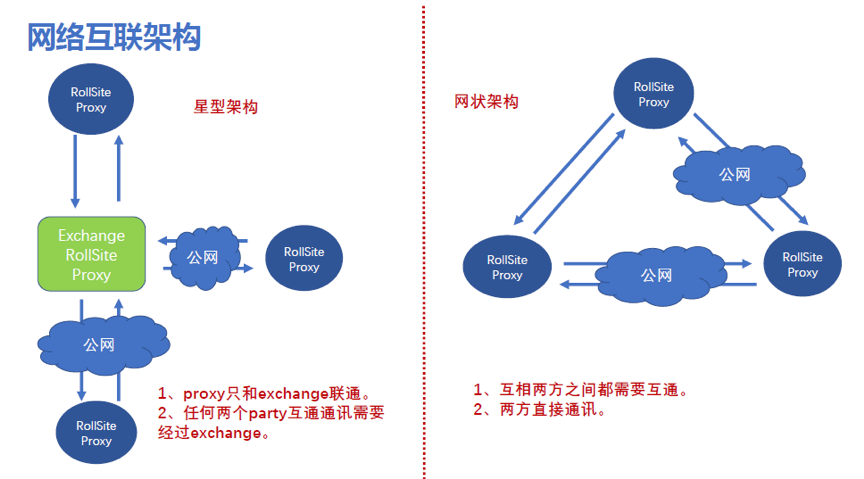
1. 概念解釋:
RollSite是一個grpc通信組件,是eggroll引擎中的一個模塊,相當於我們的grpc通信網關。
Exchange是RollSite中的一個功能,用於維護各方網關地址,並轉發消息。參考《FATE exchange部署指南》
2. 對比解讀:
l 網狀架構相當於我們的一體化版本模式,但沒有dop平台來維護網關,每方需要在配置文件裏維護其他參與方的網關地址。
l 星型架構的好處是隻在Exchange方維護所有參與方的網關地址,前提是需要信任Exchange,並且流量全部都需要從Exchange方中轉,相當於我們的中心化版本。但不支持證書。
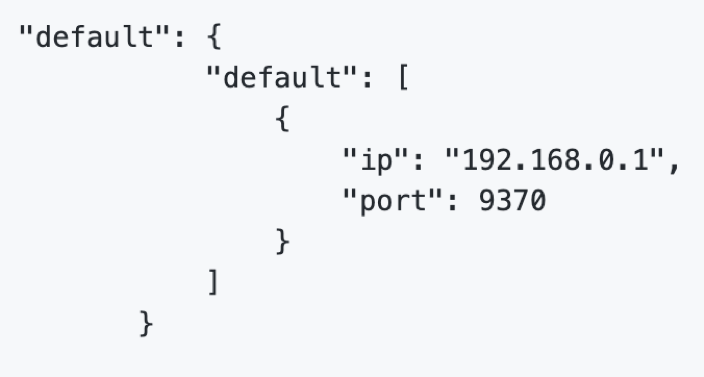
3. Exchange配置
在Exchange上配置路由表:

在各party方配置默認路由指向exchange,不需要再配置每個party的地址。
3.總體架構
FATE支持eggroll和spark兩種計算引擎,搭配不同的通信組件,共五種組合,不同的通信模塊不能兼容。
| 方案名 | 計算引擎 | 存儲 | 通信 | 是否支持exchange | task調度 | 特點 | | EggRoll | nodemanager | nodemanager | rollsite | 是 | clustermanager | 原生、最成熟 | | Spark_RabbitMQ | spark | hdfs | nginx+ rabbit | 否 | yarn? | 簡單易上手的MQ | | Spark_Pulsar | spark | hdfs | nginx+ pulsar | 是 | yarn? | 比RabbitMQ,可以支持更大規模的集羣化部署 | | Slim FATE | spark_local | localFS | nginx+ pulsar | 是 | spark? | 最小資源。可用rabbit替代pulsar |
區別:
l RabbitMQ是一個簡單易上手的MQ
l Pulsar相比RabbitMQ,可以支持更大規模的集羣化部署,也支持exchange模式的網絡結構。
l Slim FATE相比其他模式,最大化減少集羣所需的組件,可以使用在小規模聯邦學習計算,IOT設備等情況。
