【詳細教程】一文參透MongoDB聚合查詢

MongoDB聚合查詢
什麼是聚合查詢
聚合操作主要用於處理數據並返回計算結果。聚合操作將來自多個文檔的值組合在一起,按條件分組後,再進行一系列操作(如求和、平均值、最大值、最小值)以返回單個結果。
MongoDB的聚合查詢
聚合是MongoDB的高級查詢語言,它允許我們通過轉化合並由多個文檔的數據來生成新的在單個文檔裏不存在的文檔信息。MongoDB中聚合(aggregate)主要用於處理數據(例如分組統計平均值、求和、最大值等),並返回計算後的數據結果,有點類似sql語句中的 count(*)、group by。
在MongoDB中,有兩種方式計算聚合:Pipeline 和 MapReduce。Pipeline查詢速度快於MapReduce,但是MapReduce的強大之處在於能夠在多台Server上並行執行復雜的聚合邏輯。MongoDB不允許Pipeline的單個聚合操作佔用過多的系統內存。
聚合管道方法
MongoDB 的聚合框架就是將文檔輸入處理管道,在管道內完成對文檔的操作,最終將文檔轉換為聚合結果,MongoDB的聚合管道將MongoDB文檔在一個管道處理完畢後將結果傳遞給下一個管道處理,管道操作是可以重複的。
最基本的管道階段提供過濾器,其操作類似查詢和文檔轉換,可以修改輸出文檔的形式。其他管道操作提供了按特定字段對文檔進行分組和排序的工具,以及用於聚合數組內容(包括文檔數組)的工具。
此外,在管道階段還可以使用運算符來執行諸如計算平均值或連接字符串之類的任務。聚合管道可以在分片集合上運行。
聚合流程
db.collection.aggregate()是基於數據處理的聚合管道,每個文檔通過一個由多個階段(stage)組成的管道,可以對每個階段的管道進行分組、過濾等功能,然後經過一系列的處理,輸出相應的結果。
聚合管道方法的流程參見下圖

上圖的聚合操作相當於 MySQL 中的以下語句:
select cust_id as _id, sum(amount) as total from orders where status like "%A%" group by cust_id;
詳細流程
db.collection.aggregate()可以用多個構件創建一個管道,對於一連串的文檔進行處理。這些構件包括:篩選操作的match、映射操作的project、分組操作的group、排序操作的sort、限制操作的limit、和跳過操作的skip。db.collection.aggregate()使用了MongoDB內置的原生操作,聚合效率非常高,支持類似於SQL Group By操作的功能,而不再需要用户編寫自定義的JavaScript例程。- 每個階段管道限制為100MB的內存。如果一個節點管道超過這個極限,MongoDB將產生一個錯誤。為了能夠在處理大型數據集,可以設置
allowDiskUse為true來在聚合管道節點把數據寫入臨時文件。這樣就可以解決100MB的內存的限制。 db.collection.aggregate()可以作用在分片集合,但結果不能輸在分片集合,MapReduce可以 作用在分片集合,結果也可以輸在分片集合。db.collection.aggregate()方法可以返回一個指針(cursor),數據放在內存中,直接操作。跟Mongo shell 一樣指針操作。db.collection.aggregate()輸出的結果只能保存在一個文檔中,BSON Document大小限制為16M。可以通過返回指針解決,版本2.6中:DB.collect.aggregate()方法返回一個指針,可以返回任何結果集的大小。
聚合語法
db.collection.aggregate(pipeline, options)
參數説明
| 參數 | 類型 | 描述 |
|---|---|---|
| pipeline | array | 一系列數據聚合操作或階段。詳見聚合管道操作符 在版本2.6中更改:該方法仍然可以將流水線階段作為單獨的參數接受,而不是作為數組中的元素;但是,如果不將管道指定為數組,則不能指定options參數 |
| options | document | 可選。 aggregate()傳遞給聚合命令的其他選項。 2.6版中的新增功能:僅當將管道指定為數組時才可用。 |
注意事項
使用db.collection.aggregate()直接查詢會提示錯誤,但是傳一個空數組如db.collection.aggregate([])則不會報錯,且會和find一樣返回所有文檔。
常用聚合管道
與mysql聚合類比
為了便於理解,先將常見的mongo的聚合操作和mysql的查詢做下類比
| SQL 操作/函數 | mongodb聚合操作 |
|---|---|
| where | $match |
| group by | $group |
| having | $match |
| select | $project |
| order by | $sort |
| limit | $limit |
| sum() | $sum |
| count() | $sum |
| join | $lookup |
$count
返回包含輸入到stage的文檔的計數,理解為返回與表或視圖的find()查詢匹配的文檔的計數。db.collection.count()方法不執行find()操作,而是計數並返回與查詢匹配的結果數。
語法
{ $count: <string> }
$count階段相當於下面$group+$project的序列:
db.collection.aggregate([
{
"$group": {
"_id": null,
"count": {// 這裏count自定義,相當於mysql的select count(*) as tables
"$sum": 1
}
}
},
{
"$project": {// 返回不顯示_id字段
"_id": 0
}
}
])
示例
查詢人數是
100000以上的城市的數量
- $match:階段排除pop小於等於100000的文檔,將大於100000的文檔傳到下個階段
- $count:階段返回聚合管道中剩餘文檔的計數,並將該值分配給名為
count的字段。
db.zips.aggregate([
{
"$match": {
"pop": {
"$gt": 100000
}
}
},
{
"$count": "count"
}
])

