GLM國產大模型訓練加速:效能最高提升3倍,視訊記憶體節省1/3,低成本上手

作者|BBuf、謝子鵬、馮文
2017 年,Google 提出了 Transformer 架構,隨後 BERT 、GPT、T5等預訓練模型不斷湧現,並在各項任務中都不斷重新整理 SOTA 紀錄。去年,清華提出了 GLM 模型( http://github.com/THUDM/GLM ),不同於上述預訓練模型架構,它採用了一種自迴歸的空白填充方法, 在 NLP 領域三種主要的任務(自然語言理解、無條件生成、有條件生成)上都取得了不錯的結果。
很快,清華基於 GLM 架構又推出了 GLM-130B( http://keg.cs.tsinghua.edu.cn/glm-130b/zh/posts/glm-130b/ ),這是一個開源開放的雙語(中文和英文)雙向稠密模型,擁有 1300 億引數,在語言理解、語言建模、翻譯、Zero-Shot 等方面都更加出色。
預訓練模型的背後離不開開源深度學習框架的助力。在此之前,GLM 的開原始碼主要是由 PyTorch、DeepSpeed 以及 Apex 來實現,並且基於 DeepSpeed 提供的資料並行和模型並行技術訓練了 GLM-Large(335M),GLM-515M(515M),GLM-10B(10B)等大模型,這在一定程度上降低了 GLM 預訓練模型的使用門檻。
即便如此,對更廣大範圍的普通使用者來說,訓練 GLM 這樣的模型依然令人頭禿,同時,預訓練模型的效能優化還有更大的提升空間。
為此,我們近期將原始的 GLM 專案移植到了使用 OneFlow 後端進行訓練的 O ne- GLM 專案。得益於 OneFlow 和 PyTorch 無縫相容性,我們快速且平滑地移植了 GLM,併成功跑通了預訓練任務(訓練 GLM-large)。
