vivo 超大規模消息中間件實踐之路
作者:vivo 互聯網存儲技術團隊-Luo Mingbo、中間件團隊- Liu Runyun
本文根據“2022 vivo開發者大會"現場演講內容整理而成。公眾號回覆【2022 VDC】獲取互聯網技術分會場議題相關資料。
本文主要介紹超大數據規模場景下分佈式消息中間件在vivo的應用實踐。
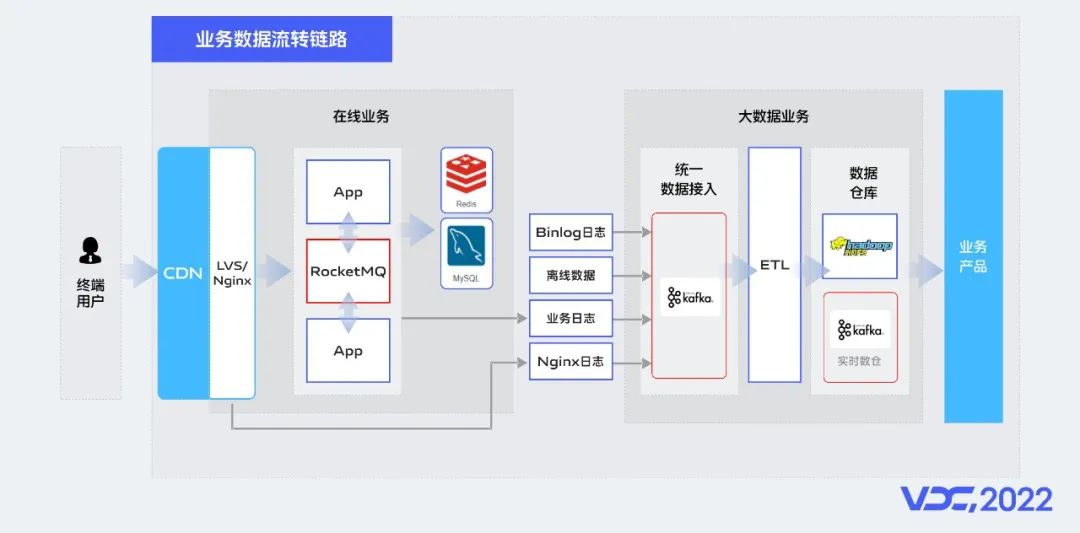
在線業務側主要從RocketMQ集羣部署架構、平台系統架構、日常運維操作平台、監控告警一體化實踐以及vivo如何通過建設AMQP消息網關的方式完成所有在線業務服務從RabbitMQ到RocketMQ的業務無感遷移,實現了在線業務消息中間件組件的統一。
大數據側主要從資源隔離、流量均衡、智能動態限流、集羣治理四個維度介紹Kafka在vivo的最佳實踐以及Kafka核心技術架構在超大數據規模場景下的缺陷以及未來對Pulsar組件的長線規劃和建設。
一、分佈式消息中間件在vivo的運營現狀
1.1 技術選型
在技術選型上,我們從吞吐量、功能特性、生態集成、開源活躍等多個維度對比了當前主流的分佈式消息中間件,最終在線業務側我們選擇基於RocketMQ構建消息平台,依託RocketMQ豐富的功能特性滿足業務間削峯、解耦、異步化的需求。
大數據側我們選擇具備高併發、高可用、低延遲、高吞吐能力的分佈式消息中間件Kafka。構建超大數據規模處理能力的統一數據接入服務和實時數倉服務。Kafka組件作為統一數據接入服務,是大數據全鏈路中的咽喉要道,是大數據生態體系建設中不可或缺的重要組件之一。
1.2 規模現狀
運營指標方面目前大數據業務側Kafka集羣接入項目數百、接入規模方面Topic數量達到數萬、集羣日均處理消息達數十萬億條、可用性保障99.99%、單機日均處理消息達數百億條。
在線業務側RocketMQ集羣接入項目數百、接入規模方面接入數千服務、集羣日均處理消息達數百億條、可用性保障100%,發送平均耗時<1ms。
二、大數據側消息中間件最佳實踐
2.1 Kafka簡介

首先我們看下Kafka的官網定義及發展歷史,Kafka是由Apache軟件基金會開源的一個流處理平台,是一種高吞吐量的分佈式發佈訂閲消息系統。具有高吞吐、低延遲、高併發、高可用、高可擴等特性。
Kafka是由LinkedIn公司在2010年開源,2011年交由Apache軟件基金會進行孵化,2012年成為Apache軟件基金會的頂級開源項目。
2.2 Kafka在超大數據規模場景下面臨的挑戰
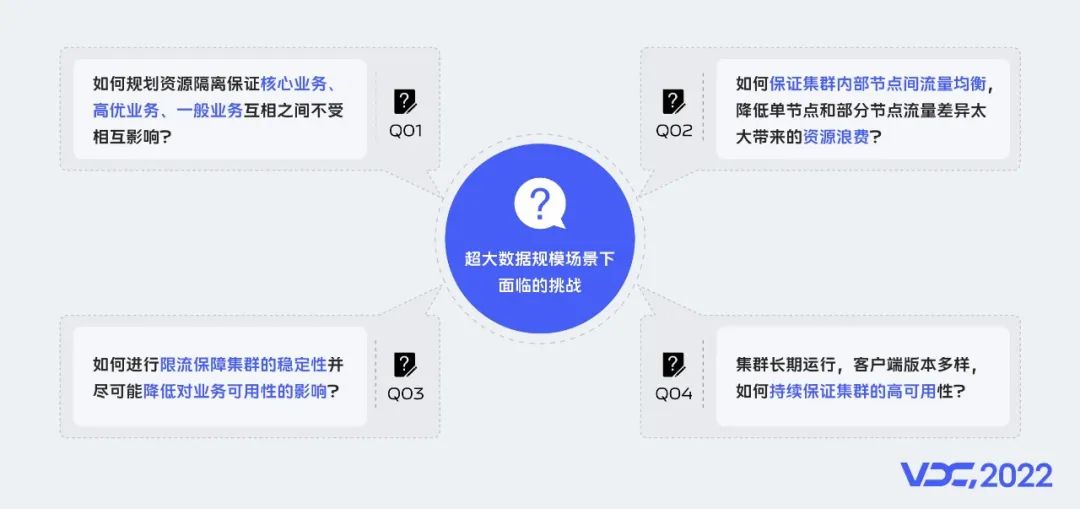
在超大數據規模場景下我們會面臨以下幾個問題?
如何規劃資源隔離保證核心業務、高優業務、一般業務之間相互不受影響?
如何保證集羣內部節點間流量均衡,降低單節點或部分節點流量差異太大帶來的資源浪費?
超大數據規模場景下如何進行限流保障集羣的穩定性並儘可能降低對業務可用性的影響?
集羣長期運行,客户端版本多樣,如何持續保障集羣的高可用性?
