淺談iceberg的儲存檔案
這是我的第100篇原創文章
【前言】
上一篇文章介紹瞭如何通過java api對iceberg進行操作。這次我們來聊聊iceberg裡的儲存檔案。
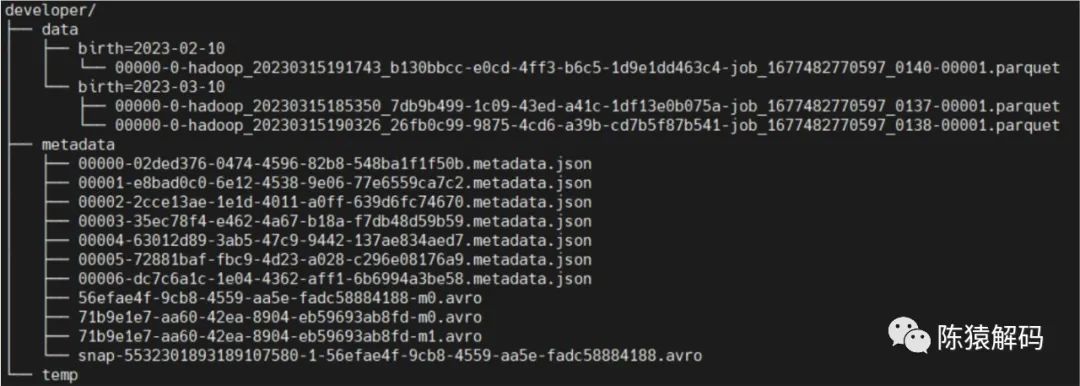
iceberg中的持久化儲存的檔案可以簡單的分為資料檔案和元資料檔案。資料檔案就是儲存資料記錄的檔案,而元資料檔案又可以分為元資料描述檔案、清單列表檔案(manifest list),或者根據檔名又可以稱為快照檔案、以及清單檔案(manifest file)。三類檔案通過層級關係相互關聯起來。下面就分別詳細介紹下檔案的具體內容與格式。
【資料檔案】
通常在表儲存目錄的data子目錄下,存放的是實際資料記錄的檔案,檔案的格式在建表時指定,預設為parquet。當然也可以指定為orc、textfile等支援的型別。
另外,在有定義分割槽欄位的表中,資料寫入時會按照分割槽欄位的值依次建立子目錄,最終的資料檔案則存放在這些子目錄中。
注:對於api的操作,可以自定義資料的儲存路徑。
【元資料檔案】
該目錄主要存放記錄表的元資料資訊的檔案,可以分為如下幾類:
1. $VersionID-$UUID$Extension
該檔案記錄表的元資料資訊。在建立表的時候,會同步建立該檔案,此後的每次操作都會產生新的元資料檔案。
檔名中的 $VersionID為版本號,共5位長度;$UUID是通過UUID庫生成的隨機32位的ID,$Extension為檔案的字尾,預設情況下為".metadata.json",如果對元資料指定了壓縮方式,那麼會在".metadata.json"的前面加上壓縮型別的名稱,例如"gzip.metadata.json"。
如檔名中的字尾描述一樣,該檔案採用json格式進行儲存,下面羅列了各欄位的含義:
format-version
table-uuid
location
last-updated-ms
last-column-id
schema
current-schema-id
schemas
partition-spec
default-spec-id
partition-specs
name
transform
source-id
field-id
last-partition-id
default-sort-order-id
sort-orders
properties
current-snapshot-id
snapshots
operation
added-data-files
added-records
added-files-size
deleted-data-files
delete-records
removed-files-size
changed-partition-count
total-records
total-files-size
total-data-files
total-delete-files
snapshot-log
metadata-log
元資料檔案格式的版本,預設為1,代表為v1版本。
表的uuid。
元資料檔案儲存位置URI,通常是在hdfs中的全路徑。
元資料最後更新時間
最後一個列欄位的ID
表格式定義說明,屬於v1版本中的必需欄位,在v2版本中以下面兩個欄位替代。
當前表格式定義(schemas中包含的schema陣列)使用的schema id。
v2格式中表格式定義說明,欄位的值為一個數組,記錄了歷史schema的變更情況,陣列中的每一項均為表schema的物件,包括型別、ID、欄位資料,配合上面的current-schema-id就能知道當前版本的表格式定義是怎樣的了。
