百度混部實踐系列 | 如何提高 K8S 叢集資源利用率?
【百度雲原生導讀】隨著Kubernetes(以下簡稱『K8S』)被業界越來越廣泛地使用,單個叢集規模也逐漸增大,很多人都會發現自己維護的 K8S 叢集普遍存在一個問題:分配率較高,而利用率偏低。
比如,一個有1000+節點的叢集,在分配率達到80%後,常常會因為叢集碎片的原因,很多大規格的 Pod 就無法再被創建出來。而與此同時,整個叢集的日均 CPU 利用率卻不足15%,常態使用率偏低。那麼,如何才能把剩餘的閒置資源儘可能利用到極致呢?
今天這篇文章,是百度雲原生團隊分享雲原生混部實戰的第一彈,我們一起探索 K8S 原理,用 K8S 原生的方式來解決這個問題。
1. 原生 K8S 能否解決資源利用率問題?
首先,我們來看下圖這個示例。圖中黃色框代表2個 Node,這兩個 Node 的 CPU 總數都是40核,並且都已經分配了38核。其中 NodeA 的真實用量是35核,NodeB 的真實用量是10核。而藍色框則代表現在我們還有3個待排程的 Pod。
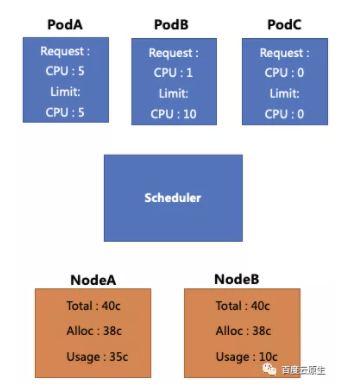
若想排程3個 Pod:
-
PodA 的 Request 和 Limit 都是5c,此時它無法被排程,即使Node B上還有空閒資源;
-
PodB 的 Request 為1c,Limit 為10c,該 Pod 超發比較嚴重,它可以被排程到 NodeA 或 NodeB,但是排程到 NodeA 時可能被驅逐;
-
PodC 的 Request 和 Limit 都沒有填寫,此時它可以被排程,但是當排程到 NodeA 時可能被驅逐
基於以上場景,可以嘗試總結一下為什麼原生 K8S 沒辦法直接解決資源利用率的問題:
第一,資源使用是動態的,而配額是靜態限制。線上業務會根據其使用的峰值去預估Quota(Request和Limit),配額申請之後就不能再修改,但資源用量卻是動態的,白天和晚上的用量可能都不一樣。
第二,原生排程器並不感知真實資源的使用情況。所以對於 PodB,PodC 這種想要超發的業務來說,無法做到合理的配置。
基於這些原因,團隊進行了下一階段的方案設計:引入動態資源檢視
2. 引入動態資源檢視
通過新增一個 Agent 去收集單機的資源用量情況,並且彙總計算得到動態的資源檢視(機器真實的用量情況),將其上報到排程器,在排程器中配置相關策略,可以將上文中提到的 PodB 和 PodC 準確的排程到 NodeB 上。
也就是說通過構建資源檢視,可以將 Limit 大於 Request 的 Pod 或者沒填 Request 和Limit 的 Pod,呼叫到真實用量更少的 Node。這個方法可以解決由於不知道機器到底用了多少資源,所以排程失敗被驅逐的問題,最終達到提升 CPU 利用率的效果。
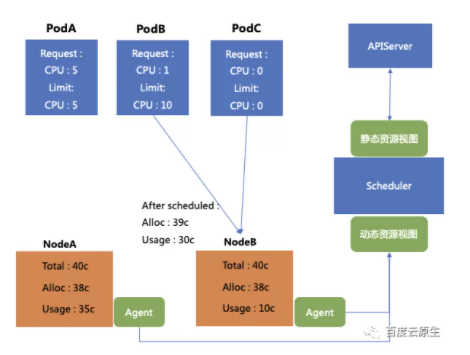
但是這樣做需要付出什麼代價?如果要將 PodB 和 PodC 排程到 NodeB 上,NodeB 的配額只多分配了1核,但是用量卻上升了20核,這就造成了超量使用。(申請量非常少,但是用量非常多)
對於 Node B,多用的20核其實是已經分配出去的 Pod 沒有用到,暫時讓出的。
為了方便理解舉個例子:因為工作需要,我申請了三臺電腦,平時大部分情況只用一臺,剩下的兩臺可以借給其他同事暫時用一用;但是我申請3臺也是有原因的,有時候是真的要用到的,那當有用到的時候,同事就必須要還給我,所以這就涉及到一個『如何借』和『如何還』的問題。