下面我將從資源隔離、流量均衡、智能動態限流、集羣治理四個維度和大家一起交流Kafka在vivo的最佳實踐。
2.3 資源隔離
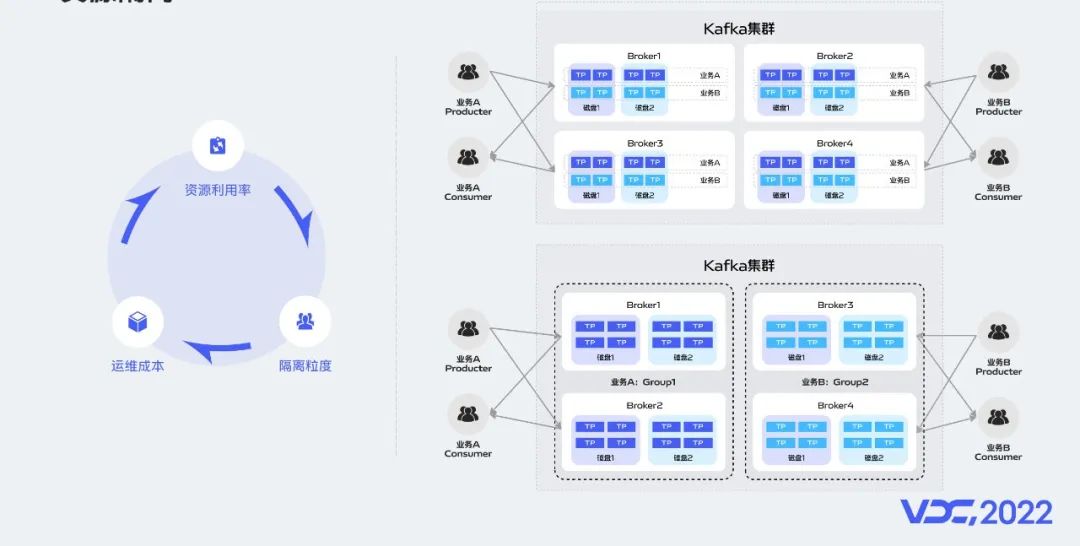
資源隔離的核心作用在於避免業務與業務之間的相互影響,但隔離粒度、資源利用率、運維成本之間如何進行權衡,是我們需要思考的重點。隔離粒度太粗會導致隔離效果不佳,隔離粒度太細會導致資源利用率較低、運維成本增加。
那vivo在Kafka集羣資源隔離上是如何平衡三者關係的呢?
首先我們根據業務屬性、業務線兩個維度進行集羣維度的隔離,例如我們在集羣劃分上分為了商業化專用集羣,監控專用集羣,日誌專用集羣等。在集羣維度做了機器資源的物理隔離。
同時我們在集羣內部引入了資源組的概念。同一個集羣內部可以包含多個資源組。每個資源組可以為多個業務提供服務。資源組與資源組之間相互獨立。
上圖中右上圖是我們沒有引入資源組概念時集羣內部不同業務Topic分區的分散情況,大家可以看到業務A和業務B的Topic分區分散到集羣內的所有broker上,若業務A的流量突增可能會造成業務B受到影響,右下圖是我們引入資源組概念後不同業務Topic分區的分散情況,可以看到不同業務的topic分區只會分配到自己業務所屬的資源組內,即使業務A的流量突增導致機器不可用也不會對業務B造成影響。
引入資源組概念後讓我們能在集羣內部實現機器資源的邏輯隔離。所以我們在資源隔離方面採用了物理隔離和邏輯隔離兩種方式相結合,實現了在超大數據規模場景下Kafka集羣的資源隔離方案。
2.4 流量均衡
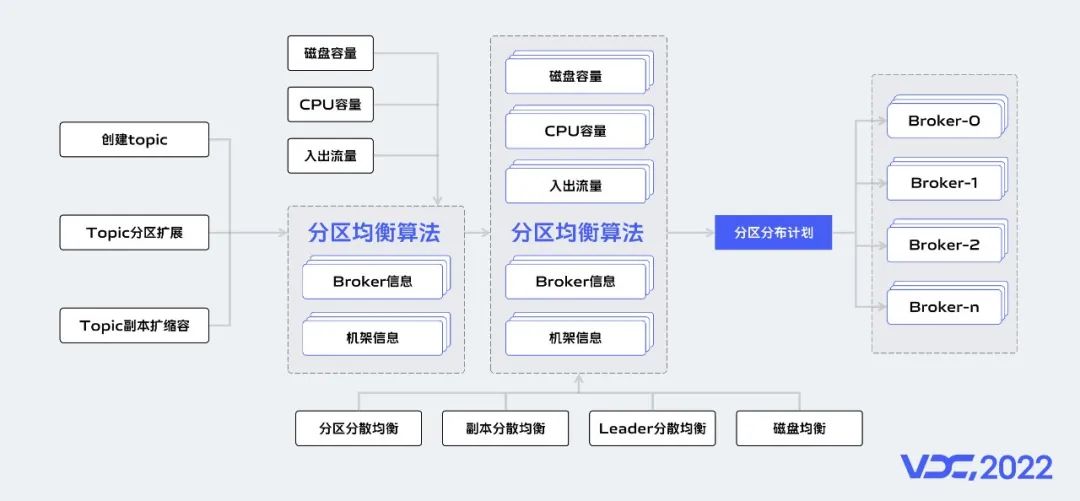
流量均衡的核心作用在於充分利用集羣內部資源,提升資源利用率。Kafka服務作為一個有狀態的服務,Kafka在技術架構設計上Topic分區與節點綁定,不支持分區同一副本數據在磁盤和節點維度分散存儲。對分區的讀寫請求都由分區Leader所在節點進行處理。所以Kafka集羣流量均衡的本質是Topic分區的分散均衡。
在流量均衡方面我們做兩期的建設,第一期我們在分區分散均衡算法上引入機器的實時出入流量、cpu負載、磁盤存儲等指標作為負載因子生成分區遷移計劃。執行分區遷移後達到流量均衡的目的。流量均衡一期功能上線後我們將資源組內節點間流量差異從數百兆/s降低到數十兆/s。隨着集羣數據規模的持續增加,我們發現數十兆/s的流量差異依然會造成資源浪費。
所以在流量均衡二期功能建設上我們增加了分區分散均衡、Leader分散均衡、副本分散均衡、磁盤均衡等Kafka元數據指標作為負載因子生成Kafka分區遷移計劃,並在分區遷移執行上增加了多種遷移提交策略。流量均衡二期功能上線後我們將資源組內節點間流量差異從數十兆/s降低到十兆以內/s。
