electron 應用開發優秀實踐
vivo 網際網路前端團隊-Yang Kun
一、背景
在團隊中,我們因業務發展,需要用到桌面端技術,如離線可用、呼叫桌面系統能力。什麼是桌面端開發?一句話概括就是:以 Windows 、macOS 和 Linux 為作業系統的軟體開發。對此我們做了詳細的技術調研,桌面端的開發方式主要有 Native 、 QT 、 Flutter 、 NW 、 Electron 、 Tarui 。其各自優劣勢如下表格所示:
我們最終的桌面端技術選型是 Electron ,Electron 是一個可以使用 Web 技術來開發跨平臺桌面應用的開發框架。
其技術組成如下:
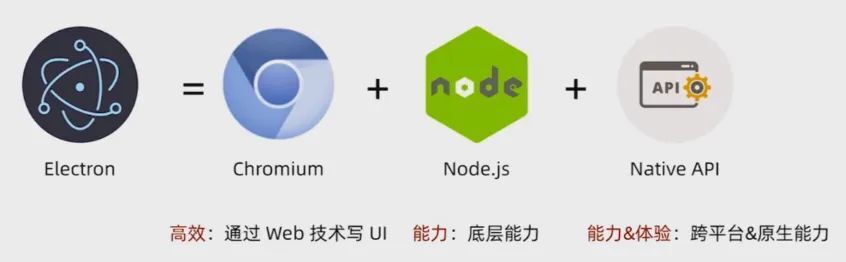
Electron = Chromium + Node.js + Native API
各技術能力如下圖所示:
整體架構如下圖所示:
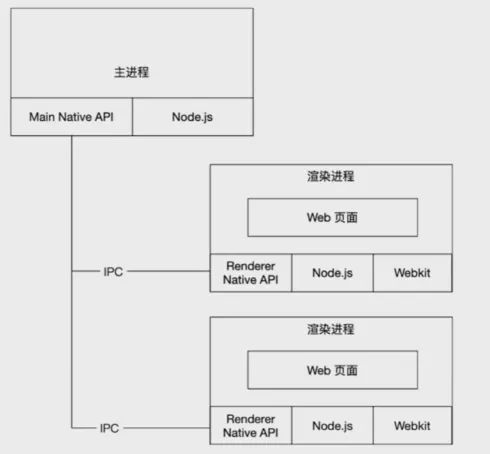
Electron 是多程序架構,架構具有以下特點:
- 由一個主程序和 N 個渲染程序組成
- 主程序承擔主導作用,用於完成各種跨平臺和原生互動
- 渲染程序可以是多個,使用 Web 技術開發,通過瀏覽器核心渲染頁面
- 主程序和渲染程序通過程序間通訊來完成各種功能
這裡說下 Electron 程序間通訊技術原理:
electron 使用 IPC (interprocess communication) 在程序之間進行通訊,如下圖所示:
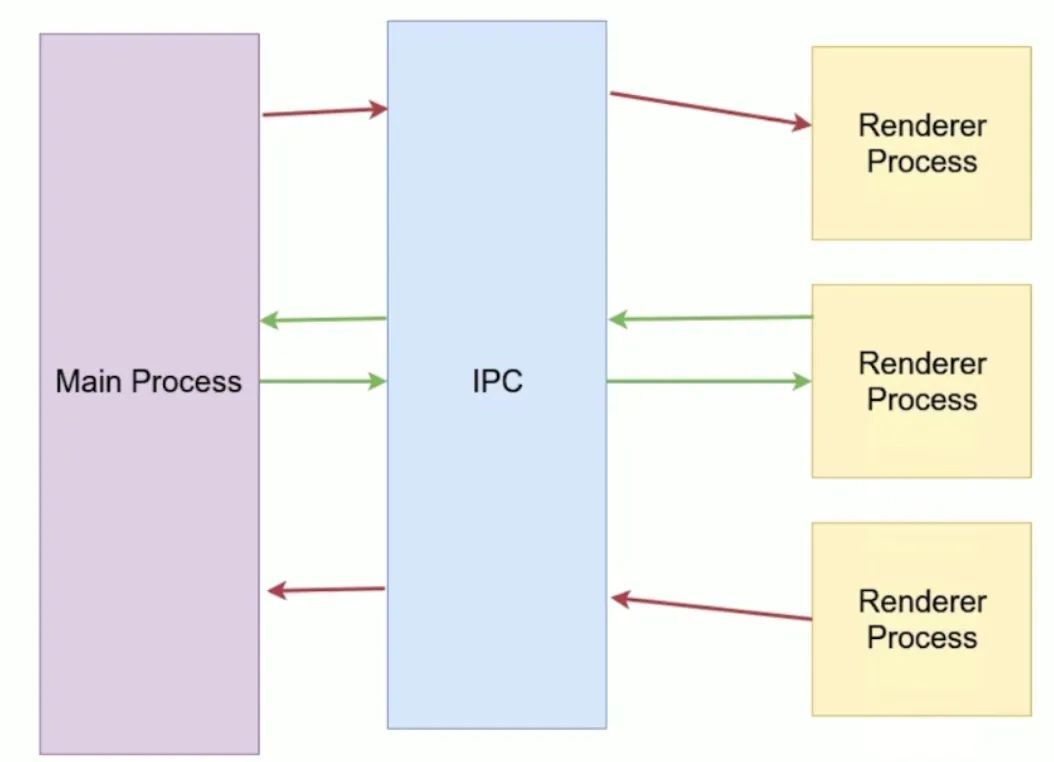
其提供了 IPC 通訊模組,主程序的 ipcMain 和渲染程序的 ipcRenderer。
從 electron 原始碼中可以看出, ipcMain 和 ipcRenderer 都是 EventEmitter 物件,原始碼如下圖所示:
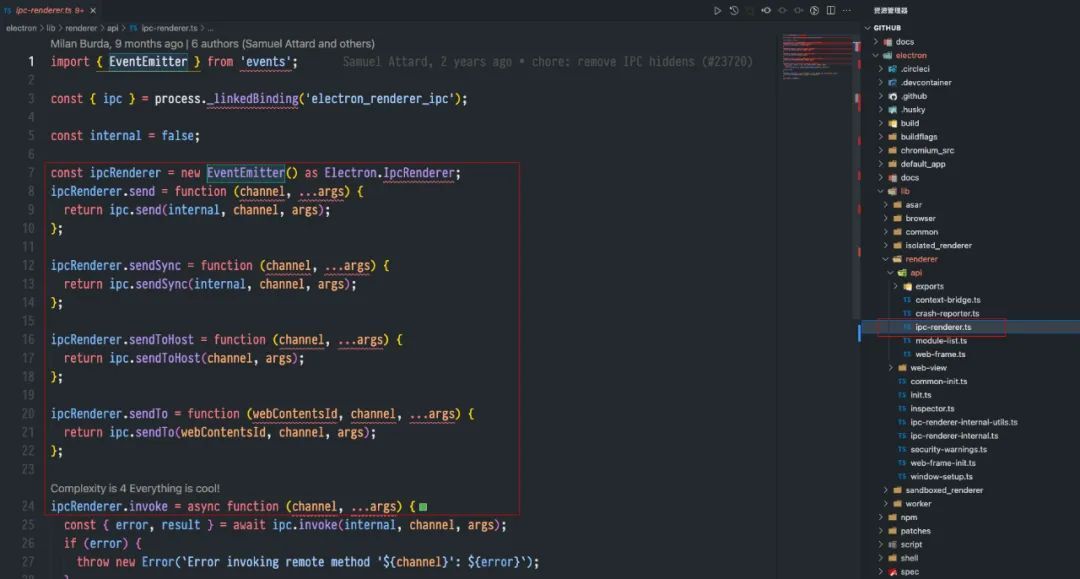
看到原始碼實現,是不是覺得 IPC 不難理解了。知其本質,方可遊刃有餘。
看到這,我們回顧上文技術表格,看到 Electron 應用包體積大,那體積大的根本原因是什麼呢?
其實這和 chromium 的框架設計有關,其對很多功能都沒有巨集控制,導致很難把龐大複雜的細節功能去除掉,也造成了基於 chromium 的開發框架,如 electron 、 nwjs 打出的包起步就是 100 多 M 。
綜上,electron 具有跨端、基於 Web 、超強生態等優點,是桌面端開發的優秀方案之一。下文將介紹 electron 應用開發實踐經驗,包括應用技術選型和常用功能。
二、應用技術選型
2.1 程式語言 Typescript
理由如下:
-
針對開發者
- Javascript 的超集 - 無縫支援所有的 es2020+ 所有的特性,學習成本小
- 編譯生成的 JavaScript 的程式碼保持很好的可讀性
- 可維護性明顯增強
- 完整的 OOP 的支援 - extends, interface, private, protect, public等
- 型別即文件
- 型別的約束,更少的單元測試的覆蓋
- 更安全的程式碼
-
針對工具
- 更好的重構能力
- 靜態分析自動導包