3.1.基於EggRoll引擎的架構
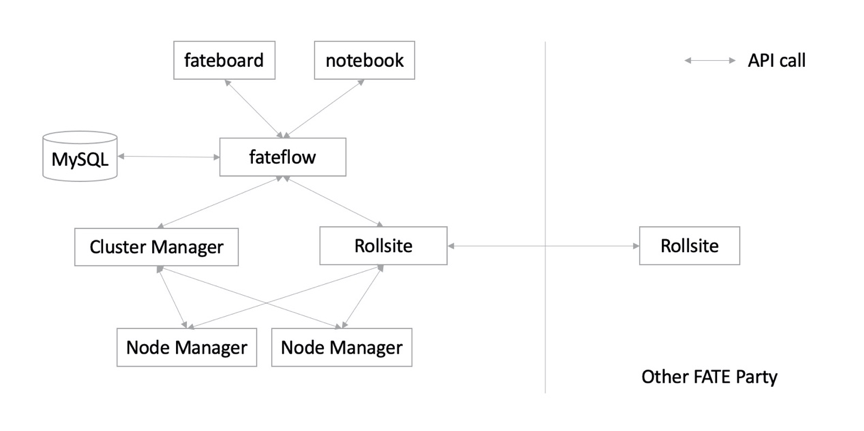
Eggroll是FATE原生支持的計算存儲引擎,包括以下三個組件:
l rollsite負責數據傳輸,以前的版本里叫 Proxy+Federation
l nodemanager負責存儲和計算
l clustermanager負責管理nodemanager
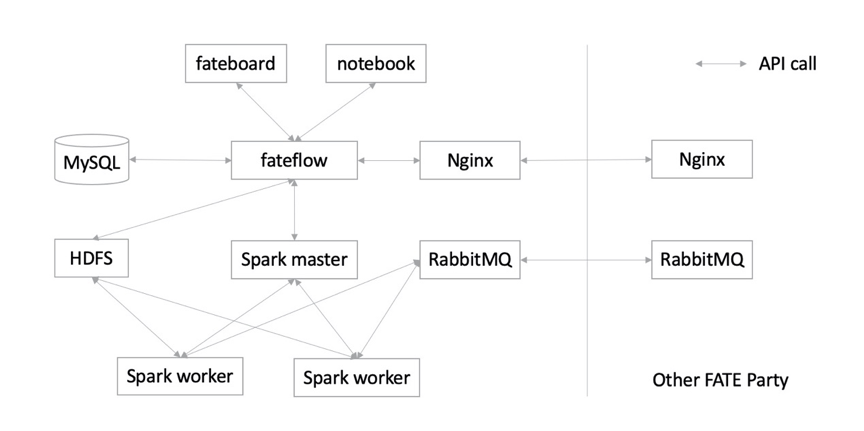
3.2.基於spark+hdfs+rabbitMQ的架構
3.3. 基於spark+hdfs+Pulsar的架構
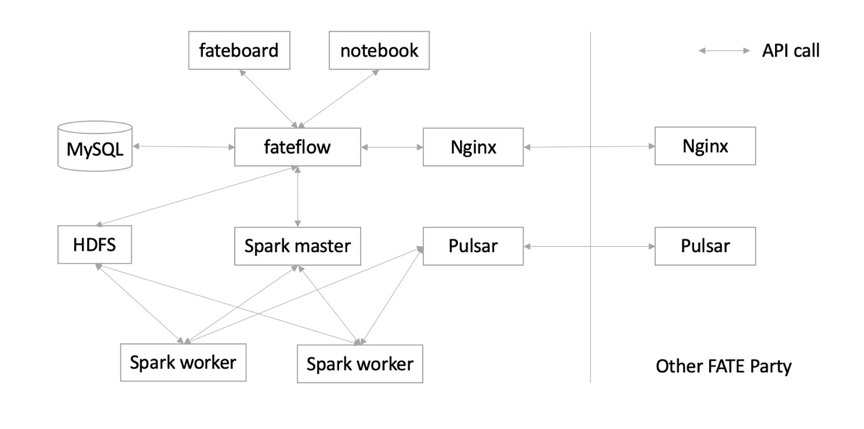
3.4. spark_local (Slim FATE)
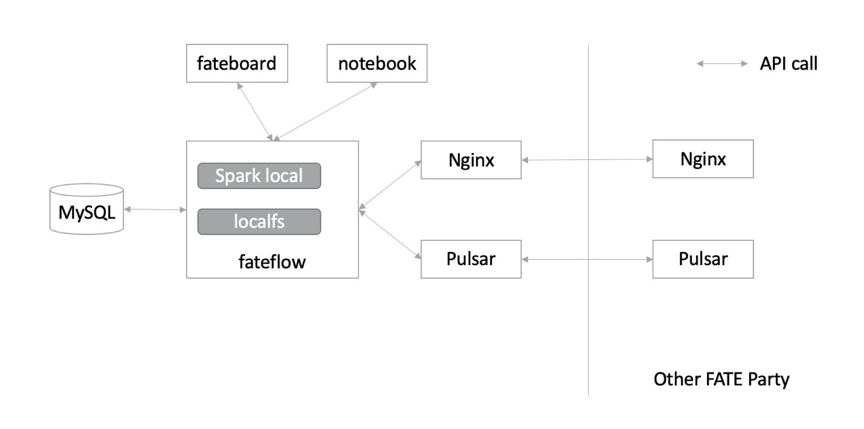
支持rabbitMQ替換pulsar
4. 組件源碼
所有的fate項目都在這個叫FederateAI社區的URL下:http://github.com/FederatedAI
主項目:FATE是一個彙總的文檔和超鏈集合, 學習入口,在線文檔
關聯項目:
•KubeFATE docker和k8s的部署
•AnsibleFATE 相當於我們的圖形化部署版的底層腳本 學習入口
•FATE-Flow 聯合學習任務流水線管理模塊,註冊、管理和調度中心。
•EggRoll 第一代fate的計算引擎
•FATE-Board 聯合學習過程可視化模塊,目前只能查看一些記錄
•FATE-Serving 在線聯合預測,學習入口
•FATE-Cloud 聯邦學習雲服務,類似於我們的dop平台,管理功能。
•FedVision 聯邦學習支持的可視化對象檢測平台
•FATE-Builder fate編譯工具
•FedLCM 新增的項目:創建 FATE 聯邦並部署FATE實例。目前僅支持部署以Spark和Pulsar作為基礎引擎,並使用Exchange實現互相連接的
5. FATE-Flow
FATE Flow是調度系統,根據用户提交的作業DSL,調度算法組件執行。
服務能力:
· 數據接入
· 任務組件註冊中心
· 聯合作業&任務調度
· 多方資源協調
· 數據流動追蹤
· 作業實時監測
· 聯合模型註冊中心
· 多方合作權限管理
· 系統高可用