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "int"
}, {
"id" : 2,
"name" : "name",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "birth",
"required" : false,
"type" : "string"
} ]
} ]表的分割槽欄位定義說明,同樣屬於v1版本中的必需欄位
預設使用的分割槽的ID
表的分割槽欄位定義說明,v2格式中的必須欄位。欄位的值為一個數組,記錄了歷史的分割槽定義,陣列中的每一項均為一個分割槽物件,其中包括ID和分割槽欄位說明,對於分割槽欄位說明則又包含如下幾個欄位。
分割槽欄位的名稱。
分割槽欄位的轉換方式,一般來說是欄位本身,即"identity"; 但可以是year、month、day、bucket等轉換函式,實現不同的分割槽的邏輯,這裡的值就是對應轉換函式名。
對應schema中的filed欄位的ID
分割槽欄位定義的ID,預設從1000開始遞增。
與schemas類似,配合default-spec-id欄位可以知道當前的分割槽定義。
最後一個分割槽欄位的ID,即對應partition-specs中分割槽欄位的filed-id。
預設排序的ID
欄位排序定義,預設為空陣列
表的屬性定義。
當前使用的快照ID
快照檔案列表,具體值為一個數組,陣列中的每一項均為一個快照資訊,每個快照資訊又是一個物件,包括ID(snapshot-id)、父snapshot的ID(parent-snapshot-id)、生成的時間戳(timestamp-ms)、概要資訊(summary),檔案清單(manifest-list或manifests)、表schema的ID(schema_id),其中概要資訊包括的常見的子欄位有:
本次快照引發的操作,例如append、delete、replace、overwrite。
本次快照新增的檔案數,operation操作為append才有該欄位
本次快照新增的記錄數,operation操作為append才有該欄位
本次快照新增的檔案大小,operation操作為append才有該欄位
本次觸發快照的操作所刪除的檔案數,operation操作為delete才有該欄位
本次觸發快照的操作所刪除的記錄數,operation操作為delete才有該欄位
本次觸發快照的操作所刪除的檔案大小,operation操作為delete才有該欄位
本次涉及變更的分割槽數
本次快照完成後,表中總的記錄數
本次快照完成後,總的檔案大小
本次快照完成後,總的檔案數
本次快照完成後,總的刪除檔案數
"snapshots" : [ {
"snapshot-id" : 8319024382941793184,
"timestamp-ms" : 1678669777251,
"summary" : {
"operation" : "append",
"added-data-files" : "2",
"added-records" : "4",
"added-files-size" : "1978",
"changed-partition-count" : "2",
"total-records" : "4",
"total-files-size" : "1978",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://hdfsHACluster/user/hive/warehouse/iceberg_db.db/developer/metadata/snap-8319024382941793184-1-051dc090-a770-441c-b76b-b97a591a97c7.avro",
