深入理解 Taier:MR on Yarn 的實現原理
我們今天常説的大數據技術,它的理論基礎來自於2003年 Google 發表的三篇論文,《The Google File System》、《MapReduce: Simplified Data Processing on Large Clusters》、《Bigtable: A Distributed Storage System for Structured Data》。這三篇論文分別對應後來出現的 HDFS,MapReduce, HBase。
在大數據的發展歷史上,還有一個名字是無論如何都繞不開的,那就是 Doug Cutting。Doug是 Apache Lucene、Nutch、Hadoop、Avro 項目的創始人,2006 年 Docu Cutting 開源了 Hadoop,名字取自於他兒子的玩具小象 Hadoop。
那麼就從 Hadoop 起,我們開始本文的分享。
Taier & Yarn
Hadoop
新生事物的成長往往是螺旋上升的,Hadoop 也是如此。Hadoop 1.0 是指 MapReduce + HDFS,其中 MapReduce 是一個離線處理框架,由編程模型(新舊API)、運行時環境(JobTracker 和 TaskTracker)和數據處理引擎(MapTask和ReduceTask)三部分組成。早期的 MapReduce 非常臃腫,有着很明顯的缺點,JobTracker 有單點故障問題、框架設計只能執行 MapReduce 任務,不能跑 Storm,Flink 等計算框架的任務。

之後迎來的 Hadoop 2.0 是指 MapReduce + HDFS + Yarn,其中 YARN 是一個資源管理系統,負責集羣資源管理和調度, MapReduce 則是運行在 YARN 上的離線處理框架。Hadoop 2.0 很好地解決了單點問題,它將 JobTracker 中的資源管理和作業控制分開,分別由 ResourceManager 負責所有應用程序的資源分配,ApplicationMaster 負責管理一個應用程序。並且解決了擴展問題,包括針對 Hadoop 1.0 中的 MapReduce 在擴展性和多框架支持等方面的不足。