$group
按指定的表達式對文檔進行分組,並將每個不同分組的文檔輸出到下一個階段。輸出文檔包含一個_id字段,該字段按鍵包含不同的組。
輸出文檔還可以包含計算字段,該字段保存由$group的_id字段分組的一些accumulator表達式的值。 $group不會輸出具體的文檔而只是統計信息。
語法
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }
_id字段是必填的;但是,可以指定_id值為null來為整個輸入文檔計算累計值。- 剩餘的計算字段是可選的,並使用
<accumulator>運算符進行計算。 _id和<accumulator>表達式可以接受任何有效的表達式。
accumulator操作符
| 名稱 | 描述 | 類比sql |
|---|---|---|
| $avg | 計算均值 | avg |
| $first | 返回每組第一個文檔,如果有排序,按照排序,如果沒有按照默認的存儲的順序返回第一個文檔。 | limit 0,1 |
| $last | 返回每組最後一個文檔,如果有排序,按照排序,如果沒有按照默認的存儲的順序返回最後一個文檔。 | - |
| $max | 根據分組,獲取集合中所有文檔對應值的最大值。 | max |
| $min | 根據分組,獲取集合中所有文檔對應值的最小值。 | min |
| $push | 將指定的表達式的值添加到一個數組中。 | - |
| $addToSet | 將表達式的值添加到一個集合中(無重複值,無序)。 | - |
| $sum | 計算總和 | sum |
| $stdDevPop | 返回輸入值的總體標準偏差(population standard deviation) | - |
| $stdDevSamp | 返回輸入值的樣本標準偏差(the sample standard deviation) | - |
$group階段的內存限制為100M,默認情況下,如果stage超過此限制,$group將產生錯誤,但是,要允許處理大型數據集,請將allowDiskUse選項設置為true以啟用$group操作以寫入臨時文件。
注意:
- "$addToSet":expr,如果當前數組中不包含expr,那就將它添加到數組中。
- "$push":expr,不管expr是什麼值,都將它添加到數組中,返回包含所有值的數組。
示例
按照
state分組,並計算每一個state分組的總人數,平均人數以及每個分組的數量
db.zips.aggregate([
{
"$group": {
"_id": "$state",
"totalPop": {
"$sum": "$pop"
},
"avglPop": {
"$avg": "$pop"
},
"count": {
"$sum": 1
}
}
}
])

