深度解析|基於 eBPF 的 Kubernetes 一站式可觀測性系統

作者:李煌東、炎尋
摘要
阿里雲目前推出了面向 Kubernetes 的一站式可觀測性系統,旨在解決 Kubernetes 環境下架構複雜度高、多語言&多協議並存帶來的運維難度高的問題,資料採集器採用當下火出天際的 eBPF 技術,產品上支援無侵入地採集應用黃金指標,構建成全域性拓撲,極大地降低了公有云使用者運維 Kubernetes 的難度。
前言
背景與問題
當前,雲原生技術主要是以容器技術為基礎圍繞著 Kubernetes 的標準化技術生態,通過標準可擴充套件的排程、網路、儲存、容器執行時介面來提供基礎設施,同時通過標準可擴充套件的宣告式資源和控制器來提供運維能力,兩層標準化推進了細化的社會分工,各領域進一步提升規模化和專業化,全面達到成本、效率、穩定性的優化,在這樣的背景下,大量公司都使用雲原生技術來開發運維應用。正因為雲原生技術帶來了更多可能性,當前業務應用出現了微服務眾多、多語言開發、多通訊協議的特徵,同時雲原生技術本身將複雜度下移,給可觀測性帶來了更多挑戰:
1、混沌的微服務架構
業務架構因為分工問題,容易出現服務數量多,服務關係複雜的現象(如圖 1)。
 圖 1 混沌的微服務架構(圖片來源見文末)
圖 1 混沌的微服務架構(圖片來源見文末)
這樣會引發一系列問題:
無法回答當前的執行架構; 無法確定特定服務的下游依賴服務是否正常; 無法確定特定服務的上游依賴服務流量是否正常; 無法回答應用的 DNS 請求解析是否正常; 無法回答應用之間的連通性是否正確; ...
2、多語言應用
業務架構裡面,不同的應用使用不同的語言編寫(如圖 2),傳統可觀測方法需要對不同語言使用不同的方法進行可觀測。
 圖 2 多語言(圖片來源見文末)
圖 2 多語言(圖片來源見文末)
這樣也會引發一系列問題:
- 不同語言需要不同埋點方法,甚至有的語言沒有現成的埋點方法;
- 埋點對應用效能影響無法簡單評估;
3、多通訊協議
業務架構裡面,不同的服務之間的通訊協議也不同(如圖 3),傳統可觀測方法通常是在應用層特定通訊介面進行埋點。
 圖 3 多通訊協議
圖 3 多通訊協議
這樣也會引發一系列問題:
- 不同通訊協議因為不同的客戶端需要不同埋點方法,甚至有的通訊協議沒有現成的埋點方法;
- 埋點對應用效能影響無法簡單評估;
4、Kubernetes 引入的端到端複雜度
複雜度是永恆的,我們只能找到方法來管理它,無法消除它,雲原生技術的引入雖然減少了業務應用的複雜度,但是在整個軟體棧中,他只是將複雜度下移到容器虛擬化層,並沒有消除(如圖 4)。
 圖 4 端到端軟體棧
圖 4 端到端軟體棧
這樣也會引發一系列問題:
- Deployment 的期望副本數和實際執行副本數不一致;
- Service 沒有後端,無法處理流量;
- Pod 無法建立或者排程;
- Pod 無法達到 Ready 狀態;
- Node 處於 Unknown 狀態;
- ...
