何為神經網路卷積層?
摘要:本文深度講解了卷積計算的原理,並詳細介紹了構成所有卷積網路主幹的基本元素,包括卷積層本身、填充和步幅的基本細節、用於在相鄰區域匯聚資訊的匯聚層,最後給出卷積層和匯聚層的程式碼示例和CNN框架結構圖。
本文分享自華為雲社群《神經網路基礎部件-卷積層詳解》,作者: 嵌入式視覺 。
前言
在全連線層構成的多層感知機網路中,我們要通過將影象資料展平成一維向量來送入模型,但這會忽略了每個影象的空間結構資訊。理想的策略應該是要利用相近畫素之間的相互關聯性,將影象資料二維矩陣送給模型中學習。
卷積神經網路(convolutional neural network,CNN)正是一類強大的、專為處理影象資料(多維矩陣)而設計的神經網路,CNN 的設計是深度學習中的一個里程碑式的技術。在 Transformer 應用到 CV 領域之前,基於卷積神經網路架構的模型在計算機視覺領域中占主導地位,幾乎所有的影象識別、目標檢測、語義分割、3D目標檢測、視訊理解等任務都是以 CNN 方法為基礎。
卷積神經網路核心網路層是卷積層,其使用了卷積(convolution)這種數學運算,卷積是一種特殊的線性運算。另外,通常來說,卷積神經網路中用到的卷積運算和其他領域(例如工程領域以及純數學領域)中的定義並不完全一致。
一,卷積
在理解卷積層之前,我們首先得理解什麼是卷積操作。
卷積與傅立葉變換有著密切的關係。例如兩函式的傅立葉變換的乘積等於它們卷積後的傅立葉變換,利用此一性質,能簡化傅立葉分析中的許多問題。
operation 視語境有時譯作“操作”,有時譯作“運算”,本文不做區分。
1.1,卷積運算定義
為了給出卷積的定義, 這裡從現實世界會用到函式的例子出發。
假設我們正在用鐳射感測器追蹤一艘宇宙飛船的位置。我們的鐳射感測器給出 一個單獨的輸出 x(t)x(t),表示宇宙飛船在時刻 tt 的位置。xx 和 tt 都是實值的,這意味著我們可以在任意時刻從感測器中讀出飛船的位置。
現在假設我們的感測器受到一定程度的噪聲干擾。為了得到飛船位置的低噪聲估計,我們對得到的測量結果進行平均。顯然,時間上越近的測量結果越相關,所 以我們採用一種加權平均的方法,對於最近的測量結果賦予更高的權重。我們可以採用一個加權函式 w(a)w(a) 來實現,其中 aa 表示測量結果距當前時刻的時間間隔。如果我們對任意時刻都採用這種加權平均的操作,就得到了一個新的對於飛船位置的平滑估計函式 s :
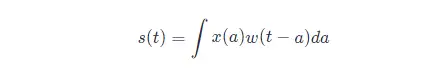
這種運算就叫做卷積(convolution)。更一般的,卷積運算的數學公式定義如下:
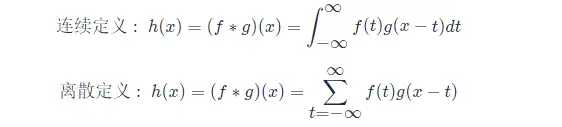
以上卷積計算公式可以這樣理解:
- 先對函式 g(t) 進行反轉(reverse),相當於在數軸上把 g(t) 函式從右邊褶到左邊去,也就是卷積的“卷”的由來。
- 然後再把 g(t) 函式向左平移 x 個單位,在這個位置對兩個函式的對應點相乘,然後相加,這個過程是卷積的“積”的過程。
1.2,卷積的意義
