開源機器學習軟件對AI的發展意味着什麼?

作者| Max Langenkamp
OneFlow編譯
翻譯|徐佳渝、楊婷
為什麼要關注機器學習開源軟件(MLOSS)?在我們看來,MLOSS對AI發展來説舉足輕重,但未獲重視。
機器學習開源軟件是開源許可下發布的專為機器學習而設計的計算機軟件。機器學習開源軟件包括框架(如PyTorch和Pyro)、“一體化”軟件包(如scikit-learn)以及模型開發工具(如TensorBoard),但不包括Jupyter Notebook這類交互式計算工具。雖然Jupyter Notebook並非專為機器學習而設計,但是相關從業者經常會用到這款工具。
1
機器學習開源軟件舉足輕重,但未獲重視
MLOSS舉足輕重
過去十年,只要構建過ML模型的人都知道MLOSS至關重要,無論是Deepmind的研發工程師,還是印度的高中生都無一例外會使用開源軟件來構建模型。我們採訪了24名ML從業者,他們都給出了相同的答案:MLOSS工具在模型構建中的地位舉足輕重。
從業者都在免費使用MLOSS工具,也就意味着這類工具會對人工智能發展產生巨大影響。然而,探索MLOSS對AI發展影響的研究人員卻寥寥無幾。
MLOSS未獲重視
迄今為止,研究者就影響人工智能發展的因素展開了多次討論,其焦點都集中於算力,部分研究者將算法和數據也列為了影響因素之一。例如,艾倫·達福(Allan Dafoe)認為影響人工智能發展的關鍵因素是計算能力(算力)、人才、數據、洞察力及資金。[1] 黃(Hwang) (2018)探究了硬件供應鏈對機器學習發展的影響。羅森菲爾德(Rosenfeld) (2019)和海斯特內斯(hesistest)(2017)研究了數據集大小與人工智能模型精度的關係。
越來越多的文獻都提到了數據集大小和人工智能模型精度,旨在明確如何建立人工智能中輸入和預測誤差之間的關係模型。然而,據我們所知,目前還未有關於MLOSS如何影響人工智能發展的深入研究。
目前,我們的關注點是數據、算力等因素如何改變人工智能的發展方向,不過,同時也應聚焦於MLOSS在人工智能發展中的角色。
MLOSS及AI生產函數
我們在早期研究中存在這樣的疑惑:數據、算力及MLOSS這些AI生產的影響因素相互之間有何聯繫,而闡明這些因素之間的聯繫正是理解AI系統開發默認軌跡(default trajectory)的關鍵。
柯布-道格拉斯生產函數(Cobb-Douglas production function)是經濟學中常用的界定方式。該函數用於資本和原材料等變量的建模,通過函數參數化以表示投入與產出的關係。
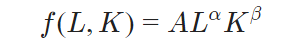
CD生產函數的表示形式
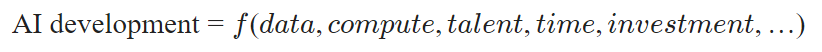
AI生產函數的隱含形式
艾倫·達福將“AI生產函數”應用於人工智能治理,並提出構成該生產函數的關鍵在於算力、人才、數據、投資、時間以及先前進展和成果等指標[1]。達福就“人工智能進展”研究進行了探討,此外,在類似研究中也有相關探討,以解除人工智能特定範式的思維限制。
實際上,這就相當於“深度學習”和“人工智能”。而我們可以選擇不同範式,不過認識到這些範式功能的多樣性也十分重要。例如,概率程序更容易吸收現存的顯性知識,同時能減少對大數據集可用性的依賴。