此外,由於 OneFlow 原生支援 DeepSpeed 和 Apex 的很多功能和優化技術,使用者不再需要這些外掛就可訓練 GLM 等大模型。更重要的是,針對當前 OneFlow 移植的 GLM 模型,在簡單調優後就能在效能以及視訊記憶體佔用上有大幅提升。
具體是怎麼做到的?下文將進行揭曉。
-
One-GLM: http://github.com/Oneflow-Inc/one-glm
-
OneFlow: http://github.com/Oneflow-Inc/oneflow
1
GLM-large 訓練效能和視訊記憶體的表現
首先先展示一下分別使用官方的 GLM 倉庫以及 One-GLM 倉庫訓練 GLM-large 網路的效能和視訊記憶體表現(資料並行技術),硬體環境為 A100 PCIE 40G,BatchSize 設定為 8。
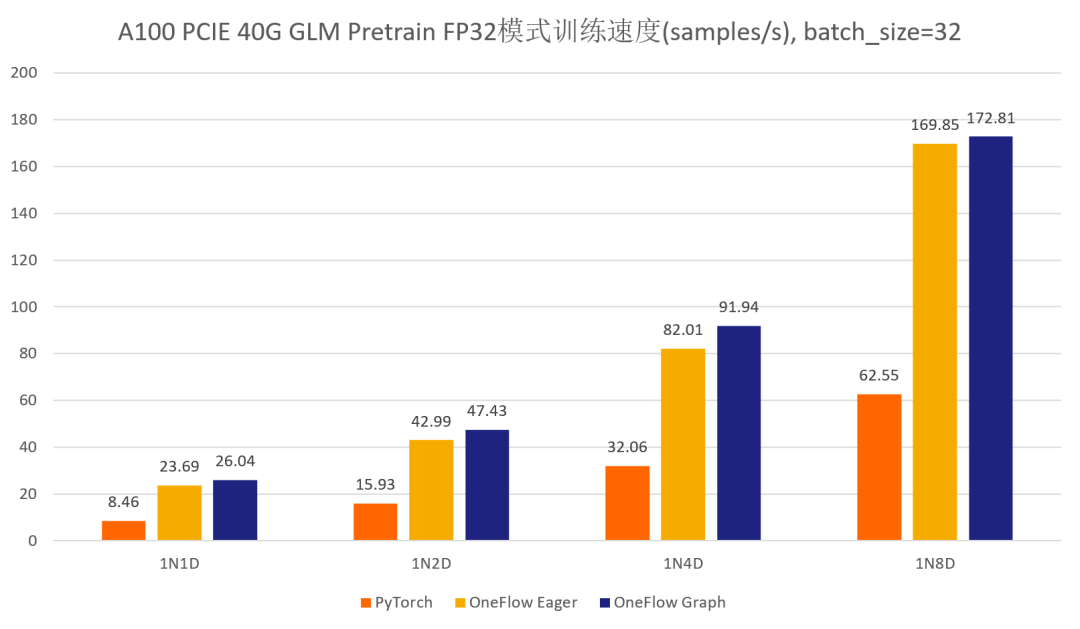
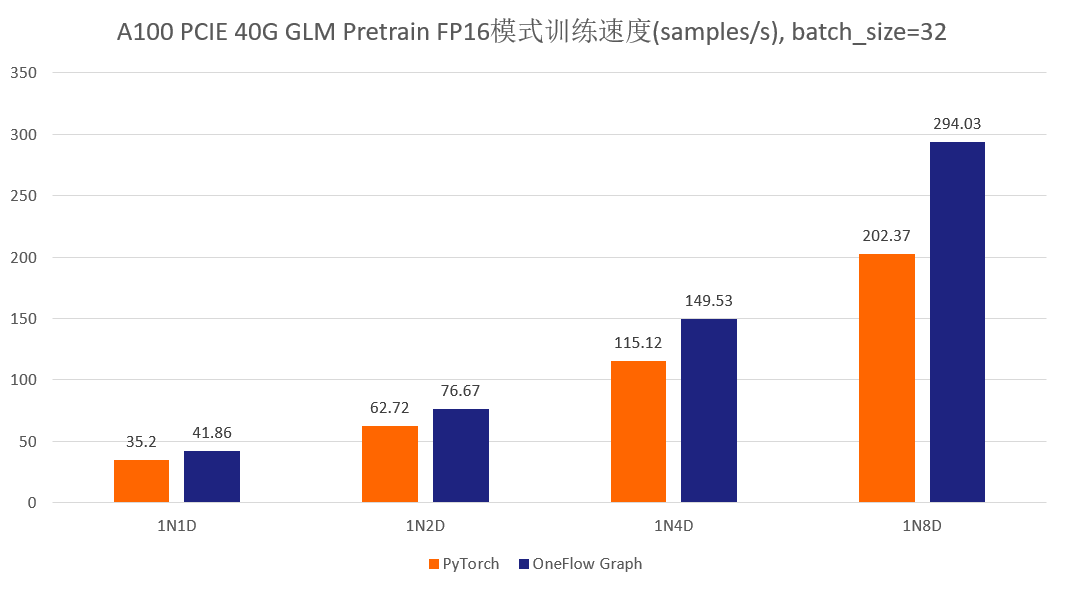
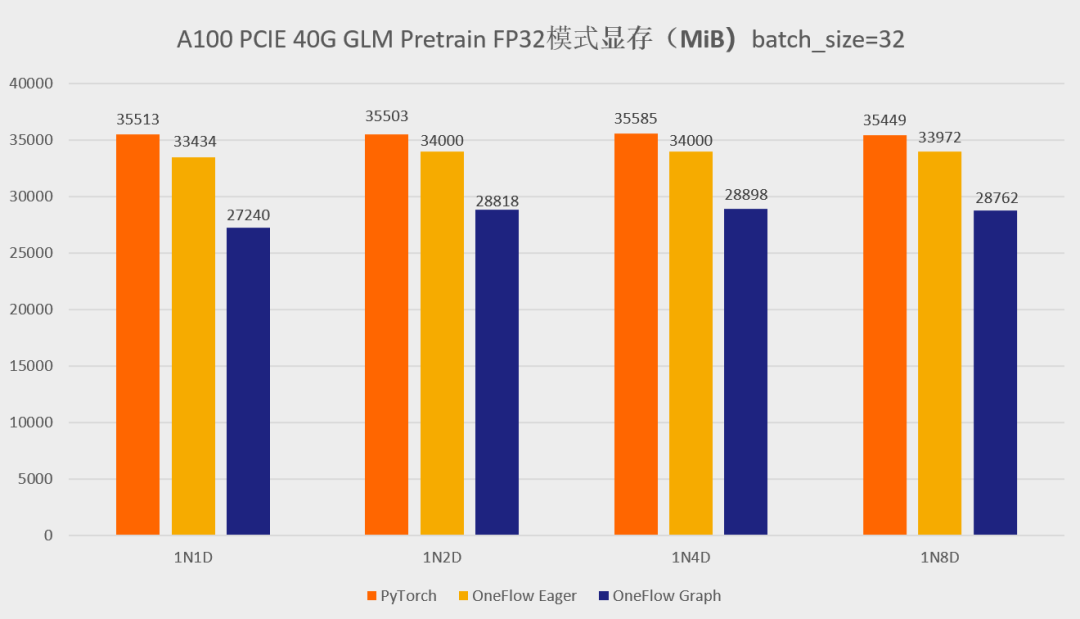
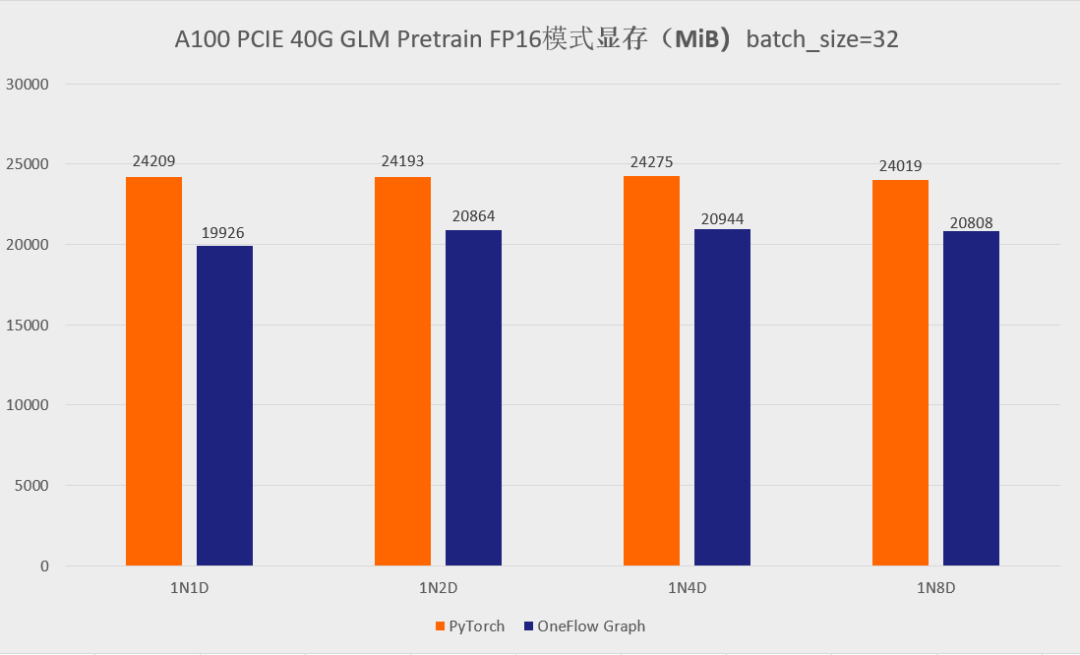
可以看到,在 GLM-large 的訓練任務中,相比原始的基於 PyTorch、DeepSpeed、Apex 的 GLM 實現,OneFlow的效能有 120% - 276% 的加速,並且視訊記憶體佔用降低了10% -30%( 測試結果均可用 o neflow >=0.9.0 復現)。
2
GLM 遷移,只需修改幾行程式碼
由於 OneFlow 無縫相容了 PyTorch 的生態,只需改動幾行程式碼,就可以讓使用者輕鬆遷移 GLM 大模型到 One-GLM:
-
將 import torch 替換為 import oneflow as torch
-
