Python GUI設計——環境搭建
Python GUI設計——環境搭建
一、Python GUI環境需要的工具:
- Python3.9安裝包(官方網站下載:http://www.python.org/downloads/)
- Pycharm整合開發工具
- PyQt相關的第三方庫(包括pyqt5,pyqt5-tools,pyqt5designer(這個pyqt5designer可以不裝,如果你喜歡中文的QT設計器就請安裝它))
二、Python GUI環境安裝:
- Python3.9 安裝過程略
- Pycharm 安裝過程略
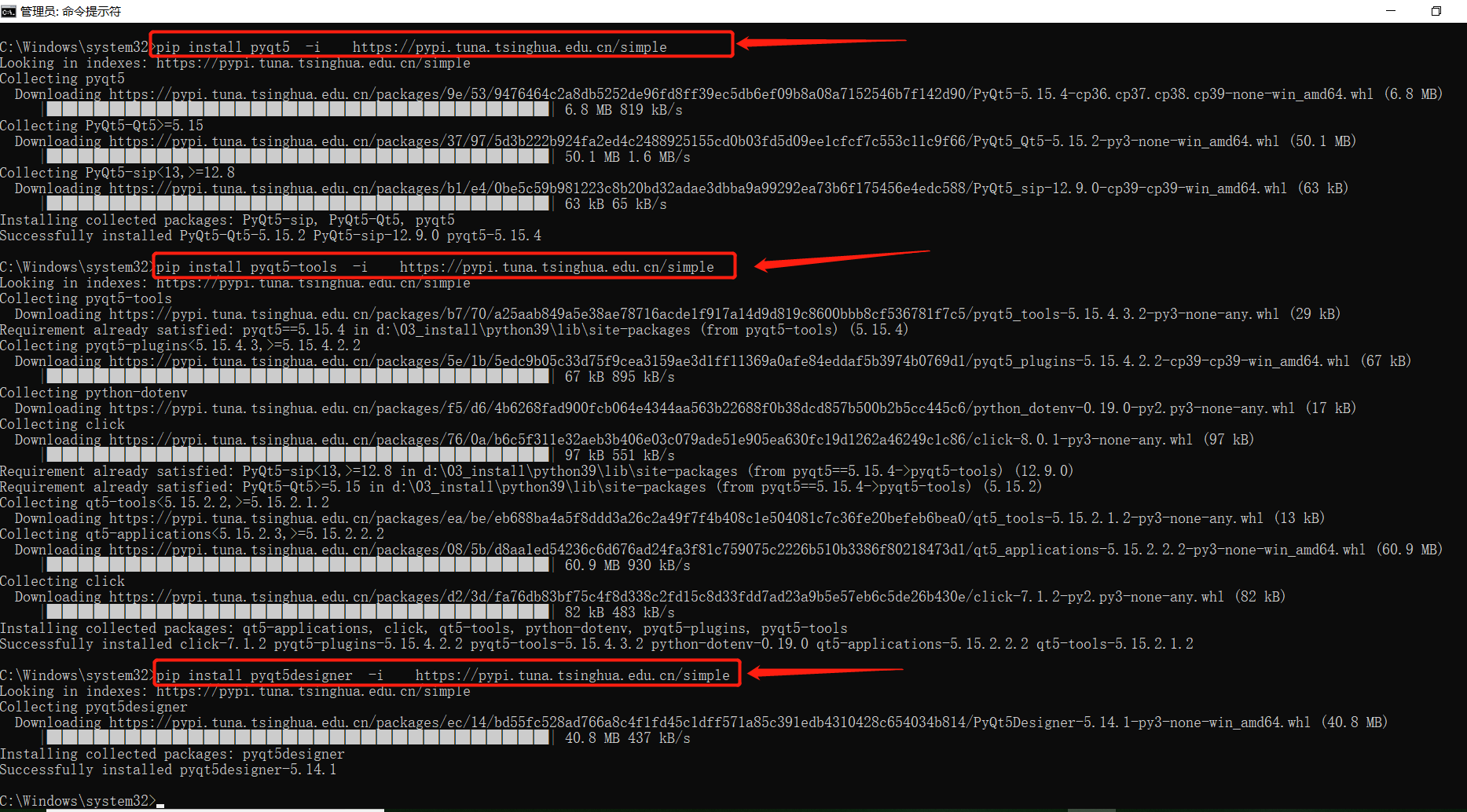
