百度工程师漫谈视频理解
作者 | FesianXu
导读
AI算法已经渗入到了我们生活的方方面面,无论是购物推荐,广告推送,搜索引擎还是多媒体影音娱乐,都有AI算法的影子。作为多媒体中重要的信息载体,视频的地位可以说是数一数二的,然而目前对于AI算法在视频上的应用还不够成熟,理解视频内容仍然是一个重要的问题亟待解决攻克。本文对视频理解进行一些讨论,虽然只是笔者对互联网的一些意见的汇总和漫谈,有些内容是笔者自己的学习所得,希望还是能对诸位读者有所帮助。
全文37074字,预计阅读时间93分钟。
完整长文可点击查看:百度工程师漫谈视频理解
为什么是视频
以视频为代表的动态多媒体,结合了音频,视频,是当前的,更是未来的互联网流量之王。 根据来自于国家互联网信息办公室的中国互联网络发展状况统计报告[1]
截至 2018 年 12 月,网络视频、网络音乐和网络游戏的用户规模分别为 6.12 亿、5.76 亿和 4.84 亿,使用率分别为 73.9%、69.5%和 58.4%。短视频用户规模达 6.48 亿,网民使用比例为 78.2%。截至 2018 年 12 月,网络视频用户规模达 6.12 亿,较 2017 年底增加 3309 万,占网民 整体的 73.9%;手机网络视频用户规模达 5.90 亿,较 2017 年底增加 4101 万,占手机 网民的 72.2%。
其中各类应用使用时长占比如图Fig 1.1所示:
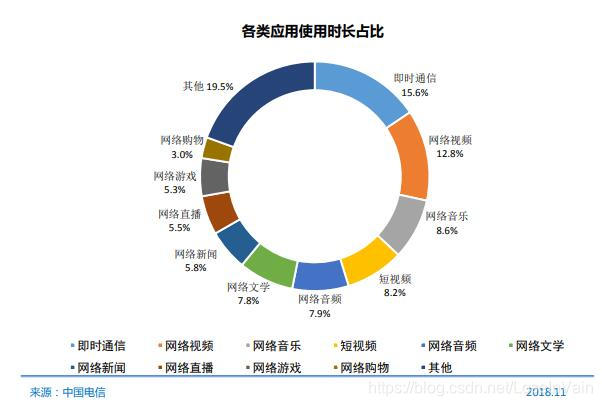
<div align='center'> <b> Fig 1.1 2018年各类应用使用时长占比。 </b> </div>
我们很容易发现,包括短视频在内的视频用户时长占据了约20%的用户时长,占据了绝大多数的流量,同时网络视频用户的规模也在逐年增加。
互联网早已不是我们20年前滴滴答答拨号上网时期的互联网了,互联网的接入速率与日俱增,如Fig 1.2所示。视频作为与人类日常感知最为接近的方式,比起单独的图片和音频,文本,能在单位时间内传递更多的信息,从而有着更广阔的用户黏性。在单位流量日渐便宜,并且速度逐渐提升的时代,视频,将会撑起未来媒体的大旗。
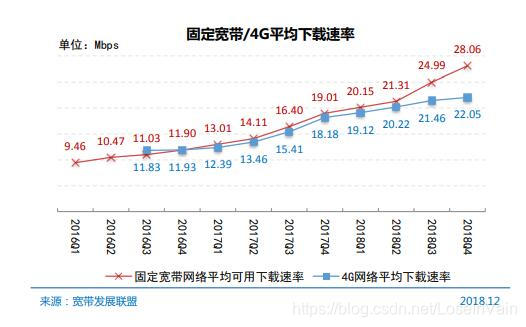
<div align='center'> <b> Fig 1.2 固定带宽/4G平均下载速率变化曲线 </b> </div>
的确,我们现在是不缺视频的时代,我们有的是数据,大型公司有着广大的用户基础,每天产生着海量的数据,这些海量的数据,然而是可以产生非常巨大的价值的。以色列历史学家尤瓦尔·赫拉利在其畅销书《未来简史》和《今日简史》中,描述过一种未来的社会,在那个社会中,数据是虚拟的黄金,垄断着数据的公司成为未来的umbrella公司,控制着人们的一言一行,人们最终成为了数据和算法的奴隶。尽管这个描述过于骇人和科幻,然而这些都并不是空穴来风,我们能知道的是,从数据中,我们的确可以做到很多事情,我们可以通过数据进行用户画像描写,知道某个用户的各个属性信息,知道他或她喜爱什么,憎恶什么,去过何处,欲往何方。我们根据用户画像进行精确的广告推送,让基于大数据的算法在无形中控制你的购物习惯也不是不可能的事情。数据的确非常重要,然而可惜的是,目前AI算法在视频——这个未来媒体之王上的表现尚不是非常理想(当前在sports-1M上的R(2+1)D模型[7]的表现不足80%,不到可以实用的精度。),仍有很多问题亟待解决,然而未来可期,我们可以预想到,在视频上,我们终能成就一番事业。
理解视频——嗯,很复杂
利用视频数据的最终目标是让算法理解视频。理解视频(understanding the video) 是一件非常抽象的事情,在神经科学尚没有完全清晰的现在,如果按照人类感知去理解这个词,我们终将陷入泥淖。我们得具体点,在理解视频这个任务中,我们到底在做什么?首先,我们要知道对比于文本,图片和音频,视频有什么特点。视频它是动态的按照时间排序的图片序列,然而图片帧间有着密切的联系,存在上下文联系;视频它有音频信息。因此进行视频理解,我们势必需要进行时间序列上的建模,同时还需要空间上的关系组织。
就目前来说,理解视频有着诸多具体的子任务:
-
视频动作分类:对视频中的动作进行分类
-
视频动作定位:识别原始视频中某个动作的开始帧和结束帧
-
视频场景识别:对视频中的场景进行分类
-
原子动作提取
-
视频文字说明(Video Caption):给给定视频配上文字说明,常用于视频简介自动生成和跨媒体检索
-
集群动作理解:对某个集体活动进行动作分类,常见的包括排球,篮球场景等,可用于集体动作中关键动作,高亮动作的捕获。
-
视频编辑。
-
视频问答系统(Video QA):给定一个问题,系统根据给定的视频片段自动回答
-
视频跟踪:跟踪视频中的某个物体运动轨迹
-
视频事件理解:不同于动作,动作是一个更为短时间的活动,而事件可能会涉及到更长的时间依赖
...
当然理解视频不仅仅是以上列出的几种,这些任务在我们生活中都能方方面面有所体现,就目前而言,理解视频可以看成是解决以上提到的种种问题。
通常来说,目前的理解视频主要集中在以人为中心的角度进行的,又因为视频本身是动态的,因此描述视频中的物体随着时间变化,在进行什么动作是一个很重要的任务,可以认为动作识别在视频理解中占据了一个很重要的地位。因此本文的理解视频将会和视频动作理解大致地等价起来,这样可能未免过于粗略,不过还是能提供一些讨论的地方的。
视频分析的主要难点集中在:
- 需要大量的算力,视频的大小远大于图片数据,需要更大的算力进行计算。
- 低质量,很多真实视频拍摄时有着较大的运动模糊,遮挡,分辨率低下,或者光照不良等问题,容易对模型造成较大的干扰。
- 需要大量的数据标签!特别是在深度学习中,对视频的时序信息建模需要海量的训练数据才能进行。时间轴不仅仅是添加了一个维度那么简单,其对比图片数据带来了时序分析,因果分析等问题。
视频动作理解——新手村
视频数据模态
然而视频动作理解也是一个非常广阔的研究领域,我们输入的视频形式也不一定是我们常见的RGB视频,还可能是depth深度图序列,Skeleton关节点信息,IR红外光谱等。

<div align='center'> <b> Fig 3.1 多种模态的视频形式 </b> </div>
就目前而言,RGB视频是最为易得的模态,然而随着很多深度摄像头的流行,深度图序列和骨骼点序列的获得也变得容易起来[2]。深度图和骨骼点序列对比RGB视频来说,其对光照的敏感性较低,数据冗余较低,有着许多优点。
关于骨骼点序列的采集可以参考以前的博文[2]。我们在本文讨论的比较多的还是基于RGB视频模态的算法。
视频动作分类数据集
现在公开的视频动作分类数据集有很多,比较流行的in-wild数据集主要是在YouTube上采集到的,包括以下的几个。
-
HMDB-51,该数据集在YouTube和Google视频上采集,共有6849个视频片段,共有51个动作类别。
-
UCF101,有着101个动作类别,13320个视频片段,大尺度的摄像头姿态变化,光照变化,视角变化和背景变化。
- sport-1M,也是在YouTube上采集的,有着1,133,157 个视频,487个运动标签。
-
YouTube-8M, 有着6.1M个视频,3862个机器自动生成的视频标签,平均一个视频有着三个标签。
-
YouTube-8M Segments[3],是YouTube-8M的扩展,其任务可以用在视频动作定位,分段(Segment,寻找某个动作的发生点和终止点),其中有237K个人工确认过的分段标签,共有1000个动作类别,平均每个视频有5个分段。该数据集鼓励研究者利用大量的带噪音的视频级别的标签的训练集数据去训练模型,以进行动作时间段定位。

- Kinectics 700,这个系列的数据集同样是个巨无霸,有着接近650,000个样本,覆盖着700个动作类别。每个动作类别至少有着600个视频片段样本。
以上的数据集模态都是RGB视频,还有些数据集是多模态的:
- NTU RGB+D 60: 包含有60个动作,多个视角,共有约50k个样本片段,视频模态有RGB视频,深度图序列,骨骼点信息,红外图序列等。
- NTU RGB+D 120:是NTU RGB+D 60的扩展,共有120个动作,包含有多个人-人交互,人-物交互动作,共有约110k个样本,同样是多模态的数据集。
在深度学习之前
视频长度不定,一般我们不直接对整段视频进行分析或者处理,我们一般对视频进行采样,比如把整段视频分成若干个片段(clip),这些片段可能是定长的,比如每个片段都是10帧,也可能不是,我们通常会对每个片段进行处理,然后想办法把不同片段的处理结果融合起来,形成最终对整个视频的处理结果。不管怎么样,我们在接下来说的片段时,我们就应该知道这个片段是对某个视频的采样。
在深度学习之前,CV算法工程师是特征工程师,我们手动设计特征,而这是一个非常困难的事情。手动设计特征并且应用在视频分类的主要套路有:
特征设计:挑选合适的特征描述视频
- 局部特征(Local features):比如HOG(梯度直方图 )+ HOF(光流直方图)
- 基于轨迹的(Trajectory-based):Motion Boundary Histograms(MBH)[4],improved Dense Trajectories (iDT) ——有着良好的表现,不过计算复杂度过高。
集成挑选好的局部特征: 光是局部特征或者基于轨迹的特征不足以描述视频的全局信息,通常需要用某种方法集成这些特征。
- 视觉词袋(Bag of Visual Words,BoVW),BoVW提供了一种通用的通过局部特征来构造全局特征的框架,其受到了文本处理中的词袋(Bag of Word,BoW)的启发,主要在于构造词袋(也就是字典,码表)等。

- Fisher Vector,FV同样是通过集成局部特征构造全局特征表征。具体详细内容见[5]

要表征视频的时序信息,我们主要需要表征的是动作的运动(motion)信息,这个信息通过帧间在时间轴上的变化体现出来,通常我们可以用光流(optical flow)进行描述,如TVL1和DeepFlow。

在深度学习来临之前,这些传统的CV算法在视频动作理解中占了主要地位,即便是如今在深度学习大行其道的时代,这些传统的算子也没有完全退出舞台,很多算法比如Two Stream Network等还是会显式地去使用其中的一些算子,比如光流,比如C3D也会使用iDT作为辅助的特征。了解,学习研究这些算子对于视频分析来说,还是必要的。
深度学习时代
在深度学习时代,视频动作理解的主要工作量在于如何设计合适的深度网络,而不是手动设计特征。我们在设计这样的深度网络的过程中,需要考虑两个方面内容:
- 模型方面:什么模型可以最好的从现有的数据中捕获时序和空间信息。
- 计算量方面:如何在不牺牲过多的精度的情况下,减少模型的计算量。
组织时序信息是构建视频理解模型的一个关键点,Fig 3.2展示了若干可能的对多帧信息的组织方法。[6]
- Single Frame,只是考虑了当前帧的特征,只在最后阶段融合所有的帧的信息。
- Late Fusion,晚融合使用了两个共享参数的特征提取网络(通常是CNN)进行相隔15帧的两个视频帧的特征提取,同样也是在最后阶段才结合这两帧的预测结果。
- Early Fusion,早融合在第一层就对连续的10帧进行特征融合。
- Slow Fusion,慢融合的时序感知野更大,同时在多个阶段都包含了帧间的信息融合,伴有层次(hierarchy)般的信息。这是对早融合和晚融合的一种平衡。
在最终的预测阶段,我们从整个视频中采样若各个片段,我们对这采样的片段进行动作类别预测,其平均或者投票将作为最终的视频预测结果。
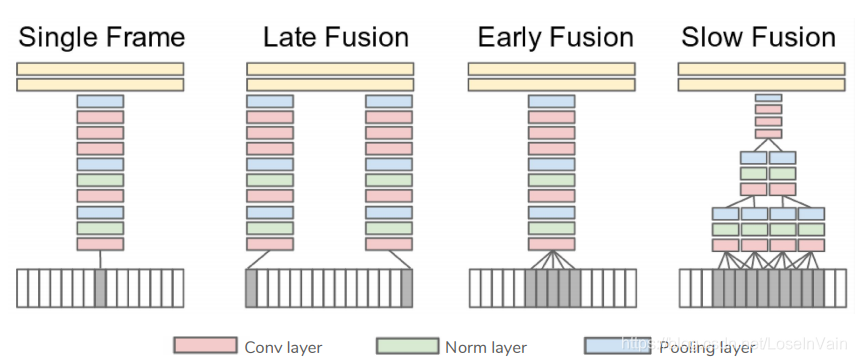
<div align='center'> <b> Fig 3.2 融合多帧信息的不同方式。 </b> </div>
最终若干个帧间信息融合的方法在sport-1M测试集上的结果如Fig 3.3所示:

<div align='center'> <b> Fig 3.3 不同帧间融合方法在sport-1M数据集上的表现。 </b> </div>
另外说句,[6]的作者从实验结果中发现即便是时序信息建模很弱的Single-Frame方式其准确率也很高,即便是在很需要motion信息的sports体育动作类别上,这个说明不仅仅是motion信息,单帧的appearance信息也是非常重要的。
这种在单帧层面用CNN进行特征提取,在时序方面用融合池化不同片段的预测的方式,在理论上,是分不清楚“开门”和“关门”两种动作的,因为其本质上没有对时序因果信息进行建模,只是融合了不同片段的预测结果而已。忽略了时间结构信息,这是融合方法的一种潜在缺点。
考虑到融合方式并不能考虑到时序因果信息,时间结构信息被忽略了[13],我们需要重新思考新的时序信息提取方式。我们知道,这些融合方法,都是手动设计的融合帧间特征的方式,而深度学习网络基本上只在提取单帧特征上发挥了作用。这样可能不够合理,我们期望设计一个深度网络可以进行端到端的学习,无论是时序信息还是空间信息。于是我们想到,既然视频序列和文本序列,语音序列一样,都是序列,为什么我们不尝试用RNN去处理呢?
的确是可以的,我们可以结合CNN和RNN,直接把视频序列作为端到端的方式进行模型学习。设计这类模型,我们有几种选择可以挑选:
- 考虑输入的数据模态:a> RGB; b> 光流; c> 光流+RGB
- 特征: a> 人工设计; b> 通过CNN进行特征提取
- 时序特征集成:a> 时序池化; b> 用RNN系列网络进行组织
时序池化如Fig 3.4所示,类似于我们之前讨论的时序融合,不过在细节上不太一样,这里不展开讨论了,具体见文章[8]。
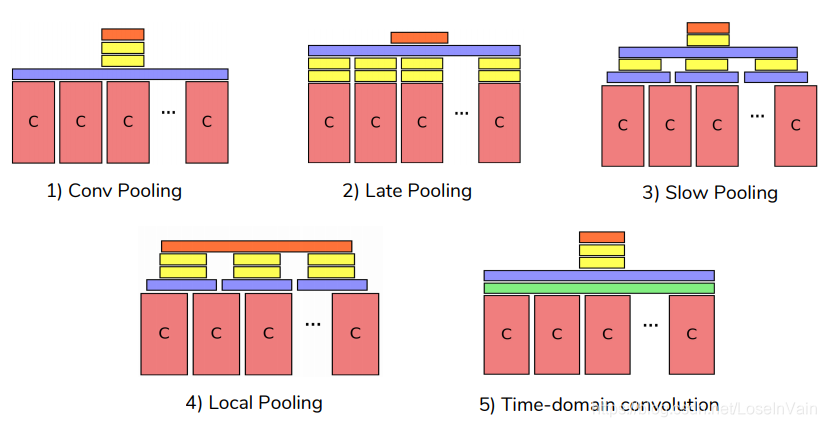
<div align='center'> <b> Fig 3.4 不同方式的时序池化。 </b> </div>
然而,[8]的作者得出的结论是时序池化比LSTM进行时序信息组织的效果好,这个结论然而并不是准确的,因为[8]的作者并不是端到端去训练整个网络。
如果单纯考虑CNN+RNN的端到端训练的方式,那么我们就有了LRCN网络[9],如Fig 3.5所示,我们可以发现其和[8]的不同在于其是完全的端到端网络,无论是时序和空间信息都是可以端到端训练的。同样的,[9]的作者的输入同样进行了若干种结合,有单纯输入RGB视频,单纯输入光流,结合输入光流和RGB的,结论发现结合输入光流和RGB的效果最为优越。这点其实值得细品,我们知道光流信息是传统CV中对运动motion信息的手工设计的特征,需要额外补充光流信息,说明光靠这种朴素的LSTM的结构去学习视频的时序信息,motion信息是不足够的,这点也在侧面反映了视频的时序组织的困难性。
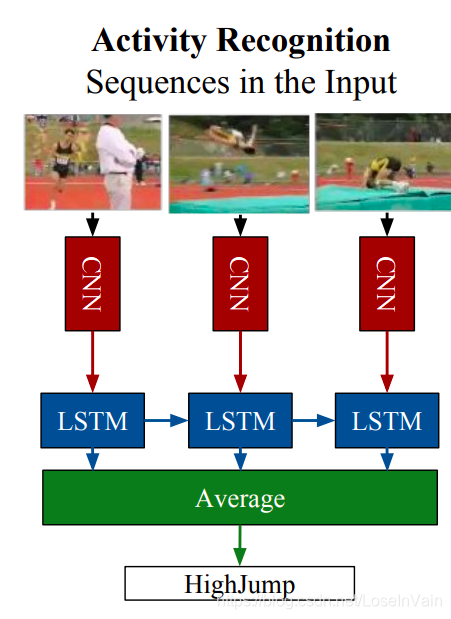
<div align='center'> <b> Fig 3.5 LRCN网络应用在动作识别问题。 </b> </div>
对比之后我们将会谈到的C3D网络,CNN+RNN的这种网络框架意味着我们可以利用ImageNet的海量标注图像数据去预训练CNN网络,这样使得我们模型性能更佳优越并且收敛更加稳定,事实上,如果完全从头训练LRCN网络(from scratch),那么按照笔者的经验是训练过程很不稳定,很容易发散,一般实际中我们都会采用已经经过预训练了的CNN作为特征提取器,然后固定住CNN后训练LSTM直至收敛后,再用较小的学习率端到端训练整个网络。
LRCN当然不可避免存在缺点,采用了光流信息作为输入意味着需要大量的预先计算用于计算视频的光流;而视频序列的长时间依赖,motion信息可能很难被LSTM捕获;同时,因为需要把整个视频分成若干个片段,对片段进行预测,在最后平均输出得到最终的视频级别的预测结果,因此如果标注的动作只占视频的很小一段,那么模型很难捕获到需要的信息。
结合光流信息并不是LRCN系列网络的专利,Two Stream Network双流网络[10]也是结合视频的光流信息的好手。在双流网络中,我们同样需要对整个视频序列进行采样,得到若干个片段,然后我们从每个片段中计算得到光流信息作为motion信息描述这个动作的运动,然后从这个片段中采样得到一帧图像作为代表(通常是最中间的帧,片段长度通常是10),表征整个片段的appearance信息。最终分别在motion流和appearance流都得到各自的分类结果,在最后层里进行各自分类结果的融合得到整个片段的预测结果。这种显式地利用光流来组织时序信息,把motion流和appearance流显式地分割开进行模型组织的,也是一大思路。