雖然生產函數可以明確區分出影響深度學習發展的因子,但也存在侷限性。特別是當生產函數被認為是自變量的乘積時,不會考慮生產因子之間的共同依賴關係,而且可能還會隱藏每個因子的上下文信息。
還有另一種方法可以闡明影響AI生產的因子,即使用有序的功能依賴圖,亦稱沃德利地圖(Wardley map),來解釋因子之間的共享依賴關係。例如:中間模型表示依賴於算力基礎設施和MLOSS框架。
2
沃德利地圖為AI生產函數提供了最佳替代方案
沃德利地圖應用廣泛。譬如, 可在無手機的情況下用於求生 , 也可用於電車的路況預測 。此外,還有本關於沃德利地圖理論的 書籍 。為探尋MLOSS在AI生態系統中發揮的作用,我們在下文提供了簡單示例。
構建沃德利地圖的三大主要步驟:描述用例、為處理用例所需的技術功能下定義以及對該地圖相應功能進行排序。
以下是“構建深度學習模型”的用例,也是重中之重。我們將重點關注框架、預訓練模型、數據及硬件的主要功能,且各功能之間相互具有依賴性。如,框架編譯軟件(Glow編譯器)受到ML框架(PyTorch)的影響,而框架編譯軟件依賴於中間表示(ONNX),此外,中間表示又會受到硬件(NVIDIA GPU)的影響。
現階段,我們旨在闡明與ML框架(MLOSS為典型示例)相關的某些關鍵功能,而非對各方面都泛泛而談。
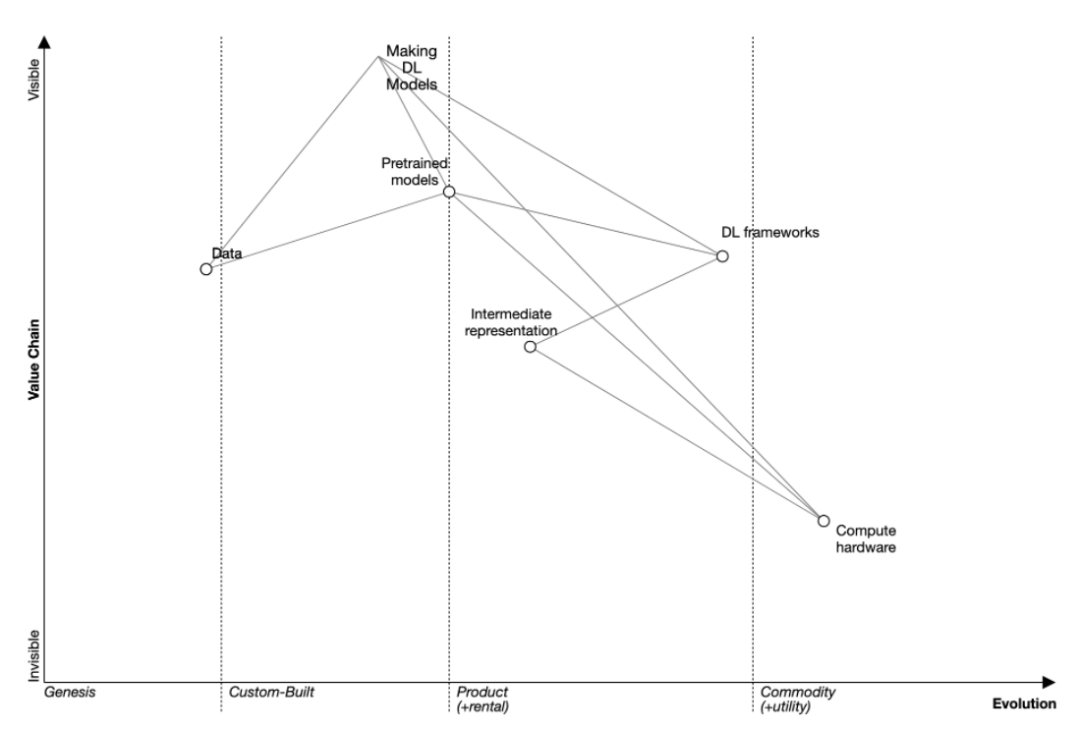
圖1. 以沃德利地圖構建深度學習模型
通過沃德利地圖,我們能更清晰闡述有關塑造深度學習研究的能力之間的關係。基於此,推斷出哪些功能將成為未來焦點。我們會在最後一節詳細討論“ MLOSS之未來 ”。
稍後,我們將通過沃德利地圖來探討人工智能的未來。
3
MLOSS通過構建標準、推行實驗及創建社區來促進人工智能研究的發展
我們對23名參與者進行了定性訪談,進而確定了MLOSS影響人工智能生態系統的三大主要因素。
構建標準
標準化是指我們普遍認可的單一技術或技能規範。參與者從研製標準化模型類型、協調框架、為開發人員提供一致的用户體驗這三個方面談論了構建標準帶來的的影響。
對大型神經網絡相關從業者而言,模型類型標準化做出的貢獻最為突出。十年前,擁有百萬參數的模型是一項浩瀚工程。然而現如今,研究人員只需連接互聯網以及使用合適的硬件,就能免費下載 一個超1700多億參數的模型 或 用這一模型進行在線推理 。因此,如今大多數與機器學習相關的工作都會涉及大型神經網絡,這與MLOSS工具的普及以及硬件和性能工程的發展密不可分。
我們見證了深度學習框架的高度標準化:雖然2016年MXNet、Theano、TensorFlow、Caffe2、Torch這幾種深度學習框架佔據很大的市場份額,但是西方相關從業者已普遍將PyTorch、JAX及TensorFlow視為深度學習的三大主流框架。
該訪談中,所有參與者至少使用過這三大主流框架中的一種。 據Paperswithcode顯示 ,截至2022年6月,採用PyTorch的相關論文佔公開發表論文的62%、JAX佔7%,TensorFlow佔1%。雖然 DeepMind公開支持JAX這類框架的 使用,但是,我們認為Paperswithcode關於JAX的使用數據無法證明JAX越來越受歡迎。