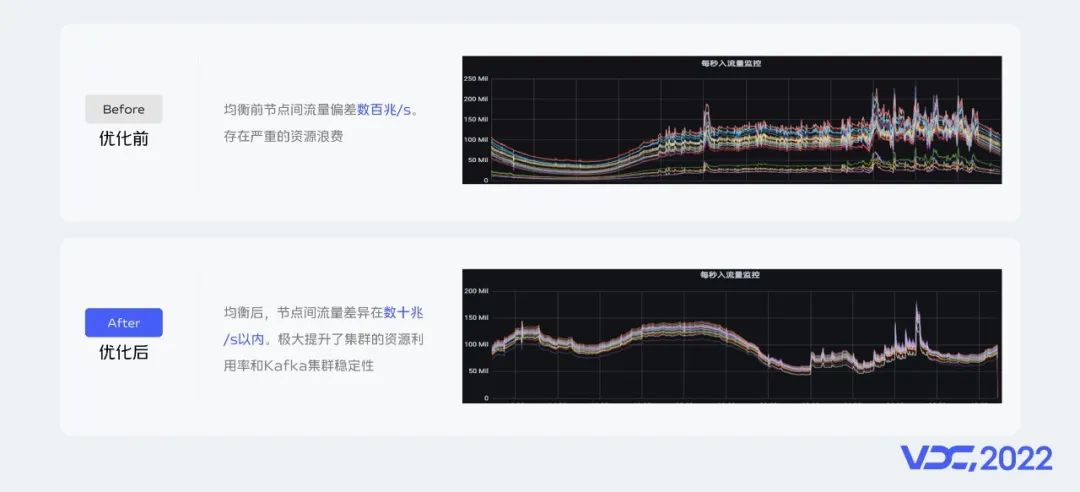
上圖是我們流量均衡一期功能上線前後資源組內節點的流量監控面板,可以看到一期功能上線前資源組內節點間的流量偏差在數百兆/s。一期功能上線後資源組內節點間流量偏差在數十兆/s以內,資源組內節點間流量偏差降低75%。極大提升了服務端的資源利用率。
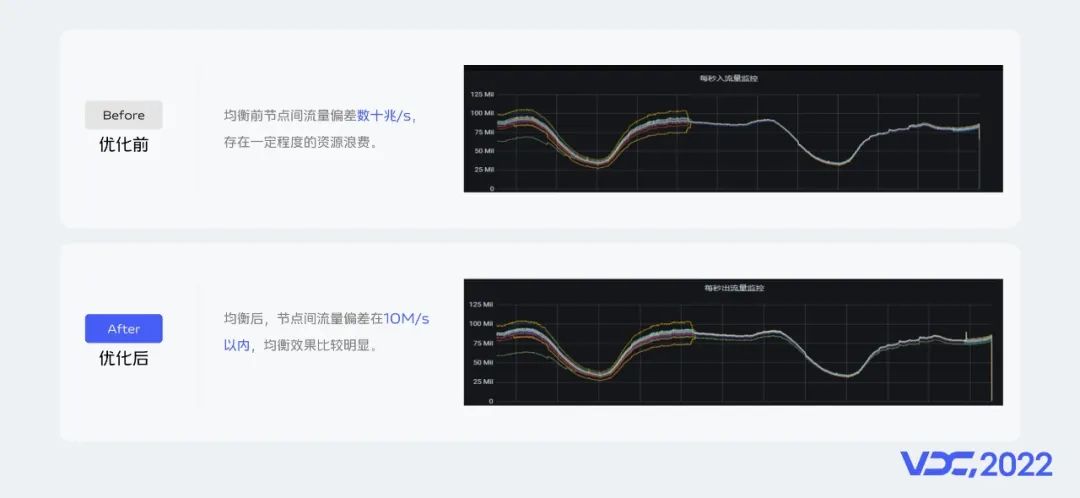
上圖是我們流量均衡二期功能上線前後資源組內節點的入出流量監控面板,可以看到節點間入出流量偏差從數十兆/s降低到十兆以內/s,資源組內節點間流量偏差降低80%。效果也是非常明顯。
2.5 智能動態限流
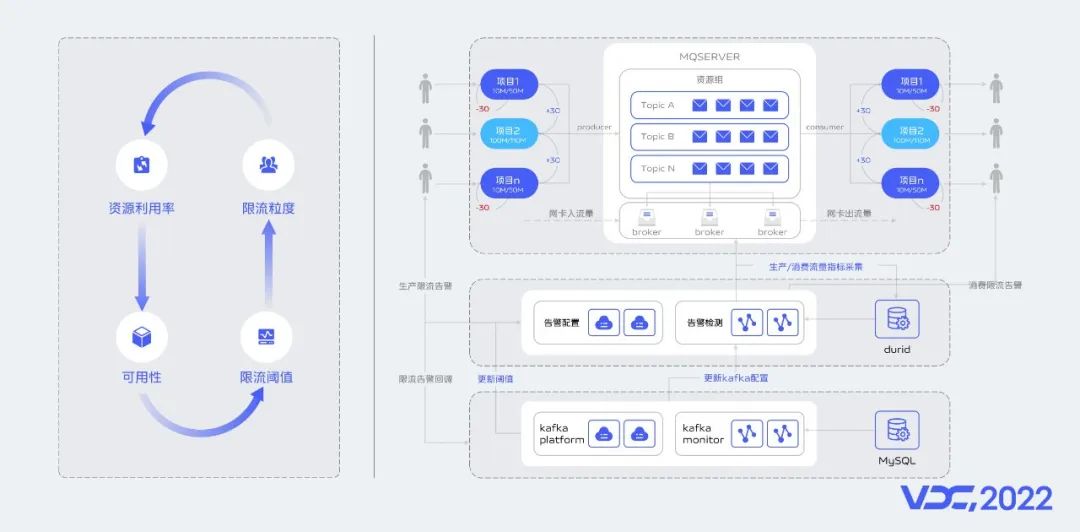
限流的本質是限制客户端的流量突增以確保服務端的可用性。避免客户端的流量突增導致服務端整體不可用。限流的粒度,限流閾值的設定,資源利用率、服務端穩定性之間應該如何做權衡呢?是我們需要思考的重點。限流粒度太粗會導致限流效果不佳,當大部分業務同時流量突增會對服務端的穩定性帶來風險。限流粒度太細服務端應對客服端流量突增能力不足,限流閾值設置太大會給服務端穩定性帶來風險,限流閾值設置太小會導致服務端資源利用率較低。
限流方面,
首先我們採用多平台聯合診斷機制根據項目實際生產數據情況判別是否需要進行流量調整,計算調整後的限流閾值。其中多平台包含(JMX統一指標採集平台,統一監控平台、統一告警平台、Kafka集羣管理平台等)。
第二、智能分析Kafka集羣服務資源負載情況,計算各資源剩餘情況。確定是否可以進行閾值調整並結合客户端實際生產數據情況計算閾值調整到多少合適。
第三、自動實時調整限流閾值。
通過以上三步實現智能動態限流方案。解決了限流粒度、限流閾值設定、資源利用率、Kafka集羣可用性四者之間的平衡關係。
實現智能動態限流後給我們帶來以下幾點明顯的收益。

大大提升Kafka集羣服務端應對客户端流量突增的能力。
利用項目錯峯的方式進一步提升Kafka集羣的資源利用率。
智能化自動調整項目限流閾值無需人工介入,大大降低Kafka集羣在超大數據規模場景下的運維成本。
動態根據服務端負載情況調整項目限流閾值,儘可能減小限流對業務可用性的影響。
2.6 集羣治理
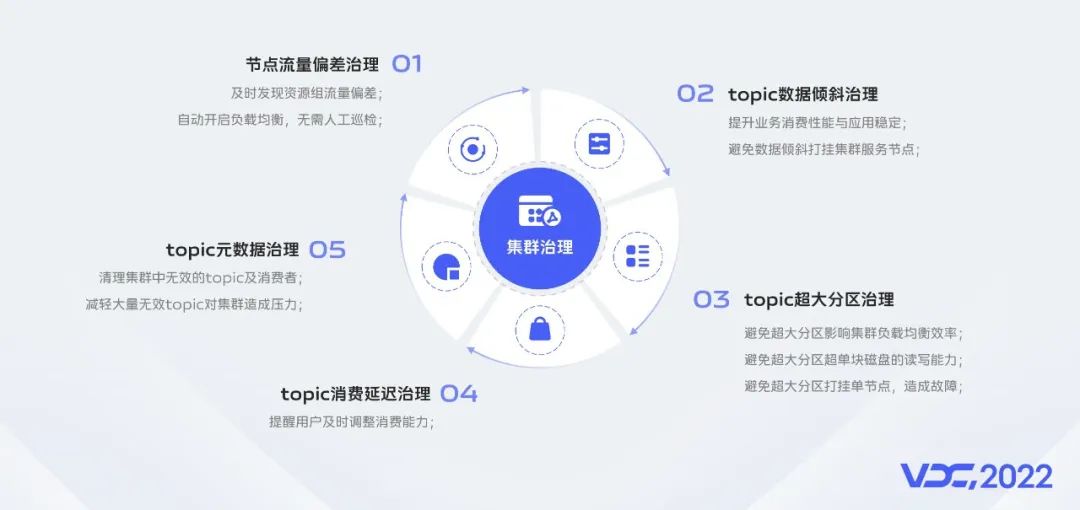