對卷積這個名詞,可以這樣理解:所謂兩個函式的卷積(f∗g),本質上就是先將一個函式翻轉,然後進行滑動疊加。在連續情況下,疊加指的是對兩個函式的乘積求積分,在離散情況下就是加權求和,為簡單起見就統一稱為疊加。
因此,卷積運算整體來看就是這麼一個過程:
翻轉—>滑動—>疊加—>滑動—>疊加—>滑動—>疊加…
多次滑動得到的一系列疊加值,構成了卷積函式。
這裡多次滑動過程對應的是 t 的變化過程。
那麼,卷積的意義是什麼呢?可以從卷積的典型應用場景-影象處理來理解:
- 為什麼要進行“卷”?進行“卷”(翻轉)的目的其實是施加一種約束,它指定了在“積”的時候以什麼為參照。在空間分析的場景,它指定了在哪個位置的周邊進行累積處理。
- 在影象處理的中,卷積處理的結果,其實就是把每個畫素周邊的,甚至是整個影象的畫素都考慮進來,對當前畫素進行某種加權處理。因此,“積”是全域性概念,或者說是一種“混合”,把兩個函式進行時間(訊號分析)或空間(影象處理)上進行混合。
1.3,從例項理解卷積
一維卷積的例項有 “丟骰子” 等經典例項,這裡不做展開描述,本文從二維卷積用於影象處理的例項來理解。
一般,數字影象可以表示為如下所示矩陣:
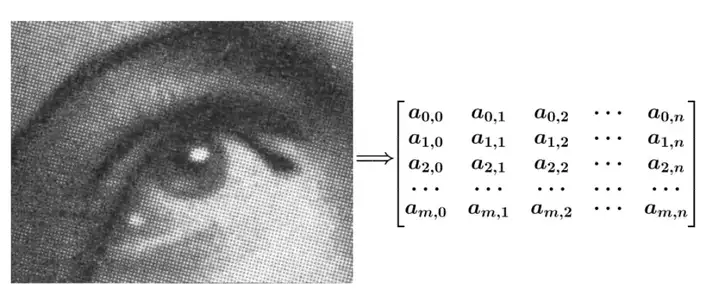
而卷積核 g 也可以用一個矩陣來表示,如:

按照卷積公式的定義,則目標圖片的第(u,v) 個畫素的二維卷積值為:
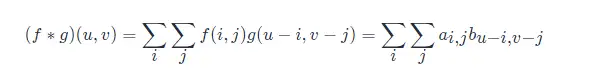
展開來分析二維卷積計算過程就是,首先得到原始影象矩陣中 (u,v) 處的矩陣:
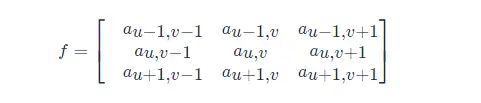
然後將影象處理矩陣翻轉(兩種方法,結果等效),如先沿 x 軸翻轉,再沿 y 軸翻轉(相當於將矩陣 g 旋轉 180 度):
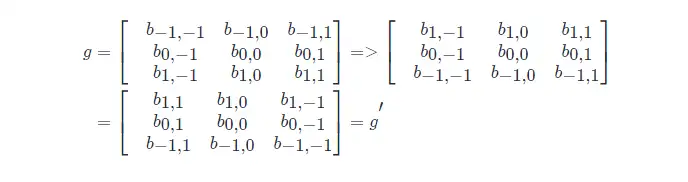
最後,計算卷積時,就可以用 f 和 g′ 的內積:
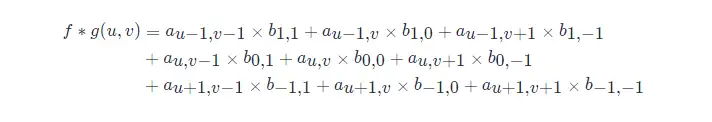
計算過程視覺化如下動圖所示,注意動圖給出的是 gg 不是 g′g′。

以上公式有一個特點,做乘法的兩個對應變數 a,b 的下標之和都是 (u,v),其目的是對這種加權求和進行一種約束,這也是要將矩陣 g 進行翻轉的原因。上述計算比較麻煩,實際計算的時候,都是用翻轉以後的矩陣,直接求矩陣內積就可以了。
1.4,影象卷積(二維卷積)
在機器學習和影象處理領域,卷積的主要功能是在一個影象(或某種特徵) 上滑動一個卷積核(即濾波器),通過卷積操作得到一組新的特徵。一幅影象在經過卷積操作後得到結果稱為特徵對映(Feature Map)。如果把影象矩陣簡寫為 II,把卷積核 Kernal 簡寫為 KK,則目標圖片的第 (i,j) 個畫素的卷積值為:
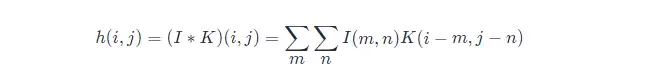
可以看出,這和一維情況下的卷積公式 2 是一致的。因為卷積的可交換性,我們也可以把公式 3 等價地寫作:
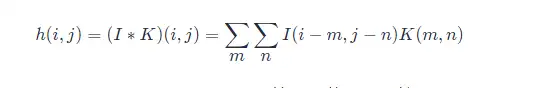
