一看就懂!任務提交的資源判斷在Taier中的實踐
Taier 介紹
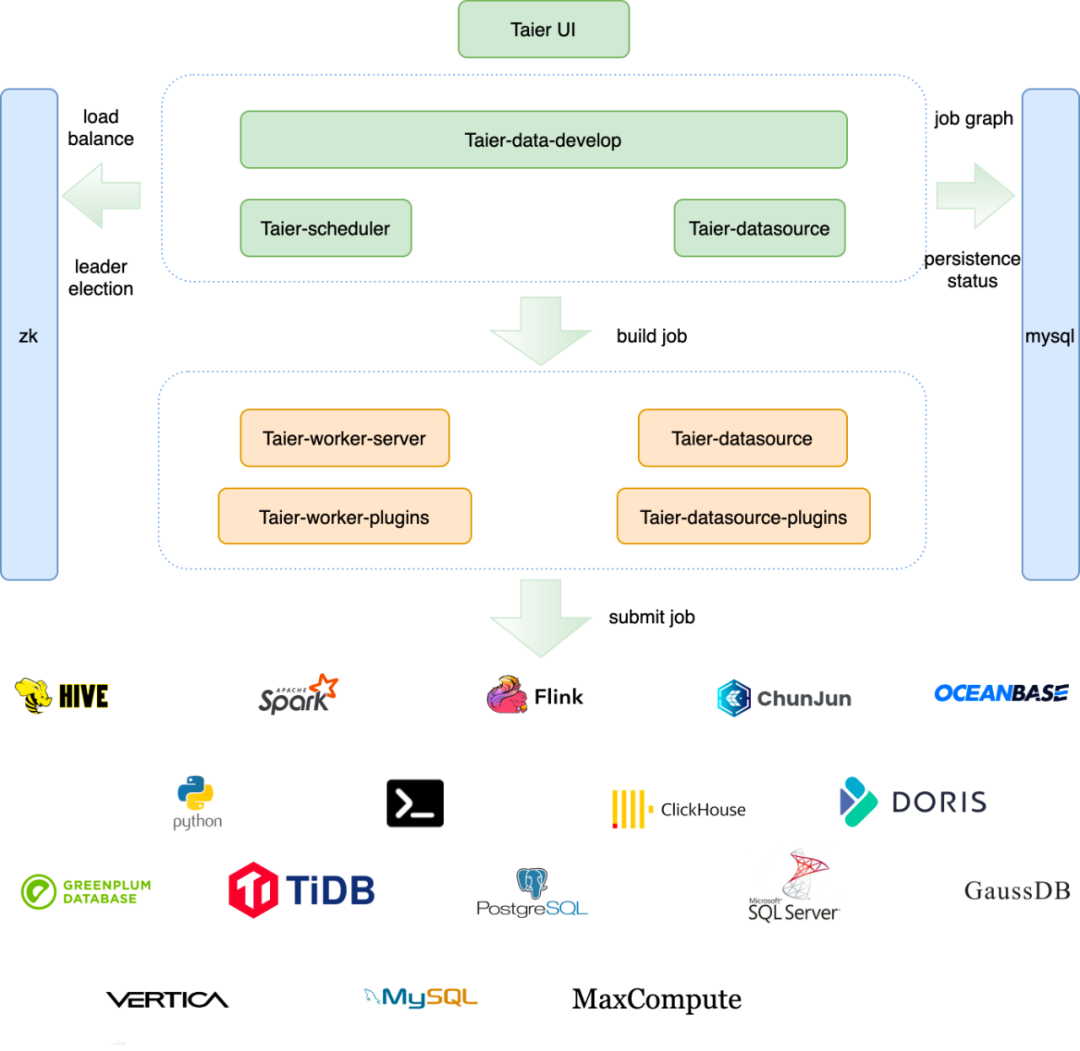
Taier 是袋鼠雲開源項目之一,是一個分佈式可視化的DAG任務調度系統。
旨在降低ETL開發成本、提高大數據平台穩定性,大數據開發人員可以在 Taier 直接進行業務邏輯的開發,而不用關心任務錯綜複雜的依賴關係與底層的大數據平台的架構實現,將工作的重心更多地聚焦在業務之中。
項目地址:http://github.com/DTStack/Taier
Taier 資源判斷
Taier 基於插件式架構設計,用户在界面開發任務並提交運行。提交運行插件又劃分為worker-plugins、datasource-plugins雙插件類型。
在任務提交的時候,Taier需要判斷是否有足夠的資源來執行,否則一股腦地提交任務,最終會拖垮環境,導致服務的不可用。根據環境資源的剩餘情況來動態調整提交任務的速率是Taier必不可少的一項功能,那麼Taier究竟是怎麼來判斷資源的呢?
