圖資料庫實操:用 Nebula Graph 破解成語版 Wordle 謎底


春節期間如果有小夥伴玩過 Wordle 這個火爆社交媒體的猜詞遊戲,可能對成語版本的漢兜有所耳聞。在玩漢兜過程中,我發現用 Nebula Graph 的圖查詢來解 Antfu 的漢兜(中文成語版 Wordle 👉🏻 handle.antfu.me)會是件特別有意思的事情,很適合當作圖資料庫語句的實操。在本文中,你將瞭解我是如何用知識圖譜“作弊”解漢兜。😁
什麼是漢兜?
漢兜(http://handle.antfu.me )是由 Vue/Vite 核心團隊成員的 Antfu 的又一個非常酷的作品,一個非常精緻的漢字版的 Wordle,它是一個每日挑戰的填字遊戲的中文成語版。
每天,漢兜會發起一個猜成語挑戰,人們要在十次內猜對對應成語才能獲勝,每一步之後都會收到相應的文字、聲母、韻母、聲調的匹配情況的提示,其中:綠色表示這個因素存在並且位置匹配、橘色表示這個元素存在但是位置不對,詳細的規則可見如下的網頁截圖:

漢兜的樂趣在於在有限的嘗試次數中,在大腦中搜尋可能的答案,不斷地去逼近真理,任何試圖作弊、討巧去洩漏結果的行為都是很無趣、倒胃口的(比如從開源的漢兜程式碼裡竊取資訊),這個過程就像大腦做了個體操。
說到大腦的成語詞彙量體操,我突然想到,為什麼我們不能在大腦之外造一個漢語成語知識圖譜,然後基於這個圖譜實操一把圖資料庫,做個圖查詢體操呢?
構造解決漢兜的成語知識圖譜
什麼是知識圖譜?
