CDP中的Hive3系列之管理Hive的工作負載
這是CDP中的Hive系列中的一篇,其他篇章請參考《CDP中的Hive3系列之CDP的Hive Metastore簡介》,《CDP中的Hive3系列之配置 HMS 以實現高可用性》,《CDP中的Hive3系列之HWC授權》,《CDP中的Hive3系列之HMS資料庫設定和優化》,《CDP中的Hive3系列之Hive從CDH遷移到CDP》,《CDP中的Hive3系列之Hive1/2到Hive3升級規劃工具》,《CDP中的Hive3系列之Apache Hive3概述》,《CDP中的Hive3系列之Apache Hive 3架構概述》,《CDP中的Hive3系列之升級Hive3處理語義和語法變更》,《CDP中的Hive3系列之Hive 3的ACID表》,《CDP中的Hive3系列之通過Hive3使用物化檢視》,《CDP中的Hive3系列之Hive3查詢基礎知識》,《CDP中的Hive3系列之Hive3連線RDBMS和使用函式》,《CDP中的Hive3系列之Hive3使用代理鍵》,《CDP中的Hive3系列之Hive on Tez 簡介》,《CDP中的Hive3系列之Hive3表》,《CDP中的Hive3系列之啟動Apache Hive3》,《CDP中的Hive3系列之分割槽介紹和管理》,《CDP中的Hive3系列之計劃查詢》和《CDP中的Hive3系列之管理Hive》。
工作負載管理
作為管理員,要管理工作負載,您將瞭解什麼是資源計劃以及如何建立資源計劃以改進並行查詢執行。當叢集共享查詢時,並行處理查詢很重要。
資源計劃是一個自包含的資源共享配置。在叢集上每次只有一個資源計劃處於活動狀態。通常,在活動叢集上啟用和禁用資源計劃不會影響正在執行的查詢。作為管理員,您可以應用針對不同情況配置叢集的資源計劃。例如,您的指令碼可以應用將叢集配置為處理高流量的資源計劃。當流量減少時,您可以切換資源計劃以支援互動式資料視覺化、深度臨時分析和大規模 BI 報告的流量。
當工作負載達到大量併發查詢時,您可以建立資源計劃以滿足定義的資料處理基準。例如,考慮一個企業,它有一個向大約 100 名分析師公開的ad hoc分析應用程式。資料集和查詢模式規定生成的查詢在幾秒鐘內執行。資源計劃可以確保當多達 100 個使用者可能同時使用系統時,至少 95% 的查詢在 15 秒內完成。
一個資源計劃可以由一個或多個查詢池、對映和觸發器組成:
查詢池與池內的叢集程序和查詢共享資源,並設定最大併發查詢數。
對映基於指定的因素(例如使用者名稱、組或應用程式)將傳入查詢路由到池。
觸發器根據由 Apache Hadoop、Tez 和 Hive 計數器表示的查詢指標啟動操作,例如終止池中的查詢或叢集中執行的所有查詢。
下圖描繪了一個簡單的資源計劃。第一張圖顯示了為高流量時段設計的資源計劃,第二張圖顯示了為低流量時段設計的資源計劃。
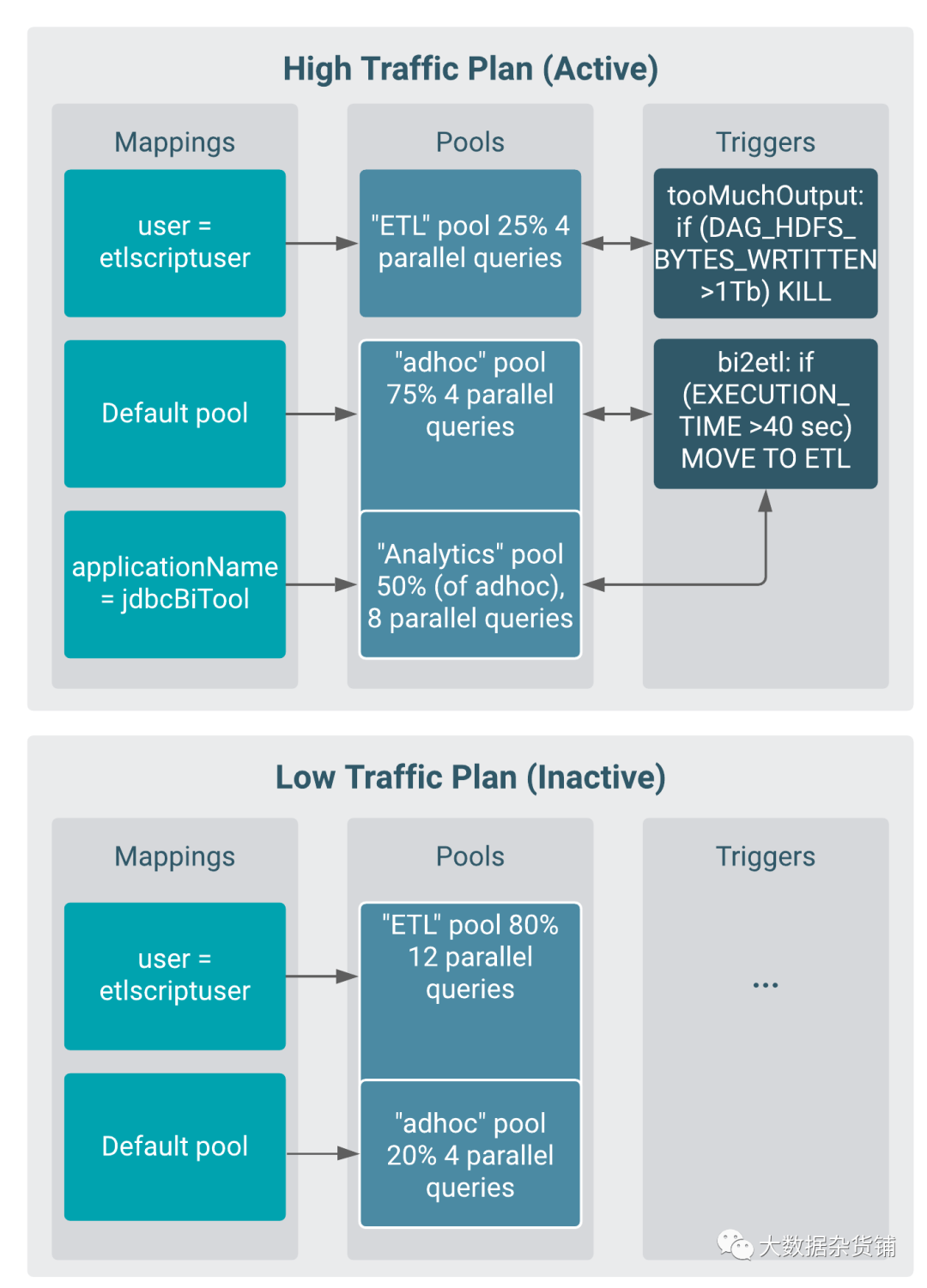
設定和使用資源計劃
瞭解使用工作負載管理的先決條件至關重要。作為管理員,您可以使用 DDL 語句定義資源計劃,這些語句通常包括針對不同使用者或應用程式的事件觸發資源池。然後,您可以使用資源計劃管理工作負載。建立並啟用資源計劃後,您必須將其啟用。當您想要更改資源計劃或停止使用它時,您必須禁用它。
