概率--概率密度函式詳解
概率領域基本概念
概率研究的問題是,已知一個模型和引數,怎麼去預測這個模型產生的結果的特性(例如均值,方差,協方差等等)。 舉個例子,我想研究怎麼養豬(模型是豬),我選好了想養的品種、餵養方式、豬棚的設計等等(選擇引數),我想知道我養出來的豬大概能有多肥,肉質怎麼樣(預測結果)。
離散型變數和連續型變數
進入主題前,先明確幾個概念: 離散型變數(或取值個數有限的變數):取值可一一列舉,且總數是確定的,如投骰子出現的點數(1點、2點、3點、4點、5點、6點)。 連續型變數(或取值個數無限的變數):取值無法一一列舉,且總數是不確定的,如所有的自然數(0、1、2、3……)。
離散型變數取某個值xi的概率P(xi)是個確定的值,即P(xi)≠0:例如,投一次骰子出現2點的概率是P(2)=1/6。
連續型變數取某個值xi的概率P(xi)=0:對於連續型變數而言,“取某個具體值的概率”的說法是無意義的,因為取任何單個值的概率都等於0,**只能說“取值落在某個區間內的概率”,或“取值落在某個值鄰域內的概率”,即只能說P(a<xi≤b),而不能說P(xi)。**為什麼是這樣?且看下例:例如,從所有自然數中任取一個數,問這個數等於5的概率是多少?從所有的自然數中取一個,當然是有可能取到5的,但是自然數有無窮多個,因此取到5的概率是1/∞,也就是0。
離散型變數
概率分佈
概率分佈:顧名思義,就是概率的分佈,還是講的"概率",不過側重點在於"分佈"。給出了所有取值及其對應的概率(少一個也不行),只對離散型變數有意義。描述離散型隨機變數的概率分佈的工具是概率分佈表,如下:

概率分佈,其實嚴格意義來說,應該叫做"離散型隨機變數的值分佈和概率分佈". 名字雖長了一點,但有利於我們更好的理解。
概率函式
概率函式:顧名思義,用函式的形式來表達概率,一次只能代表一個隨機變數的取值。函式表達: $$ p_{i}=P\left{X=x_{i}\right} \quad(i=1,2,3, \cdots) $$
概率分佈函式F(x)
概率分佈函式F(x):給出取值小於某個值的概率,是概率的累加形式,所以也叫也叫做累積概率函式。
·對於離散型變數: $$ F(x_i)=p(X<x_i)=\sum_{x_{k} < x_i} p_{k} $$
連續型變數
概率分佈和概率函式只對離散型變數有意義,那如何描述連續型變數呢?
答案就是“概率分佈函式F(x)”和“概率密度函式f(x)”,當然這兩者也是可以描述離散型變數的。
概率分佈函式F(x)
概率分佈函式F(x):給出取值小於某個值的概率,是概率的累加形式,所以也叫也叫做累積概率函式。
·對於離散型變數: $$ F(x_i)=p(X<x_i)=\sum_{x_{k} < x_i} p_{k} $$ ·對於連續型變數,採用求積分的方式: $$ F(x_i)=P(X < x_i)=\int_{-\infty}^{x_i} f(x) dx $$
概率分佈函式F(x)的作用:
(1)給出x落在某區間(a,b]內的概率: $$ P(a<X \leq b)=F(b)-F(a)=\int_{a}^{b} f(x) d x $$ (2)根據F(x)的斜率,即概率密度函式f(x)判斷“區間概率”P(a<x≤b)(x落在(a,b]中的概率)。某區間(a,b]內,F(x)越傾斜,表示x落在該區間內的概率P(a<x≤b) 越大。
概率密度函式f(x):
離散變數的概率函式在連續型變數中就對應為概率密度函式,概率密度函式是分佈函式的導函式。給出了變數落在$x_i$鄰域內(或者某個區間內)的概率變化快慢,概率密度函式的值不是概率,而是概率的變化率,概率密度函式下面的面積才是概率。

注意: 概率密度函式f(x)在點a處取值,不是事件{X=a} 的概率。但是,該值越大,X在a點附近取值的概率越大.