Kafka集羣元數據統一由ZooKeeper集羣管理,元數據信息永久有效永不過期,元數據的下發由Kafka Controller節點統一下發,隨着業務的不斷髮展,數據規模的不斷增加,集羣內部Topic的數量達到萬級,分區數量達到數十萬級。元數據治理能有效避免元數規模給Kafka集羣穩定性帶來的影響。隨着接入的服務、Kafka用户越來越多,正確的使用Kafka 客户端也能大大提升Kafka服務端的穩定性和資源利用率。Kafka分區與磁盤目錄綁定,創建Topic、Topic分區擴容時根據Topic流量合理設置Topic分區數能有效避免單機或單盤性能瓶頸成為集羣整體的性能瓶頸。
vivo在Kafka集羣治理方面實現了節點流量偏差治理、Topic元數據治理、Topic分區數據傾斜治理、Topic超大分區治理、Topic消費延遲治理等方案為Kafka集羣的高可用性保駕護航。
2.7 實踐經驗沉澱

vivo Kafka消息中間件團隊在三年時間內,根據實際的業務場景和生產數據規模沉澱了較多的實踐經驗。例如在高可用/高可擴方面實現了機架感知、彈性伸縮、數據壓縮等能力建設,在監控告警方面提供了用户限流告警、Topic流量突增告警、消費延遲告警、Leader實時監控告警,多平台聯合故障感知告警等能力建設。我們為Kafka集羣做了很多的擴展能力建設,那解決了Kafka集羣在超大數據規模場景下的所有問題了嗎?答案是否定的。
接下來我們一起看看Kafka集羣在超大數據規模場景下面臨的新挑戰。
2.8 Kafka在超大數據規模場景下由技術架構帶來的缺陷
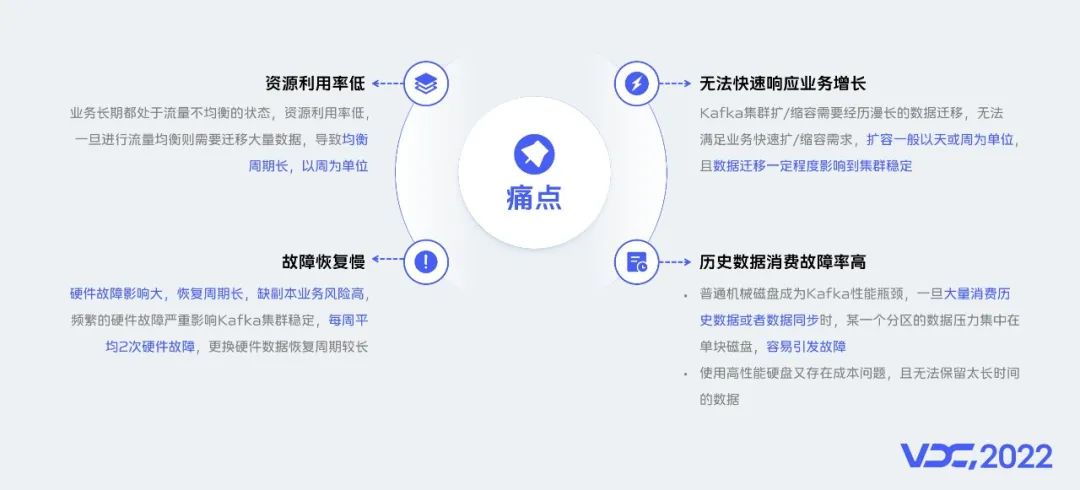
由Kafka架構設計所帶來的一些痛點無法通過擴展能力解決,並且Kafka架構設計上分區同一副本數據與磁盤強綁定不支持分散存儲、不支持存儲與運算分離、不支持冷熱數據分層存儲等設計缺陷在超大數據規模場景下顯得尤為明顯。所以在超大數據規模場景下Kafka集羣面臨了以下幾個痛點。
資源利用率低。
無法快速響應業務增長。
故障恢復時間長。
歷史數據消費故障率高(主要體現在磁盤io性能上)。
2.9 大數據側分佈式消息中間件未來規劃
基於以上Kafka在架構設計上的缺陷,vivo Kafka團隊於2021年開始對另一款開源分佈式消息中間件Pulsar進行調研。
2.9.1 Pulsar簡介

我們看下Pulsar的官網定義及發展史:Pulsar 是 Apache軟件基金會的頂級開源項目,是集消息、存儲、輕量化函數式計算為一體的下一代雲原生分佈式消息流組件,採用了計算與存儲分離的架構設計,支持多租户、持久化存儲、多機房跨區域數據複製,具有高併發、高吞吐、低延時、高可擴,高可用等特性。
Pulsar 誕生於2012 雅虎公司內部,2016年開源交由Apache軟件基金會進行孵化,2018年成為Apache軟件基金會頂級開源項目。
