PGLBox全面解決圖訓練速度、成本、穩定性、複雜演算法四大問題!
圖神經網路(Graph Neural Network,GNN)是近年來出現的一種利用深度學習直接對圖結構資料進行學習的方法,通過在圖中的節點和邊上制定聚合的策略,GNN能夠學習到圖結構資料中節點以及邊內在規律和更加深層次的語義特徵。圖神經網路不僅成為學術界研究熱點,而且已經在工業界廣泛應用落地。特別在搜尋、推薦、地圖等領域,採用大規模分散式圖引擎對異構圖結構進行建模,已經成為技術發展的新趨勢。
目前,分散式圖學習框架通常在CPU叢集上部署分散式圖服務以及引數伺服器,來支援大規模圖結構的儲存以及特徵的更新。然而,基於CPU算力的圖學習框架在建設成本、訓練速度、穩定性以及複雜演算法支援等方面都存在不足。
因此,百度飛槳推出了能夠同時支援複雜圖學習演算法+超大圖+超大離散模型的GPU大規模圖學習訓練框架PGLBox。該框架結合了百度移動生態模型團隊在大規模業務技術的深耕,凝聚飛槳圖學習PGL豐富的演算法能力與應用經驗,並依託飛槳深度學習平臺通用的訓練框架能力與靈活組網能力,不僅繼承了飛槳前期開源的Graph4Rec[1]超大規模、靈活易用和適用性廣的優點[2],更是在訓練效能、圖演算法能力支援方面獲得了顯著提升。
01 超高效能的GPU分散式圖學習訓練框架
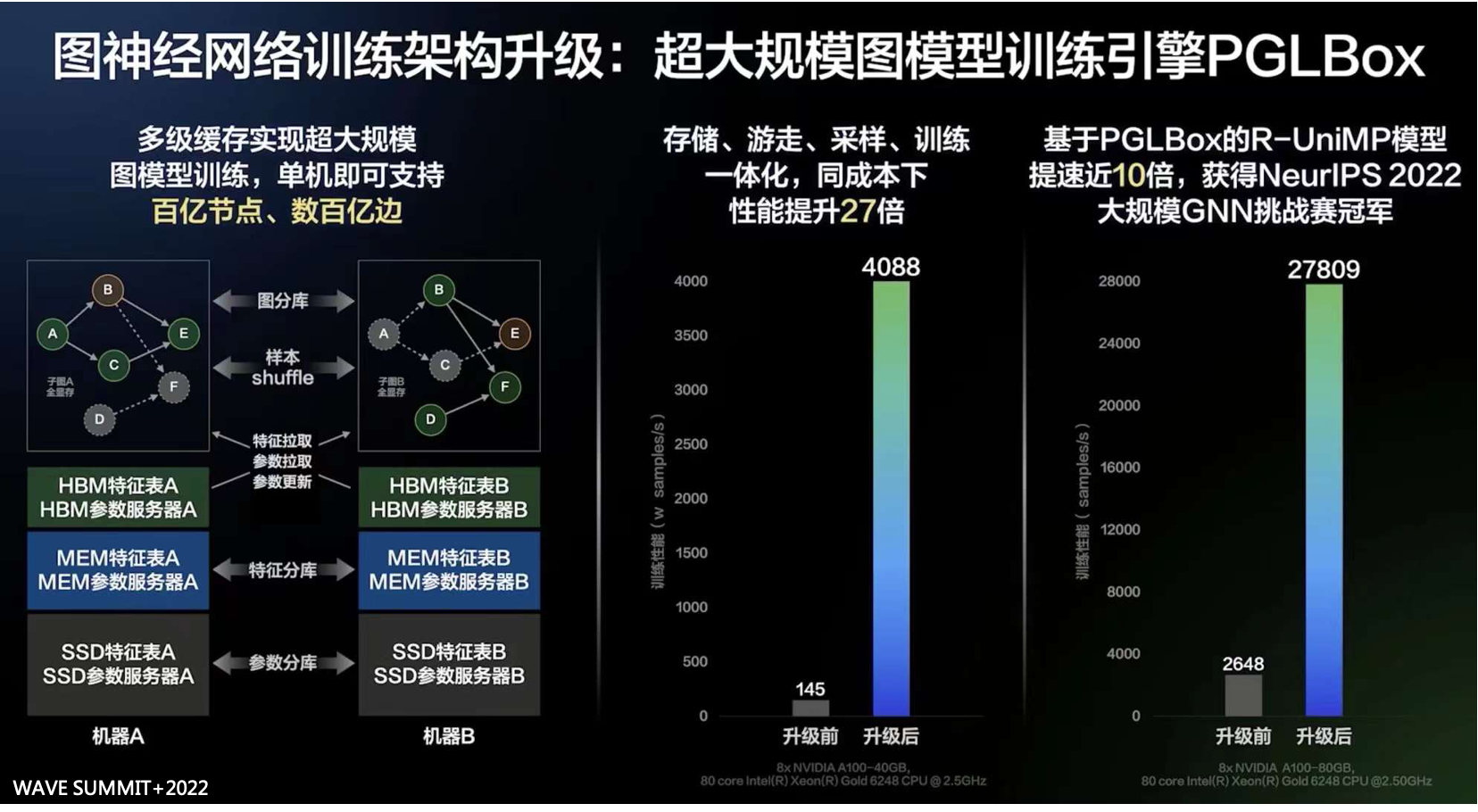
隨著圖資料規模的不斷增大,基於CPU分散式的解決方案需要大量的跨機器通訊,導致訓練速度慢且穩定性差。為了解決這個問題,PGLBox將圖儲存、遊走、取樣、訓練全流程GPU化,並實現流水線架構,極致提升異構硬體效率,大幅提升了圖學習演算法的訓練速度。同時,針對NVLink拓撲、網絡卡拓撲非全互聯問題,實現智慧化中轉通訊,進一步提升訓練能力。相比基於MPI CPU分散式的傳統方案,訓練速度提升27倍。PGLBox實現了多級儲存體系,對圖、節點屬性和圖模型進行差異化儲存,即圖結構全視訊記憶體、節點屬性二級儲存和圖模型三級儲存,將圖規模提升了一個數量級。為了平衡磁碟、記憶體、視訊記憶體之間的佔用,PGLBox實現了均衡訓練,對Pass大小平滑處理,削峰填谷,降低峰值視訊記憶體,使得在單機情況下,可支援的圖規模得到大幅提升。