- 程式碼錯誤檢查
- 程式碼跳轉
- 程式碼提示補齊
-
社群
大量的社群的型別定義檔案 提升開發效率
2.2 構建工具 Electron-Forge
理由:簡單而又強大,目前 electron 應用最好的構建工具之一。
這裡提一下 electron-builder 其和 electron-forge 的介紹和區別,看下圖所示:
兩者最大的區別在於自由度,兩者在能力上基本沒什麼差異了,從官方組織中的排序看,有意優先推薦 electron-forge 。
2.3 Web 方案 Vue3 + Vite
我們採用的是 Vue3 ,同時使用 Vite 作為構建工具,具體優點,大家可以檢視官網介紹,這套組合是目前主流的 Web 開發方案。
2.4 monorepo方案 pnpm + turbo
目前的 monorepo 生態百花齊放,正確的實踐方法應該是集大成法,也就是取各家之長,目前的趨勢也是如此,各開源 monorepo 工具達成默契,專注自己擅長的能力。
如 pnpm 擅長依賴管理, turbo 擅長構建任務編排。遂在 monorepo 技術選型上,我選擇了 pnpm 和 turbo 。
pnpm 理由如下:
- 目前最好的包管理工具, pnpm 吸收了 npm 、 yarn 、 lerna 等主流工具的精華,並去其糟粕。
- 生態、社群活躍且強大
- 結合 workspace 可以完成 monorepo 最佳設計和實踐
- 在管理多專案的包依賴、程式碼風格、程式碼質量、元件庫複用等場景下,表現出色
- 在框架、庫的開發、除錯、維護方面,表現出色
相比於 vue 官網,在使用 pnpm 上,我加了 workspace 。
turbo 理由如下:
- 它是一個高效能構建系統,擁有增量構建、雲快取、並行執行、執行時零開銷、任務管道、精簡子集等特性
- 具有非常優秀的任務編排能力,可以彌補 pnpm 在任務編排上的短板
2.5 資料庫 lowdb
electron 應用資料庫有非常多的選擇如 lowdb 、 sqlite3 、 electron-store 、 pouchdb 、 dedb 、 rxdb 、 dexie 、 ImmortalDB 等。這些資料庫都有一個特性,那就是無伺服器。
electron 應用資料庫技術選型考慮因素主要有以下3點:
- 生態(使用者數量、維護頻率、版本穩定度)
- 能力
- 效能
- 其他(和使用者技術匹配度)
我們通過以下渠道進行了相關調研
- github 的 issues、commit、fork、star
- sourcegraph 關鍵字搜尋結果數
- npm 包下載量、版本釋出
- 官網和部落格
給出四個最優選擇,分別是 lowdb 、 sqlite3 、 nedb 、 electron-store , 理由如下:
- lowdb: 生態、能力、效能三方面表現優秀, json 形式的儲存結構, 支援 lodash 、 ramda 等 api 操作,利於備份和呼叫
- sqlite3: 生態、能力、效能三方面表現優秀, Nodejs 關係型資料庫第一選擇方案
- nedb: 能力、效能三方面表現優秀,缺點是基本不維護了,但底子還在,尤其操作是 MongoDB 的子集,對於熟悉 MongoDB 的使用者來說是絕佳選擇。
