位元組跳動構建Data Catalog資料目錄系統的實踐
作為資料目錄產品,Data Catalog 通過彙總技術和業務元資料,解決大資料生產者組織梳理資料、資料消費者找數和理解數的業務場景,並服務於資料開發和資料治理的產品體系。本文介紹了位元組跳動Data Catalog系統的構建和迭代過程,將分為上、下篇釋出。上篇主要圍繞Data Catalog調研思路及技術架構展開。
一、背景
1. 元資料與Data Catalog
元資料,一般指描述資料的資料,對資料及資訊資源的描述性資訊。在當前大資料的上下文裡,通常又可細分為技術元資料和業務元資料。 Data Catalog,是一種元資料管理的服務,會收集技術元資料,並在其基礎上提供更豐富的業務上下文與語義,通常支援元資料編目、查詢、詳情瀏覽等功能。 元資料是Data Catalog系統的基礎,而Data Catalog使元資料更好的發揮業務價值。
2. Data Catalog的業務價值
Data Catalog系統主要服務於兩類使用者的兩種核心場景。
對於資料生產者來說,他們利用Data Catalog系統來組織、梳理自己負責的各類元資料。生產者大部分是大資料開發的同學。通常,生產者會將某一批相關的元資料以目錄等形式編排到一起,方便維護。另外,生產者會持續的在技術元資料的基礎上,豐富業務相關的屬性,比如打業務標籤,新增應用場景描述,欄位解釋等。
對於資料消費者來說,他們通過Data Catalog查詢和理解他們需要的資料。在使用者數量和角色上看,消費者遠多於生產者,涵蓋了資料分析師、產品、運營等多種角色的同學。通常,消費者會通過關鍵字檢索,或者目錄瀏覽,來查詢解決自己業務場景的資料,並瀏覽詳情介紹,欄位描述,產出關係等,進一步的理解和信任資料。
另外,Data Catalog系統中的各類元資料,也會向上服務於資料開發、資料治理兩大類產品體系。
在大資料領域,各類計算和儲存系統百花齊放,概念和原理又千差萬別,對於元資料的採集、組織、理解、信任等,都帶來了很大挑戰。因此,做好一個Data Catalog產品,本身是一個門檻低、上限高的工作,需要有一個持續打磨提升的過程。
3. 舊版本痛點
位元組跳動Data Catalog產品早期為能較快解決Hive的元資料收集與檢索工作,是基於LinkedIn Wherehows進行二次改造 。Wherehows架構相對簡單,採用Backend + ETL的模式。初期版本,主要利用Wherehows的儲存設計和ETL框架,自研實現前後端的功能模組。
隨著位元組跳動業務的快速發展, 公司內各類儲存引擎不斷引入,資料生產者和消費者的痛點都日益明顯。之前系統的設計問題,也到了需要解決的階段。具體來說:
- 使用者層面痛點:
資料生產者: 多引擎環境下,沒有便捷、友好的資料組織形式,來一站式的管理各類儲存、計算引擎的技術與業務元資料。 資料消費者: 各種引擎之間找數難,元資料的業務解釋零散造成理解數難,難以信任。 - 技術痛點:
擴充套件性:新接入一類元資料時,整套系統傷筋動骨,開發成本月級別。
可維護性:經過一段時間的修修補補,整個系統顯的很脆弱,研發人員不敢隨便改動;儲存依賴重,同時使用了MySQL、ElasticSearch、圖資料庫等系統儲存元資料,維護成本很高;接入一種元資料會增加2~3個ETL任務,運維成本直線上升。
4. 新版本目標
基於上述痛點,我們重新設計實現Data Catalog系統,希望能達成如下目標: - 產品能力上,幫助資料生產者方便快捷組織元資料,資料消費者更好的找數和理解數。
- 系統能力上,將接入新型元資料的成本從月級別降低為星期甚至天級別,架構精簡,單人業餘時間可運維。
二、 調研與思路
1. 業界產品調研
站在巨人的肩膀上,動手之前我們針對業界主流DataCatalog產品做了產品功能和技術調研。因各個系統都在頻繁迭代,資料僅供參考。

2. 升級思路
根據調研結論,結合位元組已有業務特點,我們敲定了以下發展思路: 對於搜尋、血緣這類核心能力,做深做強,對齊業界領先水平。 對於各產品間特色功能,挑選適合位元組業務特點的做融合。 技術體系上,儲存和模型能力基於Apache Atlas改造,應用層支援從舊版本平滑遷移。
三、技術與產品概覽
1. 架構設計
 (1)元資料的接入
(1)元資料的接入
- 元資料接入支援T+1和近實時兩種方式
- 上游系統:包括各類儲存系統(比如Hive、 Clickhouse等)和業務系統(比如資料開發平臺、資料質量平臺等)
- 中間層:
ETL Bridge:T+1方式執行,通常是從外部系統拉取最新元資料,與當前Catalog系統的元資料做對比,並更新差異的部分 MQ:用於暫存各類元資料增量訊息,供Catalog系統近實時消費 與上游系統打交道的各類Clients,封裝了操作底層資源的能力
(2)核心服務層
系統的核心服務,根據職責的不同,細拆為以下子服務: - Catalog Service:支援元資料的搜尋、詳情、修改等核心服務
- Ingestion Service:接受外部系統呼叫,寫入元資料,或主動從MQ中消費增量元資料
- Resource Control Plane:通過各類Clients,與底層的儲存或業務系統互動,操作底層資源,比如建庫建表,能力可插拔
- Q&A Service:問答系統相關能力,支援對元資料的欄位含義、使用場景等提問和回答,能力可插拔
- ML Service:負責封裝與機器學習相關的能力,能力可插拔
- API Layer:以RESTful API的形式整合系統中的各類能力
(3)儲存層
針對不同場景,選用的不同的儲存: - Meta Store:存放全量元資料和血緣關係,當前使用的是HBase
- Index Store:存放用於加速查詢,支援全文索引等場景的索引,當前使用的是ElasticSearch
