廣告流量反作弊風控中的模型應用
作者:vivo 互聯網安全團隊- Duan Yunxin
商業化廣告流量變現,媒體側和廣告主側的作弊現象嚴重,損害各方的利益,基於策略和算法模型的業務風控,有效保證各方的利益;算法模型可有效識別策略無法實現的複雜作弊模型,本文首先對廣告反作弊進行簡介,其次介紹風控系統中常用算法模型,以及實戰過程中具體風控算法模型的應用案例。
一、廣告反作弊簡介
1.1 廣告流量反作弊定義
廣告流量作弊,即媒體通過多種作弊手段,獲取廣告主的利益。
作弊流量主要來自於:
模擬器或者被篡改了設備的廣告流量;
真設備,但通過羣控控制的流量;
真人真機,但誘導產生無效流量等。
1.2 常見的作弊行為
機器行為: IP重複刷量、換不同IP重複刷量,流量劫持,換不同imei重複刷量等。
人工行為:素材交互要素誘導點擊,媒體渲染文案誘導點擊,突然彈出誤觸點擊等。
1.3 常見作弊類型
按照廣告投放流程順序
展示作弊:媒體將多個展示廣告同時曝光於同一個廣告位,向廣告主收取多個廣告的展示費用。
點擊作弊:通過腳本或計算機程序模擬真人用户,又或者僱傭和激勵誘導用户進行點擊,生成大量無用廣告點擊,獲取廣告主的CPC廣告預算。
安裝作弊:通過測試機或模擬器模擬下載,以及通過移動人工或者技術手段修改設備信息、SDK方式發送虛擬信息、模擬下載等等。
二、廣告流量反作弊算法體系
2.1 算法模型在業務風控中應用背景
智能風控,運用大量行為數據構建模型,對風險進行識別和感知監控,相比規則策略,顯著提升識別的準確性和覆蓋率以及穩定性。
常見的無監督算法:
密度聚類(DBSCAN)
孤立森林(Isolation Forest)
K均值算法
常見有監督算法:
邏輯迴歸(logistic)
隨機森林 (random forest)
2.2 廣告流量模型算法體系
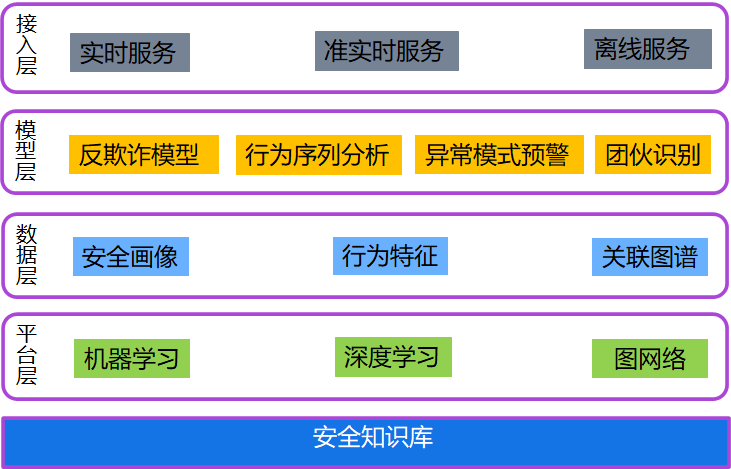
體系分四層:
平台層:主要是依託spark-ml/tensorflow/torch算法框架基礎上,引用開源以及自定義開發的算法應用於業務風控建模中。
數據層:搭建vaid/ip/媒體/廣告位等多粒度下,請求、曝光、點擊、下載、激活等多轉化流程的畫像和特徵體系,服務於算法建模。
業務模型層:基於行為數據特徵和畫像數據,搭建點擊反作弊審計模型、請求點擊風險預估模型、媒體行為相似團伙模型以及媒體粒度異常感知等模型。
接入層:模型數據的應用,離線點擊反作弊模型審計結果與策略識別審計結果彙總,同步業務下游處罰;媒體異常感知模型主要作為候選名單同步點檢平台和自動化巡檢進行。
三、算法模型應用案例
3.1 素材交互誘導感知
背景:廣告素材中添加虛擬的X關閉按鈕,導致用户關閉廣告時點擊的虛假的X按鈕,導致無效的點擊流量,同時影響用户體驗;左圖是投放的原始素材,右側是用户點擊的座標繪製熱力圖,虛擬X導致用户關閉廣告時產生無效的點擊流量。