- electron-store: 生態表現優秀,輕量級持久化方案,簡單易用
我們使用的資料庫選型是 lowdb 方案。
PS:提一下 pouchdb ,如果需要將本地資料同步到遠端資料庫,可以使用 pouchdb ,其和 couchdb 可以輕鬆完成同步。
2.6 指令碼工具 zx
軟體開發過程中,將一些流程和操作通過指令碼來完成,可以有效地提高開發效率和幸福度。
依賴 node runtime 的優秀選擇就兩個:shelljs 和 zx , 選擇 zx 的理由如下:
- 自帶 fetch 、 chalk 等常用庫,使用方便快捷
- 多個子程序方便快捷、執行遠端指令碼、解析 md 、 xml 檔案指令碼、支援 ts ,功能豐富且強大
- 谷歌出品,大廠背景,生態非常活躍
至此,技術選型就介紹完了,下面我將介紹electron 應用的常用功能。
三、構建
此部分主要介紹以下5點內容:
- 應用圖示生成
- 二進位制檔案構建
- 按需構建
- 效能優化
- 跨平臺相容
3.1 應用圖示生成
不同尺寸圖示的生成有以下方法:
Windows
- 軟體生成: icofx3
- 網頁生成: http://tool.520101.com/diannao/ico/(opens new window)
MacOS
- 軟體生成: icofx3
- 網頁生成: http://tool.520101.com/diannao/ico/(opens new window)
- 命令列生成: 使用 sips 和 iconutil 生成
3.2 二進位制檔案構建
本章節內容是基於 electron-forge 闡述的,不過原理是一樣的。
在開發桌面端應用時,會有場景要用到第三方的二進位制程式,比如 ffmpeg 這種。在構建二進位制程式時,要關注以下兩個注意項:
(1)二進位制程式不能打包進 asar 中 可以在構建配置檔案(forge.config.js)進行如下設定:
const os = require('os')
const platform = os.platform()
const config = {
packagerConfig: {
// 可以將 ffmpeg 目錄打包到 asar 目錄外面
extraResource: [`./src/main/ffmpeg/`]
}
}(2)開發和生產環境,獲取二進位制程式路徑方法是不一樣的 可以採用如下程式碼進行動態獲取:
import { app } from 'electron'
import os from 'os'
import path from 'path'
const platform = os.platform()
const dir = app.getAppPath()
let basePath = ''
if(app.isPackaged) basePath = path.join(process.resourcesPath)
else basePath = path.join(dir, 'ffmpeg')
const isWin = platform === 'win32'
// ffmpeg 二進位制程式路徑
const ffmpegPath = path.join(basePath, `${platform}`, `ffmpeg${isWin ? '.exe' : ''}`)3.3 按需構建