什麼是資源?
對一個系統而言,首先要定義出資源的種類,然後將每種資源量化,才能進行管理,這就是資源抽象的過程。那麼,想回答上文中「Taier是如何判斷資源」的這個問題,就需要先理清楚,在一個分佈式、多環境的系統中,什麼是資源,又為什麼要有“資源”這個概念?
我們通常所説的“資源”都是硬件資源,包括CPU使用/內存使用/磁盤用量/IO/網絡流量等等,這是比較粗粒度的。也可以是抽象層次更高的TPS/請求數之類的。
資源可以用來衡量系統的瓶頸。系統能否充分利用資源,什麼時候可以持續提交任務,什麼時候需要暫停提交任務,比如當總體資源充裕時,可以把對應的任務全部提交上去。
● 以Yarn框架介紹為例
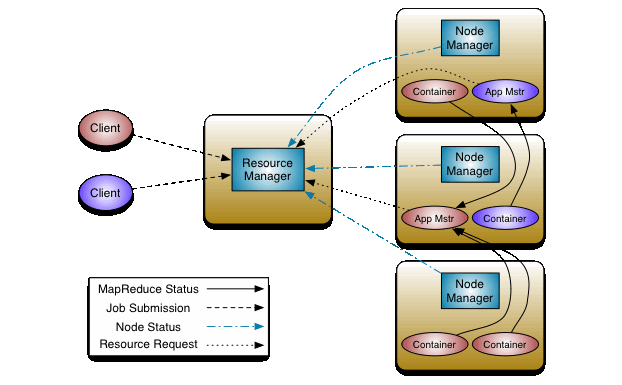
ResourceManager 是一個全局的資源管理器,負責整個系統的資源管理和分配,包括 scheduler 、Application Manager和 Node Manager。
對調度器來説,YARN 提供了多種直接可用的調度器, Fair Scheduler 和 Capacity Scheduler 等。調度器僅根據各個應用程序的資源需求進行資源分配,分配的基本單位是Container,而容器裏面是將內存、CPU、網絡、磁盤封裝到一起。
在Yarn的web 界面,我們可以直觀的看到當前Yarn集羣剩餘的內存、CPU核數、運行的Container數量。對提交到yarn上的任務來説,資源就是:內存、CPU、磁盤等可用信息。
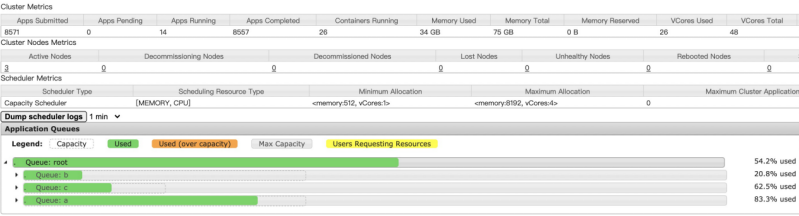
所以在提交到Yarn上執行的任務,我們可以根據ResourceManager 獲取Yarn集羣當前剩餘的內存、CPU核數來進行判斷,任務能否滿足提交條件等規則。其中,最基本的規則就是:
• Yarn集羣剩餘的內存 >= 當前任務所需的內存
• Yarn集羣剩餘的CPU核數 >= 當前任務所需的CPU核數
何時去判斷資源?
