如何快速搭建openGemini執行狀態的實時監控系統?
監控系統是運維工作中不可或缺的一項技術,一個好的監控系統能夠對裝置和系統的關鍵指標實時採集、儲存、分析、告警,真正做到“事前預警,事後追蹤”,從而大大降低運維成本,提高運維效率。
openGemini提供了260+項豐富的核心執行狀態和裝置執行監控指標,來滿足我們日常的監控告警需求和幫助問題定位,本文將著重介紹如何搭建openGemini的核心執行實時監控系統。
整體部署
監控系統的整體部署方案如下圖所示:

該方案包含監控資料生產、採集、儲存、分析告警和展示等所有功能,主要由四部分組成:
openGemini叢集: 隨著業務執行,openGemini持續輸出核心執行狀態的各項指標資料。openGemini同時支援兩種方式輸出指標資料,第一種將指標資料輸出到日誌中;第二種則為HTTP方式,採用openGemini的資料格式,接收端需使用InfluxDB或openGemini這兩種資料庫均可。
指標採集:如上所述,採用HTTP方式輸出指標資料,則無需額外的資料採集工具,但會缺乏一些監控指標,如磁碟利用率、建立的表總數、時間線數量、建立的資料庫總數等。
如果將資料輸出到日誌中時,則需要使用ts-monitor進行指標資料採集,除核心執行狀態指標資料之外,ts-monitor工具還將採集如磁碟利用率、建立的表總數、時間線數量、建立的資料庫總數等指標。ts-monitor同樣將指標資料轉換為openGemini的資料格式進行上報。
資料儲存:考慮到監控系統頻繁的查詢操作,長期來看,為避免對業務叢集的執行資源造成競爭,從而影響業務效率,因此建議將指標資料轉存到專門的儲存節點。openGemini提供了單機和叢集兩種版本,通常對於叢集自身的指標資料儲存,單機效能已然足夠。與此同時,openGemini同樣支援Grafana,且單機效能更優於InfluxDB,建議直接使用openGemini單機版部署,用於儲存監控指標資料。
資料視覺化與告警:Grafana是業界非常普遍使用的一款開源資料視覺化工具,可以做資料監控和資料統計,帶有告警功能。選擇它用在監控系統中最合適不過。