將 import torch.xx 替換為 import oneflow.xx
-
將 from apex.optimizers import FusedAdam as Adam 替換為 from oneflow.optim import Adam
-
將 from apex.normalization.fused_layer_norm import FusedLayerNorm as LayerNorm 替換為 from oneflow.nn import LayerNorm
-
註釋掉 torch.distributed.ReduceOp,torch.distributed.new_group,,torch.distributed.TCPStore,torch.distributed.all_reduce 這些API,它們是 PyTorch DDP 所需要的,但 OneFlow 的資料並行是由內部的 SBP 和 Global Tensor 機制實現,並不需要這些 API。
其它許多模型的遷移更簡單,比如在和 torchvision 對標的 flowvision 中,許多模型只需通過在 torchvision 模型檔案中加入 import oneflow as torch 即可得到,讓使用者幾乎沒有額外成本。
此外,OneFlow 還提供全域性 “mock torch” 功能( http://docs.oneflow.org/master/cookies/oneflow_torch.html ),在命令列執行 eval $(oneflow-mock-torch) 就可以讓接下來執行的所有 Python 腳本里的 import torch 都自動指向 oneflow。
3
兩大調優手段
loss 計算部分的優化
在原始的 GLM 實現中,loss計算部分使用到了 mpu.vocab_parallel_cross_entropy 這個函式 ( http://github.com/THUDM/GLM/blob/main/pretrain_glm.py#L263 ) 。
通過分析 這個函式 ,發現它實現了 sparse_softmax_cross_entropy 的功能,但在實現過程中,原始的 GLM 倉庫使用了 PyTorch 的 autograd.Function 模組,並且使用了大量的小運算元來拼接出 sparse_softmax_cross_entropy 整體的功能。而在 OneFlow 的運算元庫中,已經有 sparse_softmax_cross_entropy 這個運算元對應的 CUDA 實現了,也就是 flow.sparse_softmax_cross_entropy 這個 API。
所以,我們將 GLM 對 sparse_softmax_cross_entropy 的 naive 實現替換為 flow.sparse_softmax_cross_entropy 這個 API,並進行了 loss 對齊實驗。
結果如何?下圖展示了基於 OneFlow 的 Graph 模式訓練 GLM-large 模型前 1000 輪的 loss 對齊情況,並分別測試了 FP32 和 AMP 模式:
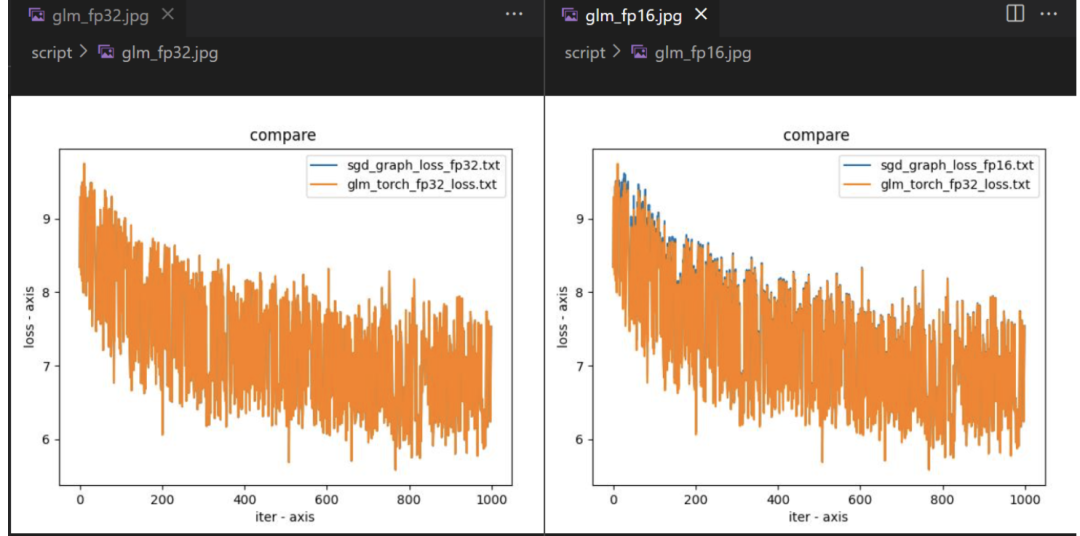
可以看到,將原始 GLM 的 naive sparse_softmax_cross_entropy 實現替換為 flow.sparse_softmax_cross_entropy 之後 loss 是完全對齊的,可以保證正確性。
相比原始的 GLM 的單卡效能,這個替換使得 One-GLM 的單卡效能有大幅提升,主要原因是 OneFlow 對 sparse_softmax_cross_entropy 運算元做了極致的效能優化,並且減少了原始 GLM 中大量的碎運算元拼湊帶來的訪存開銷。此外,這樣做也降低了 torch.autograd.Function 本身帶來的一些系統開銷。