模型識別感知:
1、密度聚類(DBSCAN):
先定義幾個概念:
鄰域:對於任意給定樣本x和距離ε,x的ε鄰域是指到x距離不超過ε的樣本的集合;
核心對象:若樣本x的ε鄰域內至少包含minPts個樣本,則x是一個核心對象;
密度直達:若樣本b在a的ε鄰域內,且a是核心對象,則稱樣本b由樣本x密度直達;
密度可達:對於樣本a,b,如果存在樣例p1,p2,...,pn,其中,p1=a,pn=b,且序列中每一個樣本都與它的前一個樣本密度直達,則稱樣本a與b密度可達;
密度相連:對於樣本a和b,若存在樣本k使得a與k密度可達,且k與b密度可達,則a與b密度相連;
所定義的簇概念為:由密度可達關係導出的最大密度相連的樣本集合,即為最終聚類的一個簇。

2、應用算法對誘導誤觸廣告感知:
①首先按照分辨率和廣告位,對點擊數據進行分組,篩選過濾掉量級較小的羣組;
②對每個羣組,使用密度聚類算法進行聚類,設置鄰域密度閾值為10,半徑ε=5,進行聚類訓練;
③對每個羣組,密度聚類後,過濾掉簇面積較小的簇,具體訓練代碼如下:

④效果監控和打擊,針對挖掘的簇,關聯點擊後向指標,針對異常轉化指標廣告位,進行復檢,並對複檢有問題廣告位進行處置。
3.2 點擊反作弊模型
3.2.1 背景
針對廣告的點擊環節建立作弊點擊識別模型,提升反作弊審計覆蓋能力,發現高緯度隱藏的作弊行為、有效補充點擊場景的策略反作弊審計。
3.2.2 建設流程

