關於數據庫分庫分表的一點想法
作者:京東物流 何小坡
1 開篇
面對數據的激增,相信大家也都有分庫分表的一些方案,這次的這個分享,算是自己的一個想法,可以當做一個參考方案,也歡迎相互討論。
話不多説,直接進入主題。
日常開發中,實現數據庫的分庫分表,在經常使用工具方面,常用的有像 sharding-sphere、TDDL、Mycat等,然後,根據主鍵key做數據分佈,有兩種常用的方案,Hash取模方案和Range範圍兩種方案,兩種路由算法,通過指定的key值進行運算後進行數據路由。兩種方案也各有各的優缺點,下面做個梳理。
2 Hash取模
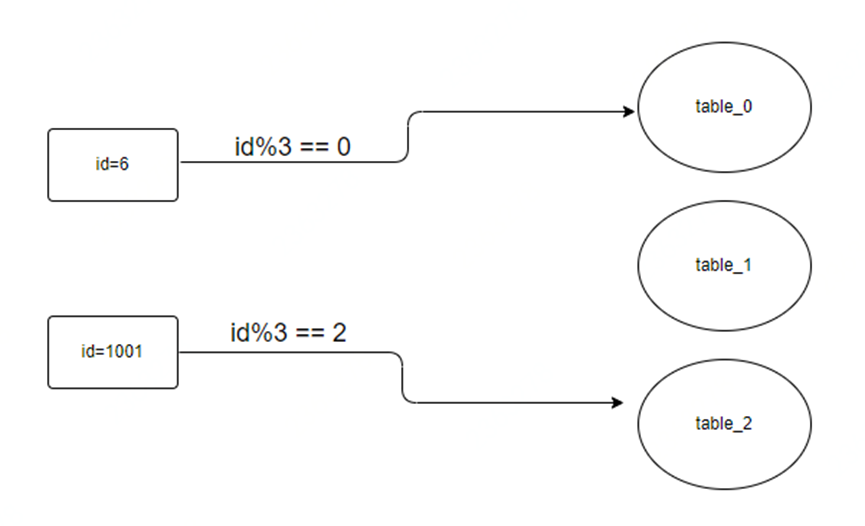
這個方案比較好理解,例如,我們假設未來幾年內,數據能夠增長到3000萬,那,我們可以設計3張表,設表名分別為:table_0, table_1, table_2, 每張表存1000萬數據,我們利用id作為路由key,進行算法處理,將hash運算後的結果與3進行取模,然後根據所得的值,可以將數據存放到對應的表中。這種方式的優點是,數據可以均勻分散的存儲到對應的表中,不會造成數據全部存儲到一個表中的情況,造成熱點庫表;但是缺點的話也很明顯,就是如果以後再需要擴容的話,再新增表後,例如又新增了 table_3, table_4, table_5, 新的取模就從3變成了6,那這時候,之前的表中的數據,就需要做全量的數據遷移,因為取模的值發生了變化,按照新值取模,可能就找不到數據了。那面對大量的已有數據,數據遷移就比較麻煩了。
3 Range範圍方法
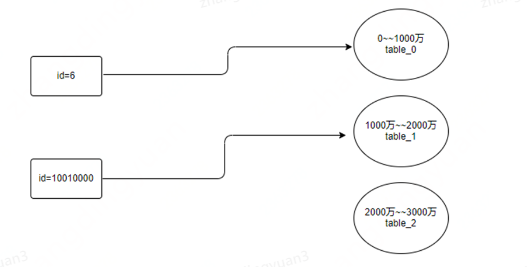
這個方案,也比較好理解,還假設業務後期數據能增長到3000萬,也是可以設計3張表,設為:table_0, table_1, table_2,我看可以按照範圍,將id在0—1000萬的數據,存放在table_0中,id在1000萬—2000萬,存放在table_1中,id在2000萬—3000萬,存放在table_2中。這種方案的話,優點很明顯,就是即使以後擴容,也很方便,直接增加新的表即可;但是缺點的話,也很明顯,數據不能做分散存儲,在某一段兒時間內,數據都會集中存儲在特定的表中,造成單個表壓力過大。
