百度工程师带你玩转正则

作者 | 向阳
导读
在很多技术领域,都有正则的身影。但许多像我一样的人,只闻其名。因此将正则常用知识汇总,便于查阅。正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具。因此正则表达式是用于匹配字符串中字符组合的模式。
正则表达式可以很方便的提取我们想要的信息,所以正则表达式是一个很重要的知识点!欢迎大家一起学习~
全文4082字,预计阅读时间11分钟。
01 正则概述
正则表达式是用于匹配字符串中字符组合的模式。在 JavaScript中,正则表达式也是对象。
02 基本语法
2.1 定义方式
字面量方式:/^\d+$/g,
new RegExp("^\\d+$", "g")
2.2 修饰符
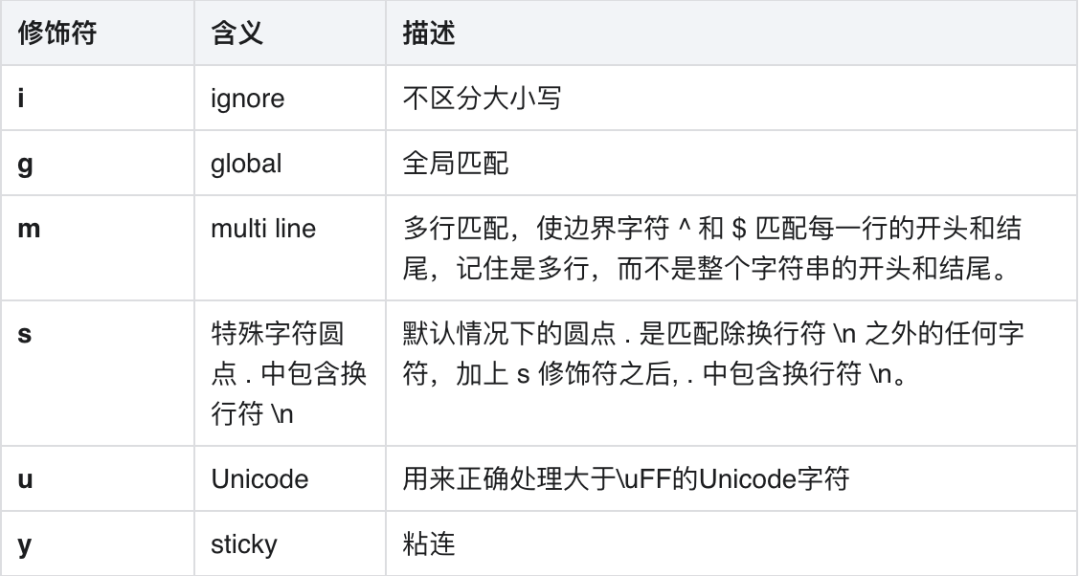
2.3 元字符
一个正则表达式模式是由简单的字符所构成的,比如 /abc/;或者是简单和特殊字符的组合,比如 /ab*c/

2.4 其他断言
断言的组成之一是边界。对于文本、词或模式,边界可以用来表明它们的起始或终止部分,分为边界类断言与其他断言。边界类断言有 ^, $, \b, \B,其他断言有 x(?=y), x(?!y), (?<=y)x, (?<!y)x。

注:需要关注写法与真正匹配到的字符串!!!