02 全面升級預置的圖表示學習演算法
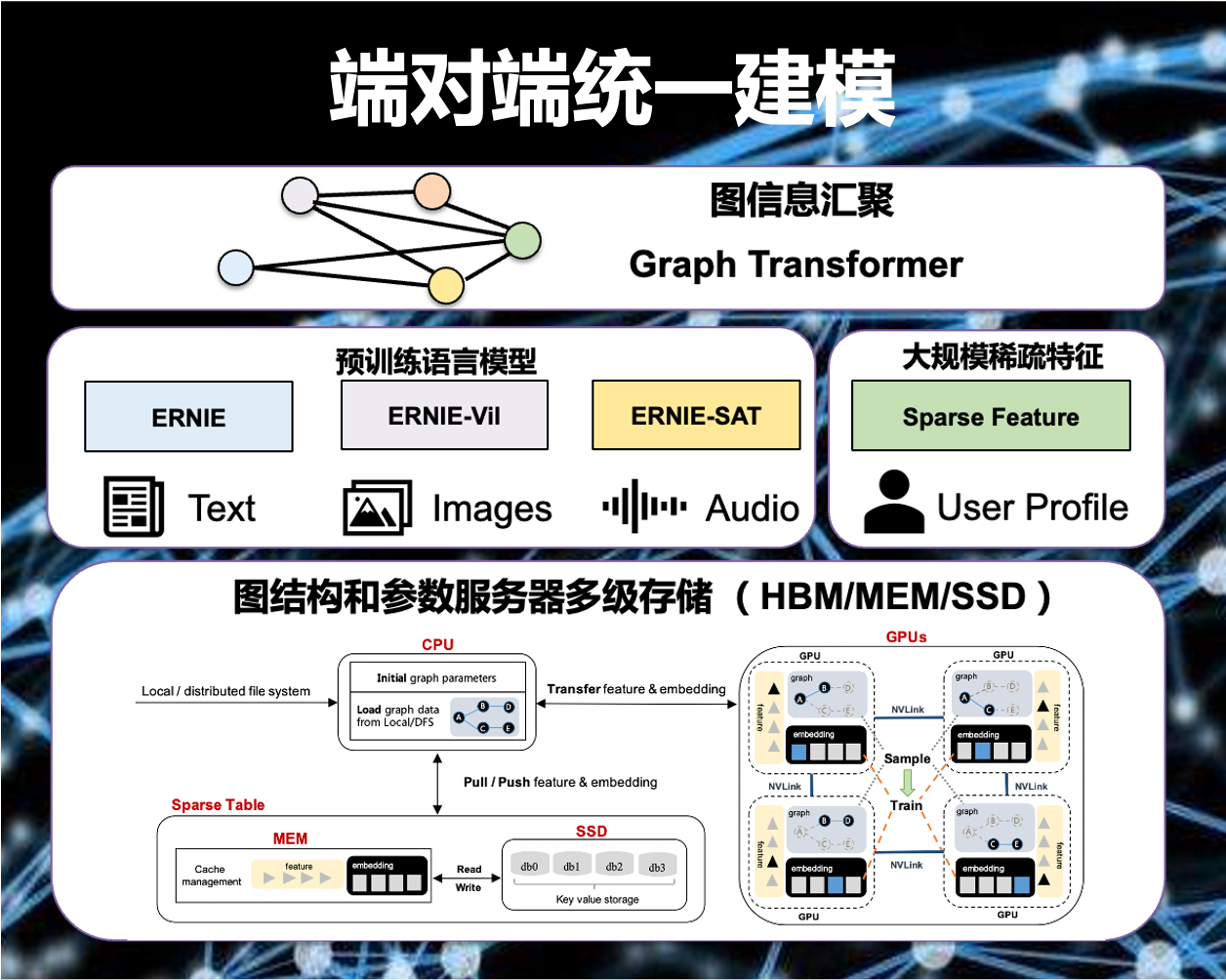
圖節點的屬性是多種多樣的,可以是文字、影象,也可以是使用者畫像、地理位置等,如何更好地建模節點特徵是圖表示學習的一個重要挑戰。隨著預訓練模型席捲NLP、CV等領域,預訓練Transformer是節點屬性建模不可或缺的一部分。而複雜結構的Transformer等預訓練模型的引入所增加的大量計算量,是以往CPU分散式圖表示學習框架不可接受的。得益於PGLBox同時兼備GPU的運算能力和大規模圖的支援,讓我們能夠同時實現大規模預訓練模型+大規模圖結構資訊+大規模離散特徵的端對端統一建模。在大規模圖資料,通過三級儲存載入之後,我們可以通過載入不同的大規模預訓練模型(例如ERNIE語言大模型、ERNIE-ViL跨模態大模型等)來建模更豐富的節點資訊。對於大規模離散特徵如使用者ID、商品ID等,我們可以同時利用到PGLBox提供的GPU引數伺服器能力來建模。最後通過圖資訊匯聚的Graph Transformer圖神經網路模組完成資訊聚合,得到圖的最終表示,並配合下游任務實現跨模態異構圖端對端優化。
基於PGLBox的GNN技術獲得了NeurIPS 2022大規模GNN挑戰賽冠軍[3],同時入選了百度Create2022十大黑科技,並在WAVE SUMMIT+2022上作為飛槳2.4版本最重要的框架新特性之一發布。憑藉其超高效能、超大規模、超強圖學習演算法、靈活易用等特性,PGLBox在百度內大量業務場景實現廣泛應用並取得顯著業務收益,如百度推薦系統、百度APP、百度搜索、百度網盤、小度平臺等。
在哪裡可以找到我們~
看到這裡相信大家已經迫不及待想要開箱試用了吧!PGLBox已全面開源,歡迎大家試用或轉發推薦,詳細程式碼庫連結請戳下方連結!
