OneFlow源碼解析:Eager模式下的SBP Signature推導

作者|鄭建華
更新|趙露陽
OneFlow 的 Global Tensor 有兩個必要屬性:
-
Placement:決定了 tensor 數據分佈在哪些設備上。
-
SBP:決定了 tensor 數據在這些設備上的分佈方式。例如:
-
-
split:將切分後的不同部分放到不同設備;同時指定切分的 axis。
-
broadcast:將數據複製到各個設備。
-
如果參與運算的 tensor 的 SBP 不一樣,結果 tensor 的 SBP 是什麼呢?例如下面的代碼:
# export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=0 LOCAL_RANK=0# export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=1 LOCAL_RANK=1import oneflow as flow
P0 = flow.placement("cpu", ranks=[0, 1])
t1 = flow.Tensor([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]], placement=P0, sbp=flow.sbp.split(0))# t1 = flow.Tensor([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]], placement=P0, sbp=flow.sbp.broadcast)t2 = flow.Tensor([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]], placement=P0, sbp=flow.sbp.split(1))t3 = t1 + t2# oneflow.placement(type="cpu", ranks=[0, 1])print(t3.placement)# (oneflow.sbp.split(dim=0),)print(t3.sbp)
t1和t2是分佈在相同設備上的兩個 tensor。t1.sbp是S(0),在行上切分;t2.sbp是S(1),在列上切分。
計算結果t3的 SBP 不需要用户手動指定,系統可以自動推導出t3.sbp為S(0)。這個過程中的一個核心步驟,就是 SBP Signature 的推導。
1
SBP相關概念
1.1 SBP
SBP是OneFlow中獨有的概念,其描述了張量邏輯上的數據與張量在真實物理設備集羣上存放的數據之間的一種映射關係。以下內容參考SBP官方文檔( http://docs.oneflow.org/master/parallelism/02_sbp.html#sbp ):
詳細而言:
-
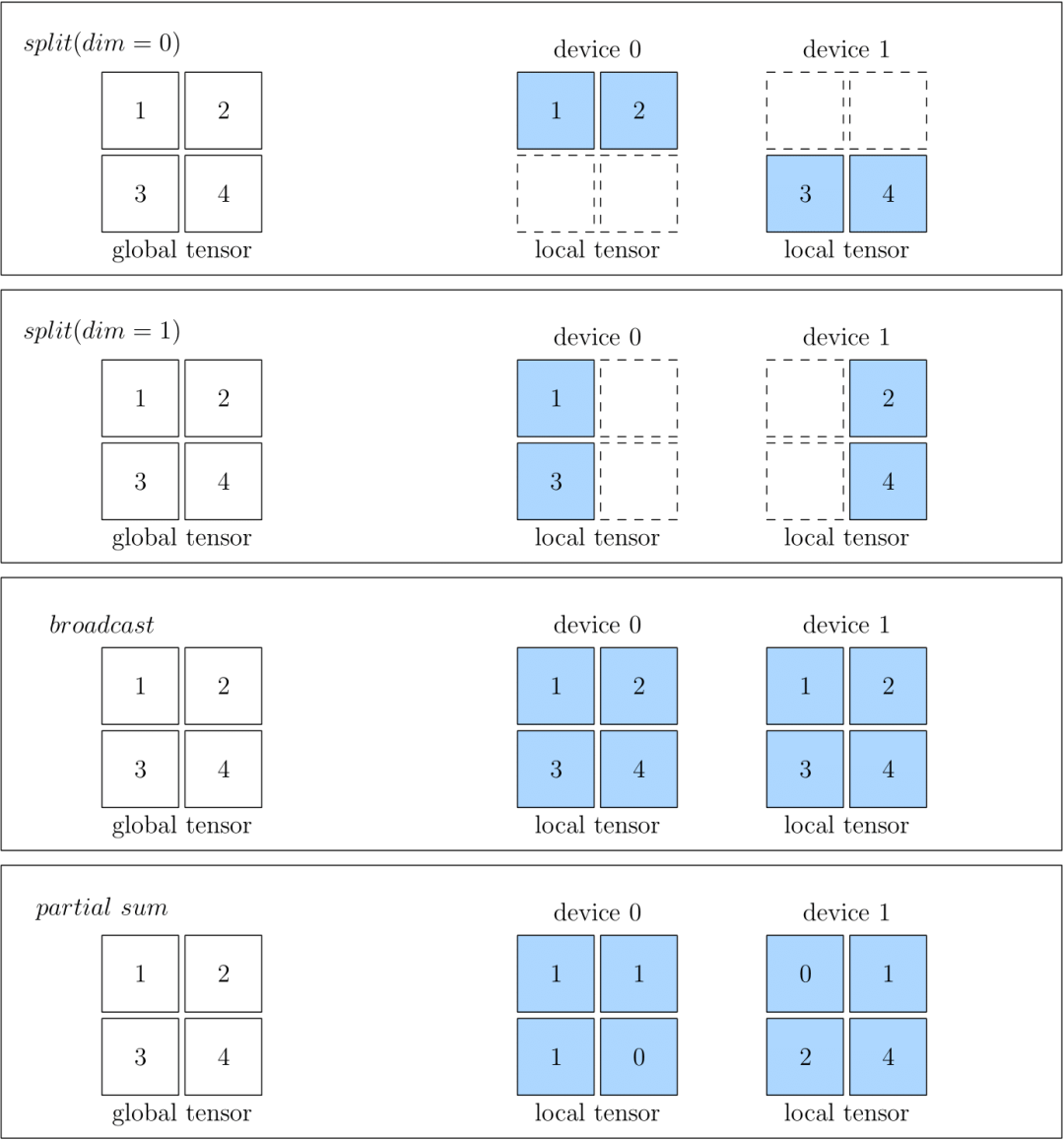
split表示物理設備上的 Tensor,是將全局視角的 Tensor 切分得到的。切分時,需要指定切分的維度。物理設備上的 Tensor ,經過拼接,可以還原得到全局視角的 Tensor 。
-
broadcast表示全局視角下的 Tensor,會複製並廣播到所有的物理設備上。
-