綜上所述,該方案的優點是部署簡單、易獲取(所有元件開源)。接下來將重點介紹不同資料採集方式對應的部署和配置。
方式一:使用ts-monitor從業務日誌中採集監控指標資料

如圖所示,監控資料以log files方式輸出的方式需要在業務叢集的每個節點中部署一個ts-monitor,用來從該節點上所有openGemini元件產生的監控日誌中採集監控指標資料,然後將資料寫入到遠端監控節點上的openGemini中,最後使用Grafana作為監控/告警面板來讀取單機版openGemini中的監控資料。
該部署方式下,業務叢集的openGemini元件的配置檔案openGemini.conf必要配置項如下圖所示,各配置項說明如表一所示,當前配置會將openGemini元件的監控日誌每隔10秒寫一次到/home/openGemini/metric/metric.data中。
表一 log files方式業務叢集配置項說明

示例
[monitor]
pushers = "file"
store-enabled = true
store-database = "monitor"
store-interval = "10s"
store-path = "/tmp/openGemini/metric/ts-sql/metric.data"
compress = false
# http-endpoint = ""
# username = ""
# password = ""
該部署方式下,業務叢集中ts-monitor的配置檔案monitor.conf的配置項說明如表二所示。
表二 ts-monitor配置項說明
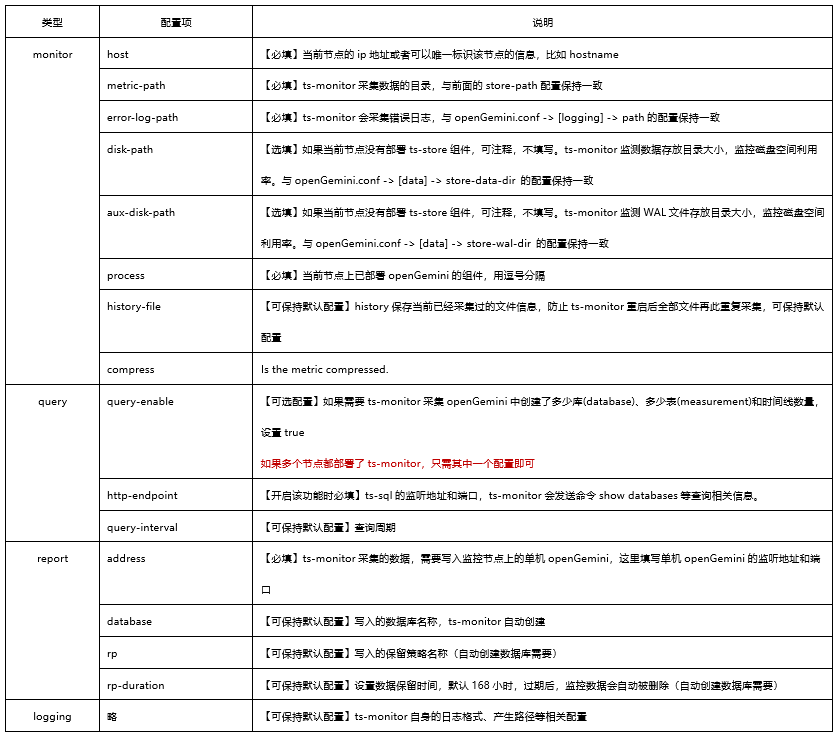
其中monitor的必填項需要與業務叢集中openGemini元件的配置保持一致,query開啟表示一些與資料模式、資料統計相關的查詢結果是否可以向ts-monitor上報,report中填寫的是監控節點的有關資訊需要與監控節點的openGemini.conf保持一致。
示例
[monitor]
host = "192.70.3.42"