如何對跨平臺二進位制檔案進行按需構建呢?
比如桌面應用中用到了 ffmpeg , 它需要有 windows 、 mac 和 linux 的下載二進位制。在打包的時候,如果不做按需構建,則會將 3 個二進位制檔案全部打到構建中,這樣會讓應用體積增加很多。
可以在 forge.config.js 配置檔案中進行如下配置,即可完成按需構建,程式碼如下:
const platform = os.platform()
const config = {
packagerConfig: {
extraResource: [`./src/main/ffmpeg/${platform}`]
},
}通過 platform 變數來把對應系統的二進位制打到構建中,即可完成對二進位制檔案的按需構建。
3.4 效能優化
主要是構建速度和構建體積優化,構建速度這塊不好優化。本文重點說下構建體積優化,這裡拿 mac 系統舉例說明, 在 electron 應用打包後,檢視應用包內容,如下圖所示:
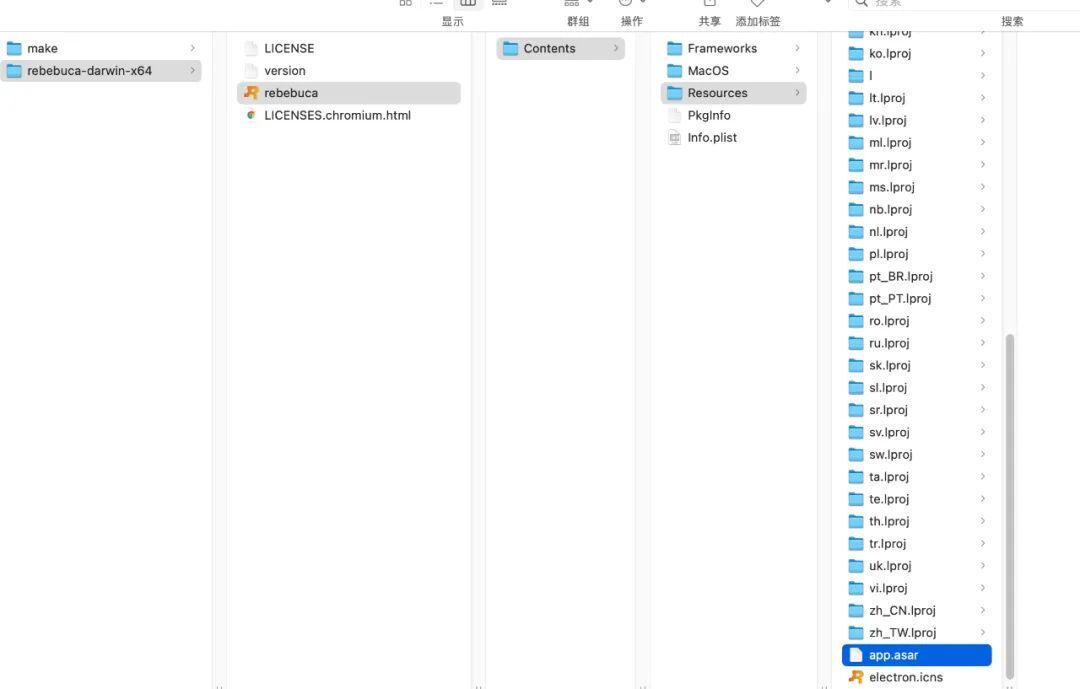
可以看到有一個 app.asar 檔案,這個檔案用 asar 解壓後可以看到有以下內容:

可以看出 asar 中的檔案,就是我們構建後的專案程式碼,從圖中可以看到有 node_modules 目錄, 這是因為在 electron 構建機制中,會自動把 dependencies 的依賴全部打到 asar 中。
所以結合上述分析,我們的優化措施有以下4點:
- 將 web 端構建所需的依賴全部放到 devDependencies 中,只將在 electron 端需要的依賴放到 dependencies
- 將和生產無關的程式碼和檔案從構建中剔除
- 對跨平臺使用的二進位制檔案,如 ffmpeg 進行按需構建(上文按需構建已介紹)
- 對 node_modules 進行清理精簡
這裡提下第 4 點,如何對 node_modules 進行清理精簡呢?
如果是 yarn 安裝的依賴,我們可以在根目錄使用下面命令進行精簡:
yarn autoclean -I
yarn autoclean -F
如果是 pnpm 安裝的依賴,第 4 點應該不起作用了。我在專案中使用 yarn 安裝依賴,然後執行上述命令後,發現打包體積減少了 6M , 雖然不多,但也還可以。
至此,構建功能就介紹完了。
四、更新
本章節主要分為以下兩個方面:
- 全量更新
- 增量更新
下面將依次介紹上述兩種更新
4.1 全量更新
通過下載最新的包或者 zip 檔案,進行軟體更新,需要替換所有的檔案。
整體設計流程圖如下:
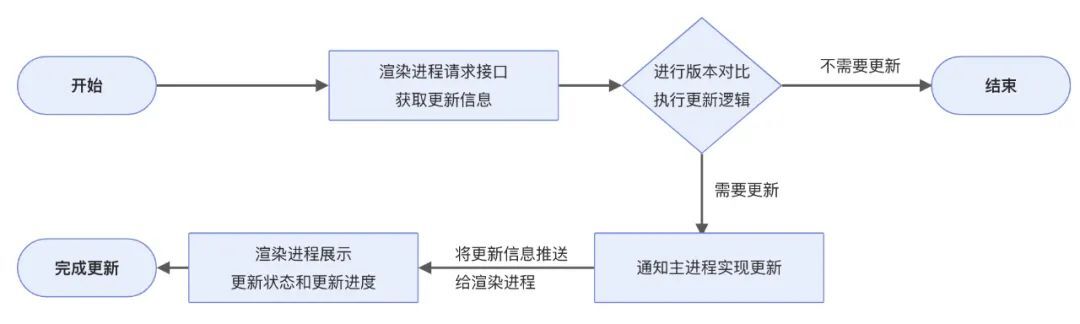
按照流程圖去實現,我們需要做以下事情:
- 開發服務端介面,用來返回應用最新版本資訊
- 渲染程序使用 axios 等工具請求介面,獲取最新版本資訊
- 封裝更新邏輯,用來對介面返回的版本資訊進行綜合比較,判斷是否更新
- 通過 ipc 通訊將更新資訊傳遞給主程序
- 主程序通過 electron-updater 進行全量更新
- 將更新資訊通過 ipc 推送給渲染程序
- 渲染程序向用戶展示更新資訊,若更新成功,則彈出彈窗告訴使用者重啟應用,完成軟體更新