<div align='center'> <b> Fig 3.6 双流网络的网络示意图,需要输入视频的光流信息作为motion信息,和其中某个采样得到的单帧信息作为appearance信息。 </b> </div>

这里需要注意一些其中的技术细节,不然后面讨论我们可能会产生疑惑。我们的光流分别需要对x和y方向进行计算,因此对于同一张图而言,会产生x方向的光流和y方向的光流,如上图的(d)和(e)所示。因此,在实践中,如果我们取片段长度$L=10$,那么对于一个片段我们便会有20个光流通道,因此我们的motion流的输入张量尺寸为$(batch_size, 224,224,20)$,而appearance流的输入张量尺寸为$(batch_size, 224,224,3)$。我们发现motion流的通道数为20,不能直接用在经过ImageNet预训练过后的模型进行初始化,因为一般ImageNet上预训练的模型的输入通道都是3。为了解决这个问题,我们可以用经过ImageNet预训练的模型,比如VGG的第一层卷积层,比如为$kernel = (3,3,3,64)$,在输入通道那个阶求平均,也就是$kernel.mean(dim=2)$,然后得到一个尺寸如$(3,3,1,64)$的张量,用这个张量去初始化我们的motion流的输入的第一层卷积,这样虽然我们的motion流有20个输入通道,但是这个20个输入通道的参数是初始化为相同的。除去第一层卷积层,其他后续的层继续沿用经过预训练的VGG的层。因此,motion流和appearance流最后的输出特征图张量尺寸都是一致的,举个例子比如是$(batch_size, 64,64,256)$。那么我们分别对每个流都预测一个结果,然后对这个结果进行融合,比如求平均,得到对这个片段的最后识别结果。
当然,LRCN具有的问题,双流网络同样也有,包括计算光流的计算复杂度麻烦,采样片段中可能存在的错误标签问题(也就是采样的片段可能并不是和视频级别有着相同的标签,可能和视频级别的标注相符合的动作只占整个视频的很小一段。)对长时间依赖的动作信息组织也是一个大问题。然而,因为双流网络两个流主要都是用2D卷积网络进行特征提取,意味着我们同样可以使用在ImageNet上经过预训练的模型作为良好的参数初始化,这是双流网络的一大优点。
到目前为止,我们都是尝试对视频的单帧应用2D卷积操作进行特征提取,然后在时间轴上进行堆叠得到最终的含有时间序列信息的特征。
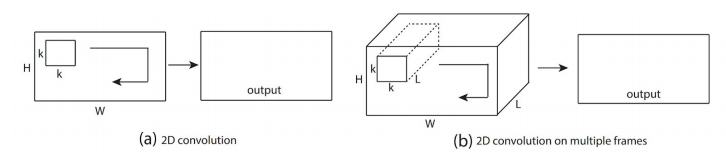
我们自然就会想到,如果有一种卷积,能在提取空间信息的同时又能够提取时序信息,那岂不是不需要手工去堆叠时序特征了?一步到位就行了。的确的,我们把这种卷积称之为3D卷积,3D卷积正如其名,其每个卷积核有三个维度,两个在空间域上平移,而另一个在时间轴上滑动卷积。

这样的工作可以追溯到2012年的文章[11],那该文章中,作者提出的网络不是端到端可训练的,同样设计了手工的特征,称之为input-hardwired,作者把原视频的灰度图,沿着x方向的梯度图,沿着y方向的梯度图,沿着x方向的光流图,沿着y方向的光流图堆叠层H1层,然后进行3D卷积得到最终的分类结果。如果我们仔细观察Fig 3.7中的3D卷积核的尺寸,我们发现其不是我们现在常见的$3\times3\times3$的尺寸。这个网络开创了3D卷积在视频上应用的先河,然而其也有不少缺点,第一就是其不是端到端可训练的,还是涉及到了手工设计的特征,其二就是其设计的3D卷积核尺寸并不是最为合适的,启发自VGG的网络设计原则,我们希望把单层的卷积核尽可能的小,尽量把网络设计得深一些。
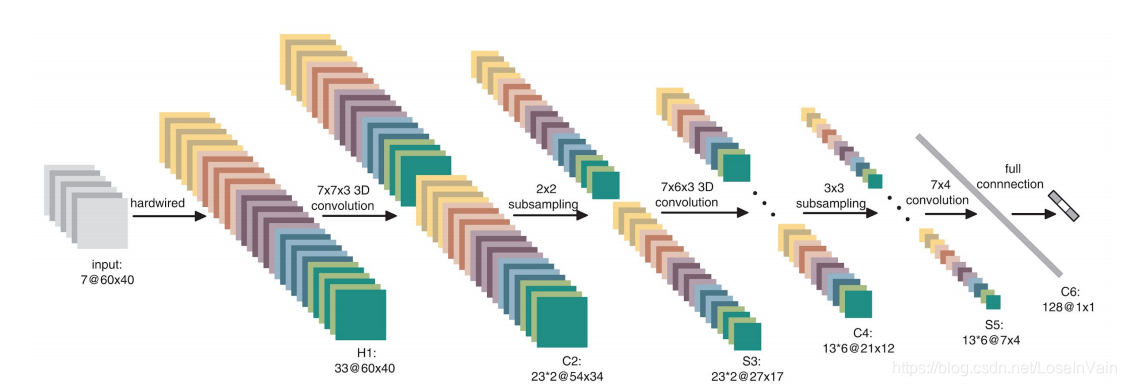
<div align='center'> <b> Fig 3.7 3D卷积网络的最初尝试。 </b> </div>
这些缺点带来了C3D[12]网络,与[11]最大的不同就是,C3D其使用的卷积核都是相同的尺寸大小,为$3\times3\times3$,并且其不涉及到任何手工设计特征输入,因此是完全的端到端可训练的,作者尝试把网络设计得更深一些,最终达到了当时的SOTA(state-of-the-art)结果。作者发现结合了iDT特征,其结果能有5%的大幅度提高(在ufc101-split1数据上从85.2%到90.4%)。

<div align='center'> <b> Fig 3.8 C3D网络框图示意。 <b/> </div>

<div align='center'> <b> Fig 3.9 3D卷积动图示意。 </b> </div>
尽管在当时C3D达到了SOTA结果,其还是有很多可以改进的地方的,比如其对长时间的依赖仍然不能很好地建模,但是最大的问题是,C3D的参数量很大,导致整个模型的容量很大,需要大量的标签数据用于训练,并且,我们发现3D卷积很难在现有的大规模图片数据集比如ImageNet上进行预训练,这样导致我们经常需要从头训练C3D,如果业务数据集很小,那么经常C3D会产生严重的过拟合。随着大规模视频动作理解数据集的陆续推出,比如Kinectics[13]的推出,提供了很好的3D卷积网络pre-train的场景,因此这个问题得到了一些缓解。我们知道很多医疗影像都可以看成是类似于视频一样的媒体,比如MRI核磁共振,断层扫描等,我们同样可以用3D卷积网络对医学图像进行特征提取,不过笔者查阅了资料之后,仍然不清楚是否在大规模动作识别数据集上进行预训练对医学图像的训练有所帮助,毕竟医学图像的时序语义和一般视频的时序语义差别很大,个人感觉可能在大规模动作识别数据集上的预训练对于医学图像帮助不大。
C3D系列的网络是完全的3D卷积网络,缺点在于其参数量巨大,呈现的是3次方级别的增长,即便是在预训练场景中,也需要巨大的数据才能hold住。为了缓解这个问题,有一系列工作尝试把3D卷积分解为2D卷积和1D卷积,其中的2D卷积对空间信息进行提取,1D卷积对时序信息进行提取。典型的3D分解网络有$F_{ST}CN$ [14], 其网络示意图如Fig 3.10所示。
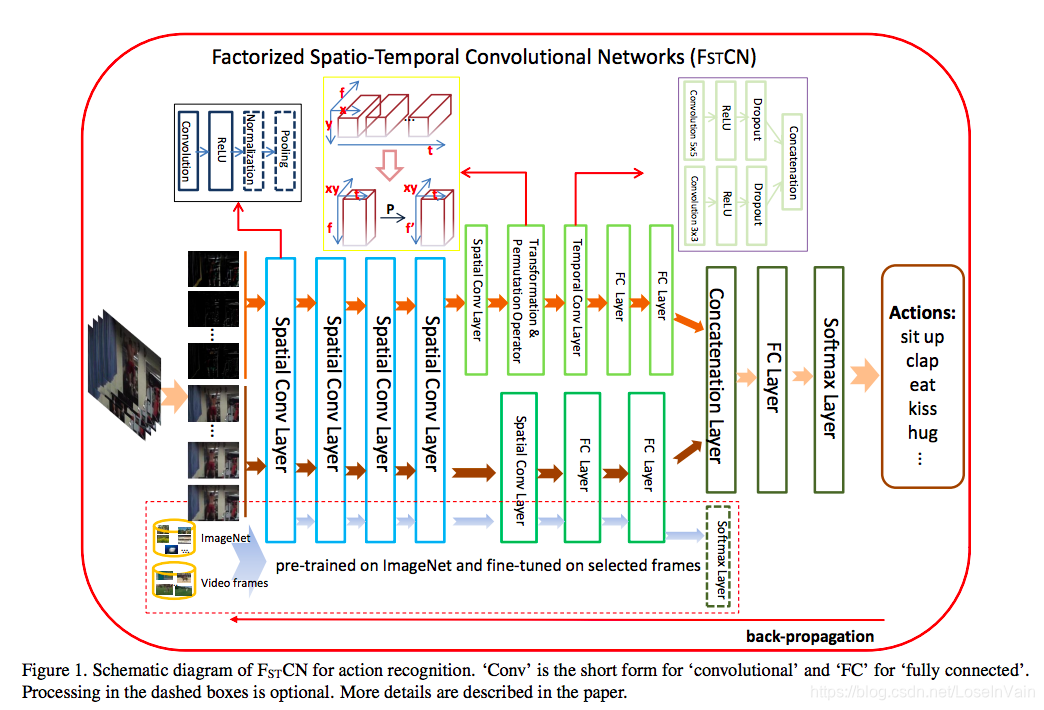
<div align='center'> <b> Fig 3.10 FstCN 网络的结构框图。 </b> </div>
Pseudo-3D ResNet(P3D ResNet)网络[15]则在学习ResNet的残差设计的路上越走越远,其基本的结构块如Fig 3.11所示。这个策略使得网络可以设计得更深,参数量却更少,然而性能表现却能达到SOTA结果,如Fig 3.12和Fig 3.13所示。
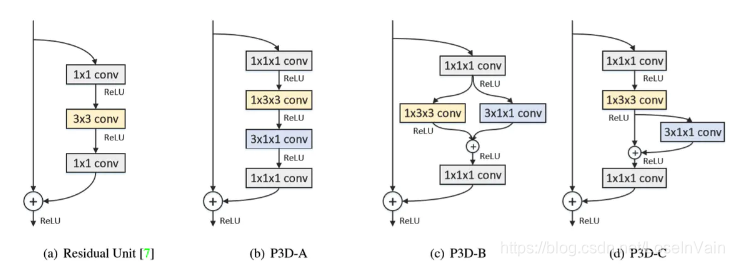
<div align='center'> <b> Fig 3.11 组成P3D的3种基本单元,分别是P3D-A,P3D-B,P3D-C。 </b> </div>
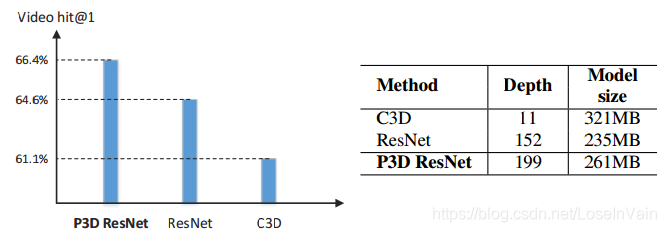
<div align='center'> <b> Fig 3.12 P3D ResNet比C3D的模型更小,深度更深,表现性能却更高。 </b> </div>
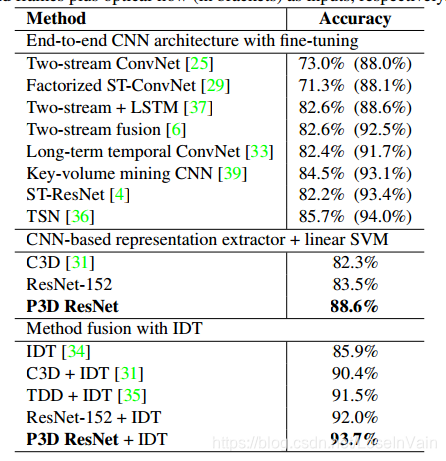
<div align='center'> <b> Fig 3.13 在UCF101上,众多模型的表现,P3D ResNet有着出色的表现。 </b> </div>
不仅如此,将3D分解成2D+1D的操作使得其在图像数据集上预训练成为了可能。(虽然这种预训练可能并没有LRCN和双流网络这种直观)
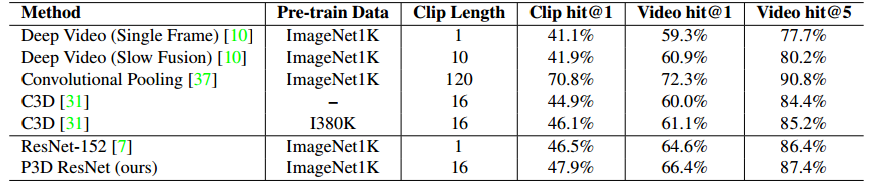
在文章[7]中,作者提出了R(2+1)D网络,作者对比了一系列不同的2D+1D的分解操作,包括一系列2D+3D的操作,如Fig 3.14所示。与P3D ResNet[15]不同的是,R(2+1)D采用了结构相同的单元,如Fig 3.15所示,而不像P3D中有3种不同的残差块设计。这种设计简化了设计,同时达到了SOTA效果。 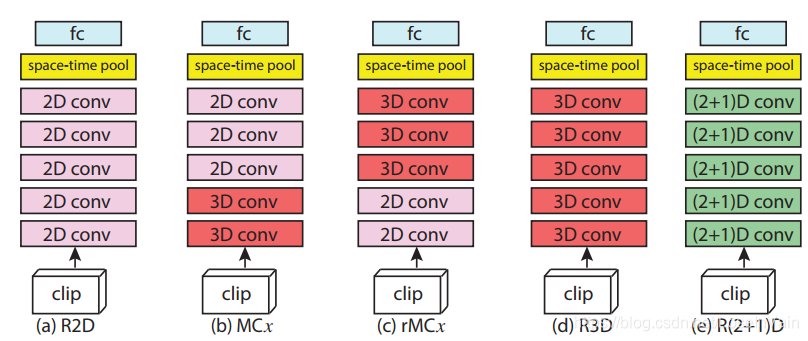
<div align='center'> <b> Fig 3.14 众多结合2D卷积和3D卷积的方法,其中实验发现R(2+1)D效果最佳。 </b> </div>
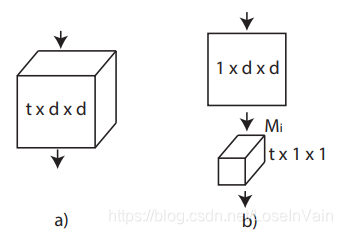
<div align='center'> <b> Fig 3.15 (2+1)D conv单元示意图,把3D卷积进行分解成了空间域卷积和时间域卷积。 </b> </div>
至此,我们讨论了视频动作识别中的若干基础思路:1.通过CNN+RNN;2.通过双流,显式地分割motion信息流和appearance信息流;3.通过3D卷积进行直接空间时间信息提取。
我们的旅途就到此为止了吗?不,我们刚出新手村呐,我们的冒险才刚刚开始,我们后续讨论的网络,或多或少受到了以上几种模型的启发,或者将以上几种模型融合起来进行改造,或添加了新的亮点,比如加入了attention注意力机制,self-attention自注意力机制等。
不过我们不妨暂且在本站结尾做个小总结:视频分析难,难在其特征不仅仅是2D图像中的二维特征了,二维特征图像现在有着多种大规模的图像数据集可以提供预训练,并且对图像进行人工标注,在很多任务中都比对视频标注工作量要小。正因为超大规模的图像标注数据集的推出,使得很多图像问题在深度学习方法加持下得到了快速的发展,在某些领域甚至已经超过了人类。
然而视频分析不同,视频是有一系列语义上有联系的单帧二维图像在时间轴上叠加而成的,而提取时序语义信息是一件不容易的事情,种种实验证明,现存的深度网络在提取时序语义特征上并没有表现得那么好,否则就不需要人工设计的光流特征进行加持了。深度网络在时序特征提取上的缺失,笔者认为大致有几种原因:
- 标注了的视频数据量不足。
- 时序信息的分布变化比二维图像分布更为多样,对于图像,我们可以进行插值,采样进行图像的缩放,只要不是缩放的非常过分,人类通常还是能正常辨认图像的内容。而视频帧间插帧却是一件更为困难的事情。因此不同长度之间的视频之间要进行适配本身就是比较困难的事情。当然你可以进行视频时序下采样,但是如果关键帧没有被采样出来,那么就会造成有效信息的丢失,相反,图像的缩放比较少会出现这种问题。说回到时序信息的分布的多样性就体现在这里,同一个动作,发生的长度可能截然不同,所造成的时序是非常复杂的,需要组织不同长度的时序之间的对齐,使得组织动作的motion变得很不容易,更别说不同人的同一个动作的motion可能千差万别,涉及到了原子动作的分解。
标注的视频数据量不足并不一定体现在视频级别的标注少,带有动作标签的视频级别的数据可能并不少,但是这些视频可能并没有进行过裁剪,中间有着太多非标注动作类别相关的内容。对视频进行动作发生时段的准确定位需要非常多的人工,因此标注视频变得比较困难。同时,一个视频中可能出现多个人物,而如果我们只关注某个人物的动作,对其进行动作标注,如果在样本不足的情况下,便很难让模型学习到真正的动作执行人,因此对视频的标注,单纯是视频级别的动作标注是非常弱的一种标注(weak-supervision)。我们可能还需要对一个视频进行多种标注,比如定位,动作类别,执行人bounding-box等等。
同时,给视频标注的信息也不一定准确,标签本身可能是带有噪声的。有很多标签可能来自于视频分类的tag,这些tag分类信息大多数来自于视频本身的上传者,是上传者自己指定的,可能存在有较大的噪声,然而这类型的数据量非常巨大,不利用却又过于可惜。类似于这种tag标签,现在弹幕网站的弹幕也是一种潜在的可以利用的带噪声的标签。
随着海量的无标签或者弱标签,带噪声标签在互联网上的与日俱增,在视频数据上,弱监督学习,带噪声的标签的监督学习,自监督学习,半监督学习将有广阔的空间。
视频动作理解——更进一步
我们在上一站已经对基本的视频动作理解的框架有了基本了解,考虑到模型需要对时空信息进行建模,归结起来无非有三种大思路,如Fig 4.1所示:
-
CNN+RNN: 这种类型的网络以LRCN[9]为代表,利用CNN提取单帧图片的空间特征,然后利用RNN系列的网络对提取好的单帧图片特征进行时序建模,最后得到视频片段的预测结果。
- 优点:可以直接自然地利用在大规模图像数据集比如ImageNet上的预训练结果。
- 缺点:后端的RNN网络是对高层次的语义特征进行建模,对于低层次的运动motion特征则爱莫能助,因为低层次的motion信息很多时候都取决于了前端的CNN的能力,而前端的CNN在此时并没有motion建模的能力。
总结: 因此,LRCN系列的网络对于单帧appearance差别明显的数据集,表现可能会更为理想。模型参数量在三种基本模型中最小。
-
3D-ConvNet : 3D卷积网络以C3D[12]为典型代表,将2D卷积核在时间方向延伸了一个维度,自然地形成了3D卷积核,以期望用3D卷积核的层叠学习到视频的时空语义特征。
- 优点:是2D卷积的自然延伸,一站式地学习motion和appearance信息,能理论上真正做到时空语义的提取。
- 缺点:参数量是3次方级别的,参数量过大,容易导致过拟合。不能直接地利用在图像数据集上的预训练模型进行初始化模型参数。
总结 : 3D卷积网络在高维医学图像和视频分析中都有广阔的应用,其存在很多尝试分解3D卷积成2D+1D卷积的操作,而且都有不错的效果。模型参数量在三种基本模型中最大。
-
Two-Stream: 双流网络[]显式地分割了motion流和appearance流两种信息,(大部分)利用人工设计的光流特征进行视频的motion信息建模,用RGB片段的单帧信息作为appearance信息,利用预训练的CNN进行特征提取后,融合不同流的预测结果得到最终视频片段的预测。
- 优点:可以直接自然地利用预训练的大多数CNN网络,如VGG,ResNet等。效果良好,现在很多工作都是基于双流网络进行改造而成。直接用光流信息去建模motion信息,使得在较小样本的数据集中也能有不错效果。
- 缺点:大部分工作的光流信息都是需要预训练的,这样无法提供一个端到端的预训练场景,同时,光流计算耗费较多的计算资源。
总结: 双流网络是目前动作识别领域较为常用的基本模型,其效果良好,模型参数量在三种基本模型之间。
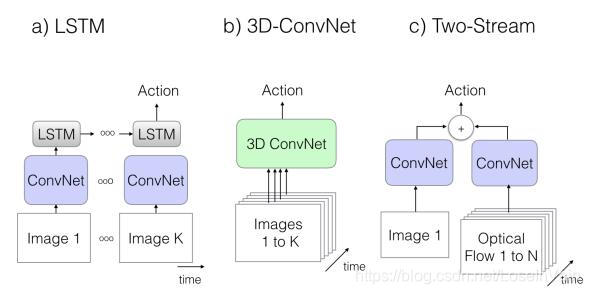
<div align='center'> <b> Fig 4.1 三种基本的对视频动作进行分析的模型框架。 </b> </div>
以上的总结其实也阐明了在视频动作理解中的几个基本难题:
- 如何高效利用已经在大规模图像数据集ImageNet上已经预训练好了的网络,对视频理解模型进行初始化?
- 视频长度一般是变长的,经常需要做片段采样,那么我们如何对样本采样比较合适?
- 光流预计算需要花费大量计算资源,并且不能进行端到端训练。
- 如何更好地组织motion和appearance信息的关系?
- 对于双流网络的流信息融合来说,以什么方式融合?在哪个层融合能取得最好效果?
那么我们接下来的内容,基本上都是在回答这些问题。Follow my lead and go on~
双流网络的信息融合——如何融合,何处融合
时空域信息融合