查找不重複的所有的
state的值
db.zips.aggregate([
{
"$group": {
"_id": "$state"
}
}
])

按照
city分組,並且分組內的state字段列表加入到stateItem並顯示
db.zips.aggregate([
{
"$group": {
"_id": "$city",
"stateItem": {
"$push": "$state"
}
}
}
])

下面聚合操作使用系統變量$$ROOT按item對文檔進行分組,生成的文檔不得超過BSON文檔大小限制
db.zips.aggregate([
{
"$group": {
"_id": "$city",
"item": {
"$push": "$$ROOT"
}
}
}
]).pretty();

$match
過濾文檔,僅將符合指定條件的文檔傳遞到下一個管道階段。
$match接受一個指定查詢條件的文檔,查詢語法與讀操作查詢語法相同。
語法
{ $match: { <query> } }
管道優化
$match用於對文檔進行篩選,之後可以在得到的文檔子集上做聚合,$match可以使用除了地理空間之外的所有常規查詢操作符,在實際應用中儘可能將$match放在管道的前面位置。這樣有兩個好處:
- 一是可以快速將不需要的文檔過濾掉,以減少管道的工作量;
- 二是如果再投射和分組之前執行$match,查詢可以使用索引。
使用限制
- 不能在
$match查詢中使用$作為聚合管道的一部分。 - 要在
$match階段使用$text,$match階段必須是管道的第一階段。 - 視圖不支持文本搜索。
示例
使用 $match做簡單的匹配查詢,查詢縮寫是
NY的城市數據
db.zips.aggregate([
{
"$match": {
"state": "NY"
}
}
]).pretty();

使用$match管道選擇要處理的文檔,然後將結果輸出到$group管道以計算文檔的計數
db.zips.aggregate([
{
"$match": {
"state": "NY"
}
},
{
"$group": {
"_id": null,
"sum": {
"$sum": "$pop"
},
"avg": {
"$avg": "$pop"
},
"count": {
"$sum": 1
}
}
}
]).pretty();

$unwind
從輸入文檔解構數組字段以輸出每個元素的文檔,簡單説就是 可以將數組拆分為單獨的文檔。
語法
要指定字段路徑,在字段名稱前加上$符並用引號括起來。
{ $unwind: <field path> }
v3.2+支持如下語法
{
$unwind:
{
path: <field path>,
#可選,一個新字段的名稱用於存放元素的數組索引。該名稱不能以$開頭。
includeArrayIndex: <string>,
#可選,default :false,若為true,如果路徑為空,缺少或為空數組,則$unwind輸出文檔
preserveNullAndEmptyArrays: <boolean>
}
}
如果為輸入文檔中不存在的字段指定路徑,或者該字段為空數組,則$unwind默認會忽略輸入文檔,並且不會輸出該輸入文檔的文檔。
版本3.2中的新功能:要輸出數組字段丟失的文檔,null或空數組,請使用選項preserveNullAndEmptyArrays。
示例
以下聚合使用$unwind為loc數組中的每個元素輸出一個文檔:
db.zips.aggregate([
{
"$match": {
"_id": "01002"
}
},
{
"$unwind": "$loc"
}
]).pretty();