MapReduce 2.0
MapReduce 1.0的工作機制中,角色主要包括客户端,Jobtracker,Tasktracker。Jobtracker 主要是協調作業的運行,而 Tasktracker 是負責運行作業劃分之後的任務。網上關於 MR 1.0 的內容很多,這裏就不再過多贅述,流程圖如下:
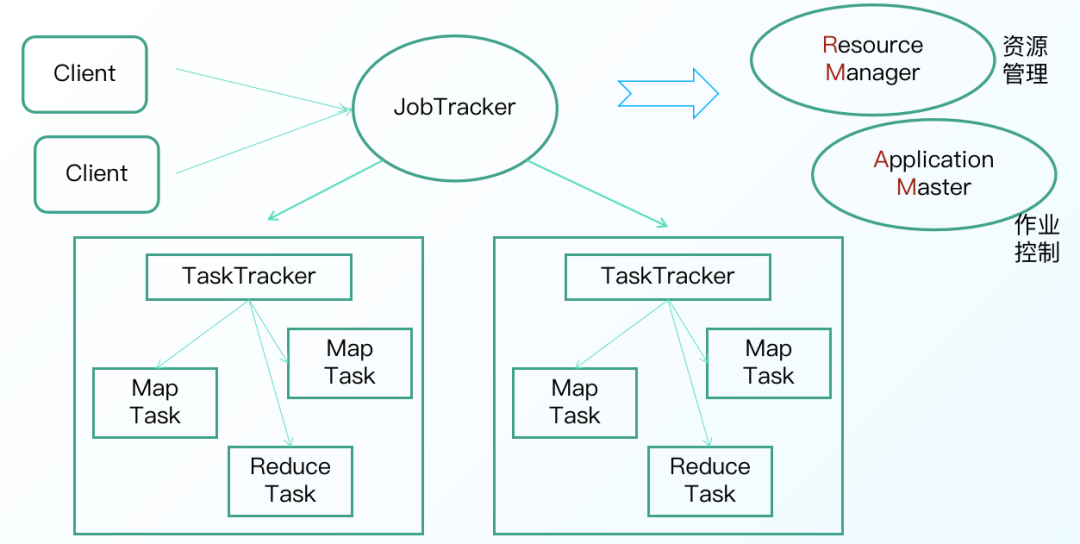
到了 MapReduce 2.0,核心思想則是將 MR 1.0 中 JobTracker 的資源管理和任務調度兩個功能分開,分別由 ResourceManager 和 ApplicationMaster 進程實現。
MR 2.0 的工作流程主要分為以下6個執行過程(請將圖片和文字對照起來看):
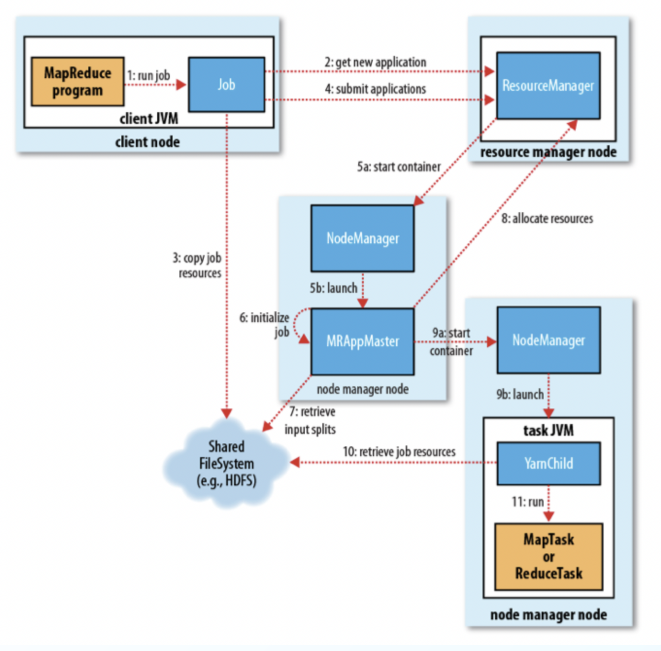
一、作業的提交
1)客户端向 ResourceManager 請求一個新的作業ID,ResourceManager 收到後,迴應一個 ApplicationID,見第2步
2)計算作業的輸入分片,將運行作業所需要的資源(包括jar文件、配置文件和計算得到的輸入分片)複製到一個(HDFS),見第3步
3)告知 ResourceManager 作業準備執行,並且調用 submitApplication() 提交作業,見第4步
二、作業的初始化
- ResourceManager收到對其 submitApplication() 方法的調用後,會把此調用放入一個內部隊列中,交由作業調度器進行調度,並對其初始化,然後為該其分配一個 contain 容器,見第5步
5)並與對應的 NodeManager 通信,見第5a步;要求它在 Contain 中啟動 ApplicationMaster ,見第5b步
-
ApplicationMaster 啟動後,會對作業進行初始化,並保持作業的追蹤,見第6步
-
ApplicationMaster 從 HDFS 中共享資源,接受客户端計算的輸入分片為每個分片,見第7步