2.9.2 Pulsar核心優勢
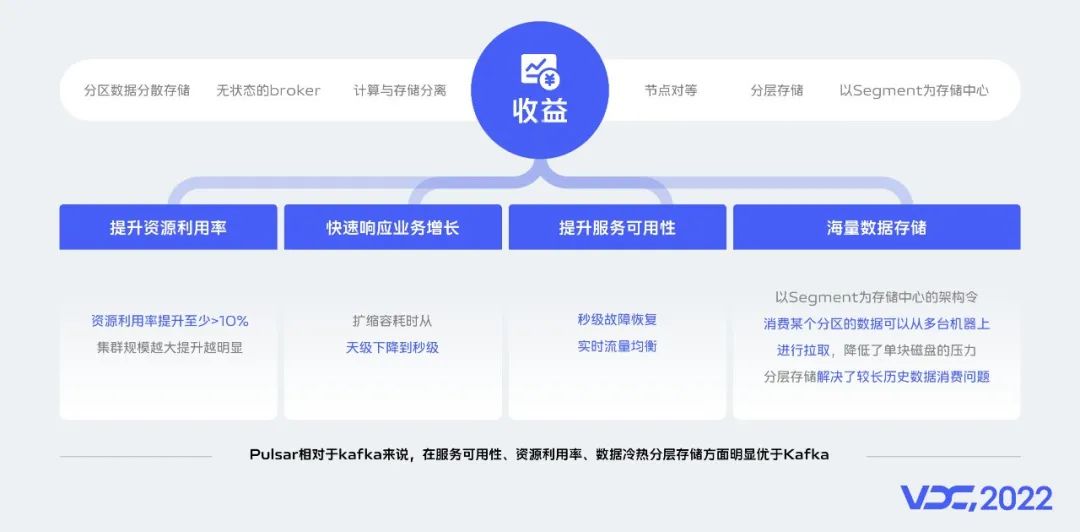
基於Pulsar支持存算分離,分區數據分散存儲、冷熱數據分層存儲、Broker無狀態等架構設計,讓Pulsar在超大數據規模場景下具備了資源利用率較高、快速響應業務增長、秒級故障恢復、實時流量均衡、支持海量數據存儲等明顯優勢。
2.9.3 Pulsar未來規劃
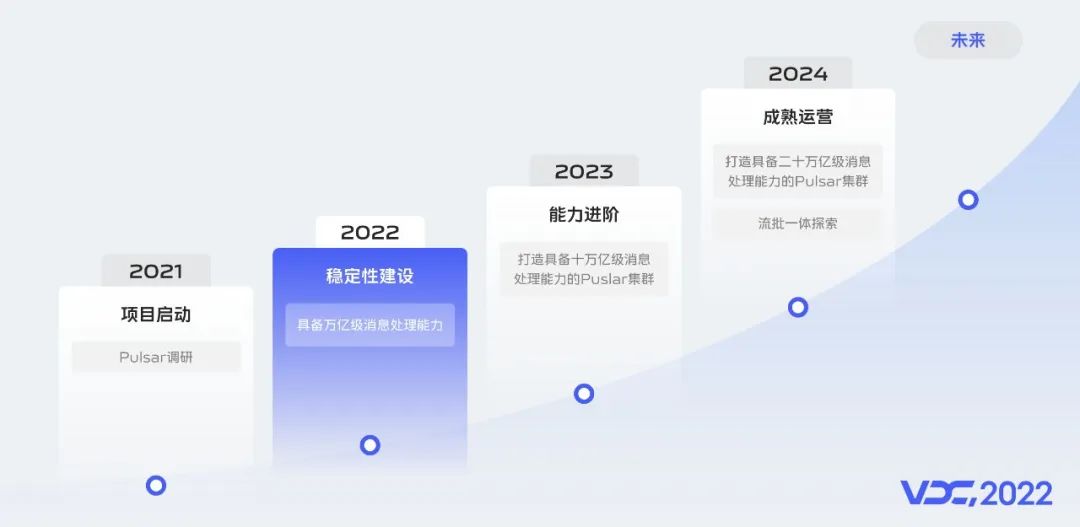
我們對Pulsar組件的規劃分為四個階段,包含項目啟動、穩定性建設、能力進階、穩定運營。
目前我們處在Pulsar組件穩定性建設階段。
2022年我們的目標是打造支持日均萬億級消息處理能力的Pulsar集羣,完成分層存儲,監控告警一體化、KoP功能平台化等擴展能力建設。
計劃2023年打造具備日均十萬億級消息處理能力的Pulsar集羣,達到行業一流水準。並完成Pulsar broker容器化部署、Pulsar生態體系建設、Pulsar Sql和Pulsar Function的應用調研等擴展能力建設。
將在2024年實現日均數十萬億級消息處理能力的Pulsar集羣,達到行業超一流的水準。
三、在線業務側消息中間件最佳實踐
3.1 RocketMQ簡介

RocketMQ是阿里巴巴於2012年開源的低延時、高併發、高可用、高可靠的分佈式消息中間件,具有海量消息堆積、高吞吐、可靠重試等特性。
RocketMQ於2012年開源,2016年進入Apache孵化,於2017年成為Apache頂級項目。
3.2 RocketMQ在vivo內部使用現狀
vivo中間件團隊在2021年引入RocketMQ並且完成了高可用和平台化建設。
當前分別在多個機房部署了多個集羣供業務使用,每日消息量數百億。
集羣分佈在多個機房,每日消息量級也不低,高可用運維保障是有難度的。
3.3 vivo基於RocketMQ的高可用保障實踐經驗
3.3.1 集羣部署架構介紹
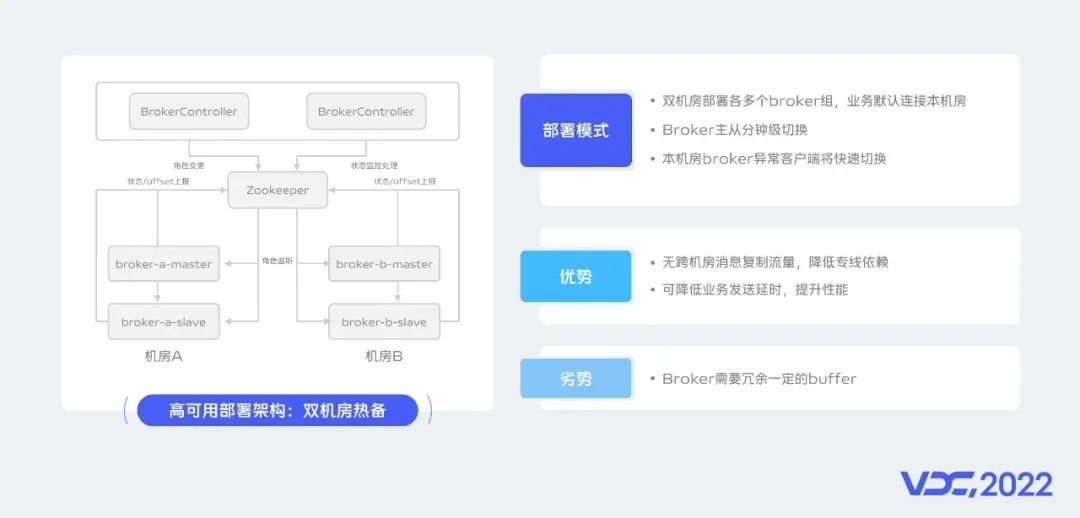
為了更好的保障集羣的高可用,我們採用了雙機房熱備的方式進行集羣搭建。
我們會在兩個機房進行Broker的部署,業務Topic會默認分佈在兩個機房,以此來保障在一個機房內的Broker節點異常時業務可以保持正常生產消費能力。
業務默認是會優先使用本機房的節點進行生產消費,只有在異常時才會自動快速完成跨機房的流量切換。
同時我們構建了一個BrokerController模塊用於實現Broker節點的主從切換,以此保障集羣容量的快速恢復。
雙機房熱備模式有哪些優勢呢?