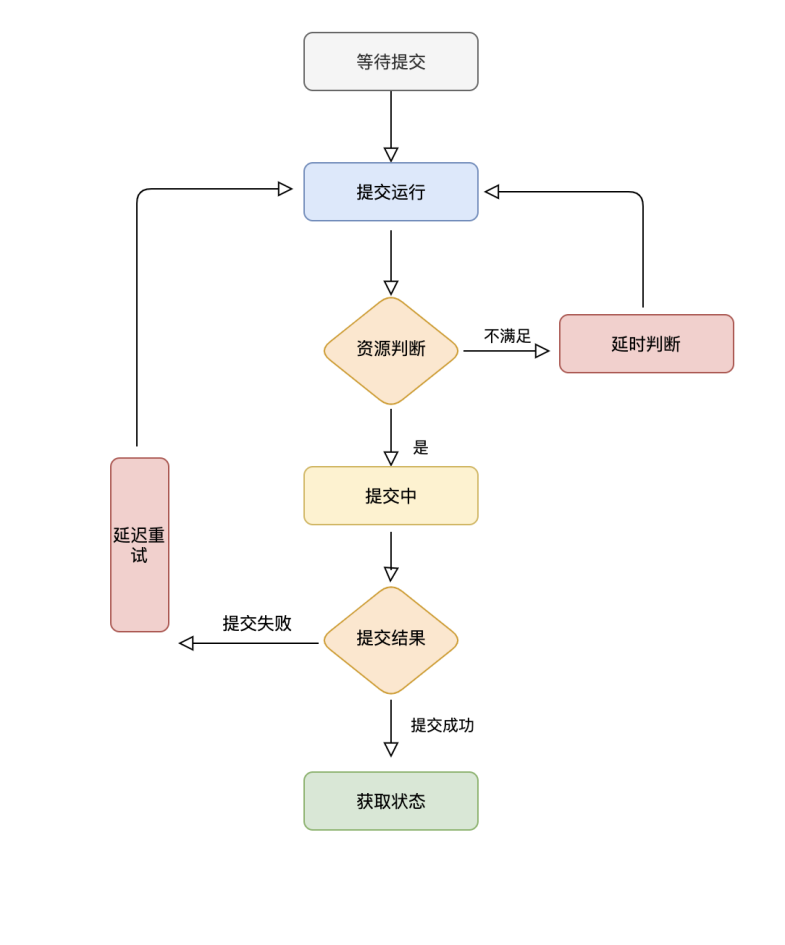
任務在界面開發完成之後,點擊運行的按鈕,開始從等待提交的狀態切換。在提交運行的時候,任務組裝好集羣配置信息進入下一個階段——資源判斷。
在這個階段開始判斷資源是否滿足任務提交。如果任務滿足則進行提交,如果任務不滿足,則定時、延時、重試直到資源滿足任務執行條件。
怎樣去判斷資源?