此外,我們還可以看到框架內部用户體驗層面的融合。部分參與者指出,TensorFlow以往默認的基於graph的機制無法給予人們直觀感受,對初學者而言更不友好。他們解釋道:因為PyTorch具有更為直觀的命令式模型規範,所以才採用PyTorch。
值得注意的是,由於受到PyTorch帶來的衝擊,TensorFlow 2.0也採用了PyTorch的接口,使其用户體驗與PyTorch趨於一致。
推行實驗
推行實驗不僅能迅速落實我們的想法,還能提供新的思考方式。PyTorch Lightning開發了一個 權重矩陣彙總模塊 ,從而節省了研究人員調試模型的時間。而Torch的命令式編程也為研究人員提供了新思路。這也意味着將基於graph的模型規範應用於Tree-LSTMs這類新穎架構成為現實,這在以前是無法想象的。
創建社區
與開源軟件(OSS)生態系統類似,MLOSS的重要之處在於它為社區技術貢獻者及用户提供了交互機會。創建這類社區的好處諸多,例如用户能為社區貢獻力量、提供反饋、輸出技術內容,併為MLOSS志願者提供就業機會。
開源軟件論壇為交流提供了新平台,讓用户成為社區貢獻者是很好的實例。社區中也發生了一些趣事,一些對社區作出了巨大貢獻的用户隨後被社區項目贊助者看中,從而獲得了工作機會。雖未經系統統計,但總的來説加入MLOSS論壇及社區就有可能獲得一定的就業機會。
通過在線社區,人們可採取多種方式與項目組織方進行交流。例如,PyTorch的聯合創始人Sousmith Chintala曾公開談論PyTorch社區對早期工具開發所帶來的影響。要想開源軟件研發走得更遠、保證項目的成功,關鍵在於能否獲得大眾認可;而要想對項目作出一個不被支持的修改,可謂難上加難,即使失敗也不足為奇。為了讓這一觀點更具説服力,不妨邀讀者來一探究竟:Facebook更改React項目的開源許可協議為何會 失敗 。
4
經濟激勵措施、社會技術因素和意識形態共同決定MLOSS的發展
激勵措施
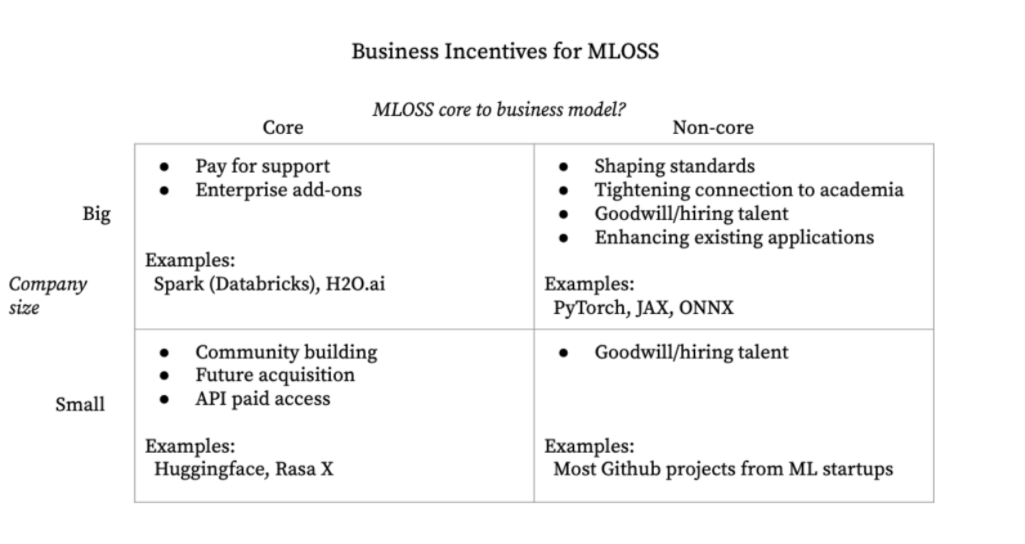
圖2. 有關商業激勵措施如何影響MLOSS的建議
結合案例研究及參與者的建議,我們發現大公司和初創公司的商業激勵措施各不相同。大公司資助MLOSS是為了引進研發人才,從而能間接控制開源軟件生態系統,強化現有能力。
由於許多開源工具的研發人員以前是用户,他們很難清晰表達如何間接控制開源軟件生態系統,因此引進人才不足為奇。這些在如何設置默認值(如:PyTorch兼容什麼類型的硬件)或如何拓展項目發展方向(如:HuggingFace是否優先考慮與Graphcore的IPU或Google的TPU的兼容性)上均有體現。
最後,無論增加計算需求(對數字雲提供商更有益)還是改進現有堆棧方式,增加MLOSS的使用往往能提升現有功能價值。由於TensorFlow的廣泛使用,谷歌Colab的用户量也大大提升。而共享PyTorch更是明顯改善了Facebook/Meta的人臉識別、圖像字幕功能。
初創公司為社區提供MLOSS以改進現有產品,助力未來產品。社區不僅僅是社區,更是強大的護城河。它可以助力發揮文化影響力、改善產品、獲取營利途徑並賦予人們 集體認同感 。
