PyFlink + 區塊鏈?揭祕行業領頭企業 BTC.com 如何實現實時計算

大家好,我們是 BTC.com 團隊。2020 年,我們有幸接觸到了 Flink 和 PyFlink 生態,從團隊自身需求出發,完善了團隊內實時計算的任務和需求,搭建了流批一體的計算環境。
在實現實時計算的過程中,我們在實踐中收穫了一些經驗,在此分享一些這方面的心路歷程。主要分享的大綱如下:
- 困惑 • 描述 • 思考 • 行動
- 流批一體的架構
- 架構
- 效果
- Zeppelin、PyFlink on K8S 等實踐
- Zeppelin
- PyFlink on K8S
- 區塊鏈領域實踐
- 展望 • 總結
01 困惑 • 描述 • 思考 • 行動
作為工程師,我們每天都在不斷地瞭解需求,研發業務。
有一天,我們被拉到了一次團隊總結會議上,收到了以下的需求:
銷售總監 A:
我們想要知道銷售的歷史和實時轉化率、銷售額,能不能統計一下實時的 TOP5 的商品,還有就是大促時候,使用者實時訪問、商品實時瀏覽量 TOP5 的情況呢,可以根據他歷史訪問的記錄實時推薦相關的嗎?
市場總監 B:
我們想要知道市場推廣的效果,每次活動的實時資料,不然我們的市場投放無法準確評估效果,及時反饋啊。
研發總監 C:
有些使用者的 Bug 無法復現,日誌可以再實時一點嗎?傳統日誌分析,需要一定的梳理,可不可以直接清洗 / 處理相關的資料?
採購總監 D:
這些年是不是流行數字化,採購這邊想預測採購需求,做一下實時分類和管理支出,預測未來供應來源,完善一下成本。這個有辦法做嗎?還有有些供應商不太穩定啊,能監控到他們的情況嗎?
運維總監 E:
網站有時候訪問比較慢,沒有地方可以看到實時的機器情況,搞個什麼監控大屏,這個有辦法解決嗎?
部門領導 F:
可以實現上面的人的需求嗎。
做以上的瞭解之後,才發現,大家對於資料需求的渴望程度,使用方不僅需要歷史的資料,而且還需要實時性的資料。
在電商、金融、製造等行業,資料有著迅猛的增長,諸多的企業面臨著新的挑戰,資料分析的實時處理框架,比如說做一些實時資料分析報表、實時資料處理計算等。
和大多數企業類似,在此之前,我們是沒有實時計算這方面的經驗和積累的。這時,就開始困惑了,怎樣可以更好地做上面的需求,在成本和效果之間取得平衡,如何設計相關的架構?

窮則思變,在有了困惑以後,我們就開始準備梳理已有的條件和我們到底需要什麼。
我們的業務範圍主要在區塊鏈瀏覽器與資料服務、區塊鏈礦池、多幣種錢包等。在區塊鏈瀏覽器的業務裡,BTC.com 目前已是全球領先的區塊鏈資料服務平臺,礦池業務在業內排行第一,區塊鏈瀏覽器也是全球前三大瀏覽器之一。
首先,我們通過 parser 解析區塊鏈上的資料,得到各方面的資料資訊,可以分析出每個幣種的地址活躍度、地址交易情況、交易流向、參與程度等內容。目前,BTC.com 區塊鏈瀏覽器與行業內各大礦池和交易所等公司都有相關合作,可以更好地實現一些資料的統計、整理、歸納、輸出等。
面向的使用者,不僅有專業的區塊鏈開發人員,也有各樣的 B 端和 C 端使用者,C 端使用者可以進行區塊鏈地址的標註,智慧合約的執行,檢視智慧合約相關內容等,以及鏈上資料的檢索和檢視。B 端使用者則有更專業的支援和指導,提供 API、區塊鏈節點等一些的定製以及交易加速、鏈上的業務合作、資料定製等。
從資料量級來講,截至目前,比特幣大概有 5 億筆交易,3000 多萬地址,22 億輸出(output:每筆交易的輸出),並且還在不斷增長中。以太坊的話,則更多。而 BTC.com 的礦池和區塊鏈瀏覽器都支援多幣種,各幣種的總資料量級約為幾十 T。