簡單來說,知識圖譜是一個連線實體之間關聯關係的網路,它最初由 Google 提出並用來滿足搜尋引擎中基於知識推理才可獲得(而不是網頁倒排索引)的搜尋問題,比如:”姚明妻子的年齡?“、”火箭隊得過幾次總冠軍?“
這些問題裡邊,我們關注問題中的條件。到 2022 年的現在,知識圖譜已經被廣泛應用在推薦系統、問答系統、安全風控等等更多搜尋之外的領域。
為什麼需要用知識圖譜解決漢兜?
原因就是:because I can
實際上,我們在大腦中解決字謎遊戲的過程像極了圖譜網路中的資訊搜尋的過程,漢兜的解謎反饋提示條件天然適合被用圖譜的語義來進行表達。在本文後邊,你們會發現解謎條件翻譯成圖語義是非常自然的,這個問題就像是一個天然的為圖譜而存在的練習一樣,我相信這和知識圖譜的結構和人腦中的知識結構接近有很大的關係。
如何構建面向漢兜解謎的知識圖譜?
知識圖譜是由實體(頂點)和關係(邊)組成的,用圖資料庫管理系統(Graph Database MS)可以很方便地進行知識的入庫、更改、查詢、甚至視覺化探索。
在本文裡,我將利用開源的分散式圖資料庫 Nebula Graph 開實踐這個過程,具體圖譜系統的搭建我都會放在文末。
在本章,我們只討論圖譜的建模:如何面向漢兜的解謎去設計“實體”與“關係”。
圖建模
最初的想法
首先,一定存在的實體是:
- 成語
- 漢字
- 成語-[包含]->漢字,每個漢字-[讀作]->讀音。