4.2 增量更新
通過拉取最新的渲染層打包檔案,覆蓋之前的渲染層程式碼,完成軟體更新,此方案只需替換渲染層程式碼,無需替換所有檔案。
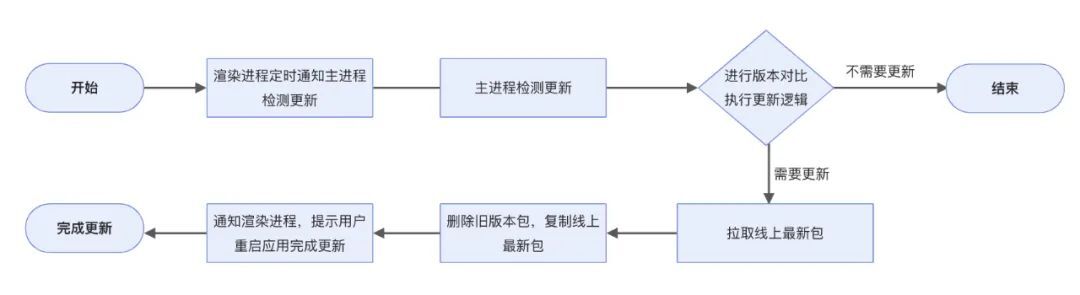
按照流程圖去實現,我們需要做以下事情
- 渲染程序定時通知主程序檢測更新
- 主程序檢測更新
- 需要更新,則拉取線上最新包
- 刪除舊版本包,複製線上最新包,完成增量更新
- 通知渲染程序,提示使用者重啟應用完成更新
全量更新和增量更新各有優勢,多數情況下,採用增量更新來提高使用者更新體驗,同時使用全量更新作為兜底更新方案。
至此,更新功能就介紹完了。
五、效能優化
分為以下3個方面:
- 構建優化
- 啟動時優化
- 執行時優化
構建優化在上文內容中,已經詳細介紹過了,這裡不再介紹,下面將介紹 啟動時優化 和 執行時優化。
5.1 啟動時優化
- 使用 v8-compile-cache 快取編譯程式碼
- 優先載入核心功能,非核心功能動態載入
- 使用多程序,多執行緒技術
- 採用 asar 打包:會加快啟動速度
- 增加視覺過渡:loading + 骨架屏
5.1.1 使用 v8-compile-cache 快取編譯程式碼
使用 V8 快取資料,為什麼要這麼做呢?
因為 electorn 使用 V8 引擎執行 js , V8 執行 js 時,需要先進行解析和編譯,再執行程式碼。其中,解析和編譯過程消耗時間多,經常導致效能瓶頸。而 V8 快取功能,可以將編譯後的位元組碼快取起來,省去下一次解析、編譯的時間。
主要使用 v8-compile-cache 來快取編譯的程式碼,做法很簡單:在需要快取的地方加一行
require('v8-compile-cache')其他使用方法請檢視此連結文件 http://www.npmjs.com/package/v8-compile-cache(opens new window)
5.1.2 優先載入核心功能,非核心功能動態載入
虛擬碼如下:
export function share() {
const kun = require('kun')
kun()
}5.2 執行時優化
- 對渲染程序 進行 Web 效能優化
- 對主程序進行輕量瘦身
5.2.1 對渲染程序 進行 Web 效能優化
用一個思維導圖來完整闡述如何進行 Web 效能優化,如下圖所示:
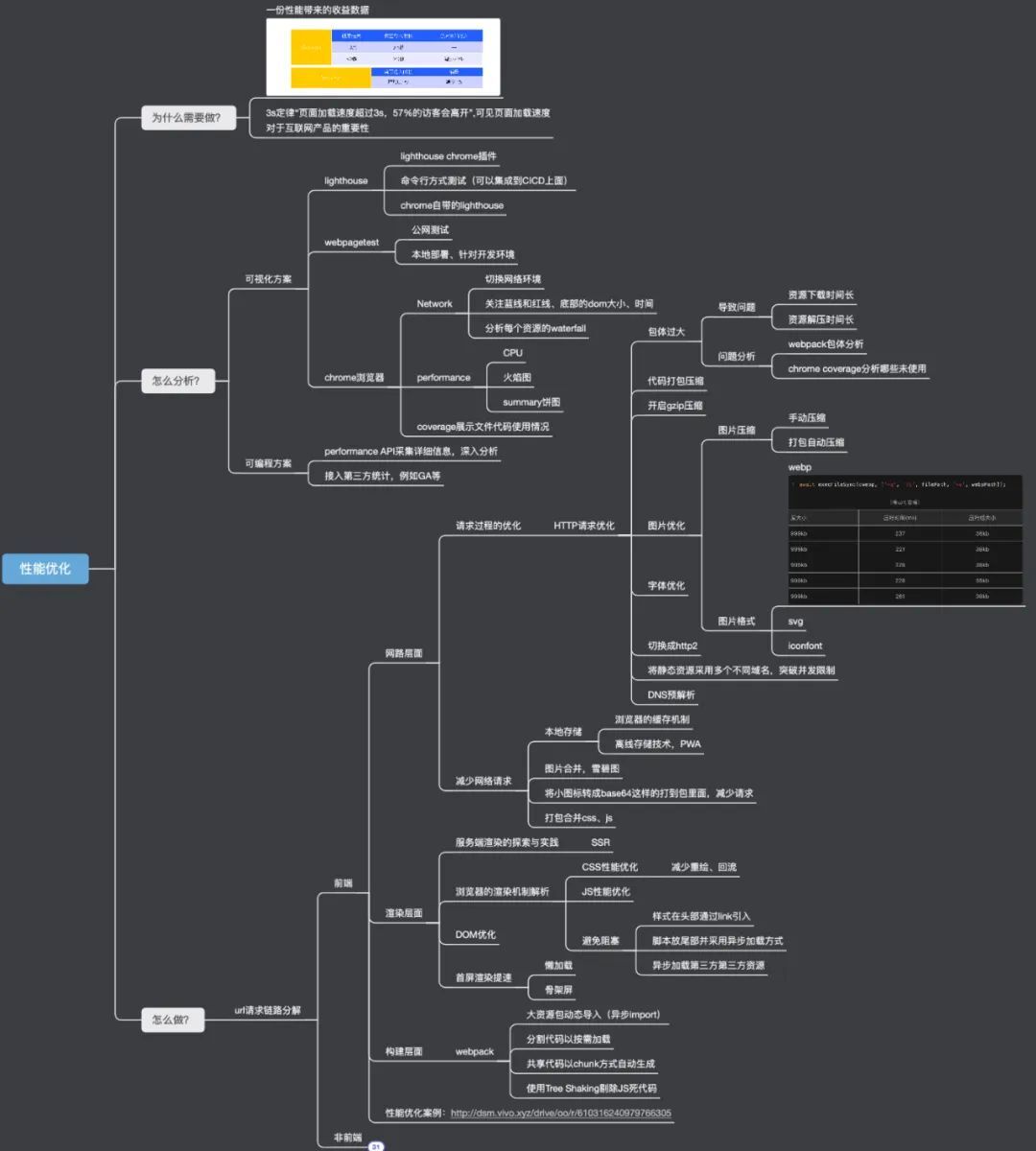
上圖基本包含了效能優化的核心關鍵點和內容,大家可以以此作為參考,去做效能優化。
5.2.2 對主程序進行輕量瘦身
核心方案就是將執行時耗時、計算量大的功能交給新開的 node 程序去執行處理。
虛擬碼如下:
const { fork } = require('child_process')
let { app } = require('electron')
function createProcess(socketName) {
process = fork(`xxxx/server.js`, [
'--subprocess',
app.getVersion(),
socketName
])
}
const initApp = async () => {
// 其他初始化程式碼...