· CLI、REST API、Python API
5.1. 流程架構
舊版,圖比較立體
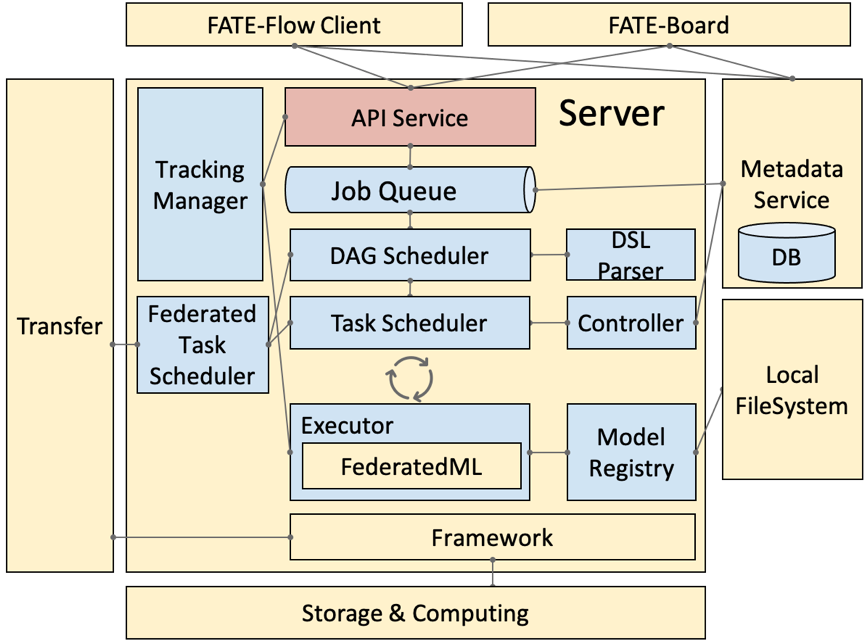
· DSL Parser:是調度的核心,通過 DSL parser 可以拿到上下游關係、依賴等。
· Job Scheduler:是 DAG 層面的調度,把 DAG 作為一個 Job,把 DAG 裏面的節點 run 起來,就稱為一個 task。
· Federated Task Scheduler:最小調度粒度就是 task,需要調度多方運行同一個組件但參數算法不同的 task,結束後,繼續調度下一個組件,這裏就會涉及到協同調度的問題。
· Job Controller:聯邦任務控制器
· Executor:聯邦任務執行節點,支持不同的 Operator 容器,現在支持 Python 和 Script 的 Operator。Executor,在我們目前的應用中拉起 FederatedML 定義的一些組件,如 data io 數據輸入輸出,特徵選擇等模塊,每次調起一個組件去 run,然後,這些組件會調用基礎架構的 API,如 Storage 和 Federation Service ( API 的抽象 ) ,再經過 Proxy 就可以和對端的 FATE-Flow 進行協同調度。
· Tracking Manager:任務輸入輸出的實時追蹤,包括每個 task 輸出的 data 和 model。
· Model Manager:聯邦模型管理器
5.2. api service
DataAccess 數據上傳,下載,歷史記錄,參考示例
Job 提交(並運行),停止,查詢,更新,配置,列表,task查詢
Tracking
Pipeline
Model
Table
客户端命令行實際上是對api的包裝調用,可以參考其示例
Python調用api示例
5.3. 算法模塊
Federatedml模塊包括許多常見機器學習算法聯邦化實現。所有模塊均採用去耦的模塊化方法開發,以增強模塊的可擴展性。具體來説,我們提供:
1.聯邦統計: 包括隱私交集計算,並集計算,皮爾遜係數, PSI等
2.聯邦特徵工程:包括聯邦採樣,聯邦特徵分箱,聯邦特徵選擇等。
3.聯邦機器學習算法:包括橫向和縱向的聯邦LR, GBDT, DNN,遷移學習等