其次,因為解謎過程中涉及到了聲母、韻母以及聲調的條件,考慮到圖譜本身的量級非常小(千級別),而且字的讀音是一對多的關係,我把讀音和聲母(包涵聲母-initial和韻母-final)也作為實體,他們之間的關係則是順理成章了:
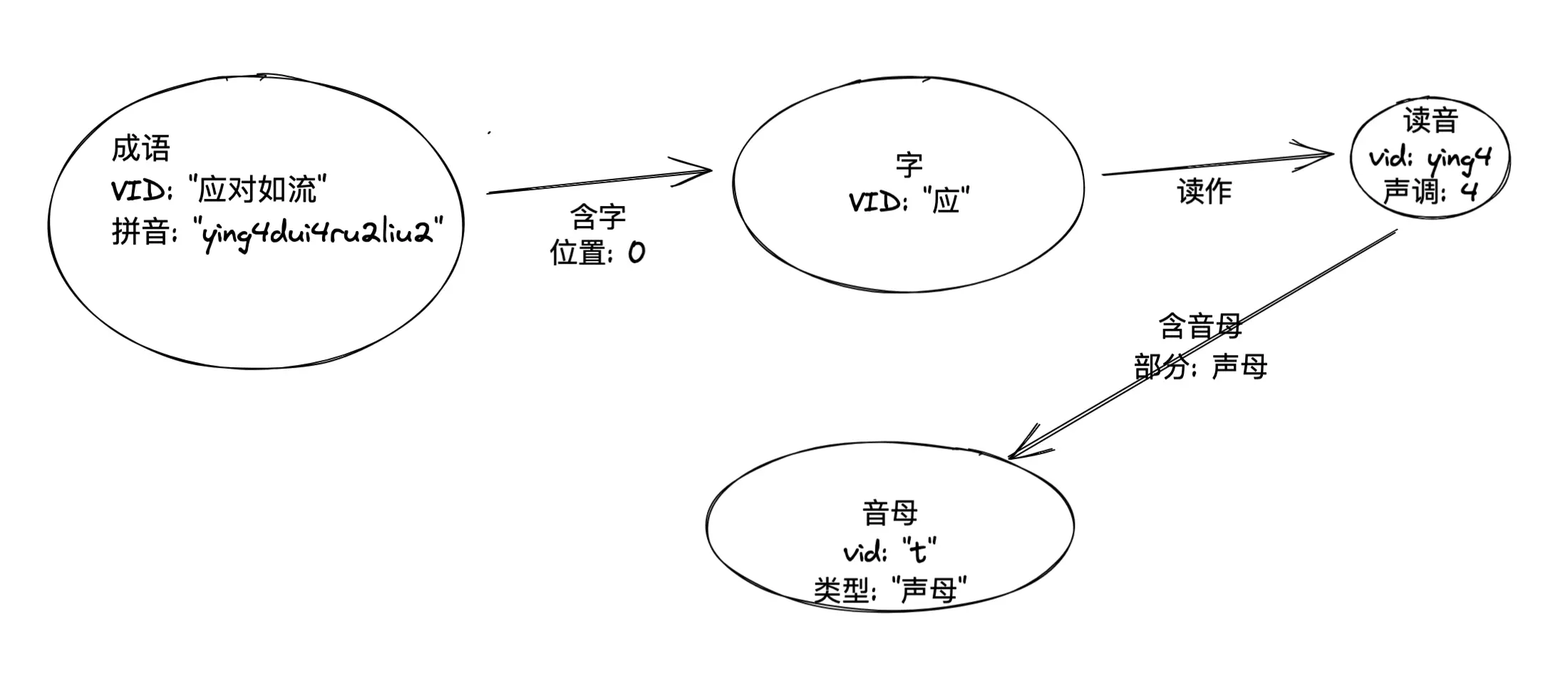
最終的版本
然而,我在後邊基於圖譜進行查詢的時候發現最初的建模會使得 (成語)–>(字)–>(讀音) 查詢過程中丟失了這個字特定的讀法的條件,所以我最終的建模是:
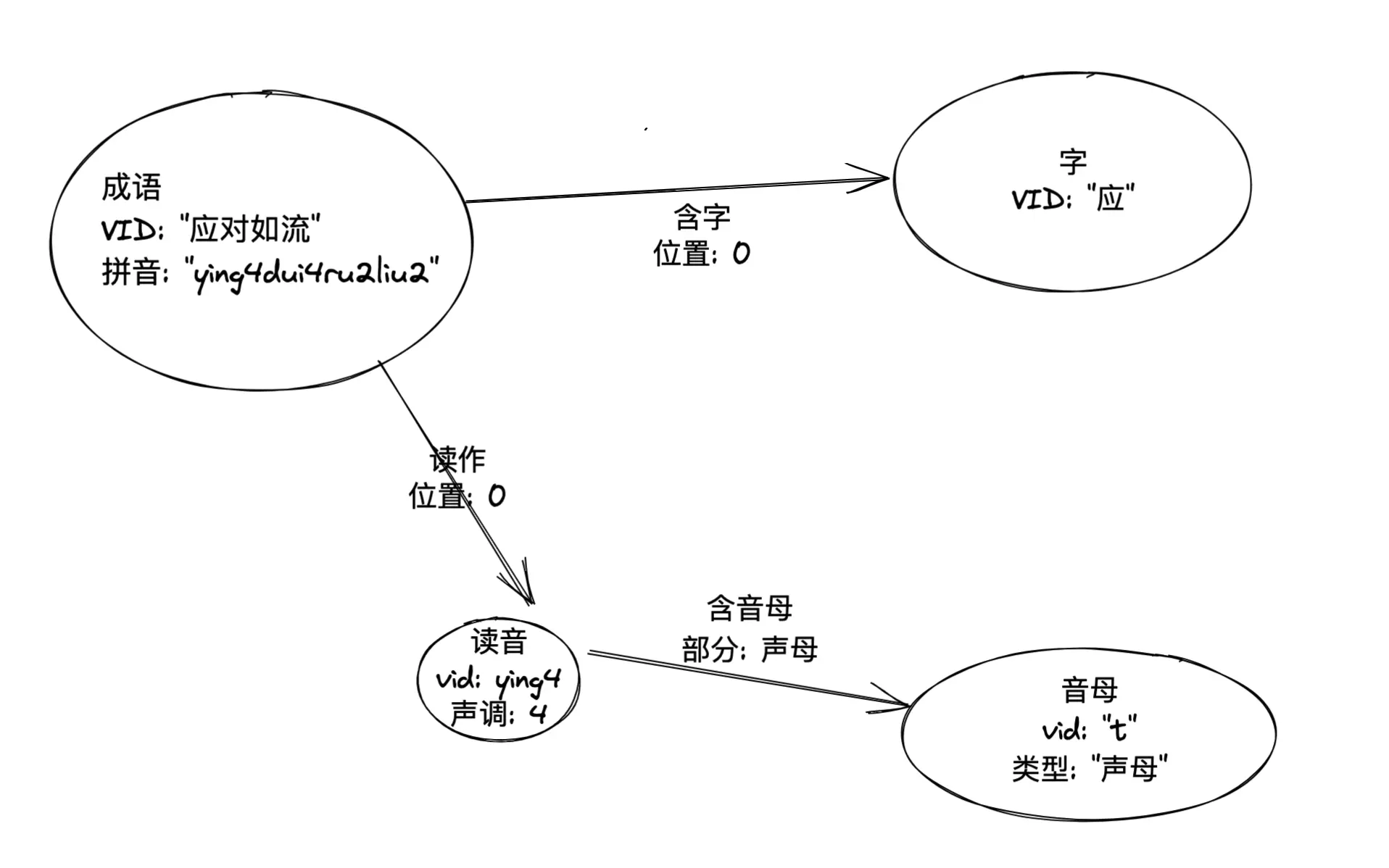
這樣,純文字的條件只涉及了 (成語)-->(字) 這一跳,而讀音、聲母、聲調的條件則是另一條關係路徑,既沒有最初版本條件的冗餘,又可以在一個路徑模式匹配裡帶上兩種條件(後邊的例子裡會涉及這樣的表達)。
構建成語知識圖譜
有了建模、這麼簡單的圖譜的構建就剩下了資料的收集、清洗和入庫。
對於所有成語資料和他們的讀音,我一方面直接抽取了漢兜程式碼內部的資料,另一方面利用 PyPinyin 這個開源的 Python 庫將漢兜資料中沒有讀音的資料獲得讀音,同時,我也用到了 PyPinyin 裡的很多方便的函式,比如:獲取一個拼音的聲母、韻母。
構建工具的程式碼在這裡:http://github.com/wey-gu/chinese-graph
更多資訊我也放在文末的附錄之中。
開始知識圖譜查詢體操
至此,我假設咱們都已經有了我幫大家搭建的成語作弊知識圖譜了,開始我們的圖譜查詢體操吧!