我们之前谈到过,我们一般的双流网络的输出无论是motion流还是appearance流,其最后一层的输出张量尺寸都是一致的,我们可以用式子(4.1)表示: $$ \mathbf{x}{t}^a \in \mathbb{R}^{H \times W \times D} \ \mathbf{x}{t}^b \in \mathbb{R}^{H^{\prime} \times W^{\prime} \times D^{\prime}} \tag{4.1} $$ 其中$\mathbf{x}t^a$表示motion流特征输出,$\mathbf{x}{t}^b$表示appearance流特征输出, $H$表示height,$W$是width, $D$表示最终输出通道数depth。我们对两个流的信息融合可以表示为(4.2) $$ f: \mathbf{x}_t^a, \mathbf{x}_t^b \rightarrow \mathbf{y}_t \ \mathbf{y}_t \in \mathbb{R}^{H^{\prime\prime} \times W^{\prime\prime} \times D^{\prime\prime}} \tag{4.2} $$ 其中的映射$f$就是我们需要指定的信息融合函数,通常为了方便,我们假定$H = H^{\prime}, W = W^{\prime}, D=D^{\prime}$,并且把下标$t$省略。我们期待的信息融合,如Fig 4.2所示,应该可以找到motion流和appearance流之间的对应关系,而不应该是割裂开的。在传统的双流网络[10]中,因为双流信息融合只在最后进行各自流的预测合并(比如说平均操作)的时候才体现出来,因此motion流信息其实并没有在各个层次(hierarchy)上和appearance流信息很好地对应。我们希望的双流信息融合应该如Fig 4.2所示。

<div align='center'> <b> Fig 4.2 理想的motion流和appearance流特征融合应该能找到两个流之间的对应特征部分。 </b> </div>
在文章[16]中,作者对若干种双流信息融合方式进行了介绍和实验对比,同时对何处进行信息融合进行了实验。通过结合最佳的信息融合方式和信息融合层的位置,作者提出了所谓的双流融合网络(Two Stream Fused Network)。
一般,有以下几种方式融合信息:
-
sum fusion,加和融合,表示为$y^{sum} = f^{sum}(\mathbf{x}^a, \mathbf{x}^b)$。如果$i,j$分别表示第$d$个通道的$i,j$空间位置,那么我们有 $y_{i,j,d}^{sum} = x^{a}{i,j,d}+x^{b}{i,j,d}$。因为通道数的排序是任意的,因此并不意味着$\mathbf{x}{i,j,1}^a$和$\mathbf{x}{i,j,1}^b$有着对应的语义含义,当然这种任意的对应关系我们可以通过后续设计网络进行学习,以求达到最好的优化效果。
-
max fusion,最大融合,表示为$y^{max} = f^{max}(\mathbf{x}^a, \mathbf{x}^b)$。同样有着:$y_{i,j,d}^{max} = \max(x^a_{i,j,d}, x^b_{i,j,d})$。和sum fusion类似的,其对应关系也是任意的。
-
Concatenation fusion,拼接融合,表示为$y^{concat} = f^{concat}(\mathbf{x}^{a},\mathbf{x}^{b})$,其叠在通道叠加了两个流的特征图。同样我们有: $$ \begin{aligned} y^{cat}{i,j,2d} &= x^{a}{i,j,d} \ y^{cat}{i,j,2d-1} &= x^{b}{i,j,d} \end{aligned} \tag{4.3} $$
拼接融合没有指定显式的对应关系,因此必须通过后续的网络设计进行学习这种对应关系。
-
Conv fusion,卷积融合,表示为$y^{conv} = f^{conv}(\mathbf{x}^a, \mathbf{x}^b)$。首先,我们需要对两个特征图进行在通道上的叠加,然后用一系列的卷积核$\mathbf{f} \in \mathbb{R}^{1 \times 1 \times 2D \times D}$和偏置$\mathbf{b} \in \mathbb{R}^{D}$进行卷积操作,有: $$ \mathbf{y}^{conv} = \mathbf{y}^{concat} * \mathbf{f}+\mathbf{b} \tag{4.4} $$ 我们发现这里的卷积操作是1x1卷积,同时进行了通道数的缩小,保持了输入输出尺寸的一致。
-
Bilinear fusion,双线性融合,表示为$y^{bil} = f^{bil}(\mathbf{x}^a, \mathbf{x}^b)$,其在每个像素位置,计算了两个特征图的矩阵外积,定义为: $$ \mathbf{y}^{bil} = \sum^{H}{i=1}\sum{j=1}^{W}(\mathbf{x}^{a}{i,j})^{\mathrm{T}}\mathbf{x}^{b}{i,j} \tag{4.5} $$ 这个产生的融合特征输出为$\mathbf{y}^{bil} \in \mathbb{R}^{D^2}$,具有过高的维度,容易导致过拟合,因此在实际中比较少应用。
作者对这几种融合方式进行了实验,得出了其模型准确度和模型参数量的实验结果。如Fig 4.3所示。
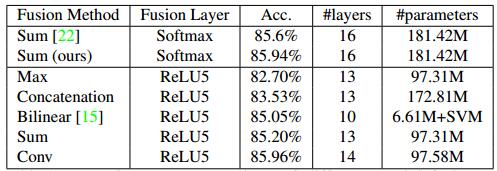
<div align='center'> <b> Fig 4.3 各种不同的双流信息融合方式的实验结果和模型参数量。 </b> </div>
我们发现,Conv fusion能在较少的模型参数量下,达到最好的实验性能。

同时,如上图所示,作者探索了在双流网络的哪个层进行融合效果会最好,最后得出实验结果如Fig 4.4所示。我们发现ReLU5+FC8的这个配置能达到最好的性能。

<div align='center'> <b> Fig 4.4 在双流网络的各个层进行融合取得的效果和模型大小实验结果。 </b> </div>
时序信息融合
我们之前谈到的是时空信息融合,指的是将motion流和appearance流融合起来的方式探索。而这个一般是在单个的片段中进行的操作,考虑到如何融合视频中不同片段之间的信息,形成最终的对整个视频的分类结果,我们就需要考虑时序特征建模了。考虑到如何将不同时间$t$的特征图$\mathbf{x}_t$融合起来,一般也可以称之为时序信息建模或者时序特征集成,我们接下来继续探索时序信息融合。
当然一种最为简单的方式,正如在原始的双流网络[10]中提到的,直接对不同时刻的网络预测结果进行平均,这种平均操作忽略了具体的时序结构,理论上,网络无法分清楚“开门”和“关门”的区别。在这种平均的情况下,这种模型框架只是对空间上的像素或者特征进行了2D池化,如Fig 4.5 (a)所示。
现在,让我们将$T$个空间特征图$x^{\prime} \in \mathbb{R}^{H \times W \times D}$进行堆叠,那么我们就有了时序池化层的输入特征张量$\mathbf{x} \in \mathbb{R}^{H \times W \times T \times D}$。我们接下来定义两种不同的时序池化层,它们可以对时序信息进行集成。
-
3D pooling,在堆叠的特征图$\mathbf{x}$上作用以池化核尺寸为$W^{\prime} \times H^{\prime} \times T^{\prime}$的max-pooling池化核,如Fig 4.5 (b)所示。注意到,在不同通道$D$上没有进行任何的池化。
-
3D Conv+3D Pooling,用一系列卷积核大小为$\mathbf{f} \in \mathbb{R}^{W^{\prime\prime} \times H^{\prime\prime} \times T^{\prime\prime} \times D \times D^{\prime}}$的卷积核和尺寸为$\mathbf{b} \in \mathbb{R}^{D^{\prime}}$的偏置对堆叠的特征图 $\mathbf{x}$ 进行卷积后,进行3D池化,如Fig4.5 (c)所示,有: $$ \mathbf{y} = \mathbf{x}_t *\mathbf{f} + \mathbf{b} \tag{4.6} $$
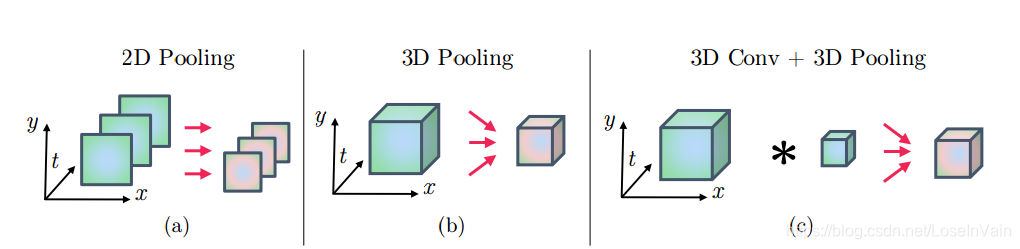
<div align='center'> <b> Fig 4.5 三种不同的时序池化方式,留意图中的坐标轴的标签。 </b> </div>
如Fig 4.6所示,作者接下来对以上提到的若干种时序特征建模进行了实验,发现3D conv+3D pooling效果最好。
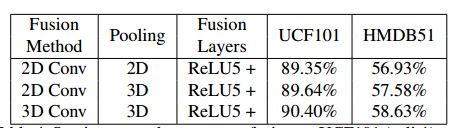
<div align='center'> <b> Fig 4.6 作者尝试了若干种时序特征建模的方式,发现3D conv+3D pooling的方式效果最好。 </b> </div>
双流融合网络
基于之前的讨论,作者根据Fig 4.7所示的基本框架提出了双流融合网络(Two-Stream Fusion Network),这个网络在双流信息融合上花了一番心思设计。作者在conv5层后进行双流信息的3D conv fusion融合,同时,作者并没有截断时间流信息(这里的时间流信息是多张RGB帧层叠而成,见Fig 4.7的右半部分),而是用刚才提到的时序信息融合,用3D Conv+3D Pooling的方式融合了时序信息流,于是我们有两个分支:一个是时间-空间双流融合信息,一个是时序特征流。如Fig 4.8的spatia-temporal loss和temporal loss所示。
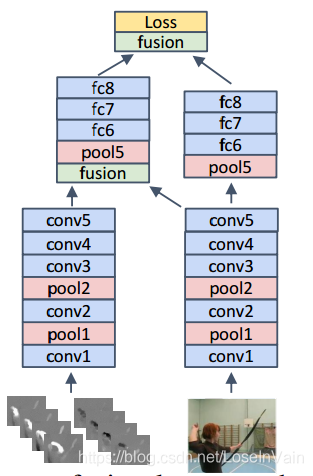
<div align='center'> <b> Fig 4.7 双流融合网络的主干框架。 </b> </div>
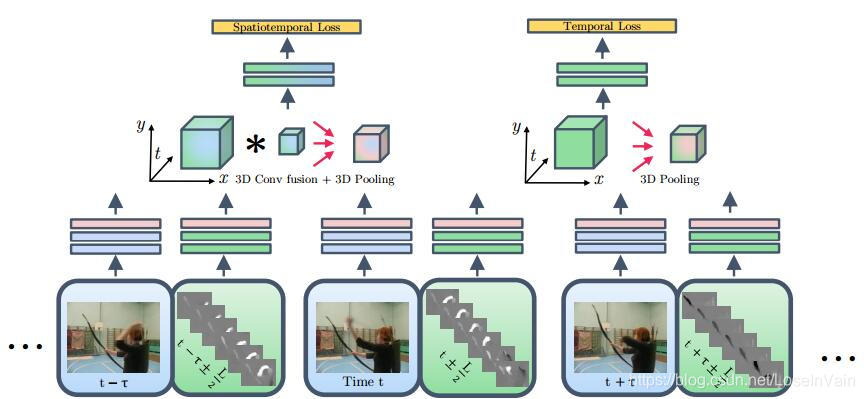
<div align='center'> <b> Fig 4.8 双流融合网络的网络框图,主要有时空损失和时序损失组成,其前端和传统的双流网络没有太大区别,主要是在时序融合上采用了3D conv+3D pooling的方式。 </b> </div>
整个网络的实验结果如下图所示:
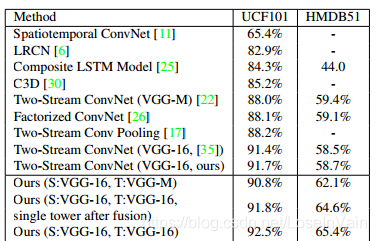
双流融合网络在用少于C3D的参数量的同时,提高了模型性能,是双流信息融合网络系列的开山鼻祖。我们之后的很多网络,包括I3D等,都是由它启发而来。
将2D卷积网络预训练模型扩展到3D卷积网络上
还记得我们之前谈到3D卷积网络有个很大的缺点是啥吗?3D卷积网络很难直接应用在图像数据上预训练的结果,导致经常需要大规模的标注视频数据集进行预训练,然而这种数据远比图片数据难收集。文献[13]的作者发现了这个问题,提出了两个解决方案:
- 采集大规模标注视频数据集Kinetics ——这点很直接粗暴,但是很有用。
- 采用将已经预训练好了的2D卷积网络的2D卷积核“膨胀”(inflate)到对应的3D卷积核的操作,利用了预训练的CNN模型。这个模型作者称之为I3D(Inflated 3D ConvNets)。
如果把之前已经介绍过了的几种模型都列成一个简图,那么我们有Fig 4.9。其中(a)-(d)我们在之前的内容中介绍过了,而(e) Two-Stream 3D-ConvNet也就是本节所说的I3D网络。我们可以发现,这种网络的基本框架还是利用了双流网络的结构,不过改变了以下几个要点:
- 完全采用3D ConvNet作为特征提取器,提取时空信息。
- RGB输入不再是单帧了,而是把整个视频输入3D卷积网络进行特征提取,同样的,光流motion流的输入也不再是片段的长度了,而是整个视频的长度。
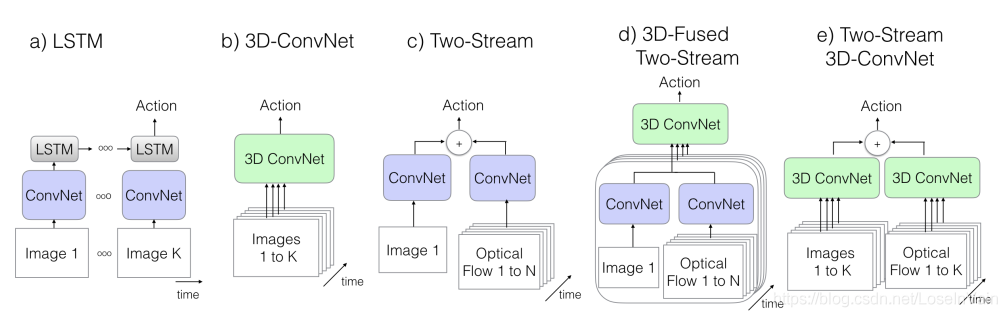
<div align='center'> <b> Fig 4.9 五种动作识别的网络简图,前四种我们已经介绍过了。其中的K代表的是整个视频的长度,N表示的是某个帧周围的邻居的长度,比如某个时间帧t,如果N=10,那么就会在[t-5,t+5]的范围内对视频采样。 </b> </div>
我们先不关心作者是怎么采集大规模数据集的,我们关心作者是怎么对2D卷积核进行“膨胀”的。我们考虑到一个2D卷积核,其尺寸为$(N \times N)$,那么我们为它添加一个时间维度,得到尺寸为$(N \times N \times 1)$的卷积核,将这个卷积核在第三个维度复制N次,我们就有了$(N \times N \times N)$的3D卷积核。这个结论其实可以推导:
假设我们想要找ImageNet上训练3D卷积网络,我们可以考虑一种最简单的方式,[13]的作者称之为boring-video fixed point。我们把一张图片,复制M次,层叠形成一个视频,只不过这个视频并没有时序上的信息,所有帧都是重复的,然后用这个视频去训练3D卷积网络。由于线性性,我们可以将整个过程简化为将2D卷积核进行时间维度的复制。这种方式使得I3D网络可以在ImageNet上进行预训练,如Fig 4.10所示,这种策略的确产生了不错的效果。