在worker-plugins提交的抽象類中,有一個通用的方法judgeSlots 去判斷資源。
judgeSlots 的判斷結果分為以下四種:
• OK: 資源判斷滿足,任務可以提交
• NOT_OK: 不滿足任務所需資源,需要延時重試
• LIMIT_ERROR: 任務參數設置錯誤: CPU核數或內存為0等場景
• EXCEPTION: 任務資源判斷異常: ResourceManager連接異常等場景

● 以Spark任務為例
下文我們以Spark任務為例,看看Spark的提交插件是如何獲取對應的ResourceManager信息並進行資源判斷的。
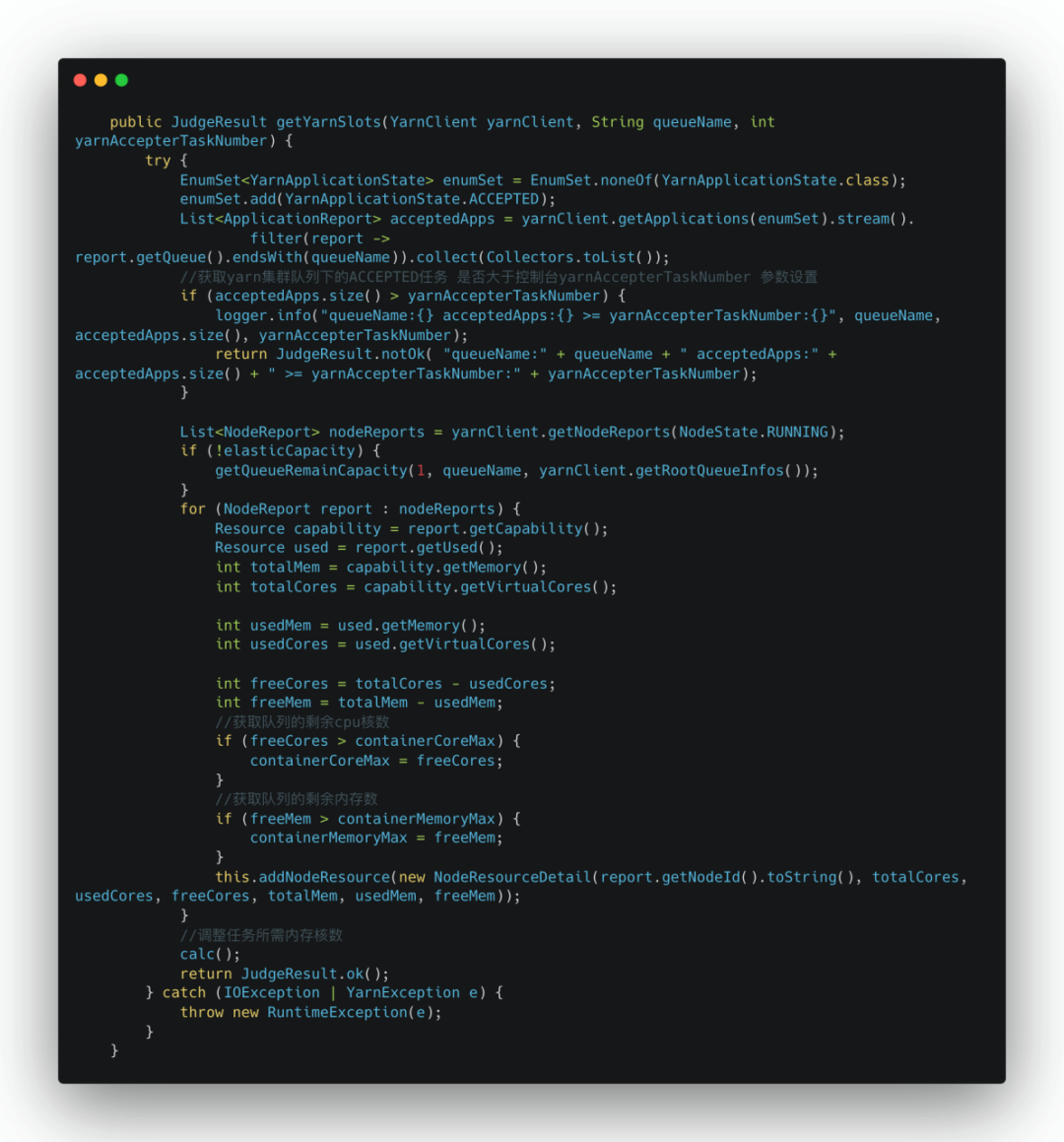
可以看到根據Yarn集羣信息獲取了以下信息:
• 根據Yarn集羣信息初始化YarnClient
• 獲取Yarn集羣隊列下的ACCEPTED狀態任務,是否大於控制枱yarnAccepterTaskNumber 參數設置
• 獲取Yarn集羣隊列的剩餘CPU核數和內存信息
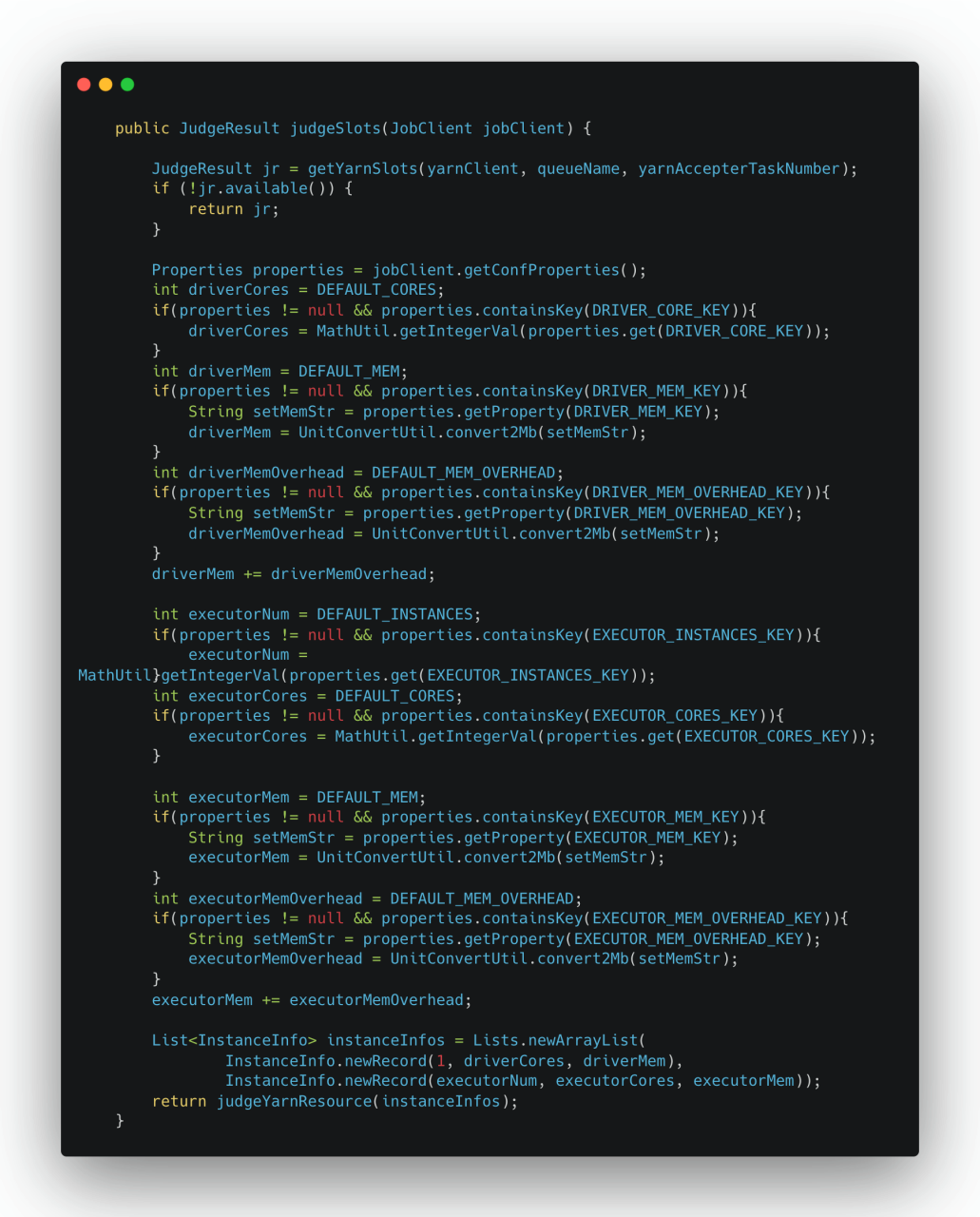
然後根據JobClient所攜帶的任務參數信息,獲取了Driver、Executor 的相關內存和CPU信息並進行計算。

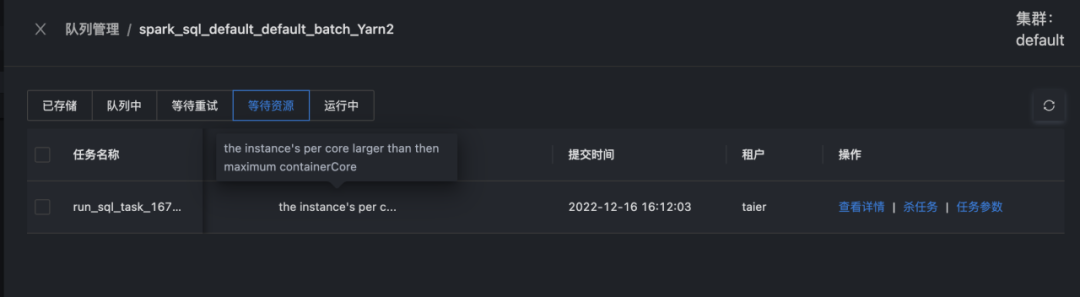
