vivo版本發佈平台:帶寬智能調控優化實踐-平台產品系列03
vivo 互聯網平台產品研發團隊 - Peng Zhong
隨着分發規模地逐步增長,各企業對CDN帶寬的使用越來越多。並且,各類業務使用CDN的場景各式各樣,導致帶寬會不斷地出現驟增驟降等問題。基於成本考慮,國內CDN廠商的計費模式主要用峯值點的帶寬來計費,就算不用峯值點的帶寬,也會因為峯值問題所產生的成本而抬高帶寬單價。基於此,控制CDN帶寬的峯谷具有重要意義,降低峯值就意味着成本節省。
《平台產品》系列文章:
一、背景
伴隨着互聯網地興起,很多企業都經歷過互聯網野蠻生長的一段歲月。然而,在互聯網市場逐步成熟穩定之後,各大企業在業務上的增長速度逐漸放緩,也紛紛開始“對內挖掘成本方面”的產出,對成本做更加精細化的管控,提升企業的競爭力。
特別是隨着“互聯網寒冬”的來臨,“冷氣”傳導到各行各業,“降本增效”的概念也紛紛被重新提起。有拉閘限電的,扣成本扣細節;也有大規模裁員一刀切的,淘汰部分業務,壓縮人力;還有些團隊直接組建橫向團隊,通過頂層思維,在不影響團隊運作的情況下,專攻核心成本技術難題,保障降本效果。
本文,基於作者在CDN帶寬利用率優化方面的實踐,跟大家分享一下我們的降本思路和實操方法。“降本增效”作為持續的創新方向,並不侷限於某個部門,企業價值鏈的任何一個環節都可能會成為突破點。作為技術開發人員,我們則更多的需要“從各自負責的業務方向出發”,對公司成本有觸點的業務進行分析和挖掘,針對性的從技術的角度出發,技術攻關,深入探索,降本增效,為公司帶來真實價值。
通過本文,你可以:
1)打開思路,為“降本增效”提供可能的思考方向,助力大家挖掘輕量化但是價值大的目標。
2)一覽無遺,瞭解我們CDN帶寬利用率優化的核心方法。
名詞解釋:
【CDN】內容分發網絡。
本文的CDN專指靜態CDN,動態CDN主要是對路由節點的加速,帶寬成本規模相對小的多。通俗的解釋:CDN廠商在各地部署了很多節點,緩存你的資源,當用户下載時,CDN網絡幫用户找到最近的一個節點,通過這個節點用户下載速度大大提升。
【CDN帶寬利用率】
帶寬利用率=真實帶寬/計費帶寬,可以理解為投入產出比一樣性質的東西。為何要提升利用率?打個比方:你不會願意花一億夠買價值一千萬的東西,如果你的利用率只有10%的話,你其實就做了這樣一件不合邏輯的事。
【愚公平台】通過帶寬預測和削峯填谷,大幅度提升企業總的CDN帶寬利用率的平台。
二、“尋尋覓覓”找降本
作為CDN的使用大户,在CDN帶寬成本指數級增長的情況下,筆者有幸見證並參與了我司CDN降本的每一個環節,從最初基於各自業務CDN帶寬利用率的優化到後來基於可控帶寬調控的思路。本章,我們來聊聊我們CDN降本的幾個重要階段,並跟大家分享一下,為什麼我會選擇CDN帶寬利用率這一個方向去研究?
