關於知識蒸餾,你一定要了解的三類基礎演算法
前言 本文將對 response-based、feature-based 和relation-based 這三類基礎 KD 演算法進行重點介紹,為大家後續的深入研究、交流打下基礎。
本文轉載自OpenMMLab
作者 | 帶來新知識的
歡迎關注公眾號CV技術指南,專注於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀、CV招聘資訊。
知識蒸餾(Knowledge Distillation,簡記為 KD)是一種經典的模型壓縮方法,核心思想是通過引導輕量化的學生模型“模仿”效能更好、結構更復雜的教師模型(或多模型的 ensemble),在不改變學生模型結構的情況下提高其效能。
2015 年 Hinton 團隊提出的基於“響應”(response-based)的知識蒸餾技術(一般將該文演算法稱為 vanilla-KD [1])掀起了相關研究熱潮,其後基於“特徵”(feature-based)和基於“關係”(relation-based)的 KD 演算法被陸續提出。
以上述三類蒸餾演算法為基礎,學術界不斷湧現出致力於解決各特定問題、面向各特定場景的 KD 演算法,如:
- 零訓練資料情況下的 data-free KD;
- 教師模型也權重更新的 online KD、self KD;
- 面向檢測、分割、自然語言處理等任務的 KD 演算法等。
圖 1 三類基礎的知識蒸餾演算法的知識來源示意圖
源自參考文獻 [2]
本系列文章將以 MMRazor 演算法庫為依託,逐步揭開各類 KD 演算法的神祕面紗。
MMRazor 連結:
http://github.com/open-mmlab/mmrazor
1 Response-based KD
如下圖所示,Response-based KD 演算法以教師模型的分類預測結果為“目標知識”。具體來說,這裡的分類預測結果指的是分類器最後一個全連線層的輸出(稱為 logits)。
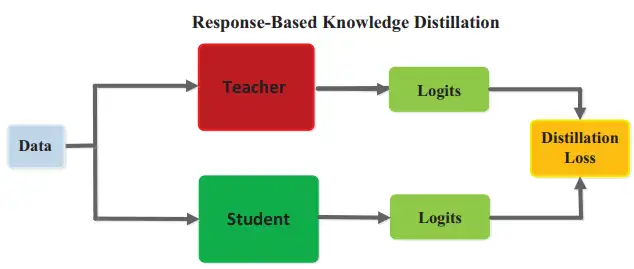
圖 2 基於響應的知識蒸餾演算法示意圖,源自參考文獻 [2]
與模型的最終輸出相比,logits 沒有經過 softmax 進行歸一化,非目標類別對應的輸出值尚未被抑制(假設教師模型 logits 中目標類別的對應值最高)。
在得到教師和學生的 logits 後,使用溫度係數 T 分別對教師和學生的 logits 進行“軟化”,進而計算二者的差異,具體的 loss 計算公式為:
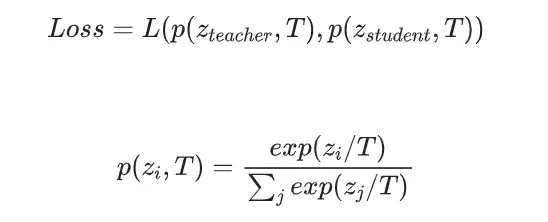
其中 z 為 logits, 為 logtis 中第 i 個類別的對應值,損失函式 L() 一般使用 KL 散度計算差異。T 一般取大於 1 的整數值,此時目標類與非目標類的預測值差異減小,logits 被“軟化”。相反地,T 小於 1 時會進一步拉大目標類與非目標類的數值差異,logtis 趨向於 one-hot。
由上可知,response-based KD 演算法的知識提取和 loss 計算過程非常簡潔,且 logits 本身具備較好理解的實際意義(模型判斷當前樣本為各類別的信心多少),因此研究者們將更多的注意力集中於 response-based KD 演算法生效原因的解釋。
1.1 Non-target class information
Vanilla-KD 認為:logits 提供的“軟標籤”資訊相比於 one-hot 形式的真值標籤(GT Label)有著更高的熵值,從而提供了更高的資訊量以及資料之間更小的梯度差異。
文中舉了一個 MNIST 資料集中的例子,對於某個手寫數字 2,模型認為它是 3 的可能性為 ,是 7 的可能性為 。其中便蘊含著“相比於 7 而言,當前的手寫數字 2 與 3 更加近似”的資訊,從而提供了當前樣本與各非目標類別的類間關係資訊。
但 logits 中的非目標類別的預測值通常相對過小(如上述預測為 3 的可能性僅為 ),因此文中使用大於 1 的溫度係數 T 降低類間得分差異(增大非目標類的預測值)。
DKD [3] 演算法將 logits 資訊拆分成目標類與非目標類兩部分,進一步驗證並得到 logits 中的非目標類別提供的資訊是 response-based KD 起效的關鍵。
DKD 首先對原始 KD 損失進行拆解,從而解耦 KD 損失為 target class knowledge distillation (TCKD)和 non-target class knowledge distillation(NCKD)兩部分:
其中,TCKD 相當於目標類概率與(1-目標類概率)的二元預測損失,NCKD 則是不考慮目標類後的軟標籤蒸餾損失。之後對 TCKD 和 NCKD 的效果做消融,結果如下表所示,其中二者同時使用代表著原始 KD 損失。可以看到單獨使用 NCKD 的效果非常好,甚至普遍優於完整的 KD 損失,而單獨使用 TCKD 帶來的效能提升不大甚至會降低訓練效果。
表 1 TCKD 和 NCKD 的消融實驗結果
那麼對於目標類別的蒸餾部分是否應該直接去除呢?TCKD 在哪些任務場景中是有效的呢?