03 正则对象的属性和方法
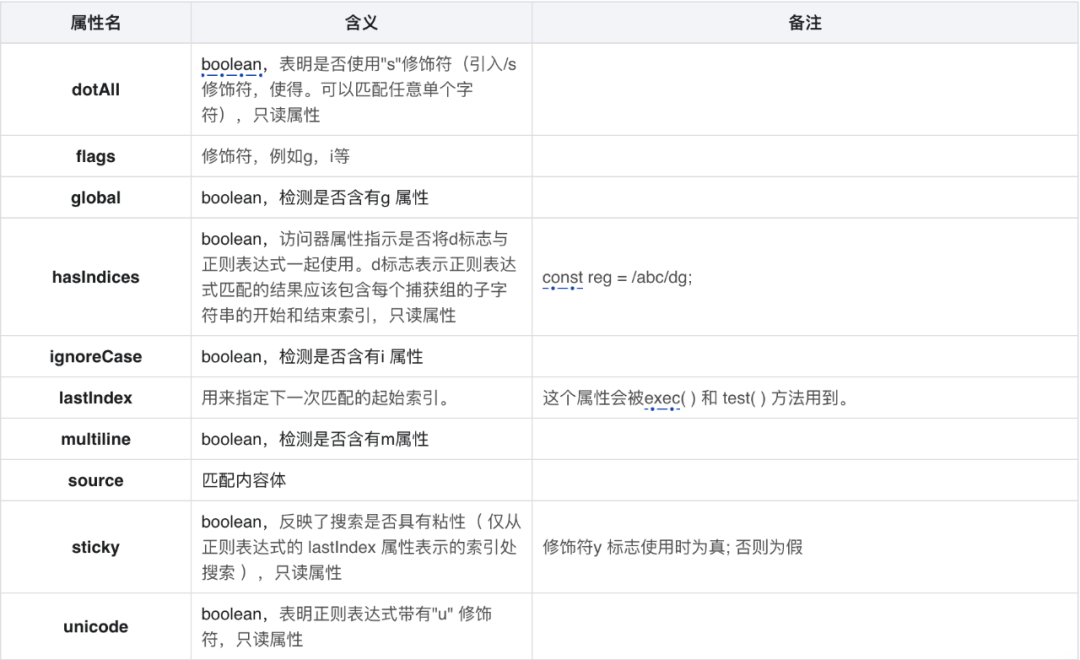
3.1 属性
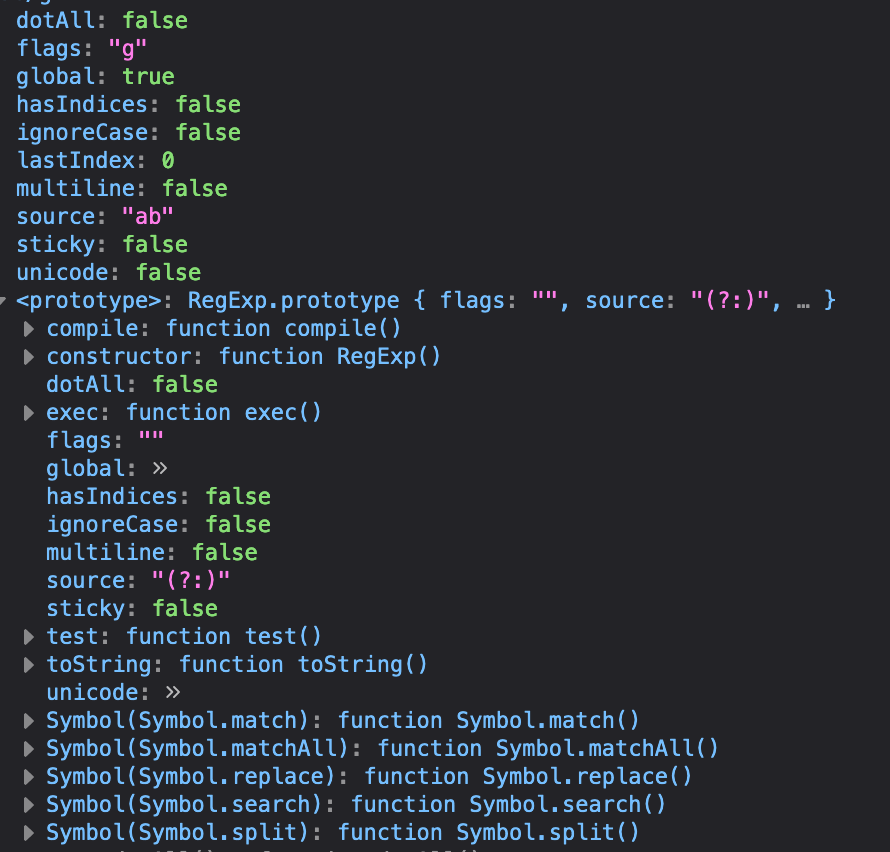
△正则属性和方法
var reg=/ab/g;
reg.ignoreCase; // false,检测是否含有i 属性
reg.global; // true,检测是否含有g 属性
reg.multiline; // false,检测是否含有m 属性
reg.source; // "ab",匹配内容体
var regex =new RegExp("\u{61}","u");
regex.unicode // true
const str1 = "foo bar foo";
const regex1 = /foo/dg;
regex1.hasIndices // Output: true
regex1.exec(str1).indices[0] // Output: Array [0, 3]
regex1.exec(str1).indices[0] // Output: Array [8, 11]
const str2 = "foo bar foo";
const regex2 = /foo/;
regex2.hasIndices // Output: false
regex2.exec(str2).indices // Output: undefined
3.2 相关方法
这些模式被用于RegExp的exec和test方法,以及String的match、matchAll、replace、search和split方法。
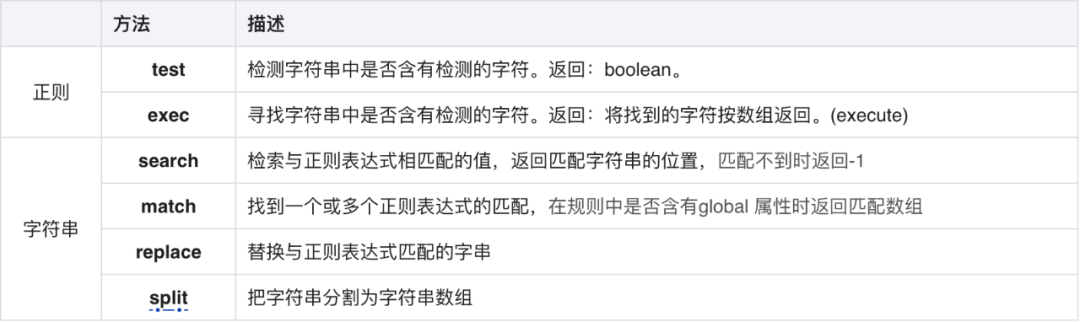
test
/str/.test('hello world'); //要求字符串包含string,所以返回false
exec
var reg=/ab/g;
var str="abababab";
reg.lastIndex //0
reg.exec(str)//["ab",index:0,input:"abababab"]
reg.lastIndex//2
reg.exec(str)//["ab",index:2,input:"abababab"]
reg.lastIndex//4
reg.exec(str)//["ab",index:4,input:"abababab"]
reg.lastIndex//6
reg.exec(str)//["ab",index:6,input:"abababab"]
reg.lastIndex//8
reg.exec(str)//null
reg.lastIndex//0
reg.exec(str)//["ab",index:0,input:"abababab"]
//reg.lastIndex是可手动修改的
reg.lastIndex=0; // reg.lastIndex重置0
reg.exec(str)
// ["ab",index:0,input:"abababab"],与上面结果中的index相同
// 若匹配规则不含有global属性,那在允许exec()方法后lastIndex值始终为0
var reg=/ab/;