- PyQt相關的第三方庫(包括pyqt5,pyqt5-tools,pyqt5designer)安裝如下,cmd中先後執行下面3條命令:
-
pip install pyqt5 -i http://pypi.tuna.tsinghua.edu.cn/simple pip install pyqt5-tools -i http://pypi.tuna.tsinghua.edu.cn/simple pip install pyqt5designer -i http://pypi.tuna.tsinghua.edu.cn/simple執行截圖:
-
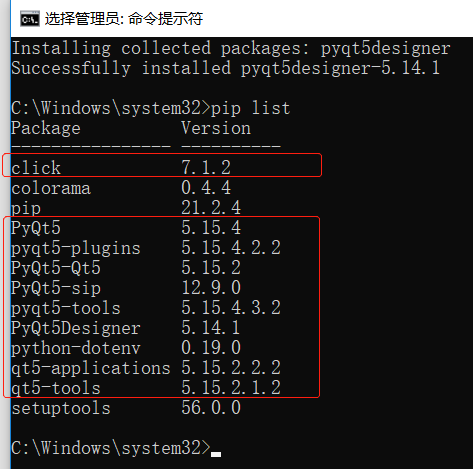
驗證下是否安裝好,cmd執行命令: pip list
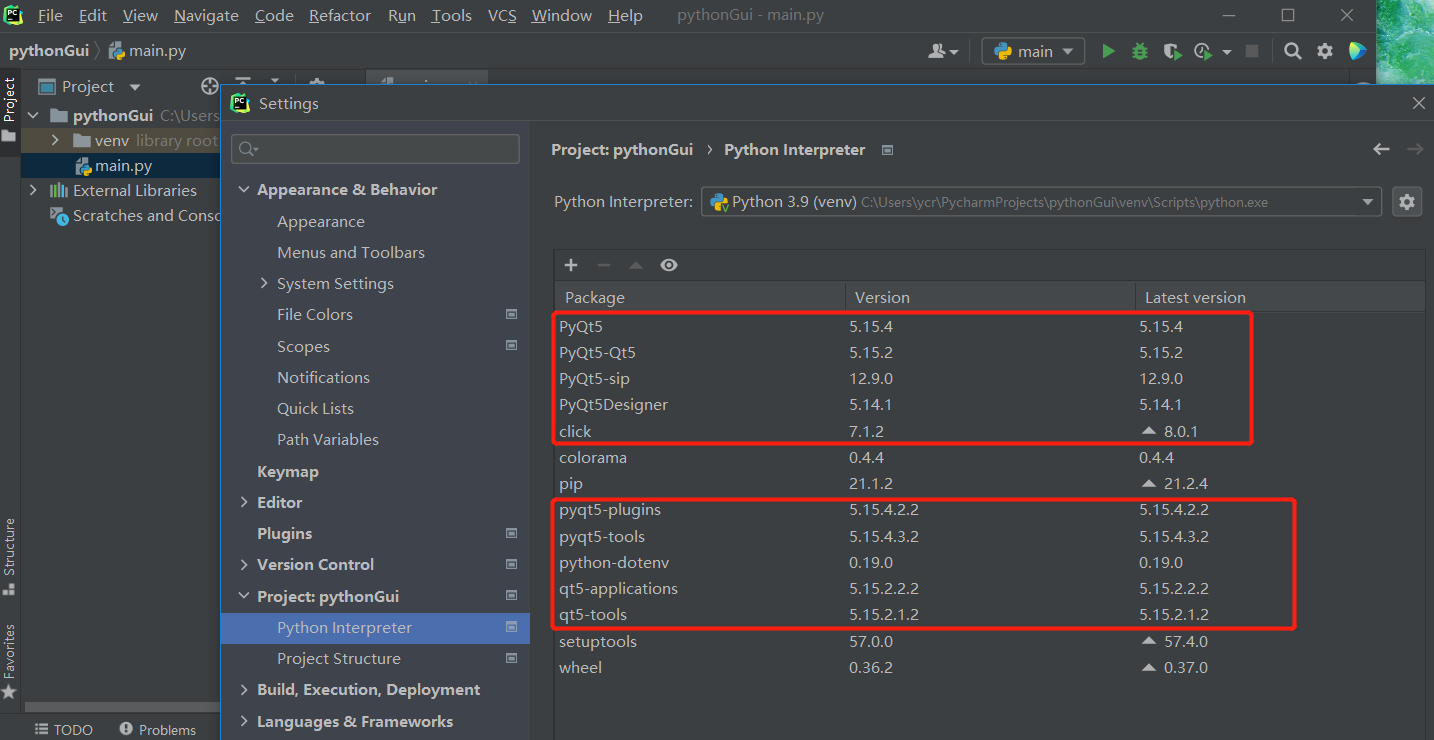
到Pycharm中再確認一把,都安裝好了:
三、Python GUI環境中PyQt5及程式碼轉換工具的配置:
1、進到Pycharm對應位置:file-settings-Tools-External Tools,配置下pyqt5designer擴充套件工具引數
- 配置中文的qtdesigner
配置下3個引數:
Name(自己隨意填),
Program:D:\03_install\Python39\Scripts\designer.exe(D:\03_install根據你自己的python目錄下調整)