礦池是礦工購買礦機裝置後連線到的服務平臺,礦工可以通過連線礦池從而獲取更穩定的收益。這是一個需要保證 7 * 24 小時穩定的服務,裡面有礦機不斷地提交其計算好的礦池下發的任務的解,礦池將達到網路難度的解進行廣播。這個過程也可以認為是近乎是實時的,礦機通過提交到伺服器,伺服器內部再提交到 Kafka 訊息佇列,同時有一些元件監聽這些訊息進行消費。而這些提交上來的解可以從中分析出礦機的工作狀態、算力、連線情況等。
在業務上,我們需要進行歷史資料和實時資料的計算。
歷史資料要關聯一些幣價,歷史交易資訊,而這些交易資訊需要一直儲存,是一種典型的批處理任務。
每當有新區塊的確認,就有一些資料可以得到處理和分析,比如某個地址在這個區塊裡發生了一筆交易,那麼可以從其交易流向去分析是什麼樣的交易,挖掘交易相關性。或者是在這個區塊裡有一些特殊的交易,比如 segwit 的交易、比如閃電網路的交易,就是有一些這個幣種特有的東西可以進行解析分析和統計。並且在新區塊確認時的難度預測也有所變化。
還有就是大額交易的監控,通過新區塊的確認和未確認交易,鎖定一些大額交易,結合地址的一些標註,鎖定交易流向,更好地進行資料分析。
還有是一些區塊鏈方面的 OLAP 方面的需求。

總結了在資料統計方面的需求和問題以後,我們就開始進行思考:什麼是最合適的架構,如何讓人員參與少、成本低?
解決問題,無非就是提出假設,通過度量,然後重新整理認知。
在瀏覽了一些資料以後,我們認為,大部分的計算框架都是通過輸入,進行處理,然後得到輸出。首先,我們要獲取到資料,這裡資料可以從 MySQL 也可以從 Kafka,然後進行計算,這裡計算可以是聚合,也可以是 TOP 5 型別的,在實時的話,可能還會有視窗型別的。在計算完之後,將結果做下發,下發到訊息渠道和儲存,傳送到微信或者釘釘,落地到 MySQL 等。
團隊一開始嘗試了 Spark,搭建了 Yarn,使用了 Airflow 作為排程框架,通過做 MySQL 的整合匯入,開發了一些批處理任務,有著離線任務的特點,資料固定、量大、計算週期長,需要做一些複雜操作。
在一些批處理任務上,這種架構是穩定的,但是隨著業務的發展,有了越來越多的實時的需求,並且實時的資料並不能保證按順序到達,按時間戳排序,訊息的時間欄位是允許前後有差距的。在資料模型上,需求驅動式的開發,成本相對來說,Spark 的方式對於當時來說較高,對於狀態的處理不是很好,導致影響一部分的效率。
其實在 2019 年的時候,就有在調研一些實時計算的事情,關注到了 Flink 框架,當時還是以 Java 為主,整體框架概念上和 Spark 不同,認為批處理是一種特殊的流,但是因為團隊沒有 Java 方面的基因和沉澱,使用 Flink 作為實時計算的架構,在當時就暫告一個段落。
在 2020 年初的時候,不管是 Flink 社群 還是 InfoQ,還是 B 站,都有在推廣 PyFlink,而且當時尤其是程鶴群[1]和孫金城[2]的視訊以及孫金城老師的部落格[3]的印象深刻。於是就想嘗試 PyFlink,其有著流批一體的優勢,而且還支援 Python 的一些函式,支援 pandas,甚至以後還可以支援 Tensorflow、Keras,這對我們的吸引力是巨大的。在之後,就在構思我們的在 PyFlink 上的流批一體的架構。
02 流批一體的架構
架構
