中年 Hadoop

2 月初,Apache Hadoop 管理工具 Apache Ambari 也正式宣告退休,一年內,Apache 軟體基金會已經有 11 個 Hadoop 生態內的專案不再是頂級專案。
“Hadoop 是為了大資料而誕生的,其本身就象徵著本世紀工業革命的焦點:業務的數字化轉型。”2016 年,Hadoop 誕生十週年之際,其創造者 Doug Cutting 這樣形容 Hadoop。
21 世紀初,正值資料大爆發時刻,Hadoop 的出現為企業解決了不少難題,成為推動企業數字化轉型的重要因素。但隨著雲時代的到來,Hadoop 似乎也開始步入中年:有了自己生態積澱,但也面臨著後來者強勁的衝擊。
或許多年後回頭看,現在正是 Hadoop 生命週期中決定興亡的重要時刻。
黃色小象 Hadoop
1985 年,斯坦福大學生 Doug Cutting 為了償還助學貸款,併為畢業後的生活做準備,意識到自己必須學一些更加實用的技能。在學校所在地矽谷,Doug Cutting 為自己找到的第一份工作是在 Xerox 做實習生,為鐳射掃描器上的其中一個系統開發螢幕保護程式。

Xerox 的這份工作不僅解決了 Cutting 生活上的“近憂”,更是為將來 Cutting 研究搜尋技術起到決定性作用。
畢業之後,Cutting 繼續留在 Xerox 工作,主要研究搜尋技術,他花了大量時間搞研發,讀論文,同時自己也發表了些論文,對於這段經歷,他形容:“我的研究生是在 Xerox 讀的。”搞了幾年“學術研究”之後,Cutting 想要讓自己的研究成果為更多人所用。
1997 年年底,Cutting 每週花兩天時間嘗試用 Java 落地研究成果。1999 年,第一個提供全文文字搜尋的開源函式庫——Lucene 誕生。這是 Cutting 的第一個代表作。
沿著 Lucene 的研發方向,Cutting 之後曾在搜尋引擎公司 Architext 呆過一段時間,Architext 因網際網路經濟泡沫衝擊破產後,Cutting 希望自己的專案能通過一種低開銷的方式來構建網頁中的大量演算法。
2002 年,Cutting 決定和 Mike Cafarella 共同開發一款開源網頁爬蟲專案 Nutch,但他們也遇到了難題——如何儲存大量網站資料。
而那一時間,IT 界最受矚目的事件便是谷歌接連發布的 3 篇論文,對外公開了內部搜尋引擎的三大關鍵技術,分別是 Google 的 GFS 檔案系統,大規模叢集上的運算技術 MapReduce,以及分散式檔案系統 Bigtable。同時,3 篇論文論述了怎麼藉助普通機器有效儲存海量大資料;怎麼樣快速計算海量資料;怎樣實現海量資料的快速查詢。這為 Cutting 解決所遇到的問題提供了新的思路。
Doug Cutting 參考了 Google 的技術和理論,利用 Java 語言,發展出自家的 DFS 檔案系統和 MapReduce 程式,解決 Nutch 搜尋引擎的大量資料擴充需求。
藉助 GFS 和 MapReduce,2006 年 1 月 28 日,Hadoop 誕生了。這時候,Cutting 已經成為一名父親,他看著牙牙學語的兒子抱著一頭黃色小象叫“Hadoop”,便決定將新專案命名為“Hadoop”,並且用黃色小象作為專案 Logo。後來,這頭黃色小象時常跟著 Cutting 出現在各種技術活動上……