let socket = await findSocket()
createProcess(socket)
}
app.on('ready', initApp)通過以上程式碼,將耗時、計算量大的功能,放在 server.js ,然後再 fork 到新開 node 程序中進行處理。
至此,效能優化就介紹完了。
六、質量保障
質量保障的全流程措施如下圖所示:
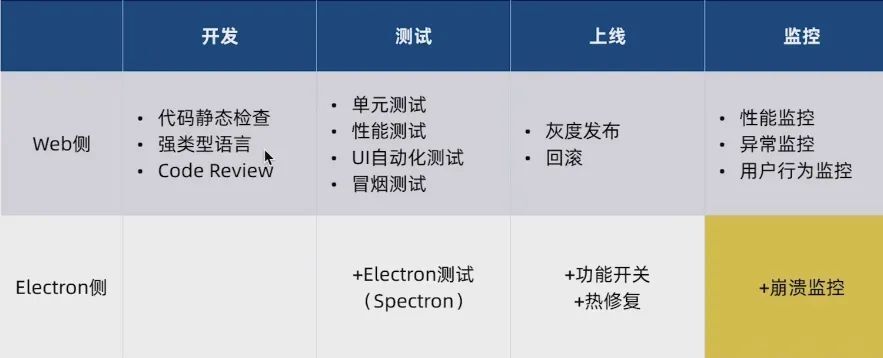
本章節主要介紹以下3個方面:
- 自動化測試
- 崩潰監控
- 崩潰治理
下面將會依次介紹上述內容。
6.1 自動化測試
自動化測試是什麼?

上圖是做自動化測試一個完整步驟,大家可以看圖領會。
自動化測試主要分為 單元測試、整合測試、端到端測試,三者關係如下圖所示:

一般情況下,作為軟體工程師,我們做到一定的單元測試就可以了。而且從我目前經驗來說,如果是寫業務性質的專案,基本上不會編寫測試相關的程式碼。自動化測試主要是用來編寫庫、框架、元件等需要作為單獨個體提供給他人使用的。
electron 的測試工具推薦 vitest 、 spectron 。具體用法參考官網文件即可,沒什麼特別的技巧。
6.2 崩潰監控
對於 GUI 軟體,尤其桌面端軟體來說,崩潰率非常重要,因此需要對崩潰進行監控。
崩潰監控原理如下圖所示:
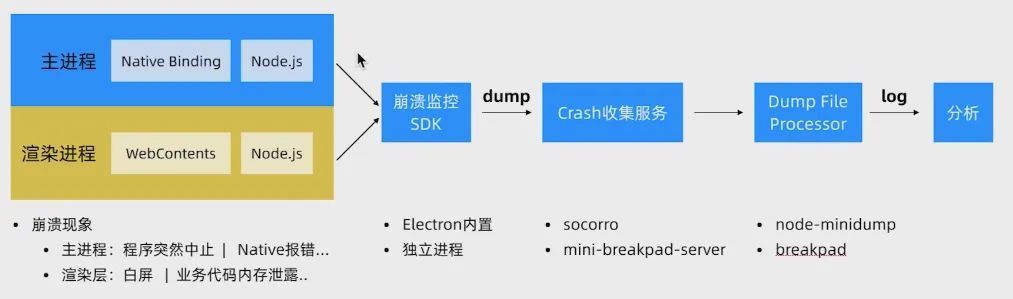
崩潰監控技巧
- 渲染程序崩潰後,提示使用者重新載入
- 通過 preload 統一初始化崩潰監控
- 主程序、渲染程序通過 process.crash() 進行模擬崩潰
- 對崩潰日誌進行收集分析
崩潰監控做好後,如果發生崩潰,該如何治理崩潰呢?
