MySQL技術專題(6)這也許是你的知識盲區-MySQL主從架構以及[半同步機制]
MySQL的主從複製
-
一般在大規模的項目上,都是使用MySQL的複製功能來創建MySQL的主從集羣的。
-
主要是可以通過為數據庫服務器配置一個或多個備庫的方式來進行數據同步。
-
複製的功能不僅有利於構建高性能應用,同時也是高可用、可擴展性、災難恢復、備份以及數據倉庫等工作的基礎。
-
通過MySQL的主從複製來實現讀寫分離,相比單點數據庫又讀又寫來説,提升了業務系統性能,優化了用户體驗。
-
另外通過主從複製實現了數據庫的高可用,當主節點MySQL掛了的時候,可以用從庫來頂上。
MySQL支持的複製方式
MySQL支持三種複製方式
-
基於語句(Statement)的複製(也稱為邏輯複製)主要是指,在主數據庫上執行的SQL語句,在從數據庫上會重複執行一遍。
- 優點:MySQL默認採用的就是這種複製,效率比較高。
- 缺點:如果SQL中使用uuid()、rand()等函數,那麼複製到從庫的數據就會有偏差。
-
基於行(Row模式)的複製,指將更新處理後的數據複製到從數據庫,而不是執行一邊語句。從MySQL5.1的版本才被支持。
-
混合複製(Mixed),默認採用語句複製,當發現語句不能進行精準複製數據時-(例如語句中含有uuid()、rand()等函數),採用基於行的複製。
主從複製原理
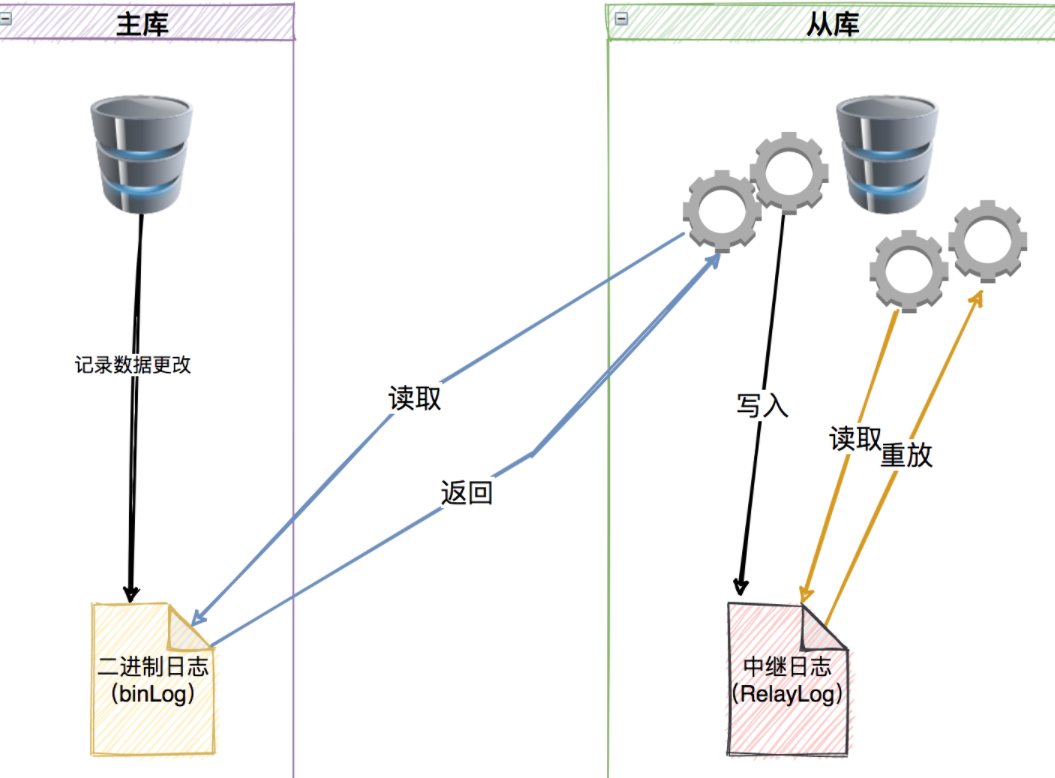
- MySQL的複製原理概述上來講大體可以分為這三步:
- 在主庫上把數據更改,記錄到二進制日誌(Binary Log)中。
- 從庫將主庫上的日誌複製到自己的中繼日誌(Relay Log)中。
- 備庫讀取中繼日誌中的事件,將其重放到備庫數據之上。
下面來詳細説一下複製的這三步:
- 第一步:是在主庫上記錄二進制日誌,
- 首先主庫要開啟binlog日誌記錄功能,
- 授權Slave從庫可以訪問的權限。
這裏需要注意的一點就是binlog的日誌裏的順序是按照事務提交的順序來記錄的而非每條語句的執行順序。