"schema-id" : 0
} ]snapshot的歷史集合,以陣列形式表示。
元資料檔案(metadata.json)的歷史集合,以陣列形式表示。
2. snap-xx.avro
清單列表檔案,也稱為快照檔案,每次有資料(提交)寫入時觸發生成。
在該檔案中主要記錄了清單檔案記錄集,檔案以avro的格式進行儲存,每一條記錄表示一個manifest,在每個記錄中最主要的欄位資訊為"manifest_path",標記清單檔案的儲存位置。
{
"manifest_path": "hdfs://hdfsHACluster/user/hive/warehouse/iceberg_db.db/developer/metadata/051dc090-a770-441c-b76b-b97a591a97c7-m0.avro",
"manifest_length": 6181,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 8319024382941793184
},
"added_data_files_count": {
"int": 2
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 0
},
"partitions": {
"array": [{
"contains_null": false,
"contains_nan": {
"boolean": false
},
"lower_bound": {
"bytes": "2023-02-10"
},
"upper_bound": {
"bytes": "2023-03-10"
}
}]
},
"added_rows_count": {
"long": 4
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 0
}
}3. $COMMITUUID-m$COUNT.avro
(資料檔案)清單資訊,一個快照中可能包含了多個這樣的檔案資訊。而在該檔案中包含了涉及的多個數據檔案資訊。其中$COMMITUUID為提交的事務UUID,與快照檔案中的COMMITUUID保持一致,$COUNT為清單檔案的計數,從0開始。
該檔案同樣採用avro的格式進行儲存,每一條記錄描述一個具體的資料檔案,在該記錄中由三個欄位組成:
status
snapshot_id
data_file
檔案狀態,0表示已存在、1表示新增、2表示刪除
檔案對應的快照ID
檔案詳細資訊,包括了檔案路徑,檔案格式,以及檔案中一些相關的metrics資訊,例如記錄數、列欄位、最大最小值等。
完整示例如下所示:
{
"status": 1,
"snapshot_id": {
"long": 8319024382941793184
},
"data_file": {
"file_path": "hdfs://hdfsHACluster/user/hive/warehouse/iceberg_db.db/developer/data/birth=2023-02-10/00000-0-hadoop_20230313090641_733a351d-0554-4129-a56b-861f715638b9-job_1677482770597_0127-00002.parquet",
"file_format": "PARQUET",
"partition": {