2.1 借用的代價:不穩定的生命週期
在上述的排程情況下,如果 PodC 用量持續增長,整體的負載可能超過了對單機裝置的驅逐上限,會觸發單機 kubelet 的驅逐行為。
對應到上述的例子中,如果我共有三臺電腦,平時只用一臺,外借了兩臺。現在由於工作需要我要多用一臺(整體用量上漲),在這種情況下我並不需要一次性把兩臺電腦都收回(驅逐 Pod),而是僅收回我需要的那一臺即可。
比如在 CPU 層面,可以嘗試先降低 PodC 的 CPU Quota;在記憶體層面,可以先嚐試進行記憶體回收。換句話說,可以優先考慮降低資源使用情況,而不是直接驅逐掉 Pod。
因此有兩個核心問題要解決:第一,動態資源檢視要如何做;第二個單機資源的調配如何保證供給。
2.2 單機引擎:隔離與退避
名詞解釋:Guaranteed-Pod、Burstable、BestEffort
K8S中的QoS是根據request 和limit動態算而來:
request等於limit,會被放到Guaranteed-Pod之中
request不等於limit,會被放在這個Burstable(突發型)目錄下
request和limit都沒有填,會被放在BestEffort目錄下
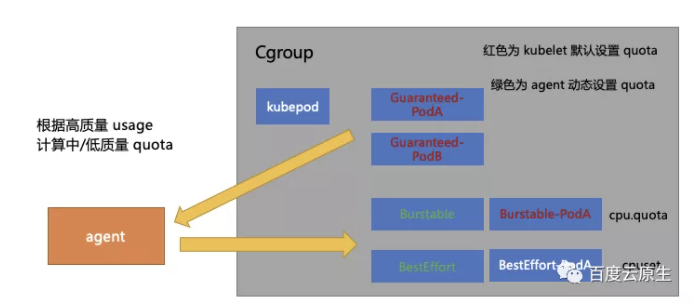
上圖灰色框的部分是 kubelet 為每個 Pod 設定 Cgroup 的目錄結構:首先有一個一級目錄叫 kubepod,所有 Pod 的 Cgroup 都會被掛到它下面,圖中有兩個紅色字型的 Guaranteed-Pod 是直接被掛載到 kubepod 目錄下。
圖中紅色字型部分(Guaranteed-Pod, Burstable-Pod)的目錄由 kubelet 給它們設定 Quota。以CPU為例,比如 Limit 填 5,Quota 就會設定為 5。白色字型部分是沒有 Quota 限制的( kubepod 和 BestEffort-Pod),可以看到的是 Burstable,BestEffort 這兩種 Pod 沒有直接掛在 kubepod 目錄下,而是自己有一個原本是空白的沒有值的二級目錄。
在樹形結構下 Cgroup 有如下特點:單個目錄下程序使用的資源限制並不僅僅受自己所在節點的限制,還要受父節點的限制。比如在 Burstable 的框下邊有兩個Pod(圖無關),在 Burstable 那個框設定了一個 Quota 是 10c,那這兩個 Burstable-Pod 的 CPU 用量總和不能超過 10c。
基於這個原理團隊設計了對應的壓制策略,單機引擎會根據 Guaranteed-Pod 的真實用量去給 Burstable 目錄整體設定了一個值,這個值通過動態計算而來。簡單來說,會先計算一下 Guaranteed-Pod 現在用多少,還剩多少資源可以給到 Burstable。BestEffort也是類似的,會先計算 Guaranteed 和 Burstable 現在的 Pod 的用量是多少,然後給框整體設定一個值。
如果單機的用量起來了,即申請的 Pod 現在要把自己借出去的這部分資源拿回來了,如何處理?此時會通過動態計算縮小 Burstable 和 BestEffort 的這兩個框的值,達到一個壓制的效果。
在不考慮整機 Quota 超發的情況下,如果整機 Quota 都分完了, 整機 Pod 資源用量又在持續上漲,這種情況要如何處理?
