CDP中的Hive3系列之啟動Apache Hive3
這是CDP中的Hive系列中的一篇,其他篇章請參考《CDP中的Hive3系列之CDP的Hive Metastore簡介》,《CDP中的Hive3系列之配置 HMS 以實現高可用性》,《CDP中的Hive3系列之HWC授權》,《CDP中的Hive3系列之HMS資料庫設定和優化》,《CDP中的Hive3系列之Hive從CDH遷移到CDP》,《CDP中的Hive3系列之Hive1/2到Hive3升級規劃工具》,《CDP中的Hive3系列之Apache Hive3概述》,《CDP中的Hive3系列之Apache Hive 3架構概述》,《CDP中的Hive3系列之升級Hive3處理語義和語法變更》,《CDP中的Hive3系列之Hive 3的ACID表》,《CDP中的Hive3系列之通過Hive3使用物化檢視》,《CDP中的Hive3系列之Hive3查詢基礎知識》,《CDP中的Hive3系列之Hive3連線RDBMS和使用函式》,《CDP中的Hive3系列之Hive3使用代理鍵》,《CDP中的Hive3系列之Hive on Tez 簡介》和《CDP中的Hive3系列之Hive3表》。
在不安全的叢集上啟動 Hive
如果您想使用 Apache Hive 進行快速測試,您可以使用 Hive 預設授權模式來執行此操作,假設您位於不安全的叢集上(沒有 Kerberos 或 Ranger 策略)。預設授權模式下,只有使用者hive可以訪問Hive。啟動 Hive shell 的步驟,不要與 CDP 不支援的 Hive CLI 混淆,包括如何登入到叢集。
在叢集命令列中,您可以在叢集的命令列上鍵入hive以啟動 Hive shell。在後臺,Beeline 啟動 Hive shell。
在 Cloudera Manager 中,單擊主機>所有主機。
記下叢集中某個節點的 IP 地址或主機名,例如 myhost-vpc.cloudera.com。
使用 ssh 登入叢集。例如:
ssh myhost-vpc.cloudera.com鍵入hive以從命令列啟動 Hive。
輸入 Hive 查詢。
SHOW DATABASES;CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3,2));INSERT INTO TABLE students VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
原文連結:http://docs.cloudera.com/cdp-private-cloud-base/latest/starting-hive/topics/hive_start_hive.html
使用密碼啟動 Hive
您可以使用 Beeline 命令啟動 Hive shell,以作為 Apache Ranger 授權的終端使用者查詢 Hive。作為管理員,您在作業系統和 Ranger 中設定終端使用者。
在第一次啟動 Hive 之前,您可能需要檢查您是否受基本操作所需的 Ranger 策略的保護,如以下步驟所示。所有使用者都需要使用default資料庫,執行列出資料庫名稱等操作,以及查詢資訊模式。在preloaded default database tables columns與information_schema database的Ranger政策覆蓋組public(所有使用者)。如果禁用這些策略,則無法使用預設資料庫、無法執行列出資料庫名稱等基本操作或查詢資訊架構。例如,如果default database tables columns策略被禁用,如果您嘗試使用default資料庫,則會出現以下錯誤:
hive> USE default;Error: Error while compiling statement: FAILED: HiveAccessControlExceptionPermission denied: user [hive] does not have [USE] privilege on [default]
訪問 Ranger 控制檯:從 Cloudera Manager,單擊 Ranger Admin Web UI 連結,輸入您的 Ranger Admin 使用者名稱和密碼,然後單擊登入。
在最右側,單擊Ranger > <Hive Ranger 服務名稱>,其中預載入服務的服務名稱是 HADOOP SQL 或舊版本的 cm_hive。
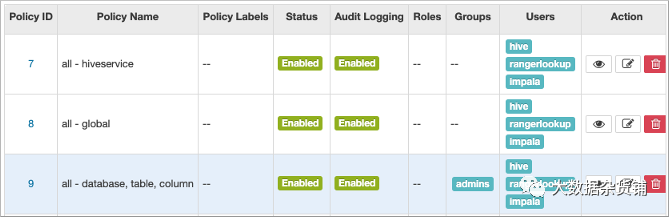
在允許條件中,編輯all - database, table, column.