partial 表示全局視角下的 Tensor 與物理設備上的 Tensor 的 形狀相同,但是物理設備上的值,只是全局視角下 Tensor 的 一部分。以 partial sum 為例,如果我們將集羣中所有設備的張量按位置相加,那麼就可以還原得到全局視角的 Tensor。除了 sum 外,min、max 等操作也適用於 partial。
下圖中分別展示了 SBP 的情況,分別是 split(0)、split(1)、broadcast 和 partial sum。
1.2 SBP Signature
SBP Signature即SBP簽名,是OneFlow中獨創且很重要的概念。本節以下文字摘自SBP Signature的官方文檔:
-
對於一個孤立的 Tensor,我們可以隨意設置它的 SBP 屬性。但是,對於一個有輸入、輸出數據的算子,我們卻不可以隨意設置它的輸入、輸出的 SBP 屬性。這是因為隨意設置一個算子輸入輸出的 SBP 屬性,可能不符合全局視角下算子的運算法則。
-
對於某個算子,其輸入輸出的一個特定的、合法的 SBP 屬性組合,稱為這個算子的一個 SBP Signature。
-
算子作者根據算子的運算法則,在開發算子時,就已經羅列並預設好該算子所有可能的 SBP Signature。
-
某一層算子只要有輸入的 SBP 屬性,OneFlow 就可以根據 SBP Signature 推導出該層算子輸出的 SBP 屬性。
-
所謂的 SBP Signature 自動推導,指的是:在給定所有算子的所有合法的 SBP Signature 的前提下,OneFlow 有一套算法,會基於傳輸代價為每種合法的 SBP Signature 進行打分,並選擇傳輸代價最小的那個 SBP Signature。這樣使得系統的吞吐效率最高。
-
如果 OneFlow 自動選擇的 SBP Signature,上一層算子的輸出與下一層算子的輸入的 SBP 屬性不匹配時,那怎麼辦呢?OneFlow 會檢測到這種不一致,並且在上游的輸出和下游的輸入間插入一類算子,做相關的轉換工作。這類自動加入做轉換的算子,就稱為 Boxing 算子。
總結一下,SBP Signature 的要點如下:
-
每個算子都需要設置相應的SBP簽名,用於描述數據(Tensor)的分佈方式。
-
SBP簽名包括算子的全部輸入、輸出的SBP。缺少(部分)輸入,或(部分)輸出,不能構成簽名。
-
-
所以SbpSignature.bn_in_op2sbp_parallel 是一個map結構,key就是各個input和output的標識。
-
-
輸入與輸出的SBP簽名組合,在算子的運算法則下必須是合法的,算子的作者需要列出合法SBP簽名的候選集。
-
如果輸入數據(input tensor)的SBP與該算子合法的SBP簽名不一致,則為了得到該算子正確計算所需要的數據(tensor),OneFlow 會在上游的輸出和下游的輸入間插入boxing算子(可能包含nccl等集合通信操作),做自動轉換工作,這類自動轉換的過程,就稱為 Boxing。例如,eager global模式下的interpreter在 GetBoxingOutput 方法中完成Boxing過程。
1.3 NdSbp 及 NdSbpSignature
在上面1.1小節中,我們瞭解到SBP用於描述一個邏輯張量(Tensor),與其對應物理設備上的映射關係,那OneFlow中的2D甚至ND SBP又是什麼意思呢?
簡單理解就是,普通的SBP(1D/1維 SBP)只能比較粗粒度地對張量進行切分,譬如split(0)就表示,沿着張量第0維進行切分,如果在此基礎上,想進行更細粒度的切分,譬如繼續沿着第1維再“切一刀”,那麼普通的1D SBP就無法做到了,於是需要2D或者ND SBP。