4.模型評估:提供對二分類,多分類,迴歸評估,聚類評估,聯邦和單邊對比評估
5.安全協議:提供了多種安全協議,以進行更安全的多方交互計算。

Figure 1: Federated Machine Learning Framework
可開發在fate框架下運行的算法:指南
6. FATE-Serving
6.1. 功能架構
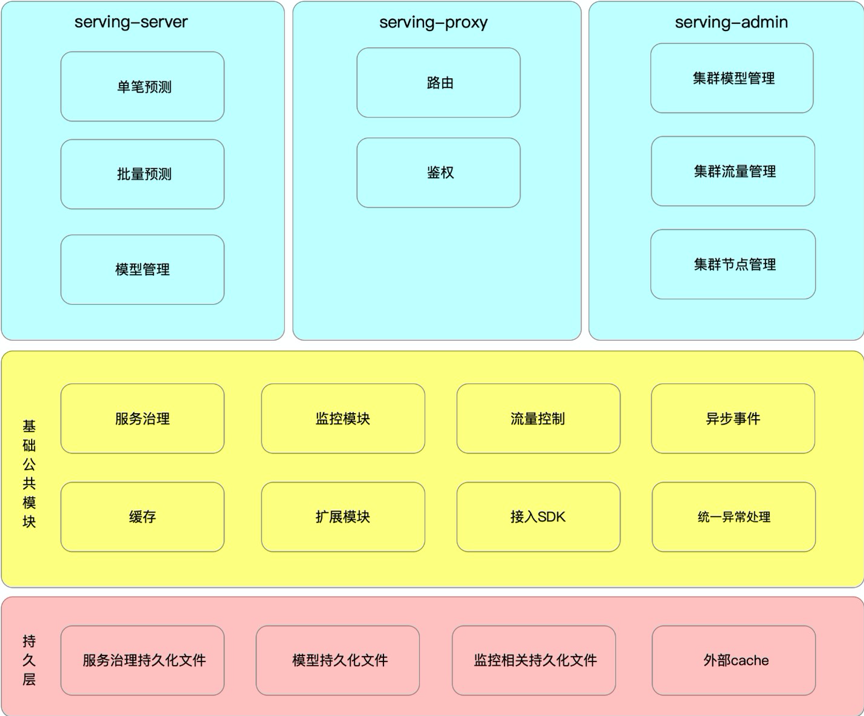
6.2. 部署邏輯架構
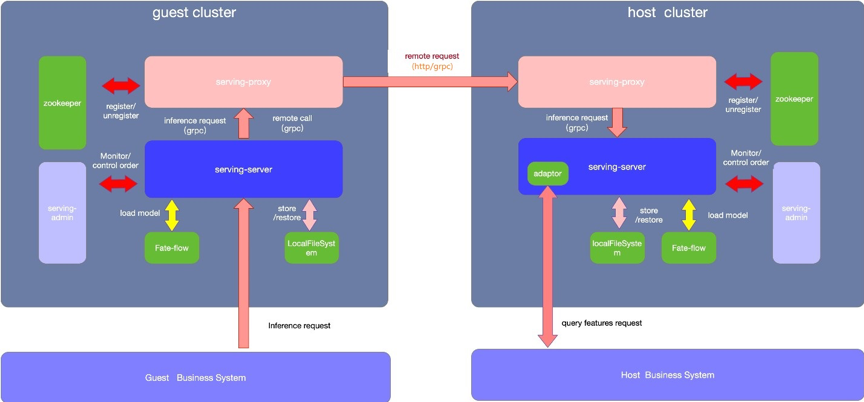
Adatptor:默認的情況使用系統自帶的MockAdatptor,僅返回固定數據用於簡單測試,實際生產環境中需要使用者需要自行開發並對接自己的業務系統。(這部分可以看看能不能對接咱們自己的在線預測系統。)
l 支持使用rollsite/nginx/fateflow作為多方任務協調通信代理
l rollsite支持fate on eggroll的場景,僅支持grpc協議,支持P2P組網及星型組網模式
l nginx支持所有引擎場景,支持http與grpc協議,默認為http,支持P2P組網及星型組網模式
l fateflow支持所有引擎場景,支持http與grpc協議,默認為http,僅支持P2P組網模式,也即只支持互相配置對端fateflow地址
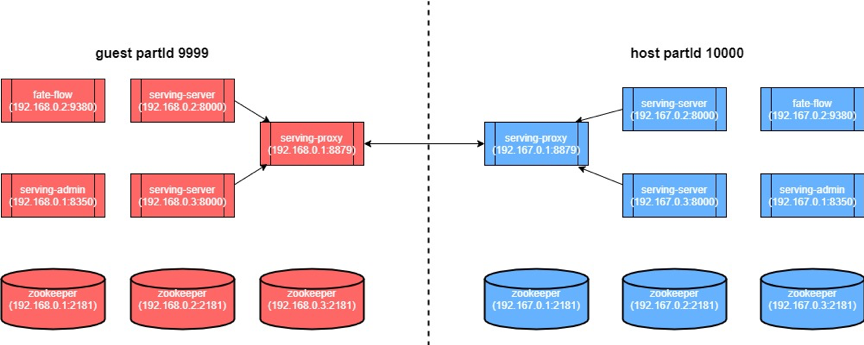
6.3. 部署實例圖
6.4. 工作時序圖

6.5. 模型推送流程
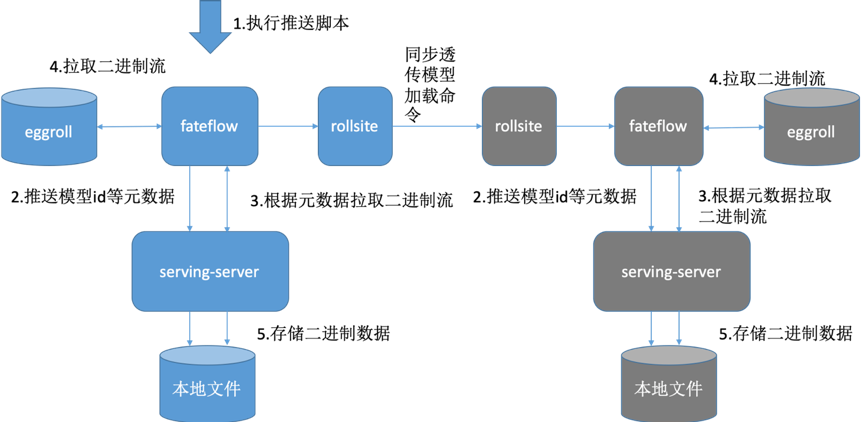
藍色為guest集羣,灰色代表host集羣
1. 通過fate flow建模 2. 分別部署guest方 Fate-serving 與host方Fate-serving
3. 分別配置好guest方Fate-flow與guest方Fate-serving、host方Fate-flow 與host方Fate-serving。
4. Fate-flow推送模型
5. Fate-flow將模型綁定serviceId
6. 以上操作完成後,可以在serving-admin頁面上查看模型相關信息(此步操作非必需)。
7. 可以在serving-admin頁面上測試調用(此步操作非必需)。
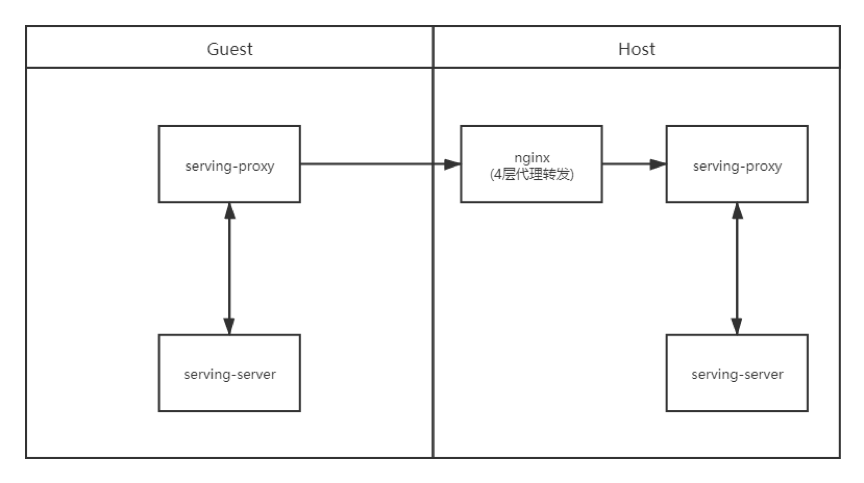