CUDA Kernel Fuse
除上述優化外,GLM 模型本質上就是一個編解碼的 Transformer 架構,所以我們將之前優化 GPT、BERT 的一些 Fuse Pattern 也帶給了 One-GLM 模型。具體包含以下兩個 Fuse Pattern :
-
fused_bias_add_gelu : 將 bias_add 和 gelu 運算元融合在一起。
-
fused_bias_add_dropout :將 bias_add 和 dropout 運算元融合在一起。
這兩個 fuse 都可以顯著改善計算的訪存,並減少 Kernel Launch 帶來的開銷,由於 GLM 模型越大則層數就會越多,那麼這種 Fuse Pattern 帶來的的優勢也會不斷放大。
最終,在上述兩方面的優化作用下,在 A100 PCIE 40G,batch_size = 8 環境中的訓練 GLM-large 的任務時,單卡 FP32 模式的效能相比原始的 GLM 取得了 280%(FP32 模式) 和 307%( AMP 模式) 的訓練加速。
4
LiBai 也能輕鬆搞定 GLM 推理
當模型規模過於龐大,單個 GPU 裝置無法容納大規模模型引數時,便捷好用的分散式訓練和推理需求就相繼出現,業內也隨之推出相應的工具。
基於 OneFlow 構建的 LiBai 模型庫讓分散式上手難度降到最低,使用者不需要關注模型如何分配在不同的顯示卡裝置,只需要修改幾個配置資料就可以設定不同的分散式策略。當然,加速效能更是出眾。
-
LiBai : http://github.com/Oneflow-Inc/libai
-
LiBai 相關介紹: 大模型訓練之難,難於上青天?預訓練易用、效率超群的「李白」模型庫來了!