$project
$project可以從文檔中選擇想要的字段,和不想要的字段(指定的字段可以是來自輸入文檔或新計算字段的現有字段),也可以通過管道表達式進行一些複雜的操作,例如數學操作,日期操作,字符串操作,邏輯操作。
語法
$project 管道符的作用是選擇字段(指定字段,添加字段,不顯示字段,_id:0,排除字段等),重命名字段,派生字段。
{ $project: { <specification(s)> } }
specifications有以下形式:
<field>: <1 or true> 是否包含該字段,field:1/0,表示選擇/不選擇 field
_id: <0 or false> 是否指定_id字段
<field>: <expression> 添加新字段或重置現有字段的值。 在版本3.6中更改:MongoDB 3.6添加變量REMOVE。如果表達式的計算結果為$$REMOVE,則該字段將排除在輸出中。
<field>:<0 or false> v3.4新增功能,指定排除字段
- 默認情況下,_id字段包含在輸出文檔中。要在輸出文檔中包含輸入文檔中的任何其他字段,必須明確指定$project中的包含。 如果指定包含文檔中不存在的字段,$project將忽略該字段包含,並且不會將該字段添加到文檔中。
- 默認情況下,_id字段包含在輸出文檔中。要從輸出文檔中排除_id字段,必須明確指定$project中的_id字段為0。
- v3.4版新增功能-如果指定排除一個或多個字段,則所有其他字段將在輸出文檔中返回。 如果指定排除_id以外的字段,則不能使用任何其他$project規範表單:即,如果排除字段,則不能指定包含字段,重置現有字段的值或添加新字段。此限制不適用於使用REMOVE變量條件排除字段。
- v3.6版本中的新功能- 從MongoDB 3.6開始,可以在聚合表達式中使用變量REMOVE來有條件地禁止一個字段。
- 要添加新字段或重置現有字段的值,請指定字段名稱並將其值設置為某個表達式。
- 要將字段值直接設置為數字或布爾文本,而不是將字段設置為解析為文字的表達式,請使用$literal操作符。否則,$project會將數字或布爾文字視為包含或排除該字段的標誌。
- 通過指定新字段並將其值設置為現有字段的字段路徑,可以有效地重命名字段。
- 從MongoDB 3.2開始,$project階段支持使用方括號[]直接創建新的數組字段。如果數組規範包含文檔中不存在的字段,則該操作會將空值替換為該字段的值。
- 在版本3.4中更改-如果$project 是一個空文檔,MongoDB 3.4和更高版本會產生一個錯誤。
- 投影或添加/重置嵌入文檔中的字段時,可以使用點符號
示例
以下$project階段的輸出文檔中只包含_id,city和state字段
db.zips.aggregate([
{
"$project": {
"_id": 1,
"city": 1,
"state": 1
}
}
]).pretty();

