kafka的消費者組(上)
最近在排查一個sparkstreaming在操作kafka時,rebalance觸發了一個異常引起任務失敗,而組內小夥伴對消費者組的一些基本知識不是很瞭解,所以抽了些時間進行相關原理的整理。本文就來聊聊相關內容。
【消費者組的基本原理】
在kafka中,多個消費者可以組成一個消費者組(consumer group),但是一個消費者只能屬於一個消費者組。消費者組保證其訂閱的topic的每個分割槽只能分配給該消費者組中的某一個消費者進行處理,那麼這裡可能就會出現兩種情況:
當消費者組中的消費者個數小於訂閱的topic的分割槽數時,那麼存在一個消費者到多個分割槽進行消費的情況;
而如果消費者組中的消費者個數大於訂閱的topic的分割槽數時,那麼就會有一部分消費者分配不到分割槽資訊,出現消費者浪費的情況。
另外,如果不同的消費者組訂閱了同一個topic,不同的消費者組彼此互不干擾。
【消費者組的原理深入】
1. group coordinator的概念
在早期版本中(0.9版本之前),kafka強依賴於zookeeper實現消費者組的管理,包括消費者組內的消費者通過在zk上搶佔znode節點來決定消費哪些分割槽;註冊消費者組和broker相關節點的監聽,以感知環境的變化進而觸發rebalance;另外就是offset也維護在zk中。
這種方式除了強依賴於zk,導致zk壓力較大之外,還容易引發其他問題,例如:
一個被監聽的zk節點發生變化,導致大量的通知訊息推送給所有監聽者(即消費者),另外就是腦裂引起的不一致問題,引發rebalance混亂。
基於以上原因,從0.9版本開始,kafka重新設計了名為group coordinator的協調者負責管理消費者的關係,以及消費者的offset。注意每個消費者組都有一個對應的group coordinator例項。
2. 消費者與broker的互動流程