-
GLM: http://github.com/Oneflow-Inc/libai/tree/glm_project/projects/GLM
用 LiBai 搭建的 GLM 可以便捷地實現model parallel + pipeline parallel推理, 很好地解決單卡放不下大規模模型的問題。
那麼,使用者如何利用大規模模型訓練與推理倉庫 LiBai 來構建 GLM 的分散式推理部分?下面用一個小例子解釋一下。
分散式推理具有天然優勢
要知道,模型的引數其實就是許多 tensor,也就是以矩陣的形式出現,大模型的引數也就是大矩陣,並行策略就是把大矩陣分為多個小矩陣,並分配到不同的顯示卡或不同的裝置上,基礎的 LinearLayer 在LiBai中的實現程式碼如下:
class Linear1D(nn.Module): def __init__(self, in_features, out_features, parallel="data", layer_idx=0, ...): super().__init__()
if parallel == "col": weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.split(0)]) elif parallel == "row": weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.split(1)]) elif parallel == "data": weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast]) else: raise KeyError(f"{parallel} is not supported! Only support ('data', 'row' and 'col')")
self.weight = flow.nn.Parameter( flow.empty( (out_features, in_features), dtype=flow.float32, placement=dist.get_layer_placement(layer_idx), # for pipeline parallelism placement sbp=weight_sbp, ) ) init_method(self.weight) ... def forward(self, x): ...
在這裡,使用者可選擇去如何切分 Linear 層的矩陣,如何切分資料矩陣,而OneFlow 中的 SBP 控制豎著切、橫著切以及其他拆分矩陣的方案(模型並行、資料並行),以及通過設定 Placement 來控制這個 LinearLayer 是放在第幾張顯示卡上(流水並行)。
所以,根據 LiBai 中各種 layer 的設計原理以及基於 OneFlow 中 tensor 自帶的 SBP 和 Placement 屬性的天然優勢,使得使用者搭建的模型能夠很簡單地就實現資料並行、模型並行以及流水並行操作。
GLM 推理的 Demo 演示
這裡為使用者展示 LiBai 中 GLM 的單卡和便捷的多卡推理 Demo,模型可在 HuggingFace 上獲取: http://huggingface.co/models?filter=glm
-
單卡 generate 任務,我們選擇 glm-10b 模型:
python demo.py
# demo.py import oneflow as flow from projects.GLM.tokenizer.glm_tokenizer import GLMGPT2Tokenizer from libai.utils import distributed as dist from projects.GLM.configs.glm_inference import cfg from projects.GLM.modeling_glm import GLMForConditionalGeneration from projects.GLM.utils.glm_loader import GLMLoaderHuggerFace from omegaconf import DictConfig
tokenizer = GLMGPT2Tokenizer.from_pretrained("/data/home/glm-10b") input_ids = tokenizer.encode( [ "Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai." ], return_tensors="of", ) inputs = {"input_ids": input_ids, "attention_mask": flow.ones(input_ids.size())} inputs = tokenizer.build_inputs_for_generation(inputs, max_gen_length=512)
sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast]) placement = dist.get_layer_placement(0)
dist.set_device_type("cpu") loader = GLMLoaderHuggerFace(GLMForConditionalGeneration, cfg, "/path/to/glm-10b") model = loader.load() model = model.half().cuda()
dist.set_device_type("cuda") outputs = model.generate( inputs=inputs['input_ids'].to_global(sbp=sbp, placement=placement), position_ids=inputs['position_ids'].to_global(sbp=sbp, placement=placement), generation_attention_mask=inputs['generation_attention_mask'].to_global(sbp=sbp, placement=placement).half(), max_length=512 ) res = tokenizer.decode(outputs[0]) print(res) >>> [CLS] Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.<|endoftext|> <|startofpiece|> Stanford University and a co-founder of <|endofpiece|>
-