首先我們要梳理資料,要清楚資料從哪裡來。在以 Spark 為主的時期,資料是定期從資料來源載入(增量)資料,通過一定的轉換邏輯,然後寫入目的地,由於資料量和業務需要,延遲通常在小時級別,而實時的話,需要儘可能短的延遲,因此將資料來源進行了分類,整體分成了幾部分,一部分是傳統的資料我們存放在 MySQL 持久化做儲存,這部分之後可以直接作為批處理的計算,也可以匯入 Hive,做進一步的計算。實時的部分,實際上是有很多思路,一種方式是通過 MySQL 的 Binlog 做解析,還有就是 MySQL 的 CDC 功能,在多方考量下,最後我們選擇了 Kafka,不僅是因為其是優秀的分散式流式平臺,而且團隊也有對其的技術沉澱。
並且實際上在本地開發的時候,安裝 Kafka 也比較方便,只需要 Brew Install Kafka,而且通過 Conduktor 客戶端,也可以方便的看到每個 Topic 的情況。於是就對現有的 Parser 進行改造,使其支援 Kafka,在當收到新的區塊時,會立即向 Kafka 傳送一個訊息,然後進行處理。
大概是在 2018 年的時候,團隊將整體的業務遷移到了 Kubernetes 上,在業務不斷髮展的過程中,其對開發和運維上來說,減輕了很多負擔,所以建議有一定規模的業務,最好是遷移到 Kubernetes,其對成本的優化,DevOps,以及高可用的支援,都是其他平臺和傳統方式無法比擬的。
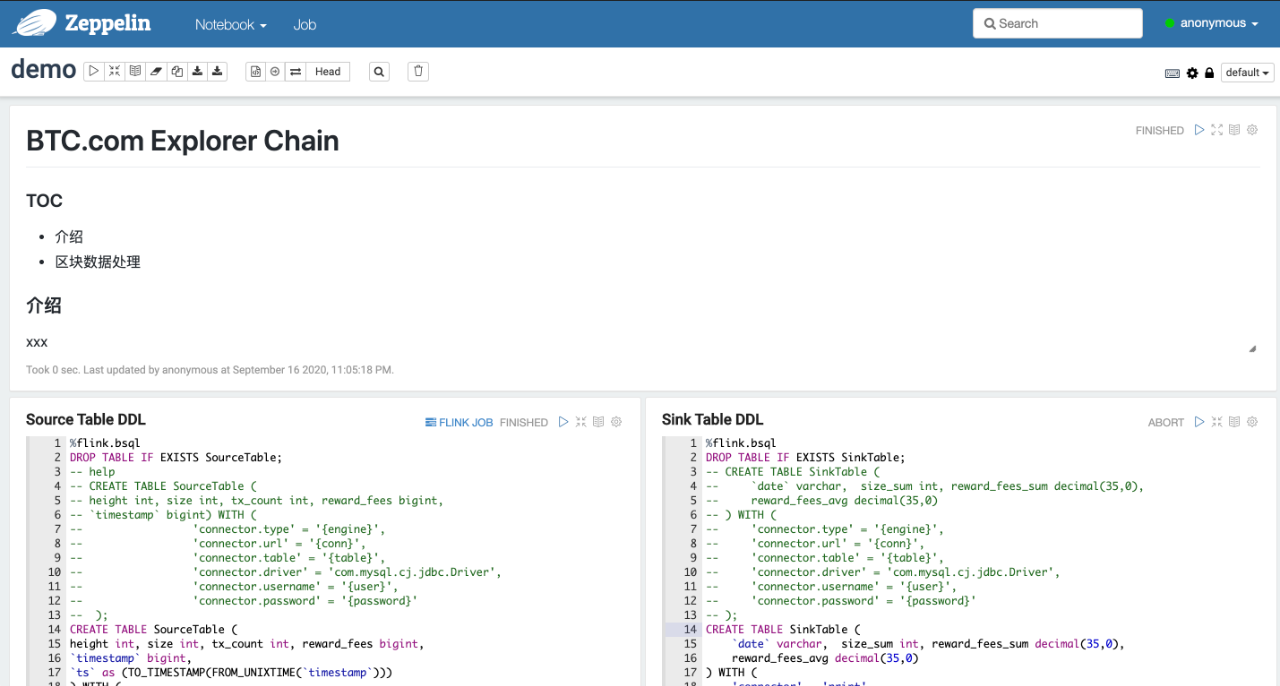
在開發作業的過程中,我們在儘可能的使用 Flink SQL,同時結合一些 Java、Python 的 UDF、UDAF、UDTF。每個作業通過初始化類似於以下的語句,形成一定的模式:
self.source_ddl = '''
CREATE TABLE SourceTable (xxx int) WITH
'''
self.sink_ddl = '''
CREATE TABLE SinkTable (xxx int) WITH
'''
self.transform_ddl = '''
INSERT INTO SinkTable
SELECT udf(xxx)
FROM SourceTable
GROUP BY FROM_UNIXTIME(`timestamp`, 'yyyyMMdd')
'''在未來的話,會針對性地將資料進行分層,按照業界通用的 ODS、DWD、DWS、ADS,分出原始層,明細層和彙總層,進一步做好資料的治理。
效果
最終我們團隊基於 PyFlink 開發快速地完成了已有的任務,部分是批處理作業,處理過去幾天的資料,部分是實時作業,根據 Kafka 的訊息進行消費,目前還算比較穩定。
部署時選擇了 Kubernetes,具體下面會進行分享。在 K8S 部署了 Jobmanager 和 Taskmanager,並且使用 Kubernetes 的 job 功能作為批處理作業的部署,之後考慮接入一些監控平臺,比如 Prometheus 之類的。
在成本方面,由於是使用的 Kubernetes 叢集,因此在機器上只有擴充套件主機的成本,在這種方式上,成本要比傳統的 Yarn 部署方式要低,並且之後 Kuberntes 會支援原生部署,在擴充套件 Jobmanager 和 Taskmanager 上面會更加方便。
03 Zeppelin、PyFlink on K8S 等實踐
Zeppelin 是我們用來進行資料探索和邏輯驗證,有些資料在本地不是真實資料,利用 Zeppelin 連線實際的鏈上資料,進行計算的邏輯驗證,當驗證完成後,便可轉換成生產需要的程式碼進行部署。
一、Kubernetes 上搭建 PyFlink 和 Zeppelin
1. 整理後的部署 Demo 在 github,可以參閱相關連結[4]。
2. 關於配置檔案,修改以下配置的作用。
(1). 修改 configmap 的 flink-conf.yaml 檔案的 taskmanager 配置。