"birth": {
"string": "2023-02-10"
}
},
"record_count": 2,
"file_size_in_bytes": 988,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [{
"key": 1,
"value": 54
}, {
"key": 2,
"value": 60
}, {
"key": 3,
"value": 103
}]
},
"value_counts": {
"array": [{
"key": 1,
"value": 2
}, {
"key": 2,
"value": 2
}, {
"key": 3,
"value": 2
}]
},
"null_value_counts": {
"array": [{
"key": 1,
"value": 0
}, {
"key": 2,
"value": 0
}, {
"key": 3,
"value": 0
}]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [{
"key": 1,
"value": "\u0002\u0000\u0000\u0000"
}, {
"key": 2,
"value": "ma"
}, {
"key": 3,
"value": "2023-02-10"
}]
},
"upper_bounds": {
"array": [{
"key": 1,
"value": "\u0004\u0000\u0000\u0000"
}, {
"key": 2,
"value": "yuan"
}, {
"key": 3,
"value": "2023-02-10"
}]
},
"key_metadata": null,
"split_offsets": {
"array": [4]
},
"sort_order_id": {
"int": 0
}
}
} {
"status": 1,
"snapshot_id": {
"long": 8319024382941793184
},
"data_file": {
"file_path": "hdfs://hdfsHACluster/user/hive/warehouse/iceberg_db.db/developer/data/birth=2023-03-10/00000-0-hadoop_20230313090641_733a351d-0554-4129-a56b-861f715638b9-job_1677482770597_0127-00001.parquet",
"file_format": "PARQUET",
"partition": {
"birth": {
"string": "2023-03-10"
}
},
"record_count": 2,
"file_size_in_bytes": 990,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [{
"key": 1,
"value": 53
}, {
"key": 2,
"value": 61
}, {
"key": 3,
"value": 103
}]
},
"value_counts": {
"array": [{
"key": 1,
"value": 2
}, {
"key": 2,
"value": 2
}, {
"key": 3,
"value": 2
}]
},
"null_value_counts": {
"array": [{
"key": 1,
"value": 0