6.6. 搭配nginx代理
http://fate-serving.readthedocs.io/en/develop/example/nginx/
FATE-Serving 之間的交互可以通過nginx反向代理轉發grpc請求,以下幾種場景配置如下:
· 場景一:雙方不配置TLS,通過nginx四層代理轉發
· 場景二:雙方配置TLS,通過nginx四層代理轉發,雙方分別進行證書校驗
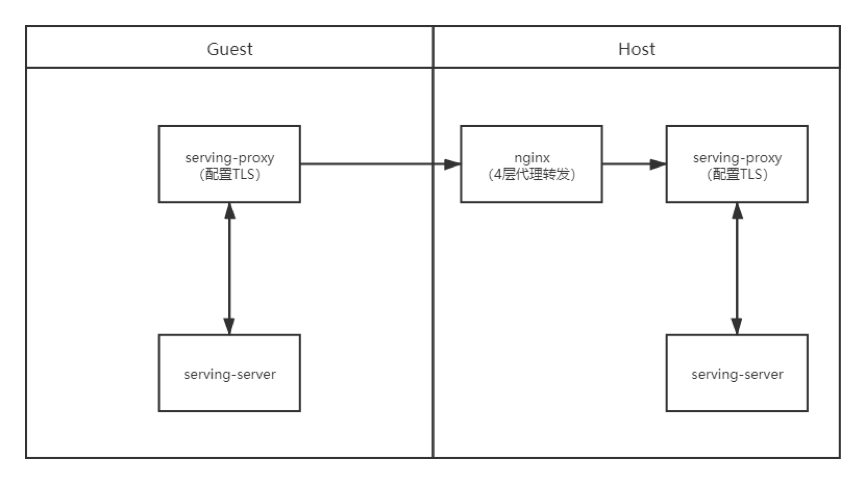
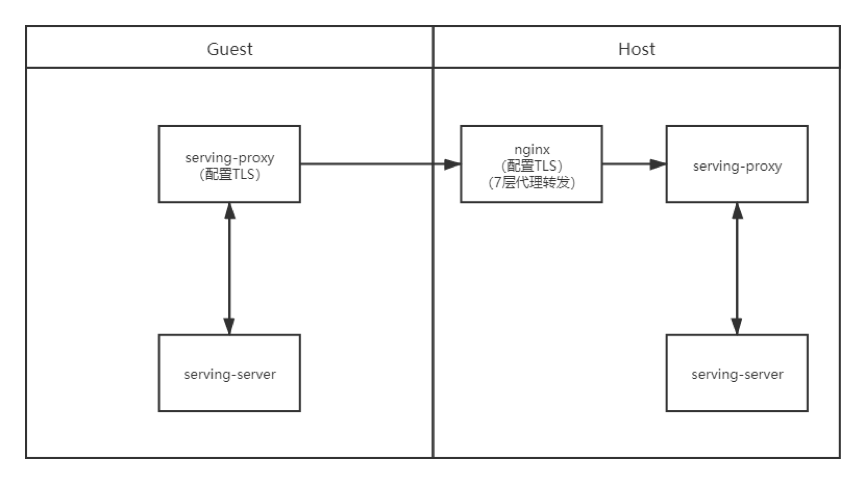
· 場景三:數據使用方配置Client端證書,Nginx配置Server端證書,Host不配置證書,通過nginx七層代理轉發,由Client端和nginx進行證書校驗
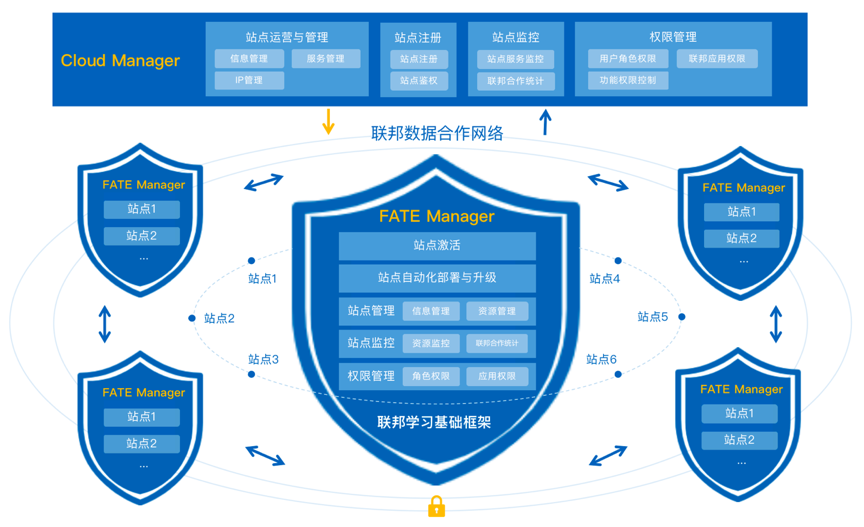
7. FATE Cloud
FATE Cloud由負責聯邦站點管理的雲管理端Cloud Manager和站點客户端管理端FATE Manager組成,提供了聯邦站點的註冊與管理、集羣自動化部署與升級、集羣監控、集羣權限控制等核心功能。
聯邦雲管理端(Cloud Manager)
聯邦雲管理端即聯邦數據網絡的管理中心,負責統一運營和管理FATE Manager及各站點,監控站點的服務與聯邦合作建模,執行聯邦各權限控制,保證聯邦數據合作網絡的正常運作;
聯邦站點管理端(FATE Manager)
聯邦站點管理端,負責管理和維護各自的聯邦站點,為站點提供加入聯邦組織、執行站點服務的自動化部署與升級,監控站點的聯邦合作與集羣服務,並管理站點用户角色與應用權限;
8. 部署測試
共有4類部署方式,單機的安裝模式是隻提供了單機的安裝文檔,也可以研究怎麼擴展成集羣模式。
| | 單機(不推薦生產用) | 集羣(生產推薦) | | 非容器 | AllinOne | ansible | | 容器 | docker compose | k8s |
部署時會要求配置機器對應的角色,只能選host,guest和Exchange,其中host和guest並沒有區別,實際運行聯邦時還是在job的配置中去配置哪一方是guest,哪一方是host,任務只能在guest方提交。
8.1. AllinOne
所有的組件都部署在一台機器上,比較適合開發調試,參考鏈接。