(1)特徵建設
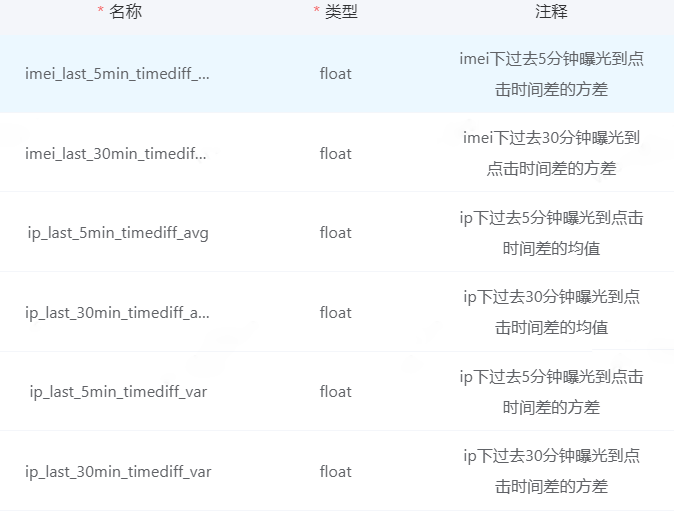
基於token粒度,計算事件發生前,設備、ip、媒體、廣告位的等粒度特徵。
頻率特徵:在過去1分鐘,5分鐘,30分鐘、1小時、1天,7天等時間窗口的曝光,點擊、安裝行為特徵、即對應的均值、方差、離散度等特徵;
基本屬性特徵:媒體類型,廣告類型,設備合法性、ip類型,網絡類型,設備價值等級等。
2、模型訓練和效果
① 樣本選擇:
樣本均衡處理:線上作弊樣本和非作弊樣本非均衡,採用對非作弊樣本下采樣方式,使得作弊和非作弊樣本量達到均衡(1:1)
魯棒性樣本選取:線上非作弊樣本量級大,且羣體行為多樣性且分佈不均等,為了小樣本訓練上線後覆蓋所有行為模式,
使用K-means算法:針對線上非作弊樣本進行分羣,然後對每個羣體按照佔比再下采樣,獲得訓練的非作弊樣本。
② 特徵預處理:
統計每個特徵缺失率,去掉缺失率大於50%的特徵;
特徵貢獻度篩選,計算每個特徵對預測標籤Y的區分度,過濾掉貢獻度低於0.001的特徵;
特徵穩定性篩選,在模型上線前,選取最大和最小時間段的樣本,計算兩個時間段每個特徵的PSI值,過濾掉PSI值(Population Stability Index)大於0.2的特徵,保留穩定性較好的特徵。
③ 模型訓練:
採用隨機森林算法,對點擊廣告作弊行為進行分類,隨機森林有較多優勢,比如:
(1)能處理很高維度的數據並且不用做特徵選擇;
(2)對泛化誤差(Generalization Error)使用的是無偏估計,模型泛化能力強;
(3)訓練速度快,容易做成並行化方法(訓練時樹與樹之間是相互獨立的);
(4)抗過擬合能力比較強;
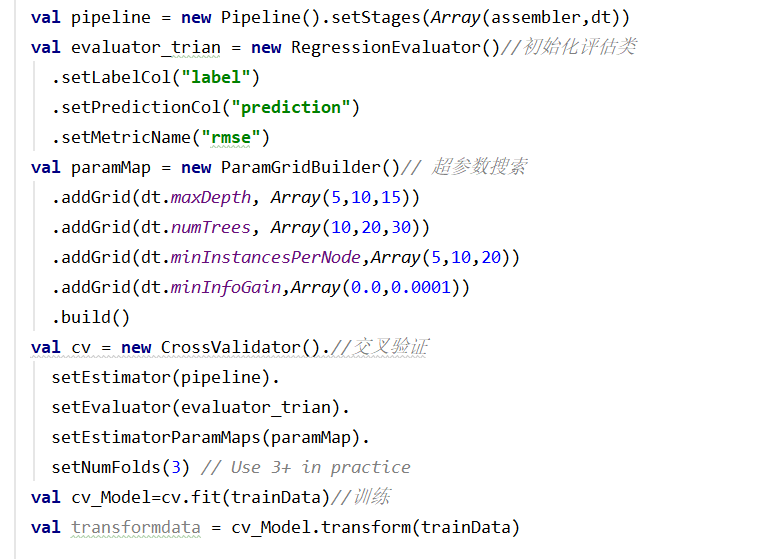
超參數搜索優化,使用ParamGridBuilder,配置max_depth(樹最大深度),numTrees(樹的個數)等超參數的進行搜索優化最優超參數。
④ 模型穩定性監控:
模型上線後,如果特徵隨着時間遷移,推理時間的特徵與訓練時間的特徵分佈存在變動差異,需要對模型穩定性監控並迭代更新;
首先對當前版本訓練樣本進行存檔,計算推理時間的數據和訓練時間數據的對應每個特徵的PSI值,計算的PSI值(Population Stability Index)每天可視化監控告警。
⑤ 模型可解釋性監控:
模型上線後,為了更直觀的定位命中模型風險的原因,對推理數據進行可解釋性監控;即對每條數據,計算其對預測標籤的影響程度;
採用Shapley值(Shapley Additive explanation)解釋特徵如何影響模型的輸出,計算shap值輸出到可視化平台,日常運營分析使用。
3.3 點擊序列異常檢測
3.3.1 背景
通過用户小時點擊量序列,挖掘惡意行為對應的設備,挖掘檢測遠離佔絕大多數正常行為外的異常模式用户羣體、比如只有凌晨0~6點有低頻的其他時間沒點擊行為的異常羣體、或者每小時均衡點擊的行為等異常模式用户等。
3.3.2 建設流程
(1)特徵建設
以設備作為用户,統計過去1/7/30天,每小時的點擊量,形成1*24小時、7*24小時、30*24小時點擊量序列,構建的特徵具備時間尺度上特徵完備性和每個特徵數據連續條件,適用於異常檢測算法。
(2)模型選擇
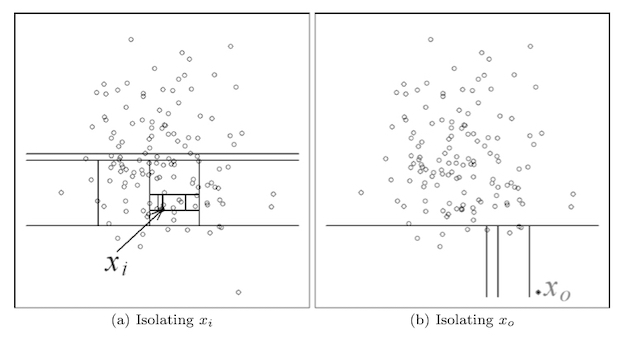
孤立森林離羣點檢測算法,算法基於兩個理論假設,即異常數據佔總樣本量的比例很小,異常點的特徵值與正常點的差異很大。
檢測分佈稀疏且離密度高的羣體較遠的點,比如下圖可以直觀的看到,相對更異常Xo的只需要4次切割就從整體中被分離出來,即被‘孤立’了,而更加正常的Xi點經過了11次分割才從整體中分離出來。
(3)模型訓練
使用IsolationForest算法,為了更好覆蓋,針對多種粒度流量進行異常檢測訓練。
①全平台流量,訓練異常感知模型,設置異常樣本比例contamination=0.05;
②每類媒體類型的流量,訓練異常感知模型,設置異常樣本比例contamination=0.1;
③每種廣告位類型流量,訓練異常感知模型,設置異常樣本比例contamination=0.1。