物理含義:就是x落在a點附近的無窮小鄰域內的概率,用數學語言描述就是: $$ f(a)=F^{\prime}(a)=P(a-\delta x<x \leq a+\delta x)_{\delta x \rightarrow 0} \neq P(a) $$
連續型變數的概率、概率分佈函式、概率密度函式之間的關係
最常見的連續型概率分佈是正態分佈,也稱為高斯分佈。它的概率密度函式為: $$ f(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}} $$ 
x落在u附近的概率最大,而F(x)是概率的累加和,因此在u附近F(x)的遞增變化最快,即F(x)曲線在(u,F(u))這一點的切線的斜率最大,這個斜率就等於f(u)。x落在a和b之間的概率為F(b)-F(a)(圖中的紅色小線段),而在概率密度曲線中則是f(x)與ab圍成的面積S。
常見概率分佈
離散分佈
- 離散均勻分佈: $X \sim U{1,2, \ldots, n}$
表示X在一次隨機事件中可以取值1到n,並且每一個取值的概率相等,因此概率密度函式為 $f(k)=P(X=k)=\frac{1}{n}$ 。常見的拋擲色子等事件都服從該分佈。
- 伯努利分佈: $X \sim B(p)=B(1, p)$
在一次伯努利實驗中,X的取值只有1(成功)或者0(失敗)兩種情況,成功的概率為p。
或者表述為事件A發生或不發生,A發生的概率為p,即概率密度函式為$f(x;p)=px(1−p)^{1−x}\quad for, x∈{0,1}$。例如商店下一位顧客的性別服從該分佈。
- 二項分佈: $X \sim B(n,p)$