}, {
"key": 2,
"value": 0
}, {
"key": 3,
"value": 0
}]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [{
"key": 1,
"value": "\u0001\u0000\u0000\u0000"
}, {
"key": 2,
"value": "chen"
}, {
"key": 3,
"value": "2023-03-10"
}]
},
"upper_bounds": {
"array": [{
"key": 1,
"value": "\u0003\u0000\u0000\u0000"
}, {
"key": 2,
"value": "jie"
}, {
"key": 3,
"value": "2023-03-10"
}]
},
"key_metadata": null,
"split_offsets": {
"array": [4]
},
"sort_order_id": {
"int": 0
}
}
}【場景分析】
按照以往文章的慣例,我們還是通過一個實際場景,包括建表、到插入資料、修改列、刪除分割槽的資料、刪除快照等操作,元資料檔案的變更等操作,對上面檔案中一些關鍵欄位進行剖析。
1. 建立表
表建立後,將元資料資訊寫入metadata.json檔案中,但此時由於還沒有資料,因此不會寫入快照資訊、資料清單檔案。

2. 插入資料
該操作完成後寫入了新的元資料檔案(注意,ID自增),快照檔案、資料清單檔案、以及實際的資料檔案。
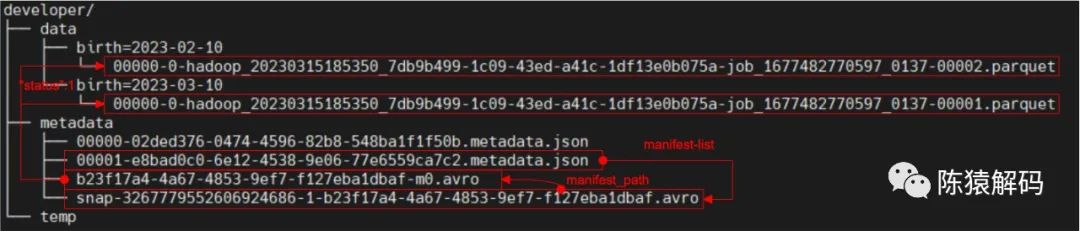
注意:建表時有指定分割槽,因此不同的記錄資料存放在對應分割槽目錄下。
3. 對錶schema進行變更,新增一個列欄位
由於沒有資料的變化,因此只會新增一個元資料檔案。
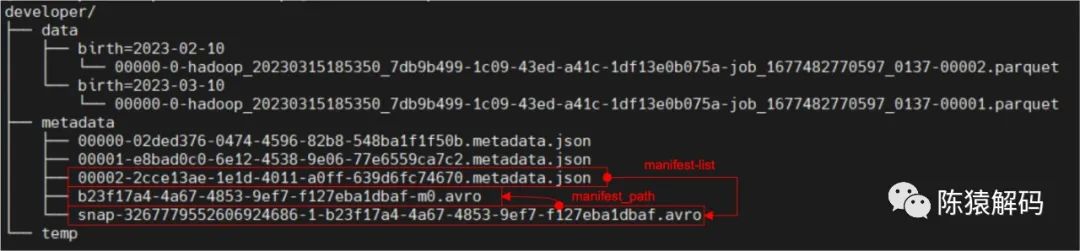
4. 再次插入資料
同樣,資料是按照分割槽存放在不同的目錄下,同時有新的清單檔案記錄本次操作新增的檔案,而新的快照檔案則同時引用兩個清單檔案,記錄表的全量資料。元資料檔案中記錄了所有的快照資訊,同時也記錄當前使用的快照ID。
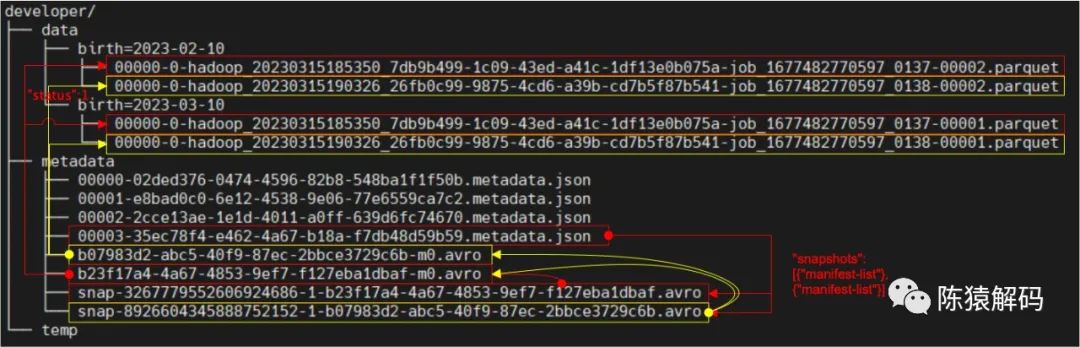
5. 刪除指定分割槽的資料
對於資料的更新,預設採用寫入合併記錄的方式,因此,新的快照中只記錄了兩個新的清單檔案,在這兩個清單檔案中分別記錄不同的資料檔案以及檔案的狀態。

6. 再次寫入資料
流程和第4步操作一致,在上一個快照的基礎上新增相關資訊。
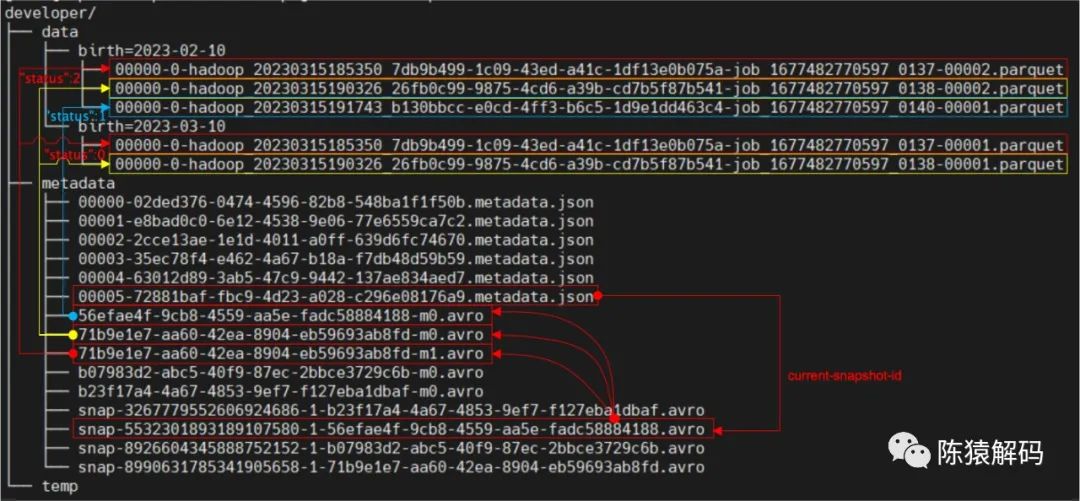
7. 僅保留當前快照
刪除快照的同時,對於(當前保留的快照中)沒有引用到的清單檔案、以及標記為刪除的資料檔案,都會一起進行刪除。
【總結】
簡單小結一下,本文主要介紹了iceberg持久化的幾個檔案,以及檔案的儲存內容與格式,以及相互之間的關聯關係,最後通過一個實際例子,分析了元資料檔案的組織與變更。瞭解了這些內容,將有助於理解iceberg的資料讀寫流程,以及其他相關邏輯。
當然,文章中也提到了元資料檔案格式的版本(v1,v2),不同版本對使用上也會有所區別。後面再單獨講解。
好了,這就是本文的全部內容,如果覺得本文對您有幫助,請點贊+轉發,如果覺得有不正確的地方,也可以拍磚指點,最後,歡迎加我微信交流~
本文分享自微信公眾號 - 陳猿解碼(gh_383bc7486c1a)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。