- 第二步:從庫將binLog複製到其本地的RelayLog中。
- 首先從庫會啟動一個工作線程,稱為I/O線程,I/O線程跟主庫建立一個普通的客户端連接,
- 然後主庫上啟動一個特殊的二進制轉儲(binlog dump)線程,此轉儲線程會讀取binlog中的事件。
- 當追趕上主庫後,會進行休眠,直到主庫通知有新的更新語句時才繼續被喚醒。
這樣通過從庫上的I/O線程和主庫上的binlog dump線程,就將binlog數據傳輸到從庫上的relaylog中了。
-
第三步:從庫中啟動一個SQL線程,從relaylog中讀取事件並在備庫中執行,從而實現備庫數據的更新。
- 這種複製架構實現了獲取事件和重放事件的解耦,運行I/O線程能夠獨立於SQL線程之外工作。
- 這種架構也限制複製的過程,最重要的一點是在主庫上併發運行的操作在備庫中只能串行化執行,因為只有一個SQL線程來重放中繼日誌中的事件。
- 數據或存在延遲和不一致性,所以如果要保證數據的一致性,一定要在主庫進行數據操作!
MySQL主從複製模式
MySQL的主從複製其實是支持,異步複製、半同步複製、GTID複製等多種複製模式的。
異步模式
MySQL的默認複製模式就是異步模式,主要是指MySQL的主服務器上的I/O線程,將數據寫到binlong中就直接返回給客户端數據更新成功,不考慮數據是否傳輸到從服務器,以及是否寫入到relaylog中。在這種模式下,複製數據其實是有風險的,一旦數據只寫到了主庫的binlog中還沒來得急同步到從庫時,就會造成數據的丟失。
- 這種模式確也是效率最高的,因為變更數據的功能都只是在主庫中完成就可以了,從庫複製數據不會影響到主庫的寫數據操作。
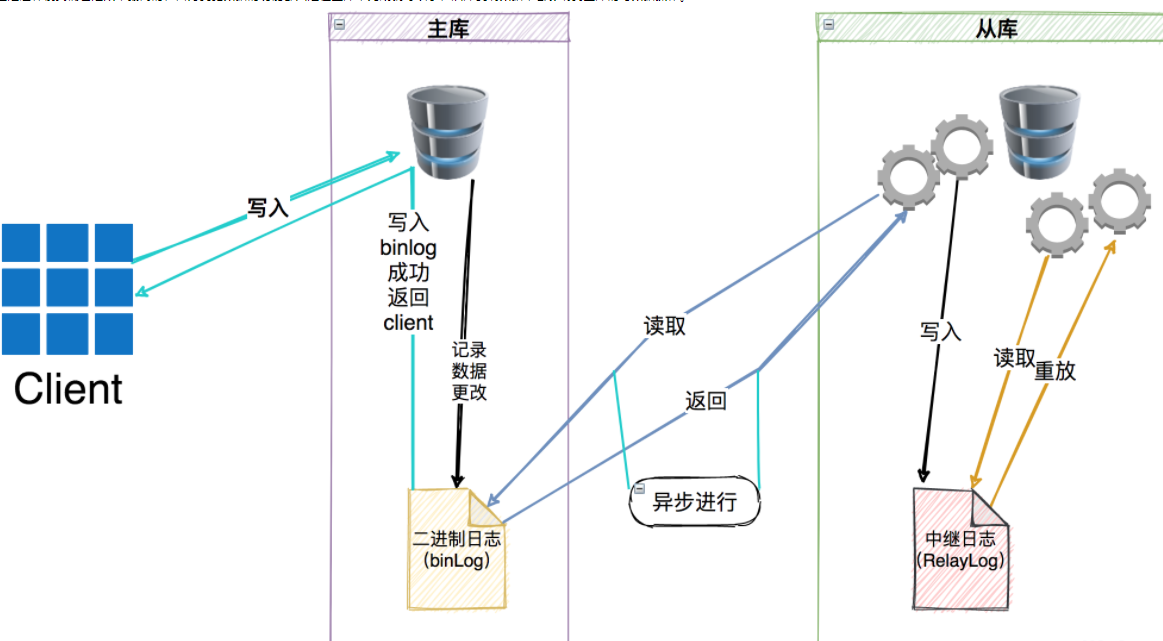
這種異步複製模式雖然效率高,但是數據丟失的風險很大,所以就有介紹的半同步複製模式。
半同步模式
MySQL從5.5版本開始通過以插件的形式開始支持半同步的主從複製模式,什麼是半同步主從複製模式呢?