(4)感知監控
異常得分定義:如果異常得分接近 1,那麼一定是異常點,如果異常得分遠小於 0.5,一定不是異常點;
異常篩選:篩選異常得分大於0.7的用户作為高風險人羣,介於0.5~0.7的人羣作為中風險人羣,對高中風險人羣,同步審計平台人工二次審計;
案例分析:
案例①
2022年XX月XX號, 7*24小時點擊量異常檢測, 可疑惡意用户A ,過去7天大部分時間,每小時均衡產生較多點擊記錄遠超正常用户。
(備註:features中每個點代表用户一個小時的點擊量)

案例②
2022年XX月XX號,1*24小時點擊量序列異常檢測,可疑惡意用户B, 基本只在凌晨產生點擊,其他白天基本無點擊行為。

四、總結
在流量反作弊領域,隨着對抗手段的升級,算法模型能更好發現和挖掘黑產的隱藏的作弊模式;在廣告流量反作弊領域,我們使用有監督和無監督等算法模型,從作弊流量識別,異常流量感知方面做了探索挖掘應用,有效提升識別能力,挖掘發現較複雜的異常行為模式。未來算法模型在機器流量識別上更多探索實踐應用。
END
猜你喜歡
本文分享自微信公眾號 - vivo互聯網技術(vivoVMIC)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- 循序漸進講解負載均衡vivoGateway(VGW)
- Tars-Java網絡編程源碼分析
- vivo 短視頻用户訪問體驗優化實踐
- 100 行 shell 寫個 Docker
- vivo全球商城:庫存系統架構設計與實踐
- 非侵入式入侵 —— Web緩存污染與請求走私
- 解密遊戲推薦系統的建設之路
- 解密遊戲推薦系統的建設之路
- 用户行為分析模型實踐(三)——H5通用分析模型
- vivo版本發佈平台:帶寬智能調控優化實踐-平台產品系列03
- 廣告流量反作弊風控中的模型應用
- vivo官網App模塊化開發方案-ModularDevTool
- OKR之劍·實戰篇05:OKR致勝法寶-氛圍&業績雙輪驅動(上)
- vivo 自研Jenkins資源調度系統設計與實踐
- vivo官網App模塊化開發方案-ModularDevTool
- Dubbo 中 Zookeeper 註冊中心原理分析
- 用户行為分析模型實踐(三)——H5通用分析模型
- Node.js 應用全鏈路追蹤技術——全鏈路信息存儲
- 從0到1設計通用數據大屏搭建平台
- vivo 超大規模消息中間件實踐之路