metric-path = "/tmp/openGemini/metric"
error-log-path = "/tmp/openGemini/logs"
disk-path = "/tmp/openGemini/data"
aux-disk-path = "/tmp/openGemini/data/wal"
process = "ts-store,ts-meta"
history-file = "history.txt"
# Is the metric compressed.
compress = false
[query]
# query for some DDL. Report for these data to monitor cluster.
# - SHOW DATABASES
# - SHOW MEASUREMENTS
# - SHOW SERIES CARDINALITY FROM mst
query-enable = false
http-endpoint = "192.70.3.42:8086"
query-interval = "5m"
[report]
address = "192.70.3.43:8086"
database = "monitor"
rp = "autogen"
rp-duration = "168h"
[logging]
format = "auto"
level = "info"
path = "/tmp/openGemini/logs/"
max-size = "64m"
max-num = 30
max-age = 7
compress-enabled = true
方式二:監控指標資料直接push到監控節點
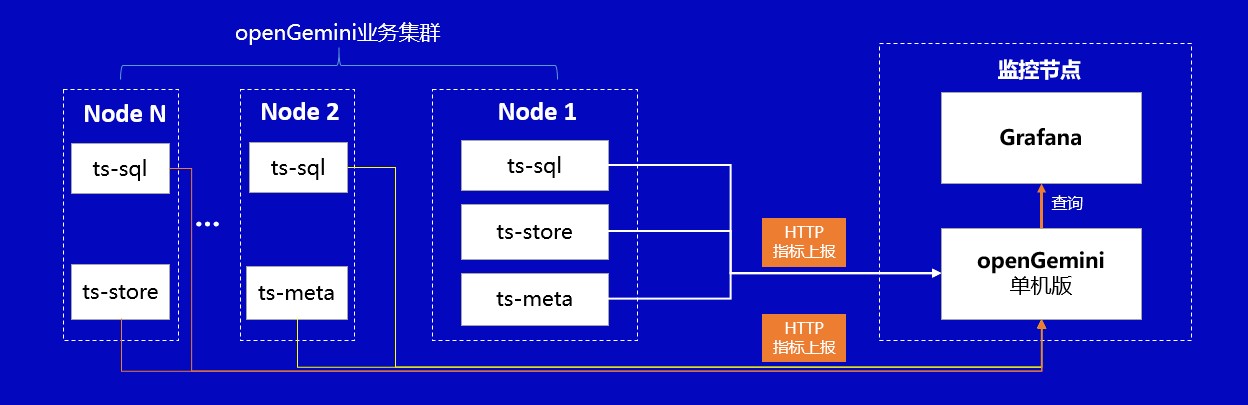
如圖所示,監控資料直接push到監控節點的方式不需要在業務叢集中部署ts-monitor,但這種情況下要求業務叢集能夠直連監控節點並且會缺乏一些監控指標,如磁碟利用率、建立的表總數、時間線數量、建立的資料庫總數等。