8.2. ansible
嘗試用ansible部署時遇到了python相關的錯誤,指導文檔也缺少詳細的步驟,沒有相關錯誤的説明。
8.3. k8s
手上沒有k8s環境,暫未測試。
8.4. docker compose
容器部署嘗試用docker compose方式部署了一對,比較順利,參考了2篇官方文章,前邊的準備步驟和安裝過程參考此文,“驗證部署”及之後的步驟參考《Docker Compose 部署 FATE》
不同點如下:
8.4.1. 準備階段
下載鏡像較慢,如果大批量部署,可以搭建內網鏡像服務。
| Role | party-id | OS | IP | | | host | 20001 | Centos7.6 | 11.50.52.81 | 8C64G | | guest | 20002 | Centos7.6 | 11.50.52.62 | 8C64G | | 部署機 | | Centos7.6 | 11.50.52.40 | |
以上內容替代文檔中對應的部分內容。
一開始我只部署了一台host,本來打算這2台做一個集羣,後來發現文檔裏沒提這種方式,只好先按文檔實驗一次,於是又部署了guest,這樣在guest的配置裏已經寫好了host的地址,於是手動將配置更新到了host的/data/projects/fate/confs-20001/confs/eggroll/conf/route_table.json
發現不需要重啟容器後續步驟也沒報錯,説明可以動態修改路由信息。
8.4.2. hetero_lr測試
進入容器的時候,容器名包含的平台id需要修改成實際的。
json格式定義説明文檔
fateflow/examples/lr/test_hetero_lr_job_conf.json 中不同點,
修改對應的平台id
"initiator": {
"role": "guest",
"party_id": 20002
},
"role": {
"guest": [
20002
],
"host": [
20001
],
"arbiter": [
20001
]
},
按文檔寫資源不夠運行不了,需要修改如下
"job_parameters": {
"common": {
"task_parallelism": 1,
"computing_partitions": 1,