-
異步複製模式:主庫在執行完客户端提交的事務後,只要將執行邏輯寫入到binlog後,就立即返回給客户端,並不關心從庫是否執行成功,這樣就會有一個隱患,就是在主庫執行的binlog還沒同步到從庫時,主庫掛了,這個時候從庫就就會被強行提升為主庫,這個時候就有可能造成數據丟失。
-
同步複製模式:當主庫執行完客户端提交的事務後,需要等到所有從庫也都執行完這一事務後,才返回給客户端執行成功。因為要等到所有從庫都執行完,執行過程中會被阻塞,等待返回結果,所以性能上會有很嚴重的影響。
-
半同步複製模式:半同步複製模式,可以説是介於異步和同步之間的一種複製模式,主庫在執行完客户端提交的事務後,要等待至少一個從庫接收到binlog並將數據寫入到relay log中才返回給客户端成功結果。半同步複製模式,比異步模式提高了數據的可用性,但是也產生了一定的性能延遲,最少要一個TCP/IP連接的往返時間。
- 半同步複製模式,可以很明確的知道,在一個事務提交成功之後,此事務至少會存在於兩個地方一個是主庫一個是從庫中的某一個。
- 在master的dump線程去通知從庫時,增加了一個ACK機制,也就是會確認從庫是否收到事務的標誌碼,master的dump線程不但要發送binlog到從庫,還有負責接收slave的ACK。當出現異常時,Slave沒有ACK事務相應,為了保證性能會那麼將自動降級為異步複製,直到異常修復後再自動變為半同步複製。
MySQL半同步複製的流程如下
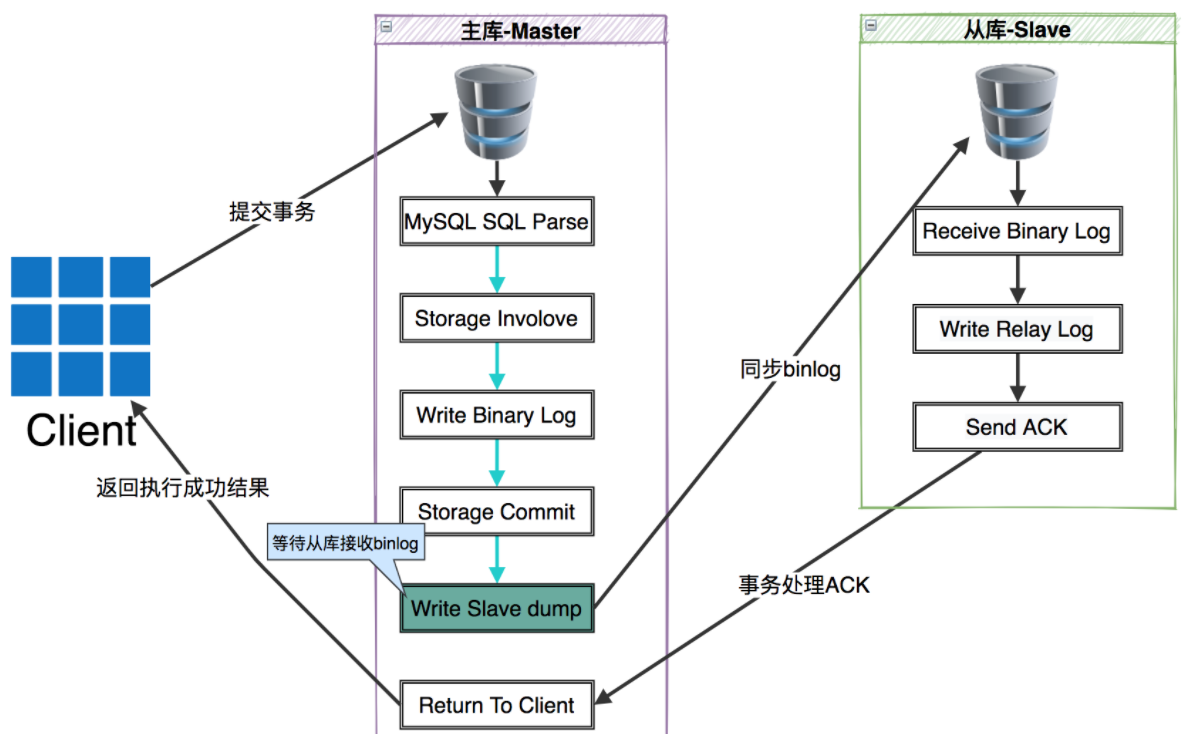
半同步複製的隱患
半同步複製模式也存在一定的數據風險,當事務在主庫提交完後等待從庫ACK的過程中,如果Master宕機了,這個時候就會有兩種情況的問題。
-
事務還沒發送到Slave上:若事務還沒發送Slave上,客户端在收到失敗結果後,會重新提交事務,因為重新提交的事務是在新的Master上執行的,所以會執行成功,後面若是之前的Master恢復後,會以Slave的身份加入到集羣中,這個時候,之前的事務就會被執行兩次,
- 第一次是之前此台機器作為Master的時候執行的,
- 第二次是做為Slave後從主庫中同步過來的。
-
事務已經同步到Slave上:因為事務已經同步到Slave了,所以當客户端收到失敗結果後,再次提交事務,你那麼此事務就會再當前Slave機器上執行兩次。
-