二項分佈可以看作是重複n次獨立伯努利實驗,得到成功X次的概率,單次伯努利實驗成功的概率為p。
另外一種解釋是有放回的抽樣。比如,籃子裡有N個球,只有紅色和白色,其中p為紅球的佔比),進行n次有放回的抽取,n次抽取後抽到X個紅球的概率服從二項分佈。概率函式為:$f(k;p)=P(X=k)=\left(\begin{array}{c}n \ k\end{array}\right) p^{k}(1-p)^{n-k}$
連續分佈
- 均勻分佈: $X \sim U{a,b}$
在區間a到b上,任意一個點出現的概率相同,和離散均勻分佈不同的是,區間a到b上可以取任何值。比如把區間換成面積,在飛鏢投擲的遊戲中,假設飛鏢不會脫靶,則投擲飛鏢到一塊區域的概率服從均勻分佈。其概率密度函式為:$f(x)= \begin{cases}\frac{1}{b-a} & a \leq x \leq b \ 0 & x<a, x>b\end{cases}$
- 指數分佈: $X \sim \operatorname{Exp}(\lambda)(\lambda>0)$
指數分佈的概率密度函式為 $f(x)=\lambda e^{-\lambda x}$ ,只有一個引數λ,其形狀為一條遞減的曲線,λ越大,曲線越陡峭,如下圖所示。

- 正態分佈: $X \sim N(\mu,\sigma)$
正態分佈在生活中無處不在,人們的身高體重,智力水平都服從或者說近似服從正態分佈。其概率密度函式為:$f(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}$