而關於谷歌論文對 Hadoop 研發的幫助,Cutting 十分認可,“我們開始設想用 4~5 臺電腦來實現這個專案,但在實際執行中牽涉了大量繁瑣的步驟需要靠人工來完成。Google 的平臺讓這些步驟得以自動化,為我們實現整體框架打下了良好的基礎。”
有了 Hadoop 之後,IT 生產所需的應用程式和產生的資料得以被儲存在單一的系統裡,並且在擴容、資料處理上也有了更加顯著的進步。
Cutting 曾說,Hadoop 的意義不在技術,更大的意義在於“數字轉型”(Digital Dransformation),而開源也非常重要,“因為它(Hadoop)並不是最好的技術,也不完美,但它因為是屬於開放原始碼,透過社群的力量,使它成為了最好的搜尋技術。對使用者來說,現在更多想要的是開放原始碼的軟體。”
成為 Core Hadoop
Hadoop 誕生沒多久,這頭“黃色小象”就再不單單只是代表一個軟體,而是一個龐大的大資料軟體生態。
借用 Cloudera 資深工程師陳飈的話來形容就是:
2006 年專案成立的一開始,“Hadoop”這個單詞只代表了兩個元件——HDFS 和 MapReduce。到現在的 10 個年頭,這個單詞代表的是“核心”(即 Core Hadoop 專案)以及與之相關的一個不斷成長的生態系統。這個和 Linux 非常類似,都是由一個核心和一個生態系統組成。
現在, Hadoop 核心模組有四個:通用庫 Hadoop Common、分散式檔案系統 HDFS、作業排程和叢集資源管理框架 YARN、計算引擎 MapReduce,在其基礎模組之上,需要藉助 Hive、HBase、Pig、Spark、Kafka、Zookeeper 等軟體真正應用在生產環境中。反之,這些軟體也在幫助 Hadoop 構築生態。在 Hadoop 生態體系之下至少有30個以上開源專案,為了完成一個生產專案需要對多個開源模組整合。也因此,Hadoop 在很大程度是代表著資料庫。
Hadoop 早期生態的擴大有三方“主要勢力”支援。
一是 Apache 軟體基金會,為 Hadoop 社群發展做了很好的信任背書。2006 年 4 月,第一個 Apache Hadoop 釋出。之後,圍繞 Hadoop,Apache 軟體基金會吸納了眾多相關專案,慢慢建成 Hadoop 生態系統。

二是 Cutting 當時的東家 Yahoo。起初,Yahoo 為了自己的搜尋引擎,看上 Nutch 專案,便在 2006 年將 Cutting 招入麾下。同年 Cutting 的 Hadoop 專案面世之後,Yahoo 看到了 Hadoop 在大資料運算上的價值,便投入人力,支援 Hadoop 的研發,同時在內部開始應用 Hadoop。
2008 年,Yahoo 建了一個當時全球最大規模的 Hadoop 叢集,使用 4 千多臺伺服器,超過 3 萬個處理器核心,索引超過 16PB 的網頁資料。Yahoo 實踐的成功也是對當時 Hadoop 實力的最好證明。
三是 Hadoop 的靈感來源商——Google,當時,Google 也參與了 Hadoop 的開發,並將其作為雲端計算的教材,在全世界範圍內推廣。當然,Goggle 當年最重要的貢獻還是在論文上,2006 年 11 月,Google 發表了 Bigtable 論文,這最終激發了 Hadoop 生態中的重要角色 HBase 的建立。