為了解決上面的隱患,MySQL從5.7版本開始,增加了一種新的半同步方式,新的半同步方式的執行過程是將“Storage Commit”這一步移動到了“Write Slave dump”後面。
-
這樣保證了只有Slave的事務ACK後,才提交主庫事務。MySQL 5.7.2版本新增了一個參數來進行配置:rpl_semi_sync_master_wait_point,此參數有兩個值可配置:
-
AFTER_SYNC:參數值為AFTER_SYNC時,代表採用的是新的半同步複製方式。
-
AFTER_COMMIT:代表採用的是之前的舊方式的半同步複製模式。
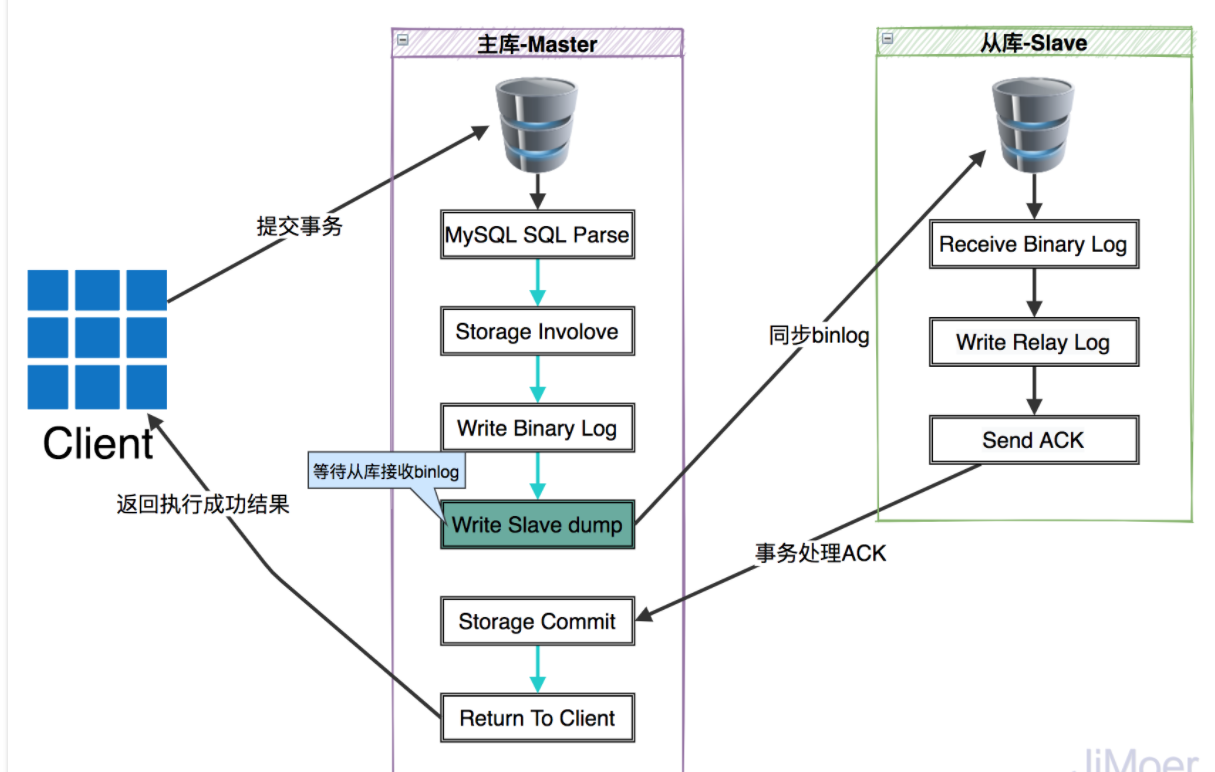
MySQL從5.7.2版本開始,默認的半同步複製方式就是AFTER_SYNC方式了,但是方案不是萬能的,因為AFTER_SYNC方式是在事務同步到Slave後才提交主庫的事務的,若是當主庫等待Slave同步成功的過程中Master掛了,這個Master事務提交就失敗了,客户端也收到了事務執行失敗的結果了,但是Slave上已經將binLog的內容寫到Relay Log裏了,這個時候,Slave數據就會多了,但是多了數據一般問題不算嚴重,多了總比少了好。
半同步複製模式的參數:
mysql> show variables like '%Rpl%';
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
| rpl_stop_slave_timeout | 31536000 |
+-------------------------------------------+------------+
- 半同步複製模式開關: rpl_semi_sync_master_enabled
- rpl_semi_sync_master_timeout:半同步複製,超時時間,單位毫秒,當超過此時間後,自動切換為異步複製模式
MySQL 5.7.3引入的,該變量設置主需要等待多少個slave應答,才能返回給客户端,默認為1。
- rpl_semi_sync_master_wait_for_slave_count:此值代表當前集羣中的slave數量是否還能夠滿足當前配置的半同步複製模式,默認為ON,當不滿足半同步複製模式後,全部Slave切換到異步複製,此值也會變為OFF