taskmanager.numberOfTaskSlots: 10
調整 Taskmanager 可以調整執行的 job 的數量。
(2). 在 Zeppelin 的 dockerfile 中修改 zeppelin-site.xml 檔案。
cp conf/zeppelin-site.xml.template conf/zeppelin-site.xml; \
sed -i 's#<value>127.0.0.1</value>#<value>0.0.0.0</value>#g' conf/zeppelin-site.xml; \
sed -i 's#<value>auto</value>#<value>local</value>#g' conf/zeppelin-site.xml- 修改請求來源為 0.0.0.0,如果是線上環境,建議開啟白名單,加上 auth 認證。
- 修改 interpreter 的啟動模式為 local,auto 會導致在叢集啟動時,以 K8s 的模式啟動,目前 K8s 模式只支援 Spark,local 模式可以理解為,Zeppelin 將在本地啟動一個連線 Flink 的 interpreter 程序。
- Zeppelin 和在本地提交 Flink 作業類似,也需要 PyFlink 的基礎環境,所以需要將 Flink 對應版本的 jar 包放入映象內。
3. Zeppelin 的 ingress 中新增 websocket 配置。
nginx.ingress.kubernetes.io/configuration-snippet: |
proxy_set_header Upgrade "websocket";
proxy_set_header Connection "Upgrade";Zeppelin 在瀏覽器需要和 server 端建立 socket 連線,需要在 ingress 新增 websocket 配置。
4.Flink 和 Zeppelin 資料持久化的作用。
volumeMounts:
- mountPath: /zeppelin/notebook/
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: zeppelin-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: zeppelin-pvc
spec:
storageClassName: efs-sc
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi- 對 Flink 的 /opt/flink/lib 目錄做持久化的目的,是當我們需要新的 jar 包時,可以直接進入 Flink 的 pod 進行下載,並存放到 lib 目錄,保證 jobmanager 和 taskmanager 的 jar 版本一致,同時也無需更換映象。
- Zeppelin 的任務作業程式碼會存放在 /zeppelin/notebook/ 目錄下,目的是方便儲存編寫好的程式碼。
5. Flink 命令提交 job 作業的方式。
(1). 本地安裝 PyFlink,Python 需要3.5及以上版本。
$ pip3 install apache-flink==1.11.1
(2). 測試 Demo
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build()
)
sink_ddl = """