<div align='center'> <b> Fig 4.10 在ImageNet上预训练对于I3D网络的性能提升。 </b> </div>
目前而言,I3D网络在各个benchmark数据集上的表现都不错,是一个不错的baseline基线网络。
此外,在工作[20]中,作者提到了一种有趣的方法,其可以将2D pretrain的卷积网络的参数扩展到3D卷积网络上。如Fig 4.11所示,这种方法采用了类似于Teacher-Student Learning的方法,主要有两个分支,第一个分支是蓝色显示的预训练好了的2D卷积网络,第二个分支是绿色显示的需要进行迁移参数的3D卷积网络,我们的蓝色分支对输入的RGB单帧进行处理,绿色分支对视频片段进行处理,我们的绿色和蓝色分支的输入可能来自于同一个视频,称之为正样本对,也可能来自于不同视频,称之为负样本对,我们的网络目标就是判断这两个输入是否是正样本还是负样本,用0/1表示。通过这种手段,我们可以让3D卷积网络学习到2D卷积预训练网络的知识。
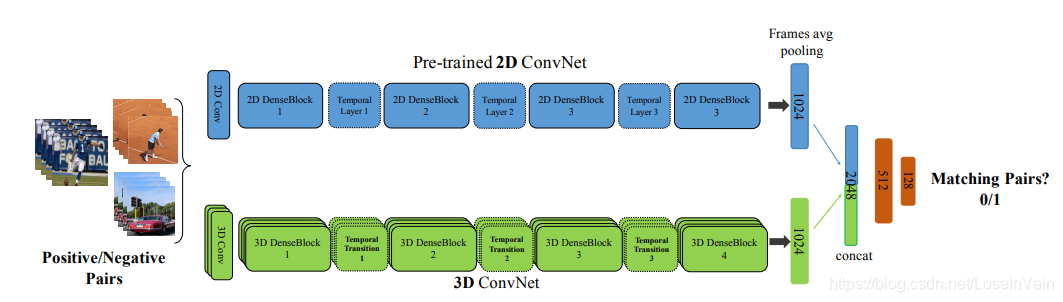
<div align='center'> <b> Fig 4.11 T3D中提到的利用2D卷积网络的预训练模型去初始化3D卷积网络参数的方法。 </b> </div>
内嵌光流计算的深度网络
我们之前谈到的网络利用了光流信息,而这里的光流信息无一例外是需要通过人工设计的方法进行预计算的,能不能考虑一种方法可以利用深度网络提取光流信息呢?[17]的作者提出了MotionNet,如Fig 4.12所示,在基于双流网络的主干上,采用深度网络提取光流信息。作者将光流提取问题视为图形重建(image reconstruction)问题,利用bottleneck的网络结构,对给定的RGB输入$I_{RGB}$,给定其光流作为输出标签(可以通过传统算法计算得到)记为$I_{flow}$,经过监督学习可以单独训练MotionNet,待其独立训练完后,可以联合起整个网络端到端训练。
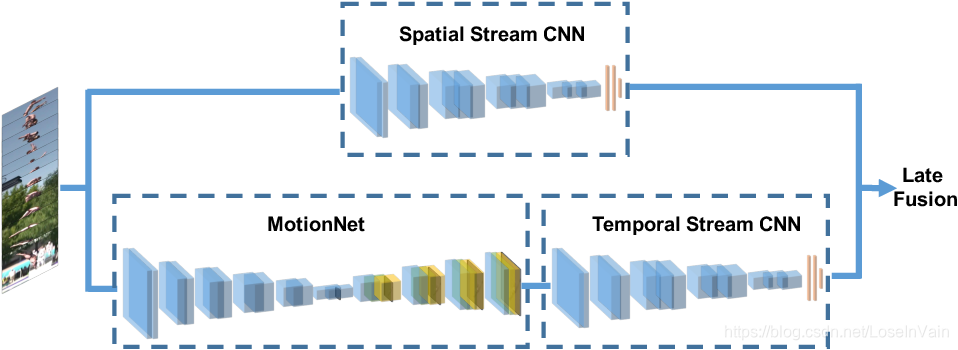
<div align='center'> <b> Fig 4.12 MotionNet的网络框图。 </b> </div>
其他模态的视频序列动作分析
之前介绍的都是RGB视频或者结合了根据RGB视频计算得到的光流信息作为输入模态,进行视频动作理解的一些方法。笔者本身的研究方向是多视角动作识别,数据输入模态多是骨骼点skeleton数据,如Fig 5.1所示。具体关于骨骼点数据的特点介绍,见笔者之前的文章[2]。在本站,我们尝试讨论骨骼点序列的动作识别和多视角动作识别。
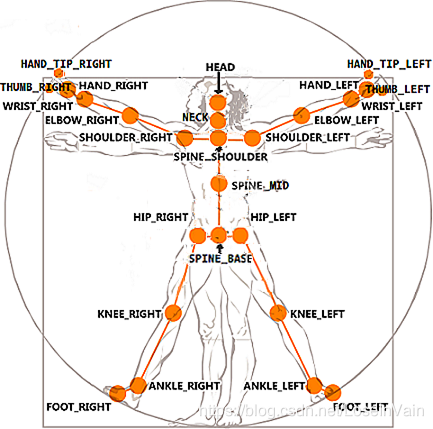
<div align='center'> <b> Fig 5.1 利用Kinect v2.0[21]得到的骨骼点排序 </b> </div>
总得来说,骨骼点数据可以看成是极端的将motion信息给提取了出来,而丢失了所有的appearance信息。如Fig 5.2所示,我们能很清楚地判断人物的动作,但是涉及到人物的衣着打扮,交互的物体是什么等信息,却是完全没办法判断了。因此,用skeleton骨骼点数据去组织motion信息是一种非常好的手段,但是涉及到与appearance有关的数据,就必须引入RGB视频信息,这类型的多模态问题,已有关于此的不少工作[23]。
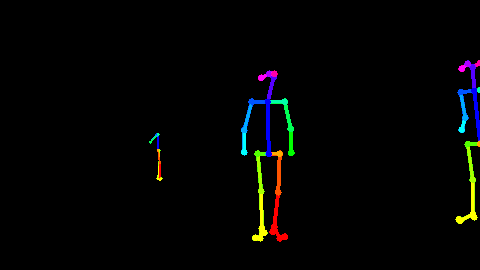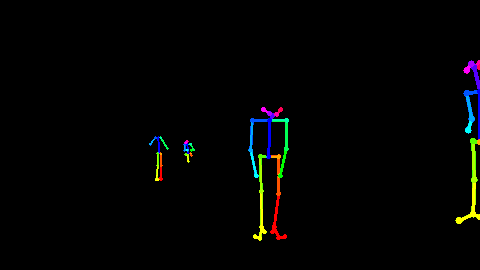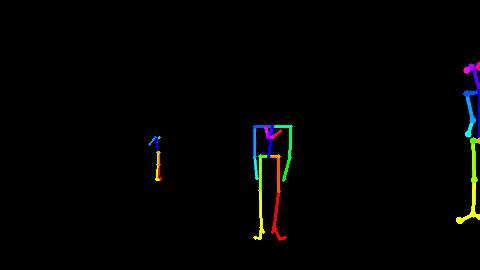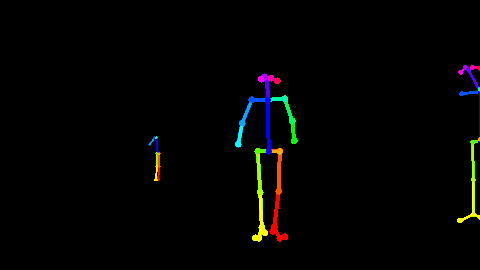
<div align='center'> <b> Fig 5.2 利用Openpose[22]对RGB视频估计出来的骨骼点数据 </b> </div>
骨骼点数据一般有两种类型,2D骨骼点数据或者3D骨骼点数据,2D骨骼点数据多是从RGB视频中进行姿态估计得到,而3D骨骼点数据一般需要深度信息,在某些文献中[24],存在将根据RGB视频姿态估计得到的2D骨骼点姿态,通过深度网络推断出3D骨骼点姿态的工作,如Fig 5.3所示。
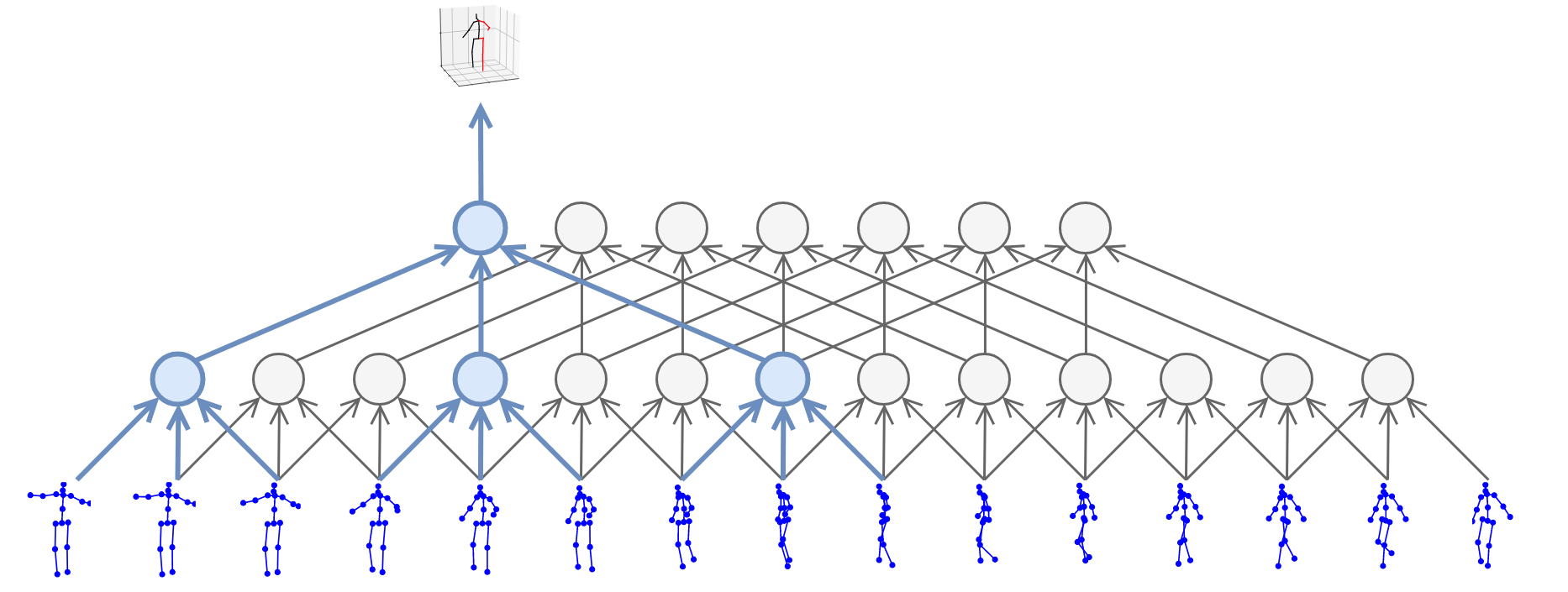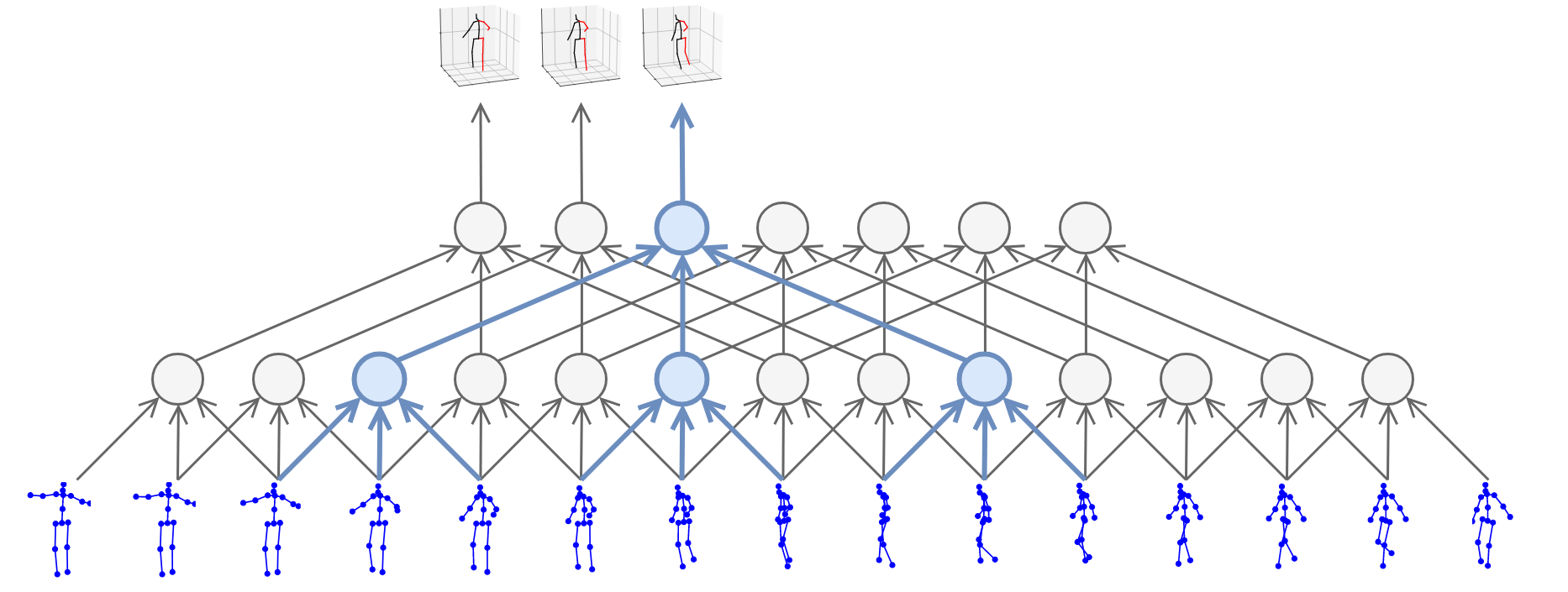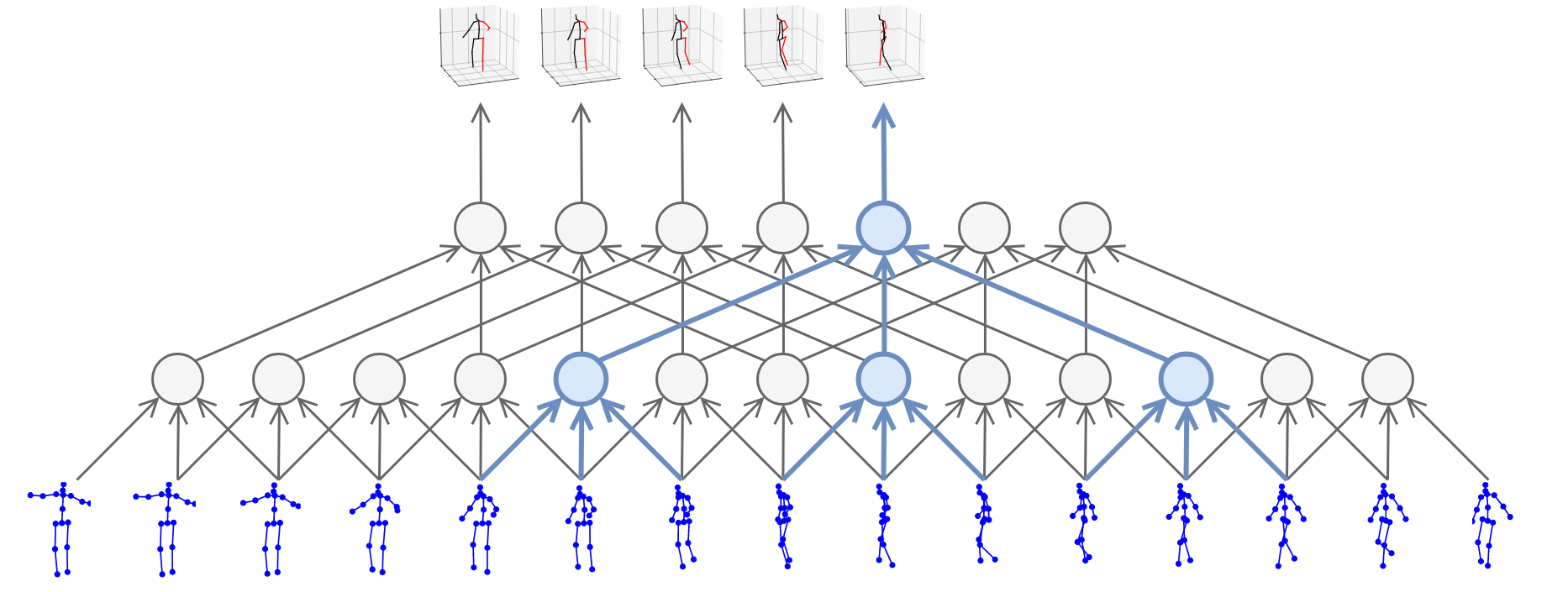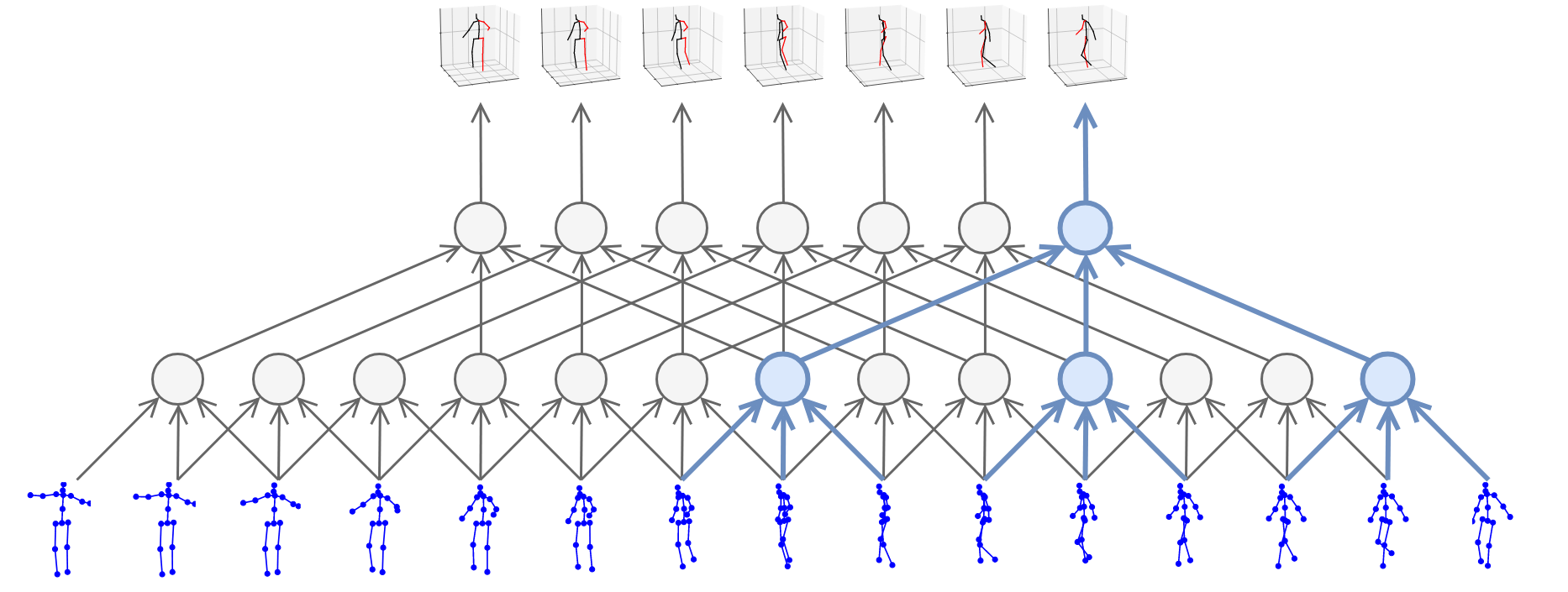
<div align='center'> <b> Fig 5.3 利用RGB模态信息进行3D关节点的姿态估计。 </b> </div>
对于骨骼点数据而言,一般可以表示为张量: $$ \mathbf{S} \in \mathbb{R}^{\mathrm{nframes} \times \mathrm{njoints} \times \mathrm{ndimension}} \tag{5.1} $$ 其中nframes表示帧数,njoints表示关节点的数量,比如25个关节点一个人一帧,ndimension是维度,比如3D骨骼点是3,而2D骨骼点是2。而这里的数据,一般都是骨骼点的空间坐标数据,比如Fig 5.4所示:

<div align='center'> <b> Fig 5.4 3D骨骼点数据,一般用物理尺度作为单位,比如米。 </b> </div>
骨骼点数据的建模,特征提取和RGB,光流等这类数据不同,骨骼点数据是属于graph图数据,属于典型的非欧几里德结构数据[25],而RGB,光流图属于欧几里德结构数据。非欧几里德数据意味着在骨骼点上不能直接应用传统的CNN,因为很直观的,每个节点周围的节点数都不一致,结构化的CNN根本无从下手。
根据笔者的研究经验,对骨骼点数据进行深度网络建模,可以有以下三种主要思路:
- 利用LSTM时序网络对骨骼点进行建模,因为单帧的骨骼点数据可以拉平(flatten)成一个向量,通过最简单的全连接层可以作为单帧提取器,然后用LSTM进行时序建模。
- 对骨骼点序列进行处理,将其拼成一个二维图像类似的数据结构后直接应用传统的CNN模型进行建模。在这类方法中,CNN模型通常需要同时对时间-空间信息进行建模。
- 把骨骼点序列看成时空图(spatia-temporal graph)数据,利用图神经网络,比如GCN图卷积网络进行建模[25,26,27]。
接下来笔者在各个小节将对这几点进行展开,休息一下,我们要开始了哦~
LSTM时序组织模型
在本框架中,我们需要对骨骼点序列进行两种最为主要的操作:
- 如何对单帧的骨骼点信息进行组织
- 如何组织时序信息
对单帧的骨骼点信息进行组织并不容易,因为单帧的骨骼点数据是一种Graph数据,或者也可以看成是一种Tree数据,需要指定特定的遍历策略将这种数据“拉平”成一维向量。单纯地按照关节点的顺序从1到25的遍历一遍骨骼点显然不能有效组织空间信息。举个例子,某些动作如跑步,双腿的规律性运动通常也会伴随着双臂的规律性摆动,这种身体部件与身体部件有关的关联,用这种简单的方法不能很好地进行建模。
在P-LSTM[28]中,作者采用LSTM作为基本的框架组织时序信息,同时,作者对LSTM的输入门,遗忘门,和门控门进行了魔改。作者把身体划分为五大部件,如Fig 5.5所示。通过这种方式,对不同身体部件之间的空间语义关系进行了初步的建模。
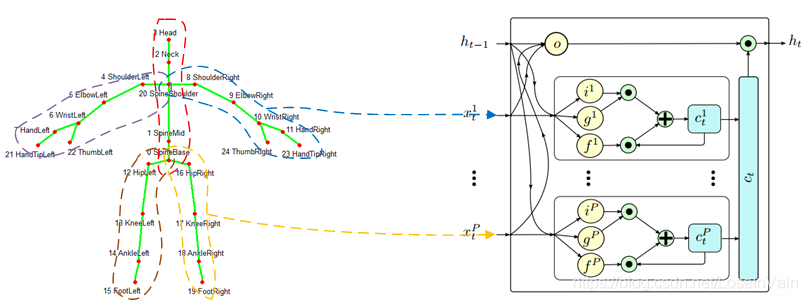
<div align='center'> <b> Fig 5.5 在P-LSTM中,作者把人体部件分为五大部分,并且分别输入P-LSTM单元中。 </b> </div>
在[29]中,作者提出ST-LSTM,利用LSTM进行3D骨骼点时间序列的时间-空间信息融合,并且开创性地采用了人体骨骼点的树形索引进行骨骼点的检索,如Fig 5.6所示。3D骨骼点数据难免存在一些因估计导致的噪声,因此并不是所有骨骼点都是可信的。在[29]中,不仅用LSTM对骨骼点数据进行时空上的信息组织,而且在传统的LSTM细胞中引入了置信门(Trust Gate)分析每一个时空步中每个节点的可靠程度。
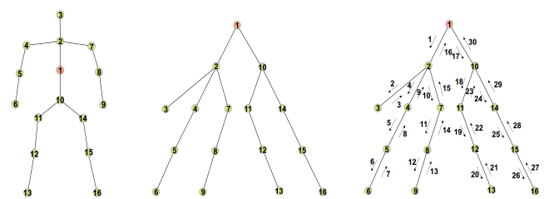
<div align='center'> <b> Fig 5.6 对骨骼点数据的树形索引方式。 </b> </div>

<div align='center'> <b> Fig 5.7 在ST-LSTM中,在Spatial空间域和Temporal时间域都有LSTM单元,对骨骼点序列的时空信息,包括带噪声的骨骼点进行了建模。 </b> </div>
总结来说,在这类型方法中对于骨骼点信息的空间信息组织是一件不容易的事情,单纯的分部件或者树形索引,在某些程度上也不能很好地遍历身体不同部件之间的关系,也没有显式地提供让后续网络学习到这种关系的通道。
二维图像化CNN建模
我们之前分析过骨骼点序列不能应用于2D ConvNets的原因。然而我们可以考虑把骨骼点序列转化为二维图像类似的数据结构,从而直接应用2D卷积网络。考虑到骨骼点序列的通常输入张量尺寸为$\mathbf{s} \in \mathbb{R}^{300,25,3}$,其中300是帧数,25是节点数,3是维度。我们发现,如果把300看成是图像的height,25看成是图像的width,3看成是图像的通道数,如Fig 5.8所示,那么骨骼点序列就天然地变成了一种二维图像。
这种方法在[30]中得到了描述和实验,开创了一种利用二维图像化CNN建模的方式。在这类型的方法中,2D CNN网络同时对空间-时间信息进行了建模。不过和LSTM时序组织模型类似,其有一个很大的难点,就是我们需要对单帧数据进行遍历,才能排列成二维图像的一列(也可以是一行),这种遍历规则通常需要指定,这里就涉及到了人工设计排序的过程,不能很好地组织起身体部件之间的空间关联性。
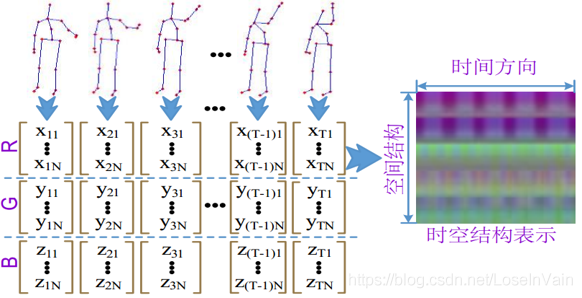
<div align='center'> <b> Fig 5.8 Skel-CNN对骨骼点序列进行二维图像化处理,将骨骼点序列转变为二维图像,从而后续可以采用2D CNN模型进行特征提取。 </b> </div>
除此之外,还有和此有关的研究方法。在[31]中,作者不是利用原始的空间坐标,而是找出人体某些相对稳定的关节点(称之为根关节点),用其他关节点对其做欧式距离后,同样按照时间轴方向拼接,形成多个以不同根关节点为基的二维特征图,尔后用多任务卷积网络进行特征提取和分类,如Fig 5.9所示。这种方法利用不同骨骼点与根关节点(比如图中的5,8,11,14关节点)进行欧式距离计算,得到了全身各个部件之间的彼此相对距离二维图,这种图显然是带有全身各个部件之间的关系信息的,在组织帧内的空间关系上做得更好,因此更加鲁棒。同时,作者还在模型中引入了多任务,使得模型的性能更加出众。
<div align='center'> <b> Fig 5.9 使用单帧内的骨骼点部件之间的相对距离作为信息源,形成了一系列的二维欧式距离图像后进行卷积。 </b> </div>
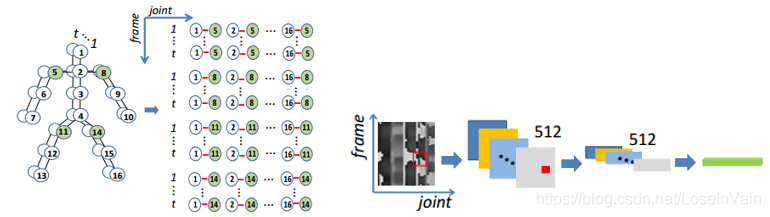
这些谈到的方法都是对帧内骨骼点信息进行组织,还有一种方法考虑组织帧间之间的motion流关系,这种组织方法对于拍摄角度和运动角度更为鲁棒。在工作[32]中,作者把骨骼点序列的关节点与关节点之间,在时序上的轨迹连接可视化为二维图像,如Fig 5.10所示,因为这种可视化结果经常不够清晰,可能伴有较为严重的缺损,因此作者同时对其进行了图像增强后,用2D卷积网络进行特征提取。
<div align='center'> <b> Fig 5.10 对骨骼点序列的帧间信息进行motion流组织,并且将其可视化成二维图像后,对该二维图像进行增强,尔后采用2D卷积网络进行特征提取。 </b> </div>
<div align='center'> <b> Fig 5.11 对motion流的轨迹进行可视化,并且对可视化后的二维图像进行了增强处理 </b> </div>
总的来说,这类型的方法中,采用CNN同时对时空信息进来组织,效果有时候会比用LSTM进行组织更稳定,但是同样面对着如何设计单帧遍历节点规则的问题。
图神经网络建模
如Fig 5.12所示,骨骼点序列天然地是个时空graph图数据,可以考虑用图神经网络(Graph Neural Network, GNN)进行处理。正如笔者在之前的博客上谈到的[25,26,27],已有多种关于图神经网络的研究,其中以图卷积网络(Graph Convolutional Network,GCN)为代表,具体的关于GCN和信息传导的推导见笔者之前博客,在此不再赘述。
在工作[33]中,作者提出了Spatial-Temporal GCN,STGCN,也就是时空图卷积网络。在这个工作中,作者对传统的卷积操作进行了延伸扩展,如式子(5.2)所示, $$ f_{out}(\mathbf{x}) = \sum_{h=1}^{K} \sum_{w=1}^{K} f_{in}(\mathbf{p}(\mathbf{x}, h,w) \cdot \mathbf{w}(h,w)) \tag{5.3} $$ 其中的$K$为卷积核的大小。作者重新定义了领域采样函数$\mathbf{p}(\mathbf{x}, h, w)$,即是对于一个当前的像素或者图节点,怎么去对周围的节点或者像素进行采样,对于二维图像来说,只需要简单的找邻居就行了,而graph数据则不能这样进行了。 作者根据重新定义的领域采样函数,定义了对应的权值函数$\mathbf{w}(h,w)$。当然,这里只是对于空间的图卷积,作者在时间域也定义了相似的领域采样和权值,因此可以延伸到时空图卷积,STGCN。最终对每个STGCN单元进行堆叠,如Fig 5.13所示,并且受到ResNet的启发,引入short-cut和block设计,达到了SOTA的效果。
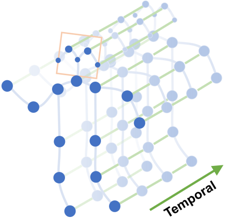
<div align='center'> <b> Fig 5.12 骨骼点序列天然地是个时空graph图数据。 </b> </div>

<div align='center'> <b> Fig 5.13 ST-GCN的处理pipeline,其中ST-GCN就是主要的特征提取网络,输入的骨骼点序列可以是3D骨骼点序列,也可以是经过姿态估计得到的2D骨骼点序列。 </b> </div>
Fig 5.14列出了以上讨论的诸多模型在NTU RGBD 60数据集上的表现,我们发现STGCN的性能的确达到了SOTA。
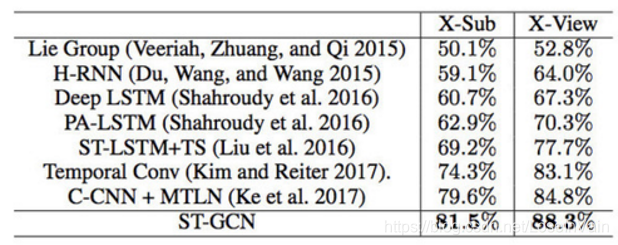
<div align='center'> <b> Fig 5.14 诸多基于骨骼点序列进行动作识别的模型在NTU RGBD 60数据集上的表现。 </b> </div>
ST-GCN是一个非常经典的网络,笔者非常喜欢这个网络,这个网络设计非常的直观,性能高效,占用内存少。直接采用图卷积的方式对空间和时间的语义信息进行组织,避免了人工去设计遍历规则,在数据量大的情况下性能通常都会更好。现在相当多关于骨骼点动作识别的工作都是基于STGCN上进行的[34,35,36,37]。
多视角动作理解
所谓多视角动作理解,就是动作可能在多种不同的摄像头姿态下发生,我们设计的模型必须能在多种不同不同的摄像头姿态下对动作进行识别。这种需求面对着诸多真实场景,比如监控场景,摄像头姿态通常都千差万别,比如真实场景的动作识别(包括在移动机器人上部署的摄像头),摄像头姿态通常都是不定的,甚至是运动的,如果算法对多视角或者移动视角的摄像头拍摄的视频不够鲁棒,显然是不能够满足我们的日常生产需求的。
多视角动作识别的一个很关键的问题在于多视角数据集很缺少,带有标注的,比如标注了相机姿态的数据集更是稀少。如此少多视角标注视频数据很难让模型具有跨视角的能力,这里指的跨视角指的是在某个或者某些视角的样本上进行模型训练,在未见过的视角样本上进行模型测试。
多视角动作识别还有一个关键问题在于提取多视角之间的共有特征,这种在多视角样本上共享的特征通常是和动作类别紧密相关的特征,具有较好的视角不变性(view-invariant)。
因此,在多视角动作理解问题上,根据笔者的研究经验,大致可以归为三种方法:
- 采用一些手段扩充多视角样本数据。
- 提取多视角样本的公共特征。
- 提取视角不变特征——手工设计或者模型深度学习。
根据这个总结,接下来我们讨论在RGB视频上进行多视角动作理解的一些方法。
在RGB视频上进行多视角动作识别
文章[38]是考虑在深度图序列上进行多视角样本扩充,因为深度图和RGB视频较为相像,我们归到这里讨论。[38]的作者提出了一种很自然的生成多视角样本的方法是:对人体模型进行三维建模,然后设置多个虚拟相机机位,纪录下这些样本,随后再进行后处理,如Fig 6.1所示可以设置任意多个虚拟机位,一般选择180个覆盖全身即可。
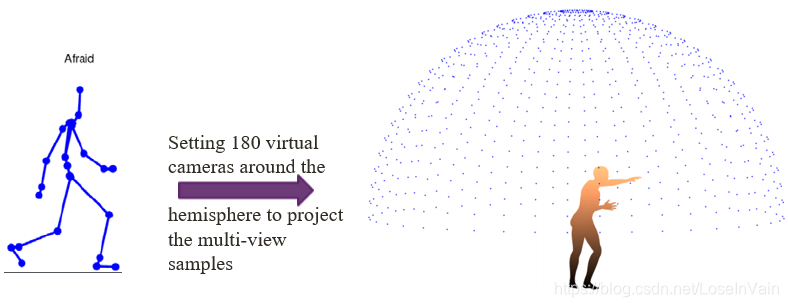
<div align='center'> <b> Fig 6.1 虚拟机位生成虚拟多视角样本。 </b> </div>
有很多3D建模软件可以对人体模型进行很好地建模,问题在于让这个模型按照需要的动作“活动”起来,以达到模拟真实人体活动的需求。我们可以通过MoCap[46]得到的骨骼点结果(是比较准确的,通过多轴传感器结果得到的骨骼点序列,对遮挡鲁棒),让模型动起来,如Fig 6.2所示。同时,我们在其表面“附上”一层膜,因此人体模型不同深度的点就有了深度信息,最后进行深度图生成即可。

<div align='center'> <b> Fig 6.2 通过MoCap的骨骼点信息,进行3D人体模型的虚拟运动后进行多机位虚拟多视角样本提取。 </b> </div>
在工作[39]中,作者同样类似的思路,采用了MoCap的骨骼点序列对3D建模好的人体模型进行动作生成,不同的是,这次作者是把不同视角的序列信息提取时序间的轨迹,具体来说,就是对于一个多视角样本,对其相同部件(比如手部,胳膊)进行时序上的跟踪,得到秘籍的轨迹图。如Fig6.3所示,最后用字典学习去学习不同视角样本的码表(用K-means进行学习)。