第一,消息無需跨機房複製,降低對機房專線的依賴;
第二,可以降低業務發送消息的延時,也可以提升業務的處理性能;
雙機房熱備模式的劣勢是每個機房的節點都需要宂餘一定的buffer來支撐其它機房的節點異常時自動轉移過來的業務流量。
3.3.2 平台系統架構介紹
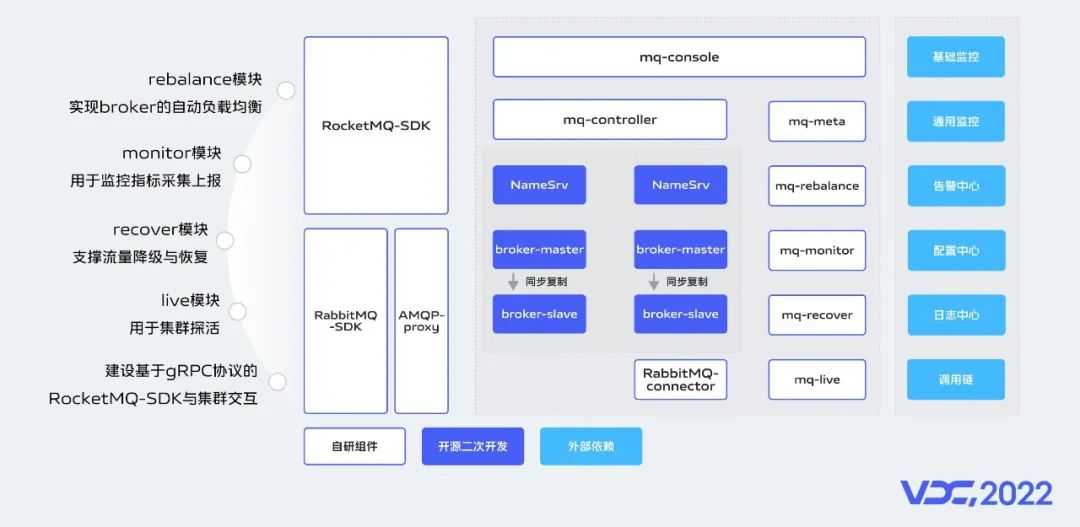
集羣雙機房熱備部署模式是消息平台的高可用基石,在此之外我們還建設了多個平台模塊來保障平台的高可靠。
如上圖所示,
mq-rebalance模塊用於支撐集羣流量的自動負載均衡;
mq-monitor模塊進行監控指標的採集並且與vivo內部的監控系統打通;
mq-recover模塊主要用於業務流量的降級和恢復處理;
mq-live模塊用於集羣的探活。
另外我們還基於社區的connector組件建設了RabbitMQ-connector,實現了全球消息路由能力。
後續我們計劃建設基於gRPC協議建設通用的消息網關實現與集羣的交互,以此屏蔽不同的消息中間件選型。
3.3.3 運維能力平台化提升運維效率
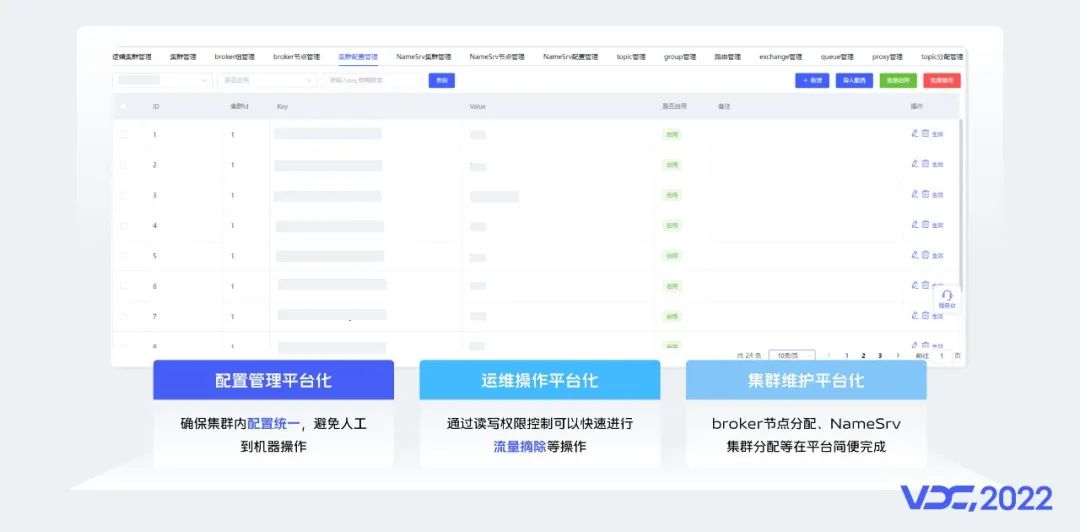
主要有三點實踐:
第一,RocketMQ集羣配置平台化管理。RocketMQ集羣含有較多的配置項,默認是通過節點文件管理的,在大規模集羣運維過程中會存在維護困難的問題。
通過平台化管理可以確保集羣內配置統一,節點在啟動時從平台中讀取到所有的配置,避免在集羣部署時需要登錄到機器進行配置維護,並且我們支持了集羣配置的動態生效。
第二,運維操作平台化,例如Broker節點的流量摘除與掛載、Topic一鍵擴縮容等直接通過平台支撐,實現便捷運維。
第三,集羣維護平台化,我們將集羣與Broker節點的關係維護在平台中,並且在首次部署時分配Broker節點所在集羣,這樣在平台上就有清晰的集羣信息,便於我們維護管理多套集羣。
3.3.4 平台監控告警能力建設
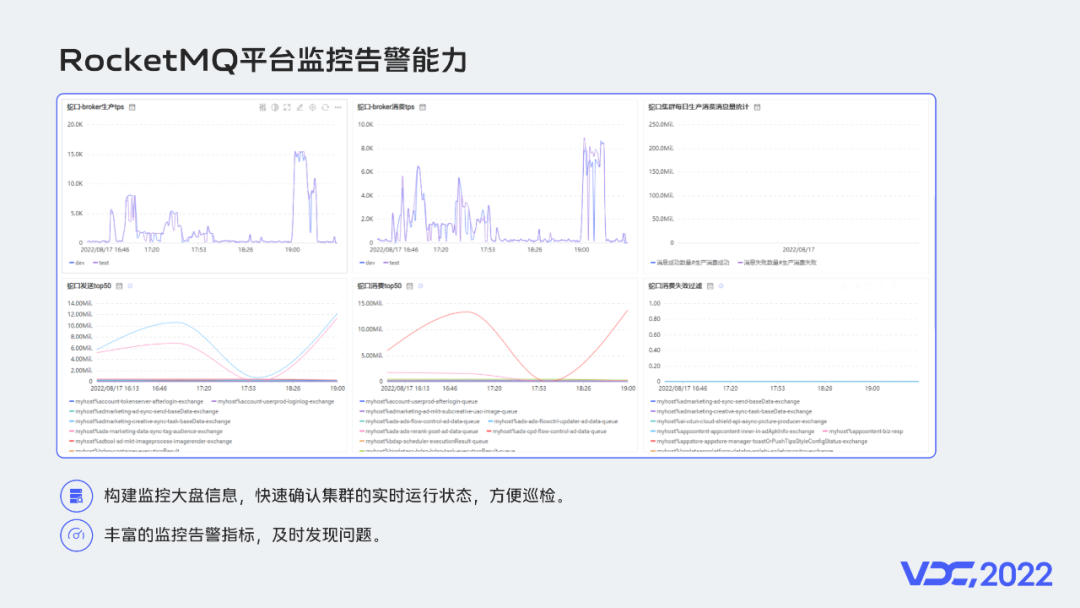
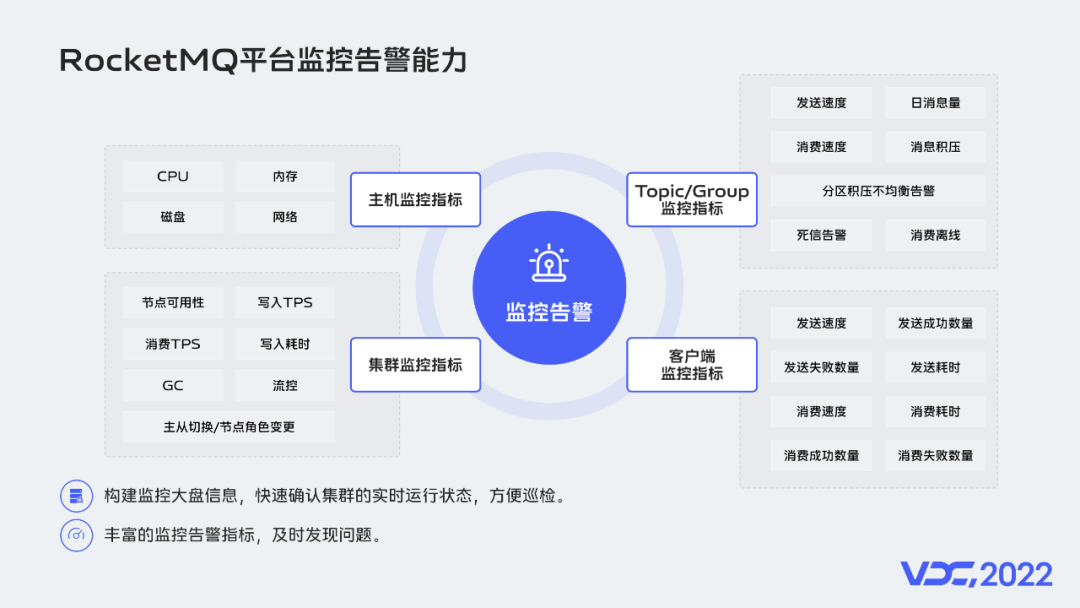
一方面,我們為每個集羣都建設了如上圖所示的監控大盤。
在監控大盤中有每個集羣的生產消費流量、業務生產消費統計、發送耗時等信息,支撐我們快速觀察集羣的運行狀態,方便日常巡檢。
消息中間件作為在線業務請求處理鏈路中的關鍵環節,高可用尤為關鍵。監控大盤中的發送耗時信息是我們認為觀察集羣是否穩定運行的最關鍵的指標。
另一方面,我們對集羣構建了豐富的監控告警能力。
如上圖所示,我們分別對主機維度、集羣維度、Topic/Group維度、客户端維度都做了監控指標埋點上報。
通過豐富的監控告警,我們可以及時發現問題並快速介入處理問題,詳細的監控告警也可以幫助我們快速確認問題根源。