以下文字主要參考官方文檔 2D SBP。
我們可以通過ranks=[0, 1, 2, 3]指定tensor的數據分佈在這4個設備上。這4個設備組成了一個一維的設備矩陣。對應的 SBP 如split(1),是單個值,即 1D SBP。
Tensor 數據的分佈也可以指定為ranks=[[0, 1], [2, 3]]。四個計算設備被劃分為2x2的設備矩陣。這時,SBP 也必須與之對應,是一個長度為 2 的數組。對應的 NdSbp.sbp_parallel 的類型就是數組。
例如sbp = (broadcast, split(0))。這個 2D SBP 的含義是:
-
在 ranks 的第一維度執行廣播,將數據分別拷貝到group 0(rank [0, 1])和group 1(rank [2, 3])。
-
在 ranks 的第二維度分別執行split(0)。
-
-
例如,對於group 0,將上一步中分配給它的數據按行拆分成(1,2)和(3,4)分別給device 0和device 1。
-
示意圖如下:
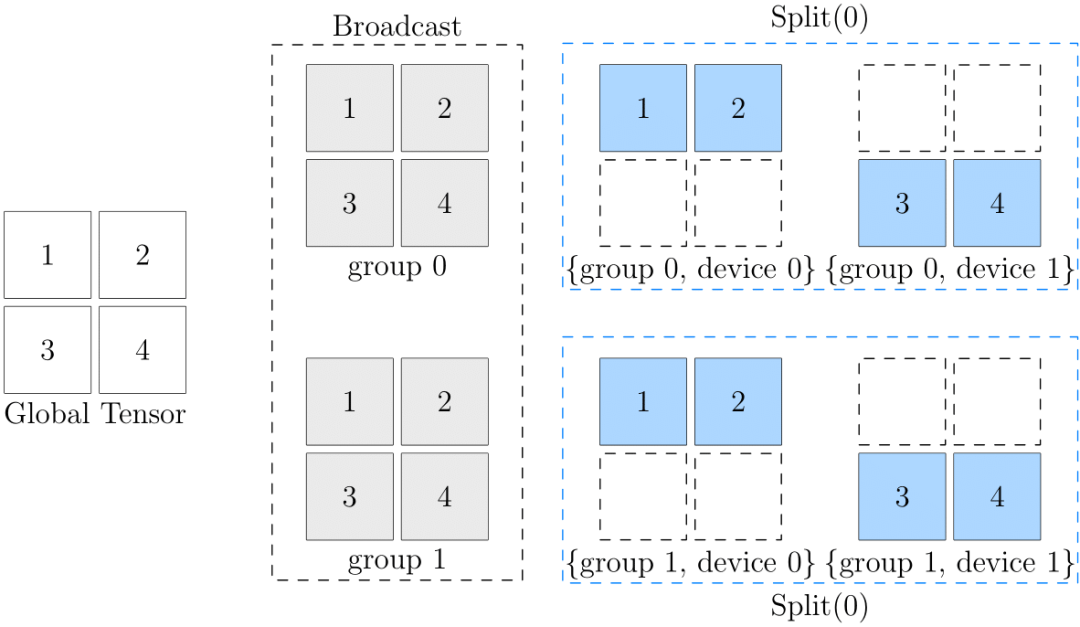
如果 Tensor 的數據分佈形式是多維的,如[[0, 1], [2, 3]],算子對應的 SBP Signature 也是多維的,所以 NdSbpSignature 中,每個 input/output 對應的 sbp_parallel 都是數組。
2
placement.hierarchy
placement 對應的 C++ 類型是 ParallelDesc 。構造 placement 的 ranks 可以是多維數組,表示設備的多維分佈矩陣。
placement.hierarchy表示了placement上ranks的層次信息。簡單理解,hierarchy就是用於描述ranks分佈的形狀(類似於shape可用於描述tensor數據分佈的形狀),hierarchy存儲了 ranks 在各個維度的 size 信息。
-
hierarchy 數組的長度是 ranks 的維數。
-
hierarchy 數組的元素值,是 ranks 對應維度的 size。
-
構造 hierarchy 的 C++ 代碼可參考 GetRanksShape 。
運行下面的代碼可以觀察 hierarchy 的值。
import oneflow as flow
placements = [ flow.placement("cpu", ranks=[ 0, 1, 2, 3, 4, 5]), flow.placement("cpu", ranks=[[0, 1, 2], [3, 4, 5]]), ] for p in placements: print(p.hierarchy) # outputs: # [6] # [2, 3]
3
tensor add 是哪個算子?
為了提高性能,從 v0.8.0 開始,Tensor 的接口基本都通過 C API 提供給Python。
PyTensorObject_methods 中定義了很多 Tensor 方法。不過,add 方法是通過 Python C API 的 number protocol 實現的 ,指定 PyTensorObject_nb_add 實現加法操作 ,實際由functional::add實現 。