Hugging Face提供的大型語言模型包廣受歡迎便是一個很好的例證。Hugging Face開源了強大、可訪問的語言模型包,此舉讓社區收穫了大量粉絲。2022年,該公司通過實施有償模型訓練或模型推理,併為大企業提供諮詢服務 才實現了現金流回正 。社區可以幫助公司發掘人才、改善現有產品、挖掘企業服務的消費羣體。
社會技術因素
除了資金和意識形態之外,還有很多社會技術因素也對MLOSS有明顯影響。以下是三個最為突出的影響因素。
1. 軟件易用性是制勝關鍵
軟件的功能會極大地左右人們的選擇,人們傾向於選擇用户界面最直觀的軟件。值得一提的是,儘管最初缺乏對生產系統命令式方法的支持,TensorFlow最終還是採用了PyTorch的命令式神經網絡規範。TensorFlow基於graph機制與PyTorch基於eager的機制之間的競爭就好比是Lisp語言和C語言,或者“正確的事情”與“ 越壞就越好 ”之爭。
與Lisp語言相比,C語言簡單且完整度不夠,但是這種“更糟”的C編程語言的採納率卻遠遠超過了複雜、完整且“正確”的Lisp語言,PyTorch和TensorFlow之間的競爭也是如此,PyTorch這種更為簡單的方法戰勝了TensorFlow更高效的基於graph的模型。
2. 部分代碼實現標準化
數據集操作(dataset manipulation)和矩陣微分(matrix differentiation)是機器學習的兩個常見任務,我們就以此為例。數據集操作在數據集之間的差異很大,但需要的步驟很少。相比之下,矩陣微分在模型之間非常相似,但需要的步驟更多。矩陣微分的單調乏味和相似性意味着它是軟件中最先實現標準化的任務之一。一般來説,模塊化、同質化和瑣碎的任務會最先被標準化。
3. 研究社區的興趣
機器學習中的流行範式對MLOSS有顯著影響。目前,機器學習的主要模型類型是深度學習,這推動了深度學習(與替代概率編程(alternate probabilistic programming)或自動規劃(automated planning)等機器學習範例相反)MLOSS工具的發展。
當然,機器學習主流範式本身就會受到多種因素的影響,硬件狀態、權威基準、商業適用性對於塑造機器學習主導方法來説都很重要。想要深入瞭解相關信息,大家可以參閲Dotan和Milli (2019)2的論文。
意識形態
最後,意識形態對於MLOSS的發展也有着至關重要的影響。大多數MLOSS關鍵人物都受到特定世界觀的影響,他們的世界觀可能帶有宗教性質或是個人價值觀的產物。這些價值觀激勵着研究人員去改善其他開發人員的體驗或是促進AI的發展。
Travis Oliphant是NumPy(Python中最常用的庫之一)的創建者,他講述了創建NumPy作為公共服務時發生的故事,然而在那時,他的這一想法遭到了楊百翰大學(Brigham Young University)的顧問和同行們的反對。
其他研究人員單純認為推動AI的發展能帶來很多好處。Soumith Chintala在一次博客訪談中被問及Facebook贊助PyTorch的原因,他答道,“在AI研究院(Facebook AI Research)中我們有一個單點議程,這個議程是為了解決AI方面的問題,包括授權他人去解決相關問題。