create table Results (word VARCHAR, `count` BIGINT) with ( 'connector' = 'print')
"""
t_env.sql_update(sink_ddl)
elements = [(word, 1) for word in content.split(" ")]
# 這裡也可以通過 Flink SQL
t_env.from_elements(elements, ["word", "count"]) \
.group_by("word") \
.select("word, count(1) as count") \
.insert_into("Results")
t_env.execute("word_count")
if __name__ == '__main__':
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")
word_count()或者是實時處理的 Demo:
def handle_kafka_message():
s_env = StreamExecutionEnvironment.get_execution_environment()
# s_env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
s_env.set_parallelism(1)
st_env = StreamTableEnvironment \
.create(s_env, environment_settings=EnvironmentSettings
.new_instance()
.in_streaming_mode()
.use_blink_planner().build())
source_ddl = '''
CREATE TABLE SourceTable (
word string
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'Topic',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.zookeeper.connect' = 'localhost:2121',
'format.type' = 'json',
'format.derive-schema' = 'true'
)
'''
sink_ddl = """
create table Results (word VARCHAR) with ('connector' = 'print')
"""
st_env.sql_update(sink_ddl)
st_env.sql_update(source_ddl)
st_env.from_path("source").insert_into("sink")
st_env.execute("KafkaTest")
if __name__ == '__main__':
handle_kafka_message()(3). 本地測試 Flink 命令提交 job 作業。
$ flink run -m localhost:8081 -py word_count.py
python/table/batch/word_count.py
Job has been submitted with JobID 0a31b61c2f974bcc3f344f57829fc5d5
Program execution finished
Job with JobID 0a31b61c2f974bcc3f344f57829fc5d5 has finished.