該方式下,業務叢集的openGemini元件的配置檔案openGemini.conf必要配置項如下表所示,當前配置會將監控資料每隔10秒寫一次到監控節點“192.70.3.43:8086”的“monitor”資料庫中。
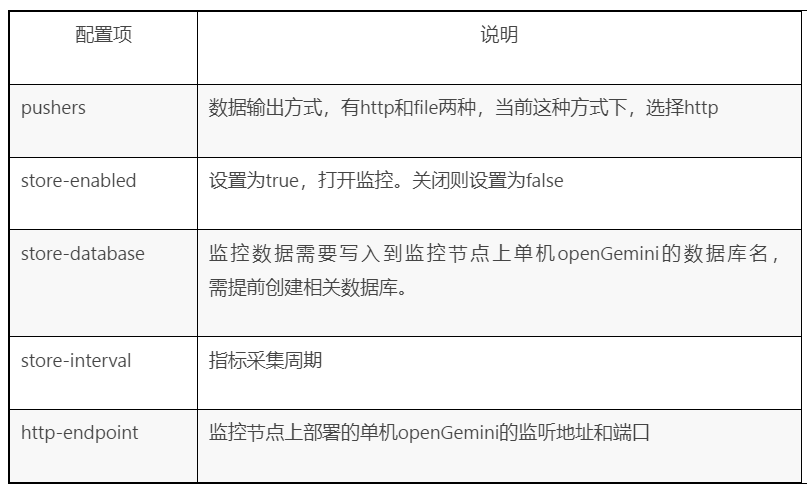
示例
[monitor]
pushers = "http"
store-enabled = true
store-database = "monitor"
store-interval = "10s"
# store-path = "/tmp/openGemini/metric/ts-sql/metric.data"
# compress = false
http-endpoint = "192.70.3.43:8086"
# username = ""
# password = ""
Grafana配置
Grafana安裝過程略,啟動Grafana後,通過瀏覽器訪問http://192.70.3.43:3000 ,新增資料來源選擇InfluxDB(openGemini相容InfluxDB)。
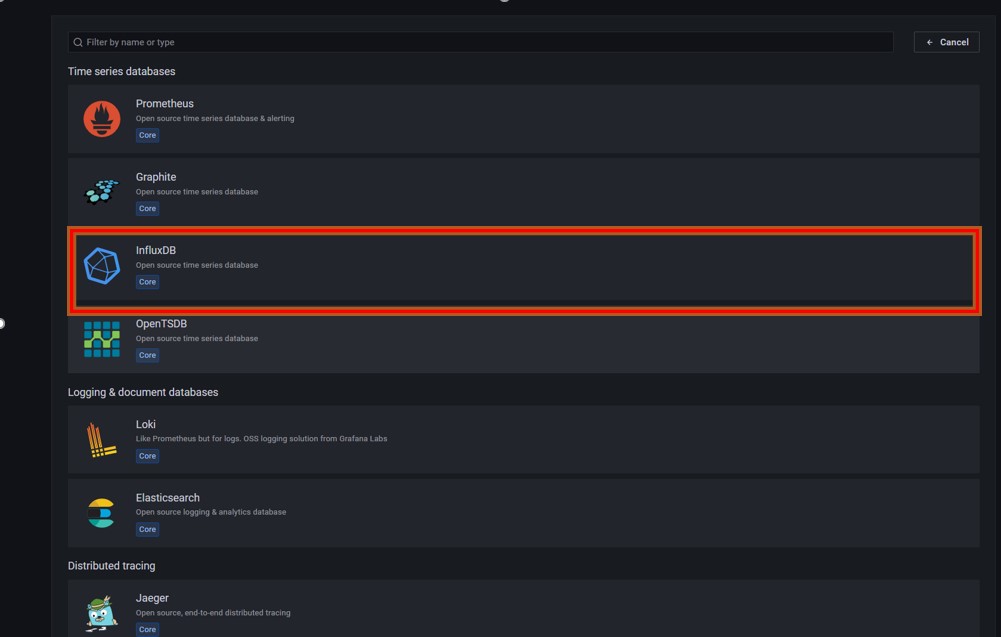
進入建立資料來源介面,其中name填寫為新建立的資料來源的名稱,URL為監控節點上openGemini的地址和埠,database為監控資料所在資料庫名稱。

圖四 資料來源建立
資料來源建立完成後可以在Grafana中新建看板來完成監控使用者感興趣的內容,如下圖所示,建立一個Panel,選擇Data source為剛剛建立的monitor,然後通過圖形化查詢選擇介面來建立看板的查詢語句。

看板建立示例
除了使用圖形化介面查詢,也可以點選“Query Inspector”來使用直接輸入查詢語句的方式建立Panel。如下圖所示,先選擇資料來源為剛才建立的“monitor”,然後可以通過查詢語句“SELECT mean("CpuUsage") FROM $database.."system" WHERE $timeFilter GROUP BY time($__interval), "host" fill(null)”來查詢資料庫中cpu的平均使用率。