在上述“三駕馬車”驅進的同時,Hadoop 正風靡全球。Facebook、Twitter 和 LinkedIn 等公司,在 Hadoop 之上也很快開發了相關開源專案——Apache Pig、Apache Hive、Apache HBase 等等,這些專案成為日後 Hadoop 生態中的重要一環。在中國,2007 年,百度開始使用 Hadoop 做離線處理,中國移動開始在“大雲”研究中使用 Hadoop 技術。2008 年,淘寶開始投入研究基於 Hadoop 的系統“雲梯”,並將其用於處理電子商務相關資料。
“Hadoop 徹底改變了整個行業的格局。開發人員可以更快、更輕鬆地構建更好的廣告方式、拼寫檢查、頁面佈局等等。”Cutting 這樣形容當時的變化。
除了 IT 廠商外,當時也有投資人、學術界認可 Hadoop。
2008 年,第一家圍繞 Hadoop 而建的開源原生商業公司 Cloudera 成立,明確自身的使命是將 Hadoop 技術引入傳統企業。
2009 年,Cutting 意識到這對 Hadoop 來說是一種巨大的可能,“如果可以讓世界 500 強企業採用 Hadoop,那很與可能改變他們的業務模式,隨著公司逐漸採用更多技術,從網站和呼叫中心、到現金出納機和條碼掃描器,他們的手指尖將會傳遞越來越多企業的資料。如果企業能夠採集和使用更多資料,那麼將可以更好地瞭解和改善他們的業務。傳統的基於關係資料庫管理系統(RDBMS)的技術存在以下弱點:在支援可變、混亂的資料和快速實驗方面太過死板;無法輕易擴充套件到支撐 PB 級資料;並且成本非常昂貴。與此相比,即使是很小的 Hadoop 叢集也可以允許公司提出和回答比以前更復雜的問題,並且可以不斷地學習和提高。”看到 Hadoop 的前景之後,Cutting 本人也加入了 Cloudera 公司,成為首席架構師。
與此同時,2009 年 MapR 成立,2011 Hortonworks 成立,早期“Hadoop 三巨頭”出現。2014 年,Hortonworks 成功上市;Cloudera Intel 7.5 億美元的投資,總估值曾達到41億美元,成為當時未上市的大資料公司裡面最為閃耀的一個;MapR 也先後融資也近 3 億美元。
這些圍繞 Hadoop 而生的商業公司讓人們更加看到 Hadoop 的前景,加之它們早期融資非常順利,一時間 Hadoop 風光無二。
中年危機
投資人對 Hadoop 的押注是 Hadoop 繁榮的一大標誌。然而,當市場趨於冷靜後,隨之而來的便是對 Hadoop 的唱衰。
歷經 2014 年的高光時刻之後,Hadoop 相關公司在資本市場上表現走低,2019 年開始渡劫,三大發行商相繼衰落。
2019 年 5 月,MapR 宣佈,即將裁員上百人,並關閉公司矽谷總部,如果找不到買家或新的資金來源,將會永久徹底地關閉公司。兩個多月後,MapR表示找到了買家——惠普企業HPE。2019 年 6 月 6 日,Cloudera 在下調收入預測並宣佈其執行長將離開公司後,股價下跌 43%,這家在 2014 年的估值為 41 億美元的公司,到了 2019 年,僅剩 14 億美元。11 月,不堪重負的 Hortonworks 完成了與 Cloudera 的 52 億美元全股票合併。
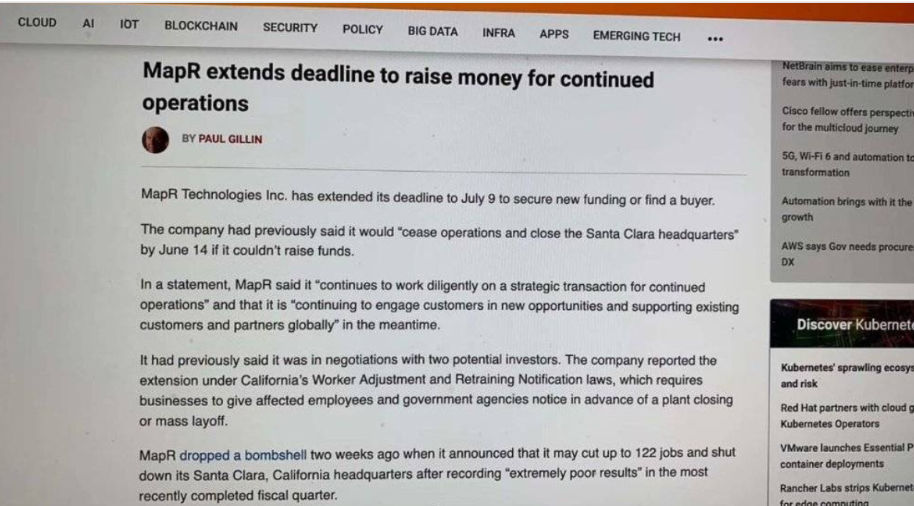