Working directory:$FileDir$ 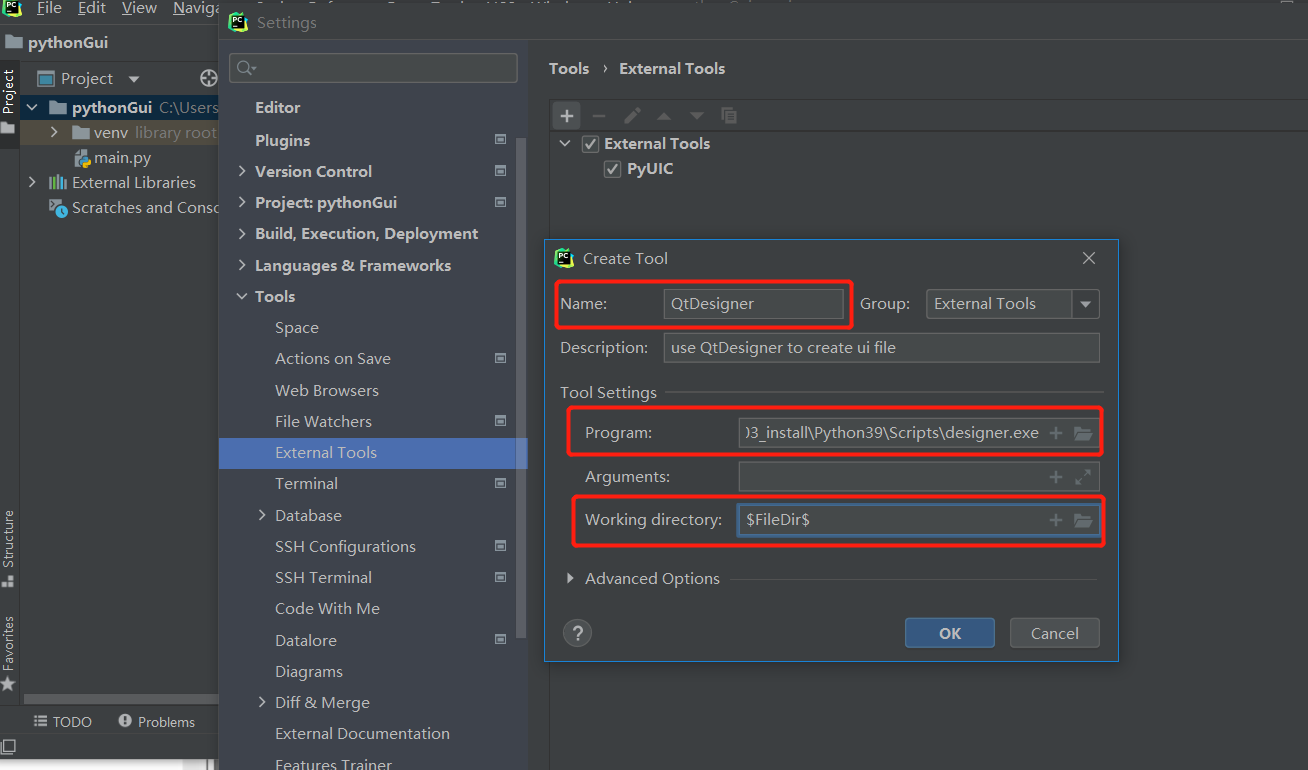
2、進到Pycharm對應位置:file-settings-Tools-External Tools,配置下pyuic程式碼轉換擴充套件工具引數(有2種方式,都可以)
- 第一種方式:使用python.exe 啟動
配置下四個引數:
Name(自己隨意填),
Program:D:\03_install\Python39\python.exe(你自己的python安裝目錄下python.exe位置)