var str="abababab";
reg.lastIndex // 0
reg.exec(str) // ["ab",index:0,input:"abababab"]
reg.lastIndex // 0
reg.exec(str) // ["ab",index:0,input:"abababab"]
search
"hello world".search(/w/) // 6
match
const str = "hello world";
const reg1 = /o/;
str.match(reg1); // ['o', index: 4, input: 'hello world', groups: undefined]
const reg2 = /o/g;
str.match(reg2); // ['o', 'o']
replace
"hello world".replace(/world/g,"baidu"); // hello baidu
split
var str="a1b2c";
var reg=/\d/g;
str.split(reg); // ["a","b","c"],即将分隔符两侧的字符串进行拆分
var reg=/(\d)/g; // "()"代表记录反向引用,将匹配表达式也返回回来
str.split(reg); // ["a","1","b","2","c"]
04 捕获组与非捕获组
正则表达式分组分为捕获组(Capturing Groups)与非捕获组Non-Capturing Groups。正则里面是用成对的小括号来表示分组的,如(\d)表示一个分组,(\d)(\d)表示有两个分组,(\d)(\d)(\d)表示有三个分组,有几对小括号元字符组成,就表示有几个分组。
4.1 分组的目的
-
作为可选分支
-
简写重复模式
-
缓存捕获数据及反向引用(只有捕获组才可以被反向引用)
4.2 捕获组
当你把一个正则表达式用一对小括号包起来的时候,就形成了一个捕获组。它捕获的就是分组里面的正则表达式匹配到的内容。
/(\w)+/.test('hello world') //(\w)组成一个捕获组
4.3 非捕获组
/(?:\w)+/.test('hello world') //(\w)组成一个捕获组
使用场景:
不需要用到分组里面的内容的时候,用非捕获组,主要是为了提升效率,因为捕获组多了一步保存数据的步骤,所以一般会多耗费一些时间。
4.4 命名捕获组
捕获组其实是分为编号捕获组Numbered Caputuring Groups和命名捕获组Named Capturing Groups的,我们上面说的捕获组,默认指的是编号捕获组。命名捕获组,也是捕获组,只是语法不一样。命名捕获组的语法如下:(?<name>group) 或 (?'name'group),其中 name 表示捕获组的名称,group 表示捕获组里面的正则。
const str = '2022-12-15';
const reg = /(\d{4})-(\d{2})-(\d{2})/;
str.match(reg)
// ['2022-12-15', '2022', '12', '15', index: 0, input: '2022-12-15', groups: undefined]