將您的使用者名稱或組名新增到 Hive 策略以授予對 Hive 的完全訪問許可權。
例如,將 admins 組名新增到可以訪問 Hive 的組列表中。
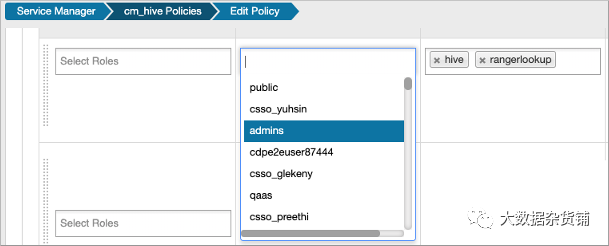
檢查是否為public 組啟用了預載入default database tables columns和 information_schema database策略。
在 Cloudera Manager 中,單擊主機>所有主機。
記下叢集中某個節點的 IP 地址或主機名,例如 myhost-vpc.cloudera.com。
使用 ssh 登入叢集。
例如:
ssh myhost-mydomain.com您可以獲得有關啟動 Hive shell 的幫助。在命令列中,鍵入
hive -h輸出是:
Connect using simple authentication to HiveServer2 on localhost:10000beeline -u jdbc:hive2://localhost:10000 username passwordConnect using simple authentication to HiveServer2 on hs.local:10000 using -n for username and -p for passwordbeeline -n username -p password -u jdbc:hive2://hs2.local:10012Connect using Kerberos authentication with hive/[email protected] as HiveServer2 principalbeeline -u "jdbc:hive2://hs2.local:10013/default;principal=hive/[email protected]"Connect using SSL connection to HiveServer2 on localhost at 10000beeline "jdbc:hive2://localhost:10000/default;ssl=true;sslTrustStore=/usr/local/truststore;trustStorePassword=mytruststorepassword"Connect using LDAP authenticationbeeline -u jdbc:hive2://hs2.local:10013/default <ldap-username> <ldap-password>
在Cloudera Manager > Hosts > Role(s) 中使用叢集中的節點的完全限定域名或 IP 地址,並檢視角色列表以查詢 HiveServer (HS2) 角色。
此節點具有 HiveServer 角色,因此您可以在 Beeline 中使用名稱或 IP 地址。
啟動 Hive shell。
如果設定了叢集安全性,請使用您的使用者名稱。
使用使用者名稱hive而不使用密碼。
將 HiveServer (HS2) 主機的名稱或 IP 地址替換為 10.65.13.98。
簡單的認證:
beeline -u jdbc:hive2://10.65.13.98:10000 -n <your user name> -pKerberos:beeline -u "jdbc:hive2://10.65.13.98:10000/default;principal=hive/_HOST@CLOUDERA.SITE"
輸入 Hive 查詢。
SHOW DATABASES;CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3,2));INSERT INTO TABLE students VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
原文連結:http://docs.cloudera.com/cdp-private-cloud-base/latest/starting-hive/topics/hive_start_hive_as_authorized_user.html
執行 Hive 命令
您可以從叢集中節點的命令列執行大多數將配置變數推送到 Hive SQL 指令碼的 Hive 命令。您可以使用關鍵字和選項在 Beeline 中啟動這些命令。
Hive 支援從命令列執行 Hive 命令。您輸入的命令在後臺啟動 Beeline。-e後跟 Hiveset命令的標誌 列出了系統變數。
在 CDP 叢集中某個節點的命令列上,輸入 hive命令以將配置屬性發送到標準輸出。
hive -e set出現支援的命令。Beeline 支援所有過時的 Hive CLI 命令,但配置 Hive Metastore 的set key=value命令除外。
輸出包括系統變數設定:
+----------------------------------------------------------------+| set |+----------------------------------------------------------------+| _hive.hdfs.session.path=/tmp/hive/hive/91ecb...00a || _hive.local.session.path=/tmp/hive/91ecb...00a | |...