通常,下面的公式在機器學習庫中實現更為簡單,因為 m 和 n 的有效取值範圍相對較小。
卷積運算可交換性的出現是因為我們將核相對輸入進行了翻轉(flip),從 m 增 大的角度來看,輸入的索引在增大,但是卷積核的索引在減小。我們將卷積核翻轉的唯一目 的是實現可交換性。儘管可交換性在證明時很有用,但在神經網路的應用中卻不是一個重要的性質。相反,許多神經網路庫會實現一個互相關函式(corresponding function),它與卷積相同但沒有翻轉核:
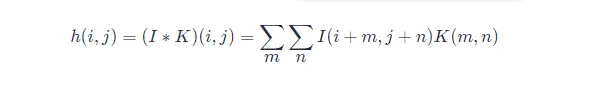
互相關函式的運算,是兩個序列滑動相乘,兩個序列都不翻轉。卷積運算也是滑動相乘,但是其中一個序列需要先翻轉,再相乘。
1.5,互相關和卷積
互相關和卷積運算的關係,可以通過下述公式理解:
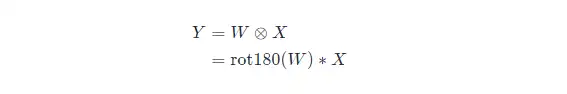
其中⊗ 表示互相關運算,∗ 表示卷積運算, rot180(⋅) 表示旋轉 180 度,Y 為輸出矩陣。從上式可以看出,互相關和卷積的區別僅僅在於卷積核是否進行翻轉。因此互相關也可以稱為不翻轉卷積.
離散卷積可以看作矩陣的乘法,然而,這個矩陣的一些元素被限制為必須和另外一些元素相等。
在神經網路中使用卷積是為了進行特徵抽取,卷積核是否進行翻轉和其特徵抽取的能力無關(特別是當卷積核是可學習的引數時),因此卷積和互相關在能力上是等價的。事實上,很多深度學習工具中卷積操作其實都是互相關操作,用來減少一些不必要的操作或開銷(不反轉 Kernal)。
總的來說,
- 我們實現的卷積操作不是原始數學含義的卷積,而是工程上的卷積,但一般也簡稱為卷積。
- 在實現卷積操作時,並不會反轉卷積核。
二,卷積層
在傳統影象處理中,線性空間濾波的原理實質上是指指影象 ff 與濾波器核 ww 進行乘積之和(卷積)運算。核是一個矩陣,其大小定義了運算的鄰域,其係數決定了該濾波器(也稱模板、視窗濾波器)的性質,並通過設計不同核係數(卷積核)來實現低通濾波(平滑)和高通濾波(銳化)功能,因此我們可以認為卷積是利用某些設計好的引數組合(卷積核)去提取影象空域上相鄰的資訊。
2.1,卷積層定義
在全連線前饋神經網路中,如果第 l 層有 Ml 個神經元,第 l−1 層有 Ml−1 個 神經元,連線邊有 Ml×Ml−1 個,也就是權重矩陣有Ml×Ml−1 個引數。當 Ml 和 Ml−1 都很大時,權重矩陣的引數就會非常多,訓練的效率也會非常低。
如果採用卷積來代替全連線,第 l 層的淨輸入 z(l) 為第 l−1 層啟用值 a(l−1)和濾波器w(l)∈RK 的卷積,即
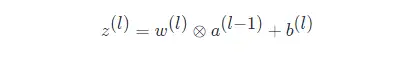
其中 b(l)∈R 為可學習的偏置。
上述卷積層公式也可以寫成這樣的形式: Z=W∗A+b
根據卷積層的定義,卷積層有兩個很重要的性質:
2.1.1,區域性連線