const isNotCaputuringReg = /(?:\d{4})-(?:\d{2})-(?:\d{2})/;
str.match(isNotCaputuringReg)
// ['2022-12-15', index: 0, input: '2022-12-15', groups: undefined]
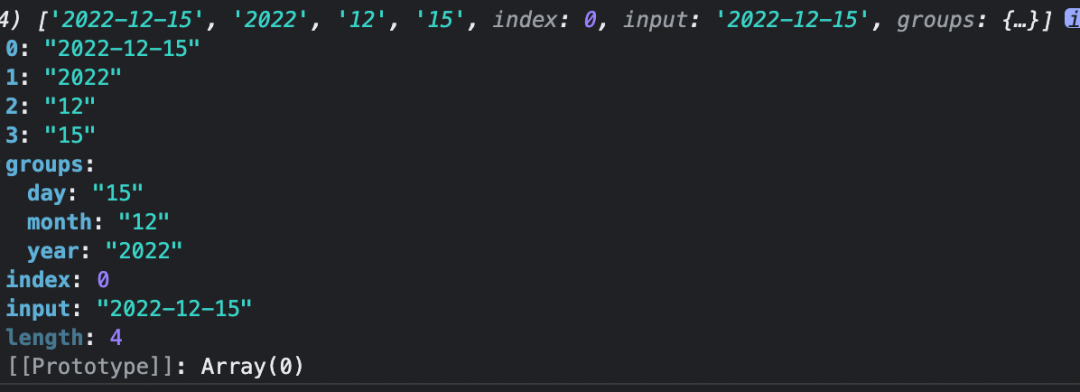
const namedCaputuringReg = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
str.match(namedCaputuringReg)
// 匹配结果如下图
05 正则中有趣用法
5.1 贪婪匹配与非贪婪匹配
贪婪匹配即照着"量词"规则中要求的更多个的情况去做匹配。
非贪婪匹配,在"量词"规则后边多加一个问号"?"。
"量词"包括 ?、*、+、{}、{n,}、{n,m}
var str="aaaaa";
var reg=/a+/g;
str.match(reg);//["aaaaa"]
var reg=/a??/g;//第一个问号代表0~1个,第二个问号代表能取0就不取1去做匹配
str.match(reg);//["","","","","",""]
5.2 反向引用
反向引用就是正则中' \1 '用法,下列代码中(\w)首先匹配a,'\1'引用a,后面量词'+'表示出现一次获多次。
var str = 'aaaaabbbbbbcccccccd'
var reg = /(\w)\1+/g
str.replace(reg,'$1') // $1是第一个小括号中的内容
// abc
06 易错用法
/[1-51]/.test('6')
'aaa'.match(/a*?/g)
false // 可匹配1,2,3,4,5,同(1-5||1)
['', '', '', ''] //注意:字符串有三个a,数组有四个空字符串
——END——
参考资料:
[1]菜鸟教程:
http://www.runoob.com/regexp/regexp-intro.html
[2]MDN:
http://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp/test
推荐阅读:
- 精准水位在流批一体数据仓库的探索和实践
- 视频编辑场景下的文字模版技术方案
- 浅谈活动场景下的图算法在反作弊应用
- 百度工程师带你玩转正则
- Serverless:基于个性化服务画像的弹性伸缩实践
- 百度APP iOS端内存优化-原理篇
- 从稀疏表征出发、召回方向的前沿探索
- 性能平台数据提速之路
- 采编式AIGC视频生产流程编排实践
- 百度工程师漫谈视频理解
- PGLBox 超大规模 GPU 端对端图学习训练框架正式发布
- 百度工程师浅谈分布式日志
- 百度工程师带你了解Module Federation
- 巧用Golang泛型,简化代码编写
- Go语言DDD实战初级篇
- 百度工程师带你玩转正则
- Diffie-Hellman密钥协商算法探究
- 贴吧低代码高性能规则引擎设计
- 浅谈权限系统在多利熊业务应用
- 分布式系统关键路径延迟分析实践