當資源用量持續上漲時,如果 BestEffort 框整體 CPU 用量小於 1c ,單機引擎會把 BestEffort Pod 全部驅逐掉。K8S 本身在單機發生資源緊張的時候,也是會按照這種順序去驅逐相應的Pod。當Guaranteed-Pod的用量還在持續上漲的時候,就會持續的壓低 Burstable 整框 CPU 的Quota,從而達到壓制的效果。
Burstable 型別的 Pod 的特徵是 Request 不等於 Limit , 該型別的 Pod 申請了相應資源的 Quota, 在這個前提下,Burstable 框內的Pod,最低會壓到本來申請的資源量。比如 Burstable 框下只有一個Pod,Request是1c,Limit是10c,那麼單機引擎最低會將 Burstable 整框壓制到 1c。
換言之,對於 Request,就是說那些使用者真實申請了 Quota 的資源,一定會得到得到供給;對於 Limit - Request 這部分資源,單機引擎和排程器會讓它儘量能夠得到供給;對於 BestEffort,也就是 No Limit 這部分資源,只要單機的波動存在,就存在被優先驅逐的風險.
但是對於一些長尾延遲來說,僅僅通過上述 K8S 的手段,保證不了服務質量。發生爭搶時,系統 load 就會比較高。所以團隊引入了內部的一些核心功能,並且對它進行一些擴充套件和支援,基本包括以下幾類:

2.3 單機引擎:構建資源檢視
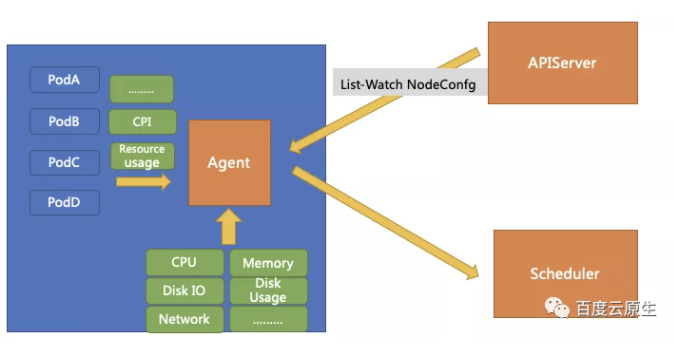
單機 Agent 需要收集兩部分資源:Pod 的資源使用情況以及整機的資源使用情況(包括機器核心指標),實時計算實時發生行為同時實時計算上報一份已經算好的資料,可以減輕排程器的計算壓力。
-
中等質量容器可用量 = 單機最大 CPU 用量 - 高質量容器用量 - Safety-Margin
-
低等質量容器可用量 = 單機最大 CPU 用量 - 高質量容器用量 - 中等質量容器用量 - Safety-Margin
這裡的 Safety-Margin 是安全水位線,作為預留buffer能夠避免用量突然的上漲導致整機突然被打滿。
這樣就構造出了一個單機的資源檢視,將其上報到排程器,排程器將此檢視來作為排程依據進行優選和預選的策略。
同時單機上還有一些可定製化的策略。通過給這些策略設計了一個這個 CRD ,單機引擎通過對 APIServer 發起 List-watch,實時的 Watch CR 的變更,實時調整引數和相關策略。
2.4 超發的結果:質量分級
以上,團隊完成了在 K8S 上混部探索的第一階段,這個方案基於 K8S 沒有做侵入式改動。
但是在對接使用者時經常要面對兩個問題:一是使用者不知道 Request 和 Limit 要怎麼填?
需要先對相關概念做科普:
-
Request 部分,代表是穩定的,安全的,只要申請了就一定可以用到的資源.。
-
Limit 減去 Request 部分,比如說申請的 Request 是5,Limit 是10,中間的 5核 的差距是相對來說不穩定,但大概率能夠得到供給的資源。如果說有需要的時候,系統會嘗試把該 Pod 超用的資源壓縮回去。
-
No Limit,就是既不寫 Request 也不寫 Limit 的部分會盡量保證,但是資源供給 sla 會是一個比較低的數字,用這部分資源就要有隨時被殺掉的準備。
第二個問題是如果可能,使用者是否都傾向於用第一種 Request 級別的資源?