解決思路與技術方案
為了解決上面的問題,我們需要使用一種支援多語言,多通訊協議的技術,並且在產品層面儘可能得覆蓋軟體棧端到端的可觀測性需求,通過調研我們提出一種立足於容器介面和底層作業系統,向上關聯應用效能觀測的可觀測性解決思路(如圖 5)。
資料採集
 圖 5 端到端可觀測性解決思路
圖 5 端到端可觀測性解決思路
我們以容器為核心,採集關聯的 Kubernetes 可觀測資料,與此同時,向下採集容器相關程序的系統和網路可觀測資料,向上採集容器相關應用的效能資料,通過關聯關係將其串聯起來,完成端到端可觀測資料的覆蓋。
資料傳輸鏈路
我們的資料型別包含了指標,日誌和鏈路,採用了 open telemetry collector 方案(如圖 6)支援統一的資料傳輸。
 圖 6 OpenTelemetry Collector(圖片來源見文末)
圖 6 OpenTelemetry Collector(圖片來源見文末)
資料儲存
背靠 ARMS 已有的基礎設施,指標通過 ARMS Prometheus 進行儲存,日誌/鏈路通過 XTRACE 進行儲存。
產品核心功能介紹
核心場景上支援架構感知、錯慢請求分析、資源消耗分析、DNS 解析效能分析、外部效能分析、服務連通性分析和網路流量分析。支援這些場景的基礎是產品在設計上遵循了從整體到個體的原則:先從全域性檢視入手,發現異常的服務個體,如某個 Service,定位到這個 Service 後檢視這個 Service 的黃金指標、關聯資訊、Trace等進行進一步關聯分析。
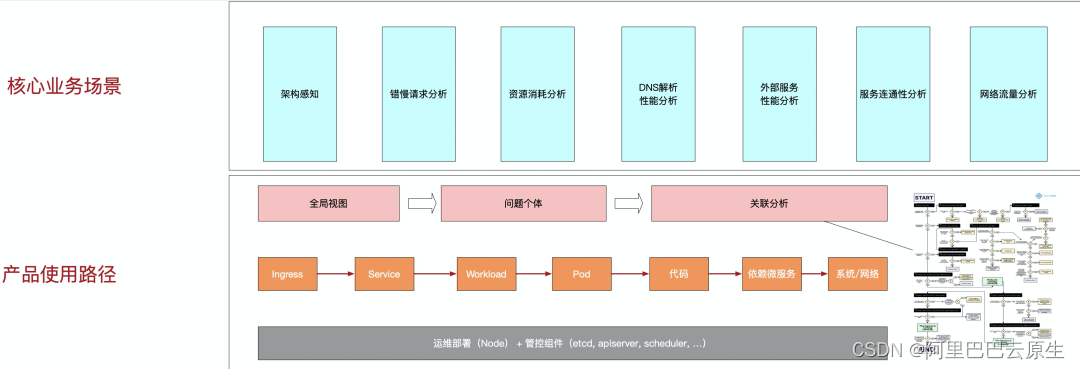 圖 7 核心業務場景
圖 7 核心業務場景
永不過時的黃金指標
什麼是黃金指標?用來可觀測性系統性能和狀態的最小集合:latency、traffic、errors、saturation。以下引自 SRE 聖經 Site Reliability Engineering 一書:
The four golden signals of monitoring are latency, traffic, errors, and saturation. If you can only measure four metrics of your user-facing system, focus on these four.
為什麼黃金指標非常重要?一,直接瞭然地表達了系統是否正常對外服務。二,面向客戶的,能進一步評估對使用者的影響或事態的嚴重性,這樣能大量節省SRE或研發的時間,想象下如果我們取 CPU 使用率作為黃金指標,那麼 SRE 或研發將會奔於疲命,因為 CPU 使用率高可能並不會造成多大的影響,尤其在執行平穩的 Kubernetes 環境中。所以 Kubernetes 可觀測性支援這些黃金指標:
- 請求數/QPS
- 響應時間及分位數(P50、P90、P95、P99)
- 錯誤數
- 慢呼叫數
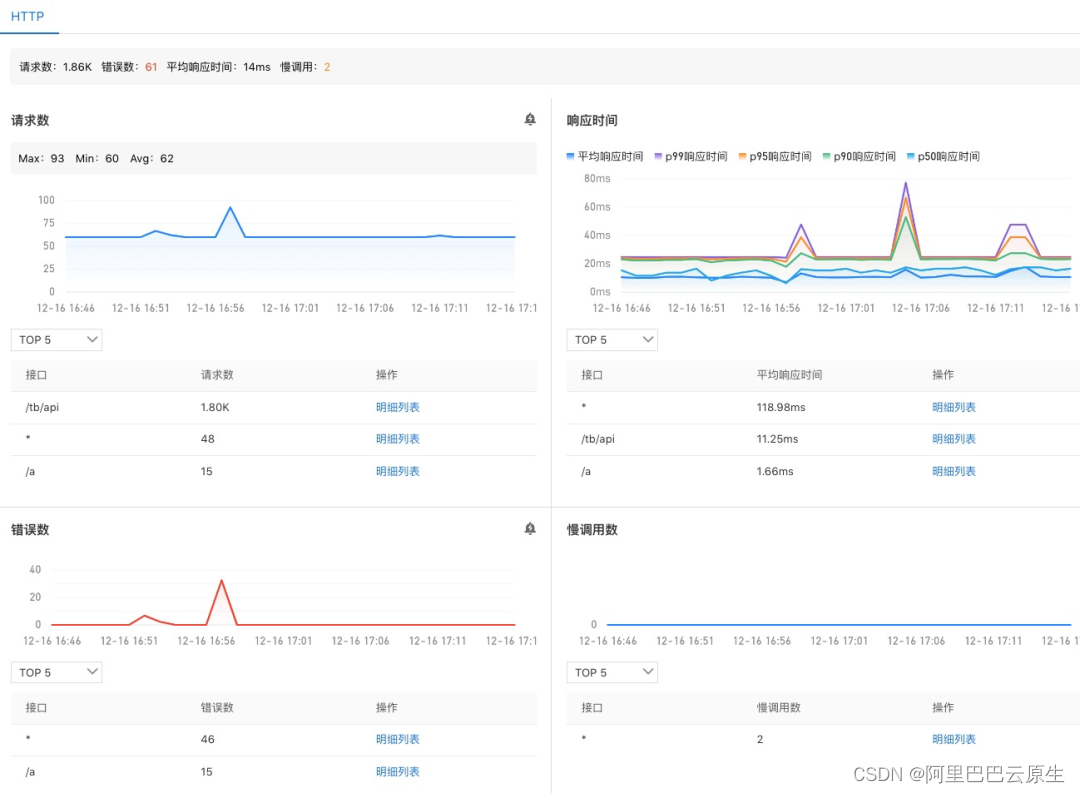 圖8 黃金指標
圖8 黃金指標
主要支援以下場景:
1、效能分析 2、慢呼叫分析