_id字段默認包含在內。要從$ project階段的輸出文檔中排除_id字段,請在project文檔中將_id字段設置為0來指定排除_id字段。
db.zips.aggregate([
{
"$project": {
"_id": 0,
"city": 1,
"state": 1
}
}
]).pretty();
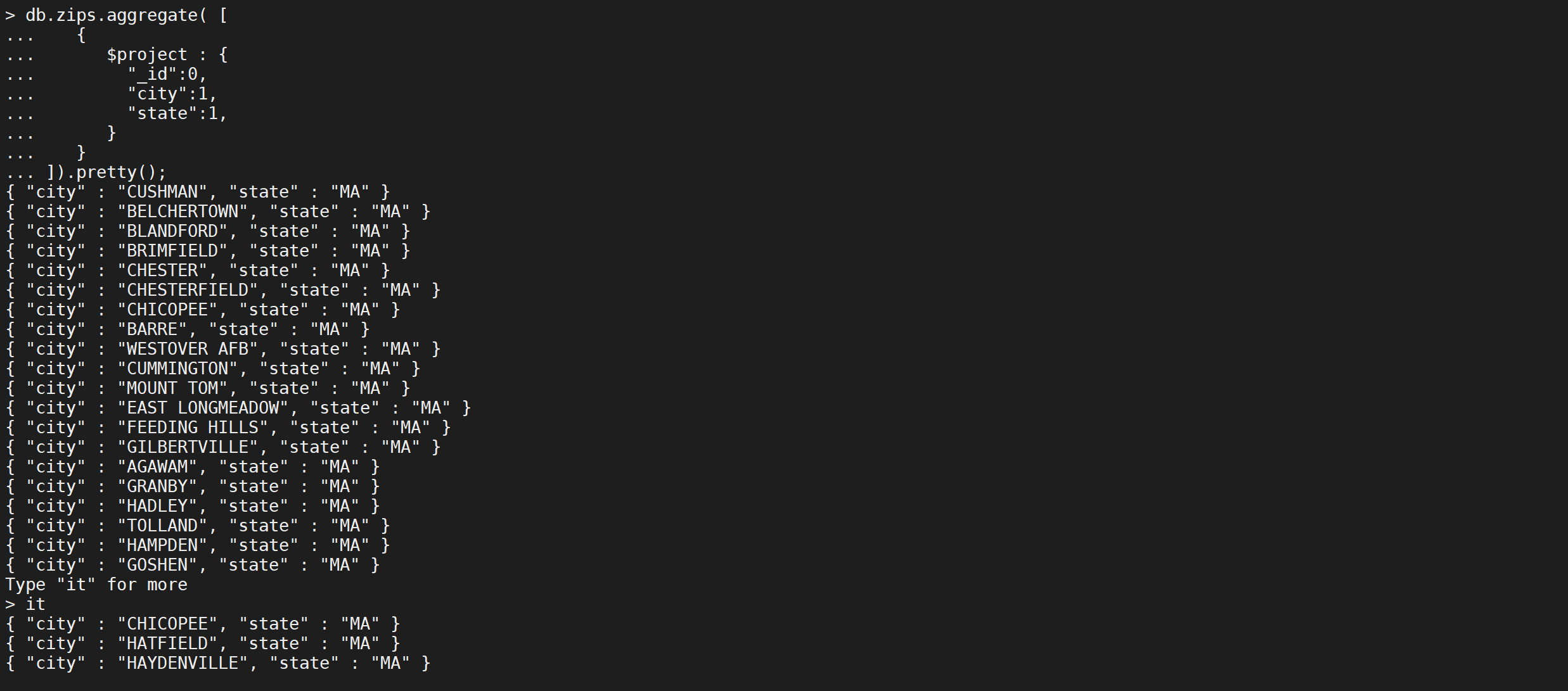
以下$ project階段從輸出中排除loc字段
db.zips.aggregate([
{
"$project": {
"loc": 0
}
}
]).pretty();

可以在聚合表達式中使用變量REMOVE來有條件地禁止一個字段,
db.zips.aggregate([
{
"$project": {
"_id": 1,
"city": 1,
"state": 1,
"pop": 1,
"loc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": "$$REMOVE",
"else": "$loc"
}
}
}
}
]).pretty();

我們還可以改變數據,將人數大於1000的城市座標重置為0
db.zips.aggregate([
{
"$project": {
"_id": 1,
"city": 1,
"state": 1,
"pop": 1,
"loc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": [
0,
0
],
"else": "$loc"
}
}
}
}
]).pretty();

新增字段列
db.zips.aggregate([
{
"$project": {
"_id": 1,
"city": 1,
"state": 1,
"pop": 1,
"desc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": "人數過多",
"else": "人數過少"
}
},
"loc": {
"$cond": {
"if": {
"$gt": [
"$pop",
1000
]
},
"then": [
0,
0
],
"else": "$loc"
}
}
}
}
]).pretty();

$limit
限制傳遞到管道中下一階段的文檔數
語法
{ $limit: <positive integer> }
示例,此操作僅返回管道傳遞給它的前5個文檔。 $limit對其傳遞的文檔內容沒有影響。
db.zips.aggregate({
"$limit": 5
});
注意
當$sort在管道中的$limit之前立即出現時,$sort操作只會在過程中維持前n個結果,其中n是指定的限制,而MongoDB只需要將n個項存儲在內存中。當allowDiskUse為true並且n個項目超過聚合內存限制時,此優化仍然適用。
$skip
跳過進入stage的指定數量的文檔,並將其餘文檔傳遞到管道中的下一個階段
語法
{ $skip: <positive integer> }
示例,此操作將跳過管道傳遞給它的前5個文檔, $skip對沿着管道傳遞的文檔的內容沒有影響。
db.zips.aggregate({
"$skip": 5
});
$sort
對所有輸入文檔進行排序,並按排序順序將它們返回到管道。
語法
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
$sort指定要排序的字段和相應的排序順序的文檔。
<sort order>可以具有以下值之一:
- 1指定升序。
- -1指定降序。
- {$meta:“textScore”}按照降序排列計算出的textScore元數據。
示例
要對字段進行排序,請將排序順序設置為1或-1,以分別指定升序或降序排序,如下例所示:
db.zips.aggregate([
{
"$sort": {
"pop": -1,
"city": 1
}
}
])