<div align='center'> <b> Fig 6.3 利用生成的多视角密集轨迹,进行字典学习,学习出多视角下的码表。 </b> </div>
在测试阶段,我们需要利用这里学习到的码表,对输入的密集轨迹进行构建动作轨迹描述子,随后进行识别,如Fig 6.4所示。
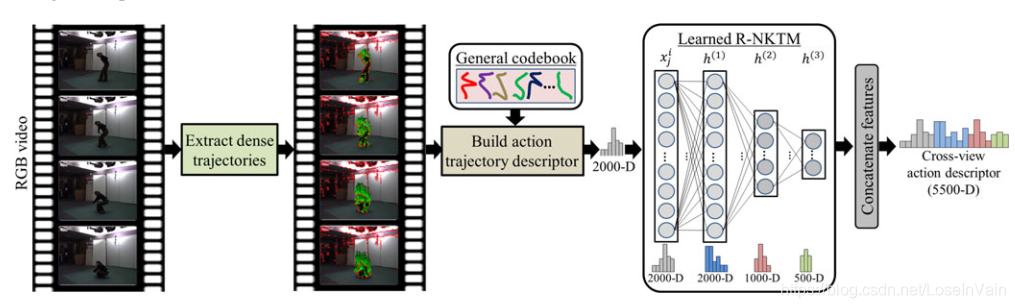
<div align='center'> <b> Fig 6.4 利用学习到的码表,在预测阶段进行动作类别预测。 </b> </div>
当然,刚才的解释并不完全,[39]的作者认为,不同视角之间存在一种所谓的典范视角(canonical view)的关系,也就是说,所有视角样本,通过某种方式,都应该能转化成典范样本,更进一步,不同视角样本之间都应该能通过典范样本作为中继,进行相互转换。之前的工作[47,48]大多假设这种关系是线性的,如Fig 6.5 (a)(b)所示,但是这个并不能准确描述视角样本之间的迁移关系,因此在本工作中,作者认为这种关系应该是非线性的,如Fig 6.5 (c)所示,不同样本之间共享着高层的语义空间。然而通过我们之前讨论的码表的方式可不能描述这种非线性,因为码表的码元的组织是线性的操作,因此我们需要引入一个网络进行这种非线性关系的学习,比如[39]中提出的Robust Non-linear Knowledge Transfer Model , R-NKTM模型,正如Fig 6.3和Fig 6.4所示。
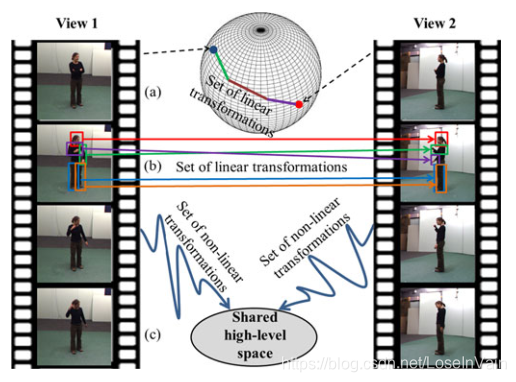
<div align='center'> <b> Fig 6.5 作者假设不同视角样本之间的迁移并不是线性的,如果假设存在一种所谓的典范样本,那么通过高维的非线性映射才是合理的方式。 </b> </div>
有些方法尝试去提取视角不变(view-invariant)的特征,自相似性矩阵(Self-Similar Matrix,SSM)[40]是一种经典的理论上的角度不变性的特征,其做法很简单,就是在时间上求帧$i$与帧$j$的欧式距离$d_{i,j}$并把它组成矩阵,如Fig 6.6所示。这类型的方法还有一些后续工作,比如[41-42],如Fig 6.7所示。同时,我们可以发现,在一些工作对人体的各个身体部件之间进行相对距离的计算,然后拼接成特征矩阵的方法,比如[31]中,都体现了视角不变性的思想。

<div align='center'> <b> Fig 6.6 SSM模型尝试构造视角不变性特征。 </b> </div>
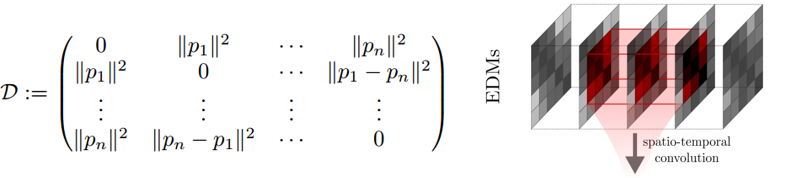
<div align='center'> <b> Fig 6.7 其他尝试构造视角不变性特征的方法,受到了SSM的启发。 </b> </div>
的确,从理论上说,进行时间帧的相对距离计算(或者身体部件之间的相对距离),这个相对距离计算应该是和视角无关的,因为你不管视角怎么改变,这个相对距离也不会变化,因此是视角不变的。但是我们注意到,正如文章[2]中所说到的,骨骼点信息多多少少会因为遮挡导致变形扭曲,如Fig 6.8所示,在大面积的遮挡情况下这种现象更为明显。在存在有这种噪声的骨骼点序列中,使用我们刚才提到的根据相对距离计算得到的视角不变性特征,却容易引入更多的噪声,所谓的理论上的视角不变性便在这里被打破了。

<div align='center'> <b> Fig 6.8 用Kinect对遮挡动作进行姿态估计,左手部分被遮挡,但是Kinect还是对时序上的上下文进行了估计,但是这种估计常常效果不佳,容易引入估计噪声。 </b> </div>
在[45]中,作者指出我们可以把多视角样本特征分解为多视角之间共享的共享特征(share features)和各个视角独有的私有特征(private features),通过这两种类型的特征的线性组合,对样本特征进行重建,公式如(6.1)。其他具体内容因为过于多数学的描述,限于篇幅,建议读者有需要的直接翻阅[45]原文。 $$ f = \sum_{i=1}^{N_v} \alpha_i f_i + f_{private} \tag{6.1} $$
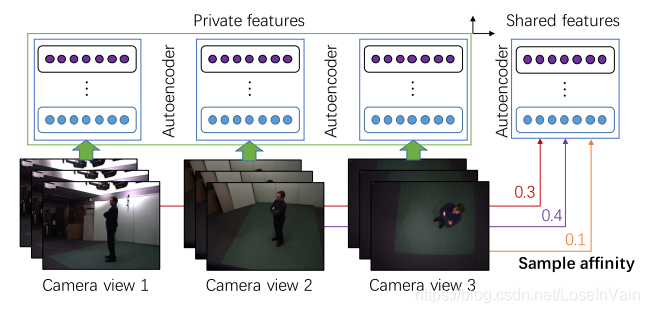
<div align='center'> <b> Fig 6.9 提取共享特征和私有特征,经过线性组合得到样本特征。 </b> </div>
在骨骼点序列上进行多视角动作识别
之前说到的都是在RGB上或者Depth数据上进行处理的方法,而在骨骼点序列上,也有很多关于多视角相关的算法。根据笔者的经验来说,骨骼点数据天然具有较好的角度不变性,如果模型设计得当,在没有显式地设计视角不变性特征的前提下,其跨视角识别能力通常都不会很差(甚至会比较理想)。但是骨骼点序列的问题在于噪声,骨骼点序列因为遮挡,会引入很多噪声,这点笔者一直在强调。笔者的一篇工作[37]也正是在尝试接近这个噪声带来的问题。
不管怎么样说,还有不少方法在尝试对不同视角的骨骼点序列进行对齐(alignment)的,这里的对齐指的是使得不同视角的同一种动作类别的样本看起来视角差异性尽量小一些。最简单的方法如P-LSTM[28]所示,直接将身体的节点的连线(比如髋部连线)进行二维平面的旋转对齐。这种方法蛮粗暴的,还有些方法在三维空间进行旋转,如[32]和Fig 6.10所示。

<div align='center'> <b> Fig 6.10 尝试在三维空间对骨骼点序列进行旋转对齐。 </b> </div>
不过笔者在这里想要介绍的是所谓的View Adaptation网络,这种网络受到了Spatial Transformer Network, STN的启发,引入了一种自动学习对齐骨骼点序列的子网络。如Fig 6.10所示,这个View Adaptation Subnetwork可以自动学习不同视角之间样本间的旋转矩阵$\mathbf{R}t$和偏移向量$\mathbf{d}t$,使得同一种动作类别,不同视角的样本看起来更加地接近,注意到三维空间的旋转可以分解成$x,y,z$轴的旋转的组合,那我们有: $$ \mathbf{R}t = \mathbf{R}{X}(\alpha) \mathbf{R}{Y}(\beta) \mathbf{R}{Z}(\gamma) \tag{6.2} $$ 其中的$\alpha,\beta,\gamma$是分别围绕坐标轴$X,Y,Z$的旋转角度。
那么具体到其中的各个旋转轴矩阵,我们有: $$ \mathbf{R}_{X}(\alpha) = \left[\begin{matrix}1 & 0 & 0 \0 & \cos(\alpha) & -\sin(\alpha) \0 & \sin(\alpha) & \cos(\alpha)\end{matrix}\right]\tag{6.3} $$
$$ \mathbf{R}_{Y}(\beta) = \left[\begin{matrix}\cos(\beta) & 0 & \sin(\beta) \0 & 1 & 0 \-\sin(\beta) & 0 & \cos(\beta)\end{matrix}\right]\tag{6.4} $$