三、任務的分配
- ApplicationMaster 向 ResourceManager 註冊,這樣就可以直接通過 RM 查看應用的運行狀態,然後為所有的 map 和 reduce 任務獲取資源,見第8步
四、任務的執行
- ApplicationMaster 申請到資源後,與 NodeManager 進行交互,要求它在 Contain 容器中啟動執行任務,見第9a、9b步
五、進度和狀態的更新
10)各個任務通過 RPC 協議 umbilical 接口向 ApplicationMaster 彙報自己的狀態和進度,方便 ApplicationMaster 隨時掌握各個任務的運行狀態,用户也可以向 ApplicationMaster 查詢運行狀態
六、作業的完成
11)應用完成後,ApplicationMaster 向 ResourceManager 註銷並關閉自己
手寫一個 Yarn 程序
如果想要將一個新的應用程序運行在 YARN 之上,通常需要編寫兩個組件:客户端和 ApplicationMaster。
· 客户端編寫需要注意:客户端通常只需與 ResourceManager 交互,期間涉及到多個數據結構和一個 RPC 協議。
· ApplicationMaster 編寫需要注意:ApplicationMaster 需要與 ResoureManager 和 NodeManager 交互,以申請資源和啟動 Container,期間涉及到多個數據結構和兩個 RPC 協議。
手寫一個 YARN Application 程序對理解 YARN 的運行原理非常有幫助,熟悉 Spark 、Flink 計算組件的同學也可以參考 Spark on Yarn、Flink on Yarn 的源代碼。
Taier&Yarn
洋洋灑灑,回過頭來,現在來給大家介紹一下 Taier 和 Yarn 之間的關係。
Taier 作為一站式大數據任務調度引擎,是數棧數據中台整體架構的重要樞紐,負責調度日常龐大的任務量。它旨在降低ETL開發成本,提高大數據平台穩定性,讓大數據開發人員可以在 Taier 直接進行業務邏輯的開發,而不用關心任務錯綜複雜的依賴關係與底層的大數據平台的架構實現,將工作的重心更多地聚焦在業務之中。