⭐️歡迎STAR收藏⭐️
http://github.com/PaddlePaddle/PGL/tree/main/apps/PGLBox
更多交流歡迎通過郵件[email protected]與我們聯絡,感謝支援!
參考文獻
[1]http://arxiv.org/abs/2112.01035
[3]http://ogb.stanford.edu/neurips2022/results/
- 基於飛槳實現的特定領域知識圖譜融合方案:ERNIE-Gram 文字匹配演算法
- 文心一言:這48小時,我被問了xxxx個問題
- 百度生成式AI產品文心一言邀請測試,五大場景、五大能力革新生產力工具
- 成為AI架構師的三大能力
- 動轉靜兩大升級!一鍵轉靜成功率領先,重點模型訓練提速18%
- 即刻報名!飛槳黑客馬拉松第四期如約而至,等你挑戰
- 文心一言,3月16日見!
- 百度集團副總裁吳甜釋出文心大模型最新升級,AI應用步入新階段
- PGLBox全面解決圖訓練速度、成本、穩定性、複雜演算法四大問題!
- C 到Python全搞定,教你如何為FastDeploy貢獻程式碼
- 飛槳框架v2.4 API新升級!全面支援稀疏計算、圖學習、語音處理等任務
- 10w 訓練標籤?成本太高!PaddleNLP情感分析賦能消費“回暖”
- 文心ERNIE 3.0 Tiny新升級!端側壓縮部署“小” “快” “靈”!
- 帶你零門檻掌握基於大模型技術的AIGC場景應用
- 從百度飛槳YOLOSeries庫看各個YOLO模型
- 30分鐘使用百度EasyDL實現健康碼/行程碼智慧識別
- 智慧健身動作識別:PP-TinyPose打造AI虛擬健身教練!
- 超大規模的產業實用語義分割資料集PSSL與預訓練模型開源啦!
- 使用百度 EasyDL 實現電動車進電梯自動預警
- 中國信通院報告:百度飛槳超越TensorFlow和PyTorch,居中國市場應用規模第一