建立資源計劃
作為管理員,您可以建立資源計劃,為不同的條件配置叢集,使您能夠改進並行查詢執行並在執行Hive的節點上共享查詢。您可以將資源分配給使用者、組或應用程式池,並在計劃中觸發操作。
您從 Beeline shell 啟動Hive,或者打開了另一個 Hive UI。
作為管理員,您可以建立新的資源計劃或克隆另一個計劃,然後對其進行修改。
建立資源計劃。
建立一個新的資源計劃(例如,一個名為 high_concurr_rp 的資源計劃):
CREATE RESOURCE PLAN high_concurr_rp;克隆現有的資源計劃(例如 ha_plan)並將其重新命名為 high_concurr_rp:
CREATE RESOURCE PLAN high_concurr_rp LIKE ha_plan;建立一個新的資源計劃(例如,名為 high_concurr_rp)並指定查詢併發限制:
CREATE RESOURCE PLAN high_concurr_rp WITH QUERY_PARALLELISM=15;(可選)向計劃新增一個或多個查詢池。
CREATE POOL high_concurr_rp.bi_poolWITH ALLOC_FRACTION=75,QUERY_PARALLELISM=5;CREATE POOL high_concurr_rp.etl_poolWITH ALLOC_FRACTION=25,QUERY_PARALLELISM=10;
此示例配置將 75% 的 LLAP 叢集資源分配給一個池,將 25% 分配給另一個池,並允許一個池中的使用者進行 5 個併發查詢,另一個池中的使用者進行 10 個併發查詢。
(可選)將應用程式對映到池。
CREATE APPLICATION MAPPING tableau_to_bi IN bi_pool;Tableau 應用程式到 bi_pool 的此示例對映要求 Tableau 使用包含 applicationName="Tableau". 在組到池的對映中,組授權取決於叢集上的 HDFS 組配置。您可以配置輕量級目錄協議 (LDAP) 和其他機制。
(可選)建立觸發器。例如,建立一個觸發器,當執行時間超過一分鐘時,將查詢移動到 etl_pool 中執行。
CREATE TRIGGER high_concurr_rp.slow_queryWHEN execution_time_ms > 60000DO MOVE TO etl_pool;
如果您正在執行 LLAP 服務,請向池或資源計劃新增觸發器,如下例所示。
ALTER TRIGGER high_concurr_rp.slow_query ADD TO POOL bi_pool;您可以使用 ALTER TRIGGER 命令向在 LLAP 下執行的池或資源計劃新增觸發器;否則,觸發器被認為是全域性的並且僅在 Tez 中執行。
啟用資源計劃
您可以啟用並可選擇啟用資源計劃以通過執行查詢來管理工作負載。
您在要管理的叢集上通過 ODBC 或 JDBC 連線到 HiveServer。