為了更好地實現讓數據開發人員關注業務的目標,Taier 主要在控制枱中展示了 Hadoop Yarn的相關信息。分為以下3點:Yarn 配置管理、Yarn 資源管理、任務 on Yarn 的相關配置。
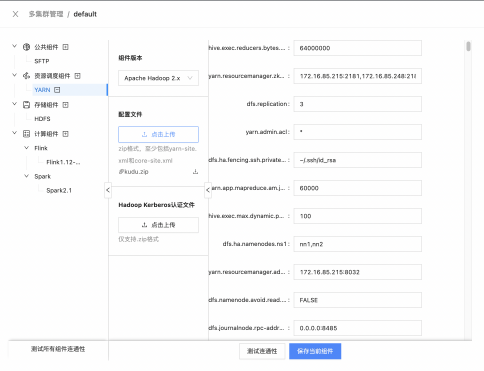
下面為大家展示一下 Taier 中 Yarn 相關的頁面:
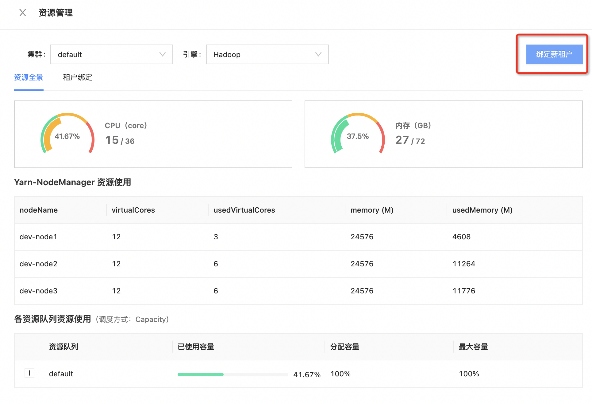
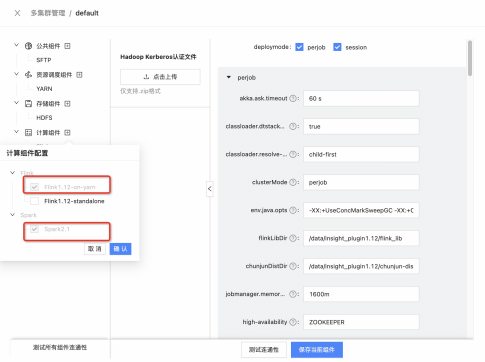
實現原理
前情提要全部講完,下面為大家重點介紹下 Taier 怎麼實現 MR on Yarn 的計算。
Taier 目前支持22種任務類型,支持在 Yarn 上運行的任務有 python、shell、數據同步、實時採集、Flink Jar、Flink SQL、Spark SQL 和 Hadoop MR 等等。
實現原理
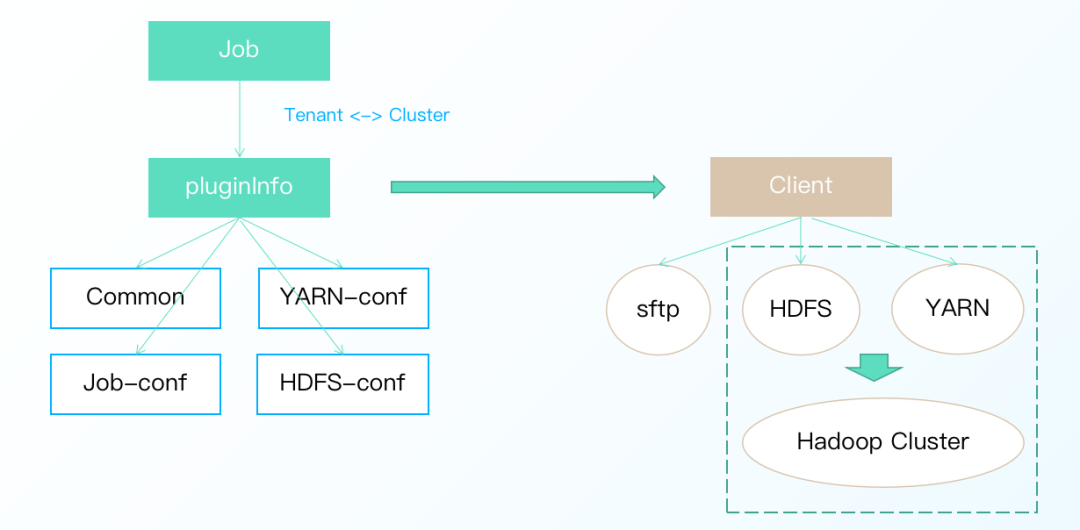
以 MR on Yarn 任務為例,其實現原理主要有2個關鍵步驟:
· 組裝任務運行時的相關信息生成 pluginInfo,信息包含任務相關配置、YARN 配置、HDFS 配置和公共配置。
· 根據 pluginInfo 實例化相應的任務提交客户端,客户端負責向 YARN 提交任務,實現了 Taier 與計算集羣的解耦、保證節點無侵入。
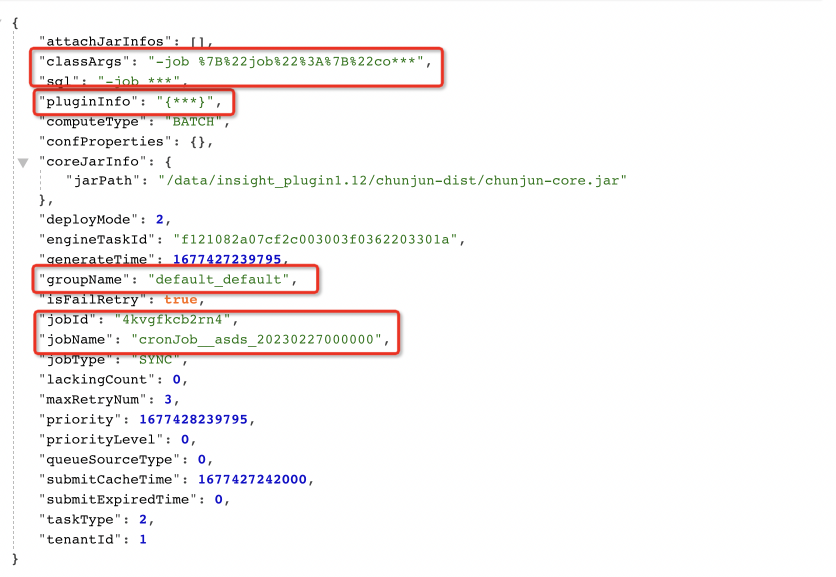
下圖是目前已經在 Taier 上運行的 Flink 任務的一些參數,包括 groupName、jobID 等:

執行原理
以 MR on Yarn 任務為例,其執行原理可以分為以下3個階段:
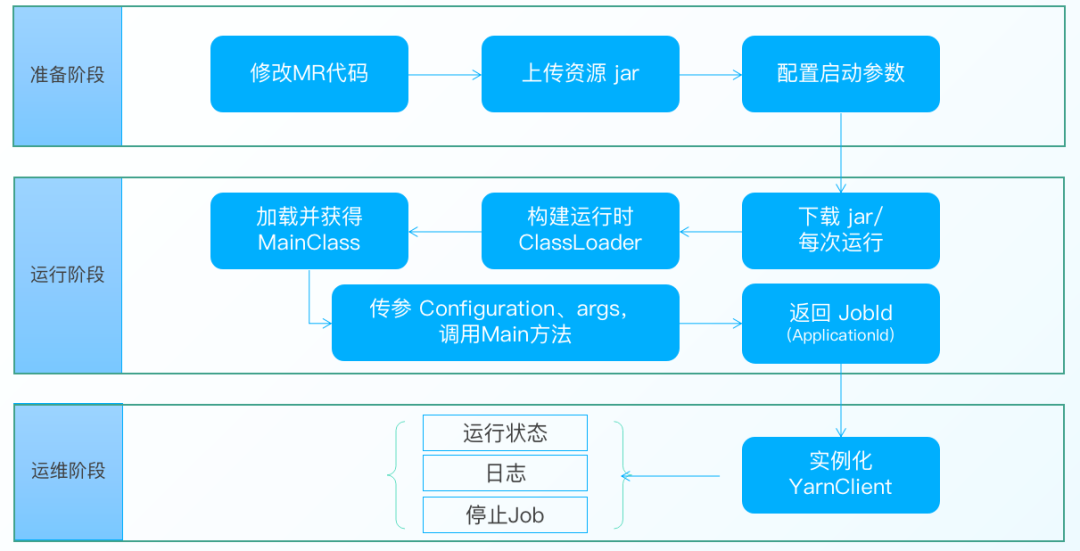
● 準備階段
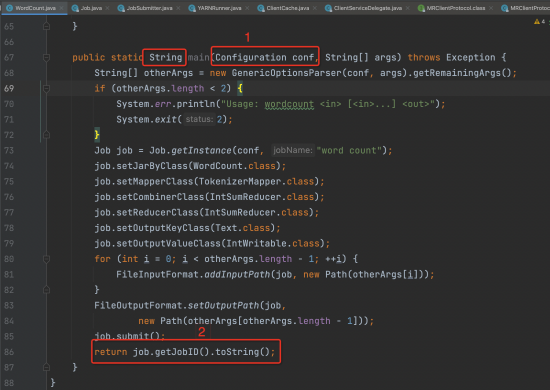
· 對普通的 Hadoop MR 任務進行改造,修改 MR 代碼的 Main 方法