3.4 業務從RabbitMQ無感遷移到RocketMQ實戰經驗
3.4.1 使用RocketMQ替換RabbitMQ根因分析
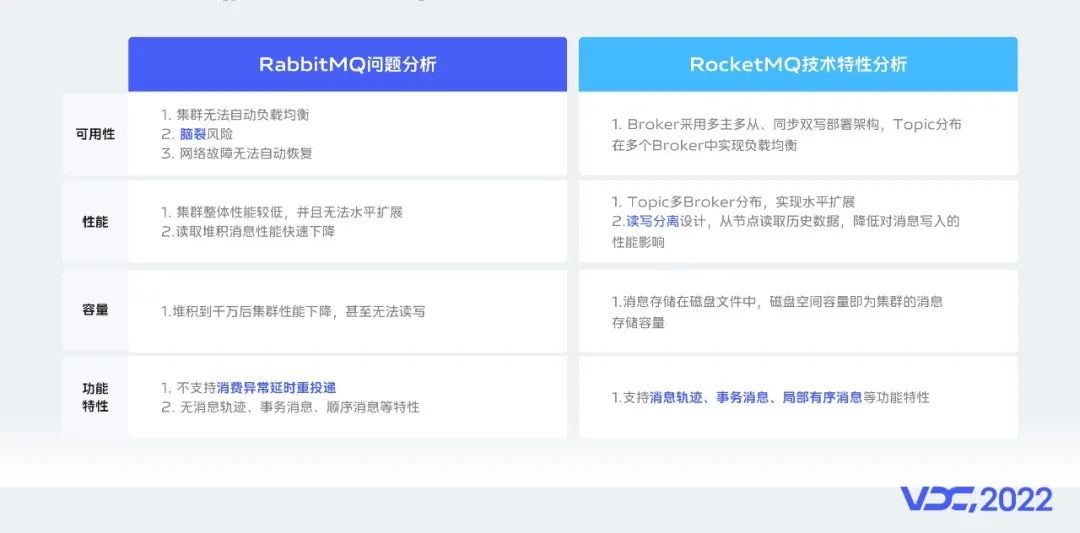
分別從可用性保障、性能、容量、功能特性對比RabbitMQ和RocketMQ。
可用性保障方面,RabbitMQ集羣無負載均衡能力,隊列流量實際由集羣內某個節點承載,存在瓶頸。其次RabbitMQ存在腦裂問題,從我們的運維經驗看如果出現網絡故障集羣通常無法自動恢復,並且可能丟失少量數據。
性能方面,RabbitMQ集羣整體性能較低,並且不支持水平擴展。
容量方面,從我們的運維經驗看,當消息堆積到千萬後,RabbitMQ性能就會有所下降。在大量消息堆積開始消費後,因為RabbitMQ的背壓流控機制,最終可能會因為集羣負載過大導致發送限流甚至發送阻塞。
功能特性方面,RabbitMQ不支持消費異常延時重投遞功能,也不支持消息軌跡、事務消息、順序消息等特性。
而RocketMQ在可用性保障、性能、容量、功能特性方面相對於RabbitMQ都是更優的。
可用性保障方面,RocketMQ採用多主多從的鬆耦合架構部署,主從間通過同步雙寫保障消息的可靠性和一致性。
性能方面,Topic可以分佈在多個Broker中,實現水平擴容,並且RocketMQ支持從從節點拉取消息,讀寫分離的設計很好的支持了業務讀取冷數據的訴求。
容量方面,RocketMQ使用磁盤存儲,磁盤容量就是消息的存儲容量,利用從從節點拉取冷數據特性,海量消息堆積對消息寫入性能基本無影響。
功能特性方面,RocketMQ支持了消息軌跡、事務消息、順序消息等特性。
綜合分析,RocketMQ可以更好的支撐互聯網業務的訴求。
3.4.2 AMQP消息網關架構支撐實現無感遷移
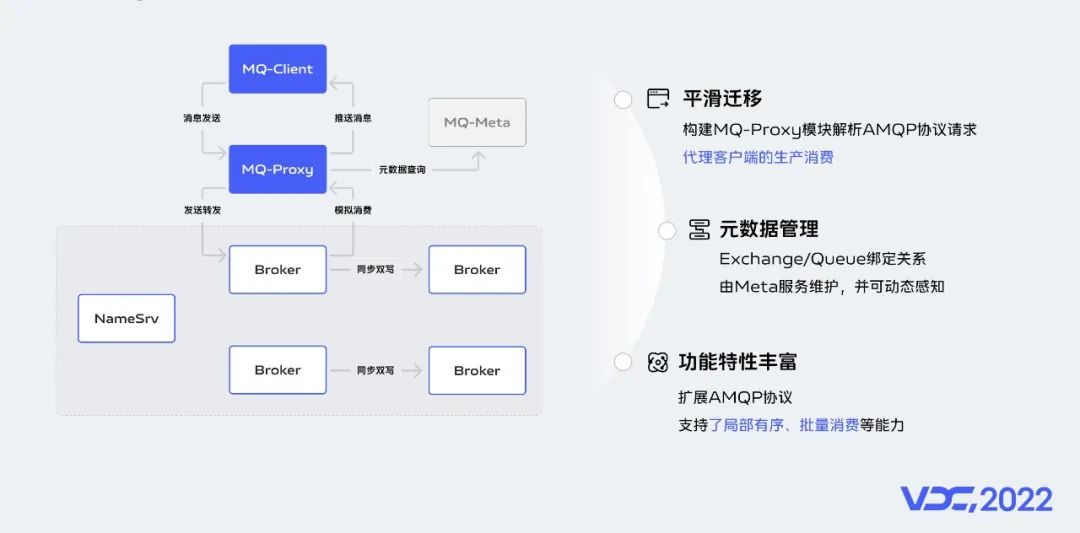
由於當前RabbitMQ已經有數千個服務接入,為了讓業務不修改代碼即可遷移到RocketMQ,我們建設了一個AMQP消息網關來實現MQ協議的解析和流量轉發。
如上圖所示,MQ-Proxy模塊用於解析AMQP協議,代理客户端的生產消費請求。
RabbitMQ的元數據信息存在在集羣中,並且與RocketMQ元數據概念存在差異,為此我們建設了MQ-Meta模塊用於維護Exchange/Queue極其綁定關係等元數據信息,並且Proxy模塊可以動態感知元數據變更。
另外,為了更好的支撐業務訴求,我們對AMQP協議進行了擴展,支持了局部有序和批量消費能力。
3.4.3 RabbitMQ和RocketMQ元數據概念映射

為了更好的整合RabbitMQ和RocketMQ,我們對它們的元數據進行了一一對應。