functional::add的定義在functional_api.yaml.pybind.cpp中,這是一個在構建期自動生成的文件。順着這個找,容易發現示例代碼對應的是 AddFunctor 。 Op的名字是"add_n" ,自動生成的文件op_generated.cpp中定義了add_n對應的Op是AddNOp。 add_n_op.cpp 中定義的 AddNOp 的幾個方法,會在 SBP Signature 推導過程中用到。
4
一維 SBP 的推導過程
SBP Signature 推導相關的類關係如下:
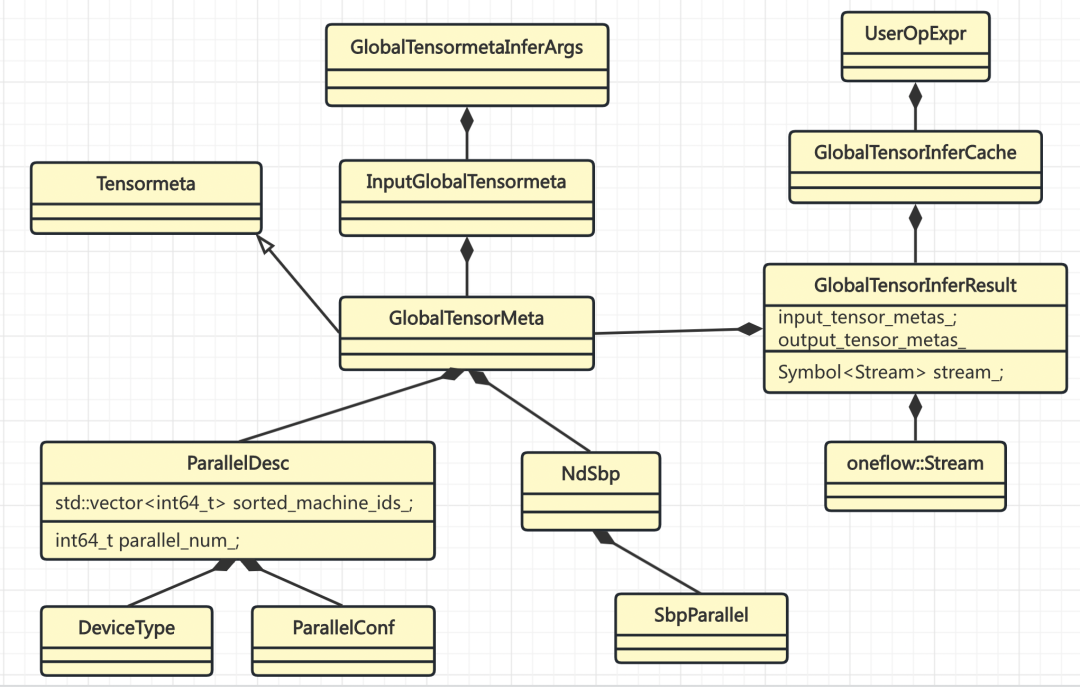
示例代碼中的 tensor add 操作(t1 + t2),執行到 Interpreter的中調用GetOrInfer 時,會進行 SBP Signature 的推導。在GlobalTensorInferCache::GetOrInfer 中,會以GlobalTensorMetaInferArgs作為 key 把推導結果存起來,不需要每次都進行推導。
GlobalTensorMetaInferArgs的 hash 函數主要依賴輸入 tensor 的 如下信息 :
-
shape
-
dtype
-
nd_sbp
-
placement
-
consumer_nd_sbp_constraint
不同的 tensor 對象,只要這些元信息相同,就可以複用同一個推導結果。
UserOpExpr通過GlobalTensorInferCache持有所有推導過的結果。
4.1 GlobalTensorInferCache 中的推導準備
實際的推導在 GlobalTensorInferCache::Infer 中進行。
4.1.1 推導 output 的 shape 和 dtype
user_op_expr.InferLogicalTensorDesc的作用主要是推導 output 的 shape 和 data_type,結果保存到 output_mut_metas 。這裏涉及到 UserOpExpr 和 Op 兩個模塊之間的交互關係。後面會總結一下幾個模塊之間的部分交互接口。
user_op_expr.InferLogicalTensorDesc 中用到的兩個函數對象,在Op中定義,並註冊到 OpRegistry 中。OpRegistryResult 的函數對象來自 Op 註冊。示例代碼中 tensor add 對應的 Op 是 AddNOp。
AddNOp 場景的實際調用順序示例如下:
-
user_op_expr.InferLogicalTensorDesc
-
-
logical_tensor_desc_infer_fn_-> AddNOp::InferLogicalTensorDesc
-
out.shape = in[0].shape
-
dtype_infer_fn_-> AddNOp::InferDataType
-
out.data_type = in[0].data_type
-
4.1.2 構造 UserOp
MakeOp(user_op_expr...) 返回一個Operator,具體類型是UserOp(參考之前靜態圖的討論)。這個對象負責執行具體的推導。
CheckInputParallelDescIdentical 要求所有 inputs 的 placement 是一致的。因為這裏是針對UserOp做的推導,例如 tensor add、matmul 等操作,操作數都在相同的設備時,這些操作才能直接計算,否則,就需要通過系統 Op 將數據搬運到一起,再進行計算。