消費者組中消費者與broker之間的互動流程如下圖所示:
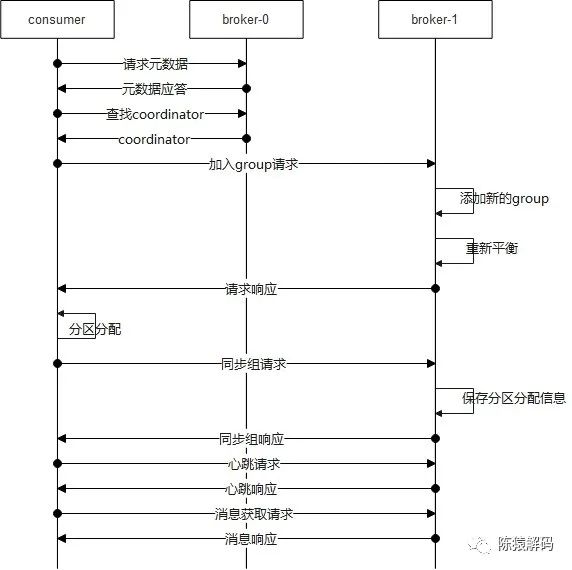
1)首先,和所有客戶端的邏輯一樣,先向服務端請求元資料資訊
2)接著向服務端請求消費者組的coordinator,得到coordinator所在的brokerid後,向對應broker建立連線並傳送請求加入消費者組的請求,服務端收到請求後,判斷消費者組是否存在,不存在則建立消費者組,並將該消費者加入到消費者組中,然後給予請求應答,對於第一個加入消費者組的消費者成為leader,在加入消費者組的應答中會告知成員資訊,以及leader的資訊。這樣客戶端可以知道自身是否成為leader。
3)此後,對於leader的消費者根據分割槽分配策略,進行分割槽分配,然後向broker傳送同步消費者組(SyncGroup)的請求,請求中包含分割槽分配的資訊。服務端,收到請求後,服務端儲存分割槽分配資訊,並進行請求應答響應。
這裡需要注意的是:對於非leader的消費者同樣會傳送同步消費者組的請求,只是請求中沒有分割槽分配的資訊而已。
4)再然後,消費者與broker之間進行定時的心跳互動,服務端以此判斷消費者的存活狀態。
5)最後,消費者進入輪詢階段,向服務端傳送訊息獲取(fetch)請求進行訊息的消費。
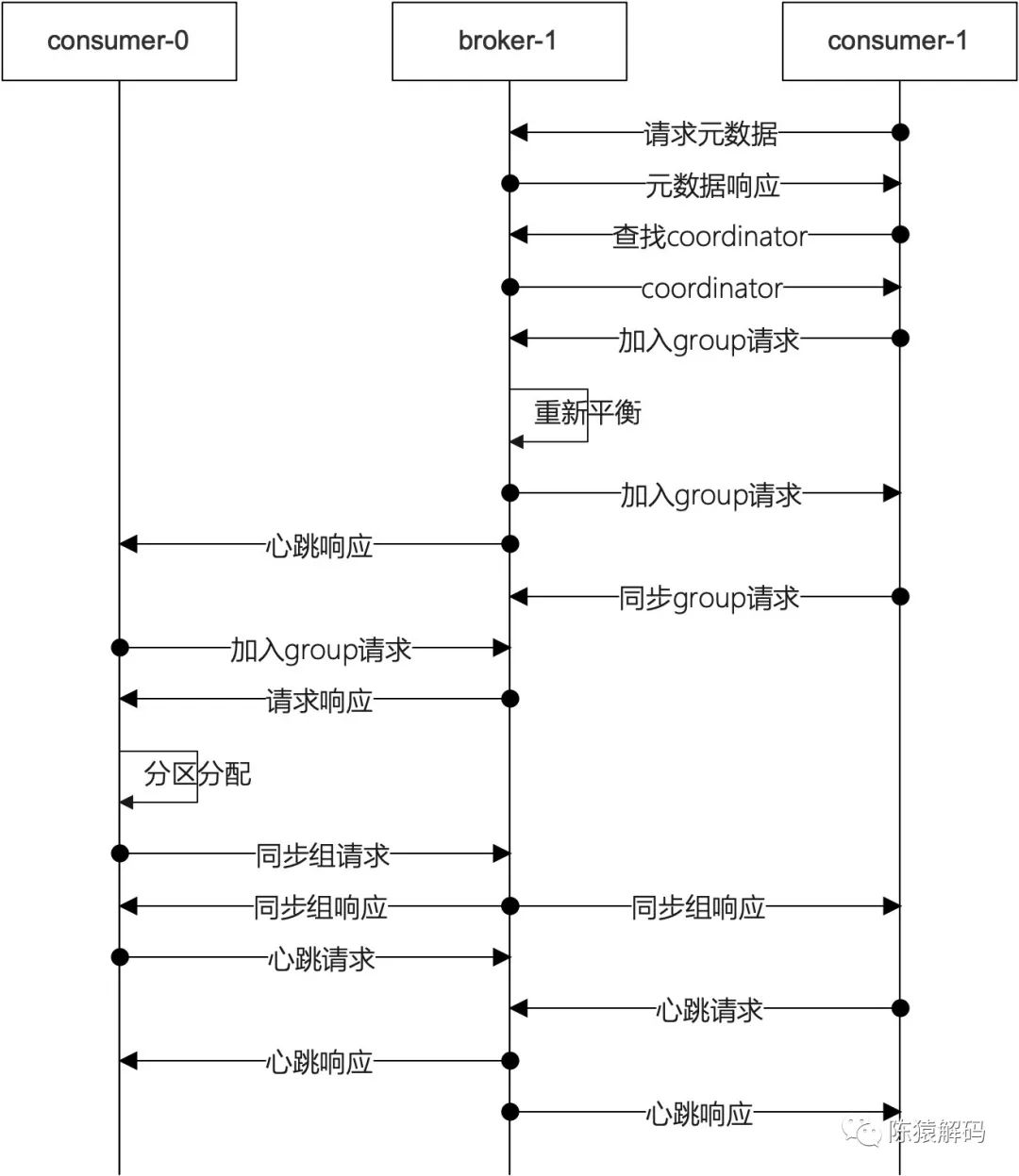
3. rebalance的流程
當消費者組有新成員加入或已有成員退出;或者topic分割槽(新增)發生變更時,服務端會觸發重新分配分割槽的邏輯,這就是所謂的rebalance。
具體實現,服務端是通過在心跳中給leader對應的消費者一個錯誤資訊,消費者在捕獲該錯誤資訊後,觸發重新加入消費者組,之後複用之前的流程, 即在加入消費者組的請求響應中,告知消費者組中消費者的情況,leader的消費者重新進行分割槽分配,然後通過同步組請求告知服務端新的分割槽分配情況。