2.1 CDN帶寬計費模式
首先,不得不講下我們的計費模式,峯值平均值計費:每天取最高值,每月取每日最高值的平均值作為計費帶寬。
月度計費=Avg(每日峯值)
該計費模式意味着:每日峯值越低,成本越低。帶寬的利用率決定了成本。由此,我們從未放棄過對帶寬利用率的追求,下面看看我們都有哪些優化帶寬利用率的經歷吧。
2.2 CDN降本三部曲
我們CDN降本優化主要分為三個階段。三階段各有妙用,在當時的環境下,都有相當不錯的戰果。並且均是基於當時的情況,探索出來的相對合理的優化方向。

2.1.1 局部優化
局部優化是基於我司的主要CDN使用情況而產生的一種思路。作為手機生產製造廠商,我們的靜態CDN使用場景的核心業務是應用分發類,如:應用商店app分發,遊戲中心app分發,版本自升級分發。歸納一下,核心六大業務佔據了我司帶寬的90%以上,只要把這六大業務的帶寬利用率提升上去,我們的帶寬利用率就可以得到明顯的提升。
基於這樣一個情況,CDN運維工經常找到核心業務,給一個帶寬利用率的指標,讓各業務把帶寬利用率提升上去。歸納一下,核心思路就是:找到核心CDN使用業務方、分別給他們定好各自的利用率指標、提需求任務、講清楚優化的價值。在這一階段優化之後,我們核心業務的帶寬突發場景得到收口,整體帶寬利用率明顯得到提升。
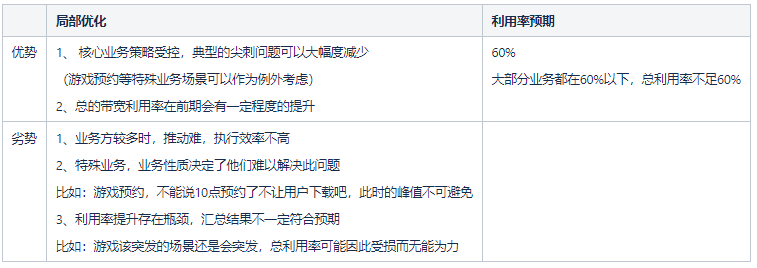
2.1.2 全局優化
由於局部優化是各自業務優化,在大量突刺問題解決之後,各業務的帶寬利用率優化會進入一個瓶頸區。其中,效果比較好的,單業務帶寬利用率也很難突破60%,除非是特殊的業務形式,帶寬完全受控這種情況。此時,我們業務把部分帶寬抽離出來,用以調控公司整體帶寬,進一步提升公司整體帶寬利用率,我們把他定義為全局優化階段。
基於這樣一個全局優化的思路,各個業務只要沒有太大的突刺,總體帶寬利用率就會得到一個較大幅度的提升。首先,我們把帶寬進行劃分,抽取部分可以受服務器控制的帶寬拆分為可控帶寬,主要是工信部許可的wlan下載部分帶寬;然後,我們觀測帶寬走勢,根據帶寬歷史走勢,分離出各個時段的帶寬數據,針對不同時段控制不同的帶寬量級放量,最終達到一個“削峯填谷”的目的。此策略是通過閾值控制放量速度的,每小時設置一個閾值,以每小時閾值生成每秒的令牌數,進行令牌桶控量。
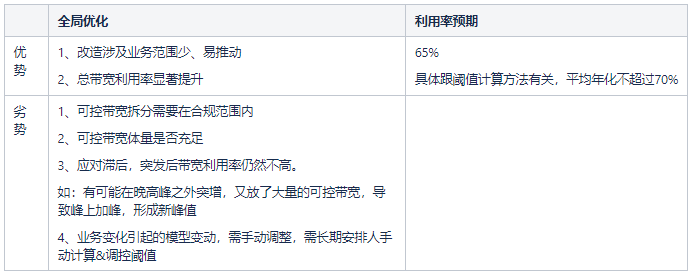