$sortByCount
根據指定表達式的值對傳入文檔分組,然後計算每個不同組中文檔的數量。每個輸出文檔都包含兩個字段:包含不同分組值的_id字段和包含屬於該分組或類別的文檔數的計數字段,文件按降序排列。
語法
{ $sortByCount: <expression> }
使用示例
下面舉了一些常用的mongo聚合例子和mysql對比,假設有一條如下的數據庫記錄(表名:zips)作為例子:
統計所有數據
SQL的語法格式如下
select count(1) from zips;
mongoDB的語法格式
db.zips.aggregate([
{
"$group": {
"_id": null,
"count": {
"$sum": 1
}
}
}
])

對所有城市人數求合
SQL的語法格式如下
select sum(pop) AS tota from zips;
mongoDB的語法格式
db.zips.aggregate([
{
"$group": {
"_id": null,
"total": {
"$sum": "$pop"
}
}
}
])

對城市縮寫相同的城市人數求合
SQL的語法格式如下
select state,sum(pop) AS tota from zips group by state;
mongoDB的語法格式
db.zips.aggregate([
{
"$group": {
"_id": "$state",
"total": {
"$sum": "$pop"
}
}
}
])

state重複的城市個數
SQL的語法格式如下
select state,count(1) AS total from zips group by state;
mongoDB的語法格式
db.zips.aggregate([
{
"$group": {
"_id": "$state",
"total": {
"$sum": 1
}
}
}
])

state重複個數大於100的城市
SQL的語法格式如下
select state,count(1) AS total from zips group by state having count(1)>100;
mongoDB的語法格式
db.zips.aggregate([
{
"$group": {
"_id": "$state",
"total": {
"$sum": 1
}
}
},
{
"$match": {
"total": {
"$gt": 100
}
}
}
])

本文由育博學谷狂野架構師發佈 如果本文對您有幫助,歡迎關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力 轉載請註明出處!
- ElasticSearch還能性能調優,漲見識、漲見識了!!!
- 【必須收藏】別再亂找TiDB 集羣部署教程了,這篇保姆級教程來幫你!!| 博學谷狂野架構師
- 【建議收藏】7000 字的TIDB保姆級簡介,你見過嗎
- Tomcat架構設計剖析 | 博學谷狂野架構師
- 你可能不那麼知道的Tomcat生命週期管理 | 博學谷狂野架構師
- 大哥,這是併發不是並行,Are You Ok?
- 為啥要重學Tomcat?| 博學谷狂野架構師
- 這是一篇純講SQL語句優化的文章!!!| 博學谷狂野架構師
- 捲起來!!!看了這篇文章我才知道MySQL事務&MVCC到底是啥?
- 為什麼99%的程序員都做不好SQL優化?
- 如何搞定MySQL鎖(全局鎖、表級鎖、行級鎖)?這篇文章告訴你答案!太TMD詳細了!!!
- 【建議收藏】超詳細的Canal入門,看這篇就夠了!!!
- 從菜鳥程序員到高級架構師,竟然是因為這個字final
- 為什麼95%的Java程序員,都是用不好Synchronized?
- 99%的Java程序員者,都敗給這一個字!
- 8000 字,就説一個字Volatile
- 98%的程序員,都沒有研究過JVM重排序和順序一致性
- 來一波騷操作,Java內存模型
- 時隔多年,這次我終於把動態代理的源碼翻了個地兒朝天
- 再有人問你分佈式事務,把這篇文章砸過去給他