其大概流程如下圖所示:
4. 服務端的相關邏輯
在服務端,coordinator分別維護了消費者組的資訊,其中通過一個狀態機來實現不同事件引起的各個不同處理操作,狀態機的各個狀態跳轉,以及觸發的事件如下圖所示:
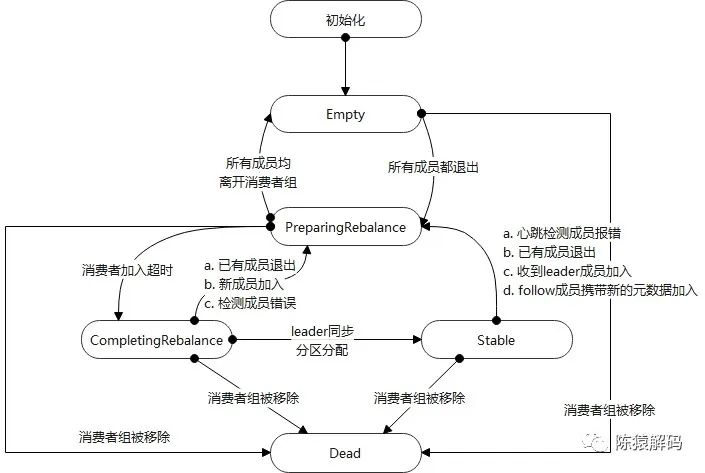
除此之外,還包括消費者組的成員資訊、leader資訊、generationId、以及偏移量的相關資訊等。
5. 分割槽分配策略
首先,客戶端可以通過"partition.assignment.strategy"引數進行分配策略的配置,當前可選的策略包括:
org.apache.kafka.clients.consumer.RangeAssignor
org.apache.kafka.clients.consumer.RoundRobinAssignor
org.apache.kafka.clients.consumer.StickyAssignor
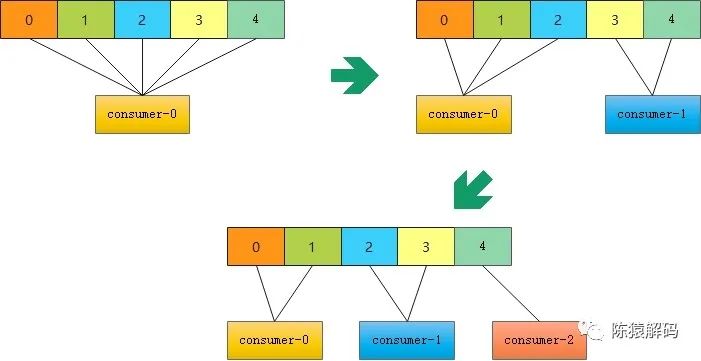
org.apache.kafka.clients.consumer.CooperativeStickyAssignor(新版本增加)對於RangeAssignor,字面意思是按分割槽範圍來進行分配的,具體分配邏輯是:針對每個topic,n=分割槽數/消費者個數,m=分割槽數%消費者個數,前m個消費者每個分配n+1個分割槽,後面的(消費者個數減去m)消費者每個分配n個分割槽。
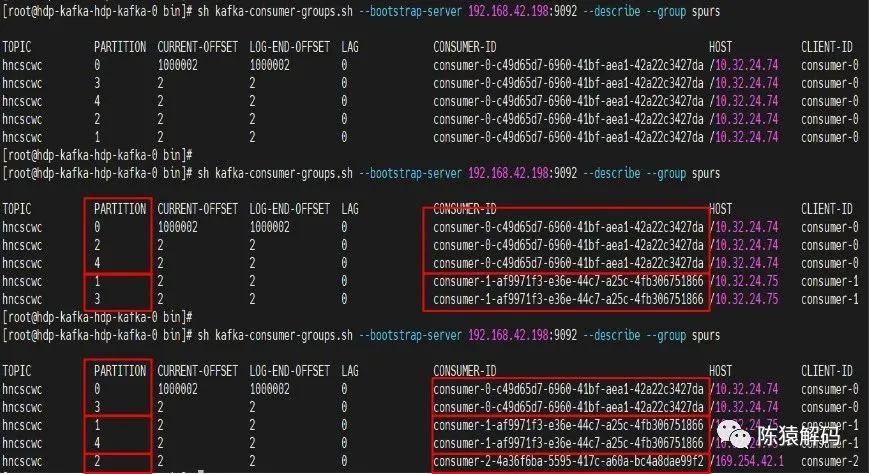
下面為實測三個消費者組依次加入同一個消費者組,並訂閱一個具有5分割槽的topic的情況:
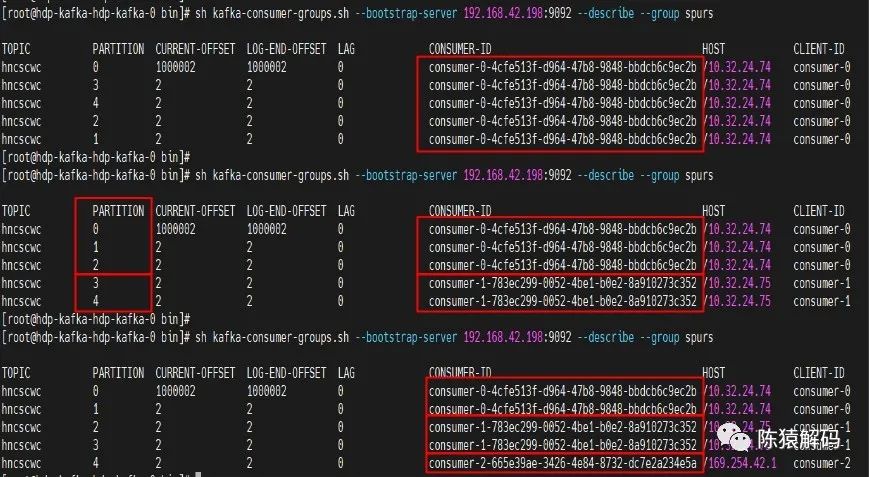
更直觀一點的圖如下所示:
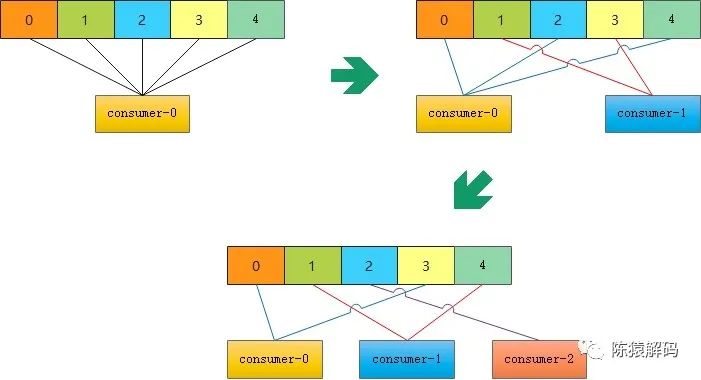
RoundRobinAssignor則是將所有消費者按照消費者ID字典序進行排序,同時將所有topic的所有分割槽也按字典序進行排序,再輪詢進行分配。
同樣實測情況與直觀的圖示如下:
StickyAssignor是在kafka的0.11版本引入的,其設計目的主要有兩個:
分割槽分配儘量平均
當分割槽重新分配時,儘量與上一次的分配保持一致,也就是儘量少的做改動,這也就是sticky(粘性)一詞的含義。
StickyAssignor的具體分配邏輯略複雜,本文不打算展開說明,來看下實際效果。
同樣是三個消費者先後加入同一個消費者組後的分割槽情況:

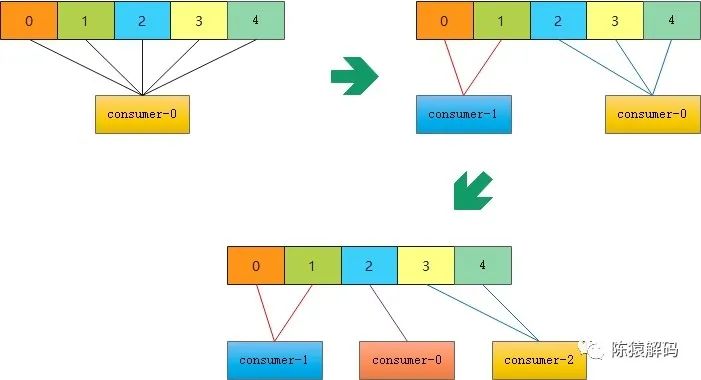
從圖中可以看出,與前面的RoundRobinAssignor相比,第三個消費者(consumer-2)加入後,前兩個消費者的分割槽幾乎沒有變動。
【小結】
小結一下,本文主要講述了kafka中,消費者組的基本概念與原理,在閱讀原始碼過程中,其實發現還有很多內容可以再展開單獨分析,例如服務端在處理加入消費者組請求時,採用了延時處理的方式,更準確的說,內部大量採用了時間輪加延時處理機制來響應客戶端的請求;例如group coordinator所在節點異常後,遷移邏輯是怎樣的保證其高可用等等。
另外一大塊內容,消費者組中消費者的偏移量是如何儲存的,其互動邏輯又是怎樣的。這一部分內容作為(下)部分內容再單獨介紹。
好了,這就是本文的全部內容,如果覺得本文對您有幫助,請點贊+轉發,如果覺得有不正確的地方,也可以拍磚指點,最後,歡迎加我微信交流~
本文分享自微信公眾號 - 陳猿解碼(gh_383bc7486c1a)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。