"task_cores": 1
}
},
不要修改fateflow/examples/lr/test_hetero_lr_job_dsl.json文件,文檔中的配置是舊版本的,修改了就不能執行了,裏面的DataIO組件已廢棄。
運行測試後可以通過board查看,成功的id:202211031508511267810
http://11.50.52.62:8080/#/history
http://11.50.52.81:8080/#/history
8.4.3. 模型部署
# flow model deploy --model-id arbiter-20001#guest-20002#host-20001#model --model-version 202211031508511267810
輸出了產生的model_version是202211031811059832400
1. 修改加載模型的配置
# cat > fateflow/examples/model/publish_load_model.json <<EOF
{
"initiator": {
"party_id": "20002",
"role": "guest"
},
"role": {
"guest": [
"20002"
],
"host": [
"20001"
],
"arbiter": [
"20001"
]
},
"job_parameters": {
"model_id": "arbiter-20001#guest-20002#host-20001#model",
"model_version": "202211031811059832400"
}
}
EOF
2. 修改綁定模型的配置
# cat > fateflow/examples/model/bind_model_service.json <<EOF
{
"service_id": "test",
"initiator": {
"party_id": "20002",
"role": "guest"
},
"role": {
"guest": ["20002"],
"host": ["20001"],
"arbiter": ["20001"]
},
"job_parameters": {
"work_mode": 1,
"model_id": "arbiter-20001#guest-20002#host-20001#model",