4卡 model parallel+pipeline parallel generate 任務,選擇 glm-10b 模型:
python3 -m oneflow.distributed.launch --nproc_per_node 4 demo.py
# demo.py import oneflow as flow from projects.GLM.tokenizer.glm_tokenizer import GLMGPT2Tokenizer from libai.utils import distributed as dist from projects.GLM.configs.glm_inference import cfg from projects.GLM.modeling_glm import GLMForConditionalGeneration from projects.GLM.utils.glm_loader import GLMLoaderHuggerFace from omegaconf import DictConfig
# 只需簡單配置並行方案 parallel_config = DictConfig( dict( data_parallel_size=1, tensor_parallel_size=2, pipeline_parallel_size=2, pipeline_num_layers=2 * 24 ) ) dist.setup_dist_util(parallel_config)
tokenizer = GLMGPT2Tokenizer.from_pretrained("/data/home/glm-10b") input_ids = tokenizer.encode( [ "Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai." ], return_tensors="of", ) inputs = {"input_ids": input_ids, "attention_mask": flow.ones(input_ids.size())} inputs = tokenizer.build_inputs_for_generation(inputs, max_gen_length=512)
sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast]) placement = dist.get_layer_placement(0)
loader = GLMLoaderHuggerFace(GLMForConditionalGeneration, cfg, "/path/to/glm-10b") model = loader.load()
outputs = model.generate( inputs=inputs['input_ids'].to_global(sbp=sbp, placement=placement), position_ids=inputs['position_ids'].to_global(sbp=sbp, placement=placement), generation_attention_mask=inputs['generation_attention_mask'].to_global(sbp=sbp, placement=placement), max_length=512 ) res = tokenizer.decode(outputs[0]) if dist.is_main_process(): print(res) >>> [CLS] Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.<|endoftext|> <|startofpiece|> Stanford University and a co-founder of <|endofpiece|>
-
使用 One- GLM 訓練的模型進行推理
LiBai對於OneFlow的模型載入同樣方便,如果你希望使用one-glm訓練後的模型進行推理,只需簡單的將上述demo中的 GLMLoaderHuggerFace 替換為 GLMLoaderLiBai 。
5
結語
基於 OneFlow 來移植 GLM 大模型非常簡單,相比於原始版本 PyTorch GLM 訓練 GLM-large 模型,OneFlow 能大幅提升效能和節省視訊記憶體。
此外,通過使用 GLM-10B 這個百億級大模型做推理,表明基於 OneFlow 的 LiBai 來做大模型推理可以開箱即用,並實現更高的推理速度,如果你想配置不同的並行方式來推理大模型,只需要簡單配置檔案的幾個引數即可。
未來,OneFlow團隊將探索使用 OneFlow 訓練更大的 GLM-130B 千億模型的可行性 ,相信基於 OneFlow 可以更快地訓練 GLM-130B 千億級別模型,加速國產大模型訓練和推理任務。
歡迎Star、試用One-GLM:
-
One-GLM: http://github.com/Oneflow-Inc/one-glm
-
OneFlow: http://github.com/Oneflow-Inc/oneflow
其他人都在看
歡迎Star、試用OneFlow最新版本:http://github.com/Oneflow-Inc/oneflow/

本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- OneFlow原始碼解析:Eager模式下的裝置管理與併發執行
- OpenAI創始人:GPT-4的研究起源和構建心法
- GPT-4創造者:第二次改變AI浪潮的方向
- NCCL原始碼解析①:初始化及ncclUniqueId的產生
- GPT-4問世;LLM訓練指南;純瀏覽器跑Stable Diffusion
- 適配PyTorch FX,OneFlow讓量化感知訓練更簡單
- 超越ChatGPT:大模型的智慧極限
- ChatGPT作者John Schulman:我們成功的祕密武器
- YOLOv5全面解析教程⑤:計算mAP用到的Numpy函式詳解
- GPT-3/ChatGPT復現的經驗教訓
- ChatGPT背後:從0到1,OpenAI的創立之路
- 一塊GPU搞定ChatGPT;ML系統入坑指南;理解GPU底層架構
- YOLOv5全面解析教程④:目標檢測模型精確度評估
- ChatGPT資料集之謎
- OneFlow原始碼解析:Eager模式下的SBP Signature推導
- YOLOv5全面解析教程③:更快更好的邊界框迴歸損失
- ChatGPT背後的經濟賬
- Sam Altman的成功學|升維指南
- 開源機器學習軟體對AI的發展意味著什麼?
- “一鍵”模型遷移,效能翻倍,多語言AltDiffusion推理速度超快