2.1.3 自動化控制
全局優化之後,作為技術開發人員,更進一步的方法就是利用程序取代人工,往更精細化控制方向控量。
基於這樣一個思路,筆者開始探索機器學習方面的預測技術,想象着有規律、有特徵,就有一定的預測的可能性。跟股票不同,雖然CDN帶寬的影響因素也有很多,但是影響最大的幾個因素卻是顯而易見的。所以我們分析這些因素,先歸因,後提取特徵和特徵分解,預測閾值,預測各點的帶寬值。最終攻克了這一預測難題,實現了通過預測技術來調節CDN帶寬峯谷問題。
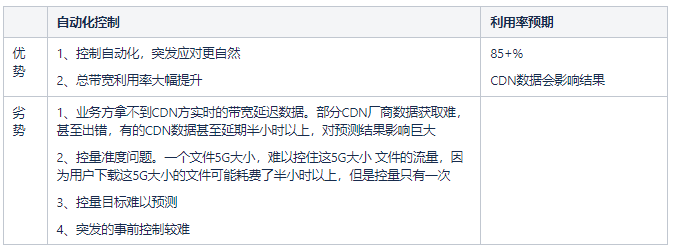
2.3 降本思路的由來
説到降本增效,作為技術開發,首先想到的就是利用技術取代人工,利用程序提升大家的工作效率。比如:自動化測試、自動化點檢、自動化監測歸類告警等等,不管哪個團隊都不少見。甚至自動化代碼生成器,提升大家的編碼效率,都已經孵化了大量平台。
下面,分析一下我們降本增效的主要思路。
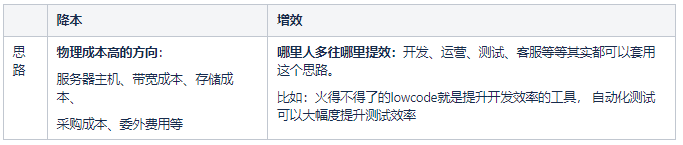
筆者主要負責的技術模塊偏應用分發,涉及的成本方向有:CDN帶寬成本、存儲成本、主機成本。相對於CDN的巨大成本,存儲成本和主機成本部分,少量業務的體量微不足道。至此,我們最合適的方向是往CDN成本方向突破。
CDN成本方向有兩個細分方向:降低帶寬體量、提升帶寬利用率。
小結:
降低帶寬體量複雜度高,基於當前情況,如果能夠自動預測帶寬,並且做到自動化控制,可以大幅度提升帶寬利用率,達成顯而易見的降本效果。並且企業CDN費用越高,降本收益顯著。
三、“踏踏實實”搞預測
確定目標之後,該專題最初是放在“個人OKR目標裏”裏緩慢推進的。本章,筆者跟大家聊聊我們最主要“預測方向”的探索思路。
3.1 帶寬預測探索
我們的探索期主要分兩個階段。前期主要是圍繞:觀察→ 分析 → 建模 開展,類似於特徵分析階段;後期主要是進行算法模擬→算法驗證,選擇效果相對滿意的算法,繼續深入分析探索,深挖價值,研究算法最終突破可用的可能性。
3.1.1 觀察規律
如圖是我司三大項目今年7月1日~7月31日 的帶寬走勢圖(數據已脱敏):

可以觀察出一些比較明顯的規律性:
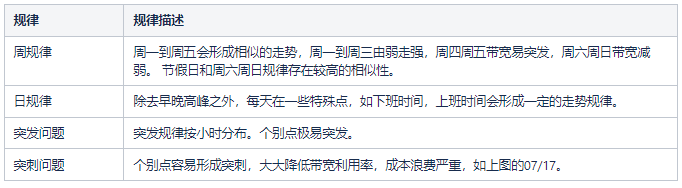
3.1.2 成因分析