· 編譯修改後的 Hadoop MR 任務,並通過 Taier 的資源上傳功能將 Jar 進行上傳,目標選擇 HDFS
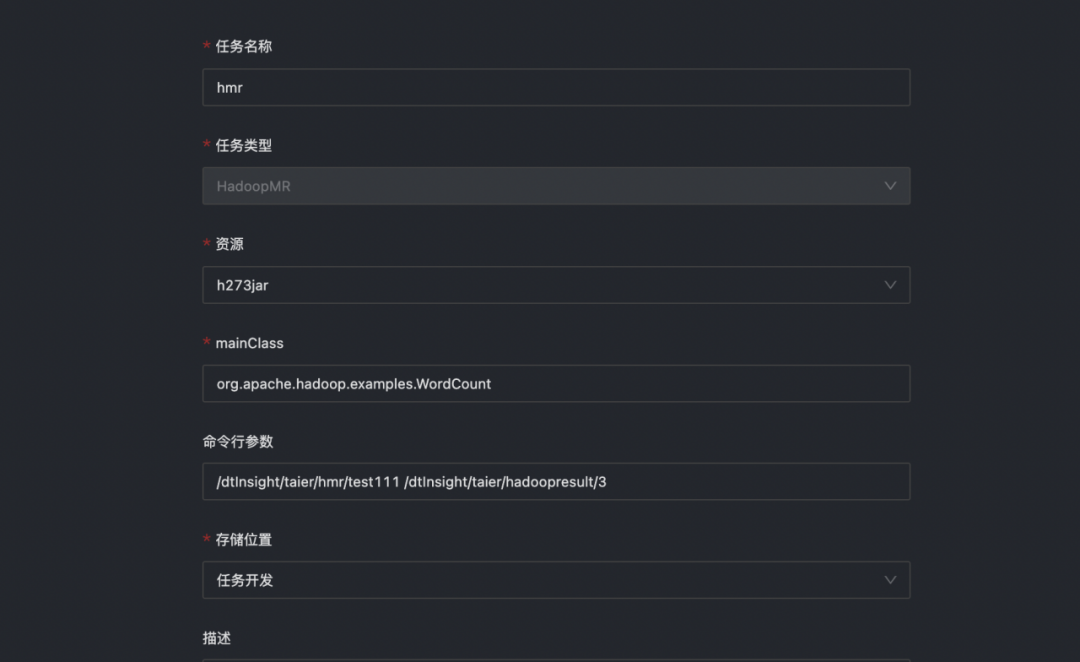
· 配置 Haddoop MR 任務的任務參數
● 運行階段
· Taier 的 worker-plugin 主要負責任務提交相關工作,其中 hadoop 插件會負責 MR 任務的相關處理
· 實例化 HadoopClient,並下載準備階段上傳的 MR 任務對應的 Jar(注意這裏是一個任務的生命週期,為了保障任務的無狀態,所以每次運行都會重新下載一次)
· 通過 MapReduceTemplate ,加載 Jar 並構建 MR 任務的類加載器
· 通過類加載器實獲取 Class 類對象,並調用類對象的 Main 方法,傳入 Configuration、args 等參數
· 返回 JobId
● 運維階段
· 處理 JobId 並轉化為 ApplicationId
· 實例化 YarnClient,獲取 MR on Yarn 的相關信息,包括運行狀態、日誌、停止 Application
Taier 中的 Hadoop 插件
Hadoop MR 的任務在 Taier 中的實現是基於 Hadoop 的插件,在裏面實現了相關的類,其中比較主要的包括:
· HadoopClient: 實現任務提交運行的相關接口(init、judgeSlots、processSubmitJobWithType、beforeSubmitFunc、afterSubmitFunc、getJobStatus、getJobLog、cancelJob)
· MapReduceTemplate:封裝 MR 任務及其重要參數、方法,實例化 PackagedProgram
· PackagedProgram:MR 任務提交前的處理實現
這一部分相關的代碼可以在 PR 中的上下文看到,也可以下載 Taier 插件看到關鍵類所做的事件,如何相互配合實現 MR 任務往 Yarn 上進行提交。
相關PR:
http://github.com/DTStack/Taier/pull/983
案例演示