區域性連線:在卷積層(假設是第 ll 層)中的每一個神經元都只和下一層(第 l−1l−1 層)中某個區域性視窗內的神經元相連,構成一個區域性連線網路。其實可能表達為稀疏互動更直觀點,傳統的網路層是全連線的,使用矩陣乘法來建立輸入與輸出的連線關係。矩陣的每個引數都是獨立的,它描述了每個輸入單元與輸出單元的互動。這意味著每個輸出單元與所有的輸入單元都產生關聯。而卷積層通過使用卷積核矩陣來實現稀疏互動(也稱作稀疏連線,或者稀疏權重),每個輸出單元僅僅與特定的輸入神經元(其實是指定通道的 feature map)產生關聯。
下圖顯示了全連線層和卷積層的每個輸入單元影響的輸出單元比較:
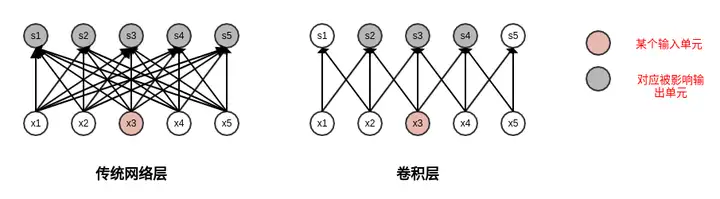
- 對於傳統全連線層,每個輸入單元影響了所有的輸出單元。
- 對於卷積層,每個輸入單元隻影響了3個輸出單元(核尺寸為3時)。
2.1.2,權重共享
權重共享:卷積層中,同一個核會在輸入的不同區域做卷積運算。全連線層和卷積層的權重引數比較如下圖:
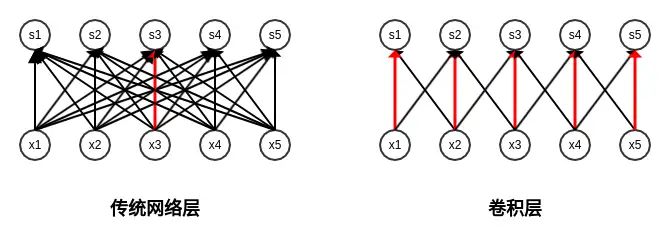
- 對於傳統全連線層: x3→s3x3→s3 的權重 w3,3w3,3 只使用了一次 。
- 對於卷積層: x3→s3x3→s3 的權重 w3,3w3,3 被共享到 xi→si,i=12,4,5xi→si,i=12,4,5。
全連線層和卷積層的視覺化對比如下圖所示:
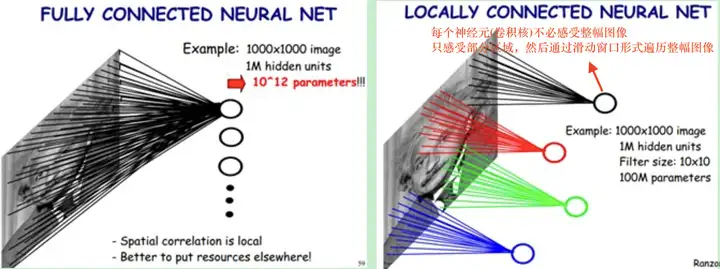
總結:一個濾波器(3維卷積核)只捕捉輸入資料中的一種特定的區域性特徵。為了提高卷積網路的表示能力,可以在每一層使用多個不同的特徵對映,即增加濾波器的數量,以更好地提取影象的特徵。
2.2,卷積層理解
前面章節內容中,卷積的輸出形狀只取決於輸入形狀和卷積核的形狀。而神經網路中的卷積層,在卷積的標準定義基礎上,還引入了卷積核的滑動步長和零填充來增加捲積的多樣性,從而可以更靈活地進行特徵抽取。
- 步長(Stride):指卷積核每次滑動的距離
- 零填充(Zero Padding):在輸入影象的邊界填充元素(通常填充元素是0)
卷積層定義:每個卷積核(Kernel)在輸入矩陣上滑動,並通過下述過程實現卷積計算:
- 在來自卷積核的元素和輸入特徵圖子矩陣的元素之間進行乘法以獲得輸出感受野。
- 然後將相乘的值與新增的偏差相加以獲得輸出矩陣中的值。
卷積層數值計算過程視覺化如下圖 1 所示:
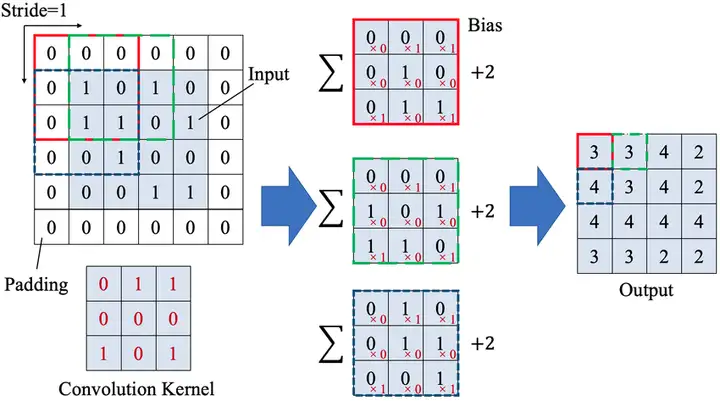
圖片來源論文 Improvement of Damage Segmentation Based on Pixel-Level Data Balance Using VGG-Unet。
注意,卷積層的輸出 Feature map 的大小取決於輸入的大小、Pad 數、卷積核大小和步長。在 Pytorch 框架中,圖片(feature map)經卷積 Conv2D 後輸出大小計算公式如下:
其中 ⌊⌋⌊⌋ 是向下取整符號,用於結果不是整數時進行向下取整(Pytorch 的 Conv2d 卷積函式的預設引數 ceil_mode = False,即預設向下取整, dilation = 1),其他符號解釋如下:
- 輸入圖片大小 W×W(預設輸入尺寸為正方形)
- Filter 大小 F×F
- 步長 S
- padding的畫素數 P
- 輸出特徵圖大小 N×N
上圖1側重於解釋數值計算過程,而下圖2則側重於解釋卷積層的五個核心概念的關係:
- 輸入 Input Channel
- 卷積核組 WeightsBias
- 過濾器 Filter
- 卷積核 kernal
- 輸出 Feature Map
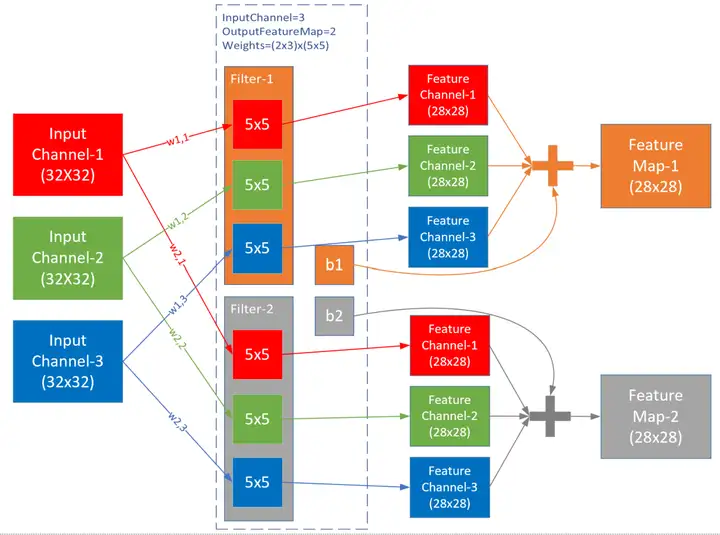
上圖是三通道經過兩組過濾器的卷積過程,在這個例子中,輸入是三維資料 3×32×323×32×32,經過權重引數尺寸為 2×3×5×52×3×5×5 的卷積層後,輸出為三維 2×28×282×28×28,維數並沒有變化,只是每一維內部的尺寸有了變化,一般都是要向更小的尺寸變化,以便於簡化計算。
假設三維卷積(也叫濾波器)尺寸為 (cin,k,k)(cin,k,k),一共有 coutcout 個濾波器,即卷積層引數尺寸為 (cout,cin,k,k)(cout,cin,k,k) ,則標準卷積層有以下特點:
- 輸出的 feature map 的數量等於濾波器數量 coutcout,即卷積層引數值確定後,feature map 的數量也確定,而不是根據前向計算自動計算出來;
- 對於每個輸出,都有一個對應的過濾器 Filter,圖例中 Feature Map-1 對應 Filter-1;
- 每個 Filter 內都有一個或多個卷積核 Kernal,對應每個輸入通道(Input Channel),圖例為 3,對應輸入的紅綠藍三個通道;
- 每個 Filter 只有一個 Bias 值,圖例中 Filter-1 對應 b1;
- 卷積核 Kernal 的大小一般是奇數如:1×11×1,3×33×3。
注意,以上內容都描述的是標準卷積,隨著技術的發展,後續陸續提出了分組卷積、深度可分離卷積、空洞卷積等。詳情可參考我之前的文章-MobileNetv1論文詳解。
2.3,卷積層 api
Pytorch 框架中對應的卷積層 api 如下:
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)主要引數解釋:
- in_channels(int) – 輸入訊號的通道。
- out_channels(int) – 卷積產生的通道。
- kerner_size(int or tuple) - 卷積核的尺寸。
- stride(int or tuple, optional) - 卷積步長,預設值為 1 。
- padding(int or tuple, optional) - 輸入的每一條邊補充 0 的層數,預設不填充。
- dilation(int or tuple, optional) – 卷積核元素之間的間距,預設取值 1 。
- groups(int, optional) – 從輸入通道到輸出通道的阻塞連線數。
- bias(bool, optional) - 如果 bias=True,新增偏置。
示例程式碼:
###### Pytorch卷積層輸出大小驗證
import torch
import torch.nn as nn
import torch.autograd as autograd
# With square kernels and equal stride
# output_shape: height = (50-3)/2+1 = 24.5,卷積向下取整,所以 height=24.
m = nn.Conv2d(16, 33, 3, stride=2)
# # non-square kernels and unequal stride and with padding
# m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2)) # 輸出shape: torch.Size([20, 33, 28, 100])
# # non-square kernels and unequal stride and with padding and dilation
# m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1)) # 輸出shape: torch.Size([20, 33, 26, 100])
input = autograd.Variable(torch.randn(20, 16, 50, 100))
output = m(input)
print(output.shape) # 輸出shape: torch.Size([20, 16, 24, 49])三,卷積神經網路
卷積神經網路一般由卷積層、匯聚層和全連線層構成。
3.1,匯聚層
通常當我們處理影象時,我們希望逐漸降低隱藏表示的空間解析度、聚集資訊,這樣隨著我們在神經網路中層疊的上升,每個神經元對其敏感的感受野(輸入)就越大。
匯聚層(Pooling Layer)也叫子取樣層(Subsampling Layer),其作用不僅是進降低卷積層對位置的敏感性,同時降低對空間降取樣表示的敏感性。
與卷積層類似,匯聚層運算子由一個固定形狀的視窗組成,該視窗根據其步幅大小在輸入的所有區域上滑動,為固定形狀視窗(有時稱為匯聚視窗)遍歷的每個位置計算一個輸出。然而,不同於卷積層中的輸入與卷積核之間的互相關計算,匯聚層不包含引數。相反,池運算是確定性的,我們通常計算匯聚視窗中所有元素的最大值或平均值。這些操作分別稱為最大匯聚層(maximum pooling)和平均匯聚層(average pooling)。
在這兩種情況下,與互相關運算子一樣,匯聚視窗從輸入張量的左上⻆開始,從左往右、從上往下的在輸入張量內滑動。在匯聚視窗到達的每個位置,它計算該視窗中輸入子張量的最大值或平均值。計算最大值或平均值是取決於使用了最大匯聚層還是平均匯聚層。
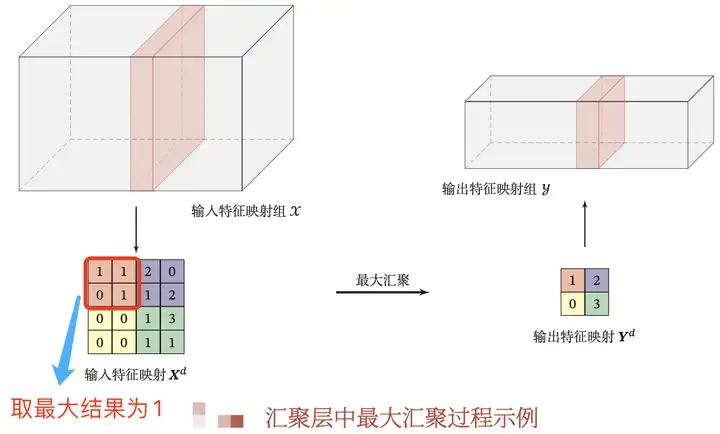
值得注意的是,與卷積層一樣,匯聚層也可以通過改變填充和步幅以獲得所需的輸出形狀。
3.2.,匯聚層 api
Pytorch 框架中對應的聚合層 api 如下:
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)主要引數解釋:
- kernel_size(int or tuple):max pooling 的視窗大小。
- stride(int or tuple, optional):max pooling的視窗移動的步長。預設值是kernel_size`。