我們的帶寬會走出如此趨勢,跟它的影響因素有關,下面列出了“顯而易見的”一些影響因素。
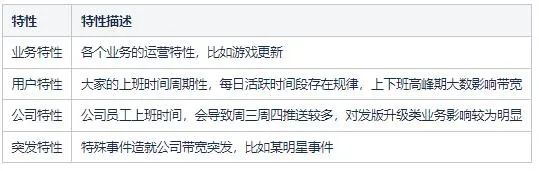
3.1.3 模型拆分
瞭解帶寬成因之後,我們主要的研究方向為:機器學習、殘差分析、時間序列擬合等方向。然而,最終契合我們的預測模式是:閾值時間序列預測、帶寬實時預測模型。從最初探索到最終成型,我們的模型探索也是多次轉變方向,逐漸變得成熟。
3.2 算法關鍵
【最近數據】雖然CDN廠商沒法提供實時帶寬數據,但是卻可以提供一段時間之前的數據,比如15分鐘之前的帶寬數據,我們簡稱之為最近數據。
基於最近的帶寬數據,我們嘗試結合延期數據和歷史數據之間的關係,納入模型,研究出一種自研的算法(主要週期單位為周),進行實時預測。
下圖(數據已脱敏)是納入最近數據之後的一週預測擬合效果。並且,區別於殘差學習對突變點的敏感,我們的模型預測主要問題出在帶寬轉折點,只要處理好轉折點的帶寬模型即可讓算法效果得到保障。
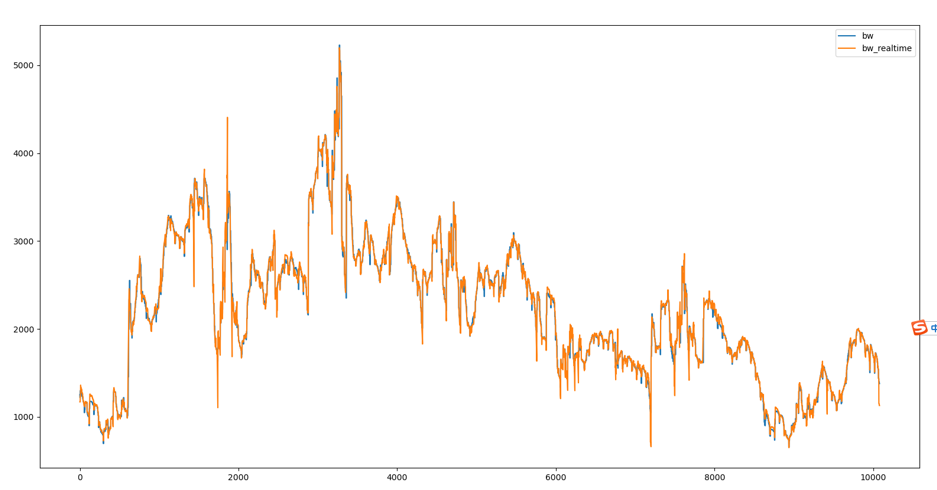
我們自研算法的核心思路:
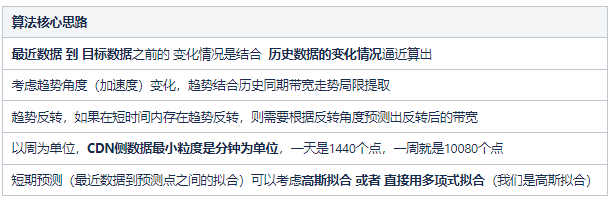
算法的注意事項:
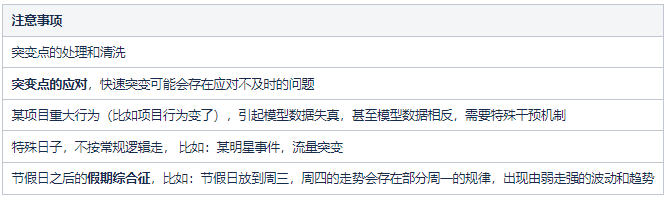
四、“兢兢業業”做愚公
假設你已經能夠較為精準的預測帶寬(標準是:特殊突變點之外,方差5%以內),那麼真正要投產其實還有很多細節要做,你可能會一些面臨模型優化的些許問題 或者 技術處理的問題。
下面,我們主要講講我們《愚公平台》處理從預測到控量的一系列方案,並針對落地實踐問題,我們做了些説明,讓大家少走彎路。
4.1 我們的落地方案
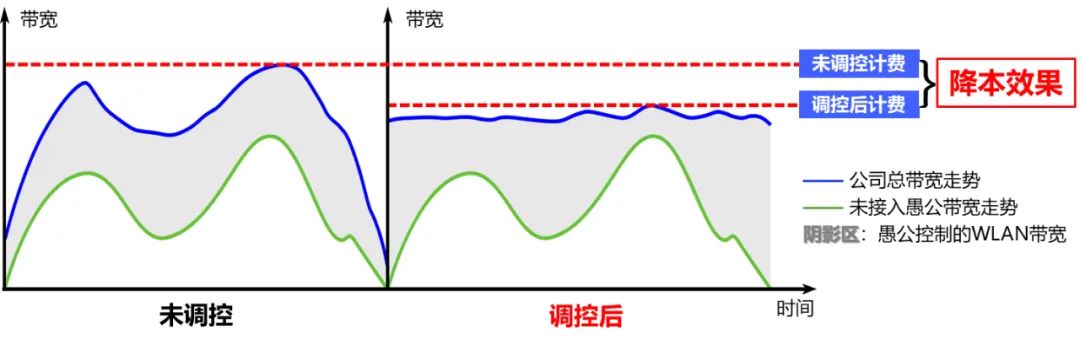
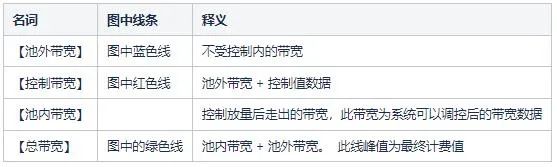
總體上,我們方案的最終目標還是降本,降本思路是基於計費模式。我用一句話概括了我們的方案,如下圖,預測藍色線、控制陰影區,最終壓低藍色線,也就是我們的計費帶寬,從而達到如圖的降本效果。
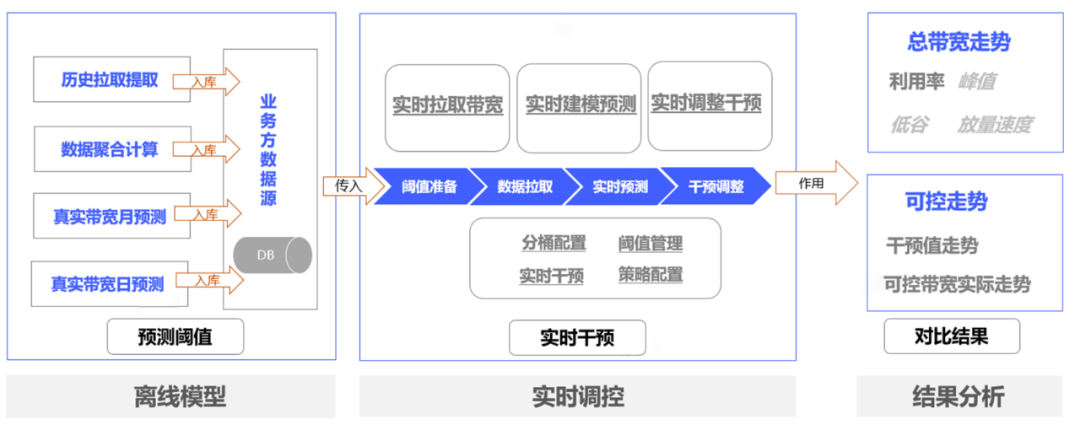
4.2 愚公平台的實踐思路
如下圖,愚公平台的核心思路可以概括為:
通過離線模型預測明日的閾值
使用自研模型,實時預測未來一段時間的帶寬值