Job Runtime: 741 ms(4). 如果存在多個 Python 檔案,可以先 zip 打包後再進行提交作業。
$ zip -r flinkdemo.zip ./*
$ flink run -m localhost:8081 -pyfs flinkdemo.zip -pym main(5). Kubernetes 通過叢集的 CronJob 定時排程來提交 Job,之後會做自研一些 UI 後臺介面做作業管理與監控。
04 在區塊鏈領域實踐
隨著區塊鏈技術的越來越成熟,應用越來越多,行業標準化、規範化的趨勢也開始顯現,也越來越依賴於雲端計算、大資料,畢竟是數字經濟的產物。BTC.com 也在紮根於區塊鏈技術基礎設施,為各類公司各類應用提供資料和業務上的支援。
近些年,有個詞火遍了 IT 業界,中臺,不管是大公司還是創業公司,都喜歡扯上這個概念,號稱自己業務中臺,資料中臺等。我們的理解中,中臺是一種整合各方面資源的能力,從傳統的單兵作戰,到提升武器裝備後勤保障,提升作戰能力。在資料上打破資料孤島,在需求快速變化的前臺和日趨穩定的後臺中取得平衡。而中臺更重要的是服務,最終還是要回饋到客戶,回饋到合作伙伴。
在區塊鏈領域,BTC.com 有著深厚的行業技術積累,可以提供各方面資料化的能力。比如在利用機器學習進行鏈上資料的預估,預估 eth 的 gas price,還有最佳手續費等,利用 keras 深度學習的能力,進行一些迴歸計算,在之後也會將 Flink、機器學習和區塊鏈結合起來,對外提供更多預測類和規範化分類的資料樣本,之前是在用定時任務不斷訓練模型,與 Flink 結合之後,會更加實時。在這方面,以後也會提供更多的課題,比如幣價與 Defi,輿情,市場等的關係,區塊鏈地址與交易的標註和分類。甚至於將機器學習訓練的模型,放於 IPFS 網路中,通過去中心化的代幣進行訓練,提供方便呼叫樣本和模型的能力。
在目前,BTC.com 推出了一些通過資料探勘實現的能力,包括交易推送、OLAP 鏈上分析報表等,改善和提升相關行業和開發者實際的體驗。我們在各種鏈上都有監控節點,監控各區塊鏈網路的可用性、去中心化程度,監控智慧合約。在接入一些聯盟鏈、隱私加密貨幣,可以為聯盟鏈、隱私加密貨幣提供這方面的資料能力。
BTC.com 將為區塊鏈產業生態發展做出更多努力,以科技公司的本質,以技術發展為第一驅動力,以市場和客戶為導向,開發創新和融合應用,做好基礎設施。
05 展望與總結
從實時計算的趨勢,到流批一體的架構,通過對 PyFlink 和 Flink 的學習,穩定在線上運行了多種作業任務,對接了實際業務需求。並且搭建了 Zeppelin 平臺,使得業務開發上更加方便。在計算上儘可能地依賴 SQL,方便各方面的整合與除錯。
在社群方面,PyFlink 也是沒有令我們失望的,較快的響應能力,不斷完善的文件。在 Confluence[5]上也可以看到一些 Flink Improvement Proposals,其中也有一些是 PyFlink 相關的,在不遠的將來,還會支援 Pandas UDAF,DataStream API,ML API,也期望在之後可以支援 Joblistener,總之,在這裡也非常感謝相關團隊。
未來的展望,總結起來就是,通過業務實現資料的價值化。而資料中臺的終局,是將資料變現。
原文連結
本文為阿里雲原創內容,未經允許不得轉載。
- 15M安裝包就能玩《原神》,帶你瞭解雲遊戲背後的技術祕密
- 主流定時任務解決方案全橫評
- 面向中後臺複雜場景的低程式碼實踐思路
- PolarDB-X 全域性二級索引
- 微服務治理熱門技術揭祕:無損上線
- 「技術人生」第9篇:如何設定業務目標
- 資料庫治理的探索與實踐
- 一個開發者自述:我是如何設計針對冷熱讀寫場景的 RocketMQ 儲存系統
- 全鏈路壓測:影子庫與影子表之爭
- 阿里雲中間件開源往事
- 阿里雲易立:雲原生如何破解企業降本提效難題?
- 雲原生混部最後一道防線:節點水位線設計
- 照妖鏡:一個工具的自我超越
- 將 Terraform 生態粘合到 Kubernetes 世界
- EventBridge 在 SaaS 企業整合領域的探索與實踐
- 全鏈路壓測:影子庫與影子表之爭
- 當 Knative 遇見 WebAssembly
- 【USENIX ATC】支援異構GPU叢集的超大規模模型的高效的分散式訓練框架Whale
- 千萬級可觀測資料採集器--iLogtail程式碼完整開源
- 設計穩定的微服務系統時不得不考慮的場景