$$ \mathbf{R}_{Z}(\gamma) = \left[\begin{matrix}\cos(\gamma) & -\sin(\gamma) & 0 \\sin(\gamma) & \cos(\gamma) & 0 \0 & 0 & 1\end{matrix}\right]\tag{6.5} $$
那么我们经过对齐后的,新的骨骼点坐标是: $$ \mathbf{v}^{\prime}{t,j} = [x{t,j}^{\prime}, y_{t,j}^{\prime}, z_{t,j}^{\prime}]^{\mathrm{T}} = \mathbf{R}{t} (\mathbf{v}{t}-\mathbf{d})\tag{6.6} $$ 其中的参数$\mathbf{d}_t = [d_1,d_2,d_3]^{\mathrm{T}}$和$\alpha,\beta,\gamma$等完全由网络学习得到,其旋转和平移如Fig 6.11所示。
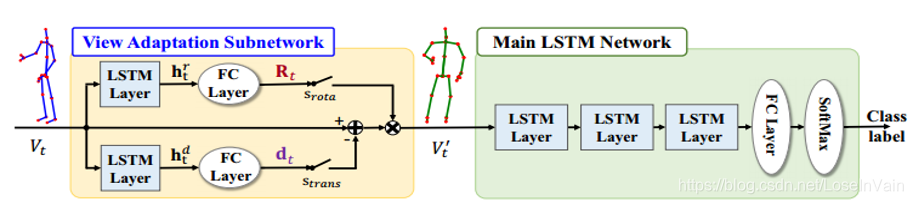
<div align='center'> <b> Fig 6.10 尝试在三维空间对骨骼点序列进行旋转对齐。 </b> </div>
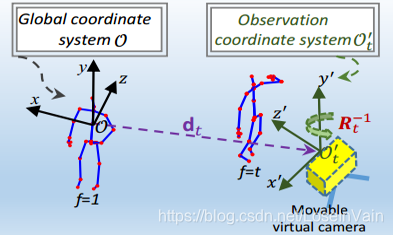
<div align='center'> <b> Fig 6.11 骨骼点在三维空间的旋转和平移。 </b> </div>
View Adaptation网络是可以随处安插的,有点像BN层和Dropout层,你可以在模型中随意安插这个子网络。最终结果证明了这个对齐网络的有效性,如Fig 6.12所示。
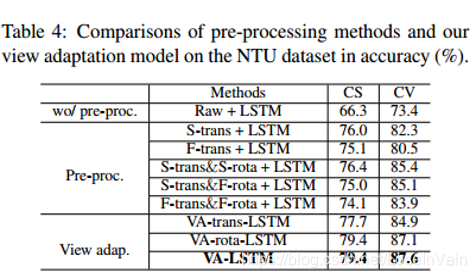
<div align='center'> <b> Fig 6.12 在NTU RGBD 60数据集上的结果证明了View Adaptation网络的有效性。 </b> </div>
在视频动作理解中应用自监督学习
众所周知,深度学习是数据驱动的(data-driven),非常需要有标注的良好数据去喂养模型。然而现实中我们并没有那么多有标注的数据,标注数据是非常耗时耗力耗财的。而我们在一开始就已经说过,每天互联网上产生着那么多的无标签的视频数据,不加以运用过于可惜,我们需要考虑如何让模型在无标签的视频上“汲取”知识和养分,在不进行人工标注的情况下,提高模型的性能。
自监督学习背景
自监督学习(self-supervised Learning)是无监督学习中的一个有趣的分支,在介绍自监督学习之前,笔者打算举个例子。假如我们现在有一个8位灰度图像,其尺寸为10*10,也就是灰度级为256。那么显然的,如果对所有可能的像素值的情况进行遍历,我们的图片像素空间非常大,为$256^{100}$。这还只是在如此小的尺寸下的一个灰度图的像素空间。
然而,大多数情况下,很多像素组合是没有任何语义的,也就是说,你在现实中根本见不到这种像素组合,我们把所有可能在现实中见到的像素组合在高维空间中表示为一个点,那么所有的点的组合构成了流形(manifold)。也就是说,我们的一切可能的样本采样都来自于这个流形。
对这个流形的形状进行建模很重要,但是显然不可能完全精确地描述这个流形,因为你需要几乎无数的样本才足以描述。在强监督学习中,我们现在有的只是这个流形上的一些有过标注的样本(流形上的某些点可能代表一个类别,某些点可能是另一个类别),然而我们可以用无标签的样本去填补这个流形的缺口,尝试去尽可能地描述这个流形,这是无监督学习整体来说在做的事情。
但是我们这个假设有个前提,每个像素之间的独立无关的,然而现实是像素与像素之间很可能存在有语义关系,我们通常可以用一个像素去估计其周围的像素,一般变化都不会特别大,就说明了这一点。因此我们可以进一步缩小无监督中需要的样本数,我们因此有了自监督学习。
在自监督学习中,我们让无标签的样本自己产生自己的标签,因此我们就可以在无标签样本上进行强监督训练了。我们需要定义出一个pretext任务,我们在无标签的数据集上训练这个pretext任务,通常我们并不很在意这个pretext模型的性能表现。在得到了模型参数之后,我们以这个模型的参数作为初始化,再在有标签的数据集上进行训练得到最后的模型。就本质上而言,自监督学习对模型进行了正则,减少了对标签样本的需求。
让无标签的样本自己产生自己的标签显得很神奇,但其实并不难,比如一张图片,我们可以把其中某一块扣掉,然后让模型根据没有扣掉的部分去填充扣掉部分的图形,这种叫inpainting,如Fig 7.1所示。
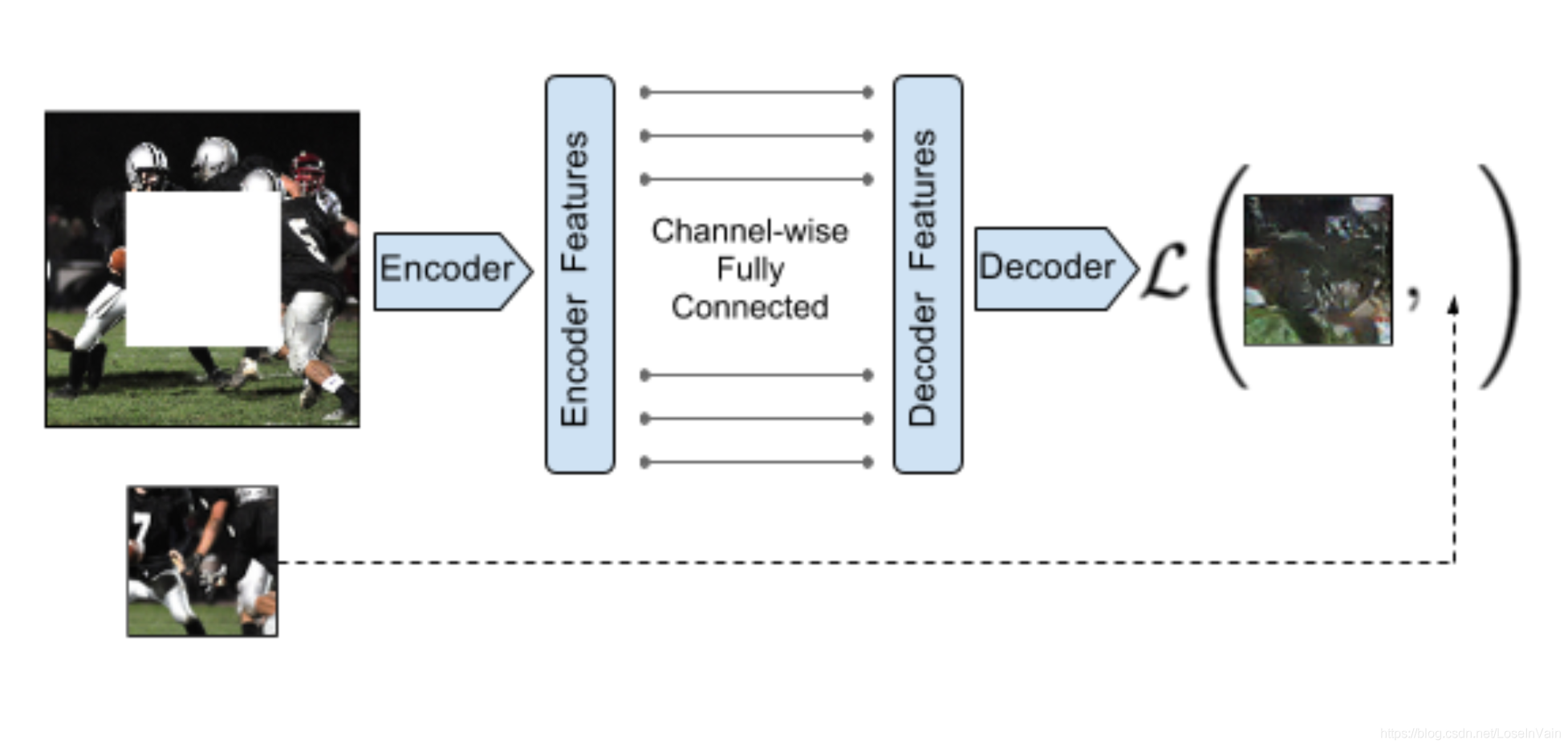
<div align='center'> <b> Fig 7.1 利用inpainting进行图片的自监督学习。 </b> </div>
对于文本序列样本来说,更为直接的self-supervision方法就是Word2Vec语义嵌入了,我们可以用之前的词语去预测后续的词语,也可以用后续的词语回测之前的词语,也可以给词语挖个空,根据周围的词语去预测中心词语等等,如Fig 7.2所示。
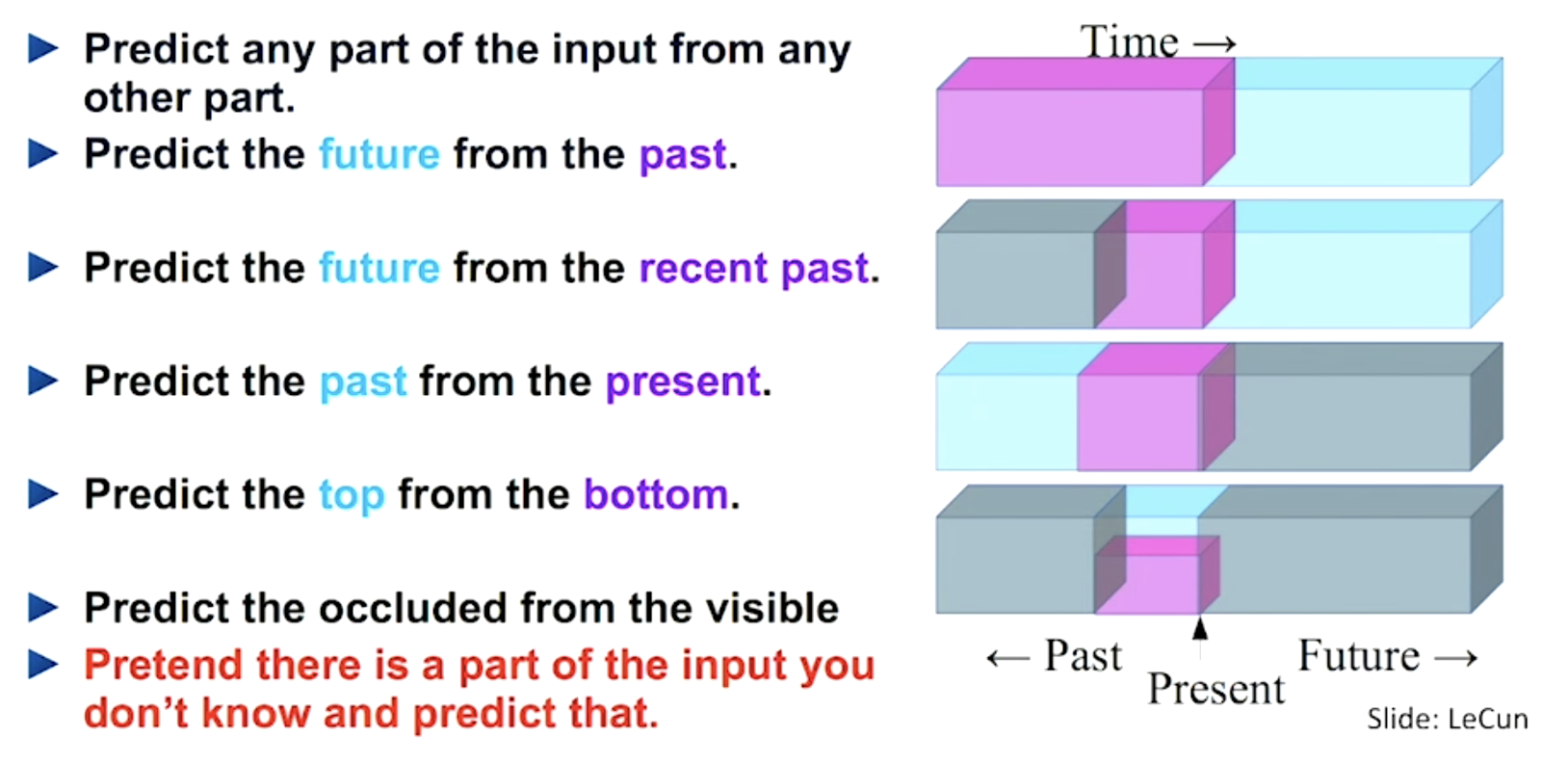
<div align='center'> <b> Fig 7.2 对于序列的自监督学习可以参考的方法,文本序列类似。 </b> </div>
当然基于图像的pretext任务还有很多,比如对输入图像进行指定角度的旋转[54],训练模型去判断这个图像旋转角度是多少,因为旋转角度是自己指定的有限集中的一个,因此是有标签的,如Fig 7.3所示。也有一种是非常出名的方法,通过拼拼图(jigsaw puzzle)[55]的方式进行pretext任务的定义。如Fig 7.4所示,我们在图像上指定了九个拼图块,每一个块都有其固定的编号从1-9。我们随意进行打乱后,期望网络可以对其重新排序,恢复正常的顺序。
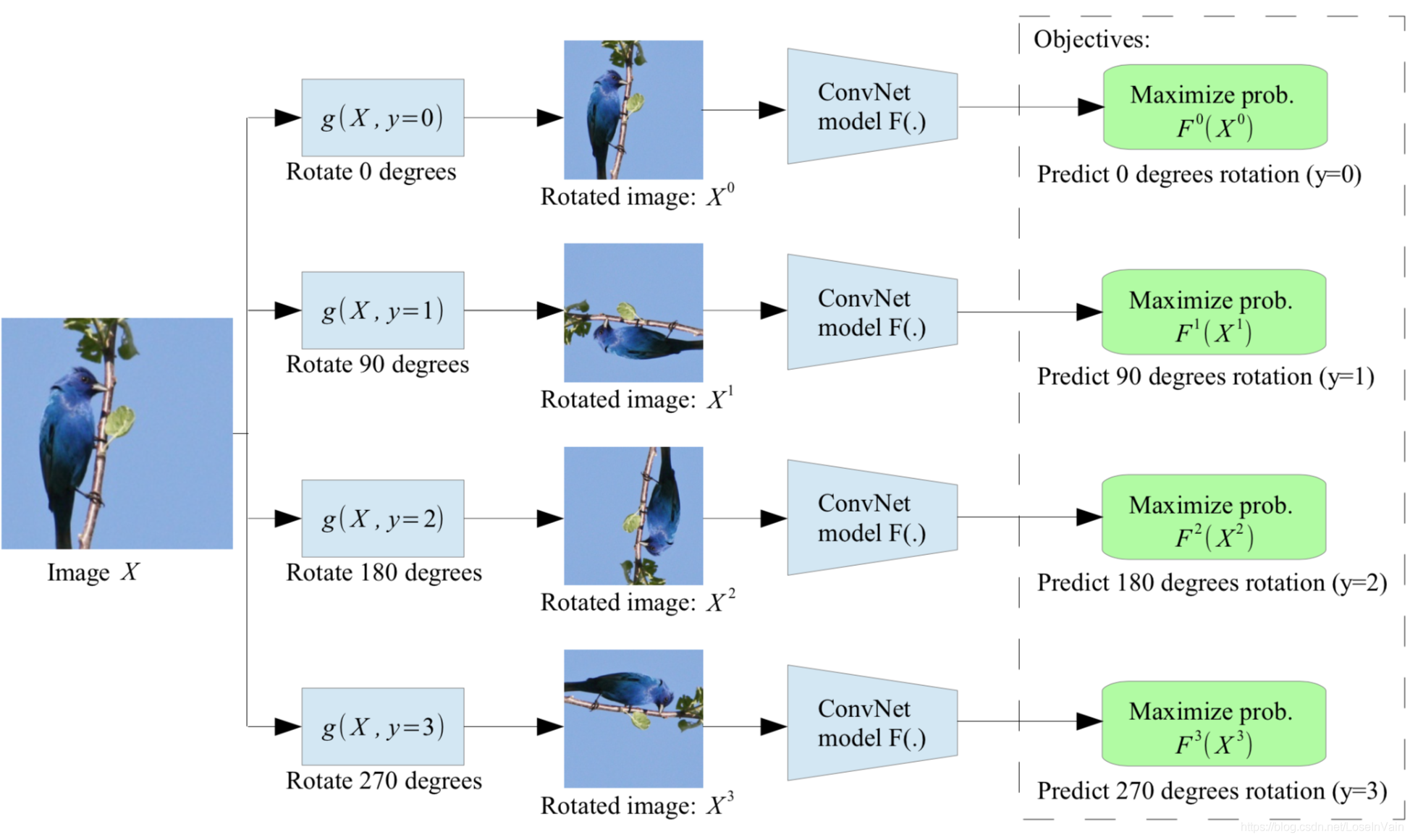
<div align='center'> <b> Fig 7.3 在这种自监督策略中,模型需要判断图像的旋转角度是多少。 </b> </div>
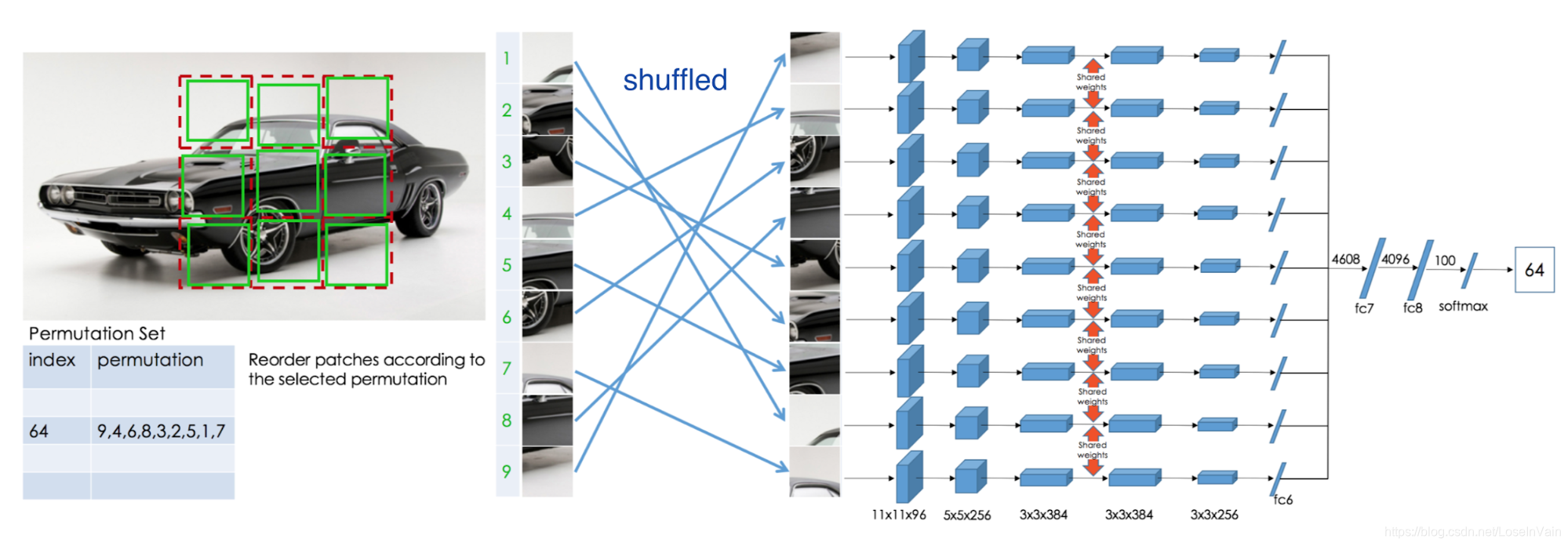
<div align='center'> <b> Fig 7.4 对图片块进行拼拼图(jigsaw puzzle)的方式进行自监督学习。 </b> </div>
这些pretext任务,都是让无标签的数据自己产生了标签,让模型学习到了样本本身的语义特征,虽然这个pretext任务和我们的目标任务(比如动作识别,物体检测,定位)等大相径庭,但是它们的数据流形是一样的,共享着语义特征空间,因此通过自监督学习的方式,可以利用海量的无标签的数据学习出更为理想的表征(representation)。
在文章[51]中,研究者针对多种不同的视觉任务,对自监督的效果进行了广泛的基线测试。研究者主要关注两个问题:自监督任务的辅助数据集的大小尺度和pretext任务的任务难度对于整个预训练过程的影响。作者发现自监督的无标签数据集数据量越大,模型的效果越好,如Fig 7.5所示。同时作者发现,对于设定pretext任务的复杂度,对于整体模型的性能也是有很大影响的,如Fig 7.6所示。
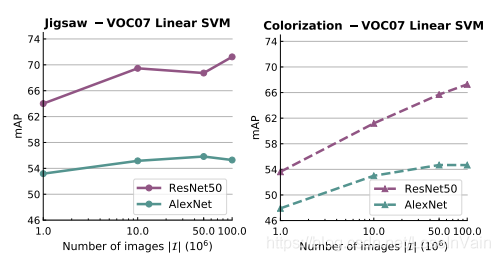
<div align='center'> <b> Fig 7.5 自监督的数据集越大,效果越好。 </b> </div>