這三家公司成敗皆是基於 Hadoop。MapR 在裁員之前,業務模式是做私有化產品的售賣,核心資產是其檔案系統,相較 Hadoop 的開源版本 HDFS 效能要高,但同時也意味這成本,即銷售困難。而 Hortonworks 和 Cloudera 兩家公司在宣佈合併之後,只要業務也從 Hadoop 相關產品轉向“從邊緣到 AI 的企業資料雲”產品。由此可見,僅僅從市場來說,Hadoop 並非一個可以輕鬆為投資人帶來收益的工具,也因此傳來了唱衰的聲音。
為什麼 Hadoop 不能掙錢?大概是因為 Hadoop 生態剛成型沒多久,就出現了一個更強的生態——以 Spark 為代表的雲原生大資料專案。
早期,Spark 被認為是 Hadoop 的補充。一位雅虎投資 Hadoop 的早期倡導者在 2015 年有一個觀點,認為 Spark 和 Hadoop 會和諧相處,Spark 可以作為 Hadoop 頂層的記憶體處理方案,eBay 和雅虎 —— 都在 Hadoop 叢集中執行著 Spark,Spark 對於 Hadoop 來說不是挑戰,也不是來取代 Hadoop 的。相反,Hadoop 是 Spark 成長髮展的基礎。
甚至是對於 2019 的情況,Alluxio 的創始人兼 CTO Haoyuan Li 認為,這最多證明 Hadoop 分散式檔案系統(HDFS)形式的 Hadoop 儲存已死,但 Spark 形式的 Hadoop 計算仍然強大。
但是,這種 Spark 可以讓 Hadoop 變得更強的觀點近兩年已經慢慢消失,Spark 對於 Hadoop 來說已經不再是一個沒有威脅的輔助角色。以“閃電般的執行速度”而聞名的 Spark 自稱比 Hadoop 快一百倍,雖然實際倍數有待考量,但拼速度,Hadoop 顯然已經不行了。
更進一步說,雲的流程更是襯得 Hadoop 的優點不復。Hadoop 最初風靡的最大原因就是讓資料的儲存變得廉價,但是雲端計算可以提供更加優惠的儲存。此外,雲端計算廠商也學會了打造自身的生態,在雲上提供多個元件來取代原有的 Hadoop 生態元件,如 AWS 的 S3 替代了 HDFS,K8S 替代了 YARN 等等。
早在 2018 年,Twitter 宣佈遷移到 Google Cloud,以提高生產力並滿足其不斷增長的需求。此外,他們還表示,他們的 Hadoop 檔案系統儲存了超過 300 PB 的資料,並且他們正在將 Hadoop 計算系統遷移到 Google Cloud。
面對雲的衝擊,Hadoop 生態圈也在嘗試擁抱新變化。2018 年,Google 收購 Cask 以強化雲端 Hadoop 的應用生態。Cask 的主要產品 CDAP 是一個開源的應用平臺,它整合了 Hadoop 生態,提供資料以及應用的抽象層,使得開發者能以快速且簡單的方式開發應用。而合作 Google Cloud,便是希望能夠做更具規模和效率的服務。
但根據 The Next Platform 在 2021 年釋出的最新報告,財富 500 強企業正在對 Hadoop 失去興趣。主要原因有二:首先是效能,其次是成本。
Next Pathway 的戰略負責人 Vinay Mathur 解釋,效能方面,大公司發現,使用結構化和非結構化的資料分析需求越來越複雜,在基於 Hadoop 的 Hive 和 Impala 技術之上,大規模的查詢、轉換資料變得緩慢,使用 Snowflake 或 Google BigQuery 能大幅縮短時間,“隨著資料量和分析需求複雜性增加,Hadoop 根本不再適用。