原文連結:http://docs.cloudera.com/cdp-private-cloud-base/latest/starting-hive/topics/hive_run_hive_command.html
將 Hive CLI 指令碼轉換為 Beeline
如果您有使用 Hive CLI 從邊緣節點執行 Hive 查詢的遺留指令碼,您必須解決這些指令碼中變數替換的潛在不相容性。CDP 支援 Beeline 而不是 Hive CLI。您可以使用 Beeline 執行遺留指令碼,但有一些注意事項。
在此任務中,您將解決舊 Hive CLI 指令碼和 Beeline 中的不相容問題:
配置變數
問題:除非允許,否則您不能使用hiveconf名稱空間在指令碼中引用配置引數。
解決方案:您將該引數包含在 HiveServer 許可名單(白名單)中。
名稱空間問題
問題:Beeline 不支援名稱空間的變數 system和env。
解決方案:您可以使用本任務中描述的轉換技術從指令碼中刪除這些名稱空間引用。
建立一個名為的轉換指令碼env_to_hivevar.sh,用於刪除envSQL 指令碼中的引用。
CMD_LINE=""#Blank conversion of all env scoped valuesfor I in `env`; doCMD_LINE="$CMD_LINE --hivevar env:${I} "doneecho ${CMD_LINE}
例如,在叢集中某個節點的命令列中,定義並匯出一個名為 HIVEVAR 的變數,並將其設定為執行轉換指令碼。
export HIVEVAR=`./env_to_hivevar.sh`定義和匯出變數以儲存一些用於測試轉換的變數。
export LOC_TIME_ZONE="US/EASTERN"export MY_TEST_VAR="TODAY"
在叢集節點的命令列上,測試轉換:執行引用HIVEVAR的命令解析SQL語句,去除不相容的 env名稱空間,執行剩餘的SQL。
hive ${HIVEVAR} -e 'select "${env:LOC_TIME_ZONE}";'+-------------+| _c0 |+-------------+| US/EASTERN |+-------------+
建立一個名為init_var.sql模擬遺留指令碼的文字檔案,該指令碼設定兩個配置引數,一個在有問題的 env名稱空間中。
set mylocal.test.var=hello;set mylocal.test.env.var=${env:MY_TEST_VAR};
在許可名單中包含這些配置引數:在 Cloudera Manager 中,轉到Clusters > HIVE_ON_TEZ-1 > Configuration,然後搜尋 hive-site。
在hive-site.xml 的 HiveServer2 高階配置片段(安全閥)中,新增屬性鍵:hive.security.authorization.sqlstd.confwhitelist.append。
向許可名單提供一個或多個屬性值,例如:mylocal\..*|junk。
這個動作追加mylocal.test.var和 mylocal.test.env.var引數的允許列表。
儲存配置更改,並根據需要重新啟動任何元件。
執行引用 HIVEVAR 的命令來解析 SQL 指令碼,移除不相容的env名稱空間,並執行剩餘的 SQL,包括由 hiveconf:.
hive -i init_var.sql ${HIVEVAR} -e 'select "${hiveconf:mylocal.test.var}","${hiveconf:mylocal.test.env.var}";'+--------+--------+| _c0 | _c1 |+--------+--------+| hello | TODAY |+--------+--------+
原文連結:http://docs.cloudera.com/cdp-private-cloud-base/latest/starting-hive/topics/hive_use_variables.html
本文分享自微信公眾號 - 大資料雜貨鋪(bigdataGrocery)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- Yarn管理放置規則
- Yarn在全域性級別配置排程程式屬性
- 使用YARN Web UI和CLI
- CDP中的Hive3系列之管理Hive的工作負載
- CDP中的Hive3系列之啟動Apache Hive3
- Hive on Tez 簡介
- CDP私有云基礎7.1.7發行說明
- CDP的Hive Metastore簡介
- FAQ系列之Impala
- CDP私有云基礎版7.1.6版本概要
- CDP通過支援谷歌雲擴充套件了混合雲的支援
- 教程|運營資料庫 Phoenix SQL:在CDP公有云上使用HBase、Nifi和Kafka
- 下一站–建立從邊緣到洞察的資料管道
- 配置客戶端以安全連線到Apache Kafka叢集4:TLS客戶端身份驗證
- 配置客戶端以安全連線到Kafka叢集–LDAP
- NiFi –混合雲環境中的資料移動賦能者
- 有關Apache NiFi的5大常見問題
- 使用YCSB進行HBase效能測試
- Cloudera Manager主機管理
- 使用CFM進行日誌減少技術