既然所有 inputs 的 placement 都是一樣的,那就用 第一個 作為代表,並 賦值給 UserOp 保存 。
op->InferParallelSignatureIf() 的作用是將 placement 填充到op.bn2parallel_desc_。
對於 AddNOp 來説,key是in_0, in_1, out_0,value 是 inputs[0].placement。
infer_args.MakeInputBlobDescs 操作用偽碼錶示如下:
# for each input index iblob_descs[i].shape = inputs[i].shapeblob_descs[i].stride = inputs[i].strideblob_descs[i].data_type = inputs[i].data_type
infer_args.MakeNdSbpInferHints 操作用偽碼錶示如下:
# for each input index ihints[i].parallel_desc = inputs[i].parallel_deschints[i].blob_desc = blob_descs[i]hints[i].nd_sbp = inputs[i].nd_sbp
blob_descs的作用是為了構造pd_infer_hints,pd_infer_hints是為了構造 NdSbpInferHint4Ibn ,將相關信息封裝到這個函數對象中。這個 函數對象被傳遞給UserOp進行推導 。在UserOp中,通過這個函數對象,根據input/output的標識bn(blob name),獲取NdSbpInferHint,從而可以得到上述元信息。
UserOp推導完畢後,GlobalTensorInferCache會將 inputs/outputs 的元信息,連同推導得到的 NdSbp ,一起保存到GlobalensorInferResult。
4.2 Operator 中的推導準備
Operator::InferNdSbpSignatureIf中,調用 InferNdSbpSignature 進行實際的推導,然後調用 FillNdSbpSignature 保存推導結果。
InferNdSbpSignature是一個虛函數。 UserOp 會先檢查Op有沒有定義自己的 SBP Signature 推導函數,AddNOp 沒有這方面的函數,就 調用 Operator::InferNdSbpSignature 。
InferNdSbpSignature 中會 根據 parallel_desc.hierarchy() 判斷 是 1D SBP,還是 ND SBP。
先只看 1D SBP 的情況。調用傳入的 NdSbpInferHint4Ibn 函數對象,查到 GlobalTensorInferCache 中創建的 NdSbpInferHint,轉為 NdSbpInferHint 並存到 map 中。因為是一維的,所以只需要 取 sbp_parallel 的第一個元素 。然後 調用 InferSbpSignature (名字中少了 Nd), 將推導結果寫到 SbpSignature 。
無論是一維還是多維,結果的類型都是 NdSbpSignature。所以要將 SbpSignature 轉為 NdSbpSignature。