1.2 Difficulty transfer
DKD 認為教師 logits 中目標類預測值代表著教師模型對各樣本的難度評估,舉個例子,目標類別預測值為 0.99 的樣本要比 0.75 的樣本更簡單。
當資料集較為簡單時(如 1.1 節實驗中使用的 CIFAR-100 資料集),教師模型 logtis 中目標類預測值均較高,樣本難度資訊的資訊量很低時 TCKD 的效果會隨之變差。
相反地,DKD 中相關實驗表明,當經過資料增強、標籤噪聲化處理或任務本身較困難時,TCKD 的正面作用會更加明顯。使用資料增強後的實驗結果如下所示(使用 CIFAR-100 資料集),可以看到此時 TCKD 帶來的正面作用明顯。
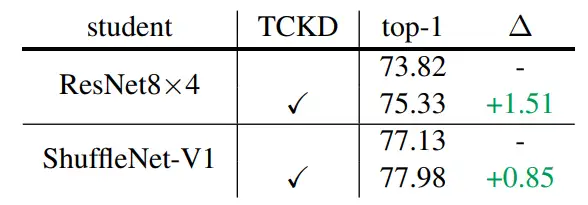
表 2 使用資料增強的情況下,新增 TCKD 帶來的效能收益,效能指標為 top-1 準確率
無獨有偶,BAN [4] 演算法也對 logtis 中的目標類預測值進行了重點分析驗證。
經過公式推導(詳細推導過程見 BAN section 3.2)得到結論:教師 logits 中的目標類預測值相當於各樣本的加權因子。
直接使用目標類預測值進行損失加權(Confidence Weighted by Teacher Max, CWTM)的結果如下所示(使用 CIFAR-100 資料集,指標為 test error),模型效能得到小幅提升。
表 3 CWTM 和 DKPP 用在不同模型上的蒸餾結果,效能指標為錯誤率,越小越好
需要說明的是:BAN 為級聯自蒸餾演算法,上表中 Teacher 即為學生模型;DKPP 為 dark knowledge with Permuted Predictions 的簡寫,具體做法為打亂非目標類的預測值,如原始為 [0.05, 0.2, 0.1, 0.6] 的 logits 打亂為 [0.2, 0.1, 0.05, 0.6]。
為什麼 BAN 中使用打亂非目標類後的 logits 蒸餾(DKPP)依然有效,且在 DenseNet80-80 和 80-120 模型中得到了比 CWTM 更好的效能呢?
1.3 Label smoothing
原因在於,此時的軟標籤仍在起到類似標籤平滑(label smoothing)的作用,從而提高了模型的泛化性。標籤平滑是一種緩解模型過擬合問題的技術,它將 one-hot 形式的標籤轉換為如下形式,其中 為人為設定的超引數。
參考文獻 [5] 認為:one-hot 形式的標籤會鼓勵模型將目標類別的概率預測為 1、非目標類別的概率預測為 0,從而導致 logtis 中目標類的值趨於無窮大。當訓練資料質量較差(有偏分佈明顯)或數量較少時容易導致模型 over-confident。因此,為了提高模型的泛化能力,標籤平滑將目標類的一部分標籤值平均分給了非目標類。
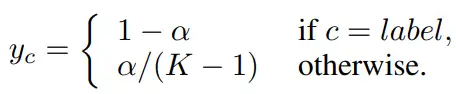
可以發現,軟標籤與標籤平滑有著異曲同工之妙,軟標籤在不經意間起到了標籤平滑的作用。二者最主要的區別在於,軟標籤中非目標類的標籤由教師給出,包含著類間關係資訊。DKPP 打亂各類預測值後導致類間關係錯亂,但仍起到了標籤平滑的作用。
關於軟標籤損失與標籤平滑損失的相同性、相異性等進一步關係分析詳見參考文獻 [6],同時,關於使用標籤平滑訓練後的教師能否用於知識蒸餾等問題的探究可見參考文獻 [6]、[7]、[8]。
1.4 Quantifying
進一步地,response-based KD 在模型訓練過程中起到了哪些正面影響(除了最終效能的提高)呢?
