JuiceFS 在火山引擎邊緣計算的應用實踐
火山引擎邊緣雲是以雲端計算基礎技術和邊緣異構算力結合網路為基礎,構建在邊緣大規模基礎設施之上的雲端計算服務,形成以邊緣位置的計算、網路、儲存、安全、智慧為核心能力的新一代分散式雲端計算解決方案。
01- 邊緣場景儲存挑戰
邊緣儲存主要面向適配邊緣計算的典型業務場景,如邊緣渲染。火山引擎邊緣渲染依託底層海量算力資源,可助力使用者實現百萬渲染幀佇列輕鬆編排、渲染任務就近排程、多工多節點並行渲染,極大提升渲染 簡單介紹一下在邊緣渲染中遇到的儲存問題:
- 需要物件儲存與檔案系統的元資料統一,實現資料通過物件儲存介面上傳以後,可以通過 POSIX 介面直接進行操作;
- 滿足高吞吐量的場景需求,尤其是在讀的時候;
- 完全實現 S3 介面和 POSIX 介面。
為了解決在邊緣渲染中遇到的儲存問題,團隊花了將近半年的時間開展了儲存選型測試。最初,團隊選擇了公司內部的儲存元件,從可持續性和效能上來說,都能比較好的滿足我們的需求。 但是落地到邊緣場景,有兩個具體的問題:
- 首先,公司內部元件是為了中心機房設計的,對於物理機資源和數量是有要求的,邊緣某些機房很難滿足;
- 其次,整個公司的儲存元件都打包在一起,包括:物件儲存、塊儲存、分散式儲存、檔案儲存等,而邊緣側主要需要檔案儲存和物件儲存,需要進行裁剪和改造,上線穩定也需要一個過程。
團隊討論後,形成了一個可行的方案:CephFS + MinIO 閘道器。MinIO 提供物件儲存服務,最終的結果寫入 CephFS,渲染引擎掛載 CephFS,進行渲染操作。測試驗證過程中,檔案到千萬級時,CephFS 的效能開始下降,偶爾會卡頓,業務方反饋不符合需求。
同樣的,基於 Ceph 還有一個方案,就是使用 Ceph RGW + S3FS。這個方案基本能滿足要求,但是寫入和修改檔案的效能不符合場景要求。
經過三個多月的測試之後,我們明確了邊緣渲染中對於儲存的幾個核心訴求:
- 運維不能太複雜:儲存的研發人員能夠通過運維文件上手操作;後期擴容以及處理線上故障的運維工作需要足夠簡單。
- 資料可靠性:因為是直接給使用者提供儲存服務,因此對於寫入成功的資料不允許丟失,或者出現跟寫入的資料不一致的情況。
- 使用一套元資料,同時支援物件儲存和檔案儲存:這樣業務方在使用的時候,不需要多次上傳和下載檔案,降低業務方的使用複雜度。
- 針對讀有比較好的效能:團隊需要解決的是讀多寫少的場景,因此希望有比較好的讀效能。
- 社群活躍度:在解決現有問題以及積極推進新功能的迭代時,一個活躍的社群能有更快的響應。
明確核心訴求之後,我們發現前期的三個方案都不太滿足需求。
02- 使用 JuiceFS 的收益