6.3 崩潰治理
崩潰治理難點:
- 定位出錯棧困難:Native 錯誤棧,無操作上下文
- 除錯門檻高:C++ 、 IIdb/GDB
- 執行環境複雜:機器型號、系統、其他軟體
崩潰治理技巧:
- 及時升級 electron
- 使用者操作日誌和系統資訊
- 復現和定位問題比治理重要
- 把問題交給社群解決,社群響應快
- 善於用 devtool 分析和治理記憶體問題
七、安全
俗話說的好,安全大於天,保證 electron 應用的安全也是一項重要的事情,本章節將安全分為以下 5 個方面:
- 原始碼洩漏
- asar
- 原始碼保護
- 應用安全
- 編碼安全
下面將會依次介紹上述內容。
7.1 原始碼洩漏
目前 electron 在原始碼安全做的不好,官方只用 asar 做了一下很沒用的原始碼保護,到底有多沒用呢?
你只需要下載 asar 工具,然後對 asar 檔案進行解壓就可以得到裡面的原始碼了,如下圖所示:
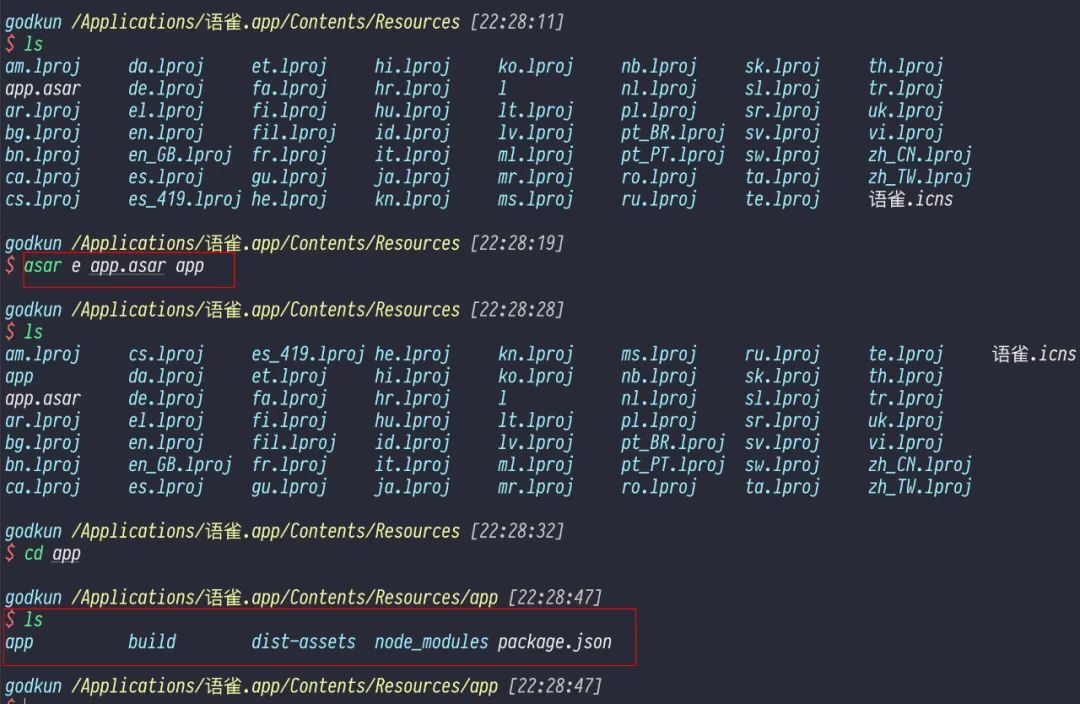
通過圖中操作即可看到語雀應用的原始碼。上面提到的 asar 是什麼呢?
7.2 asar
asar 是一種將多個檔案合併成一個檔案的類 tar 風格的歸檔格式。Electron 可以無需解壓整個檔案,即可從其中讀取任意檔案內容。
asar 技術原理:
可以直接看 electron 原始碼,都是 ts 程式碼,容易閱讀,原始碼如下圖所示:
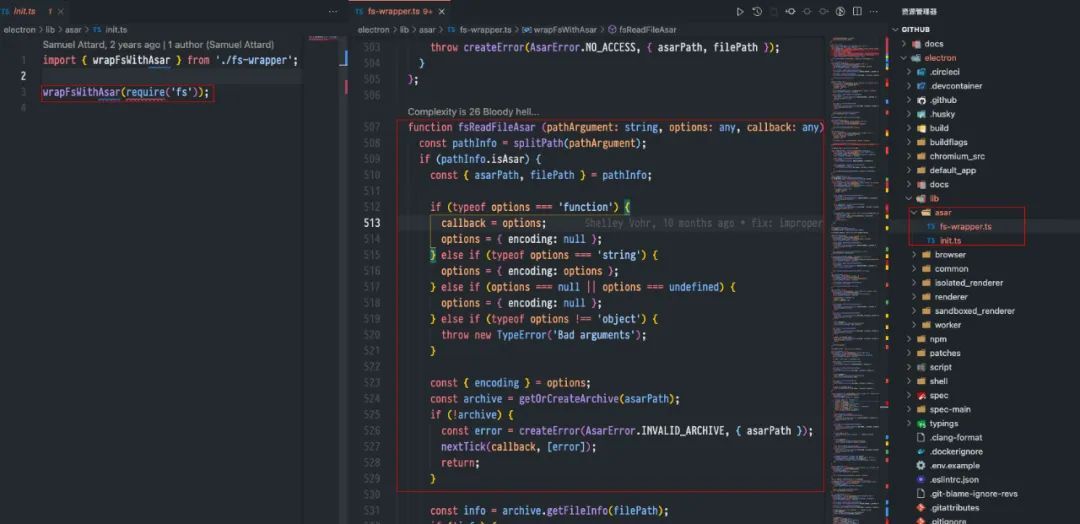
從圖中可以看出, asar 的核心實現就是對 nodejs 的 fs 模組進行重寫。
7.3 原始碼保護
避免原始碼洩漏,按照從低到高的原始碼安全,可以分為以下程度
- asar
- 程式碼混淆
- WebAssembly
- Language bindings
其中,Language bindings 是最高的原始碼安全措施,其實使用 C++ 或 Rust 程式碼來編寫 electron 應用程式碼,通過將 C++ 或 Rust 程式碼編譯成二進位制程式碼後,破譯的難度會變高。這裡我說下如何使用 Rust 去編寫 electron 應用程式碼。
方案:使用 napi-rs 作為工具去編寫,如下圖所示:
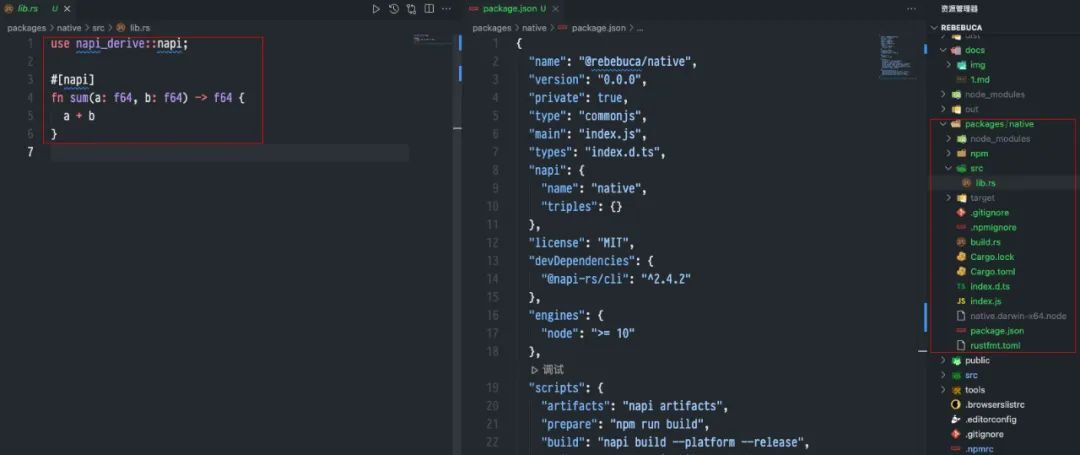
我們採用 pnpm-workspace 去管理 Rust 程式碼,使用 napi-rs ,比如我們寫一個 sum 函式,rs程式碼如下:
fn sum(a: f64, b: f64) -> f64 {
a + b
}此時我們加上 napi 裝飾程式碼,如下所示:
use napi_derive::napi;
#[napi]
fn sum(a: f64, b: f64) -> f64 {
a + b