答案是否定的。事實證明,如果能把成本降下,一些魯棒性高的業務是願意接受低質量資源的。
比如一些不敏感的離線業務,如果被 kill,代價就是過一會再跑或者重新算一遍,它是樂於接受這種這個低質量資源的,前提條件是系統要給一個很低的成本。
因此團隊構造了下圖的成本模型,對於不同質量的資源,有不同的定價。作為平臺方給使用者結算計費的時候,會根據實際的用量和質量的乘積進行結算。
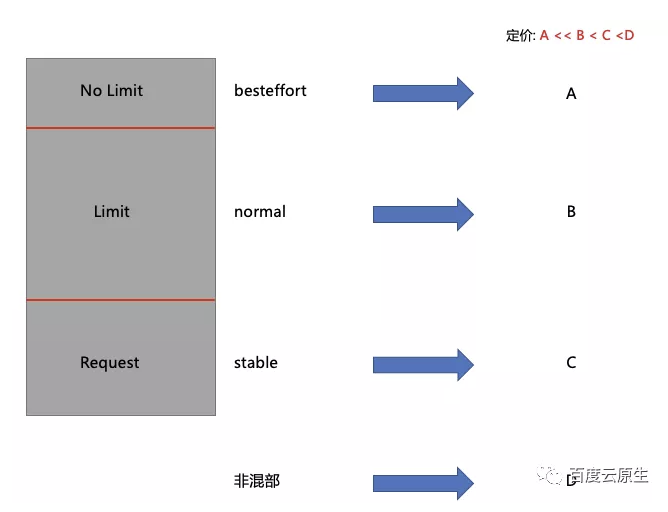
比如 K8S 叢集中託管的機器沒開混部,定價可能是D(假設D為1);在開了混部的叢集當中,使用者去用這些 Request,價格可能就是0.85;在開了混部的很多叢集當中,使用者用 Limit 部分的話,價格可能就是0.5;如果用 Besteffort 部分,那可能它的價格是0.1。
通過這種方式,找到了第一批的這個種子使用者。不管是線上業務、離線業務、測試業務,還有一些內部 DevOps 業務,都非常願意根據這個成本模型再重新審視自己的業務模型, 選擇對應的資源等級來執行自己的業務。
3.落地之後遇到了哪些問題
熱點問題 : 保證了用量, 如何保證質量?
熱點問題並不僅僅是混部帶來的,線上跟線上業務部署在同一臺機器上也有這個問題。比如資源的爭搶、核心關鍵路徑的爭搶都可能導致延遲的上升。在百度內部如果搜尋的一個介面,由於混部質量導致延遲超過一百毫秒的話,影響面就會非常大,因為業務的鏈路通常都比較長,延遲累計最終給使用者響應的時間可能達到秒級,這種情況是不可接受的。
除了核心提供的隔離技術外,如何給出熱點問題的兜底方案?
答案是熱點遷移,出現熱點,系統自動遷移容器。具體而言,單機引擎會通過收集應用的一些指標來判斷這個應用是否發生熱點。如果發生熱點的話,就會給一個機器上打一個 Annotation,然後當排程器 Watch 到這個 Annotation 時,它就會認為臺機器上發生了熱點,就要遷移熱點容器。
Pending Pod : 低質量需求激增帶來的排程效能需求
以某使用者跑數的場景為例,假設他預計需要1000核資源,要在明天早上9點完成,因此他就申請了1000核高質量的資源,同時他又申請了1萬核 Besteffort 的資源一塊跑,通過了1萬核的低質量的資源加速,可能不用明早9點,半夜1點就跑完了,剩下的這部分成本就了省下來。
但是使用者這種使用方法會給排程器的效能帶來很大影響,在叢集負載較高時,使用者建立的 BestEffort Pod 由於資源不足導致全部 Pending,而這些 Pending Pod 會反覆的出現在排程佇列中,針對這種場景,我們嘗試對離線排程器進行功能和效能上的優化 :
-
副本數託管 : 基於叢集負載對應用進行動態擴縮容。社群叫 HCPA,使用者通過建立一個 CR 來描述任務的最低的副本數是多少,最高的副本數是多少,當叢集負載發生變化的時候,Controller 可以動態的擴縮使用者的任務副本數,而不再是靜態的創建出海量的 Pending Pod, 阻塞在佇列中。
-
多排程器 : 基於質量的多排程器。對 Besteffort 的容器來說, 在排程時排程器並不關心靜態資源檢視,也就是 Node Allocatable Resource。排程器只關心這臺機器上現在還剩多少可用資源,所以在資源檢視的角度,天然就和其他兩種質量的 Pod 不衝突. 基於這個前提,我們將 Guaranteed 和 Burstable 兩種型別的 Pod 歸併到一個排程器內進行排程, 而 BestEffort 型別的 Pod 則在另外一個離線排程器內排程。
-