結合閾值與預測值,算出一個控量值
控量值寫入令牌桶,每秒生成令牌給端側消費
4.2.1 使用Prophet預測閾值
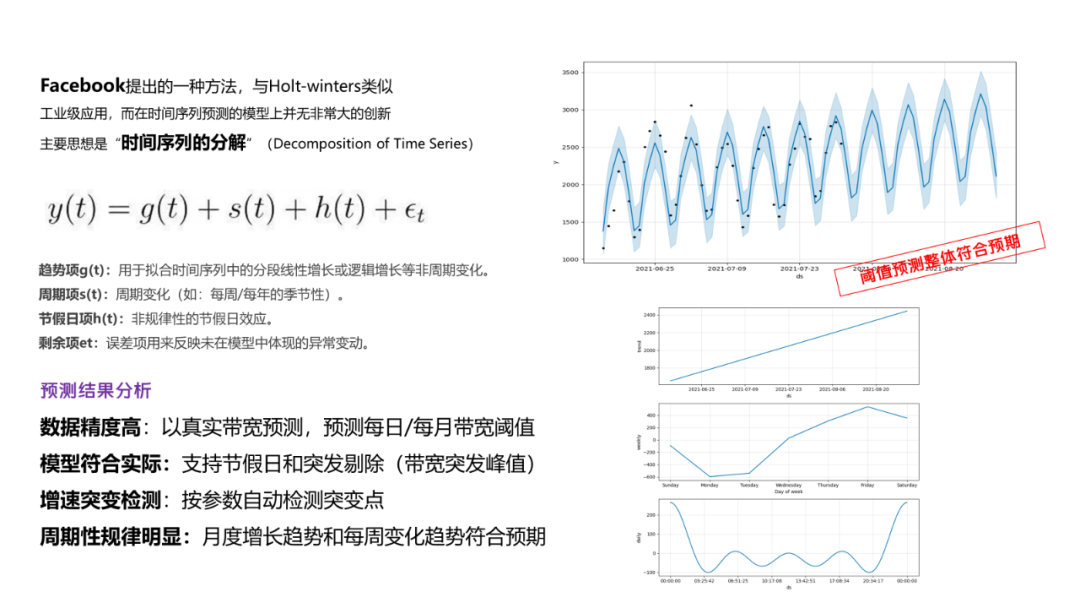
首先是閾值預測,基於之前做帶寬預測的時候也研究過prophet預測,所以最終選擇其作為閾值預測的核心算法。其時間序列特性配合突變點的識別非常契合我們的場景,最終的效果也是非常優秀的。
如下圖(數據已脱敏),除少量特別突發點以外,大部分閾值點基本上落在預測範圍內。
最後,閾值預測本身是一種時間序列預測模型,網上也有較多的類似的選型方案,我們使用prophet預測閾值,並且我們也設計了閾值自適應模型,自動擴充帶寬閾值,可以一定程度降低閾值偏離風險。所以,我們使用的閾值一般是體量閾值,結合其自適應特性,加上一些干預手段,可以極大的保障我們的調控效果。
4.2.2 使用自研算法預測帶寬
這部分內容在預測部分已經有較為詳細的介紹,這裏就不再贅述。總體上,還是用最近的帶寬,結合歷史走勢,擬合出未來一段時間的帶寬走勢,從而預測未來短暫的帶寬走勢。
4.2.3 子模型解決調控問題
這裏主要是針對預測之後的數據,到控制數據之間的轉換,做一些細化處理。對突發、邊界、折算、干預等問題給予關注,需要根據業務實際情況做分析和應對。
4.2.4 流控SDK問題
研究發現,許多業務可能都存在可控制的帶寬,基於此,我們統一做了一個流控SDK。把更多帶寬納入管控,控制的帶寬體量越大,帶來的效果相對會更好。這裏的SDK本質還是一種令牌桶技術,通過此SDK完成所有帶寬的統一控制,可以大幅度減少各個業務處理帶寬問題的煩惱。
4.3 精細化控制能力
閾值預測之後,到最後控量,期間存在較大的轉換關係,可能還需要進一步思考和優化才能讓帶寬利用率得到較大的提升。本節例舉了我們遇到的挑戰,針對我們流控問題,做了些例舉,並做了些分解説明。
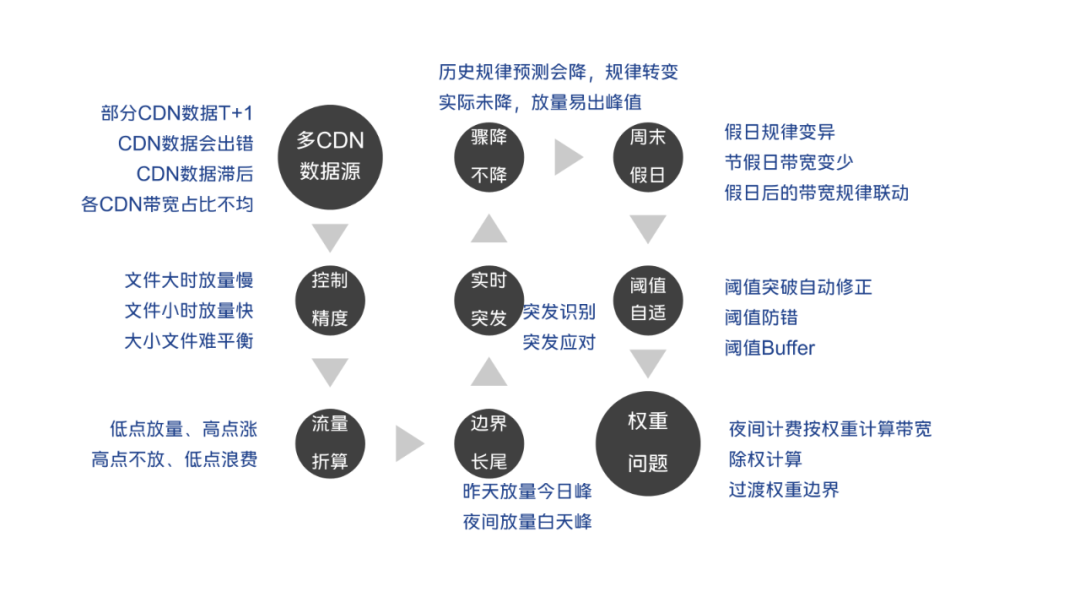
4.3.1 多CDN數據源問題
一般公司會對接多家CDN,各家CDN分配一定的量級,部分CDN不提供最近數據的拉取能力,或者對頻率限制太嚴重,導致數據拉取困難。我們的解決思路:找一家比例相對尚可 且 數據拉取相對配合 的廠商, 用他們的數據和比例反推公司總帶寬,減少對其它CDN廠商的依賴。