案例演示的部分,大家直接觀看視頻,會得到最直觀清楚的講解,本文就不再進行贅述。
視頻鏈接:
http://www.bilibili.com/video/BV1ag4y1n7bT/?spm_id_from=333.999.0.0
《數據治理行業實踐白皮書》下載地址:http://fs80.cn/380a4b
想了解或諮詢更多有關袋鼠雲大數據產品、行業解決方案、客户案例的朋友,瀏覽袋鼠雲官網:http://www.dtstack.com/?src=szkyzg
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:http://github.com/DTStack
- 乾貨分享|袋鼠雲數棧離線開發平台在小文件治理上的探索實踐之路
- 大數據計算引擎 EasyMR:擁抱開源,引領技術創新
- 數據湖選型指南|Hudi vs Iceberg 數據更新能力深度對比
- 深入理解 Taier:MR on Yarn 的實現原理
- 從5分鐘到60秒,袋鼠雲數棧在熱重啟技術上的提效探索之路
- 詳細剖析|袋鼠雲數棧前端框架Antd 3.x 升級 4.x 的踩坑之路
- Teradata在華落幕,國產化崛起,袋鼠雲數棧會是更好的選擇嗎?
- 大數據應用場景下,標籤策略如何實現價值最大化?
- 袋鼠雲數棧UI5.0煥新升級,全新設計語言DT Design,更懂視覺更懂你!
- 一看就懂!任務提交的資源判斷在Taier中的實踐
- 我的 React 最佳實踐
- 看這篇就夠了丨基於Calcite框架的SQL語法擴展探索
- 無監控,不運維!深入淺出介紹ChengYing監控設計和使用
- DAG任務調度系統 Taier 演進之道,探究DataSourceX 模塊
- 數字孿生賦能智慧港口解決方案,助力港口數字化轉型
- Iceberg在袋鼠雲的探索及實踐
- Kerberos身份驗證在ChunJun中的落地實踐
- 從數據治理到數據應用,製造業企業如何突破數字化轉型困境丨行業方案
- 行業方案 | 新規落地,企業集團財務公司如何構建數智財務體系?
- 數據安全新戰場,EasyMR為企業築起“安全防線”