首先,開啟漢兜 👉🏻 http://handle.antfu.me/
假設我們想從一個成語開始,如果你沒有想法的話可以試試這個:
# 匹配成語中的一個結果
MATCH (x:idiom) "愛憎分明" RETURN x LIMIT 1
# 返回結果
("愛憎分明" :idiom{pinyin: "['ai4', 'zeng1', 'fen1', 'ming2']"})
然後我們把它填到漢兜之中,獲得第一次嘗試的提示條件:
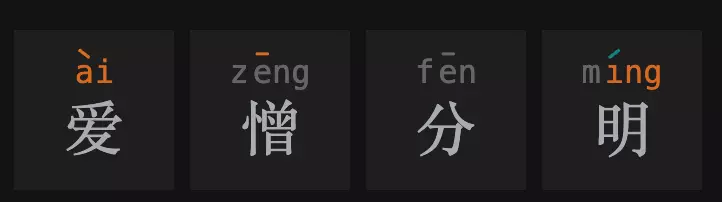
我們運氣不錯,得到了三個位置上的條件!
- 有一個非第一個位置的字,拼音是 4 聲,韻母是 ai,但不是愛(愛)
- 有一個一聲的字,不在第二個位置(憎)
- 有一個字韻母是 ing,不在第四個位置(明)
- 第四個字是二聲(明)
下面,我們開始圖資料庫語句體操!
# 有一個非第一個位置的字,拼音是 4 聲,韻母是 ai,但不是愛
MATCH (char0:character)<-[with_char_0:with_character]-(x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0 AND with_char_0.position != 0 AND id(char0) != "愛"
# 有一個一聲的字,不在第二個位置
MATCH (x:idiom) -[with_pinyin_1:with_pinyin]->(pinyin_1:character_pinyin)
WHERE pinyin_1.character_pinyin.tone == 1 AND with_pinyin_1.position != 1
# 有一個字韻母是 ing,不在第四個位置
MATCH (x:idiom) -[with_pinyin_2:with_pinyin]->(:character_pinyin)-[:with_pinyin_part]->(final_part_2:pinyin_part{part_type: "final"})
WHERE id(final_part_2) == "ing" AND with_pinyin_2.position != 3
# 第四個字是二聲
MATCH (x:idiom) -[with_pinyin_3:with_pinyin]->(pinyin_3:character_pinyin)
WHERE pinyin_3.character_pinyin.tone == 2 AND with_pinyin_3.position == 3
RETURN x, count(x) as c ORDER BY c DESC
在圖資料庫之中執行,得到了 7 個答案:
("驚愚駭俗" :idiom{pinyin: "['jing1', 'yu2', 'hai4', 'su2']"})
("驚世駭俗" :idiom{pinyin: "['jing1', 'shi4', 'hai4', 'su2']"})
("驚見駭聞" :idiom{pinyin: "['jing1', 'jian4', 'hai4', 'wen2']"})
("沽名賣直" :idiom{pinyin: "['gu1', 'ming2', 'mai4', 'zhi2']"})
("驚心駭神" :idiom{pinyin: "['jing1', 'xin1', 'hai4', 'shen2']"})
("荊棘載途" :idiom{pinyin: "['jing1', 'ji2', 'zai4', 'tu2']"})
("出賣靈魂" :idiom{pinyin: "['chu1', 'mai4', 'ling2', 'hun2']"})
看起來“驚世駭俗“比較主流,試試!

我們很幸運,藉助於成語作弊知識圖譜,居然一次就找到了答案,當然這實際上得益於第一次隨機選取的詞帶來的限制條件的個數,不過在大部分情況下,兩次嘗試獲得最終答案的可能性還是非常大的!
注,這中間很長的 253 分鐘是因為我在查詢中發現之前程式碼裡構造的圖譜有點 bug,是“披枷帶鎖”這個詞引起的讀音圖譜的錯誤資料,還好後來被修復了。
大家知道“披枷帶鎖”的正確讀音麼?😭
回題,我給大家詳細解釋一下這個成語破解的過程。
語句的含義
我們從第一個字的條件開始,這是一個既有聲音、又有字形資訊的條件。
- 聲音資訊:存在一個韻母為 ai4 的發音,位置不在第一個字
- 文字資訊:這個韻母為 ai4 的字,不是愛字
對於聲音資訊條件,轉換為圖模式匹配為:(成語)-一個字發音-(拼音)-包含聲母-(韻母) WHERE 拼音韻母為 ai4 AND 位置不是第一個。
因為建模的時候,屬性名稱我用的是英文(其實中文也是支援的),實際上的語句為:
# 有一個非第一個位置的字,拼音是 4 聲,韻母是 ai
MATCH (x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0
# ...
RETURN x
類似的,表示非第一個位置的字,不是愛的表達是:
# 有一個非第一個位置的字,拼音是 4 聲,韻母是 ai,但不是愛
MATCH (char0:character)<-[with_char_0:with_character]-(x:idiom)
WHERE with_char_0.position != 0 AND id(char0) != "愛"
# ...
RETURN x, count(x) as c ORDER BY c DESC
而因為這兩個條件最終描述的是同一個字,所以它們是可以被寫在一個路徑下的:
# 有一個非第一個位置的字,拼音是 4 聲,韻母是 ai,但不是愛
MATCH (char0:character)<-[with_char_0:with_character]-(x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0 AND with_char_0.position != 0 AND id(char0) != "愛"
# ...
RETURN x
更多的 MATCH 語法和例子細節,請大家參考文件:
- MATCH:http://docs.nebula-graph.com.cn/3.0.1/3.ngql-guide/7.general-query-statements/2.match/
- 圖模式:http://docs.nebula-graph.com.cn/3.0.1/3.ngql-guide/1.nGQL-overview/3.graph-patterns/
- nGQL 命令:cheatsheet
視覺化展示線索
我們把每一個條件的匹配路徑作為輸出,利用 Nebula Graph 的視覺化能力,可以得到:
# 有一個非第一個位置的字,拼音是 4 聲,韻母是 ai,但不是愛 # 有一個非第一個位置的字,拼音是 4 聲,韻母是 ai,但不是愛
MATCH p0=(char0:character)<-[with_char_0:with_character]-(x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0 AND with_char_0.position != 0 AND id(char0) != "愛"
# 有一個一聲的字,不在第二個位置
MATCH p1=(x:idiom) -[with_pinyin_1:with_pinyin]->(pinyin_1:character_pinyin)
WHERE pinyin_1.character_pinyin.tone == 1 AND with_pinyin_1.position != 1
# 有一個字韻母是 ing,不在第四個位置
MATCH p2=(x:idiom) -[with_pinyin_2:with_pinyin]->(:character_pinyin)-[:with_pinyin_part]->(final_part_2:pinyin_part{part_type: "final"})
WHERE id(final_part_2) == "ing" AND with_pinyin_2.position != 3
# 第四個字是二聲
MATCH p3=(x:idiom) -[with_pinyin_3:with_pinyin]->(pinyin_3:character_pinyin)
WHERE pinyin_3.character_pinyin.tone == 2 AND with_pinyin_3.position == 3
RETURN p0,p1,p2,p3
在視覺化工具的 Console 控制檯裡執行上邊的語句之後,選擇匯入圖探索,就可以看到:
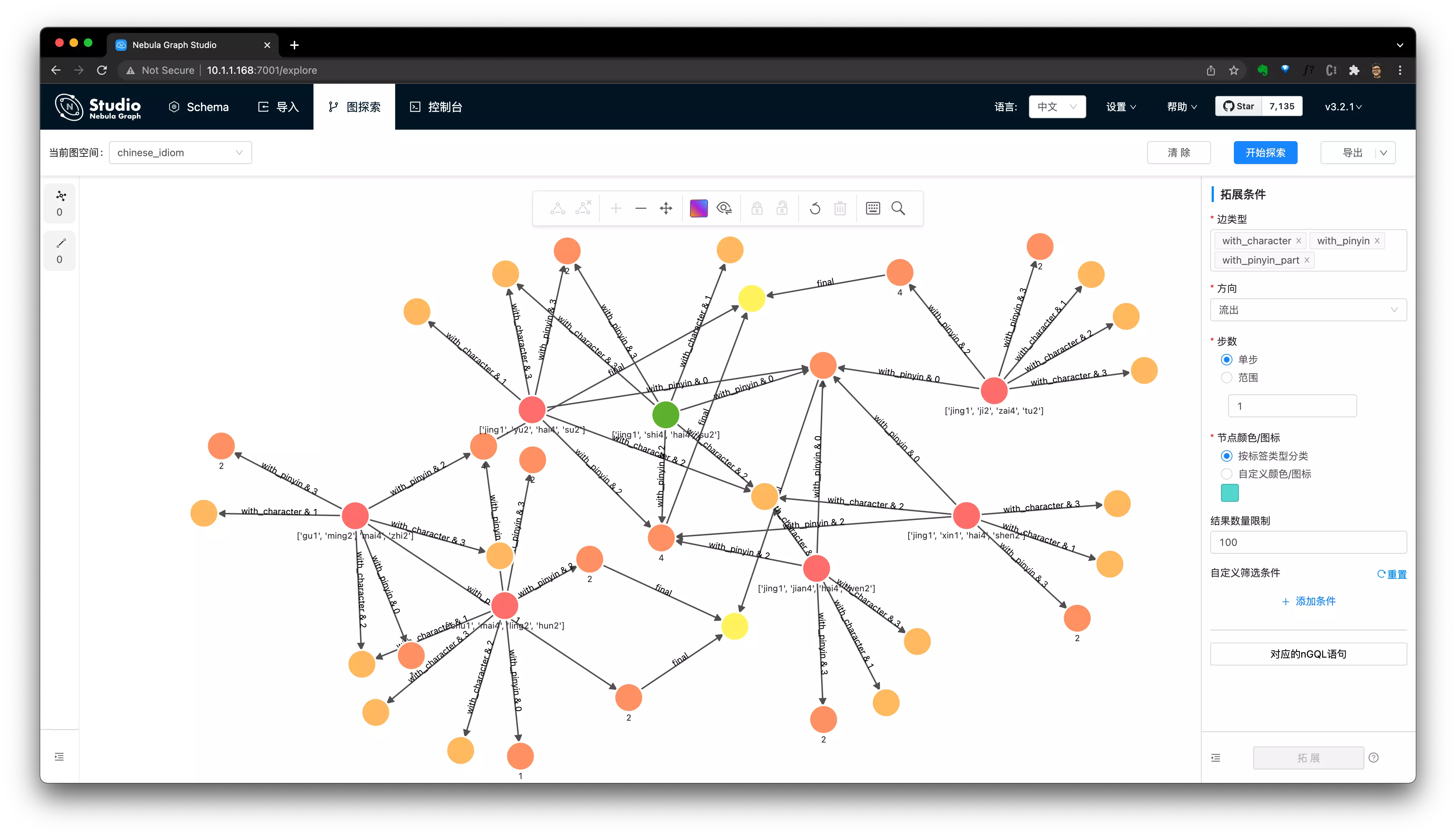
下一步
如果大家是從本文第一次瞭解到 Nebula Graph 圖資料庫,那麼大家可以下一步從 Nebula Graph 專案和 Nebula Graph 社群的官方 Bilibili 站點 👉🏻 http://space.bilibili.com/472621355 瞭解更多有意思的入門知識。
另外,這裡是 Nebula Graph 的官方線上試玩環境,大家可以照著文件,利用試玩環境嚐鮮。