其中將RabbitMQ的Exchange映射為RocketMQ的Topic,Queue映射為Group,RoutingKey映射為消息頭的一個參數,VirtualHost映射為Namespace。
為什麼將RoutingKey映射為消息頭的一個參數而不是Tag呢?這是因為RabbitMQ的RoutingKey是有模糊匹配過濾能力的,而RocketMQ的Tag是不支持模糊匹配的。
另外我們還通過擴展使得RocketMQ也支持了RoutingKey過濾。
在經過多輪優化後,在1KB消息體場景下,一台8C16G的機器在單發送下可支撐超過九萬的TPS,單推送可以支撐超過六萬TPS,性能上很好的滿足了當前業務的訴求。
3.5 在線業務消息中間件的未來規劃

主要有兩部分:
一方面,我們希望可以調研升級到RocketMQ5.0版本架構,RocketMQ5.0的存算分離架構可以更好的解決我們當前遇到的存儲瓶頸問題,Pop消費可以幫助我們實現更好的消費負載均衡。
我們還希望可以基於gRPC協議建設統一的消息網關能力。
另一方面,我們希望可以探索消息中間件容器化部署,提供消息中間件的快速彈性擴縮容能力,更好的支持業務需求。
四、總結
回顧vivo消息中間件演進歷史,我們完成了在線業務消息中間件從RabbitMQ遷移到RocketMQ,大數據消息中間件正在從kafka演進為使用pulsar支撐。
我們理解消息中間件將繼續朝着雲原生演進,滿足業務快速增長的訴求,充分利用雲的優勢為業務提供極致的體驗。
END
猜你喜歡
本文分享自微信公眾號 - vivo互聯網技術(vivoVMIC)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- 循序漸進講解負載均衡vivoGateway(VGW)
- Tars-Java網絡編程源碼分析
- vivo 短視頻用户訪問體驗優化實踐
- 100 行 shell 寫個 Docker
- vivo全球商城:庫存系統架構設計與實踐
- 非侵入式入侵 —— Web緩存污染與請求走私
- 解密遊戲推薦系統的建設之路
- 解密遊戲推薦系統的建設之路
- 用户行為分析模型實踐(三)——H5通用分析模型
- vivo版本發佈平台:帶寬智能調控優化實踐-平台產品系列03
- 廣告流量反作弊風控中的模型應用
- vivo官網App模塊化開發方案-ModularDevTool
- OKR之劍·實戰篇05:OKR致勝法寶-氛圍&業績雙輪驅動(上)
- vivo 自研Jenkins資源調度系統設計與實踐
- vivo官網App模塊化開發方案-ModularDevTool
- Dubbo 中 Zookeeper 註冊中心原理分析
- 用户行為分析模型實踐(三)——H5通用分析模型
- Node.js 應用全鏈路追蹤技術——全鏈路信息存儲
- 從0到1設計通用數據大屏搭建平台
- vivo 超大規模消息中間件實踐之路