這似乎意味着“解決AI”將極大促進社會發展,這種發展可以是發明新的藥品也可以是證明新的定理。同樣,H2O.ai和Hugging Face都將“人工智能民主化”作為開源其產品的核心動機。
5
MLOSS(深度學習)中的自我強化反饋循環
在本節中,我們將討論MLOSS的增殖(proliferation)方式,這種方式可能會選擇性地偏愛某一種機器學習(深度學習)類型。
AI深度學習範式的替代方案
除了深度學習,AI研究還有其他範式,比如概率機器學習(probabilistic machine learning)、基於規則的專家系統(rule-based expert systems)以及自動規劃(automated planning)。
正如一些受訪者所説,儘管深度學習是 ML/AL 研究中的主導範式,但我們很難理清深度學習取得進步的原因,顯然技術優勢是一部分原因,但是隨着 MLOSS 生態系統的進步,我們也不能忽視進步背後巨大的工程優勢。充其量,很難評估若替代方法具有類似資源,技術會如何進步。在最壞的情況下,深度學習創造了一種自我強化動力,使得生態系統的影響比底層技術的優勢更重要。
提到深度學習沒有明顯優勢的領域,驗證飛行軟件(verifying flight software)就是一個例子,它對確定性有很高的要求。在這些領域,工程師們會選擇使用與自動規劃密切相關的定理證明器(theorem provers)來正式驗證軟件質量。目前深度學習還不能勝任這方面的任務,因為它們無法提供正式的保證。
更好地支持深度學習工具有助於加強深度學習
目前MLOSS工具有兩種支持深度學習的方式:減少開發人員摩擦和改變研究人員激勵措施。
PyTorch和FastDownward分別是深度學習和自動規劃領域最流行的兩個開源工具。PyTorch主要由Facebook的AI研究院開發,並得到了極好的支持。用户通常可以通過單個搜索引擎查詢來解決技術問題,這個查詢會解析數以萬計的帖子和活躍用户。許多有用的代碼片段詳細説明了如何調試尺寸不匹配的張量。
現在我們來聊一聊FastDownward。FastDownward的安裝非常重要,需要操作系統的基本知識才能下載壓縮文件包 (tarball) 並手動配置安裝。如果遇到技術問題,用户很難立即獲得支持。在我們嘗試的大多數錯誤查詢中,通過搜索引擎直接搜索的方式找不到答案,所以我們不得不求助於他們的自定義論壇。我們這樣説並不是在貶低FastDownward,而是想要説明全職工程師團隊之間在用户體驗上的巨大差異。
在採訪過程中,我們看到了工具使用摩擦的微小差異是如何推動TensorFlow轉向PyTorch的。我們認為,研究工具的易用性對研究人員關注問題的選擇有着顯著的影響。通過這種方式,當前最流行的MLOSS工具(PyTorch、JAX、Hugging Face等)促進了深度學習方面的工作,這並不是深度學習作為AI範式的科學價值的直接結果。
因為強大的生態系統支持,深度學習工具已經生產化,這讓深度學習工程成為一種非常理想的技能組合,這是MLOSS加強深度學習的另一種方式。
深度學習工具易用、可靠且得到大量用户社區的支持,因此許多公司都可以使用深度學習。很多公司已經開始通過TensorFlow等工具應用深度學習,因此,相比其他範式,深度學習領域專家擁有更多的工作機會,同時行業裏對涉及深度學習工作的需求量也更高。在Indeed.com上有超過15000個崗位涉及深度學習,而涉及概率編程和自動規劃的崗位則分別只有40個和8個。