正態分佈的神奇之處在於,所有分佈在一定情況下都收斂於正態分佈。也就是我們說的中心極限定理:假設 $X_1,...X_n$ 是獨立同分布(independent and identically distributed),那麼他們的和或者均值服從近似正態分佈,並且隨著n越來越大,越接近正態分佈。中心極限定理也可以用公式來表示:$\sum_{i=1}^{n} X_{i} \approx N\left(n \mu, n \sigma^{2}\right)$
未整理
置信區間詳解
置信區間,提供了一種區間估計的方法。
下面採用 置信區間來構造區間估計
按照 置信區間構造出來的區間,如果我構造出100個這樣的區間,其中大約有95個會包含
這就好像用漁網撈魚,我知道一百次網下去,可能會有95次網到我想要的魚,但是我並不知道是不是現在這一網:
你得出的置信區間就像一張大網,而你要推斷的真值是海里的一條魚(不動的魚),你的網可以撒向任何地方,有可能能捕捉到那條魚,有可能一無所獲。95%是用來描述你捕獲真值的概率的,你撒100次網,有95次捕到了真值,5次一無所獲。
剩下的問題就是 置信區間是如何構造的。
假設人群的身高服從:$X \sim N(\mu,\sigma)$
答案1
置信區間,就是一種區間估計。
先來看看什麼是點估計,什麼是區間估計。
1 點估計與區間估計
以前很流行一種刮刮卡:


遊戲規則是(假設只有一個大獎):
- 大獎事先就固定好了,一定印在某一張刮刮卡上
- 買了刮刮卡之後,刮開就知道自己是否中獎
那麼我們起碼有兩種策略來刮獎:
- 點估計:買一張,這就相當於你猜測這一張會中獎
- 區間估計:買一盒,這就相當於你猜測這一盒裡面會有某一張中獎