- Model Store:存放推薦、打標等的演算法模型資訊,使用HDFS,當ML Service啟用時使用
(4)元資料的消費 - 資料的生產者和消費者,通過Data Catalog的前端與系統互動
- 下游線上服務可通過OpenAPI訪問元資料,與系統互動
- Metadata Outputs Layer:提供除了API之外的另外一種下游消費方式
MQ:用於暫存各類元資料變更訊息,格式由Catalog系統官方定義 Data warehouse:以數倉表的形式呈現的全量元資料
2. 產品功能升級
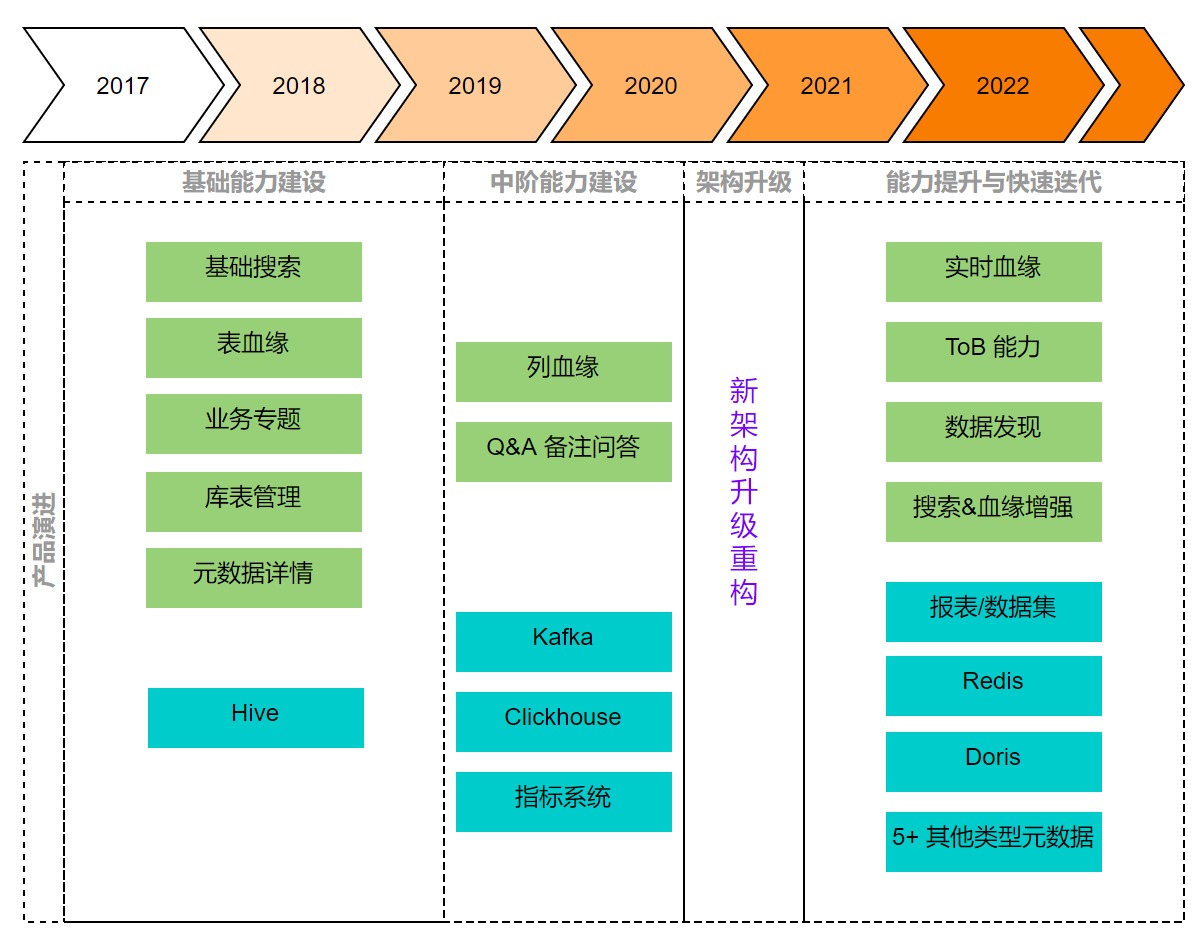
產品能力上的升級迭代,大致分為以下幾個階段: - 基礎能力建設(2017-2019):資料來源主要是離線數倉Hive,支援了Hive相關庫表建立、元資料搜尋與詳情展示、表之間血緣,以及將相關表組織成業務視角的資料專題等
- 中階能力建設(2019-2020年中):資料來源擴充套件了Clickhouse與Kafka,支援了Hive列血緣,Q&A問答系統等
- 架構升級(2020年中-2021年初):產品能力迭代放緩,基於新設計升級架構
- 能力提升與快速迭代(2021年至今):資料來源擴充套件為包含離線、近實時、業務等端到端系統,搜尋和血緣能力有明顯增強,探索機器學習能力,產品形態更成熟穩定。另外我們還具備了ToB售賣的能力。
四、關鍵技術
構建一個好的Data Catalog系統,需要考慮的核心產品設計和技術設計有很多。篇幅所限,本文只概要介紹技術設計中最核心重要的部分,更多細節展開可參照後續的文章。
1. 資料模型統一
將不同元資料的資料模型統一,是降低接入成本和維護成本的重要前提。系統的資料模型,基本參照了Apache Atlas的設計與實現。一些基本概念簡單介紹如下:
- 型別(Type):描述一類元資料,由多個屬性組成。例如,hive table是一類元資料,hive_db也是一類元資料。Type可具備繼承關係。按面向物件的程式設計思想,可以理解type為一個Class。
- 例項(Entity):代表一個type的具體事例。一個entity可能作為一個屬性存在於另一個entity中,例如hive_table中的db屬性,db本身也是一個entity。在面向物件的程式設計思想中,一個entity可以認為是一個class的instance。
- 屬性(Attribute):屬性的集合組合而成為一個Type。屬性本身的型別(typeName)可能是一個自定義的type,也可能是一種基礎型別,包括date,string等。例如,db是hive_table的一個屬性,column也是hive_table的一個屬性。
- 關係(Relationship):一種特殊的Entity,用以描述兩個Entity之間的關聯模式。 在實際應用這套型別系統時,我們有兩個方面比較有特點:
(1)繼承與組合的廣泛使用
 位元組的業務場景十分複雜,為了充分複用各種元資料型別之間的相似能力,又獲得足夠的定製靈活性,我們為每類元資料設計了父Type。比如,Hive Table和Clickhouse Table,都含有名稱、描述、欄位等屬性,他們都繼承自DataStore這個父Type。
位元組的業務場景十分複雜,為了充分複用各種元資料型別之間的相似能力,又獲得足夠的定製靈活性,我們為每類元資料設計了父Type。比如,Hive Table和Clickhouse Table,都含有名稱、描述、欄位等屬性,他們都繼承自DataStore這個父Type。
另外一種情況,有些型別的實體可以作用於多種其他的實體,比如一張Hive表和一堆被組織在一起的業務報表,都可以被使用者收藏或點贊。我們將收藏、點贊這些行為也抽象為實體,並通過關係與Hive表、業務報表集合等相關聯。這種思想,類似程式設計中的組合或者是切面的概念。
(2)調整型別載入機制
在實踐中我們意識到,跟某種資料來源相關聯的能力,應該儘可能收斂到一起,這可以極大降低後續的維護成本。對於一種元資料型別定義,也在這種考慮的範圍之內。我們調整了Apache Atlas載入型別檔案的機制,使其可以從多個package,以我們定義過的目錄結構和先後順序載入。這也為後面的標準化奠定了基礎。
2. 資料接入標準化
為了最終達成降低接入和維護成本的目標,統一了型別系統之後,第二步就是接入流程的標準化。
我們將某一種元資料型別的接入邏輯封裝為一個connector,並通過提供SDK的方式簡化connector的編寫成本。
以使用最廣泛的T+1 bridge接入的connector SDK為例,我們參照時下流行的Flink流式處理框架,結合T+1 bridge的業務特點,實現瞭如下模型:
- Source:從外部儲存計算系統等批量拉取最新的全量元資料。資料結構和欄位通常由外部系統決定。概念上可對齊Flink的source operator。
- Diff Operator:接收source的輸出,並從Catalog Service拉取當前系統中的全量元資料,做差異對比,產出差異的部分。概念上對齊Flink中的某一種自定義的ProcessFunction。
- Event Generate Operator:接收Diff Operator的輸出,根據Catalog系統定義好的格式,將差異的metadata轉化成event格式,比如對於新建的metadata,轉換成CreateEvent。概念上對齊Flink中的某一種自定義的ProcessFunction。
- Sink:接收Event Generate Operator的輸出,將差異的metadata寫入Ingestion Service。概念上對齊Flink的sink operator。