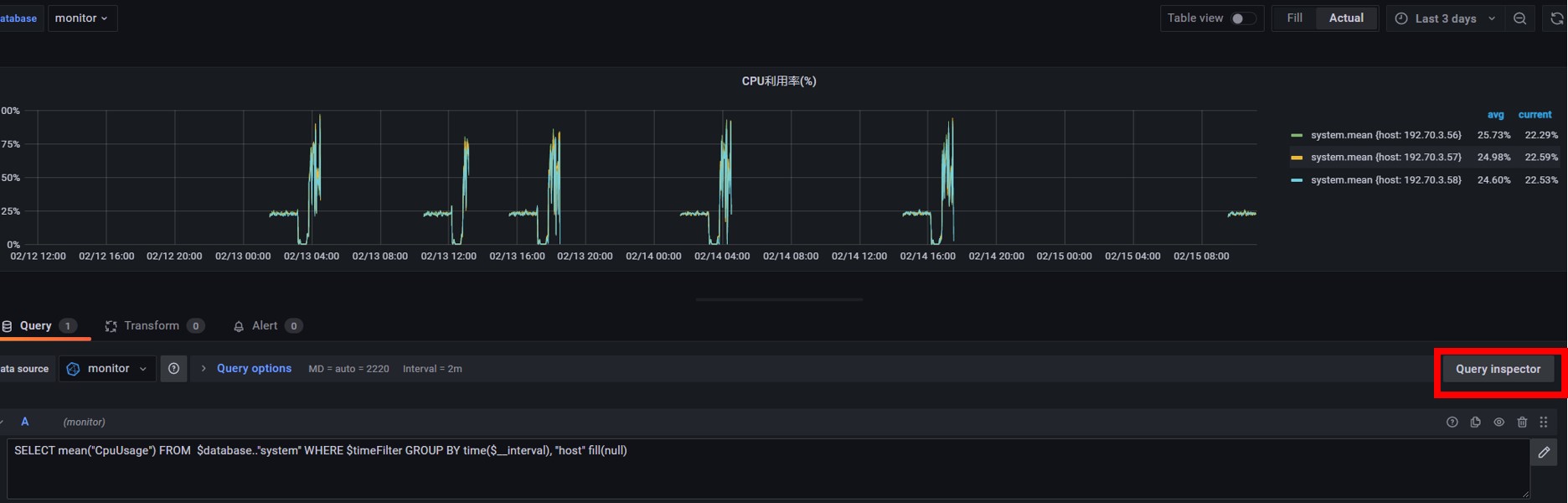
輸入查詢語句的方式建立Panel示例
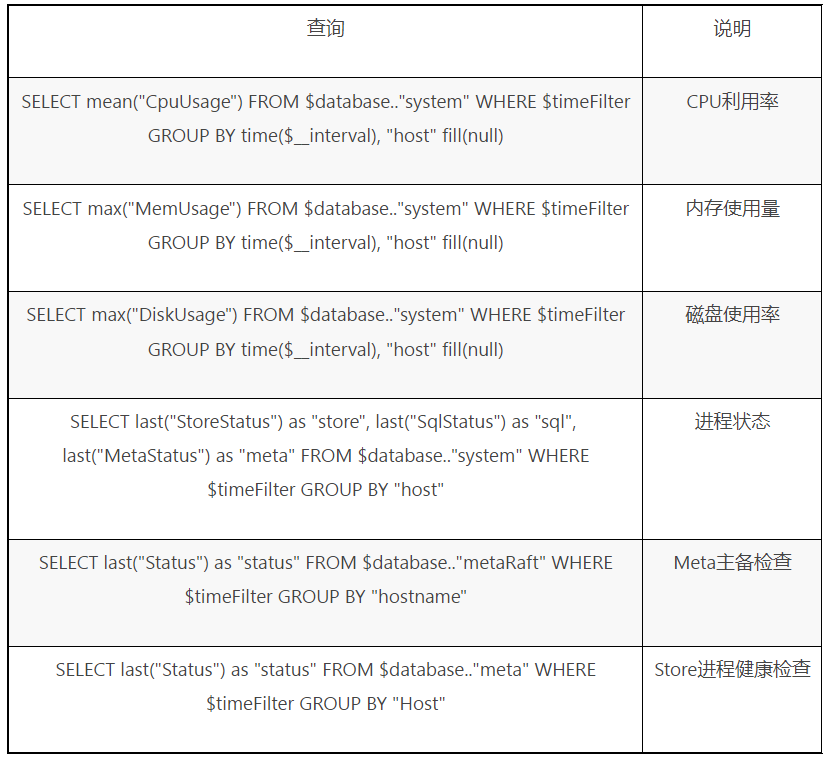
除了“CpuUsage”監控資料還包括其他的一些指標用來建立監控面板,例如跟叢集整體健康狀態相關的一些查詢如下表所示。
表三 叢集整體健康狀態相關查詢
總結
本文旨在幫助使用者快速上手搭建openGemini的實時監控系統,希望能對大家有所幫助。文中並未提及單機版本的監控,單機版的監控與叢集相同。
任何問題,可通過社群聯絡方式找到我們,或者提交issue到社群,我們第一時間會進行回覆。
openGemini是一個共享、共建、共治的開放社群,歡迎大家參與!
更多資訊,歡迎關注openGemini社群公眾號
- 如何快速搭建openGemini執行狀態的實時監控系統?
- Java Agent場景效能測試分析優化經驗分享
- 用100W 行程式碼貢獻經驗,帶你瞭解如何參與OpenHarmony開源
- 細數華為云云原生產品及五大開源實踐
- 探索開源工作流引擎Azkaban在MRS中的實踐
- KeyDB重量釋出6.3.0開源版,華為深度參與貢獻
- GaussDB(for Influx)與開源企業版效能對比
- 新特性巨量來襲,MindSpore 開源一週年實力“狂歡”
- 華為雲企業級Redis揭祕第16期:超越開源Redis的ACID"真"事務
- 華為雲企業級Redis揭祕第16期:超越開源Redis的ACID"真"事務
- 左手自研,右手開源,技術揭祕華為雲如何領跑容器市場
- 從原始碼分析快速實現對新開源軟體的檢測
- 雲原生新正規化出爐,華為雲開源專案助力數字化轉型
- 一文詳細分析公式樹開源庫
- 技術架構 應用場景揭祕,為什麼高斯Redis比開源香?
- 一文詳細分析公式樹開源庫
- 華為雲開源的Karmada正式成為CNCF首個多雲容器編排專案
- VEGA:諾亞AutoML高效能開源演算法集簡介
- 什麼?語音合成開原始碼不會跑,Follow me!
- 什麼?語音合成開原始碼不會跑,follow me!