您從 Beeline shell 啟動 Hive,或其他 Hive UI。
啟用資源計劃的部分過程是驗證計劃。啟用計劃不會將計劃應用於查詢工作負載。您無法在啟用時修改計劃。您可以啟用多個計劃,但一次只能在一個叢集上啟用一個。啟用和啟用計劃也會驗證該計劃。
驗證名為 myplan 的資源計劃。
ALTER RESOURCE PLAN myplan VALIDATE;使用以下方法之一啟用資源計劃,具體取決於您是要現在還是稍後啟用該計劃,以及您是否已經激活了另一個計劃。
啟用資源計劃:
ALTER RESOURCE PLAN myplan ENABLE;啟用並激活資源計劃:
ALTER RESOURCE PLAN myplan ENABLE ACTIVATE;歸檔活動資源計劃並將其替換為指定的資源計劃:
ALTER RESOURCE PLAN myplan ENABLE ACTIVATE WITH REPLACE啟用資源計劃
您可以啟用已啟用的資源計劃以將該計劃應用於查詢工作負載以開始管理工作負載。
您連線到要管理的叢集上的 HiveServer,並從 Beeline shell 啟動 Hive、或開啟另一個 Hive UI。
您啟用了資源計劃。
您一次只能啟用一個資源計劃。
啟用資源計劃。
ALTER RESOURCE PLAN plan1 ACTIVATE;本示例啟用 plan1。
通過啟用另一個資源計劃來停用一個資源計劃。
ALTER RESOURCE PLAN plan2 ACTIVATE;此示例啟用 plan2 並停用 plan1,但仍啟用 plan1。
查詢 sys 資料庫以獲取計劃資料
您查詢 Hive 元儲存中的 sys 資料庫以檢索有關工作負載管理實體的資訊,例如資源計劃。
您在要管理的叢集上建立了到 HiveServer 的連線,並從 Beeline shell 啟動了 Hive,或者打開了另一個 Hive UI。
已建立用於管理叢集上的工作負載的資源計劃。
假設您按照前面所述建立了 high_concurr_rp 資源計劃,請查詢 sys 資料庫以獲取有關該計劃的資訊。
例如,獲取資源計劃的查詢池的檢視。
SELECT * FROM SYS.WM_POOLS WHERE RP_NAME = 'high_concurr_rp';獲取有關計劃的名為 etl_pool pool 的池中名為 slow_query 的觸發器的資訊。
SELECT TRIGGER_NAME.slow_query FROM SYS.WM_POOLS_TO_TRIGGERS WHERE RP_NAME = 'high_concurr_rp';禁用資源計劃
您可以禁用資源計劃以對其進行修改或停止管理工作負載。您執行查詢以禁用資源計劃。
您已連線到要管理的叢集上的 HiveServer。
您從 Beeline shell 啟動了 Hive,或者打開了另一個 Hive UI。
禁用資源計劃。
ALTER RESOURCE PLAN myplan DISABLE;原文連結:http://docs.cloudera.com/cdp-private-cloud-base/latest/managing-a-hive-workload/topics/hive_workload_management.html