其次,維護線上的 Hadoop 處理環境,並且為計算和儲存付費是一項持續的投入,繼續使用 Hadoop 並不會節約成本,反而是從 Hadoop 轉向更加混合的基礎架構和分析模型,並不會造成所有資料丟失,因此,越來越多的公司在更換 Hadoop。
挑戰與機會
當下,Hadoop 的處境可謂是冰火兩重天。
2021 年 4 月起,Apache 軟體基金會在幾個月內宣佈 13 個大資料相關的專案退役(Attic)了,其中 10 個屬於 Hadoop 生態,包括 Apex、Chukwa、Crunch、Eagle、Falcon、Hama、Lens、Sentry、Tajo、Twill。
這一動作讓“Hadoop 將被替代”的聲音再次響起。
Apache 軟體基金會官方對此的迴應是屬於常規的專案集中報廢。Apache 軟體基金會的營銷和公關副總裁 Sally Khudairi 稱:“Apache 專案的活動在其整個生命週期中有起有落,這取決於社群的參與情況。從專案管理委員會(PMC)到董事會,對於 Apache 的幾個專案的審查和評估工作取得進展,我們投票決定,將這些專案束之高閣(Attic)。”
雖然 Apache 聲稱是常規的專案清理,但有觀點認為:單看個別專案的退役可能微不足道,但作為一個整體事件,這已經形成了一個分水嶺——幫助從業者和行業觀察這瞭解大資料領域開源力量重組的影響,Hadoop 在開源分析技術的霸主地位已讓給了 Spark。
另一方面,最新的聯合市場研究報告顯示,到 2027 年,全球 Hadoop 市場預計將達到 3403.5 億美元,相較於 2019 年為 267.4 億美元,2020-2027 年的複合年增長率為 37.5%。未來幾年,企業可能會通過混合雲方式進行資料儲存和分析,那麼,Hadoop 便還有機會在現有市場的基礎上壯大。
最後,引用撰稿人 Andrew Brust 對技術圈的一句評價:幾乎所有技術類別的炒作都得會得到週期性地教訓:社群變得興奮,開源技術激增,生態系統建立起來——但這些生態系統並非永垂不朽,幾乎任何新平臺都存在固有風險,無論是商業平臺還是開源平臺。
任何一個軟體都有自己的生命週期,邁入“中年”的 Hadoop 是能順勢而變接住挑戰,還是在新事物的衝擊下慢慢走下舞臺?現在,似乎還沒有答案。
- 悟空劉歧:技術瑕疵不除不快,開源社群程式碼說話
- 挖掘非結構化資料潛能——向量資料庫的探索之路
- 【直播回顧】開源許可證冷熱知識大揭祕
- BSL:MySQL 之父關於兼顧開源與活下去的解法
- Jina AI:定義開源神經搜尋,A 輪融資 2 個億
- 學習 Rust 你需要一個認知框架
- 雙許可,我開源的軟體只能我拿來賺錢
- 開放協作的世界裡,每一份貢獻都值得回報
- 開源軟體出口管制合規政策與管控策略研究
- 當你瞭解了 Apahce 的過去,你就瞭解了 Apache Way
- 社群糾紛不斷:程式設計師何苦為難程式設計師
- 婦女節,見證女性科技力量
- 中年 Hadoop
- 寫了開源軟體沒申專利,反被索賠該怎麼辦?
- 嚴父 Rust
- 成立兩年不談營收,這家公司在想什麼?
- “Dying since 1995”的 PHP 怎麼還活著
- Rust 社群求變,PHP 大旗不倒?
- 對話西喬霍炬,什麼塑造了今天的程式設計世界?
- 如何評價一個開源專案(三)——價值流網路