基於以上兩種方式的優勢和劣勢,可以設計一種能夠兼顧兩者優勢的方案,即能使數據能夠分散存儲,也能方便以後的擴容。以下算是一個方案。主要就是利用hash算法來實現數據的分散存儲,利用range方式能夠比較好的擴容,將兩種方案的優勢結合使用。
4 具體方案
我們假設有一個分組的概念,假設項目初期,預期幾年內的數據,數據可以達到6000萬,可以做如下設計:
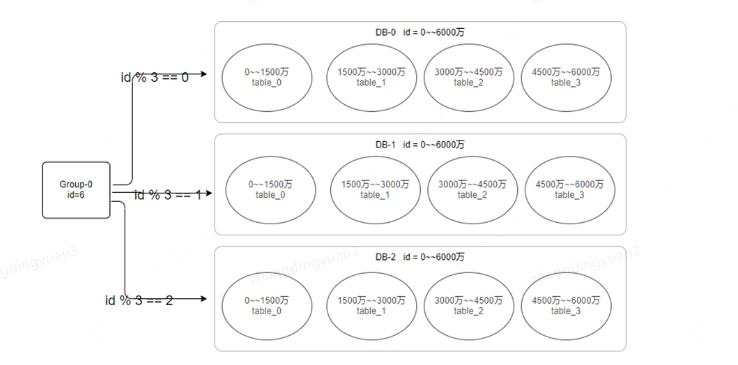
如果後面涉及到擴容,那隻需要再直接增加一個分組即可,在分組內,實現數據的分散存儲,擴容也比較方便。
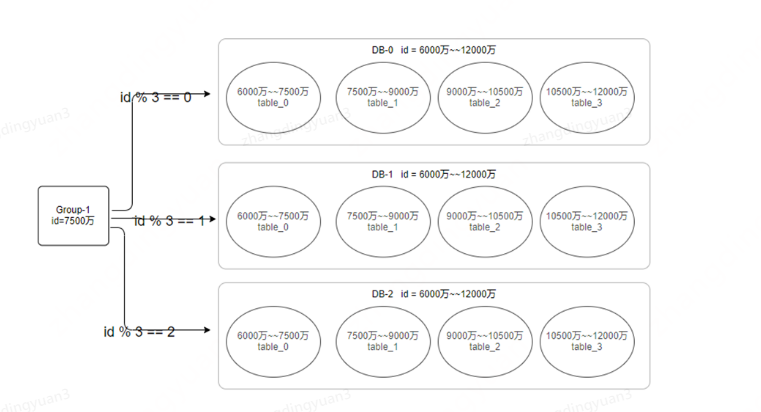
即每次擴容,只需要整體增加一個分組即可,一個分組下,可以存儲將近幾年的數據,所以也不用經常擴容。然後,也可以根據業務情況,將舊數據做歸檔處理,像現在優惠券系統的數據,舊數據就可以做整體歸檔處理,不影響正常業務情況,也減輕生產庫的壓力。
5 總結
分庫分表作為大型應用項目的架構實現方案,確實有一定的複雜性,可以根據當前項目的實際情況,使用適合的工具,做具體開發,最主要的還是需要結合自己的項目的實際業務情況來定,根據數據的分佈以及數據的增長速度,來做結合項目場景的設計。也歡迎大夥一起討論,如果有別的更精妙的“祕籍”,也希望不吝賜教,謝謝。
- 應用健康度隱患刨析解決系列之數據庫時區設置
- 對於Vue3和Ts的心得和思考
- 一文詳解擴散模型:DDPM
- zookeeper的Leader選舉源碼解析
- 一文帶你搞懂如何優化慢SQL
- 京東金融Android瘦身探索與實踐
- 微前端框架single-spa子應用加載解析
- cookie時效無限延長方案
- 聊聊前端性能指標那些事兒
- Spring竟然可以創建“重複”名稱的bean?—一次項目中存在多個bean名稱重複問題的排查
- 京東金融Android瘦身探索與實踐
- Spring源碼核心剖析
- 深入淺出RPC服務 | 不同層的網絡協議
- 安全測試之探索windows遊戲掃雷
- 關於數據庫分庫分表的一點想法
- 對於Vue3和Ts的心得和思考
- Bitmap、RoaringBitmap原理分析
- 京東小程序CI工具實踐
- 測試用例設計指南
- 當你對 redis 説你中意的女孩是 Mia