火山引擎邊緣儲存團隊在 2021 年 9 月瞭解到了 JuiceFS,並跟 Juicedata 團隊進行了一些交流。經過交流我們決定在邊緣雲場景嘗試一下。JuiceFS 的官方文件非常豐富,可讀性很高,通過看文件就可以瞭解比較多的細節。
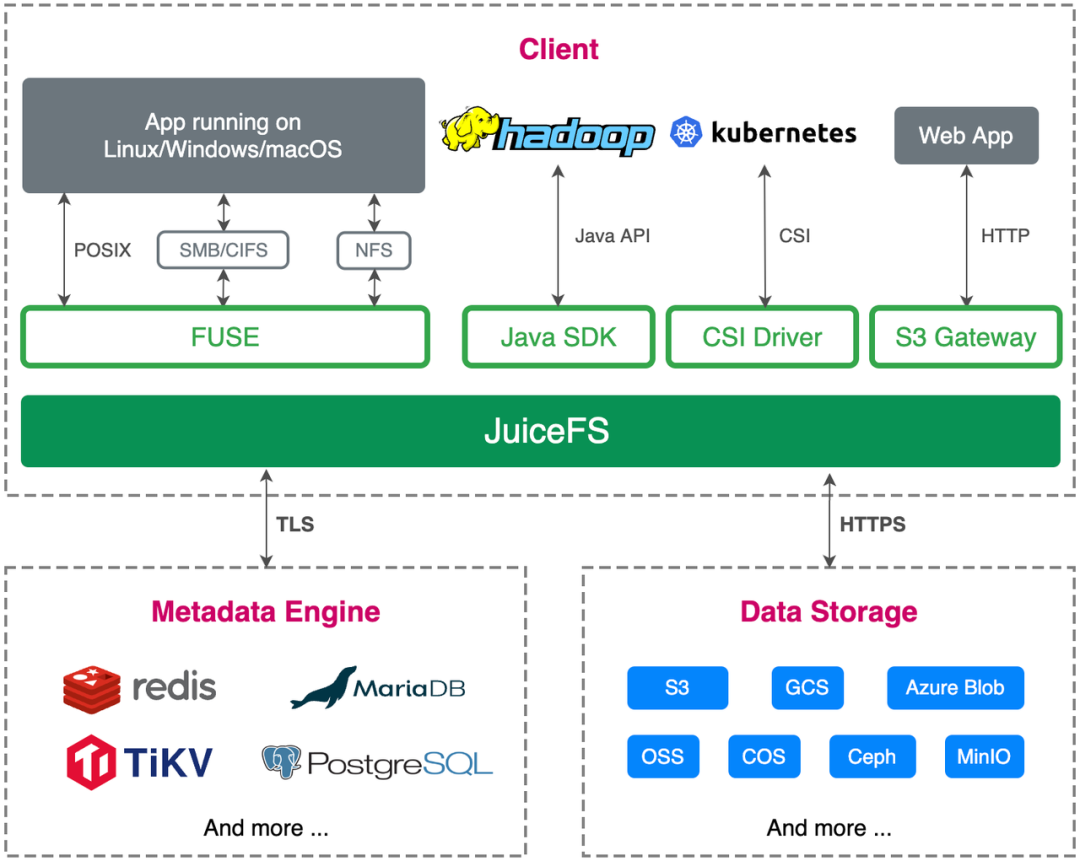
於是,我們就開始在測試環境做 PoC 測試,主要關注的點是可行性驗證,運維和部署的複雜度,以及跟上游業務的適配,是否符合上游業務的需求。
我們部署了 2 套環境,一個環境是基於單節點的 Redis + Ceph 搭建,另一個環境是基於單例項的 MySQL + Ceph 搭建。
在整個環境搭建方面因為 Redis、MySQL 和 Ceph(通過 Rook 部署)都比較成熟,部署運維方案可以參考的資料也比較全面,同時 JuiceFS 客戶端也能夠簡單和方便地對接這些資料庫和 Ceph,因此整體的部署流程非常流暢。
業務適配方面,邊緣雲是基於雲原生開發和部署的,JuiceFS 支援 S3 API,同時完全相容 POSIX 協議,還支援 CSI 的方式掛載,完全滿足我們的業務需求。
綜合測試後,我們發現 JuiceFS 完全契合業務方的需求,可以在生產上進行部署執行,滿足業務方的線上需求。
收益1:業務流程優化
在使用 JuiceFS 之前,邊緣渲染主要利用位元組跳動內部的物件儲存服務(TOS),使用者上傳資料到 TOS 中,渲染引擎再從 TOS 上將使用者上傳的檔案下載到本地,渲染引擎讀取本地的檔案,生成渲染結果,再將渲染結果上傳回 TOS,最後使用者從 TOS 中下載渲染結果。整體的互動流程有好幾個環節,而且中間涉及到比較多的網路以及資料拷貝,所以在這個過程中會存在網路抖動或者時延偏高的情況,影響使用者體驗。
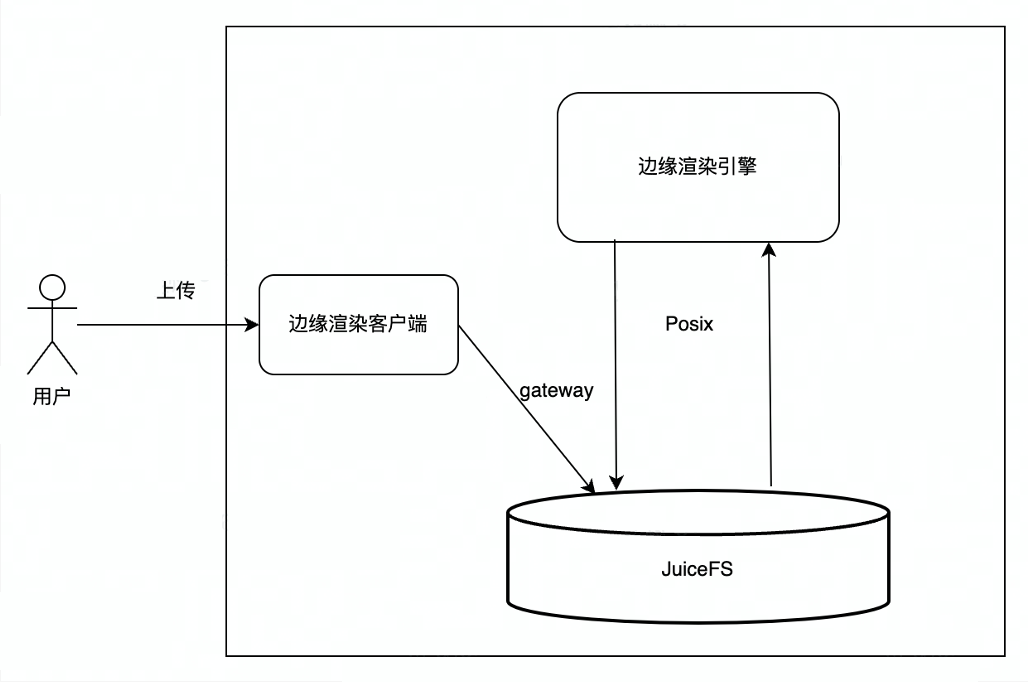
使用 JuiceFS 之後,流程變成了使用者通過 JuiceFS S3 閘道器進行上傳,由於 JuiceFS 實現了物件儲存和檔案系統的元資料的統一,可以直接將 JuiceFS 掛載到渲染引擎中,渲染引擎以 POSIX 介面對檔案進行讀寫,終端使用者直接從JuiceFS S3 閘道器中下載渲染結果,整體的流程更加簡潔和高效,同時也更穩定。
收益2:讀檔案加速,大檔案順序寫加速
得益於 JuiceFS 的客戶端快取機制,我們可以將頻繁讀取的檔案快取到渲染引擎本地,極大加速了檔案的讀取速度。我們針對是否開啟快取做了對比測試,發現使用快取後可以提升大約 3-5 倍的吞吐量。
同樣,因為 JuiceFS 的寫模型是先寫記憶體,當一個 chunk(預設 64M)被寫滿,或者應用呼叫強制寫入介面(close 和 fsync 介面)時,才會將資料上傳到物件儲存,資料上傳成功後,再更新元資料引擎。所以,在寫入大檔案時,都是先寫記憶體,再落盤,可以大大提升大檔案的寫入速度。