"model_version": "202211031811059832400"
}
}
EOF
3. 在線測試
發送以下信息到"GUEST"方的推理服務"{SERVING_SERVICE_IP}:8059/federation/v1/inference"
# curl -X POST -H 'Content-Type: application/json' -i 'http://11.50.52.62:8059/federation/v1/inference' --data '{
"head": {
"serviceId": "test"
},
"body": {
"featureData": {
"x0": 1.88669,
"x1": -1.359293,
"x2": 2.303601,
"x3": 2.00137,
"x4": 1.307686
},
"sendToRemoteFeatureData": {
"phone_num": "122222222"
}
}
}'
9.在Jupyther中構建任務
Jupyter Notebook是web界面IDE。已集成在fate-client容器中。
10. 總結
本文旨在從宏觀的角度分析FATE的源碼分佈、總體架構、主要功能及核心流程,尚有許多細節和功能未深入研究,歡迎大家留言,互相學習。
- 應用健康度隱患刨析解決系列之數據庫時區設置
- 對於Vue3和Ts的心得和思考
- 一文詳解擴散模型:DDPM
- zookeeper的Leader選舉源碼解析
- 一文帶你搞懂如何優化慢SQL
- 京東金融Android瘦身探索與實踐
- 微前端框架single-spa子應用加載解析
- cookie時效無限延長方案
- 聊聊前端性能指標那些事兒
- Spring竟然可以創建“重複”名稱的bean?—一次項目中存在多個bean名稱重複問題的排查
- 京東金融Android瘦身探索與實踐
- Spring源碼核心剖析
- 深入淺出RPC服務 | 不同層的網絡協議
- 安全測試之探索windows遊戲掃雷
- 關於數據庫分庫分表的一點想法
- 對於Vue3和Ts的心得和思考
- Bitmap、RoaringBitmap原理分析
- 京東小程序CI工具實踐
- 測試用例設計指南
- 當你對 redis 説你中意的女孩是 Mia