- Bridge Job:組裝pipeline,做執行時控制。概念上對齊Flink的Job。
- 當需要接入新的元資料時,通常只需要重新編寫Source和Diff Operator,其他元件都是可直接複用的。標準化的connector極大節省接入和運維成本。
3 . 搜尋優化
搜尋是Data Catalog中,除了詳情瀏覽外,最廣泛使用的功能,也是資料消費者找數最主要的手段。在我們的系統中,每天有70%以上的使用者都會使用搜索功能。
搜尋是一個相對成熟的技術領域,針對元資料的檢索可以看作是垂直領域的搜尋引擎。本節概要介紹我們在設計實現元資料搜尋引擎時的收穫,更多的細節展開,會有後續的文章。
在實際場景中,我們發現公司內的元資料搜尋,與通用搜索引擎相比,有兩個十分顯著的特點: - 搜尋中存在部分很強的Pattern:使用者搜尋元資料時,有一些隱式的習慣,通過挖掘埋點中的固定pattern,給了我們針對性優化的機會。
- 行為資料規模有限:公司內部的元資料搜尋使用者,通常是千級別,而每天搜尋的點選次數是萬級別,這個規模遠遠小於對外的通用搜索引擎,也造成很多模型沒法及時收斂,但也一定程度上給我們簡化問題的機會。
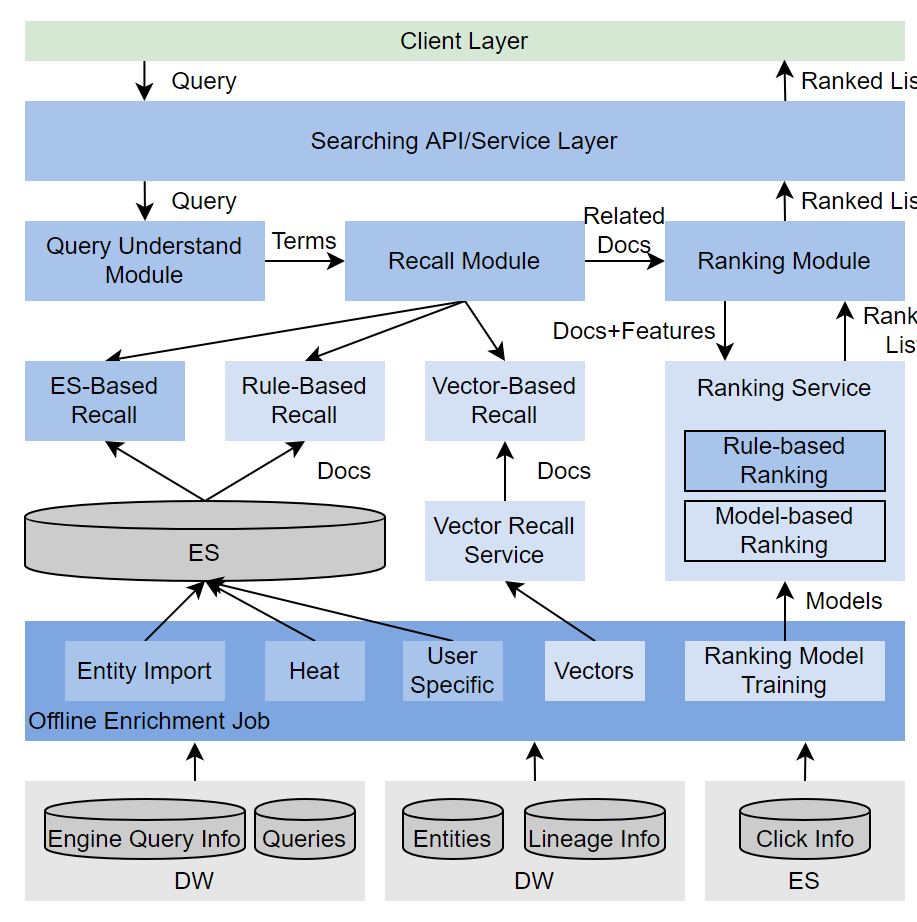
我們設計的元資料搜尋,架構如上圖所示。粗略來看,可以劃分為兩大部分: - 離線部分:負責彙集各類與搜尋相關的資料,做資料清洗或者模型訓練,根據不同的用途,寫入不同的儲存,供給線上搜尋模組使用。
- 線上部分:分為搜尋理解、召回、精排三個主要階段,步驟和概念上與通用搜索引擎對齊。
針對上面分析的特點,我們在搜尋優化時,有兩個對應的策略: - 對於強Pattern,廣泛使用Rule-Based的優化手段:比如,我們發現很大一部分使用者在搜尋Hive時,會使用“庫名.表名”的pattern,在識別到query語句中有“.”時,我們會優先嚐試根據庫名和表名檢索
- 激進的個性化:因使用者規模可控,且某位使用者通常會頻繁使用某個領域的元資料,我們記錄了很多使用者的歷史行為細節,當query語句與過去瀏覽過元資料有一定文字相關性時,個性化相關的得分會有較大提升
4. 血緣能力
血緣能力是Data Catalog系統的另外一個核心能力。自動化的,端到端的血緣能力,是很多業界系統宣稱的亮點功能。構建完備的血緣能力,既可以幫助生產者梳理、組織他們負責的元資料,也可以幫助資料消費者找數和理解資料的上下文 。
位元組跳動非常關注資料價值,業務也複雜,對我們資料血緣鏈路的建設也提出了很高的要求。本節只概要介紹我們搭建血緣鏈路時考慮的核心問題,更多細節可以參照之前的文章:位元組跳動內部的資料血緣用例與設計。
首先,資料血緣的系統邊界是:從RDS和MQ開始,一路圖經各種計算和儲存,最終匯入指標、報表和資料服務系統。