6
MLOSS的未來
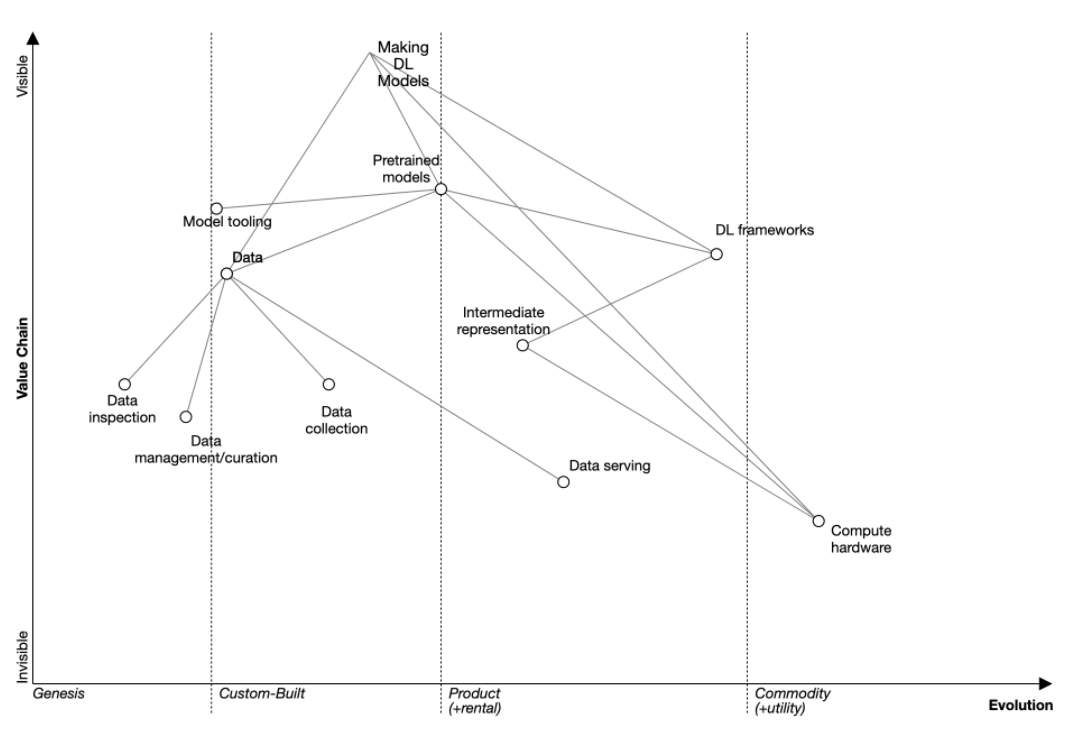
圖3: 深度學習模型的擴展沃德利地圖
前面提到過的沃德利地圖可以對技術發展軌跡作出一些預測。一般來説,能力越靠近左邊就意味着該能力越是不足,就越會制約技術的發展,生態系統的注意力就會轉向去提升這些相對被忽視的能力。與定性證據相結合,沃德利地圖推測出了下面四個發展趨勢。
趨勢1:MLOSS的重心將從深度學習框架轉移
儘管深度學習框架(PyTorch 、TensorFlow、Chainer、Theano、Torch以及華為最近發佈的MindSpore)之間的競爭非常激烈,但使用框架表達深度學習模型已不再是瓶頸。
PyTorch的創建者之一Soumith Chintala隱晦地説道“通過PyTorch和TensorFlow,我們已經看到了框架之間的融合趨勢,接下來競爭的主戰場將會是框架編譯器,比如XLA、TVM以及PyTorch的Glow,這一領域將會迎來大量創新”。
趨勢2:更多大型預訓練模型工具
最近,許多著名項目都在對大型預訓練模型進行迭代升級。Github的大模型Copilot是GPT-3[12]的微調版本,旨在協助Python進行代碼編寫。從最基礎的層面來説,這涉及為預訓練模型提供服務的基礎設施。
當前的大語言模型太大,無法在單台計算機上運行,但OpenAI的GPT-3 API和Hugging Face的服務基礎設施已經能夠做到這一點。後續工具允許管理不同模型版本,用於組合大型的不同預訓練模型的元框架,以及用於將不同模式(例如視覺、聲音、文本)合併到預訓練模型中的工具。
趨勢3:(潛在閉源)數據工具更加多樣
許多初創公司正試圖解決當前處理數據的臨時性質(ad-hoc nature),但尚未整合到單一工具上。更廣泛地説,隨着 Andrew Ng 的“以數據為中心的人工智能”等活動的發展,許多研究人員認為數據這一工具和研究的重點被忽視了。如果這一看法正確,那麼用於數據檢查和生產的工具將變得尤為重要。
是否對這些未來工具開源將取決於任務規模。與大學或小型初創公司的 GB 級實驗相比,PB 級數據系統,例如特斯拉的自動駕駛汽車數據pipeline會開源的可能性要小得多。這可能會讓大小型工具發展道路進一步分化,大規模工具由 Scale 等專有平台提供,部分小規模數據工具則會開源,可供研究人員免費使用。

表1.不同類型的數據工具
對風險的簡要反思
數據工具的發展趨勢對機器學習的中期風險來説意味着什麼?與計算的發展趨勢類似,數據工具的發展趨勢似乎也是小部分公司集中了大部分能力。這種發展趨勢可能更便於管理,各國政府都已成功展現出管理由通用技術發展而來的壟斷行業的能力,比如説電力。然而令人擔憂的是,我們對這些技術的控制能力遠遠跟不上管理能力的發展。
MLOSS 中的社區規範也對潛在風險有重大影響。因為MLOSS有很多強大社區,如果其中某個有影響力的社區無視發佈強大AI系統的安全問題,在這種情況下,我們認為高風險模型(例如致命病毒生成)的研究人員更可能公開發布他們的模型。