很顯然區間估計的命中率會更高(當然費用會更高,因為風險降低了)。
接下來,我們看看置信區間是如何進行區間估計的。
2 置信區間
我們通過對人類身高的估計來講解什麼是置信區間。
2.1 上帝視角
對於人類真實的平均身高,我們是沒有辦法知道的,因為幾乎不可能把每個人都統計到。
但這個資料肯定是真實存在的,我們可以說,上帝知道。
在這裡我們引入了上帝視角,即上帝看到的人類身高的真實分佈。
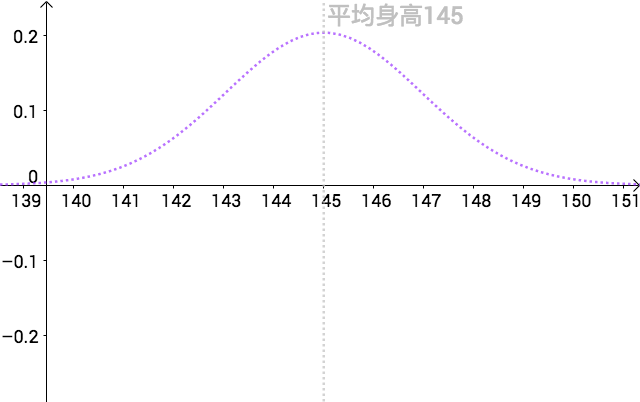
假設人類的身高分佈服從如下正態分佈( ):
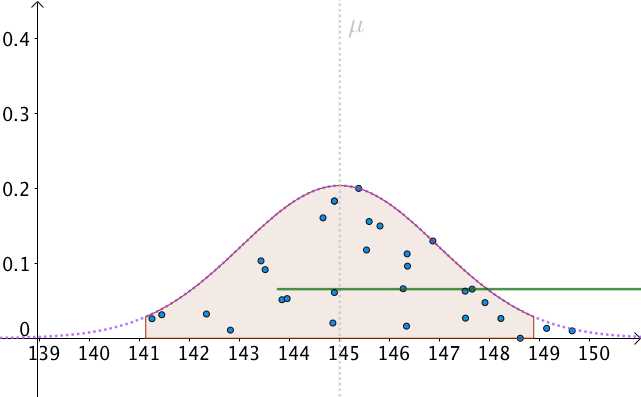
也就是說全體人類的平均身高為145cm,為了表示只有上帝可以看到,我把真實分佈用虛線來表示:
2.2 點估計
作為愚蠢的人類,我們只能在人群中抽樣統計:


比如下面是一次抽樣資料,我把算出來的樣本均值(記作 )畫在圖上(藍色的點):
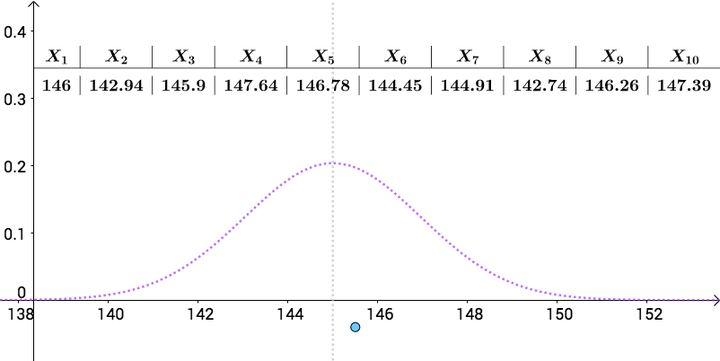
就是對真實的
的一次點估計。
通過一次次的抽樣,我們可以算出不同的身高均值的點估計:
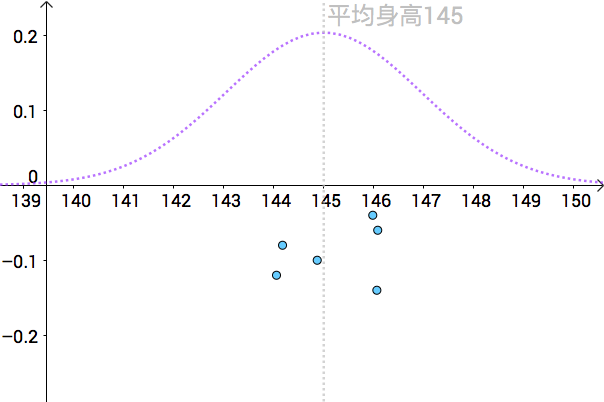
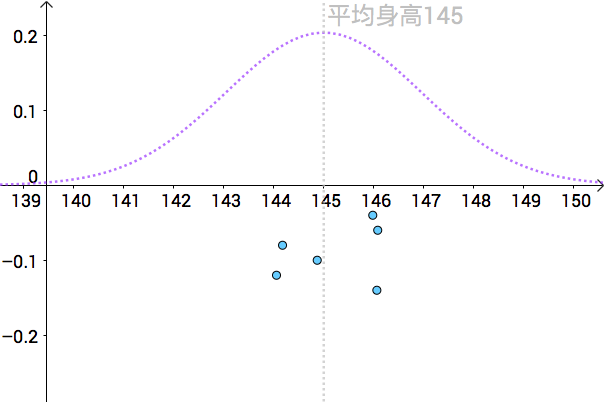
如果我們關閉上帝視角,我們分辨不出哪個點估計更好:
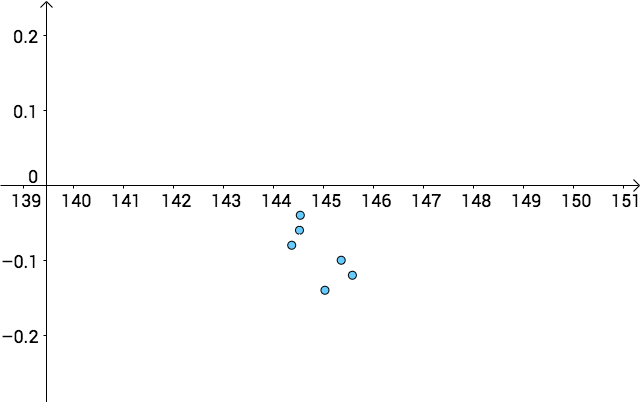
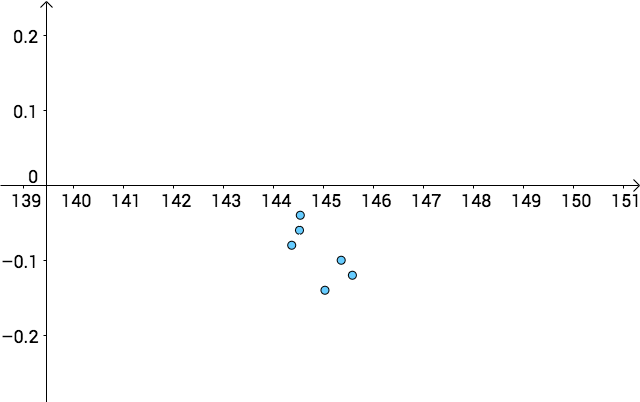
區間估計可以改進此問題。
2.3 置信區間