等價類合併 : 在一個排程週期內, 使用相同 Pod Template 生成的 Pod, 在進行排程計算時一定會得到相同的 Node 列表。基於這個前提, 在排程上我們構造了等價類的概念,在排程時單位從 Pod 變成了 PodEquivalenceGroup. 在優選結束後, 會按照 Node 分數的順序來依次排程 PodEquivalenceGroup 中的所有 Pod。這樣處理相當於將 O(n) 的排程計算降為了 O(1)。
-
樂觀併發排程 : 目前開源的 Kubernetes 排程器, 無論是預設排程器還是社群的 kube-batch, volcano 都是依次進行排程的,隊頭阻塞的現象較為嚴重。在優先順序相同的情況下, 最後一個 Pod 的排程延遲約等於佇列內所有 Pod 的排程延遲之和。併發的關鍵在於如何解決衝突 : 在排程器記憶體中為每一個 Node 維護了一個版本號, 當 Pod 與 Node 進行 Bind 操作時, 會嘗試對 Node 版本號進行 +1 的 CAS 操作, 如果失敗,則說明該 Node 已經發生過 Bind 操作, 此時會將該 Node 重算並重新嘗試排程。基於 CAS + Version 的機制, 我們實現了同優先順序情況下, Pod 併發排程的方案。該方案可以帶來 4 ~ 8 倍的排程效能提升。
4.總結
-
K8S 原本的資源模型存在侷限性。我們可以基於原生的 QOS 體系做一些不修改原本語義的擴充套件行為,並且基於質量建立相應的定價體系,通過給出不同質量的資源供給 SLA,來對資源進行差異化定價,從而引導使用者更加合理地使用資源。目前我們在做的進一步探索是,如何根據業務特徵,來劃分出更適合業務的,更細粒度的資源模型。
-
建立雲原生可觀測體系,根據質量去做單機資源的隔離/壓制以及驅逐行為。因為在常見混部的情況下熱點問題經常發生,由於熱點對延遲敏感型業務會造成較大的影響,所以熱點問題事實上限制了整機最大的資源利用率。而熱點問題根因通常在核心層面,核心的可觀測性又比較差,因此目前百度雲原生團隊在探索基於 ebpf 來建立更細粒度的熱點探測/分析體系。
-
大規模混部落地後,需要對熱點問題、排程效能等問題給出解決方案。後續持續迭代相應的排程功能,在排程效能和支撐大資料業務容器化上做出更進一步的探索。
- End -
進群!聊聊混部
掃碼新增小助手即可申請加入,一定要備註:名字-公司/學校-地區,根據格式備註,才能通過且邀請進群。

瞭解更多微服務、雲原生技術的相關資訊,請關注我們的微信公眾號【百度雲原生】!

- 如何治理資源浪費?百度雲原生成本優化最佳實踐
- OpenTelemetry 在服務網格架構下的最佳實踐
- 百度可觀測系列 | 如何構建億級指標的高可用 TSDB 儲存叢集?
- 百度可觀測系列 | 採集億級別指標,Prometheus 叢集方案這樣設計
- AI 原生雲:是“現在式”也是“未來時”
- 服務網格在聯通的落地實踐
- 深入理解百度在離線混部技術
- 百度可觀測系列 | 基於 Prometheus 的大規模線上業務監控實踐
- 殊途同歸,Proxyless Service Mesh在百度的實踐與思考
- 實踐 | 百信銀行基礎設施容器化改造之路
- 雲原生計算動態週報9.6-9.12
- 雲原生計算動態週報9.6-9.12
- 百度混部實踐系列 | 如何提高 K8S 叢集資源利用率?
- 雲原生計算動態週報8.30-9.5
- 雲原生計算動態週報8.30-9.5
- 服務網格在百度核心業務大規模落地實踐
- 雲原生計算動態週報8.23-8.29
- 雲原生計算動態週報8.23-8.29
- 如何用3分鐘搭建一個屬於自己的網站?
- 雲原生計算動態週報8.16-8.22