後邊,Nebula Graph 會開展每天的漢兜 nGQL 體操活動,敬請關注哈!
Happy Graphing!
附錄:搭建成語知識圖譜
收集、生成圖譜資料
$ python3 graph_data_generator.py
匯入資料到 Nebula Graph 圖資料庫
部署圖資料庫
藉助於 Nebula-Up:http://github.com/wey-gu/nebula-up/,一行就可以了。
$ curl -fsSL nebula-up.siwei.io/install.sh | bash -s -- v3.0.0
部署成功的話,會看到這樣的結果:
┌────────────────────────────────────────┐
│ 🌌 Nebula-Graph Playground is Up now! │
├────────────────────────────────────────┤
│ │
│ 🎉 Congrats! Your Nebula is Up now! │
│ $ cd ~/.nebula-up │
│ │
│ 🌏 You can access it from browser: │
│ http://127.0.0.1:7001 │
│ http://<other_interface>:7001 │
│ │
│ 🔥 Or access via Nebula Console: │
│ $ ~/.nebula-up/console.sh │
│ │
│ To remove the playground: │
│ $ ~/.nebula-up/uninstall.sh │
│ │
│ 🚀 Have Fun! │
│ │
└────────────────────────────────────────┘
圖譜入庫
藉助於 Nebula-Importer http://github.com/vesoft-inc/nebula-importer/ ,一行就可以了。
$ docker run --rm -ti \
--network=nebula-docker-compose_nebula-net \
-v ${PWD}/importer_conf.yaml:/root/importer_conf.yaml \
-v ${PWD}/output:/root \
vesoft/nebula-importer:v3.0.0 \
--config /root/importer_conf.yaml
大概一兩分鐘資料就匯入成功了,命令也會正常退出。
連到圖資料庫的 Console
獲得本機第一個網絡卡的地址,這裡是 10.1.1.168
$ ip address
2: enp4s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 2a:32:4c:06:04:c4 brd ff:ff:ff:ff:ff:ff
inet 10.1.1.168/24 brd 10.1.1.255 scope global dynamic enp4s0
進入 Console 的容器執行下邊的命令:
$ ~/.nebula-up/console.sh
# nebula-console -addr 10.1.1.168 -port 9669 -user root -p nebula
檢查一下匯入的資料:
([email protected]) [(none)]> show spaces
+--------------------+
| Name |
+--------------------+
| "chinese_idiom" |
+--------------------+
([email protected]) [(none)]> use chinese_idiom
Execution succeeded (time spent 1510/2329 us)
Fri, 25 Feb 2022 08:53:11 UTC
([email protected]) [chinese_idiom]> match p=(成語:idiom) return p limit 2
+------------------------------------------------------------------+
| p |
+------------------------------------------------------------------+