置信區間,提供了一種區間估計的方法。
下面採用 置信區間來構造區間估計(什麼是
置信區間,這個我們後面解釋):
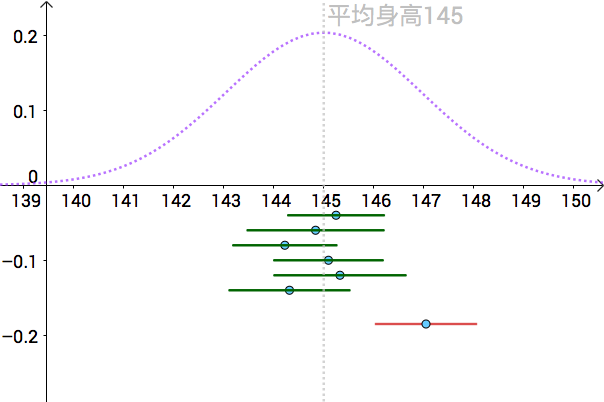
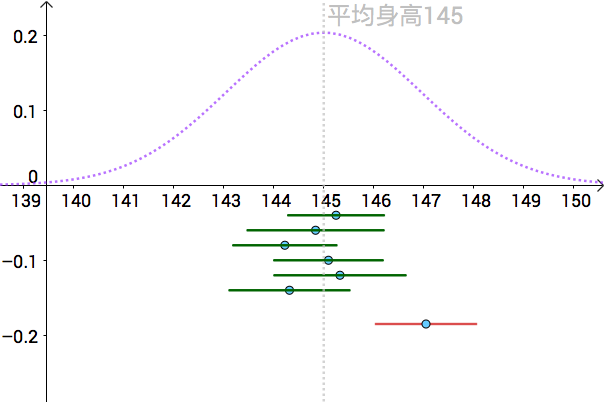
通過 置信區間構造出來的區間,我們可以看到,基本上都包含了真實的
,除了紅色的那根。
關閉上帝視角,我們仍然不知道哪一個區間估計更好:
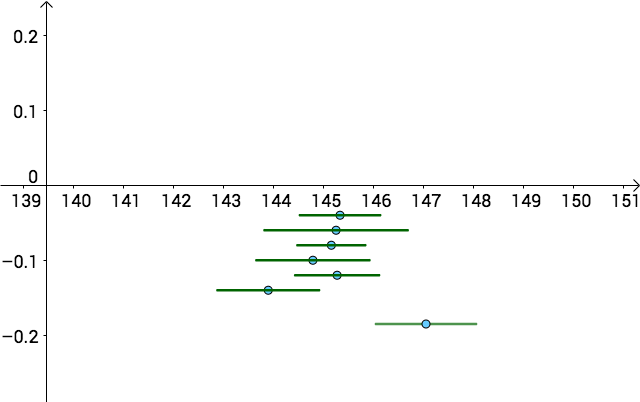
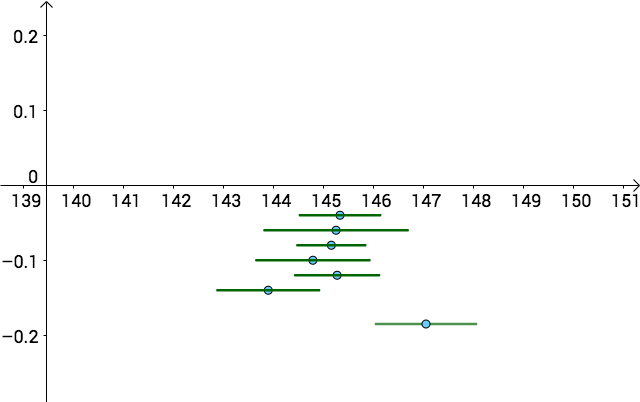
但是,和點估計比較:
- 點估計和區間估計,都不知道哪個點或者哪個區間更好
- 但是,按照
置信區間構造出來的區間,如果我構造出100個這樣的區間,其中大約有95個會包含
這就好像用漁網撈魚,我知道一百次網下去,可能會有95次網到我想要的魚,但是我並不知道是不是現在這一網:


剩下的問題就是 置信區間是如何構造的。
3 置信區間
假設人群的身高服從:
其中 未知,
已知。
我們不斷對人群進行取樣,樣本的大小為 ,樣本的均值:
根據大數定律和中心極限定律, 服從:
我們可以算出以 為中心,面積為0.95的區間,如下圖:
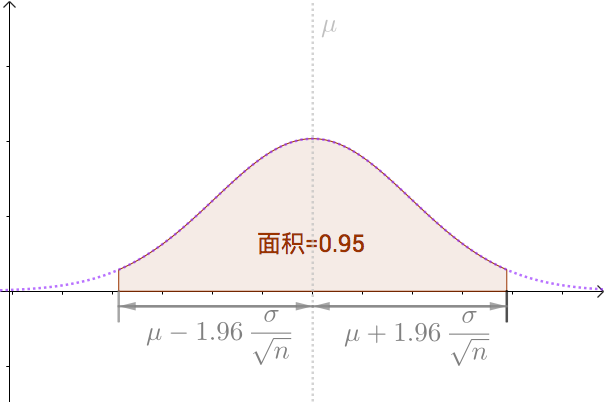
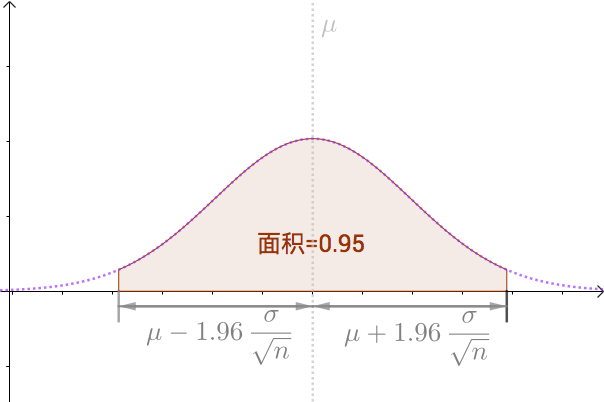
即:
也就是, 有
的機率落入此區間:
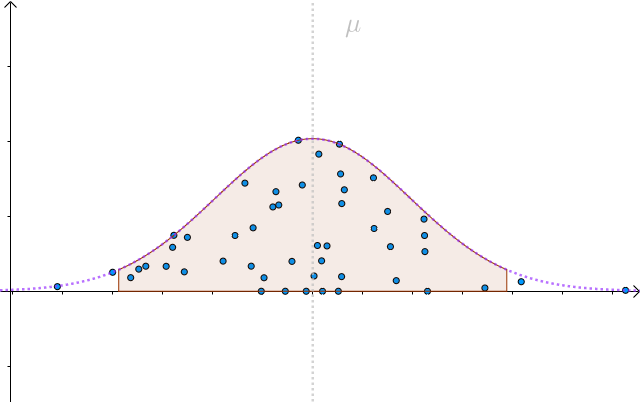