- rpl_semi_sync_master_wait_no_slave: 代表半同步複製提交事務的方式,5.7.2之後,默認為AFTER_SYNC
- rpl_semi_sync_master_wait_point
GTID模式
MySQL從5.6版本開始推出了GTID複製模式,GTID即全局事務ID (global transaction identifier)的簡稱,GTID是由UUID+TransactionId組成的,UUID是單個MySQL實例的唯一標識,在第一次啟動MySQL實例時會自動生成一個server_uuid, 並且默認寫入到數據目錄下的auto.cnf(mysql/data/auto.cnf)文件裏。TransactionId是該MySQL上執行事務的數量,隨着事務數量增加而遞增。這樣保證了GTID在一組複製中,全局唯一。
這樣通過GTID可以清晰的看到,當前事務是從哪個實例上提交的,提交的第多少個事務。
來看一個GTID的具體形式:
mysql> show master status;
+-----------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------+----------+--------------+------------------+-------------------------------------------+
| on.000003 | 187 | | | 76147e28-8086-4f8c-9f98-1cf33d92978d:1-322|
+-----------+----------+--------------+------------------+-------------------------------------------+
1 row in set (0.00 sec)
GTID:76147e28-8086-4f8c-9f98-1cf33d92978d:1-322 UUID:76147e28-8086-4f8c-9f98-1cf33d92978d TransactionId:1-322
GTID的工作原理
由於GTID在一組主從複製集羣中的唯一性,從而保證了每個GTID的事務只在一個MySQL上執行一次。那麼是怎麼實現這種機制的呢?GTID的原理又是什麼樣的呢?