<div align='center'> <b> Fig 7.6 控制自监督pretext任务的问题复杂度对于性能有很大影响。 </b> </div>
该文章还进行了很多其他实验,在多种视觉任务中提供了自监督学习的坚实的(solid)基线标准,值得各位读者仔细研读。
基于视频的自监督学习
我们之前谈到的是在图像数据上进行的自监督任务的例子。自监督学习的要点经常就体现在怎么根据具体的下游任务和数据模态去设计合适的自监督pretext任务,在视频数据上,其pretext任务和图像数据有所不同。视频包含着一系列在时间轴上具有语义关系的图像帧,时间上邻近的帧比其他更远的帧可能具有着更强的语义关联关系。这种特定的视频序列排序描述了物理世界逻辑的因果逻辑和推断:比如物体的运动应该是平滑的,重力方向总是朝下的(体现在物体下落)。对于视频数据来说,一种通用的模式是:在海量的无标签数据上进行一种或者多种pretext任务的训练,然后提取出其特征提取层,用有标签的数据进行fine-tune下游任务,例如动作分类,分割,定位或者物体跟踪等。
对于设计基于视频的自监督pretext任务,有着以下几种逻辑。
基于帧序列顺序
视频帧自然地是按照时间顺序排列的。我们的模型理应能学习到视频帧的正确顺序,因而研究者们提出了若干基于帧序列顺序的方法。其中一类方法被称之为验证帧顺序(validate frame order)[53],这里的pretext任务在于判断给定的一小段视频帧是否是按照正确的时间顺序排列的(所谓的有效时间顺序,valid temporal order)。模型需要具备能够从视频帧中的细微运动线索中跟踪和推理的能力,从而才能完成这个任务。
首先,训练帧序列从所谓的高运动窗区域(high-motion windows)提取,每次采样5帧,记为$(f_a, f_b, f_c, f_d, f_e)$,并且其时间戳顺序为$a < b < c < d < e$。在这5帧中,我们从中构建一个正样本三元组(也就是时间顺序是正常的),记为$(f_b, f_c, f_d)$,构建两个负样本三元组(时间顺序乱序),记为$(f_b, f_a,f_d)$和$(f_b, f_e,f_d)$。超参数$\tau_{\max} = |b-d|$决定了正样本训练实例的难度(也就是越大,难度越强),超参数$\tau_{\min} = \min(|a-b|, |d-e|)$控制了负样本的难度(也就是越小,难度越强)。研究者已经证实了在动作识别类型的下游任务中,基于验证帧序列顺序的方法可以提高性能。整体框图如Fig 7.7所示。
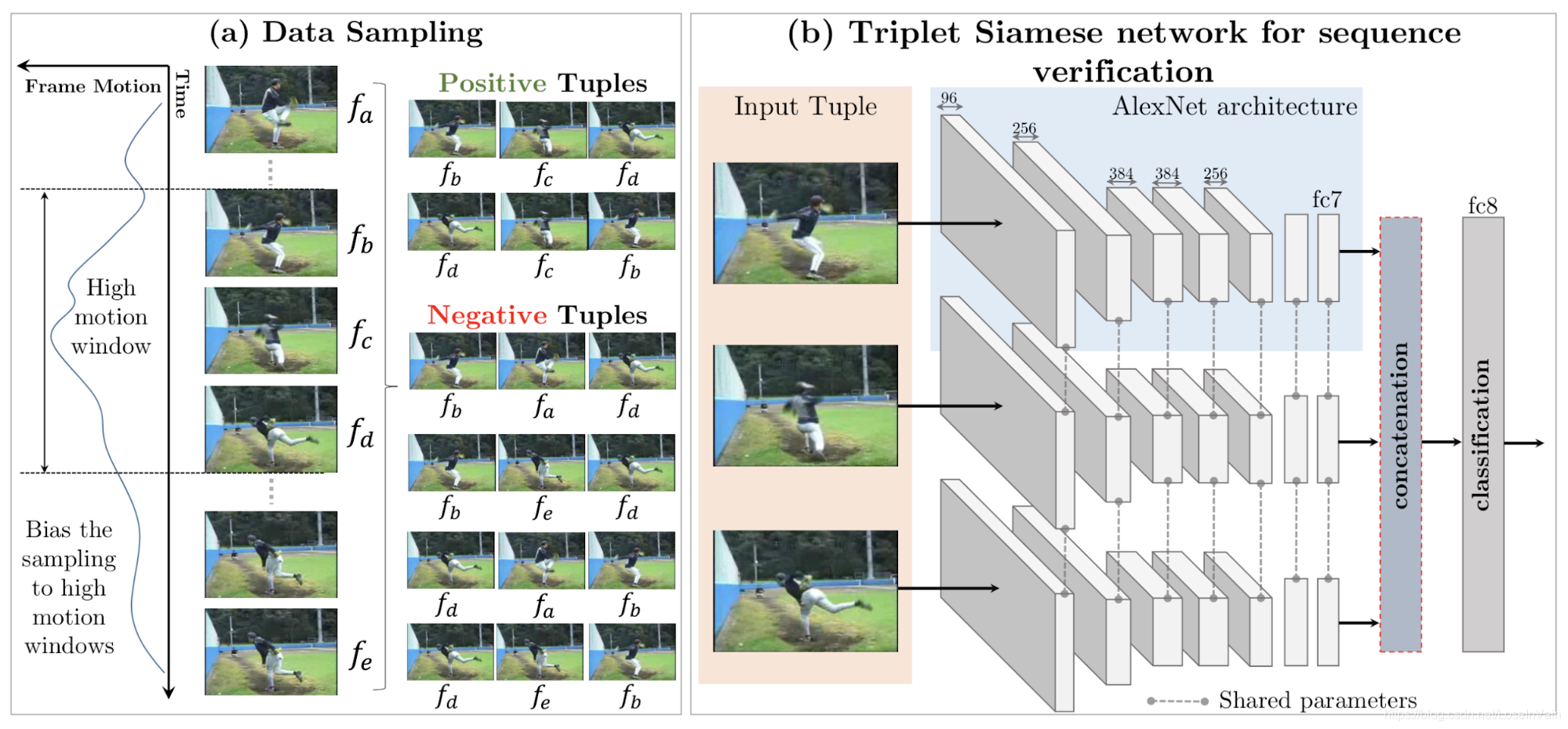
<div align='center'> <b> Fig 7.7 验证帧顺序自监督方法的框图。 </b> </div>
在O3N(Odd-One-Out Network)[56]中,作者同样定义了一种新的基于验证帧序列顺序的pretext任务。这个任务尝试从一堆小视频片段中挑选出乱序的一个视频片段,而其他是正常顺序的。假设给定$N+1$个输入视频片段,其中的一个被人为地乱序了,其他的$N$个片段是正常顺序的,我们的模型需要从中确定乱序的片段的位置。
基于跟踪
视频序列中物体的移动可以被视频的时序关系所追踪。在时间轴上相邻的帧中出现的物体,通常差别不会特别大,通常只会有因为细小运动或者摄像头抖动造成的干扰。因此,任何关于相同物体在相邻的视频帧上学习到的表征,在特征空间上应该是相似的。基于这个启发,[57]提出了通过跟踪视频中运动物体,达到自监督目的的方法。
在具有运动信息的小时间视频窗口(比如30帧),我们从中按照时间顺序截取patch块,其中第一个块$\mathbf{x}$和最后一个块$\mathbf{x}^+$被选择作为训练样本点。我们可以预想到,因为是在小时间窗发生的动作,因此这两个时间窗的特征应该是接近的。但是如果我们简单最小化这两个patch之间的特征向量,模型最终会陷入平凡解——也就是所有的特征向量都会趋同,没有任何区别,这样并没有带来任何信息量。为了接近这个问题,我们引入第三个patch,我们同样通过乱序的方式构造了负样本$\mathbf{x}^-$。因此,我们最终期望有: $$ D(\mathbf{x}, \mathbf{x}^+) > D(\mathbf{x}, \mathbf{x}^-)\tag{7.1} $$ 其中的$D(\cdot)$是余弦距离,为 $$ D(\mathbf{x}_1, \mathbf{x}_2) = 1 - \dfrac{f(\mathbf{x}_1)f(\mathbf{x}_2) }{||f(\mathbf{x}_1)|| \cdot ||f(\mathbf{x}_2)||}\tag{7.2} $$ 损失函数为: $$ \mathcal{L}(\mathbf{x}, \mathbf{x}^+, \mathbf{x}^-) = \max(0, D(\mathbf{x}, \mathbf{x}^+)-D(\mathbf{x}, \mathbf{x}^-)+M) + R\tag{7.3} $$ 其实就是triplet loss,其中的$R$是正则项,具体见笔者之前博文[58]。整个网络框图见Fig 7.8。
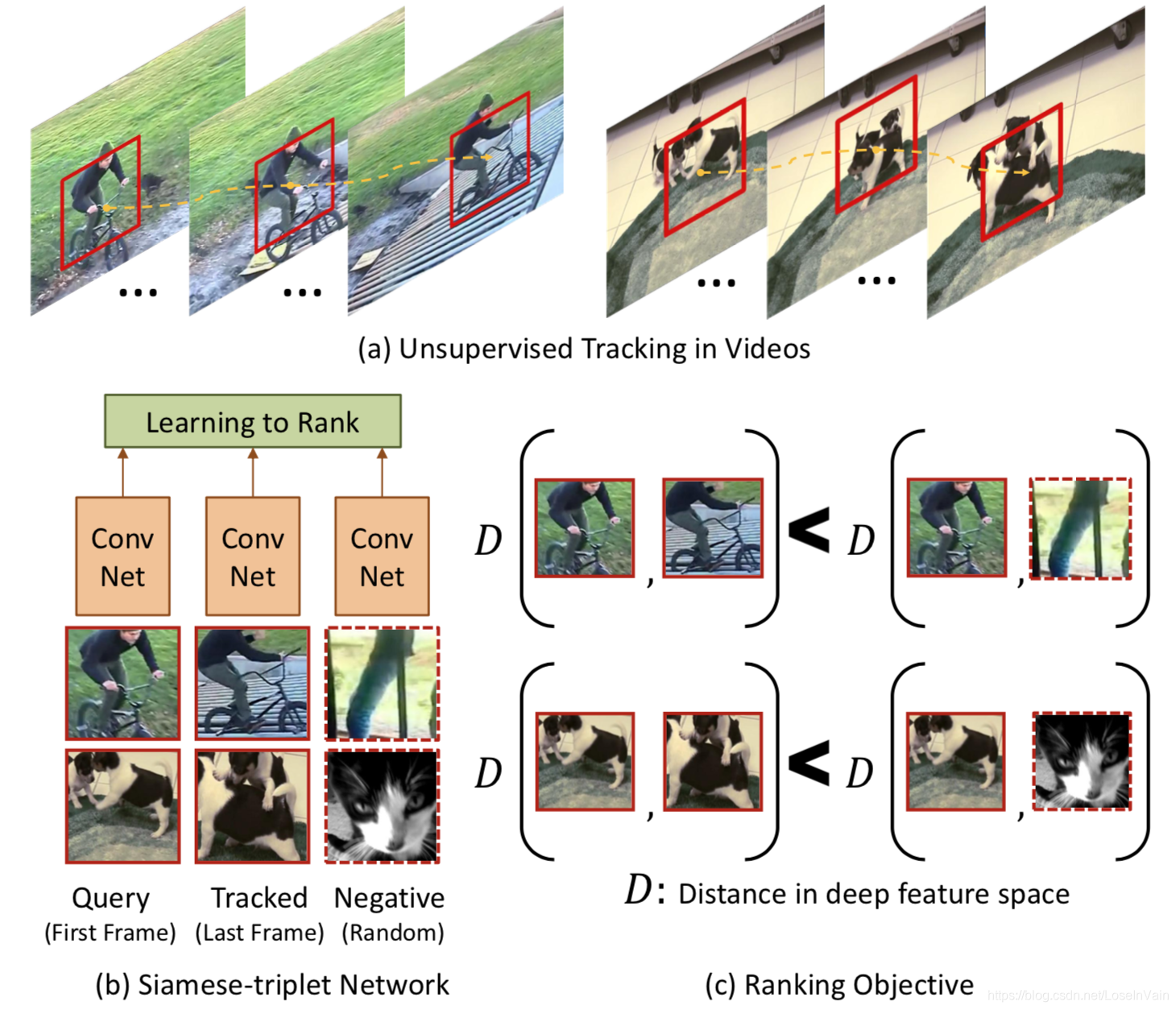
<div align='center'> <b> Fig 7.8 对短时间窗口的物体进行跟踪自监督方法。 </b> </div>
基于视频着色
在[59]中,研究者提出将视频着色(video-colorization)作为自监督方法手段,这样产生的丰富表征可以在不经过额外fine-tune的情况下,在视频分割中使用。和在图像中进行着色不同,在这里的着色是,将彩色的目标视频的像素拷贝到对应的灰度化的视频上(灰度化可以由RGB视频转化而来),而并不是直接生成的。为了能够做到这种拷贝,模型理应能够对不同帧的相关联的像素进行跟踪。
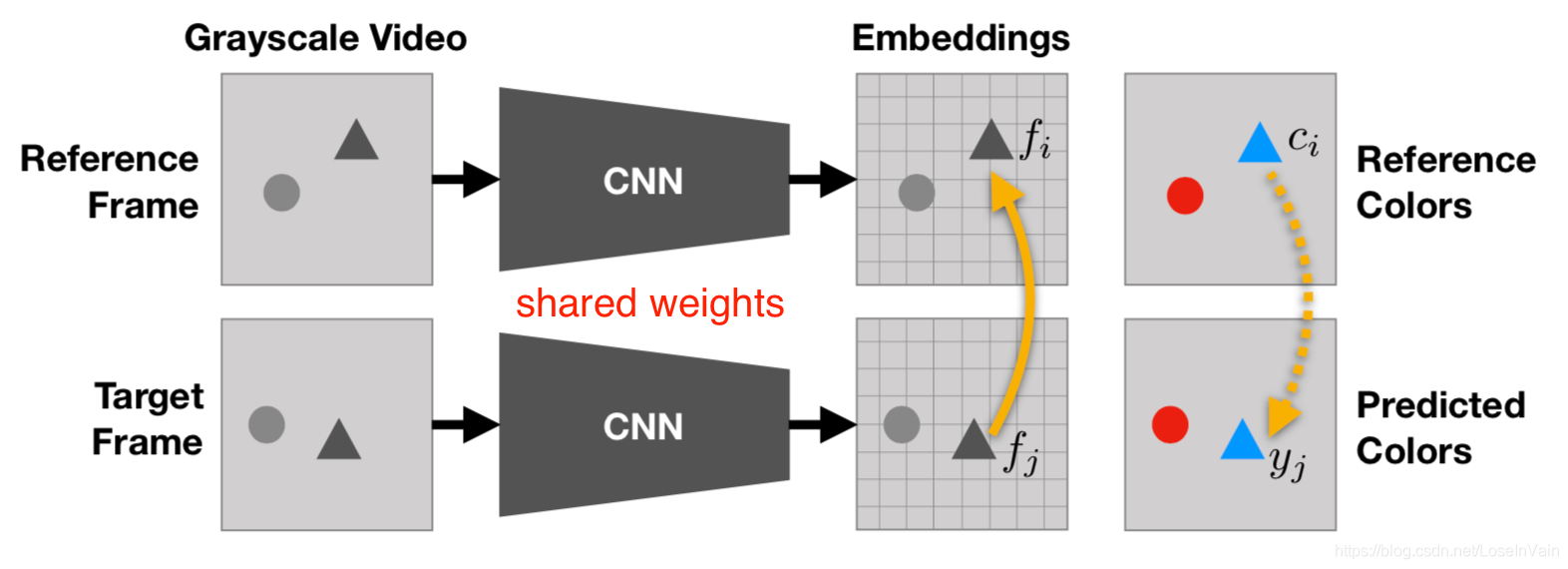
<div align='center'> <b> Fig 7.9 基于视频着色的自监督方法。 </b> </div>
这个想法简单而有效,我们用$c_i$表示在参考的彩色视频的第$i$个像素,用$c_j$表示灰度化的目标视频的第$j$个像素。那么对目标视频的第$j$个像素的预测$\hat{c}j$是一个对参考视频的所有像素的加权和: $$ \hat{x}j = \sum{i} A{ij}C_i \A_{ij} = \dfrac{\exp(f_i f_j)}{\sum_{i^{\prime}}\exp(f_{i^{\prime}}f_j)}\tag{7.4} $$ 其中的$f$是学习到的对应像素的嵌入特征。$i^{\prime}$表示了在参考视频中的像素。这种加权实现了注意力机制,类似于matching network[60]和pointer network[61]。
总结
基于视频的自监督方法还有很多,有涉及到视频拼图恢复的,光流任务嵌入的等等,不管怎么,这些pretext任务都是尝试在无标签数据中学习到视频的motion和appearance信息,作为良好的正则引入模型,减少模型对有标签样本的需求,提高了性能。
视频动作分析为什么可以视为视频理解的核心
我们在上文中提到了非常多的视频动作识别的方法,涉及到了各种视频模态,为什么我们着重于讨论视频动作理解呢?明明视频理解任务有着那么多类型。无论具体的视频理解任务是什么,笔者认为视频理解的核心还是在于如何组织视频的motion流和appearance流语义信息,而动作识别任务是很好地评价一个模型是否对motion和appearance信息进行了有效组织的标准(而且对视频进行动作标签标注也比较简单),如果一个模型能够对视频动作识别任务表现良好,那么其特征提取网络可以作为不错的视频表征提取工具,给其他下游的任务提供良好的基础。
说在最后
这一路过来道阻且长,我们说了很多算法,对整个视频动作理解的发展做了一个简单的梳理,但是限于篇幅,意犹未尽,还有很多最新的论文内容在这里没有得到总结,我们在以后的拾遗篇将继续我们的视频分析的旅途。路漫漫其修远兮,吾将上下而求索。
Reference
[1]. http://www.cac.gov.cn/wxb_pdf/0228043.pdf
[2]. http://blog.csdn.net/LoseInVain/article/details/87901764
[3]. http://research.google.com/youtube8m/
[4]. Wang H, Kläser A, Schmid C, et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International journal of computer vision, 2013, 103(1): 60-79.
[5]. http://hal.inria.fr/hal-00830491v2/document
[6]. Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2014: 1725-1732.
[7]. Tran D, Wang H, Torresani L, et al. A closer look at spatiotemporal convolutions for action recognition[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018: 6450-6459.
[8]. Yue-Hei Ng J, Hausknecht M, Vijayanarasimhan S, et al. Beyond short snippets: Deep networks for video classification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 4694-4702.
[9]. Donahue J, Anne Hendricks L, Guadarrama S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 2625-2634.
[10]. Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Advances in neural information processing systems. 2014: 568-576.
[11]. Ji S, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2012, 35(1): 221-231.
[12]. Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 4489-4497.
[13]. Carreira J, Zisserman A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6299-6308. (I3D)
[14]. Sun L, Jia K, Yeung D Y, et al. Human action recognition using factorized spatio-temporal convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 4597-4605.
[15]. Qiu Z, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3d residual networks[C]//proceedings of the IEEE International Conference on Computer Vision. 2017: 5533-5541.
[16]. Feichtenhofer C, Pinz A, Zisserman A. Convolutional two-stream network fusion for video action recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 1933-1941. (TwoStreamFused)
[17]. Zhu Y, Lan Z, Newsam S, et al. Hidden two-stream convolutional networks for action recognition[C]//Asian Conference on Computer Vision. Springer, Cham, 2018: 363-378. (HiddenTwoStream)
[18]. Wang L, Xiong Y, Wang Z, et al. Temporal segment networks: Towards good practices for deep action recognition[C]//European conference on computer vision. Springer, Cham, 2016: 20-36. (TSN)
[19]. Girdhar R, Ramanan D, Gupta A, et al. Actionvlad: Learning spatio-temporal aggregation for action classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 971-980. (ActionVLAD)
[20]. Diba A, Fayyaz M, Sharma V, et al. Temporal 3d convnets: New architecture and transfer learning for video classification[J]. arXiv preprint arXiv:1711.08200, 2017. (T3D)
[21]. http://medium.com/@lisajamhoury/understanding-kinect-v2-joints-and-coordinate-system-4f4b90b9df16
[22]. http://github.com/CMU-Perceptual-Computing-Lab/openpose
[23]. Baradel F, Wolf C, Mille J. Human action recognition: Pose-based attention draws focus to hands[C]//Proceedings of the IEEE International Conference on Computer Vision Workshops. 2017: 604-613.
[24]. Pavllo D, Feichtenhofer C, Grangier D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training[J]. arXiv preprint arXiv:1811.11742, 2018.
[25]. http://blog.csdn.net/LoseInVain/article/details/88373506
[26]. http://blog.csdn.net/LoseInVain/article/details/90171863
[27]. http://blog.csdn.net/LoseInVain/article/details/90348807
[28]. A. Shahroudy, J. Liu, T. T. Ng, et al. Ntu rgb+d: A large scale dataset for 3d human activity analysis[C]. IEEE Conference on Computer Vision and Pattern Recognition, 2016, 1010-1019 (P-LSTM)
[29]. Liu J, Shahroudy A, Xu D, et al. Spatio-temporal lstm with trust gates for 3d human action recognition[C]//European Conference on Computer Vision. Springer, Cham, 2016: 816-833. (ST-LSTM)
[30]. Y. Du, Y. Fu, L. Wang. Skeleton based action recognition with convolutional neural network[C]. Pattern Recognition, 2016, 579-583 (Skel-CNN)
[31]. Ke Q, Bennamoun M, An S, et al. A new representation of skeleton sequences for 3d action recognition[C]//Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017: 4570-4579.
[32]. Liu M, Liu H, Chen C. Enhanced skeleton visualization for view invariant human action recognition[J]. Pattern Recognition, 2017, 68: 346-362.
[33]. S. Yan, Y. Xiong, D. Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. The Association for the Advance of Artificial Intelligence, AAAI, 2018, 5344-5352 (ST-GCN)
[34]. Yang D, Li M M, Fu H, et al. Centrality Graph Convolutional Networks for Skeleton-based Action Recognition[J]. arXiv preprint arXiv:2003.03007, 2020.
[35]. Gao J, He T, Zhou X, et al. Focusing and Diffusion: Bidirectional Attentive Graph Convolutional Networks for Skeleton-based Action Recognition[J]. arXiv preprint arXiv:1912.11521, 2019.
[36]. Li M, Chen S, Chen X, et al. Symbiotic Graph Neural Networks for 3D Skeleton-based Human Action Recognition and Motion Prediction[J]. arXiv preprint arXiv:1910.02212, 2019.
[37]. Ji Y, Xu F, Yang Y, et al. Attention Transfer (ANT) Network for View-invariant Action Recognition[C]//Proceedings of the 27th ACM International Conference on Multimedia. 2019: 574-582.
[38]. Rahmani H, Mian A. 3D action recognition from novel viewpoints[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1506-1515.
[39]. Rahmani H, Mian A, Shah M. Learning a deep model for human action recognition from novel viewpoints[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(3): 667-681.
[40]. Junejo I N, Dexter E, Laptev I, et al. Cross-view action recognition from temporal self-similarities[C]//European Conference on Computer Vision. Springer, Berlin, Heidelberg, 2008: 293-306.
[41]. Kacem A, Daoudi M, Amor B B, et al. A Novel Geometric Framework on Gram Matrix Trajectories for Human Behavior Understanding[J]. IEEE transactions on pattern analysis and machine intelligence, 2018.
[42]. Hernandez Ruiz A, Porzi L, Rota Bulò S, et al. 3D CNNs on distance matrices for human action recognition[C]//Proceedings of the 2017 ACM on Multimedia Conference. ACM, 2017: 1087-1095
[43]. Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
[44]. Zhang P, Lan C, Xing J, et al. View adaptive recurrent neural networks for high performance human action recognition from skeleton data[J]. ICCV, no. Mar, 2017.
[45]. Kong Y, Ding Z, Li J, et al. Deeply learned view-invariant features for cross-view action recognition[J]. IEEE Transactions on Image Processing, 2017, 26(6): 3028-3037.
[46]. Rogez G, Schmid C. Mocap-guided data augmentation for 3d pose estimation in the wild[C]//Advances in Neural Information Processing Systems. 2016: 3108-3116.
[47]. A. Gupta, J. Martinez, J. J. Little, and R. J. Woodham, “3D pose from motion for cross-view action recognition via non-linear circulant temporal encoding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2014, pp. 2601–2608.
[48]. A. Gupta, A. Shafaei, J. J. Little, and R. J. Woodham, “Unlabelled 3D motion examples improve cross-view action recognition,” in Proc. British Mach. Vis. Conf., 2014
[49]. Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
[50]. http://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
[51]. Goyal P, Mahajan D, Gupta A, et al. Scaling and benchmarking self-supervised visual representation learning[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 6391-6400.
[52]. Wang J, Jiao J, Bao L, et al. Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 4006-4015.
[53]. Misra I, Zitnick C L, Hebert M. Shuffle and learn: unsupervised learning using temporal order verification[C]//European Conference on Computer Vision. Springer, Cham, 2016: 527-544.
[54]. Gidaris S, Singh P, Komodakis N. Unsupervised representation learning by predicting image rotations[J]. arXiv preprint arXiv:1803.07728, 2018.
[55]. Noroozi M, Favaro P. Unsupervised learning of visual representations by solving jigsaw puzzles[C]//European Conference on Computer Vision. Springer, Cham, 2016: 69-84.
[56]. Fernando B, Bilen H, Gavves E, et al. Self-supervised video representation learning with odd-one-out networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 3636-3645.
[57]. Wang X, Gupta A. Unsupervised learning of visual representations using videos[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 2794-2802.
[58]. http://blog.csdn.net/LoseInVain/article/details/103995962
[59]. Vondrick C, Shrivastava A, Fathi A, et al. Tracking emerges by colorizing videos[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 391-408.
[60]. Vinyals O, Blundell C, Lillicrap T, et al. Matching networks for one shot learning[C]//Advances in neural information processing systems. 2016: 3630-3638.
[61]. Vinyals O, Fortunato M, Jaitly N. Pointer networks[C]//Advances in neural information processing systems. 2015: 2692-2700.
- 精准水位在流批一体数据仓库的探索和实践
- 视频编辑场景下的文字模版技术方案
- 浅谈活动场景下的图算法在反作弊应用
- 百度工程师带你玩转正则
- Serverless:基于个性化服务画像的弹性伸缩实践
- 百度APP iOS端内存优化-原理篇
- 从稀疏表征出发、召回方向的前沿探索
- 性能平台数据提速之路
- 采编式AIGC视频生产流程编排实践
- 百度工程师漫谈视频理解
- PGLBox 超大规模 GPU 端对端图学习训练框架正式发布
- 百度工程师浅谈分布式日志
- 百度工程师带你了解Module Federation
- 巧用Golang泛型,简化代码编写
- Go语言DDD实战初级篇
- 百度工程师带你玩转正则
- Diffie-Hellman密钥协商算法探究
- 贴吧低代码高性能规则引擎设计
- 浅谈权限系统在多利熊业务应用
- 分布式系统关键路径延迟分析实践