全域性視角的應用拓補
不謀全域性者,不足謀一域 。--諸葛亮
隨著當下技術架構、部署架構的複雜度越來越高,發生問題後定位問題變得越來越棘手,進而導致 MTTR 越來越高。另一個影響是對影響面的分析帶來非常大的挑戰,通常顧得了這頭顧不了那頭。因此,有一張像地圖一樣的大圖非常必要。全域性拓撲具有以下特點:
- 系統架構感知:系統架構圖通常稱為程式設計師瞭解一個新系統的重要參考,當我們拿到一個系統,起碼我們得知道流量的入口在哪裡,有哪些核心模組,依賴了哪些內部外部元件等。在異常定位過程中,有一張全域性架構的圖對異常定位程序有非常大的推動作用。一個簡單電商應用的拓撲示例,整個架構一覽無遺:
 圖 9 架構感知
圖 9 架構感知
- 依賴分析:有一些問題是出現在下游依賴,如果這個依賴不是自己團隊維護就會比較麻煩,當自己系統和下游系統沒有足夠的可觀測性的時候就更麻煩了,這種情況下就很難跟依賴的維護者講清楚問題。在我們的拓撲中,通過將黃金指標的上下游用呼叫關係連起來,形成了一張呼叫圖。邊作為依賴的視覺化,能檢視對應呼叫的黃金訊號。有了黃金訊號就能快速地分析下游依賴是否存在問題。下圖為底層服務呼叫微服務發生慢呼叫導致應用整體 RT 高的定位示例,從入口閘道器,到內部服務,到 MySQL 服務,最終定位到發生慢 SQL 的語句:
 圖 10 依賴分析
圖 10 依賴分析
- 高可用分析:拓撲圖能方便地看出系統之間的互動,從而看出哪些系統是主要核心鏈路或者是被重度依賴的,比如 CoreDNS,幾乎所有的元件都會通過 CoreDNS 進行 DNS 解析,所以我們進一步看到可能存在的瓶頸,通過檢查 CoreDNS 的黃金指標預判應用是否健康、是否容量不足等。
 圖 11 高可用分析
圖 11 高可用分析
- 無侵入:跟螞蟻的 linkd 和集團的 eagleeye 不同的是,我們的方案是完全無侵入的。有時候我們之所以缺少某個方面的可觀測性,並不是說做不到,而是因為應用需要改程式碼。作為 SRE 為了更好的可觀測性固然出發點很好,但是要讓全集團的應用 owner 陪你一起改程式碼,顯然是不合適的。這時候就顯示出無侵入的威力了:應用不需要改程式碼,也不需要重啟。所以在接入成本上是非常低的。
協議 Trace 方便根因定位
協議 Trace 區別於分散式追蹤,只跟蹤一次呼叫。協議 Trace 同樣是無入侵、語言無關的。如果請求內容中存在分散式鏈路 TraceID,能自動識別出來,方便進一步下鑽到鏈路追蹤。應用層協議的請求、響應資訊有助於對請求內容、返回碼進行分析,從而知道具體哪個介面有問題。
 圖 12 協議詳情
圖 12 協議詳情
開箱即用的告警功能
任何一個可觀測性系統不支援告警是不合適的。
1、預設模板下發,閾值經過業界最佳實踐。
 圖 13 告警
圖 13 告警
2、支援使用者多種配置方式
靜態閾值,使用者只需要配置閾值即可,不需要手動寫 PromQL 基於靈敏度調節的動態閾值,適合不好確定閾值的場景 相容 PromQL,需要一定的學習成本,適合高階使用者
豐富的上下文關聯