注意:因為公司業務多,小業務不支持多CDN比例調控能力,會導致這個比例存在波動,波動太大的情況下會導致調控失真,會導致你的利用率受損。
4.3.2 大小文件引起帶寬控制不準
限流時,一般只能控制開始下載,但是一旦開始下載,不知道什麼時候才會下載完成。小文件,下載耗時較短,控制精準度較高。(常見的小文件、小資源下發等。)大文件,如系統升級包,3G的包,下載可能要一小時以上,控制下載開始是會出問題的。下載時長引起的長尾會讓你絕望。
我們的解決思路:
思路一:對於這種特別大的文件 但是 流量及時性要求不高的,拆分到粗控模型中(可以理解成全局控制那一套思路)。用小文件做精控。精控使用預測模型,對整體帶寬做進一步補充。
思路二:對大文件的下載進行拆分,假設拆成100M, 每下載100M都請求一下流控服務器。 這裏複雜度較高,依賴於客户端改造,作為一種思路考慮。
4.3.3 流量折算問題
其實也是流量長尾引起的,你控制每秒可以下載100個文件,每個文件100MB, 那麼就是10000MB/s的帶寬,實際上由於下載是連續的,這一秒並不會完成下載,實際跑出來的流量沒這麼多。
我們的解決思路:存在流量折算係數,就是你控制3Gbps,實際上打滿之後只有2Gbps,這裏需要手動設置一個折算係數,方便進行流量更精準的控制。
注意:這個折算係數因為包體的大小存在波動,會導致你的利用率受損。
4.3.4 邊界長尾問題
一般情況下,邊界在凌晨, 就是每天一計費。而昨天23:59,往往是大家的帶寬低估,你如果控制了非常多的帶寬(假設因為昨天有突發,導致你控制放量10Tbps),剛好流量又足夠,這個流量可能會因為長尾問題,到今天00:01才放完。因為流量太過龐大,導致今天的計費帶寬在凌晨形成巨峯。
我們的解決思路: 對邊界點之前的一些點進行特殊控制。比如:23:50~ 23:59, 使用明天的峯值進行控量。
4.3.5 突發應對問題
這裏主要是指模型識別的突發,比如數據顯示20分鐘之前帶寬驟增,那麼根據模型你其實已經可以根據這個突發識別到當前的帶寬是在高位行走,且因為趨勢的問題,帶寬預測出一個較高的值。我們的解決思路: 根據總的增長值(或者增長值佔比), 或者增長速度(或者增長速度佔比), 或者增長最大步長(每分鐘增長最大的數據) 考慮作為判斷突發的方式,採取突發應對方案。
有人也發現了,上文講過的,部分突發是預測不了的,我們是怎麼應對來減少損失呢?