Operator::InferSbpSignature 的作用主要是構造兩個函數對象,SbpInferHint4Ibn 和 CalcOrderValue4SbpSig,然後調用子類 override 的、同名重載的虛函數 InferSbpSignature 。
SbpInferHint4Ibn 是將傳入的 map 數據封裝到函數對象中,用於查詢輸入輸出的元信息。
CalcOrderValue4SbpSig 給每個 SbpSignature 計算一個序值,用於對簽名進行排序。
InferSbpSignature 也是一個虛函數。因為 AddNOp 沒有定義簽名推導函數,會調用 Operator::InferSbpSignature 。
4.3 SbpSignature 的推導
之前都是做各種準備, Operator::InferSbpSignature 裏才進行真正的推導。簡單講就3步:
-
獲取候選集
-
過濾不合適的簽名
-
排序
4.3.1 SbpSignature 的候選集
調用 GetValidNdSbpSignatureList 會獲取 SbpSignature 的候選集。在這個函數中,先調用 GetNdSbpSignatureList 獲取初步的候選集,再通過 FilterNdSbpSignatureListByLogicalShape 過濾得到正確可用的候選集。候選集都保存到sbp_sig_list。
GetNdSbpSignatureList是一個虛函數, UserOp 實現了自己的版本 。這個函數中最核心的操作就是 val_->get_nd_sbp_list_fn ,實際調用 AddNOp::GetSbp 。 UserOpSbpContext 是 UserOp 與 AddNOp 等類之間的協議接口的一部分。
如前所述,提供 SBP Signature 的候選集,是算子的責任。AddNOp這個算子比較簡單,只給出兩類簽名:
-
對輸入 tensor 的 shape 的每個 axis i,所有的 input/output 都創建一個 split(i)。
-
-
對於 tensor add 來説,input/output 的 shape 一樣才能直接計算,所以 split 的 axis 也都一樣。
-
-
所有的 input/output 都創建一個 partialsum。
-
broadcast 的情況會在 Operator 中默認設置,因為理論上所有inputs/outputs都應該支持以broadcast的方式進行運算。
候選集數據示例如下:
{"sbp_signature":[{"bn_in_op2sbp_parallel":{"in_0":{"split_parallel":{"axis":"0"}},"in_1":{"split_parallel":{"axis":"0"}},"out_0":{"split_parallel":{"axis":"0"}}}},{"bn_in_op2sbp_parallel":{"in_0":{"split_parallel":{"axis":"1"}},"in_1":{"split_parallel":{"axis":"1"}},"out_0":{"split_parallel":{"axis":"1"}}}},{"bn_in_op2sbp_parallel":{"in_0":{"partial_sum_parallel":{}},"in_1":{"partial_sum_parallel":{}},"out_0":{"partial_sum_parallel":{}}}},{"bn_in_op2sbp_parallel":{"in_0":{"broadcast_parallel":{}},"in_1":{"broadcast_parallel":{}},"out_0":{"broadcast_parallel":{}}}}]}