因為AI系統通常是可組合的,所以我們預測模型增殖(model proliferation)的風險可能呈非線性增長。由於不良分子可以將不同模式的模型相結合,因此公開可用模型可能產生的風險將遠遠超出公開的模型數量。如果要嚴肅對待這種情況,那麼我們就必須要在模型發佈之前制定謹慎的相關規範。
為了增加研究可靠性,我們對模型未來的發展前景作了一些推測,這些推測都有一定的可能性:
-
截至2027年1月,根據Paperswithcode(中國境外),PyTorch和JAX將成為最受歡迎的三大深度學習框架中的其中兩大框架。
-
Python將成為2027年最流行的機器學習語言。
-
ONNX將成為主流的中間表示框架。
-
在2023至2027年間,對公眾閉源的前5大語言模型不會開源。
-
截至2027年,三個最受歡迎的數據工具提供平台在很大程度上會是專有的,也就是説他們不會開源堆棧的關鍵組成部分。
這些預測大多基於我們的直覺,並不完全準確,但我們認為,無論如何這些粗略的預測都有一定的作用,因此也將其列了下來。
下一步研究方向
-
其他領域(比如LLVM等編譯器)裏的MLOSS和OSS有哪些相同/不同點?
-
我們期望數據工具以何種有別於框架工具的方式發展?
-
擴展概率編程與深度學習(特別是計算)所需的能力有何不同?
-
中國的MLOSS與美國的有何不同?這對人工智能研究知識的傳播來説意味着什麼?
-
開源數據工具的激勵與其他MLOSS(尤其是框架)的激勵有何不同?
(本文經授權後由OneFlow社區編譯發佈,譯文轉載請聯繫獲得授權。原文 :http://maxlangenkamp.me/posts/mloss_essay/)
其他人都在看
歡迎Star、試用OneFlow最新版本:http://github.com/Oneflow-Inc/oneflow/

本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- OneFlow源碼解析:Eager模式下的設備管理與併發執行
- OpenAI創始人:GPT-4的研究起源和構建心法
- GPT-4創造者:第二次改變AI浪潮的方向
- NCCL源碼解析①:初始化及ncclUniqueId的產生
- GPT-4問世;LLM訓練指南;純瀏覽器跑Stable Diffusion
- 適配PyTorch FX,OneFlow讓量化感知訓練更簡單
- 超越ChatGPT:大模型的智能極限
- ChatGPT作者John Schulman:我們成功的祕密武器
- YOLOv5全面解析教程⑤:計算mAP用到的Numpy函數詳解
- GPT-3/ChatGPT復現的經驗教訓
- ChatGPT背後:從0到1,OpenAI的創立之路
- 一塊GPU搞定ChatGPT;ML系統入坑指南;理解GPU底層架構
- YOLOv5全面解析教程④:目標檢測模型精確度評估
- ChatGPT數據集之謎
- OneFlow源碼解析:Eager模式下的SBP Signature推導
- YOLOv5全面解析教程③:更快更好的邊界框迴歸損失
- ChatGPT背後的經濟賬
- Sam Altman的成功學|升維指南
- 開源機器學習軟件對AI的發展意味着什麼?
- “一鍵”模型遷移,性能翻倍,多語言AltDiffusion推理速度超快