- 當從服務器連接主服務器時,把自己執行過的GTID(Executed_Gtid_Set: 即已經執行的事務編碼)以及獲取到GTID(Retrieved_Gtid_Set: 即從庫已經接收到主庫的事務編號)都傳給主服務器。
- 主服務器會從服務器缺少的GTID以及對應的transactionID都發送給從服務器,讓從服務器補全數據。當主服務器宕機時,會找出同步數據最成功的那台conf服務器,直接將它提升為主服務器。
- 若是強制要求某一台不是同步最成功的一台從服務器為主,會先通過change命令到最成功的那台服務器,將GTID進行補全,然後再把強制要求的那台機器提升為主。
主要數據同步機制可以分為這幾步:
- master更新數據時,在事務前生產GTID,一同記錄到binlog中。
- slave端的i/o線程,將變更的binlog寫入到relay log中。
- sql線程從relay log中獲取GTID,然後對比Slave端的binlog是否有記錄。
- 如果有記錄,説明該GTID的事務已經執行,slave會忽略該GTID。
- 如果沒有記錄,Slave會從relay log中執行該GTID事務,並記錄到binlog。
- 在解析過程中,判斷是否有主鍵,如果沒有主鍵就使用二級索引,再沒有二級索引就掃描全表。
GTID的優劣勢
通過上面的分析我們可以得出GTID的優勢是:
- 每一個事務對應一個執行ID,一個GTID在一個服務器上只會執行一次;
- GTID是用來代替傳統複製的方法,GTID複製與普通複製模式的最大不同就是不需要指定二進制文件名和位置;
- 減少手工干預和降低服務故障時間,當主機掛了之後通過軟件從眾多的備機中提升一台備機為主機;
GTID的缺點:
- 首先不支持非事務的存儲引擎;
- 不支持create table ... select 語句複製(主庫直接報錯);(原理: 會生成兩個sql, 一個是DDL創建表SQL, 一個是insert into 插入數據的sql; 由於DDL會導致自動提交, 所以這個sql至少需要兩個GTID, 但是GTID模式下, 只能給這個sql生成一個GTID)
- 不允許一個SQL同時更新一個事務引擎表和非事務引擎表;
- 在一個MySQL複製羣組中,要求全部開啟GTID或關閉GTID。
- 開啟GTID需要重啟 (mysql5.7除外);
- 開啟GTID後,就不再使用原來的傳統複製方式(不像半同步複製,半同步複製失敗後,可以降級到異步複製);
- 對於create temporary table 和 drop temporary table語句不支持;
- 不支持sql_slave_skip_counter;
開啟GTID的必備條件:
MySQL 5.6 版本,在my.cnf文件中添加:
gtid_mode=on (必選) #開啟gtid功能
log_bin=log-bin=mysql-bin (必選) #開啟binlog二進制日誌功能
log-slave-updates=1 (必選) #也可以將1寫為on
enforce-gtid-consistency=1 (必選) #也可以將1寫為on
MySQL 5.7或更高版本,在my.cnf文件中添加:
gtid_mode=on (必選)
enforce-gtid-consistency=1 (必選)
log_bin=mysql-bin (可選) #高可用切換,最好開啟該功能
log-slave-updates=1 (可選) #高可用切換,最好打開該功能
- 完整秒殺架構的設計到技術關鍵點的“情報信息”
- 獨一無二的「MySQL調優金字塔」相信也許你擁有了它,你就很可能擁有了全世界。
- 【MySQL技術之旅】(5)該換換你的數據庫版本了,讓我們一同迎接8.0的到來哦!(初探篇)
- ☕【Java技術指南】「Java8編程專題」讓你真正會用對Java新版日期時間API編程指南
- 【Fegin技術專題】「原生態」打開Fegin之RPC技術的開端,你會使用原生態的Fegin嗎?(高級用法)
- 【優化技術專題】「線程間的高性能消息框架」終極關注Disruptor的核心源碼和Java8的@Contended偽共享指南
- 【優化技術專題】「線程間的高性能消息框架」再次細節領略Disruptor的底層原理和優勢分析
- 【Zookeeper核心原理】Paxos協議的原理和實際運行中的應用流程分析
- ☕【Java技術指南】「JPA編程專題」讓你不再對JPA技術中的“持久化型註解”感到陌生了!
- Java技術開發專題系列之【Guava RateLimiter】針對於限流器的入門到精通(含源碼分析介紹)
- ☕【Java技術指南】「JPA編程專題」讓你不再對JPA技術中的“持久化型註解”感到陌生了!
- 【Eureka技術指南】「SpringCloud」從源碼層面讓你認識Eureka工作流程和運作機制(下)
- MySQL技術專題(6)這也許是你的知識盲區-MySQL主從架構以及[半同步機制]
- 優化技術專題-線程間的高性能消息框架-深入淺出Disruptor的使用和原理
- ☕【Java技術指南】「併發編程專題」Fork/Join框架基本使用和原理探究(原理篇)
- ☕【Java技術指南】「併發編程專題」Guava RateLimiter針對於限流器的入門到精通(含源碼分析介紹)
- 【優化技術專題】「温故而知新」基於Quartz系列的任務調度框架的動態化任務實現分析
- ☕【Java技術指南】「併發編程專題」Guava RateLimiter針對於限流器的入門到精通(含實戰和原理分析)
- 【MySQL技術之旅】(4)這也許是你的知識盲區-[MySQL主從架構]之半同步機制
- ☕【Java技術指南】「併發編程專題」CompletionService框架基本使用和原理探究(基礎篇)