參考文獻 [9] 從資訊量化的角度對蒸餾過程進行了深入分析,該文章的深度分析可見第一作者的知乎回答,本文不再班門弄斧。文章中驗證為真的三個假設為:
- 比起直接從資料學習,蒸餾演算法往往使得深度神經網路(DNN)學到更多的知識;
- 比起直接從資料學習,蒸餾演算法往往使得 DNN 更傾向於同時學到不同知識;
- 比起直接從資料學習,蒸餾演算法往往使得 DNN 的優化方向更為穩定。
1.5 太長不看,直接看結論
如果你沒有充足的時間瀏覽上面的各項論述,可以直接獲取本節的結論:
- logits 中的非目標類資訊是 response-based KD 起效的關鍵;
- 目標類資訊傳遞的是教師模型對各樣本“難度”的評估,資料噪聲較大、任務困難的情況下,難度傳遞的作用更為明顯;
- logits 相比於 one-hot label 而言,起到了類似標籤平滑的作用,抑制了模型的 over-confidence 傾向,從而提高了模型泛化性;
- 從資訊量化的角度來看,response-based KD 往往使得模型學到更多的知識、更傾向於同時學到不同的知識、優化方向更為穩定。
2 Feature-based KD
通常的知識蒸餾設定中,教師模型與學生模型的分類器(或檢測器、解碼器等)是一致的,二者的差異在於特徵提取器(或稱 backbone、encoder)能力的強弱。
對於深度神經網路而言,由輸入資料抽象而來的特徵的質量高低,很大程度上決定了模型效能的優劣。自然而然地,以教師模型特徵提取器產生的中間層特徵為學習物件的 feature-based KD 演算法應運而生。
圖 3 FitNets 蒸餾演算法示意圖
最先成功將上述思想應用於 KD 中的是 FitNets [10] 演算法,文中將教師的中間層輸出特徵定義為 Hints,以教師和學生特徵圖中對應位置的特徵啟用的差異為損失。
通常情況下,教師特徵圖的通道數大於學生通道數,二者無法完全對齊。為解決該問題,一般在學生特徵圖後接卷積層(或全連線層、由多層卷積構成的卷積模組等),將學生特徵圖通道數與教師特徵圖通道數對齊,從而實現特徵點的一一對應。
損失函式計算公式如下所示,其中 和 分別代表教師和學生的特徵圖, 和 分別代表對教師和學生特徵的轉換,從而實現二者的維度對齊, 一般使用 損失。
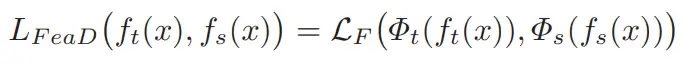
2.1 Connector
實現特徵對齊功能的模組(上面提到的 和 )是 feature-based KD 演算法的核心模組(本文中稱之為 connector),也是很多演算法的重點研究物件。
如針對教師 connector 進行預訓練的 Factor Transfer [11] 演算法;以二值化形式篩選教師和學生原始特徵的 AB [12] 演算法;將特徵值轉換為注意力值的 AT [13] 演算法等。
OFD [14] 對各相關演算法進行總結,研究了多種蒸餾演算法採用的特徵位置、 connector 的構成、損失函式等因素對資訊損失的影響,彙總表如下所示:
表 4 各蒸餾演算法的細節差異與資訊損失情況,表中的文獻編號與本文不相對應
可以看到 connector 的樣式多變,特徵的選取位置也是多種多樣,因此將上表中的演算法整合到一個演算法框架中看起來比較困難。那麼,有沒有一個演算法庫成功做到了這一點呢?