| <("一丁不識" :idiom{pinyin: "['yi1', 'ding1', 'bu4', 'shi2']"})> |
| <("一絲不掛" :idiom{pinyin: "['yi1', 'si1', 'bu4', 'gua4']"})> |
+------------------------------------------------------------------+
([email protected]) [chinese_idiom]> SUBMIT JOB STATS
+------------+
| New Job Id |
+------------+
| 11 |
+------------+
([email protected]) [chinese_idiom]> SHOW STATS
+---------+--------------------+--------+
| Type | Name | Count |
+---------+--------------------+--------+
| "Tag" | "character" | 4847 |
| "Tag" | "character_pinyin" | 1336 |
| "Tag" | "idiom" | 29503 |
| "Tag" | "pinyin_part" | 57 |
| "Edge" | "with_character" | 116090 |
| "Edge" | "with_pinyin" | 5943 |
| "Edge" | "with_pinyin_part" | 3290 |
| "Space" | "vertices" | 35739 |
| "Space" | "edges" | 125323 |
+---------+--------------------+--------+
附錄:圖建模的 Schema nGQL
CREATE SPACE IF NOT EXISTS chinese_idiom(partition_num=5, replica_factor=1, vid_type=FIXED_STRING(24));
USE chinese_idiom;
# 建立點的型別
CREATE TAG idiom(pinyin string); #成語
CREATE TAG character(); #漢字
CREATE TAG character_pinyin(tone int); #單字的拼音
CREATE TAG pinyin_part(part_type string); #拼音的聲部
# 建立邊的型別
CREATE EDGE with_character(position int); #包含漢字
CREATE EDGE with_pinyin(position int); #讀作
CREATE EDGE with_pinyin_part(part_type string); #包含聲部
參考文獻
交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebula 名片,Nebula 小助手會拉你進群~~
- 智聯招聘基於 Nebula Graph 的推薦實踐分享
- 基於 Nebula Graph 構建百億關係知識圖譜實踐
- GraphX 圖計算實踐之模式匹配抽取特定子圖
- 數倉血緣關係資料的儲存與讀寫
- 如何快速解決叢集異常和機器效能波動
- 圖資料庫|Nebula Graph v3.1.0 效能報告
- Nebula Graph|如何打造多版本文件中心
- Nebula Graph|資訊圖譜在攜程酒店的應用
- 一文帶你瞭解 「圖資料庫」Nebula 的儲存設計和思考
- 雲原生 on nLive:雲上 Nebula Graph
- BIGO 的資料管理與應用實踐
- 圖資料庫|如何從零到一構建一個企業股權圖譜系統?
- 圖資料庫|如何從零到一構建一個企業股權圖譜系統
- 圖資料庫|正反向邊的最終一致性——TOSS 介紹
- 圖資料庫|基於 Nebula Graph 的 Betweenness Centrality 演算法
- 開源分散式圖資料庫的思考和實踐
- Nebula Graph 在眾安保險的圖實踐
- 全方位講解 Nebula Graph 索引原理和使用
- 一首古詩帶來的圖資料庫大冒險
- Nebula Graph 在網易遊戲業務中的實踐