sys中的工作負載管理實體資料
從 Hive sys 資料庫中,您可以獲得有關工作負載管理和其他 Hive 實體的資訊。給定工作負載管理檢視的宣告,有足夠的資訊來構建資訊查詢。
工作負載管理檢視
Hive 有一個名為 sys 的特殊資料庫,類似於系統目錄或資訊目錄。sys 資料庫是 Hive Metastore 的一部分。在 sys 資料庫中,您可以查詢所有 Hive 實體的檢視,包括工作負載管理實體。以下工作負載管理檢視可用:
SYS.WM_RESOURCEPLANS(名稱字串、狀態字串、QUERY_PARALLELISM int、DEFAULT_POOL_PATH 字串)
SYS.WM_POOLS(RP_NAME 字串、PATH 字串、ALLOC_FRACTION 雙精度、QUERY_PARALLELISM int、SCHEDULING_POLICY 字串)
SYS.WM_MAPPINGS(RP_NAME 字串、ENTITY_TYPE 字串、ENTITY_NAME 字串、POOL_PATH 字串、ORDERING 整數)
SYS.WM_TRIGGERS(RP_NAME 字串、NAME 字串、TRIGGER_EXPRESSION 字串、ACTION_EXPRESSION 字串)
SYS.WM_POOLS_TO_TRIGGERS(RP_NAME 字串、POOL_PATH 字串、TRIGGER_NAME 字串)
原文連結:http://docs.cloudera.com/cdp-private-cloud-base/latest/managing-a-hive-workload/topics/hive_workload_management_entity_data_in_sys.html
本文分享自微信公眾號 - 大資料雜貨鋪(bigdataGrocery)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- Yarn管理放置規則
- Yarn在全域性級別配置排程程式屬性
- 使用YARN Web UI和CLI
- CDP中的Hive3系列之管理Hive的工作負載
- CDP中的Hive3系列之啟動Apache Hive3
- Hive on Tez 簡介
- CDP私有云基礎7.1.7發行說明
- CDP的Hive Metastore簡介
- FAQ系列之Impala
- CDP私有云基礎版7.1.6版本概要
- CDP通過支援谷歌雲擴充套件了混合雲的支援
- 教程|運營資料庫 Phoenix SQL:在CDP公有云上使用HBase、Nifi和Kafka
- 下一站–建立從邊緣到洞察的資料管道
- 配置客戶端以安全連線到Apache Kafka叢集4:TLS客戶端身份驗證
- 配置客戶端以安全連線到Kafka叢集–LDAP
- NiFi –混合雲環境中的資料移動賦能者
- 有關Apache NiFi的5大常見問題
- 使用YCSB進行HBase效能測試
- Cloudera Manager主機管理
- 使用CFM進行日誌減少技術