其次,在設計系統時,我們充分考慮了血緣鏈路的多樣性和複雜性。如下圖所示,我們通過T+1和近實時的方式,獲取各類任務系統中的資訊,根據任務型別,呼叫不同的解析服務,將格式化過的血緣資料寫入Data Catalog系統,供給下游的API呼叫或者MQ、離線數倉消費。
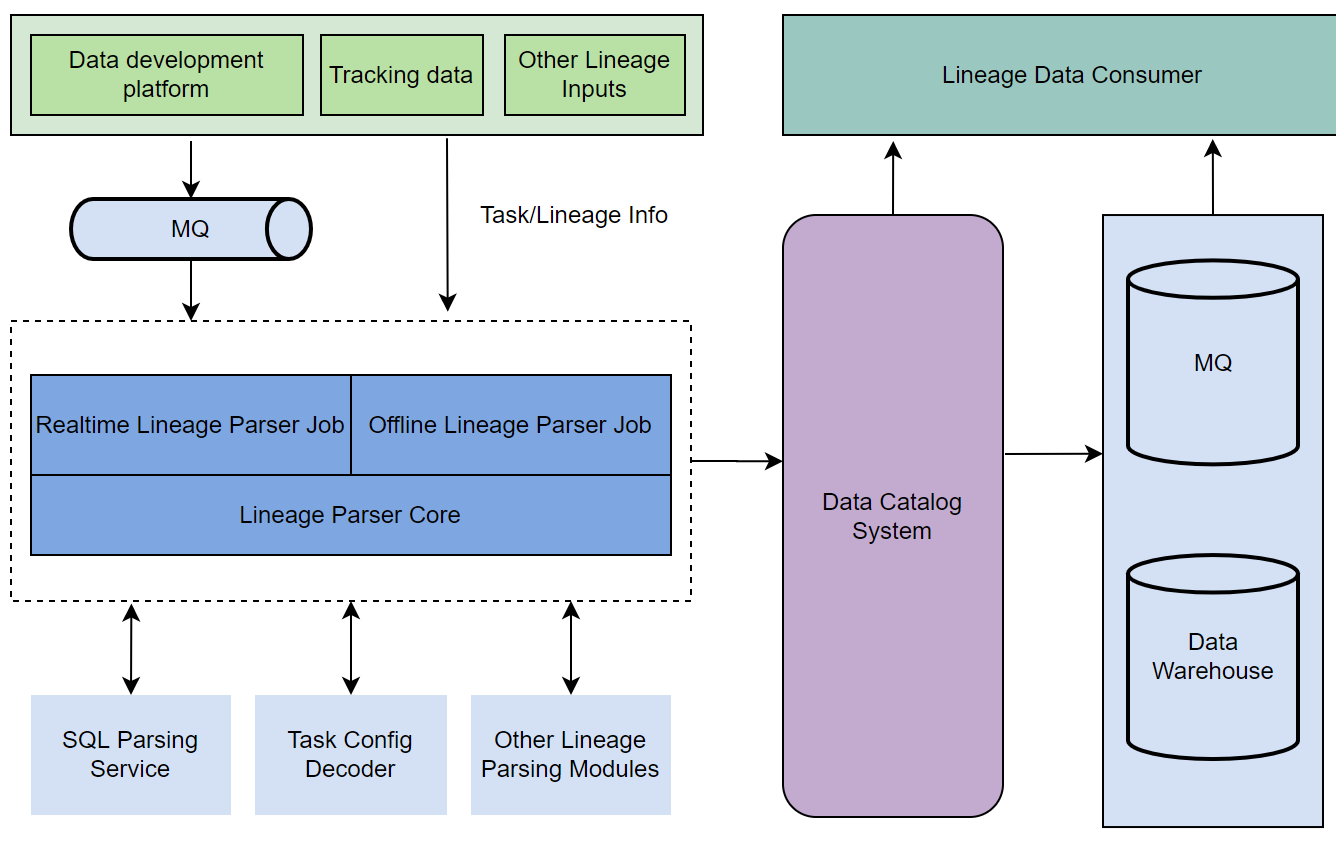
最後,在血緣質量衡量上,我們通過定義有效的血緣準確率、覆蓋率和時效性,來確保血緣資訊的準確、全面和實時性。
當前,我們的血緣能力已經廣泛應用於位元組的資料資產、資料開發和資料治理等領域。
5 .儲存層優化
如前面介紹,在儲存層,我們借用了Atlas的設計與實現。Atlas的底層使用JanusGraph做圖引擎。JanusGraph 是基於Gremlin 圖查詢語義實現的計算引擎,其底層儲存支援HBase/Cassadra/BerkeleyDB等KCV結構的儲存,同時,使用ElasticSearch作為索引查詢支援。
當我們將越來越多的元資料接入系統,圖儲存中的點和邊分別到達百萬和千萬量級,讀寫效能都遇到了比較大的問題。我們做了部分原始碼的修改,這邊介紹其中比較重要的兩個,更多細節請參照後續的文章。
(1 )讀優化:開啟MutilPreFetch 能力
在我們的相簿中,存在很多超級點,也就是關係十分龐大的元資料。舉兩種情況,一是列十分多的大寬表,對於一些機器學習的表,甚至會超過1萬列;另外一種情況是被廣泛引用的底表,比如埋點底表的一級血緣下游就超過了1萬。在讀取這類資料時,我們發現效能極差。
與關係型資料庫慢查詢優化類似,我們通過監控埋點收集到慢查詢語句,藉助gremlin的profile函式,分析query plan中的問題,並通過構建索引或者改寫語句與配置等,做相應的優化。
開啟JanusGraph的MutilPreFetch查詢開關,是其中一種情況。該特性的大致實現原理是,在屬性過濾的時候, 批量並行獲取所有關聯頂點的屬性,再在記憶體做屬性過濾,而未開啟該特性時,則會找到對端的頂點後,每個頂點單獨去獲取屬性再做過濾條件。

需要注意的是,該機制在觸發優化時的前置條件: -
- Janusgraph 0.4版本以上且配置開啟
-
- 語句中不包含limit
-
- 語句中包含has
-
- 查詢結果行數不超過cache.tx-cache-size
(2) 寫優化:去除Guid全域性唯一性檢查 對於超大元資料的寫入請求,也有比較嚴重的效能問題。比如超過3000列的寫入,我們發現需要消耗接近15分鐘。
通過模擬單個超大表寫入,並使用arthas火焰圖跟蹤相關程式碼, 我們發現在每個JanusGraph圖頂點寫入時,都會做guid的全域性唯一性校驗,這裡十分耗時。

通過分析,我們發現guid在全域性上預設是唯一的,沒有必要做這個唯一性檢查,同時,我們定義了業務語義上全域性唯一的qualifiedName,以此減少不必要的唯一性重複檢查。
配合其他的優化,我們在一次寫入大量節點時,節省不少開銷,最終效能大致如下:

- 查詢結果行數不超過cache.tx-cache-size
五、未來工作
文中闡述的部分Data Catalog技術和產品功能已經通過火山引擎大資料研發治理套件 DataLeap 對外開放。
接下來,我們提升Data Catalog系統,會主要集中在以下幾個方面:
- 首先,是將元資料往資料資產轉化。當前,我們收集了豐富的技術類元資料和一部分業務類元資料,如何將各類元資料,與真實的業務場景關聯,將沒有直接業務價值的元資料轉化為有直接業務價值的資料資產,是我們正在探索的方向。
- 其次,是更廣泛的應用智慧能力。Data Catalog中有很多可以落地的智慧化場景,比如搜尋推薦,自動打標等,我們已經做了一些基礎的嘗試,接下來會進行更廣泛的推廣。
- 最後,開放能力的搭建。在元資料接入方面,我們準備將其封裝成產品能力,提供類似connector市場的功能,便於在ToB市場做更敏捷的合作與推廣;另外計劃與開源和商用的敏捷報表等
六、關聯產品
火山引擎大資料研發治理套件DataLeap
一站式資料中臺套件,幫助使用者快速完成資料整合、開發、運維、治理、資產、安全等全套資料中臺建設,幫助資料團隊有效的降低工作成本和資料維護成本、挖掘資料價值、為企業決策提供資料支撐。
歡迎關注位元組跳動資料平臺同名公眾號獲取更多技術乾貨
- 從銀行數字化轉型來聊一聊,火山引擎 VeDI 旗下 ByteHouse 的應用場景
- ByteHouse 實時匯入技術演進
- 關於 DataLeap 中的 Notebook,你想知道的都在這
- 火山引擎DataLeap:3個關鍵步驟,複製位元組跳動一站式資料治理經驗
- 如何又快又好實現 Catalog 系統搜尋能力?火山引擎 DataLeap 這樣做
- 什麼是A/B實驗,為什麼要開A/B實驗?
- 計算效能提升百倍 火山引擎數智平臺這款產品助力企業員工更好看數用數
- 火山引擎DataLeap資料排程例項的 DAG 優化方案
- 如何快速構建企業級資料湖倉?
- 位元組跳動基於Doris的湖倉分析探索實踐
- 火山引擎在行為分析場景下的ClickHouse JOIN優化
- 位元組跳動資料血緣圖譜升級方案設計與實現
- 提速 10 倍!深度解讀位元組跳動新型雲原生 Spark History Server
- 位元組跳動基於 ClickHouse 優化實踐之“查詢優化器”
- 位元組跳動基於ClickHouse優化實踐之“多表關聯查詢”
- “今日頭條”名字是 AB 測試定的?位元組跳動用九年時間打造出了怎樣的資料平臺
- 位元組跳動基於ClickHouse優化實踐之Upsert
- 位元組跳動資料質量動態探查及相關前端實現
- 位元組跳動資料平臺技術揭祕:基於 ClickHouse 的複雜查詢實現與優化
- 位元組跳動資料平臺技術揭祕:基於ClickHouse的複雜查詢實現與優化