4.3.2 過濾不合適的簽名
分兩步過濾不合適的簽名
-
FilterAndCheckValidSbpSignatureListByLogicalShape中,對於每個輸入tensor ibn,簽名中 ibn 的 split axis,必須小於 tensor ibn 的 shape axes 數量。換句話説,如果 tensor 是二維的,就無法接受split(2),只能是split(0)或split(1)。
-
FilterSbpSignatureList的作用是檢驗sbp_sig_conf約束,也就是從GlobalTensorInferCache一路傳過來的參數nd_sbp_constraints。這個過濾規則要求,符合條件的簽名,其內容必須包含sbp_sig_conf。
4.3.3 簽名排序
SortSbpSignatureListByCopyCost 對候選簽名進行排序。
-
優先按 OrderValue 比較
-
OrderValue 相等時,按 CopyCost 比較
二者都是較小的值優先。
OrderValue4SbpSig 是對CalcOrderValue4SbpSig的封裝, 預先計算所有簽名的 OrderValue 存到 map 中 ,便於 sort 函數查找。 IbnCopyCost4SbpSig 也是同理。
回過頭來看CalcOrderValue4SbpSig 的定義。因為AddNOp是有輸入的 ,對於每個輸入 tensor ibn 會加上一個權重 ,當 ibn 的 sbp 與 簽名中對應的 sbp 相同 時,權重值為-10,即增加了選中的機會,因為 sbp 一致通常就不需要數據搬運。而parallel_num 的條件判斷在UserOp下應該是都成立的。
當 sbp_sig_conf 不空時, CalcOrderValue4SbpSig 直接返回0 。因為如果簽名不 包含 sbp_sig_conf ,即使 SBP 都一致 ,簽名也不一定符合要求,所以直接返回0。
簽名成本由ComputeIbnCopyCost4SbpSig計算 。主要是 根據輸入和簽名的 sbp 計算 cost :
-
如果 sbp 一致,cost 為0
-
partial_sum 和 broadcast 的 cost 都是一個超大的數字。
-
否則 cost 等於 input tensor 的數據傳輸字節數量。
4.4 推導結果
推導得到的 nd_sbp_signature 如下:
{"bn_in_op2nd_sbp":{"in_0":{"sbp_parallel":[{"split_parallel":{"axis":"0"}}]},"in_1":{"sbp_parallel":[{"split_parallel":{"axis":"0"}}]},"out_0":{"sbp_parallel":[{"split_parallel":{"axis":"0"}}]}}}
示例代碼中,如果一個輸入是split,另一個是broadcast,推導的簽名結果都是broadcast。如果推斷的sbp簽名是split,是否能減少數據搬運呢?