datadog 的 CEO 在一次採訪中直言 datadog 的產品策略不是支援越多功能越好,而是思考怎樣在不同團隊和成員之間架起橋樑,儘可能把資訊放在同一個頁面中(to bridge the gap between the teams and get everything on the same page)。產品設計上我們將關鍵的上下文資訊關聯起來,方便不同背景的工程師理解,從而加速問題的排查。
目前我們關聯的上下文有告警資訊、黃金指標、日誌、Kubernetes 元資訊等,同時不斷新增有價值的資訊。比如告警資訊,告警資訊自動關聯到對應的服務或應用節點上,清晰地看到哪些應用有異常,點選應用或告警能自動展開應用的詳情、告警詳情、應用的黃金指標,所有的動作都在一個頁面中進行:
 圖 14 上下文關聯
圖 14 上下文關聯
其他
一、網路效能可觀測性:
網路效能導致響應時間變長是經常遇到的問題,由於 TCP 底層機制遮蔽了一部分的複雜性,應用層對此是無感的,這對丟包率高、重傳率高這種場景帶來一些麻煩。Kubernetes 支援了重傳&丟包、TCP 連線資訊來表徵網路狀況,下圖展示了重傳高導致 RT 高的例子:
 圖 15 網路效能可觀測性
圖 15 網路效能可觀測性
eBPF 超能力揭祕
 圖 16 資料處理流程
圖 16 資料處理流程
eBPF 相當於在核心中構建了一個執行引擎,通過核心呼叫將這段程式 attach 到某個核心事件上,做到監聽核心事件;有了事件我們就能進一步做協議推導,篩選出感興趣的協議,對事件進一步處理後放到 ringbuffer 或者 eBPF 自帶的資料結構 Map 中,供使用者態程序讀取;使用者態程序讀取這些資料後,進一步關聯 Kubernetes 元資料後推送到儲存端。這是整體處理過程。
eBPF 的超能力體現在能訂閱各種核心事件,如檔案讀寫、網路流量等,執行在 Kubernetes 中的容器或者 Pod 裡的一切行為都是通過核心系統呼叫來實現的,核心知道機器上所有程序中發生的所有事情,所以核心幾乎是可觀測性的最佳觀測點,這也是我們為什麼選擇 eBPF 的原因。另一個在核心上做監測的好處是應用不需要變更,也不需要重新編譯核心,做到了真正意義上的無侵入。當叢集裡有幾十上百個應用的時候,無侵入的解決方案會幫上大忙。
eBPF作為新技術,人們對其有些擔憂是正常的,這裡分別作簡單的回答:
1、eBPF 安全性如何?eBPF 程式碼有諸多限制,如最大堆疊空間當前為 512、最大指令數為 100 萬,這些限制的目的就是充分保證核心執行時的安全性。
2、eBPF探針的效能如何?大約在 1% 左右。eBPF 的高效能主要體現在核心中處理資料,減少資料在核心態和使用者態之間的拷貝。簡單說就是資料在核心裡算好了再給使用者程序,比如一個 Gauge 值,以往的做法是將原始資料拷貝到使用者程序再計算。
總結
產品價值
阿里雲 Kubernetes 可觀測性是一套針對 Kubernetes 叢集開發的一站式可觀測性產品。基於 Kubernetes 叢集下的指標、應用鏈路、日誌和事件,阿里雲 Kubernetes 可觀測性旨在為 IT 開發運維人員提供整體的可觀測性方案。
阿里雲 Kubernetes 可觀測性具備以下特性:
-
程式碼無侵入:通過旁路技術,不需要對程式碼進行埋點即可獲取到豐富的網路效能資料。
-
語言無關:在核心層面進行網路協議解析,支援任意語言,任意框架。
-
高效能:基於 eBPF 技術,能以極低的消耗獲取豐富的網路效能資料。
-
強關聯:通過網路拓撲,資源拓撲,資源關係從多個維度描述實體關聯,與此同時也支援各類資料(可觀測指標、鏈路、日誌和事件)之間的關聯。
-
資料端到端覆蓋:涵蓋端到端軟體棧的觀測資料。
-
場景閉環:控制檯的場景設計,關聯起架構感知拓撲、應用可觀測性、Prometheus 可觀測性、雲撥測、健康巡檢、事件中心、日誌服務和雲服務,包含應用理解,異常發現,異常定位的完整閉環。
點選此處,前往阿里雲可觀測專題頁檢視更多詳情!
圖片來源:
圖 1: http://www.infoq.com/presentations/netflix-chaos-microservices/
圖 2: http://www.lackuna.com/2013/01/02/4-programming-languages-to-ace-your-job-interviews/
圖 6: http://opentelemetry.io/docs/collector/
歡迎大家掃碼或搜尋釘釘群號(31588365)加入答疑交流群進行交流。
釋出雲原生技術最新資訊、彙集雲原生技術最全內容,定期舉辦雲原生活動、直播,阿里產品及使用者最佳實踐釋出。與你並肩探索雲原生技術點滴,分享你需要的雲原生內容。
關注【阿里巴巴雲原生】公眾號,獲取更多雲原生實時資訊!
- 阿里巴巴重磅開源雲原生閘道器: Higress
- 啟動!阿里巴巴程式設計之夏2022
- 雲原生混部最後一道防線:節點水位線設計
- OpenKruise v1.2:新增 PersistentPodState 實現有狀態 Pod 拓撲固定與 IP 複用
- Serverless Job——傳統任務新變革
- 首評 | 阿里雲順利完成國內首個雲原生安全成熟度評估
- Serverless Job——傳統任務新變革
- 阿里雲釋出效能測試 PTS 2.0:低成本、高效率、多場景壓測,業務穩定性保障利器
- ZooKeeper 在阿里巴巴的服務形態演進
- OpenYurt v0.7.0 版本解讀:無侵入的跨網路域解決方案 Raven
- K8s 閘道器選型初判:Nginx 還是 Envoy?
- K8s 閘道器選型初判:Nginx 還是 Envoy?
- ZooKeeper 在阿里巴巴的服務形態演進
- 面向高校 | “雲原生技術應用與實踐”示範課程專案開放申報
- 硬之城獲阿里雲首批產品生態整合認證,攜手阿里雲共建新合作
- 基於阿里雲 ASK 的 Istio 微服務應用部署初探
- Seata 1.5.1 重磅釋出,支援使用者控制檯,企業版正式免費公測
- OpenYurt v0.7.0 版本解讀:無侵入的跨網路域解決方案 Raven
- 最佳實踐|從Producer 到 Consumer,如何有效監控 Kafka
- 報名進入尾聲,趕快申請加入 sealer 開源之夏吧!