目前邊緣的使用場景主要以渲染類為主,檔案系統讀多寫少,檔案寫入也是以大檔案為主。這些業務場景的需求和 JuiceFS 的適用場景非常吻合,業務方在儲存替換為 JuiceFS 後,整體評價也很高。
03- 在邊緣場景中如何使用 JuiceFS
JuiceFS 主要是在 Kubernetes 上部署,每個節點都有一個 DaemonSet 容器負責掛載 JuiceFS 檔案系統,然後以 HostPath 的方式掛載到渲染引擎的 pod 中。如果掛載點出現故障,DaemonSet 會負責自動恢復掛載點。
在許可權控制上,邊緣儲存是通過 LDAP 服務來認證 JuiceFS 叢集節點的身份,JuiceFS 叢集的每個節點都通過 LDAP 的客戶端與 LDAP 服務進行驗證。
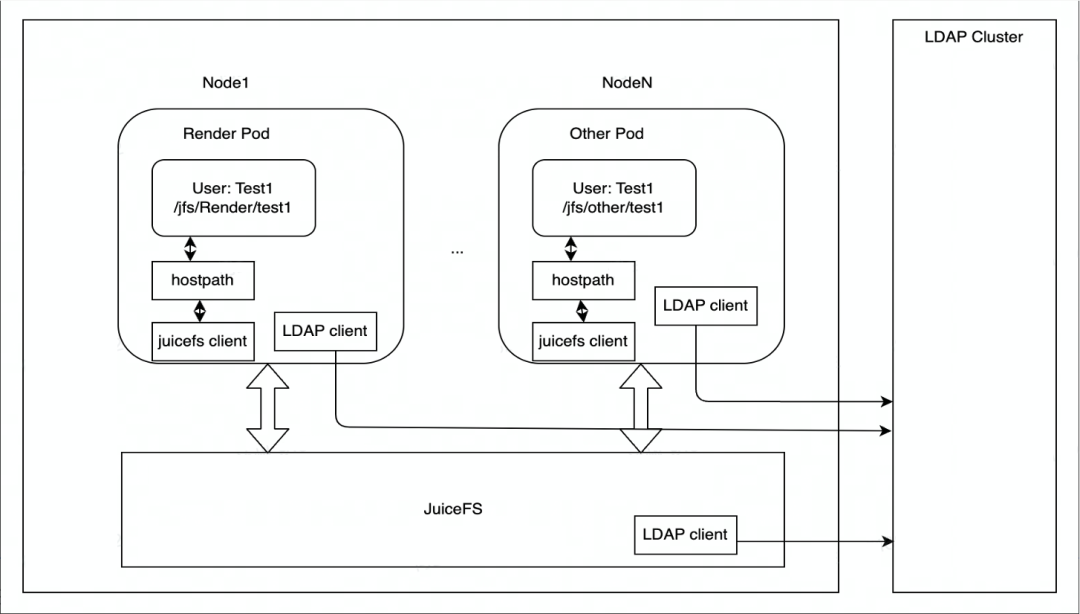
我們目前應用的場景主要還是以渲染為主,後期會擴充套件到更多業務場景。在資料訪問上,邊緣儲存目前主要通過 HostPath 的方式進行訪問,後期如果涉及到彈性擴容的需求,會考慮使用 JuiceFS CSI Driver 來部署。

04- 生產環境中的實踐經驗
元資料引擎
JuiceFS 支援了非常多的元資料引擎(如 MySQL、Redis),火山引擎邊緣儲存生產環境採用的是 MySQL。我們在評估了資料量與檔案數的規模(檔案數在千萬級,大概幾千萬,讀多寫少場景),以及寫入與讀取效能以後,發現 MySQL 在運維、資料可靠性,以及事務方面都做得比較好。
MySQL 目前採用的是單例項和多例項(一主二從)兩種部署方案,針對邊緣不同的場景靈活選擇。在資源偏少的環境,可以採用單例項的方式來進行部署,MySQL 的吞吐在給定的範圍之內還是比較穩定的。這兩種部署方案都使用高效能雲盤(由 Ceph 叢集提供)作為 MySQL 的資料盤,即使是單例項部署,也能保證 MySQL 的資料不會丟失。
在資源比較豐富的場景,可以採用多例項的方式來進行部署。多例項的主從同步通過 MySQL Operator(http://github.com/bitpoke/mysql-operator) 提供的 orchestrator 元件實現,兩個從例項全部同步成功才認為是 OK 的,但是也設定了超時時間,如果超時時間到了還沒有同步完成,則會返回成功,並打出報警。待後期的容災方案健全後,可能會採用本地盤作為 MySQL 的資料盤,進一步提升讀寫效能,降低時延以及提升吞吐。
MySQL 單例項配置 容器資源:
- CPU:8C
- 記憶體:24G
- 磁碟:100G(基於 Ceph RBD,在儲存千萬級檔案的場景下元資料大約佔用 30G 磁碟空間)
- 容器映象:mysql:5.7
MySQL 的 my.cnf 配置:
ignore-db-dir=lost+found # 如果使用 MySQL 8.0 及以上版本,需要刪除這個配置
max-connections=4000
innodb-buffer-pool-size=12884901888 # 12G
物件儲存
物件儲存採用自建的 Ceph 叢集,Ceph 叢集通過 Rook 部署,目前生產環境用的是 Octopus 版本。藉助 Rook,可以以雲原生的方式運維 Ceph 叢集,通過 Kubernetes 管控 Ceph 元件,極大降低了 Ceph 叢集的部署和管理複雜度。
Ceph 伺服器硬體配置:
- 128 核 CPU
- 512GB 記憶體
- 系統盤:2T * 1 NVMe SSD
- 資料盤:8T * 8 NVMe SSD
Ceph 伺服器軟體配置:
- 作業系統:Debian 9
- 核心:修改 /proc/sys/kernel/pid_max
- Ceph 版本:Octopus
- Ceph 儲存後端:BlueStore
- Ceph 副本數:3
- 關閉 Placement Group 的自動調整功能
邊緣渲染主打的就是低時延高效能,所以在伺服器的硬體選擇方面,我們給叢集配的都是 NVMe 的 SSD 盤。其它配置主要是基於火山引擎維護的版本,作業系統我們選擇的是 Debian 9。資料冗餘上為 Ceph 配置了三副本,在邊緣計算的環境中可能因為資源的原因,用 EC反而會不穩定。
JuiceFS 客戶端
JuiceFS 客戶端支援直接對接 Ceph RADOS(效能比對接 Ceph RGW 更好),但這個功能在官方提供的二進位制中預設沒有開啟,因此需要重新編譯 JuiceFS 客戶端。編譯之前需要先安裝 librados,建議 librados 的版本要跟 Ceph 的版本對應,Debian 9 沒有自帶與 Ceph Octopus(v15.2.*)版本匹配的 librados-dev 包,因此需要自己下載安裝包。
安裝好 librados-dev 之後,就可以開始編譯 JuiceFS 客戶端。我們這邊使用了 Go 1.19 來編譯,1.19 中新增了控制記憶體分配最大值(http://go.dev/doc/gc-guide#Memory_limit)這個特性,可以防止極端情況下 JuiceFS 客戶端佔用過多記憶體而出現 OOM。
make juicefs.ceph
編譯完 JuiceFS 客戶端即可建立檔案系統,並在計算節點掛載 JuiceFS 檔案系統了,詳細步驟可以參考 JuiceFS 官方文件。
05- 未來和展望