}在通過 napi-cli 將上述程式碼編譯成 node 可以呼叫的二進位制程式碼。
編譯後,在electron使用上述程式碼,如下所示:
import { sum as rsSum } from '@rebebuca/native'
// 輸出 7
console.log(rsSum(2, 5))napi-rs 的使用請閱讀官方文件,地址是:http://napi.rs/(opens new window)
至此,language bindings 的闡述就完成了。我們通過這種方式,可以完成對重要功能的原始碼保護。
7.4 應用安全
目前熟知的一個安全問題是克隆攻擊,此問題的主流解決方案是將使用者認證資訊和應用裝置指紋進行繫結,整體流程如如下圖所示:

應用裝置指紋生成:可以用上文闡述的 napi-rs 方案去實現
使用者認證資訊和裝置指紋繫結:使用服務端去實現
7.5 編碼安全
主要有以下措施:
- 常用的 web 安全,比如防 xss 、 csrf
- 設定 node 可執行環境
- 窗體開啟安全選項
- 限制連結跳轉
以上具體細節不再介紹,自行搜尋上述方案。除此之外,還有個官方推薦的最佳安全實踐,有空可以看看,地址如下:http://www.electronjs.org/docs/latest/tutorial/security(opens new window)
至此,安全這塊就介紹完了。
八、總結
本文介紹了我們對桌面端技術的調研、確定技術選型,以及用 electron 開發過程中,總結的實踐經驗,如構建、效能優化、質量保障、安全等。希望對讀者在開發桌面應用過程中有所幫助,文章難免有不足和錯誤的地方,歡迎讀者在評論區交流。
- 循序漸進講解負載均衡vivoGateway(VGW)
- Tars-Java網路程式設計原始碼分析
- vivo 短視訊使用者訪問體驗優化實踐
- 100 行 shell 寫個 Docker
- vivo全球商城:庫存系統架構設計與實踐
- 非侵入式入侵 —— Web快取汙染與請求走私
- 解密遊戲推薦系統的建設之路
- 解密遊戲推薦系統的建設之路
- 使用者行為分析模型實踐(三)——H5通用分析模型
- vivo版本釋出平臺:頻寬智慧調控優化實踐-平臺產品系列03
- 廣告流量反作弊風控中的模型應用
- vivo官網App模組化開發方案-ModularDevTool
- OKR之劍·實戰篇05:OKR致勝法寶-氛圍&業績雙輪驅動(上)
- vivo 自研Jenkins資源排程系統設計與實踐
- vivo官網App模組化開發方案-ModularDevTool
- Dubbo 中 Zookeeper 註冊中心原理分析
- 使用者行為分析模型實踐(三)——H5通用分析模型
- Node.js 應用全鏈路追蹤技術——全鏈路資訊儲存
- 從0到1設計通用資料大屏搭建平臺
- vivo 超大規模訊息中介軟體實踐之路