① 小突發預留閾值空間
比如預測目標閾值是2T,可能會放1.8T作為閾值,這樣就算有短暫的突發,帶寬突到2T,也在我們的目標範圍內。預留的0.2T就是我們給自己留下的退路,我們的目標也從來不是100%的帶寬利用率,這部分預留就是我們要犧牲掉的帶寬利用率。並且,當帶寬突到更高峯值之後,這部分預留值要合理配置。
②大突發收集統一接入
怎麼定義大突發?有些業務,比如遊戲發版、微信發版,涉及包體很大、涉及用户很廣。只要發版,必定引起大突發,這種只有大業務才能引起的較大帶寬突變,這就是大突發。如果這個突發走勢非快,可以嘗試控制速度,壓一壓這個走勢(在我們第一階段的帶寬利用率優化其實已經做的不錯了)。如果壓成了緩慢突發,我們模式是可以識別到趨勢,做好應對,至此,大突發就不是問題。反之,壓不了的大突發,一下突增300G以上,迅雷不及掩耳之勢突上去的,模型來不及調整,我們建議直接讓類似的行為接入控制系統,讓控制系統提前挖坑應對。
③容易突發的區段,帶寬放量少放一些,犧牲一些量,來做防禦
有些時段,比如晚高峯,就是容易突發,不是這事就是那事,總會出現意想不到的突發,建議直接壓低閾值,本來閾值2T,直接控制一個時段壓到1.5T。這0.5T就是對系統的保護,畢竟只挖一個時段,在其它時段把堵住的流量放出去就好,整體影響還好。
4.3.6 驟降不降問題
根據模型預測驟降(歷史規律導致的),你知道這個點的帶寬趨勢是降低,並且有一些常規降低的降低數據。然而,實際可能沒有降低那麼多,最終因為調控問題可能會引起新峯值。
基於這個問題,我們的解決思路:定義驟降場景和驟降識別規律,對驟降點做特殊標記,處理好驟降帶寬的放量策略,避免引入新峯值。
4.3.7 手動干預處理
部分特殊場景,比如,大型軟件,可以預料到量級非常大,或者大型遊戲預約(如:王者榮耀)更新。這部分可以提前知道突發。
我們的解決思路: 提供突發SDK接入能力和後台錄入能力,對部分容易突發的業務,提供突發上報SDK,提前上報數據,方便模型做出突發應對。
比如:根據帶寬體量,歷史突發場景規律,建模擬合出突發峯值,在突發期間,降低閾值;在突發前,提升閾值。
4.3.8 特殊模式:週末&節假日模式
節假日不同於平時的帶寬走勢,會存在幾個明顯的規律:
大家不上班,可控帶寬明顯偏少
突發點往早高峯偏移
我們的解決思路:針對節假日單獨建模,分析節假日的帶寬走勢。
4.3.9 閾值自適應調整問題
如果按閾值一成不變,那麼突發之後,用之前的閾值會造成大量的帶寬浪費。
我們的解決思路:設計閾值增長模型, 如果池外帶寬峯值突破閾值,或者總帶寬超過閾值一定比例,則考慮放大閾值。
4.3.10 帶寬權重問題
在CDN競爭激烈的時代,由於用户習慣,導致白天帶寬使用較多,而夜間帶寬使用較少。所以部分CDN廠商支持了分段計費方案,這就意味着我們在有些時間段可以多用一些帶寬,有些時間段需要少用一些帶寬。
我們的解決思路: 此方案是基於分段計費, 所以需要設置不同時段的帶寬權重,即可保障帶寬模型平滑運行。當然,分段之後,會出現新的邊界問題,邊界問題需要重新應對解決。
4.4 技術問題
本節基於我們使用的技術,對大家最可能遇到的技術問題做些説明。
4.4.1 熱點key問題
由於接入業務方多,且下載限流經過的流量巨大,可能是每秒百萬級的,這裏必然存在一個問題就是熱點key問題。我們通過槽與節點的分佈關係(可以找DBA獲取),確定key前綴,每次請求隨機到某個key前綴,從而隨機到某個節點上。從而把流量均攤到各個redis節點,減少各個節點的壓力。
下面是我們的流控SDK,LUA 腳本參考:
//初始化和扣減CDN流量的LUA腳本// KEY1 扣減key// KEY2 流控平台計算值key// ARGV1 節點個數 30 整形// ARGV2 流控兜底值MB/len 提前除好(防止平台計算出現延遲或者異常,設一個兜底值),整形// ARGV3 本次申請的流量(統一好單位MB,而不是Mb) 整形// ARGV4 有效期 整形public static final String InitAndDecrCdnFlowLUA ="local flow = redis.call('get', KEYS[1]) " +//優先從控制值裏取,沒有則用兜底值"if not flow then " +" local ctrl = redis.call('get', KEYS[2]) " +" if not ctrl then " +//兜底" flow = ARGV[2] " +" else " +" local ctrlInt = tonumber(ctrl)*1024 " +//節點個數" local nodes = tonumber(ARGV[1]) " +" flow = tostring(math.floor(ctrlInt/nodes)) " +" end " +"end " +//池子裏的值"local current = tonumber(flow) " +//扣減值"local decr = tonumber(ARGV[3]) " +//池子裏沒流量,返回扣減失敗"if current <= 0 then " +" return '-1' " +"end " +//計算剩餘"local remaining = 0 " +"if current > decr then " +" remaining = current - decr " +"end " +//執行更新"redis.call('setex', KEYS[1], ARGV[4], remaining) " +"return flow";
4.4.2 本地緩存
雖然解決了熱點key的問題,但是真正流控控到0的時候(比如連續1小時控到0),還是會存在大量請求過來,特別是客户端重試機制導致請求更頻繁的時候,這些請求全部都過一遍LUA有點得不償失。
所以需要設計一套緩存,告訴你當前這一秒 流控平台沒有流量了,減少併發。
我們的解決辦法: 使用內存緩存。當所有節點都沒有流量的時候,對指定秒的時間,設置一個本地緩存key,經過本地緩存key的過濾,可以大幅減少redis訪問量級。
當然,除此之外,還有流量均衡問題,客户端的流量在1分鐘內表現為:前面10s流量很多,導致觸發限流,後面50s沒什麼流量。
這種問題我們服務端暫時還沒有很好的解決辦法。可能需要端側去想辦法,但是端側又較多,推起來不容易。
4.5 最終效果
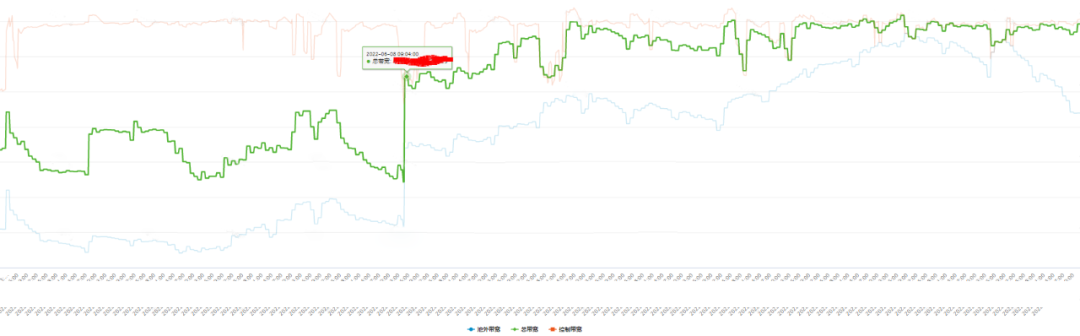
如圖是除權之後的帶寬走勢。從圖中可以看出,使用《愚公平台》調控帶寬,CDN帶寬利用率顯著提升。
五、寫在最後
本文主要講述了《愚公平台》從研究到落地實踐的歷程:
結合業務,選擇了CDN降本方向作為技術研究方向。
觀察規律,選擇了Prophet作為離線閾值預測算法。
算法突破,自研出擬合算法作為實時預測算法。
持續思考,思考應對模型中的問題及持續優化方案。
最終,從技術的角度,為公司創造巨大的降本收益。
END
猜你喜歡
本文分享自微信公眾號 - vivo互聯網技術(vivoVMIC)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- 循序漸進講解負載均衡vivoGateway(VGW)
- Tars-Java網絡編程源碼分析
- vivo 短視頻用户訪問體驗優化實踐
- 100 行 shell 寫個 Docker
- vivo全球商城:庫存系統架構設計與實踐
- 非侵入式入侵 —— Web緩存污染與請求走私
- 解密遊戲推薦系統的建設之路
- 解密遊戲推薦系統的建設之路
- 用户行為分析模型實踐(三)——H5通用分析模型
- vivo版本發佈平台:帶寬智能調控優化實踐-平台產品系列03
- 廣告流量反作弊風控中的模型應用
- vivo官網App模塊化開發方案-ModularDevTool
- OKR之劍·實戰篇05:OKR致勝法寶-氛圍&業績雙輪驅動(上)
- vivo 自研Jenkins資源調度系統設計與實踐
- vivo官網App模塊化開發方案-ModularDevTool
- Dubbo 中 Zookeeper 註冊中心原理分析
- 用户行為分析模型實踐(三)——H5通用分析模型
- Node.js 應用全鏈路追蹤技術——全鏈路信息存儲
- 從0到1設計通用數據大屏搭建平台
- vivo 超大規模消息中間件實踐之路