Argument:-m PyQt5.uic.pyuic $FileName$ -o $FileNameWithoutExtension$.py
Working directory:$FileDir$ 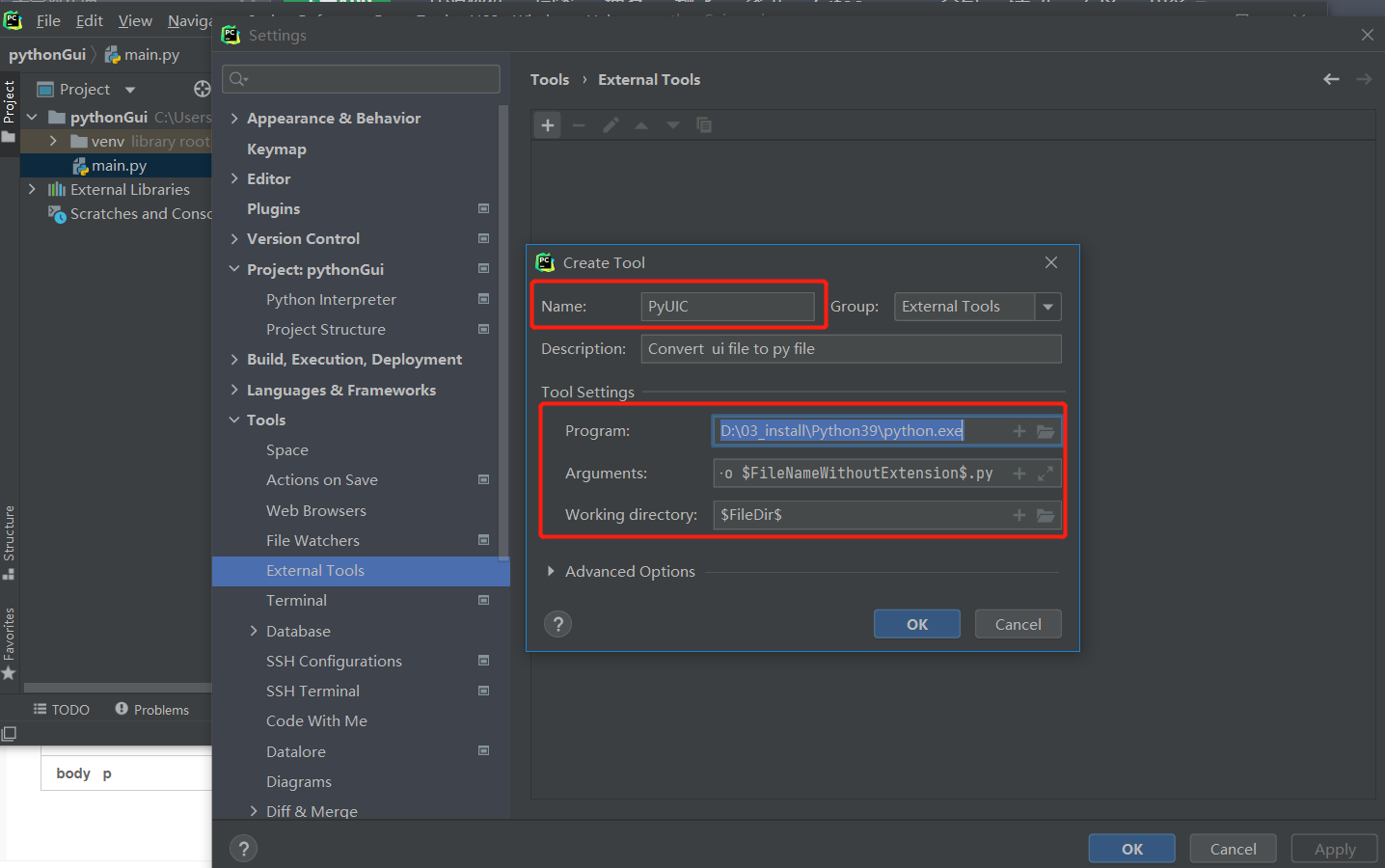
引數配置好了,就點選OK,應用並儲存好。
- 第二種:使用pyuic5.exe 啟動
配置下四個引數:
Name(自己隨意填),
Program:D:\03_install\Python39\Scripts\pyuic5.exe(D:\03_install根據自己的python目錄下調整)
Argument: $FileName$ -o $FileNameWithoutExtension$.py