好訊息!好訊息!上面提到的 FitNets、Factor Transfer、AB、AT Loss(AT 演算法與蒸餾最相關的損失計算部分)、OFD 等演算法均被整合到了 MMRazor 演算法庫中,且核心模組 connector 被單獨抽象出來作為可配置元件,非常便於大家進行“演算法魔改”(如為 FitNets 演算法配置上 Factor Transfer 的 connector 並計算 AT Loss)。
Recorder 機制更是實現了 function、method、model和parameter 等各類資訊的“無痛”獲取,大家不需要額外進行程式碼編寫,只需要稍微更改 config 配置便可獲取你想要的資訊。
表 5 MMRazor 中多種型別的 Recorder
2.2 Summary
Feature-based KD相關的研究較多,本文不再進行深入討論。稍作總結的話,該類別演算法的核心關注點在於:
- 知識的定位(設計規則選出更為重要的教師特徵,這一點在檢測蒸餾演算法中非常重要)
- 如何進行特徵維度對齊、特徵語義對齊、特徵加權(connector 設計)
- 如何進行知識的高效傳遞(特徵 fusion、loss 設計)
3 Relation-based KD
最後一個蒸餾基礎演算法是 relation-based KD,有的研究者會將該類別演算法視為 feature-based KD 演算法的一種。原因在於 relation-based KD 使用的資訊也是模型特徵,只不過計算的不是對應特徵點之間的一對一差異,而是特徵關係的差異。
relation-based KD 演算法關心的重點是樣本之間或特徵層之間的關係,如分別構建教師和學生特徵層之間關係矩陣的 FSP [15] 演算法、分別構建相同 batch 內教師和學生各樣本特徵之間關係矩陣的 RKD [16] 演算法,二者均計算關係矩陣的差異損失。
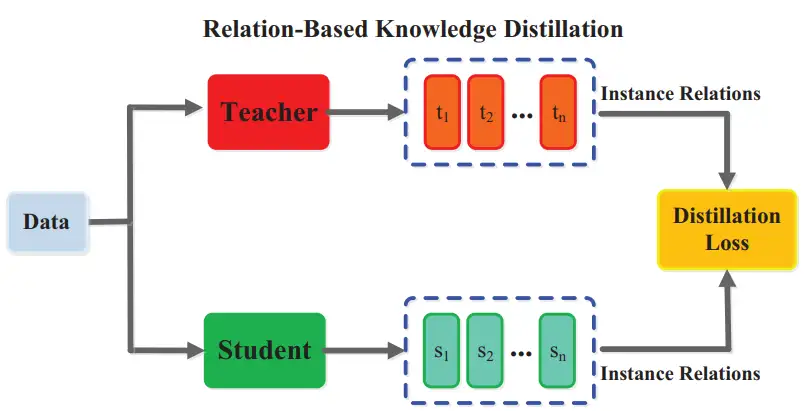
圖 4 基於關係的知識蒸餾演算法示意圖
上圖來源自參考文獻 [2]
3.1 Relational Knowledge Distillation
以 RKD 演算法為例,其核心思想如下圖所示。RKD 認為關係是一種更 high-level 的資訊,樣本之間的關係差異資訊優於單個樣本在不同模型的表達差異資訊,其中關係的差異同時包含兩個樣本之間的關係差異和三個樣本之間的夾角差異。
圖 5 RKD 演算法中的“關係”示意圖
將兩兩樣本之間的關係組成的關係矩陣差異損失記為 ,計算公式如下所示:
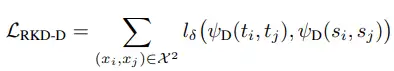
其中, 為 Huber loss, 計算的是歐式距離, 、 為不同樣本的特徵。將三個樣本之間的夾角組成的角度關係矩陣差異損失記為 ,計算公式如下所示:
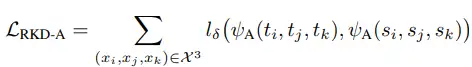
其中, 為 Huber loss, 計算夾角餘弦值,具體計算公式為:
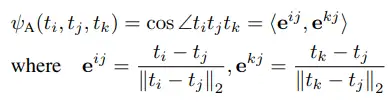
3.2 Summary
近年來,relation-based KD 演算法在分割任務中不斷取得突破。同一張影象中,畫素點之間的特徵關係差異或區域之間的特徵關係差異成為蒸餾分割模型的有效手段。但在檢測任務中 relation-based KD 演算法取得的成果較少。
一個可能的原因在於,構建高質量的關係矩陣需要大量的樣本,分類和分割(以畫素點或區域為樣本)任務的樣本數量足夠大;而受限於儲存空間大小等硬體因素,檢測任務同一個 batch 中的前景目標(object)數量較少且存在低質量前景目標(被遮擋的、模糊的物體等),因此制約了樣本間關係蒸餾在檢測任務上的應用。
4 Conclusion
本文對知識蒸餾中的三類基礎演算法進行了淺薄的介紹,近年來的 KD 演算法大多是依託於這三類基礎演算法進行的優化升級,相信本文對大家在知識蒸餾的進一步研究會有所幫助。
參考文獻:
- [1] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015, 2(7).