JuiceFS 是一款雲原生領域的分散式儲存系統產品,提供了 CSI Driver 元件能夠非常好的支援雲原生的部署方式,在運維部署方面為使用者提供了非常靈活的選擇,使用者既可以選擇雲上,也可以選擇私有化部署,在儲存擴容和運維方面較為簡單。完全相容 POSIX 標準,以及跟 S3 使用同一套元資料的方式,可以非常方便地進行上傳、處理、下載的操作流程。由於其後端儲存是物件儲存的特點,在隨機小檔案讀寫方面有較高的延遲,IOPS 也比較低,但在只讀場景,結合客戶端的多級快取,以及大檔案場景,還有讀多寫少的場景,JuiceFS 有比較大的優勢,非常契合邊緣渲染場景的業務需求。
火山引擎邊緣雲團隊未來與 JuiceFS 相關的規劃如下:
- 更加雲原生:目前是以 HostPath 的方式來使用 JuiceFS,後面我們考慮到一些彈性伸縮的場景,可能會切換到以 CSI Driver 的方式來使用 JuiceFS;
- 元資料引擎升級:抽象一個元資料引擎的 gRPC 服務,在其中提供基於多級快取能力,更好地適配讀多寫少的場景。底層的元資料儲存,可能會考慮遷移到 TiKV 上,以支援更多的檔案數量,相對於 MySQL 能夠更好地通過橫向擴充套件來增加元資料引擎的效能;
- 新功能及 bug 修復:針對當前業務場景,會增加一些功能以及修復一些 bug,並期望為社群貢獻 PR,回饋社群。
如有幫助的話歡迎關注我們專案 Juicedata/JuiceFS 喲! (0ᴗ0✿)
- 淺析三款大規模分散式檔案系統架構設計
- JuiceFS 在火山引擎邊緣計算的應用實踐
- 淺析 SeaweedFS 與 JuiceFS 架構異同
- 從 Hadoop 到雲原生, 大資料平臺如何做存算分離
- JuiceFS 商業版 v4.8 新功能: 增強 Kerberos 和 Ranger 支援
- 儲存更彈性,詳解 Fluid “ECI 環境資料訪問” 新功能
- 理想汽車 x JuiceFS:從 Hadoop 到雲原生的演進與思考
- 萬字長文 | 理想汽車:從 Hadoop 到雲原生的演進與思考
- 一面資料: Hadoop 遷移雲上架構設計與實踐
- 淺析 Redis 作為 JuiceFS 元資料引擎的優劣勢
- 40 倍提升,詳解 JuiceFS 元資料備份恢復效能優化之路
- AI 企業多雲儲存架構實踐 | 深勢科技分享
- AI場景儲存優化:雲知聲超算平臺基於 JuiceFS 的儲存實踐
- 30款提升組織效能 SaaS 工具,我們的寶藏工具箱大公開
- Grafana Prometheus 搭建 JuiceFS 視覺化監控系統
- 移動雲使用 JuiceFS 支援 Apache HBase 增效降本的探索
- Grafana Prometheus 搭建 JuiceFS 視覺化監控系統
- JuiceFS 在資料湖儲存架構上的探索
- JuiceFS 在資料湖儲存架構上的探索
- JuiceFS 快取預熱詳解