- padding(int or tuple, optional):預設值為 0,即不填充畫素。輸入的每一條邊補充 0 的層數。
- dilation:滑動窗中各元素之間的距離。
- ceil_mode:預設值為 False,即上述公式預設向下取整,如果設為 True,計算輸出訊號大小的時候,公式會使用向上取整。
Pytorch 中池化層預設ceil mode = false,而 Caffe 只實現了 ceil mode= true 的計算方式。
示例程式碼:
import torch
import torch.nn as nn
import torch.autograd as autograd
# 大小為3,步幅為2的正方形視窗池
m = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# pool of non-square window
input = autograd.Variable(torch.randn(20, 16, 50, 32))
output = m(input)
print(output.shape) # torch.Size([20, 16, 25, 16])四,卷積神經網路結構
一個典型的卷積網路結構是由卷積層、匯聚層、全連線層交叉堆疊而成。如下圖所示:
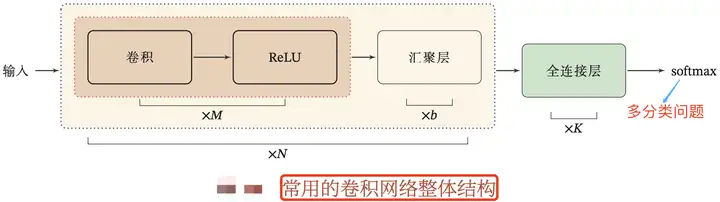
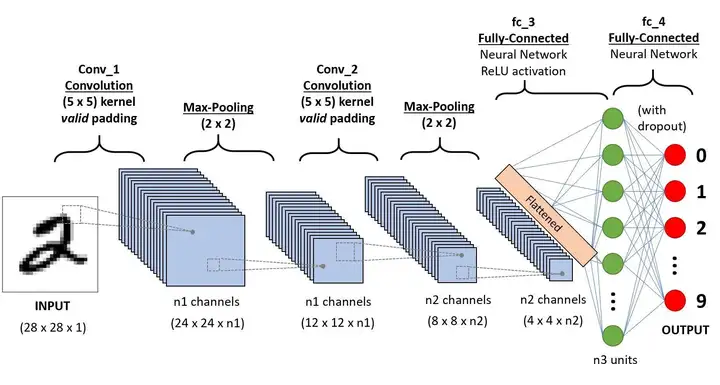
一個簡單的 CNN 網路連線圖如下所示。
經典 CNN 網路的總結,可參考我之前寫的文章-經典 backbone 網路總結。
目前,卷積網路的整體結構趨向於使用更小的卷積核(比如 1×11×1 和 3×33×3) 以及更深的結構(比如層數大於 50)。另外,由於卷積層的操作性越來越靈活(同樣可完成減少特徵圖解析度),匯聚層的作用越來越小,因此目前的卷積神經網路逐漸趨向於全卷積網路。
另外,可通過這個網站視覺化 cnn 的全部過程。
參考資料
- AI EDU-17.3 卷積的反向傳播原理
- Visualizing the Feature Maps and Filters by Convolutional Neural Networks
- 《神經網路與深度學習》-第5章
- 《動手學深度學習》-第6章
- http://www.zhihu.com/question/22298352
- 卷積神經網路
- 使用卷積神經網路實現圖片去摩爾紋
- 核心不中斷前提下,Gaussdb(DWS)記憶體報錯排查方法
- 簡述幾種常用的排序演算法
- 自動調優工具AOE,讓你的模型在昇騰平臺上高效執行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及程式碼實現
- CosineWarmup理論與程式碼實戰
- 淺談DWS函數出參方式
- 程式碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種資料預處理的方式:AIPP和DVPP
- 詳解ResNet 網路,如何讓網路變得更“深”了
- 帶你掌握如何檢視並讀懂昇騰平臺的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網路卷積層?
- 在昇騰平臺上對TensorFlow網路進行效能調優
- 介紹3種ssh遠端連線的方式
- 分散式資料庫架構路線大揭祕
- DBA必備的Mysql知識點:資料型別和運算子
- 5個高併發導致數倉資源類報錯分析