- [2] Gou J, Yu B, Maybank S J, et al. Knowledge distillation: A survey[J]. International Journal of Computer Vision, 2021, 129(6): 1789-1819.
- [3] Zhao B, Cui Q, Song R, et al. Decoupled Knowledge Distillation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 11953-11962.
- [4] Furlanello T, Lipton Z, Tschannen M, et al. Born again neural networks[C]//International Conference on Machine Learning. PMLR, 2018: 1607-1616.
- [5] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2818-2826.
- [6] Shen Z, Liu Z, Xu D, et al. Is label smoothing truly incompatible with knowledge distillation: An empirical study[J]. arXiv preprint arXiv:2104.00676, 2021.
- [7] Müller R, Kornblith S, Hinton G E. When does label smoothing help?[J]. Advances in neural information processing systems, 2019, 32.
- [8] Chandrasegaran K, Tran N T, Zhao Y, et al. Revisiting Label Smoothing and Knowledge Distillation Compatibility: What was Missing?[C]//International Conference on Machine Learning. PMLR, 2022: 2890-2916.
- [9] Zhang Q, Cheng X, Chen Y, et al. Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [10] Romero A, Ballas N, Kahou S E, et al. Fitnets: Hints for thin deep nets[J]. arXiv preprint arXiv:1412.6550, 2014.
- [11] Kim J, Park S U, Kwak N. Paraphrasing complex network: Network compression via factor transfer[J]. Advances in neural information processing systems, 2018, 31.
- [12] Heo B, Lee M, Yun S, et al. Knowledge transfer via distillation of activation boundaries formed by hidden neurons[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 3779-3787.
- [13] Zagoruyko S, Komodakis N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer[J]. arXiv preprint arXiv:1612.03928, 2016.
- [14] Heo B, Kim J, Yun S, et al. A comprehensive overhaul of feature distillation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 1921-1930.
- [15] Yim J, Joo D, Bae J, et al. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4133-4141.
- [16] Park W, Kim D, Lu Y, et al. Relational knowledge distillation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 3967-3976.
歡迎關注公眾號CV技術指南,專注於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀、CV招聘資訊。
【技術文件】《從零搭建pytorch模型教程》122頁PDF下載
QQ交流群:444129970。群內有大佬負責解答大家的日常學習、科研、程式碼問題。
其它文章
用於超大影象的訓練策略:Patch Gradient Descent
CV小知識討論與分析(5)到底什麼是Latent Space?
CVPR 2023 Workshop | 首個大規模視訊全景分割比賽
如何更好地應對下游小樣本影象資料?不平衡資料集的建模的技巧和策
CVPR 2023 Workshop | 首個大規模視訊全景分割比賽
如何更好地應對下游小樣本影象資料?不平衡資料集的建模的技巧和策
用少於256KB記憶體實現邊緣訓練,開銷不到PyTorch千分之一
DAMO-YOLO | 超越所有YOLO,兼顧模型速度與精度
- 普通段位玩家的CV演算法崗上岸之路(2023屆秋招)
- 用於超大影象的訓練策略:Patch Gradient Descent
- 關於知識蒸餾,你一定要了解的三類基礎演算法
- 深度理解變分自編碼器(VAE) | 從入門到精通
- CUDA 教程(一) GPU 程式設計概述和 CUDA 環境搭建
- 一文總結當下常用的大型 transformer 效率優化方案
- 多模態學習有哪些架構?MBZUAI最新《多模態表示學習》綜述,29頁詳述多模態表示學習的演化、預訓練及其應用綜述
- Transformer-Based Learned Optimization
- U-Net在2022年相關研究的論文推薦
- ECCV 2022 | 新方案: 先剪枝再蒸餾
- CVPR2022 | 簡單高效的語義分割體系結構
- CVPR 2022 | 網路中批處理歸一化估計偏移的深入研究
- CVPR2022 | 通過目標感知Transformer進行知識蒸餾
- 經典論文 | 300FPS,超快結構感知的深度車道檢測
- YOLO系列梳理(九)初嘗新鮮出爐的YOLOv6
- CVPR2022 | 長期行動預期的Future Transformer
- CVPR2022 | 可精簡域適應
- CVPR2022 | 弱監督多標籤分類中的損失問題
- 計算機視覺中的論文常見單詞總結
- CVPR2022 | A ConvNet for the 2020s & 如何設計神經網路總結