Working directory:$ProjectFileDir$ 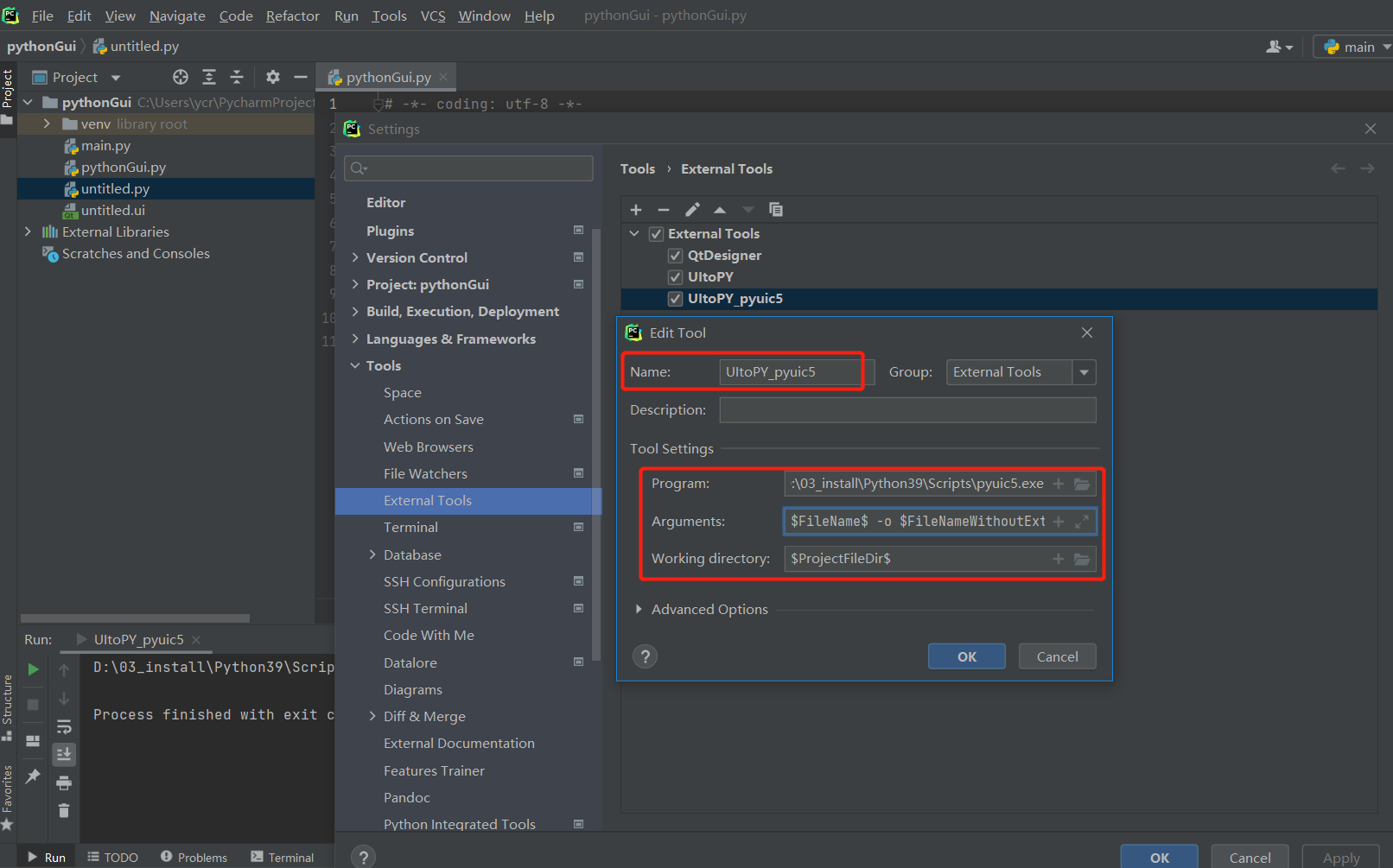
四、檢視pyqt5designer擴充套件工具引數和pyuic程式碼轉換擴充套件工具引數是否配置好:
1、首先,pycharm 的Tools中有新配置的擴充套件工具
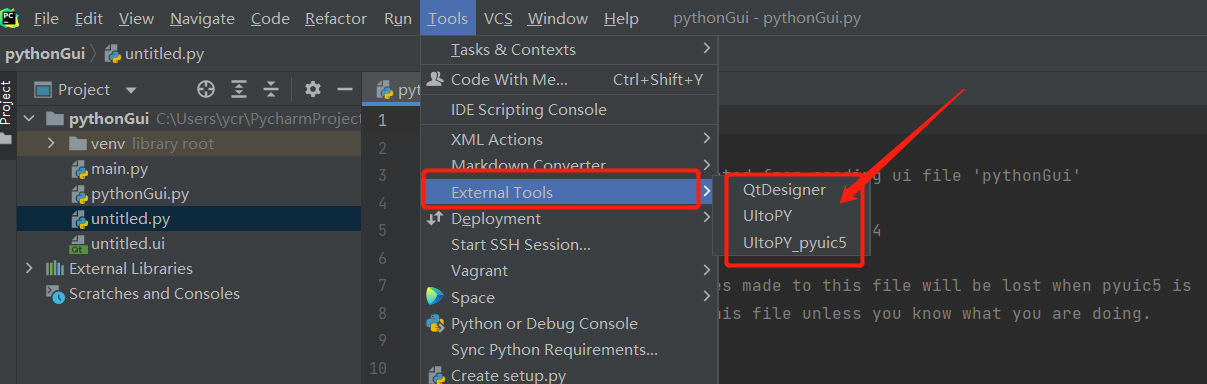
2、執行擴充套件工具中的QtDesigner,生成 .ui檔案;
3、選中上一步中的.ui 檔案執行擴充套件工具中的UItoPY_pyuic5,即可將 .ui檔案轉為.py檔案;