最後將獲取到的Yarn集羣信息和任務所需的資源信息按照固定規則進行比對,返回對應的資源判斷結果。資源判斷的結果將會實時在 Taier 的界面上展示,所以在任務處於等待提交狀態的時候,可以去控制枱->隊列,管理並查看該任務資源判斷信息。
Taier 未來規劃
展望未來,為進一步提升Taier的使用場景,同時也為了減少Hadoop生態在Taier中的依賴,Taier後續會擴展更多的任務類型。除了支持對接Hadoop集羣外,Taier也會陸續支持相關類型的local模式運行,完善更多的場景使用。
Taier團隊非常期待得到每一個人的反饋,能夠和其他優秀開發者共同合作,進一步推動Taier的技術發展。
如果您對Taier有興趣,希望可以參與到我們的建設中來,一起交流,一起進步,為 Taier變得更好貢獻一點你的代碼和意見,這將是我們,同時也是 Taier莫大的榮幸。
想了解或諮詢更多有關袋鼠雲大數據產品、行業解決方案、客户案例的朋友,瀏覽袋鼠雲官網:http://www.dtstack.com/?src=szkyzg
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:http://github.com/DTStack
- 從5分鐘到60秒,袋鼠雲數棧在熱重啟技術上的提效探索之路
- 詳細剖析|袋鼠雲數棧前端框架Antd 3.x 升級 4.x 的踩坑之路
- Teradata在華落幕,國產化崛起,袋鼠雲數棧會是更好的選擇嗎?
- 大數據應用場景下,標籤策略如何實現價值最大化?
- 袋鼠雲數棧UI5.0煥新升級,全新設計語言DT Design,更懂視覺更懂你!
- 一看就懂!任務提交的資源判斷在Taier中的實踐
- 看這篇就夠了丨基於Calcite框架的SQL語法擴展探索
- 無監控,不運維!深入淺出介紹ChengYing監控設計和使用
- DAG任務調度系統 Taier 演進之道,探究DataSourceX 模塊
- 數字孿生賦能智慧港口解決方案,助力港口數字化轉型
- Iceberg在袋鼠雲的探索及實踐
- Kerberos身份驗證在ChunJun中的落地實踐
- 從數據治理到數據應用,製造業企業如何突破數字化轉型困境丨行業方案
- 行業方案 | 新規落地,企業集團財務公司如何構建數智財務體系?
- 數據安全新戰場,EasyMR為企業築起“安全防線”
- ChunJun框架在數據還原上的探索和實踐 | Hadoop Meetup精彩回顧
- 開源直播課丨大數據集成框架ChunJun類加載器隔離方案探索及實踐
- 激活數據價值,探究DataOps下的數據架構及其實踐丨DTVision開發治理篇
- 實用五步法教會你指標體系的設計與加工
- 他來了!袋鼠雲大數據基礎平台EasyMR正式上線