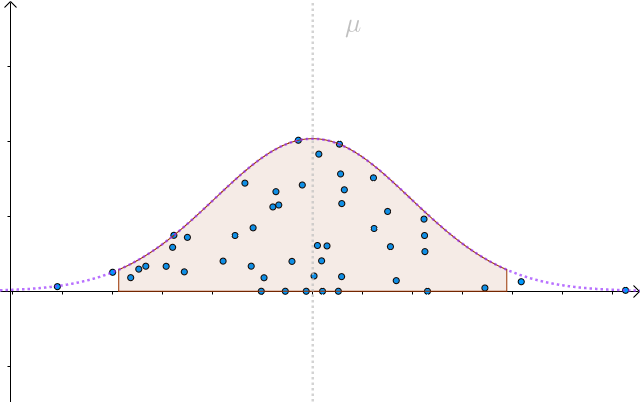
我們以 為半徑做區間,就構造出了
置信區間。按這樣去構造的100個區間,其中大約會有95個會包含
:
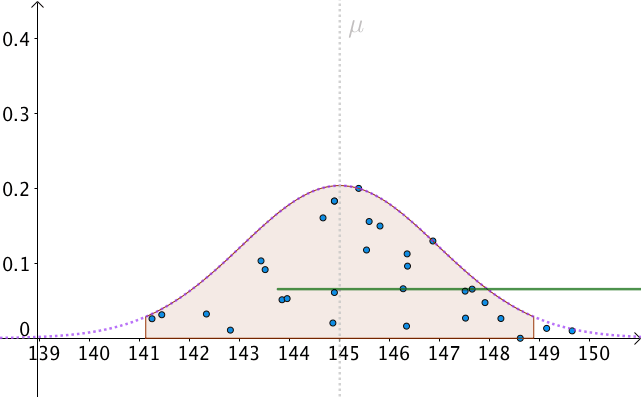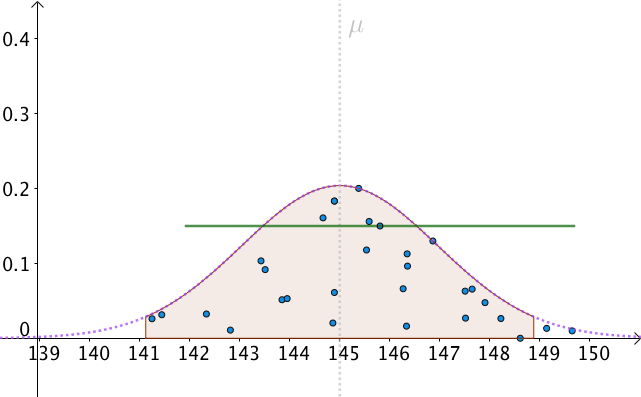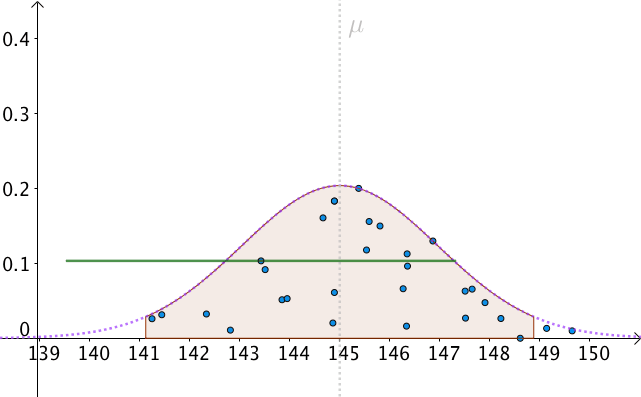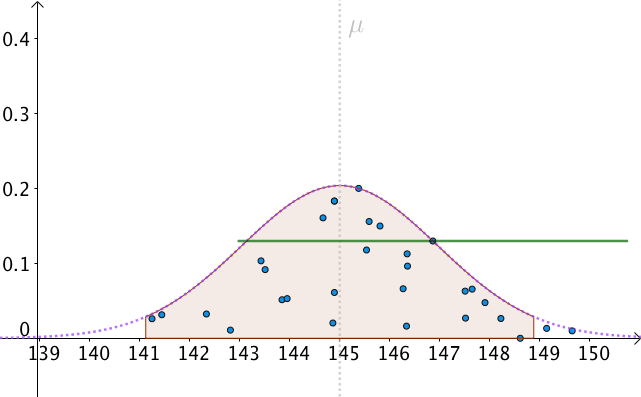
那麼,只有一個問題了,我們不知道、並且永遠都不會知道真實的 是多少。
我們就只有用 來代替
:
4 總結
總結一下:
- 置信區間要求估計量是個常數
答案2
[
陳鵬](http://www.zhihu.com/people/chen-peng-95-54)
專門倒騰資料
236 人贊同了該回答
用於理解的話你可以這樣想: 你得出的置信區間就像一張大網,而你要推斷的真值是海里的一條魚(不動的魚),你的網可以撒向任何地方,有可能能捕捉到那條魚,有可能一無所獲。95%是用來描述你捕獲真值的概率的,你撒100次網,有95次捕到了真值,5次一無所獲。 引用一下Gudmud R .Iverson的《統計學-基本概念和方法》p157關於置信水平的小結: “置信水平為95%的意思是多次抽樣中有95%的置信區間包含未知的引數值而另外的5%則不包含真值。至於在一次抽樣得到的置信區間是包含總體引數的眾多區間中的一員呢,還是屬於個別不包含引數值的區間就不得而知了” 這就是統計學的魅力,雖然我不知道真值是否在區間中,但是我有95%的把握它在裡面。 最後希望這個回答對你有用。