5
NdSbp 的推導過程
NdSbp 的推導主要包括3步
-
調用 GetValidNdSbpSignatureList 獲取有效的簽名
-
剔除不能包含 nd_sbp_constraints 的簽名
-
貪心搜索較優的簽名
重點看一下有效簽名的獲取。主要是兩步:
-
GetNdSbpSignatureList: 獲取全部簽名
-
FilterNdSbpSignatureListByLogicalShape: 過濾不合適的簽名
5.1 NdSbp 簽名的候選集
GetNdSbpSignatureList 核心是兩步:
-
GetSbpSignaturesIf: 得到一維的簽名(和 1D SBP 的情況相同)
-
DfsGetNdSbpSignature: 根據一維簽名拓展到多維
這個過程,如果深入到數據細節去看,會涉及 input/output、ranks、NdSbp 等多個維度,有點抽象複雜。如果從官方文檔 2D SBP 中説明的 ranks 和 NdSbp 的物理含義出發,會更容易理解。
以ranks=[[0, 1, 2], [3, 4, 5]]為例(ranks=[r1, r2])
這是一個二維的設備矩陣/陣列。算子的每個輸入、輸出也都有兩個 sbp,NdSbpSignature 中的 value 是二維的,有兩個槽位。假設 Op 的 1D Sbp 有 n 個簽名。
從形式上看,NdSbpSignature 是先按 bn 組織數據。但是從數據分佈的過程看,是先按SbpSignature組織數據。一個 NdSbpSignature 等價於 SbpSignature 數組。NdSbp中的每個槽位,都表示一個 1D Sbp 的數據分佈(所有的 input/output一起分佈)。
-
比如第 0 個槽位,就是在r1和r2這兩個 sub group 之間分佈數據,這個分佈必須是一個有效的 1D SbpSignature(所有的 input/output一起分佈)。
-
第 1 個槽位,對於r1,就是將分配給它的數據子集,再根據一個 SbpSignature 進行分佈(所有的 input/output一起分佈)。
所以,只需要按 SbpSignature整體 填滿兩個槽位就行。每個槽位各有 n 種可能,一共有 n*n 個候選簽名。這樣生成的候選集是完整的,不會漏掉候選項。這應該就是 direct product of 1D sbp signatures 的含義。
6
模塊間協作關係
SbpSignature 推導的實現用了大量 functional 的代碼。應該是為了不同模塊間的信息屏蔽,或者父類、子類之間的邏輯複用、信息傳遞等目的,很多信息都封裝到 function 中,需要時再檢索、轉換。
下圖展示了不同模塊之間的部分關係:

參考資料
-
oneflow v0.9.1(http://github.com/Oneflow-Inc/oneflow/tree/0ea44f45b360cd21f455c7b5fa8303269f7867f8/oneflow)
-
SBP Signature(http://docs.oneflow.org/master/parallelism/02_sbp.html#sbp-signature)
-
2D SBP(http://docs.oneflow.org/master/parallelism/04_2d-sbp.html)
-
placement api(http://oneflow.readthedocs.io/en/master/tensor_attributes.html?highlight=placement#oneflow-placement)
-
http://segmentfault.com/a/1190000042625900
其他人都在看
-
“一鍵”模型遷移,性能翻倍,多語言AltDiffusion推理速度超快
歡迎Star、試用OneFlow最新版本:http://github.com/Oneflow-Inc/oneflow/

本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯繫 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閲讀的你也加入,一起分享。
- OneFlow源碼解析:Eager模式下的設備管理與併發執行
- OpenAI創始人:GPT-4的研究起源和構建心法
- GPT-4創造者:第二次改變AI浪潮的方向
- NCCL源碼解析①:初始化及ncclUniqueId的產生
- GPT-4問世;LLM訓練指南;純瀏覽器跑Stable Diffusion
- 適配PyTorch FX,OneFlow讓量化感知訓練更簡單
- 超越ChatGPT:大模型的智能極限
- ChatGPT作者John Schulman:我們成功的祕密武器
- YOLOv5全面解析教程⑤:計算mAP用到的Numpy函數詳解
- GPT-3/ChatGPT復現的經驗教訓
- ChatGPT背後:從0到1,OpenAI的創立之路
- 一塊GPU搞定ChatGPT;ML系統入坑指南;理解GPU底層架構
- YOLOv5全面解析教程④:目標檢測模型精確度評估
- ChatGPT數據集之謎
- OneFlow源碼解析:Eager模式下的SBP Signature推導
- YOLOv5全面解析教程③:更快更好的邊界框迴歸損失
- ChatGPT背後的經濟賬
- Sam Altman的成功學|升維指南
- 開源機器學習軟件對AI的發展意味着什麼?
- “一鍵”模型遷移,性能翻倍,多語言AltDiffusion推理速度超快